
简介
机器学习中生存树(Survival Tree)的原理详解 生存树是结合决策树与生存分析的机器学习模型,主要用于处理带有时间-事件数据(包含删失数据)的预测问题。其核心目标是:通过树状结构对数据进行递归分割,使每个叶节点内的样本具有相似的生存模式。以下是生存树的核心原理分步解析:
一、基础概念回顾
生存分析的核心要素:
时间(Time):事件发生的时间或研究截止时间。
状态(Status):事件是否发生(如1=死亡,0=存活)。
删失(Censoring):部分样本在研究结束时未观察到事件。
传统生存模型:
Kaplan-Meier估计:非参数方法,估计生存函数。
Cox比例风险模型:半参数模型,分析协变量对风险的影响。
二、生存树的构建原理
生存树通过递归划分数据,生成树结构,每个叶节点代表一个风险群体。其核心步骤包括:
分裂准则(Splitting Criterion) 目标:选择最优特征和切分点,使得子节点的生存差异最大化。
常用方法:
对数秩检验(Log-Rank Test):比较左右子节点生存曲线的差异,选择统计量最大的分裂点。
似然比检验:基于生存模型(如指数分布或Cox模型)的似然函数差异。
Harrell's C-index:最大化子节点的预测区分度。
示例: 在每个候选分裂点,计算左右子节点的Kaplan-Meier曲线,通过对数秩检验的p值评估差异显著性,选择p值最小的分裂点。
处理删失数据 删失数据参与计算:在计算生存差异时,删失数据会被纳入风险集,直到其退出研究。
节点纯度的衡量:使用生存函数的差异性(而非分类的纯度指标如基尼系数)。
树的生长与剪枝 生长阶段:递归分裂直到满足停止条件(如节点样本数过少或无法显著提升区分度)。
剪枝策略:
复杂度参数(CP):通过交叉验证选择最优子树,平衡模型复杂度与预测误差。
基于损失函数:如指数损失(method="exp")或Cox模型的偏似然损失。
三、生存树的预测与解释
预测输出 风险评分(Risk Score):每个叶节点的样本具有相似的风险水平,可通过中位生存时间或累积风险函数描述。
生存概率曲线:基于叶节点内样本的Kaplan-Meier估计生成。
变量重要性 分裂贡献度:通过特征在分裂过程中提升的生存差异(如对数秩统计量)衡量重要性。
替代指标:基于特征在树中出现的位置和次数(越靠近根节点或出现次数越多,重要性越高)。
可视化解释 树结构图:显示每个节点的分裂条件、样本量及生存统计量。
生存曲线对比:不同叶节点的Kaplan-Meier曲线可视化(如下图)。
生存树节点生存曲线示例
四、生存树的优缺点
优点: 非线性关系处理:自动捕捉变量间的交互效应和非线性模式。
可解释性:树结构直观展示风险分层规则。
无需分布假设:非参数方法,适用于复杂生存数据。
缺点: 过拟合风险:需通过剪枝和交叉验证控制。
稳定性较低:数据微小变化可能导致树结构剧变(可通过集成方法如随机生存森林缓解)。
五、与经典方法的对比
特性 Cox模型 生存树 模型假设 比例风险假设 无分布假设 交互效应处理 需手动指定 自动捕捉 可解释性 回归系数解释 树结构规则解释 适用场景 线性效应主导的问题 复杂非线性/交互效应问题
六、实际应用案例
医疗领域:预测患者生存时间,根据年龄、基因表达等特征分层。
金融风控:预测客户流失时间,识别高风险群体。
工业维护:预测设备故障时间,制定预防性维护策略。
安装必要包
install.packages(c("survival", "rpart", "rpart.plot", "ggplot2", "survminer"))加载包
library(survival) # 生存分析基础包
library(rpart) # 递归分区生存树
library(rpart.plot) # 树结构可视化
library(ggplot2) # 图形绘制
library(survminer) # 生存曲线可视化载入示例数据(lung数据集)
data(lung)## Warning in data(lung): 没有'lung'这个数据集df <- lung[, c("time", "status", "age", "sex", "ph.ecog", "ph.karno")]数据预处理
df$status <- ifelse(df$status == 2, 1, 0) # 将状态转换为0/1(1=事件发生)
