目录
1.题目
2.分析
暴力解法
方法1:排序(超时)
方法2:哈希表(险过)
★判断两个哈希表是否相同算法(通用方法,必须掌握)
能相等的前提:两个哈希表的大小相等
哈希表有迭代器,可以使用范围for从头到尾遍历
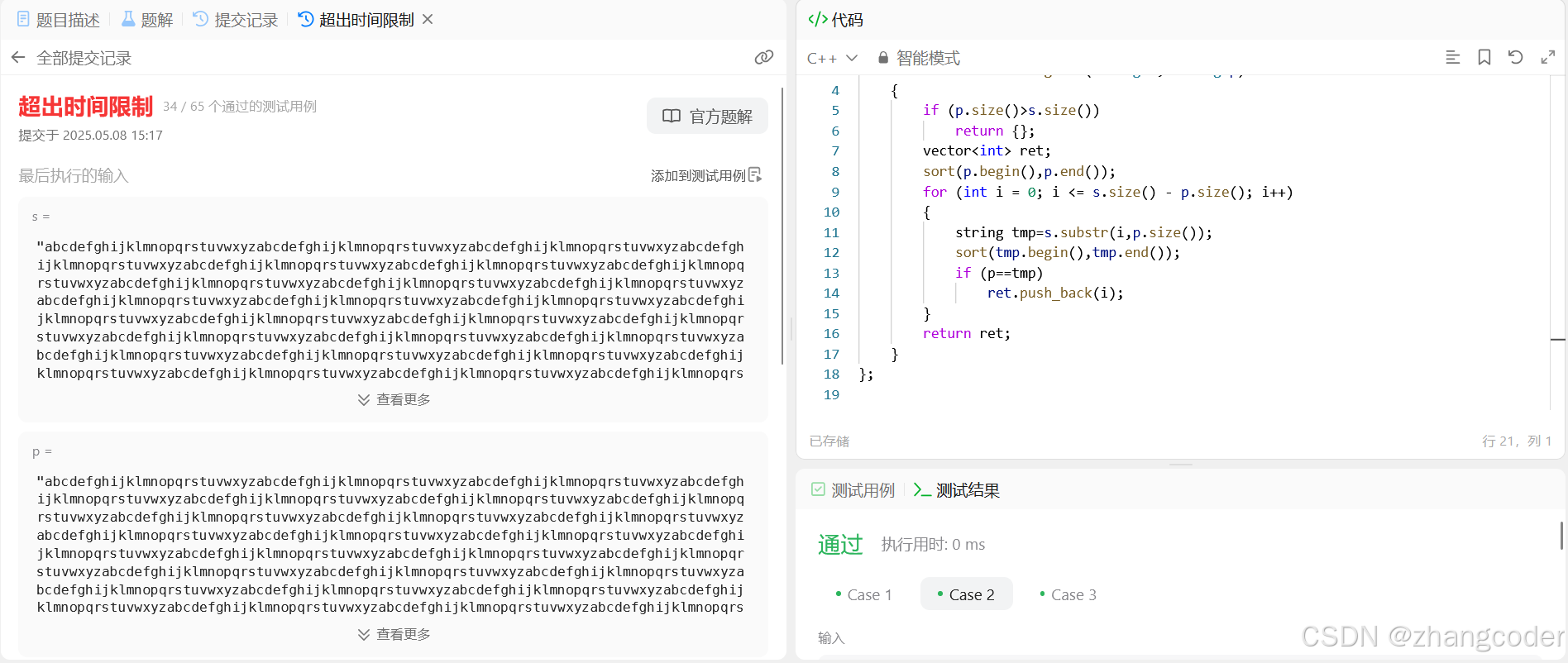
提交结果
优化方法:定长滑动窗口
提交结果
使用哈希数组更快
提交结果
★★★更优化的方法:不定长滑动窗口(比定长的要快!)
