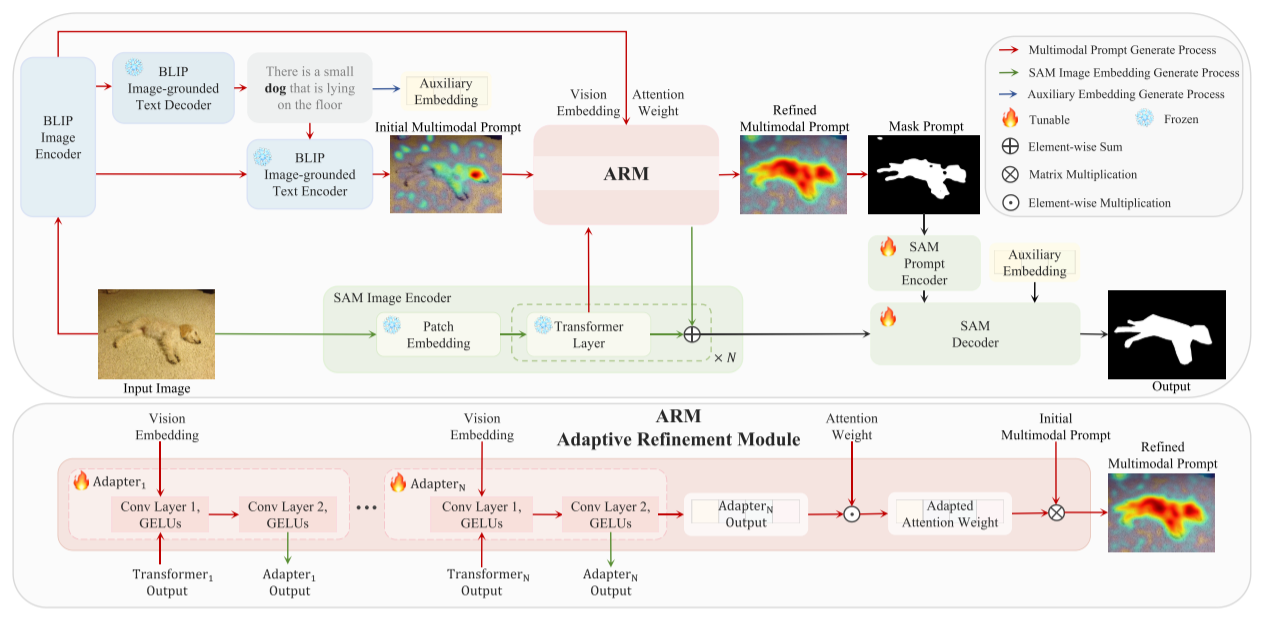
一、首先是图像caption的生成。
输入的图像,被输入进BLIP的图像编码器得到图像嵌入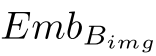 ,图像嵌入再经过
,图像嵌入再经过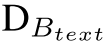 (BLIP Image-grounded Text Decoder)
(BLIP Image-grounded Text Decoder)
得到图像caption。
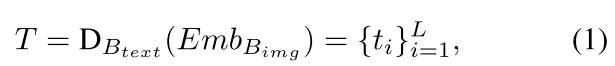
ti表示caption的第i个单词,总共有L个单词。
但是,caption中会存在与目标对象无关的内容(floor),分散了注意力。所以我们使用spaCy库进行词性标记,提取出现在caption中的第一个名词。
二、Initial Multimodal Prompt的生成。
我们将图像嵌入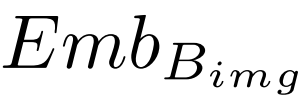 与名词
与名词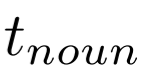 输入进BLIP Image-grounder Text Encoder
输入进BLIP Image-grounder Text Encoder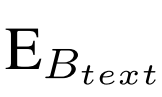 ,然后它会输出一个分数S,反应输入图像与文本的匹配程度。
,然后它会输出一个分数S,反应输入图像与文本的匹配程度。

