文本分类 是机器学习中最基础的任务之一,拥有悠久的研究历史和深远的实用价值。更重要的是,它是许多实际项目中不可或缺的组成部分,从搜索引擎到生物医学研究都离不开它。文本分类方法被广泛应用于科学论文分类、用户工单分类、社交媒体情感分析、金融研究中的公司分类等领域。让我们再拓展一下这个任务的范畴到序列分类,这个领域的应用场景和影响力会更加广泛,从 DNA 序列分类到 RAG 管道,后者是当前聊天机器人系统中保证高质量和时效性输出的最常用方式。
近年来,自回归语言模型 的进步为许多 零样本分类 任务(包括文本分类)开辟了新天地。虽然这些模型展示出了惊人的多功能性,但它们往往难以严格遵循指令,并且在训练和推理方面都可能存在计算效率问题。
交叉编码器 作为 自然语言推理(NLI)模型是另一种常用于零样本分类和 检索增强生成(RAG)管道的方法。该方法通过将待分类的序列作为 NLI 的前提,并为每个候选标签构造一个假设来进行分类。总的来说,这种方法在处理大量类别时会遇到效率挑战,因为它采用的是成对处理方式。此外,它在理解跨标签信息方面的能力有限,这可能会影响预测质量,尤其是在复杂的场景中。
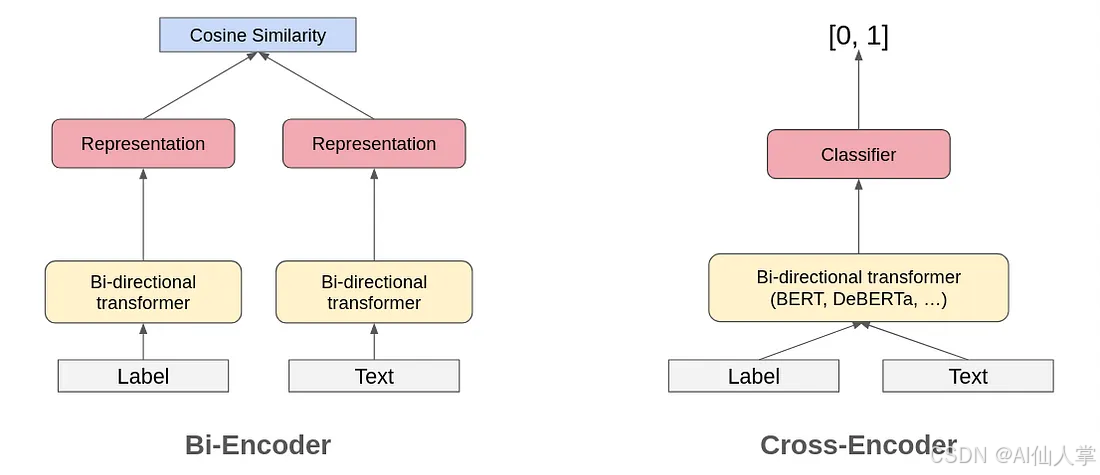
双编码器与交叉编码器架构对比
Word2Vec 的嵌入式方法被认定为文本分类的一种潜在方法,特别是在零样本设置下。使用句子编码器能够更好地理解句子和文本的语义,这使得使用句子嵌入进行文本分类的想法变得显而易见。Sentence Transformers 的出现进一步提高了嵌入的质量,使得即使不进行微调也能使用它们进行分类任务成为可能。SetFit —— 一项基于 Sentence Transformers 的工作,使得即使在每个标签只有少量示例的情况下也能获得良好的性能。尽管基于嵌入的方法效率高且在许多语义任务中表现良好,但在涉及逻辑和语义约束的复杂场景中常常表现不佳。
本文介绍的一种新的文本分类方法,该方法基于 GLiNER 架构,特别适用于 序列分类 任务。旨在在复杂模型的准确性与嵌入式方法的效率之间取得平衡,同时保持良好的 零样本 和 少样本 能力。
GLiClass 架构
我们的架构引入了一种新颖的 序列分类 方法,该方法能够在保持计算效率的同时实现标签与输入文本之间的丰富交互。该实现由几个关键阶段组成,这些阶段协同工作以实现卓越的分类性能。
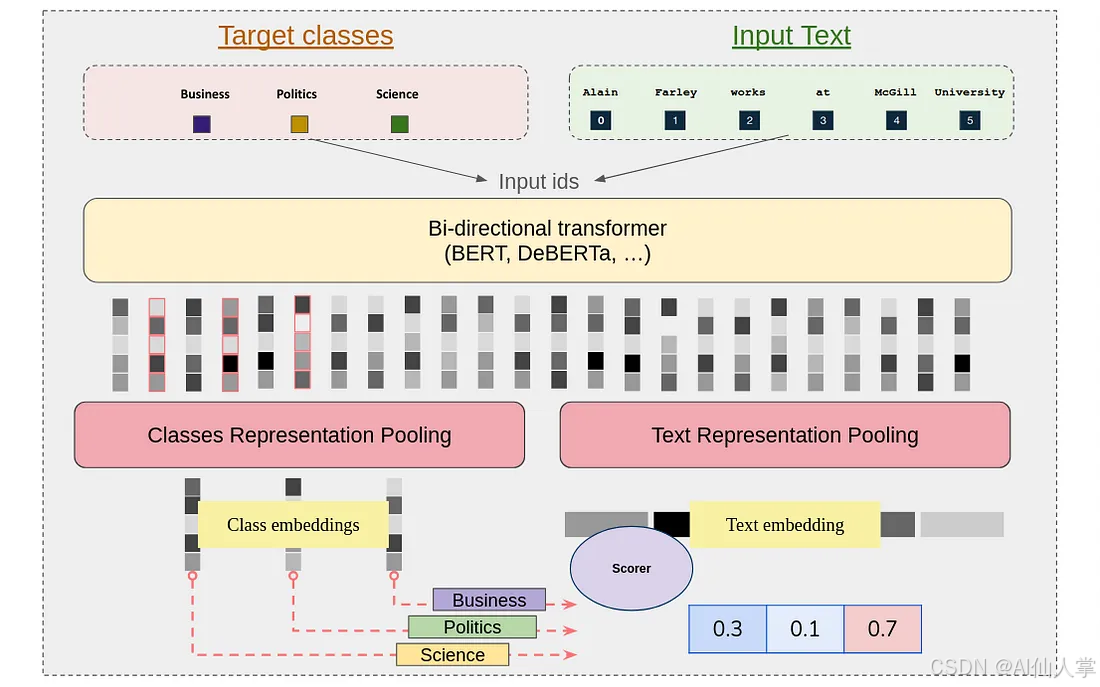
GLiClass 架构
输入处理与标签整合
该过程始于标签整合机制。我们在每个类别标签前添加一个特殊标记 <
上下文表示学习