提交结果
1.题目
https://leetcode.cn/problems/find-all-anagrams-in-a-string/
给定两个字符串
s和p,找到s中所有p的的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
示例 1:
输入: s = "cbaebabacd", p = "abc" 输出: [0,6] 解释: 起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。 起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。示例 2:
输入: s = "abab", p = "ab" 输出: [0,1,2] 解释: 起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。 起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。 起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。提示:
1 <= s.length, p.length <= 3 * 104s和p仅包含小写字母
2.分析
暴力解法
大致思路:使用i遍历字符串s,从i位置截取和p相同长度的子串(前提p.size()<=s.size(),这个要在一开始就要判断),比较这个子串和p是否是异位词
方法1:排序(超时)
可以先对两个串排序,再调用operator==判断是否相等
class Solution {
public:vector<int> findAnagrams(string s, string p){if (p.size()>s.size())return {};vector<int> ret;sort(p.begin(),p.end());for (int i = 0; i <= s.size() - p.size(); i++){string tmp=s.substr(i,p.size());sort(tmp.begin(),tmp.end());if (p==tmp)ret.push_back(i);}return ret;}
};调用sort函数的时间复杂度是,过高容易超时:
方法2:哈希表(险过)
统计s的子串和p串的词频,记录到哈希表中,再判断两个哈希表是否相同,这个时间复杂度比方法1低一点
★判断两个哈希表是否相同算法(通用方法,必须掌握)
虽然可以用哈希数组hash['z'+1]投机取巧(这个解法在本文的最后),但是其他题可能用不了哈希数组,因此掌握通用的方法是很有必要的
算法:
能相等的前提:两个哈希表的大小相等
