1、环境/问题介绍
- 概述:多臂老虎机问题是指:智能体在有限的试验回合 𝑇 内,从 𝐾 台具有未知奖赏分布的“老虎机”中反复选择一个臂(即拉杆),每次拉杆后获得随机奖励,目标是在累积奖励最大化的同时权衡探索(尝试不同臂以获取更多信息)和利用(选择当前估计最优臂)
你站在赌场前,有三台老虎机(臂 A 、 B 、 C A、B、C A、B、C),它们的中奖概率分别为 ( p A , p B , p C ) ( p_A, p_B, p_C ) (pA,pB,pC),但你并不知道具体数值。你有 100 次拉杆的机会,每次只能选择一台机器并拉动其拉杆,若中奖则获得 1 枚筹码,否则 0。你的目标是在这 100 次尝试中,尽可能多地赢得筹码。
这个例子直观地展示了多臂老虎机问题的核心要素:
- 未知性:每台机器的中奖概率对你未知。
- 试错学习:通过拉杆并观察结果,逐步估计每台机器的回报。
- 探索–利用权衡:需要在尝试新机器(探索)与选择当前估计最优机器(利用)之间取得平衡,以最大化总收益。
2、主要算法
2.1. ε-贪心算法(Epsilon‑Greedy)
1. 算法原理
以概率 ε 随机探索,概率 1 − ε 选择当前估计最高的臂,实现简单的探索–利用平衡。
-
这里的 ϵ (epsilon) 是一个介于 0 和 1 之间的小参数(例如 0.1, 0.05)。它控制着探索的程度:
-
ϵ=0:纯粹的贪婪算法 (Greedy),只利用,不探索。如果初始估计错误,可能永远无法找到最优臂。
-
ϵ=1:纯粹的随机探索,完全不利用过去的经验。
-
0<ϵ<1:在大部分时间利用已知最优选择,但保留一小部分机会去探索其他可能更好的选择。
ϵ-Greedy 保证了即使某个臂的初始估计很差,仍然有一定概率被选中,从而有机会修正其估计值。
-
-
变种: 有时会使用随时间衰减的 ϵ 值(如 ϵ = 1 / t ϵ =1/t ϵ=1/t 或 ϵ = c / log t ϵ =c / \log t ϵ=c/logt),使得算法在早期更多地探索,随着信息积累越来越充分,逐渐转向利用。
2. ε-Greedy 算法实现步骤
假设有 K K K 个臂,总共进行 T T T 次试验。
-
初始化 (Initialization):
- 设置探索概率 ϵ \epsilon ϵ(一个小的正数)。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化奖励估计值 Q 0 ( a ) = 0 Q_0(a) = 0 Q0(a)=0。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化被选择的次数 N 0 ( a ) = 0 N_0(a) = 0 N0(a)=0。
-
循环执行 (Loop): 对于时间步 t = 1 , 2 , . . . , T t = 1, 2, ..., T t=1,2,...,T:
- 选择动作 (Select Action):
- 生成一个 [0, 1) 范围内的随机数 p p p。
- 如果 p < ϵ p < \epsilon p<ϵ (探索):
从所有 K K K 个臂中等概率随机选择一个臂 A t A_t At。 - 如果 p ≥ ϵ p \ge \epsilon p≥ϵ (利用):
选择当前估计奖励最高的臂 A t = arg max a Q t − 1 ( a ) A_t = \arg\max_{a} Q_{t-1}(a) At=argmaxaQt−1(a)。- 注意: 如果有多个臂具有相同的最高估计值,可以随机选择其中一个,或按编号选择第一个。
- 执行动作并观察奖励 (Execute Action & Observe Reward):
拉动选定的臂 A t A_t At,得到奖励 R t R_t Rt。这个奖励通常是从该臂的未知奖励分布中采样得到的。 - 更新估计值 (Update Estimates):
- 更新被选中臂 A t A_t At 的计数: N t ( A t ) = N t − 1 ( A t ) + 1 N_t(A_t) = N_{t-1}(A_t) + 1 Nt(At)=Nt−1(At)+1。
- 更新被选中臂 A t A_t At 的奖励估计值。常用的方法是增量式样本均值:
Q t ( A t ) = Q t − 1 ( A t ) + 1 N t ( A t ) [ R t − Q t − 1 ( A t ) ] Q_t(A_t) = Q_{t-1}(A_t) + \frac{1}{N_t(A_t)} [R_t - Q_{t-1}(A_t)] Qt(At)=Qt−1(At)+Nt(At)1[Rt−Qt−1(At)]
这等价于:
Q t ( A t ) = 臂 A t 到目前为止获得的总奖励 臂 A t 到目前为止被选择的总次数 Q_t(A_t) = \frac{\text{臂 } A_t \text{ 到目前为止获得的总奖励}}{\text{臂 } A_t \text{ 到目前为止被选择的总次数}} Qt(At)=臂 At 到目前为止被选择的总次数臂 At 到目前为止获得的总奖励 - 对于未被选择的臂 a ≠ A t a \neq A_t a=At,它们的计数和估计值保持不变: N t ( a ) = N t − 1 ( a ) N_t(a) = N_{t-1}(a) Nt(a)=Nt−1(a), Q t ( a ) = Q t − 1 ( a ) Q_t(a) = Q_{t-1}(a) Qt(a)=Qt−1(a)。
- 选择动作 (Select Action):
-
结束 (End): 循环 T T T 次后结束。最终的 Q T ( a ) Q_T(a) QT(a) 值代表了算法对每个臂平均奖励的估计。算法在整个过程中获得的总奖励为 ∑ t = 1 T R t \sum_{t=1}^T R_t ∑t=1TRt。
3. 优缺点
优点:
- 简单性: 概念清晰,易于理解和实现。
- 保证探索: 只要 ϵ > 0 \epsilon > 0 ϵ>0,就能保证持续探索所有臂,避免完全陷入局部最优。
- 理论保证: 在一定条件下(如奖励有界), ϵ \epsilon ϵ-Greedy 算法可以收敛到接近最优的策略。
缺点:
- 探索效率低: 探索时是完全随机的,没有利用已知信息。即使某个臂的估计值已经很低且置信度很高,仍然会以 ϵ K \frac{\epsilon}{K} Kϵ 的概率去探索它。
- 持续探索: 如果 ϵ \epsilon ϵ 是常数,即使在后期已经对各臂有了较好的估计,算法仍然会以 ϵ \epsilon ϵ 的概率进行不必要的探索,影响最终的总奖励。使用衰减 ϵ \epsilon ϵ 可以缓解这个问题。
- 未考虑不确定性: 选择利用哪个臂时,只看当前的估计值 Q ( a ) Q(a) Q(a),没有考虑这个估计的不确定性。
2.2. UCB (Upper Confidence Bound) 算法
1. UCB (Upper Confidence Bound) 算法
核心思想:对于每个臂(老虎机),不仅要考虑它当前的平均奖励估计值,还要考虑这个估计值的不确定性。一个臂被选择的次数越少,我们对其真实平均奖励的估计就越不确定。UCB 算法会给那些不确定性高(即被选择次数少)的臂一个“奖励加成”,使得它们更有可能被选中。这样,算法倾向于选择那些 潜力高(可能是当前最佳,或者因为尝试次数少而有很大不确定性,可能被低估)的臂。
2. UCB 算法原理
UCB 算法在每个时间步 t t t 选择臂 A t A_t At 时,会计算每个臂 a a a 的一个置信上界分数,然后选择分数最高的那个臂。这个分数由两部分组成:
- 当前平均奖励估计值 (Exploitation Term): Q t − 1 ( a ) Q_{t-1}(a) Qt−1(a),即到时间步 t − 1 t-1 t−1 为止,臂 a a a 的平均观测奖励。这代表了我们当前对该臂价值的最好估计。
- 不确定性加成项 (Exploration Bonus): 一个基于置信区间的项,用于量化估计值的不确定性。常见的形式是 c ln t N t − 1 ( a ) c \sqrt{\frac{\ln t}{N_{t-1}(a)}} cNt−1(a)lnt。
因此,选择规则为:
A t = arg max a [ Q t − 1 ( a ) + c ln t N t − 1 ( a ) ] A_t = \arg\max_{a} \left[ Q_{t-1}(a) + c \sqrt{\frac{\ln t}{N_{t-1}(a)}} \right] At=argamax[Qt−1(a)+cNt−1(a)lnt]