在分词之后,合并后的输入 ID 会通过双向 Transformer 架构(如 BERT 或 DeBERTa)进行处理。这个阶段至关重要,因为它能够实现三种不同的上下文理解:
- 标签间交互:标签之间可以共享信息,使模型能够理解标签关系和层次结构
- 文本-标签交互:输入文本可以直接影响标签表示
- 标签-文本交互:标签信息可以指导文本的解读
这种多向信息流动代表了对传统交叉编码器架构的重大优势,后者通常仅限于文本-标签对交互,而忽略了宝贵的标签间关系。
表示池化
在获得上下文化表示后,我们采用不同的池化机制来分别处理标签和文本,以提取变压器输出中的基本信息。我们的实现支持多种池化策略:
- 首个 token 池化:利用首个 token 的表示
- 平均池化:对所有 token 进行平均
- 注意力加权池化:应用学习到的注意力权重
- 自定义池化策略:针对特定分类需求进行调整
池化策略的选择可以根据分类任务的具体要求和输入数据的性质进行优化。
评分机制
最后阶段涉及计算合并表示之间的兼容性分数。我们通过灵活的评分框架实现这一点,该框架可以适应各种方法:
- 简单点积评分:对于许多应用来说既高效又有效
- 神经网络评分:用于具有挑战性的场景的更复杂评分函数
- 任务特定评分模块:针对特定分类需求进行定制
这种模块化评分方法使架构能够适应不同的分类场景,同时保持计算效率。
如何使用模型
Hugging Face 上开源了这个模型。
要使用它们,首先安装 gliclass 包:
pip install gliclass
然后你需要初始化一个模型和一个管道:
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizermodel = GLiClassModel.from_pretrained("knowledgator/gliclass-modern-base-v2.0-init")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-modern-base-v2.0-init")pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
这是如何执行推理:
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0]
for result in results:print(result["label"], "=>", result["score"])
如何微调
首先,你需要准备如下格式的训练数据:
[{"text": "Some text here!","all_labels": ["sport", "science", "business", …],"true_labels": ["other"]}, …