if (mp1.size() != mp2.size()) return false;哈希表有迭代器,可以使用范围for从头到尾遍历
STL的map底层实现是红黑树,对于for (const auto& pair : mp1),pair拿到的是mp1的红黑树中一个节点,到mp2中查有没有相同的节点即可,使用find函数
find函数的查找逻辑:
cplusplus网上是这样说的:https://legacy.cplusplus.com/reference/map/map/find/
find取得(get)指向元素的迭代器(iterator to element)
在容器中查找一个键值与k等价的元素,如果找到,则返回指向该元素的迭代器;否则返回指向map::end的迭代器

比较时会出现两种情况
1.找到一个键值与k等价的元素,此时还不能断定两个节点一定相等,需要比较第二个关键字(pair.second)是否相等,如果不等(it->second != pair.second),返回false
2.没找到一个键值与k等价的元素(it == mp2.end()),返回false
class Solution {
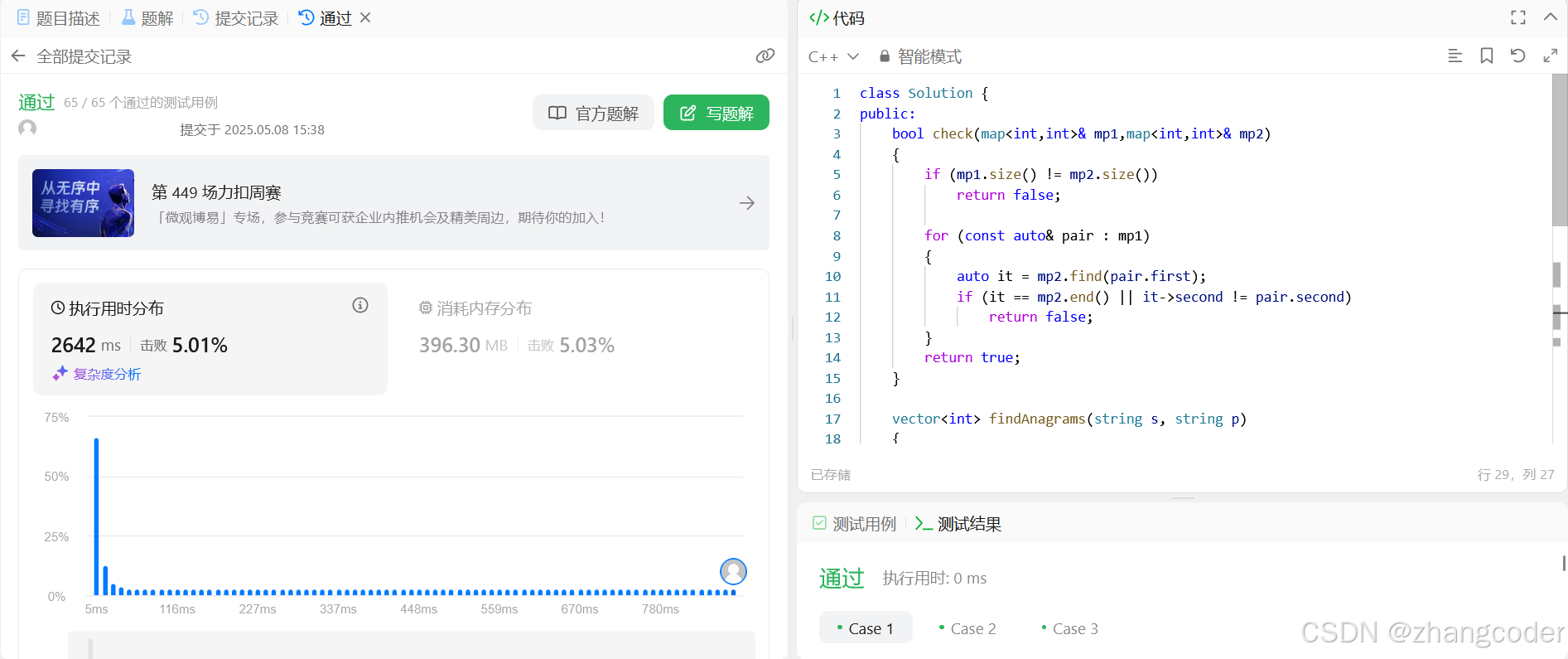
public:bool check(map<int,int>& mp1,map<int,int>& mp2){if (mp1.size() != mp2.size()) return false;for (const auto& pair : mp1) {auto it = mp2.find(pair.first);if (it == mp2.end() || it->second != pair.second) return false;}return true;}vector<int> findAnagrams(string s, string p){if (p.size()>s.size())return {};vector<int> ret;map<int,int> mp1;for (int i=0;i<p.size();i++)mp1[p[i]]++;for (int i = 0; i <= s.size() - p.size(); i++){map<int,int> mp2;string tmp=s.substr(i,p.size());for (int i=0;i<tmp.size();i++)mp2[tmp[i]]++;if (check(mp1,mp2))ret.push_back(i);}return ret;}
};提交结果
优化方法:定长滑动窗口
以s = "cbaebabacd", p = "abc"为例分析:
异位词子串首先要长度和p从串相等,对s从头到尾遍历即可,