让我们解析这个公式:
- Q t − 1 ( a ) Q_{t-1}(a) Qt−1(a): 臂 a a a 在 t − 1 t-1 t−1 时刻的平均奖励估计。
- N t − 1 ( a ) N_{t-1}(a) Nt−1(a): 臂 a a a 在 t − 1 t-1 t−1 时刻之前被选择的总次数。
- t t t: 当前的总时间步(总拉杆次数)。
- ln t \ln t lnt: 总时间步 t t t 的自然对数。随着时间的推移, t t t 增大, ln t \ln t lnt 也缓慢增大,这保证了即使一个臂的 N ( a ) N(a) N(a) 很大,探索项也不会完全消失,所有臂最终都会被持续探索(尽管频率会降低)。
- c c c: 一个正常数,称为探索参数。它控制着不确定性加成项的权重。 c c c 越大,算法越倾向于探索; c c c 越小,越倾向于利用。理论上 c = 2 c=\sqrt{2} c=2 是一个常用的选择,但在实践中可能需要调整。
工作机制:
- 如果一个臂 a a a 的 N t − 1 ( a ) N_{t-1}(a) Nt−1(a) 很小,那么分母 N t − 1 ( a ) \sqrt{N_{t-1}(a)} Nt−1(a) 就很小,导致不确定性加成项很大。这使得该臂即使 Q t − 1 ( a ) Q_{t-1}(a) Qt−1(a) 不高,也有较高的 UCB 分数,从而被优先选择(探索)。
- 随着一个臂被选择的次数 N ( a ) N(a) N(a) 增加,不确定性项会逐渐减小,UCB 分数将越来越依赖于实际的平均奖励 Q ( a ) Q(a) Q(a)(利用)。
- ln t \ln t lnt 项确保了随着时间的推移,即使是那些表现似乎较差的臂,只要它们的 N ( a ) N(a) N(a) 相对较小,其 UCB 分数也会缓慢增长,保证它们不会被完全放弃。
处理 N ( a ) = 0 N(a)=0 N(a)=0 的情况: 在算法开始时,为了避免分母为零,通常需要先将每个臂都尝试一次。
3. UCB 算法实现步骤
假设有 K K K 个臂,总共进行 T T T 次试验。
-
初始化 (Initialization):
- 设置探索参数 c > 0 c > 0 c>0。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化奖励估计值 Q 0 ( a ) = 0 Q_0(a) = 0 Q0(a)=0 (或一个较大的初始值以鼓励早期探索)。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化被选择的次数 N 0 ( a ) = 0 N_0(a) = 0 N0(a)=0。
-
初始探索阶段 (Initial Exploration Phase):
- 为了确保每个臂至少被选择一次(避免后续计算 ln t N ( a ) \sqrt{\frac{\ln t}{N(a)}} N(a)lnt 时出现除以零),先将每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 都拉动一次。
- 这通常会占用前 K K K 个时间步( t = 1 t=1 t=1 到 t = K t=K t=K)。对于每个 t = a t=a t=a (其中 a a a 从 1 到 K K K):
- 选择臂 A t = a A_t = a At=a。
- 执行动作,观察奖励 R t R_t Rt。
- 更新 N t ( a ) = 1 N_t(a) = 1 Nt(a)=1。
- 更新 Q t ( a ) = R t Q_t(a) = R_t Qt(a)=Rt。
- (其他臂的 N N N 和 Q Q Q 保持为 0 或初始值)。
-
主循环阶段 (Main Loop): 对于时间步 t = K + 1 , . . . , T t = K+1, ..., T t=K+1,...,T:
- 计算所有臂的 UCB 分数: 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K,计算其 UCB 值:
UCB t ( a ) = Q t − 1 ( a ) + c ln t N t − 1 ( a ) \text{UCB}_t(a) = Q_{t-1}(a) + c \sqrt{\frac{\ln t}{N_{t-1}(a)}} UCBt(a)=Qt−1(a)+cNt−1(a)lnt- 注意:此时 N t − 1 ( a ) ≥ 1 N_{t-1}(a) \ge 1 Nt−1(a)≥1 且 t ≥ K + 1 ≥ 2 t \ge K+1 \ge 2 t≥K+1≥2,所以 ln t ≥ ln 2 > 0 \ln t \ge \ln 2 > 0 lnt≥ln2>0。
- 选择动作 (Select Action):
选择具有最高 UCB 分数的臂:
A t = arg max a UCB t ( a ) A_t = \arg\max_{a} \text{UCB}_t(a) At=argamaxUCBt(a)- 如果存在多个臂具有相同的最高分数,可以随机选择其中一个。
- 执行动作并观察奖励 (Execute Action & Observe Reward):
拉动选定的臂 A t A_t At,得到奖励 R t R_t Rt。 - 更新估计值 (Update Estimates):
- 更新被选中臂 A t A_t At 的计数: N t ( A t ) = N t − 1 ( A t ) + 1 N_t(A_t) = N_{t-1}(A_t) + 1 Nt(At)=Nt−1(At)+1。
- 使用增量式样本均值更新被选中臂 A t A_t At 的奖励估计值:
Q t ( A t ) = Q t − 1 ( A t ) + 1 N t ( A t ) [ R t − Q t − 1 ( A t ) ] Q_t(A_t) = Q_{t-1}(A_t) + \frac{1}{N_t(A_t)} [R_t - Q_{t-1}(A_t)] Qt(At)=Qt−1(At)+Nt(At)1[Rt−Qt−1(At)] - 对于未被选择的臂 a ≠ A t a \neq A_t a=At,它们的计数和估计值保持不变: N t ( a ) = N t − 1 ( a ) N_t(a) = N_{t-1}(a) Nt(a)=Nt−1(a), Q t ( a ) = Q t − 1 ( a ) Q_t(a) = Q_{t-1}(a) Qt(a)=Qt−1(a)。
- 计算所有臂的 UCB 分数: 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K,计算其 UCB 值:
-
结束 (End): 循环 T T T 次后结束。
4. 优缺点
优点:
- 智能探索: 相较于 ϵ \epsilon ϵ-Greedy 的随机探索,UCB 的探索更有针对性,优先探索那些潜力更大(不确定性高)的臂。
- 无需设置 ϵ \epsilon ϵ: 它不需要像 ϵ \epsilon ϵ-Greedy 那样设定探索概率 ϵ \epsilon ϵ(尽管需要设定探索参数 c c c)。
- 性能优越: 在许多平稳(Stationary)的 MAB 问题中,UCB 及其变种通常比 ϵ \epsilon ϵ-Greedy 表现更好,尤其是在试验次数较多时。
- 良好的理论性质: UCB 算法有很强的理论支持,其累积遗憾(Regret)通常被证明是对数级别的( O ( log T ) O(\log T) O(logT)),这是非常理想的性能。
缺点:
- 需要知道总时间步 t t t: 标准 UCB 公式需要用到总时间步 t t t 的对数 ln t \ln t lnt。
- 对参数 c c c 敏感: 探索参数 c c c 的选择会影响算法性能,可能需要根据具体问题进行调整。
- 对非平稳环境敏感: 标准 UCB 假设臂的奖励分布是固定的(平稳的)。在奖励分布随时间变化的环境(非平稳)中,其性能可能会下降(因为旧的观测数据可能不再准确)。有一些变种(如 D-UCB, SW-UCB)用于处理非平稳环境。
- 计算开销: 每次选择都需要计算所有臂的 UCB 分数,虽然计算量不大,但比 ϵ \epsilon ϵ-Greedy 的贪婪选择略高。
2.3. Thompson Sampling 汤普森采样算法
1. Thompson Sampling 算法简介
核心思想:
