SAM的局限性:
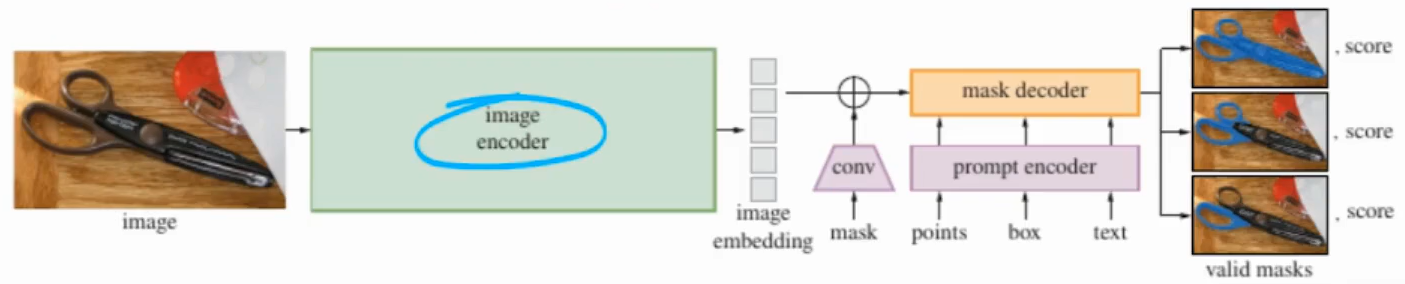
1、依赖用户手动提示,用户在输入一张图片后,还需要给予手动提示,模型才能分割。**
2、当用户未提供输入掩码时,则掩码嵌入将被随机初始化的嵌入替换,导致性能下降。
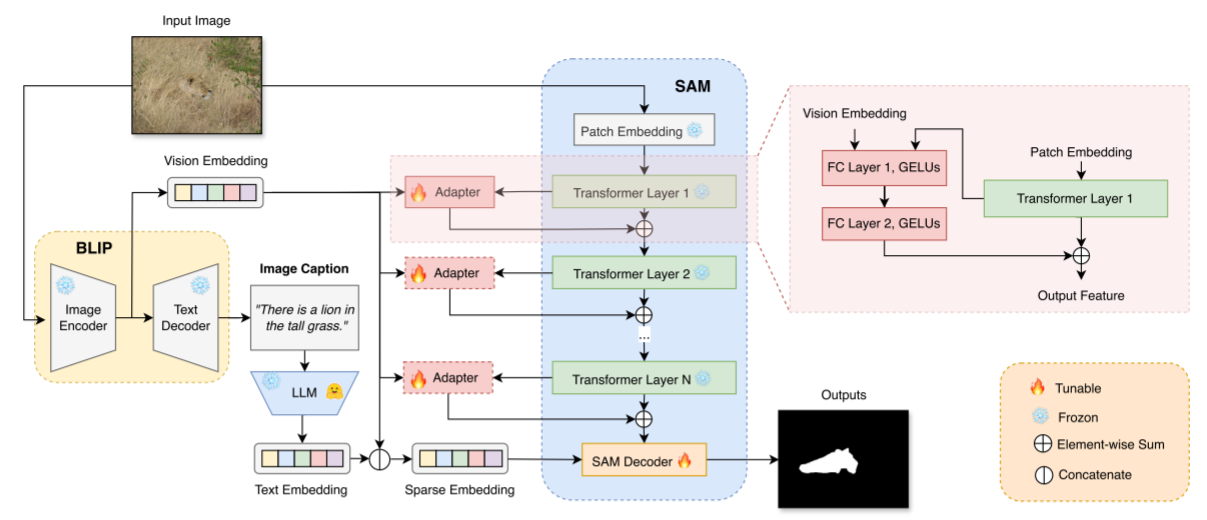
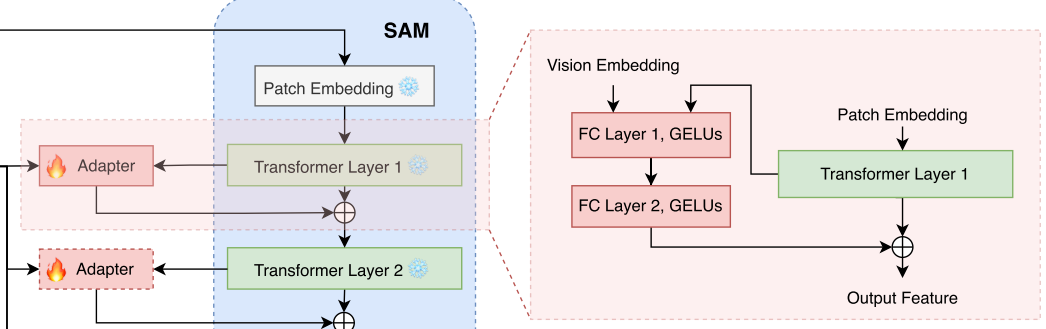
MM-SAM的结构:
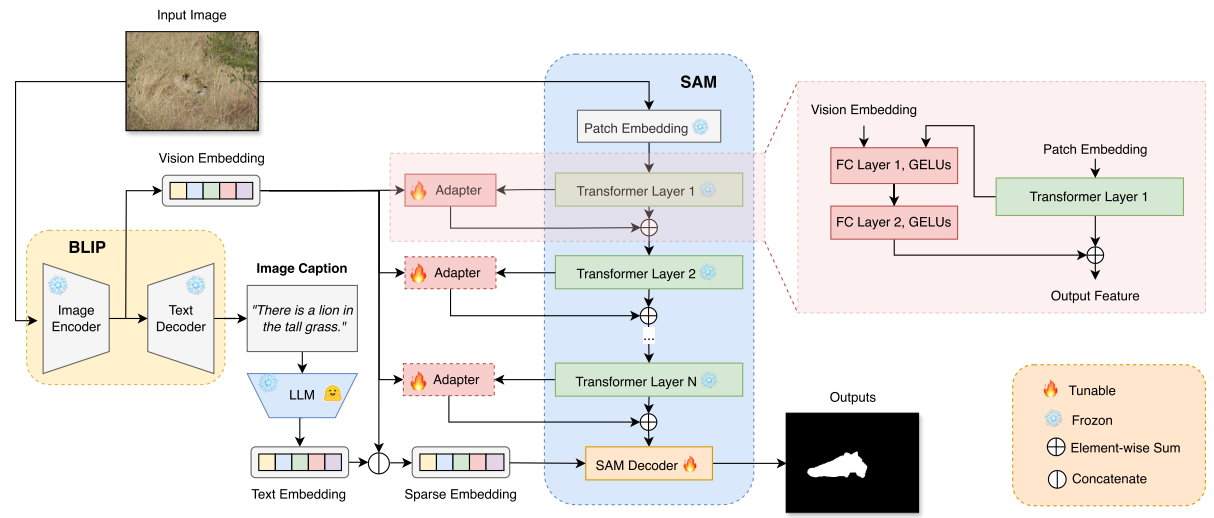
(1)将BLIP用于图像caption任务,以自动为每个输入图像生成描述;
(2)使用LLM或文本编码器(Mamba)从生成的描述中提取文本嵌入;
(3)图像通过BLIP的图像编码器(VIT)得到视觉嵌入;
(4)上面生成的文本嵌入和视觉嵌入相结合,作为SAM解码器的视觉语言提示;
(5)在SAM图像编码器中,来自每个transformer块的视觉嵌入与来自BLIP的视觉嵌入相结合,用于训练用于微调SAM图像编码器的Adapter。