在移动窗口时,注意左侧元素离开哈希表,右侧元素加入哈希表,当mp2[s[left]]==0时,必须删除这个节点,否则影响哈希表的结构
class Solution {
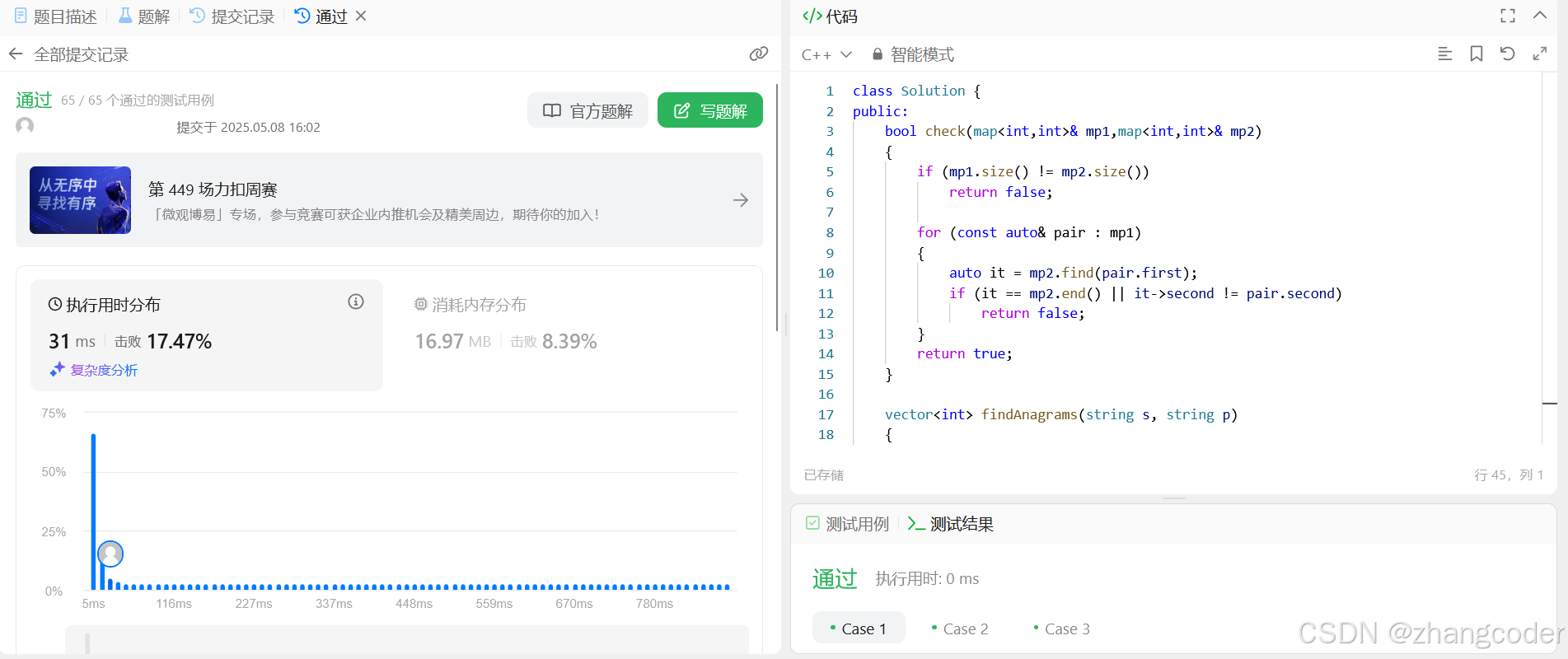
public:bool check(map<int,int>& mp1,map<int,int>& mp2){if (mp1.size() != mp2.size()) return false;for (const auto& pair : mp1) {auto it = mp2.find(pair.first);if (it == mp2.end() || it->second != pair.second) return false;}return true;}vector<int> findAnagrams(string s, string p){if (p.size()>s.size())return {};vector<int> ret;map<int,int> mp1,mp2;for (int i=0;i<p.size();i++){mp1[p[i]]++;mp2[s[i]]++;}for (int left=0,right=p.size()-1; right<s.size();left++,right++){if (check(mp1,mp2)){ret.push_back(left);}mp2[s[left]]--;mp2[s[right+1]]++;if (mp2[s[left]]==0)mp2.erase(s[left]);}return ret;}
};注:right+1最大为s.size(),此时mp2[s[right+1]]++;访问到字符串的'\0'没有越界,不影响结果
提交结果
使用哈希数组更快
将map<int,int>改成数组,其他地方稍作修改即可
class Solution {
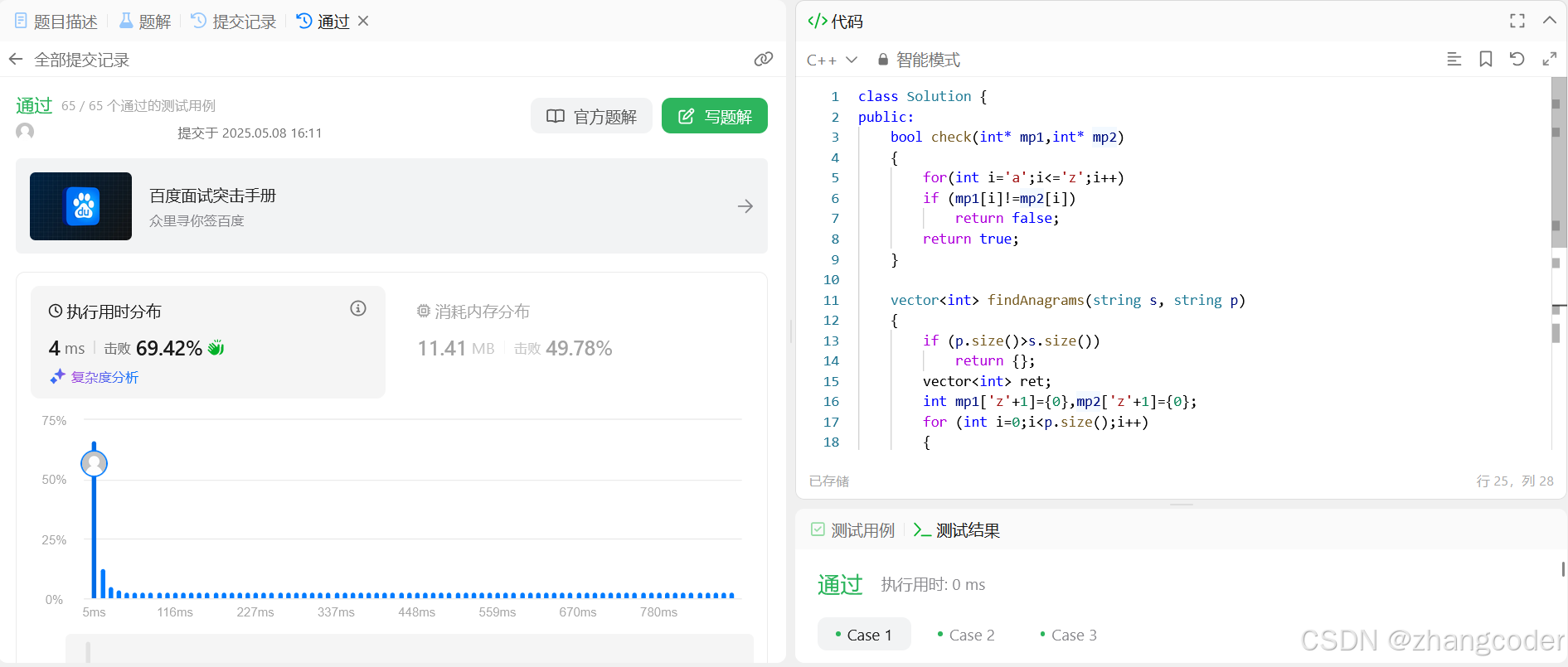
public:bool check(int* mp1,int* mp2){for(int i='a';i<='z';i++)if (mp1[i]!=mp2[i])return false;return true; }vector<int> findAnagrams(string s, string p){if (p.size()>s.size())return {};vector<int> ret;int mp1['z'+1]={0},mp2['z'+1]={0};for (int i=0;i<p.size();i++){mp1[p[i]]++;mp2[s[i]]++;}for (int left=0,right=p.size()-1; right<s.size();left++,right++){if (check(mp1,mp2))ret.push_back(left);mp2[s[left]]--;mp2[s[right+1]]++;}return ret;}