- 维护信念分布: 对每个臂 a a a 的未知奖励参数(例如,伯努利臂的成功概率 p a p_a pa)维护一个后验概率分布。这个分布反映了基于已观察到的数据,我们对该参数可能取值的信念。
- 采样: 在每个时间步 t t t,为每个臂 a a a 从其当前的后验分布中抽取一个样本值 θ a \theta_a θa。这个样本可以被看作是该臂在当前信念下的一个“可能”的真实参数值。
- 选择: 选择具有最大采样值 θ a \theta_a θa 的那个臂 A t A_t At。
- 更新信念: 观察所选臂 A t A_t At 的奖励 R t R_t Rt,然后使用贝叶斯定理更新臂 A t A_t At 的后验分布,将新的观测信息融合进去。
这种方法的巧妙之处在于,选择臂的概率自动与其后验分布中“该臂是最优臂”的概率相匹配。
- 如果一个臂的后验分布集中在较高的值(即我们很确定它很好),那么从中采样的值很可能最高,该臂被选中的概率就高(利用)。
- 如果一个臂的后验分布很宽(即我们对它的真实值很不确定),那么即使其均值不是最高,它也有机会采样到一个非常高的值而被选中,从而实现探索。
2. Thompson Sampling 算法原理
在这种情况下,通常使用 Beta 分布 作为成功概率 p a p_a pa 的先验和后验分布,因为 Beta 分布是伯努利似然函数的共轭先验 (Conjugate Prior)。这意味着,如果先验是 Beta 分布,并且观测数据来自伯努利分布,那么后验分布仍然是 Beta 分布,只是参数会更新。
- Beta 分布: Beta ( α , β ) (\alpha, \beta) (α,β) 由两个正参数 α \alpha α 和 β \beta β 定义。其均值为 α α + β \frac{\alpha}{\alpha + \beta} α+βα。 α \alpha α 可以看作是“观测到的成功次数 + 1”, β \beta β 可以看作是“观测到的失败次数 + 1”(这里的“+1”来自一个常见的 Beta(1,1) 均匀先验)。分布的形状由 α \alpha α 和 β \beta β 控制,当 α + β \alpha+\beta α+β 增大时,分布变得更窄,表示不确定性降低。
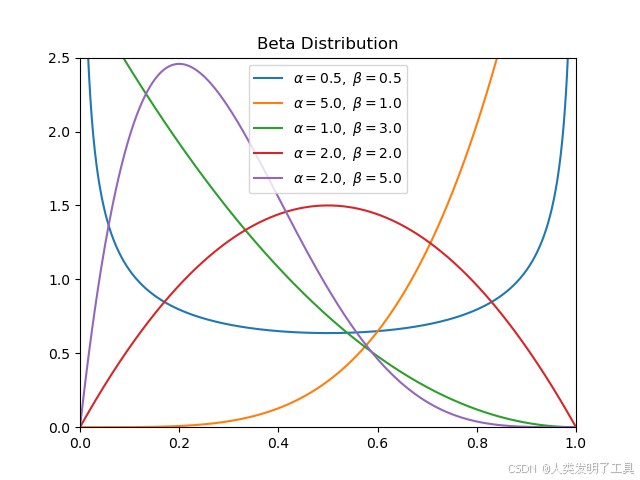
算法流程中的关键步骤:
- 初始化: 为每个臂 a a a 设置 Beta 分布的初始参数,通常为 α a = 1 , β a = 1 \alpha_a = 1, \beta_a = 1 αa=1,βa=1。这对应于一个 Beta(1, 1) 分布,即 [0, 1] 上的均匀分布,表示在没有任何观测数据之前,我们认为 p a p_a pa 在 [0, 1] 区间内取任何值的可能性都相同。
- 采样: 在每个时间步 t t t,为每个臂 a a a 从其当前的后验分布 Beta ( α a , β a ) (\alpha_a, \beta_a) (αa,βa) 中独立抽取一个随机样本 θ a \theta_a θa。
- 选择: 选择使得 θ a \theta_a θa 最大的臂 A t = arg max a θ a A_t = \arg\max_a \theta_a At=argmaxaθa。
- 更新: 假设选择了臂 A t A_t At 并观察到奖励 R t ∈ { 0 , 1 } R_t \in \{0, 1\} Rt∈{0,1} :
- 每个臂 a a a 的奖励是 0 (失败) 或 1 (成功)
- 如果 R t = 1 R_t = 1 Rt=1 (成功),则更新臂 A t A_t At 的参数: α A t ← α A t + 1 \alpha_{A_t} \leftarrow \alpha_{A_t} + 1 αAt←αAt+1。
- 如果 R t = 0 R_t = 0 Rt=0 (失败),则更新臂 A t A_t At 的参数: β A t ← β A t + 1 \beta_{A_t} \leftarrow \beta_{A_t} + 1 βAt←βAt+1。
- 未被选择的臂的参数保持不变。
随着观测数据的增加,每个臂的 Beta 分布会变得越来越集中(方差减小),反映了我们对其真实成功概率 p a p_a pa 的信念越来越确定。
3. Thompson Sampling 算法实现步骤