]
下面是你需要的导入需求:
import os
os.environ["TOKENIZERS_PARALLELISM"] = "true"from datasets import load_dataset, Dataset, DatasetDict
from sklearn.metrics import classification_report, f1_score, precision_recall_fscore_support, accuracy_score
import numpy as np
import random
from transformers import AutoTokenizer
import torch
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from gliclass.data_processing import GLiClassDataset, DataCollatorWithPadding
from gliclass.training import TrainingArguments, Trainer
然后,我们初始化模型和分词器:
device = torch.device('cuda:0') if torch.cuda.is_available else torch.device('cpu')
model_name = 'knowledgator/gliclass-base-v1.0'
model = GLiClassModel.from_pretrained(model_name).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
然后,我们指定训练参数:
max_length = 1024
problem_type = "multi_label_classification"
architecture_type = model.config.architecture_type
prompt_first = model.config.prompt_firsttraining_args = TrainingArguments(output_dir='models/test',learning_rate=1e-5,weight_decay=0.01,others_lr=1e-5,others_weight_decay=0.01,lr_scheduler_type='linear',warmup_ratio=0.0,per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=8,evaluation_strategy="epoch",save_steps = 1000,save_total_limit=10,dataloader_num_workers=8,logging_steps=10,use_cpu = False,report_to="none",fp16=False,
)
当你以正确的格式准备好了数据集后,我们需要初始化 GLiClass 数据集和数据收集器:
train_dataset = GLiClassDataset(train_data, tokenizer, max_length, problem_type, architecture_type, prompt_first)
test_dataset = GLiClassDataset(train_data[:int(len(train_data)*0.1)], tokenizer, max_length, problem_type, architecture_type, prompt_first)data_collator = DataCollatorWithPadding(device=device)
当一切就绪后,我们可以开始训练:
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,tokenizer=tokenizer,data_collator=data_collator,
)
trainer.train()
在仓库中查看更多示例:https://github.com/Knowledgator/GLiClass/blob/main/finetuning.ipynb
关键应用场景
GLiClass 在广泛的自然语言处理任务中展示了卓越的多功能性,使其在研究和实际应用中都具有极高的价值。
多类分类
该架构高效地处理大规模分类任务,单次处理最多可处理 100 个不同类别。这一能力对于文档分类、产品分类和内容标签系统等需要多个详细类别的应用特别有价值。
主题分类
GLiClass 在识别和分类文本主题方面表现出色,特别适用于:
- 学术论文分类
- 新闻文章分类
- 内容推荐系统
- 研究文档组织
情感分析
该架构有效捕捉细微的情感和观点内容,支持:
- 社交媒体情感跟踪
- 客户反馈分析
- 产品评论分类
- 品牌感知监控
事件分类
GLiClass 在识别和分类文本中的事件方面表现出强大的能力,支持:
- 新闻事件分类
- 社交媒体事件检测
- 历史事件分类
- 时间线分析和组织