Across表示来自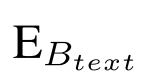 的cross attention layer的注意力权重,反映着图像和文本的关系。
的cross attention layer的注意力权重,反映着图像和文本的关系。
接着,通过反向传播以获得梯度Gcross,Gcross再与Aross进行element-wise(逐元素运算)。
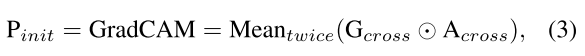
Pinit就是Initial Multimodal Prompt。
Grad-CAM表示梯度加权类激活映射,是一种可视化技术,可视化BLIP(输入多模态数据后)的对齐过程,以生成热力图(Pinit)。
这里的平均操作是,对每个注意头下不同文本序列对图像的影响进行平均,从而得到最终的Pinit。
也就是说,哪里影响最大,图像的哪里就高亮。
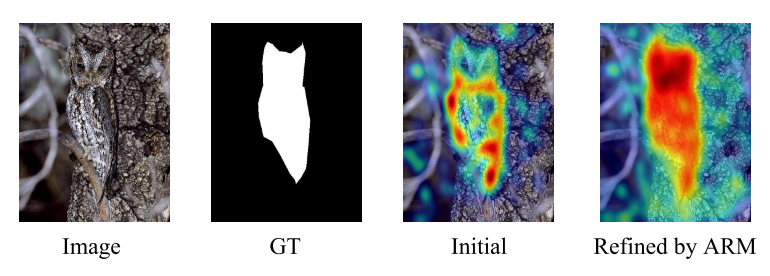
上面得到Pinit后,我们发现Initial的掩码是不完整的,所以我们设计了ARM模块来优化这个不完整prompt。
因为,我们输入的文本只有一个名词,并没有额外的描述,所以最初生成的prompt只能粗略地之时对象的位置,而不能完全捕获其结构。
三、ARM
1、Adapter部分

对于每一个Adapter模块,计算过程是(Conv是二维卷积):
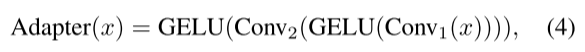
对于第k个Adapter模块的输出:
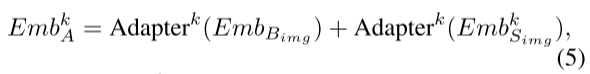
等号左边是第k个Adapter模块的输出,右边的第一个Emb是从上面来的Vision Embedding(BLIP Image Encoder),第二个Emb是从下面来的嵌入(SAM Image Encoder中的第k个Transformer Layer输出的图像嵌入)。
2、SAM图像编码器的优化。
上面第k个Adapter的输出与SAM图像编码器中第k个Transformer层的输出相结合,作为第k+1个Transformer层的输入。
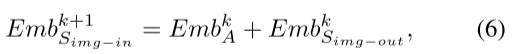
从左到右,第一个Emb是第k+1个Transformer层的输入,第二个Emb是第k个Adapter的输出,第三个Emb是第k个Transformer层的输出。
3、对热力图的优化。
受CLIP-ES[32]的启发,我们不重新训练另外的模型来精炼Pint,而是从 中提取注意力权重Aself,并使用最后一层Adapter的输出(吸取了所有的图像信息)来调整注意力权重。
中提取注意力权重Aself,并使用最后一层Adapter的输出(吸取了所有的图像信息)来调整注意力权重。
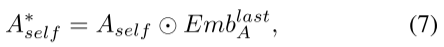
问:为什么要从中提取?
答:我们的Pinit是通过输入和名词然后对齐得到的,所以要提取它里面的注意力权重。
然后:
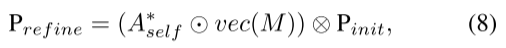
其中,vec(M)是通过提取Pinit的高亮区域而产生的掩码M的矢量化。这里的第一个操作符还是Element-wise逐元素运算,第二个是矩阵乘法。
然后我们就得到了优化后的热力图,提取其中的高亮区域,得到最终的高质量掩码。
4、最后SAM Decoder的输入(共三个输入)。
(1)上一步生成的高质量掩码,经过SAM Prompt Encoder,生成密集嵌入。这是第一个输入。
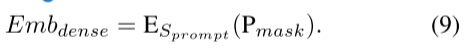
(2)将SAM图像编码器中最后一个Transformer层产生的图像嵌入与ARM模块中最后一个Adapter层产生的图像嵌入相结合,得到最终的图像嵌入。这是第二个输入。
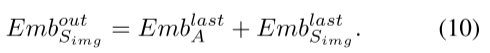
(3)我们把名词输入进Mamba得到对应的文本嵌入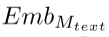
,再将文本嵌入与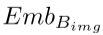 相结合,得到辅助稀疏嵌入。这是第三个输入。
相结合,得到辅助稀疏嵌入。这是第三个输入。
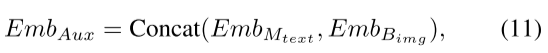
这三个一起输入进SAM Decoder,得到最终的分割结果。
总结一下整个过程:
1、图像输入进BLIP图像编码器得到图像嵌入,
2、这个图像嵌入先经过文本解码器得到描述,
3、在描述中提取第一个名词,输入进BLIP Image-grounded Text Encoder得到文本嵌入,
4、在BLIP Image-grounded Text Encoder中进行图像嵌入和文本嵌入的对齐,得到Pinit。
5、但是Pinit是低质量的,所以我们引入了ARM模块来优化Pinit。
(1)ARM一方面用来优化SAM Image Encoder,有效地将Adapter提取的图像特征集成到SAM中(第k个Adapter的输出与第k个Transformer的输出相结合作为第k+1个Transformer的输入),
(2)ARM一方面通过调整图像嵌入里的注意力权重(最后一个Adapter的输出与初始权重Elemrnt-wise)来优化Pinit。
6、得到高质量掩码后,最后输入进SAM Decoder就好了。
7、另外还有一个辅助稀疏嵌入,将名词输入进Mamba得到文本嵌入,然后与图像嵌入级联Concat。
实验:
常用的COD数据集(4个):CHAMELEON、CAMO、COD10K、NC4K
评估指标(4个,前三个值越高效果越好,第四个值越小效果越好):