假设有 K K K 个臂,总共进行 T T T 次试验。
-
初始化 (Initialization):
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 设置 Beta 分布参数 α a = 1 \alpha_a = 1 αa=1。
- 设置 Beta 分布参数 β a = 1 \beta_a = 1 βa=1。
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
-
循环执行 (Loop): 对于时间步 t = 1 , 2 , . . . , T t = 1, 2, ..., T t=1,2,...,T:
- 采样阶段 (Sampling Phase):
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 从 Beta 分布 Beta ( α a , β a ) (\alpha_a, \beta_a) (αa,βa) 中抽取一个随机样本 θ a \theta_a θa。
- (这需要一个能够从 Beta 分布生成随机数的函数库,例如 Python 的
numpy.random.beta)。
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 选择动作 (Select Action):
- 找到使得样本值 θ a \theta_a θa 最大的臂:
A t = arg max a ∈ { 1 , . . . , K } θ a A_t = \arg\max_{a \in \{1, ..., K\}} \theta_a At=arga∈{1,...,K}maxθa - 如果存在多个臂具有相同的最大样本值,可以随机选择其中一个。
- 找到使得样本值 θ a \theta_a θa 最大的臂:
- 执行动作并观察奖励 (Execute Action & Observe Reward):
- 拉动选定的臂 A t A_t At,得到奖励 R t ∈ { 0 , 1 } R_t \in \{0, 1\} Rt∈{0,1}。
- 更新后验分布 (Update Posterior):
- 如果 R t = 1 R_t = 1 Rt=1:
α A t ← α A t + 1 \alpha_{A_t} \leftarrow \alpha_{A_t} + 1 αAt←αAt+1 - 如果 R t = 0 R_t = 0 Rt=0:
β A t ← β A t + 1 \beta_{A_t} \leftarrow \beta_{A_t} + 1 βAt←βAt+1
- 如果 R t = 1 R_t = 1 Rt=1:
- 采样阶段 (Sampling Phase):
-
结束 (End): 循环 T T T 次后结束。
4. 优缺点
优点:
- 性能优异: 在实践中,Thompson Sampling 通常表现非常好,经常优于或至少媲美 UCB 算法,尤其是在累积奖励方面。
- 概念优雅且自然: 基于贝叶斯推理,提供了一种原则性的方式来处理不确定性并通过概率匹配来平衡探索与利用。
- 易于扩展: 可以相对容易地适应不同的奖励模型(如高斯奖励,只需将 Beta-Bernoulli 更新替换为 Normal-Normal 或 Normal-Inverse-Gamma 更新)。
- 无需手动调整探索参数: 不像 ϵ \epsilon ϵ-Greedy 的 ϵ \epsilon ϵ 或 UCB 的 c c c 需要仔细调整(虽然先验选择也可能影响性能,但通常对标准先验如 Beta(1,1) 较为鲁棒)。
- 良好的理论性质: 具有较好的理论累积遗憾界。
缺点:
- 需要指定先验: 作为贝叶斯方法,需要为参数选择一个先验分布。虽然通常有标准选择(如 Beta(1,1)),但在某些情况下先验的选择可能影响早期性能。
- 计算成本: 需要在每个时间步从后验分布中采样。对于 Beta 分布,采样通常很快,但对于更复杂的模型,采样可能比 UCB 的直接计算更耗时。
- 实现略复杂: 相较于 ϵ \epsilon ϵ-Greedy,需要理解贝叶斯更新规则并使用能进行分布采样的库。






/FormatMessage 的区别)

)

检测工具)






)