基于提示的约束分类
该系统提供灵活的基于提示的分类与自定义约束,支持:
- 引导分类任务
- 上下文感知分类
- 自定义分类规则
- 动态类别适配
自然语言推理
GLiClass 支持关于文本关系的复杂推理,促进:
- 文本蕴含检测
- 矛盾识别
- 语义相似性评估
- 逻辑关系分析
检索增强生成 (RAG)
良好的架构泛化性以及对自然语言推理任务的支持使其成为 RAG 管道中重排序的理想选择。此外,GLiClass 的效率使其更具竞争力,尤其是与交叉编码器相比。
这一全面的应用范围使 GLiClass 成为现代自然语言处理挑战的多功能工具,在各种分类任务中提供灵活性和精确性。
基准测试结果
我们发布了一个基于 ModernBERT 的新 GLiClass 模型,与旧模型如 DeBERTa 相比,它提供了更长的上下文长度支持(高达 8k 个 token)和更快的推理速度。我们在多个 文本分类数据集 上对我们的 GLiClass 模型进行了基准测试。
以下是 F1 分数在几个 文本分类数据集 上的表现。所有测试模型都没有在这些数据集上进行微调,并且在 零样本设置 下进行了测试。
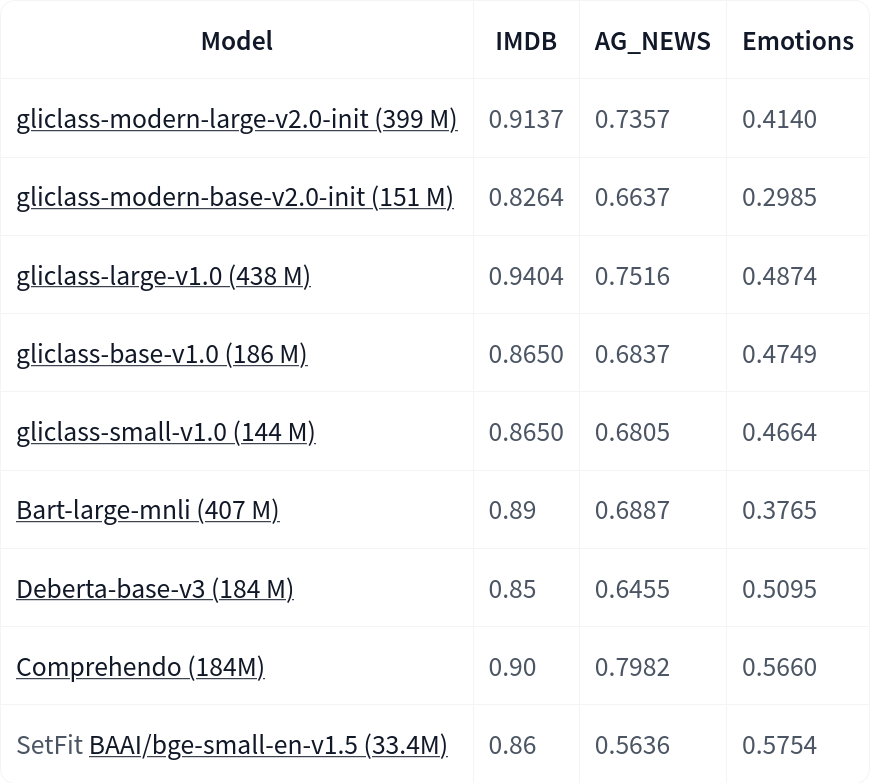
以下是对 ModernBERT GLiClass 与其他 GLiClass 模型的更全面比较:
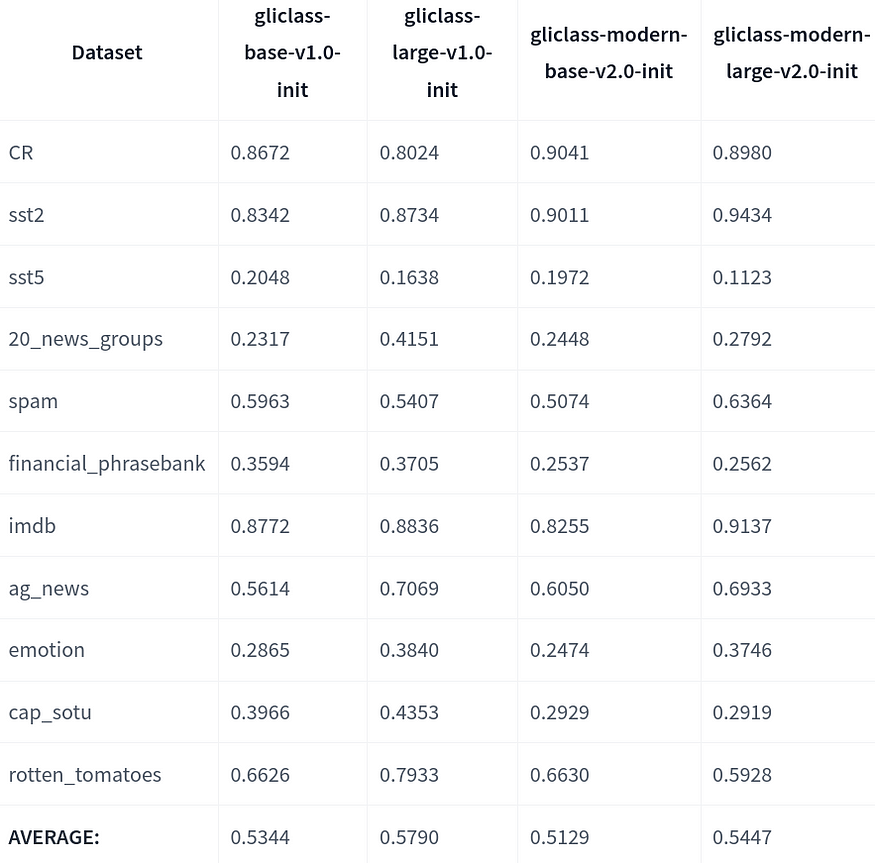
我们研究了如果我们对少量 每个标签的示例 进行 微调,性能会如何增长。此外,我们测试了一种简单的方法,当我们不提供真实文本而是提供给定文本主题的通用短描述时,我们称之为 弱监督。令人惊讶的是,对于像“emotion”这样的某些数据集,它显著提高了性能。
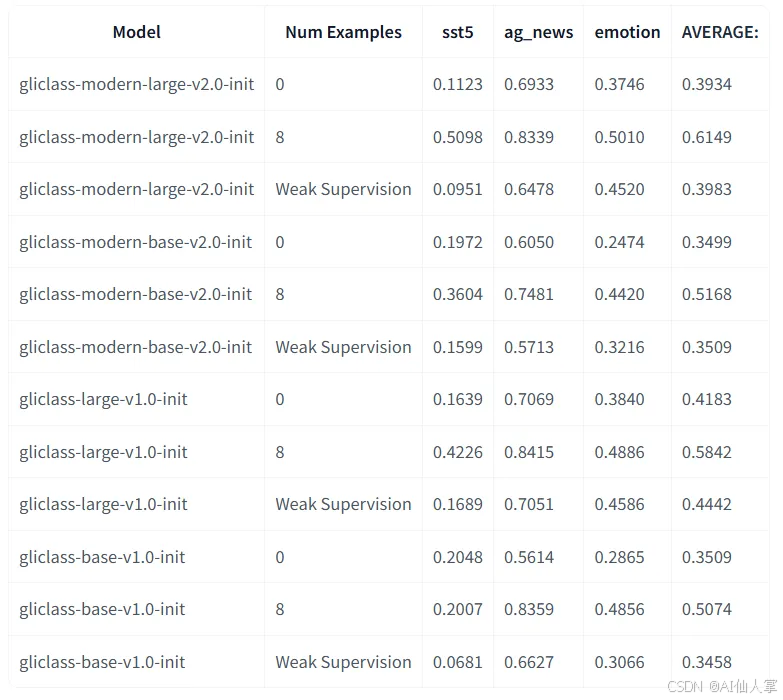
结论
GLiClass 代表了文本分类领域的重大进步,提供了一种强大而高效的解决方案,弥合了复杂 Transformer 模型的准确性与嵌入式方法的简单性之间的差距。通过利用一种新颖的架构,该架构促进了输入文本和标签之间的丰富交互,GLiClass 在零样本和少样本分类任务中实现了卓越的性能,同时保持了计算效率,即使面对大型标签集也是如此。它能够捕捉跨标签依赖关系,适应各种分类场景,并与现有的 NLP 管道无缝集成,使其成为从情感分析和主题分类到检索增强生成和自然语言推理等各种应用的多功能工具。
使用生成式语言模型进行零样本分类:https://github.com/Knowledgator/unlimited_classifier




: 数据集-语料库(Corpus))









)