下面分别讲一下每一块:
(1)生成caption
BLIP作为caption生成器,为图片生成一段文字描述(不提供模板指令)。
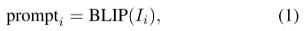
(2)得到文本嵌入
使用LLM-Mamba从上面生成的描述中提取文本嵌入。
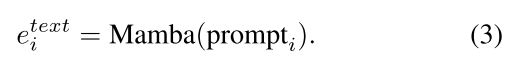
(3)生成视觉嵌入
BLIP的图像编码器为输入图像生成对应的视觉嵌入。
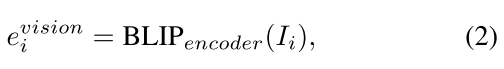
(4)将上面生成的文本嵌入和视觉嵌入连接起来,作为SAM Decorder的输入token。

(5)多级特征Adapter
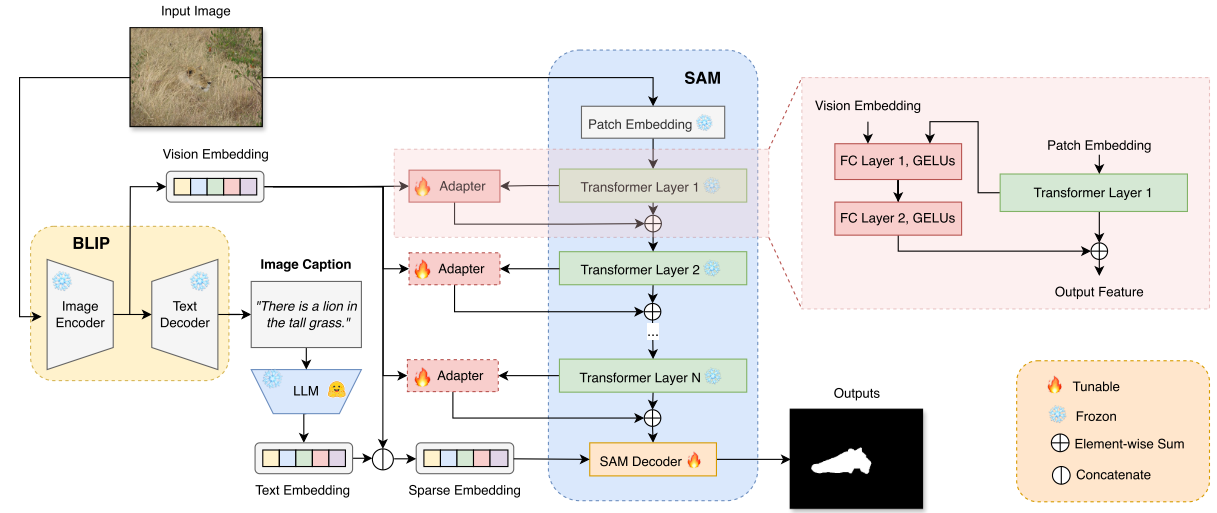
transformer层的输出与视觉嵌入相结合作为Adapter的输入:
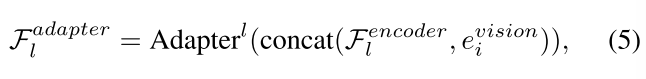