};
提交结果
★★★更优化的方法:不定长滑动窗口(比定长的要快!)
hash_s是字符串s的滑动窗口的哈希数组,hash_p是字符串p的的哈希数组
上面的优化的方法还可以继续优化,引入有效字符的个数:
先让hash_s[s[right]]++,之后判断:
1.当hash_s[s[right]] <= hash_p[s[right]]时计入有效字符的个数count,即count++
2.一旦窗口长度大于len时,及时调整让left++,当hash_s[s[left]] <= hash_p[s[left]]时减小有效字符的个数count,即count--
★更新结果的条件:窗口长度相等,且有效字符的个数要相等,这样就不用像上面方法那样遍历mp1和mp2数组的每个元素
个数从0变成1,有效字符的个数+1,因此count++
个数从1变成0,有效字符的个数-1,因此count--
符合有效字符的个数==p串的长度,将left尾插到返回数组ret
class Solution {
public:vector<int> findAnagrams(string s, string p) {if (p.size() > s.size())return {};vector<int> ret;int len = p.size();int count = 0;int hash_s['z'+1] = {0}, hash_p['z'+1] = {0};for (int i = 0; i < p.size(); i++)hash_p[p[i]]++;for (int left = 0, right = 0; right < s.size(); right++) {hash_s[s[right]]++;if (hash_s[s[right]] <= hash_p[s[right]])count++;if (right - left + 1 > len) {if (hash_s[s[left]] <= hash_p[s[left]])count--;hash_s[s[left]]--;left++;}if (count == len)ret.push_back(left);}return ret;}
};提交结果












)



)
![SierraNet协议分析使用指导[RDMA]| 如何设置 NVMe QP 端口以进行正确解码](http://pic.xiahunao.cn/SierraNet协议分析使用指导[RDMA]| 如何设置 NVMe QP 端口以进行正确解码)

——09.softmax回归+图像分类数据集+从零实现+简洁实现)