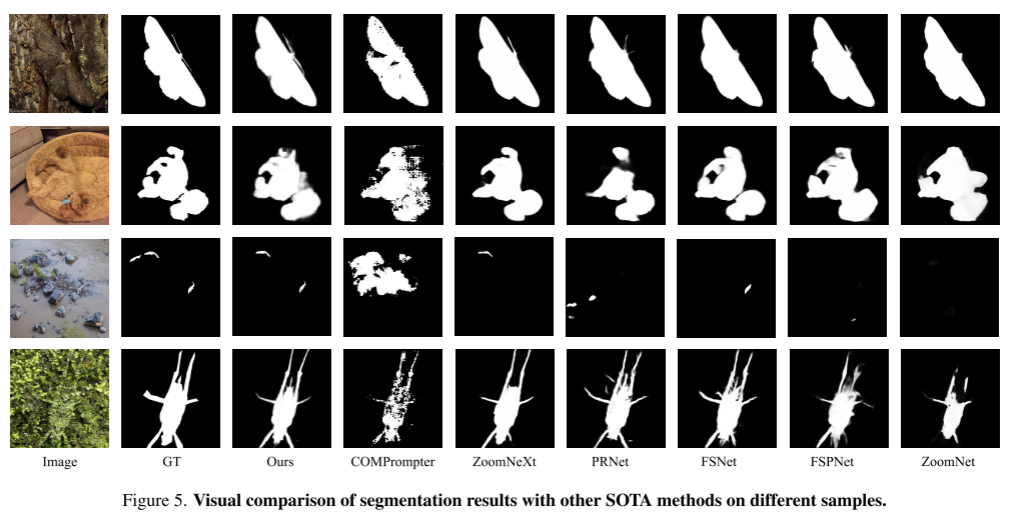
与其他SOTA的比较(table 1、figure 5):

:需求分析——代码质量的“源头防线”)

)


)

一类支配点对解决区间查询问题)



)
![P10259 [COCI 2023/2024 #5] Piratski kod](http://pic.xiahunao.cn/P10259 [COCI 2023/2024 #5] Piratski kod)
的生命周期包装特性 实现前后置处理)


)