Adapter的输出与transformer层的输出相结合作为下一层transformer块的输入(为了减少参数量,所有Adapter共享相同的权重系数):
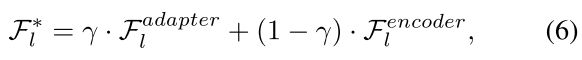
最后一部分:
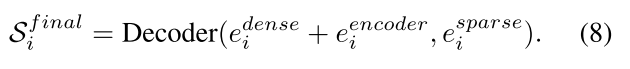
图像嵌入:来自原始SAM的图像编码器。
密集嵌入:图像嵌入经过全连接层调整维度、GELU激活函数增强非线性得到。
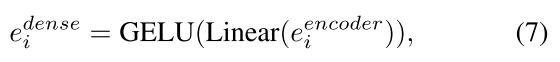
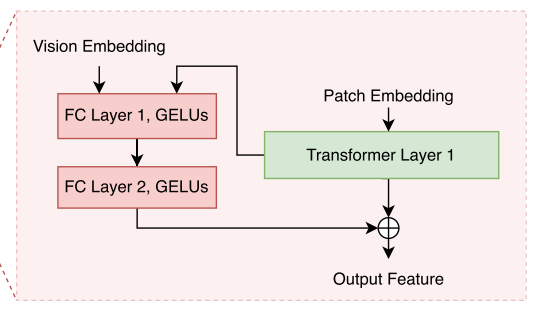
稀疏嵌入:由视觉嵌入(BLIP的图像编码器得到)和文本嵌入相结合得到。
图像嵌入包含全局图像特征,密集嵌入由图像嵌入得到,是对图像嵌入中“目标相关特征”的强化(基于全局特征生成的纹理差异)。二者相加 = 全局上下文 + 目标细节。
稀疏嵌入负责语义层面的目标指引,告诉解码器“我们要找的东西是什么”。
三者一起输入进SAM Decoder,用于预测最终的分割掩码。
也就是说,现在的视觉嵌入 + 文本嵌入代替了原来的稀疏嵌入(现在也叫稀疏嵌入)。
也就是说,现在的图像嵌入 + 密集嵌入代替了原来的密集嵌入(虚线方框内)。
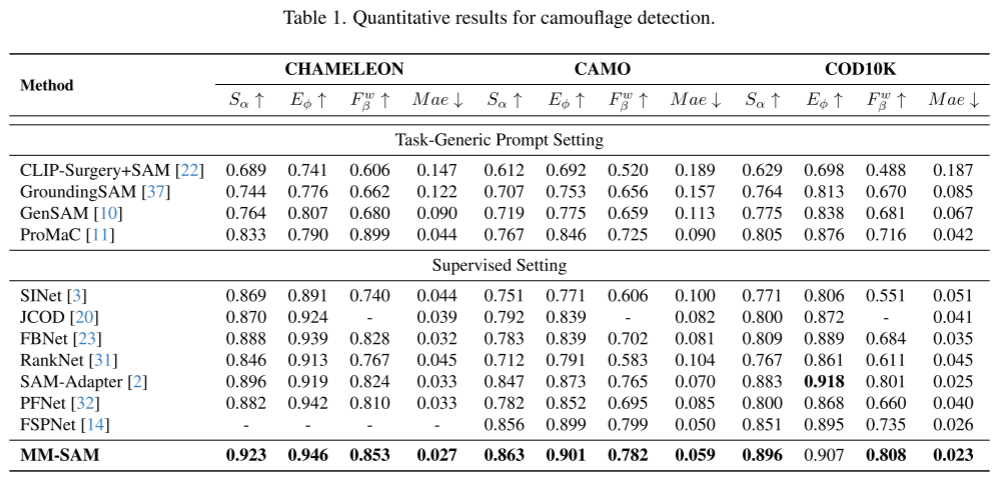
实验:
数据集(3个):COD10K、CHAMELEON、CAMO
评估方式(4个):

与当前最优的伪装检测方法比较(9个)(table 1):SINet、RankNet、JCOD、PFNet、FBNet、SAM、SCOD、SAM-Adapter、GenSAM

总结一下:
原来的SAM是稀疏嵌入 + 密集嵌入,但两个嵌入都有问题:稀疏嵌入依赖用户手动提示(方框、点击等),密集嵌入缺失时会被随机初始化。
改进后,稀疏嵌入 = 文本嵌入(BLIP文本解码器 + Mamba) + 视觉嵌入(BLIP Encoder),不再依赖用户手动提示;密集嵌入 = 来自原始SAM的图像嵌入(全连接、GELU),然后将密集嵌入 + 图像嵌入实现全局 + 细节。最后密集嵌入 + 图像嵌入与稀疏嵌入一起作为SAM Decoder的输入,结束。






-安装JDK-mac)