df <- na.omit(df) # 删除缺失值(实际分析需谨慎处理缺失值)划分训练集/测试集
set.seed(123)
train_index <- sample(1:nrow(df), size = floor(0.7*nrow(df)))
train_data <- df[train_index, ]
test_data <- df[-train_index, ]构建生存树模型
surv_tree <- rpart(formula = Surv(time, status) ~ ., # 生存公式data = train_data,method = "exp", # 指数生存模型control = rpart.control(minsplit = 10, # 节点最小样本数cp = 0.01, # 复杂度参数xval = 10# 交叉验证折数)
)可视化树结构
prp(surv_tree,main = "Survival Tree Structure",extra = 101, # 显示节点样本数和风险比branch.type = 5,nn = TRUE,cex = 0.5)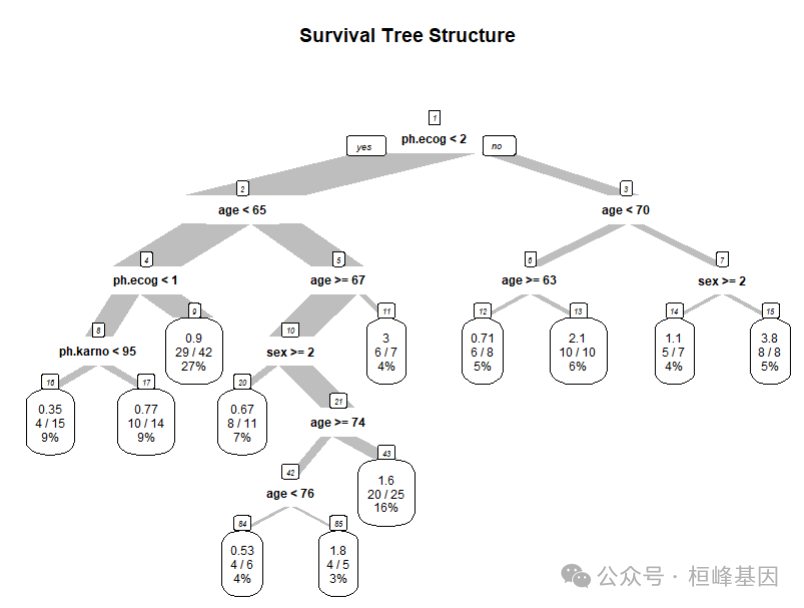
绘制变量重要性
var_imp <- surv_tree$variable.importance
barplot(var_imp, main = "Variable Importance", col = "skyblue",horiz = T,las=1)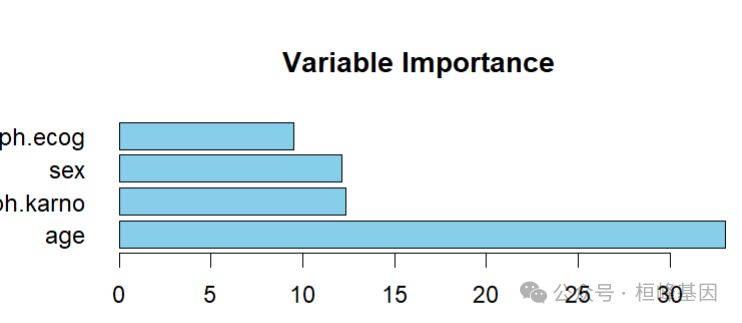
模型预测(示例:测试集)
test_pred <- predict(surv_tree, newdata = test_data, type = "vector")生存曲线可视化(按风险分组)
分组
使用中位数风险值划分高低风险组,生成风险分组并绑定到测试数据。
test_data$risk_groups <- ifelse(test_pred > median(test_pred), "High Risk", "Low Risk")
surv_fit <- survfit(Surv(time, status) ~ risk_groups, data = test_data)绘制KM图
ggsurvplot(surv_fit,data = test_data,pval = TRUE,risk.table = TRUE,legend.labs = c("High Risk", "Low Risk"),title = "Kaplan-Meier Survival Curves by Risk Group")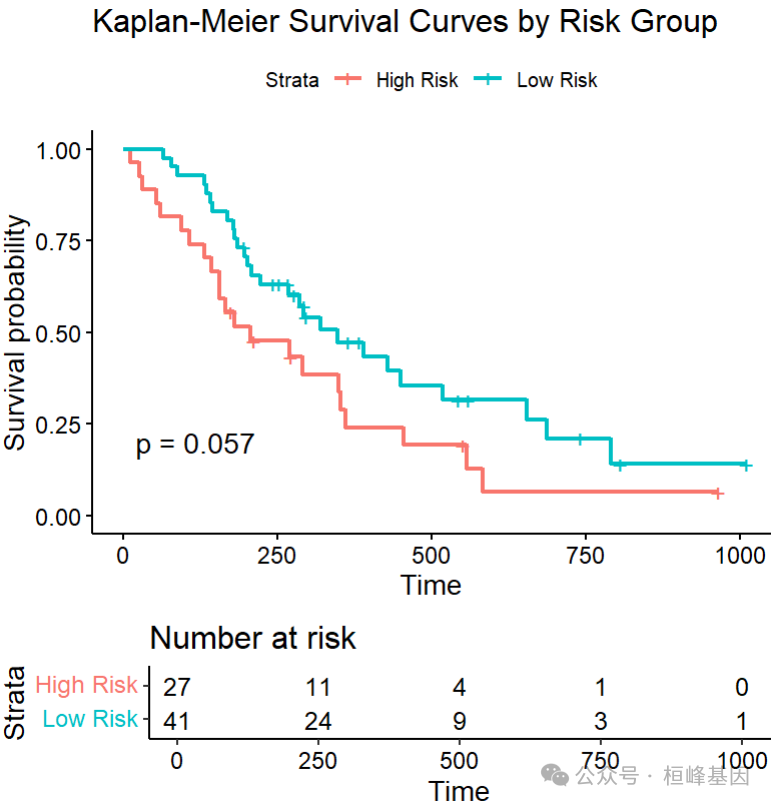
模型评估(C-index)
训练集性能
train_pred <- predict(surv_tree, newdata = train_data)
c_index_train <- concordance(Surv(train_data$time, train_data$status) ~ train_pred)$concordance测试集性能
c_index_test <- concordance(Surv(test_data$time, test_data$status) ~ test_pred)$concordancecat(paste("Training C-index:", round(c_index_train, 3), "\n",
"Test C-index:", round(c_index_test, 3)))## Training C-index: 0.287
## Test C-index: 0.346保存结果
保存模型
saveRDS(surv_tree, file = "survival_tree_model.rds")保存预测结果
write.csv(test_pred, file = "test_predictions.csv")保存工作空间镜像
save.image("survival_tree_analysis.RData")

为1毫秒(设备拔插或系统重启后自动生效)】)
)


!!!)




 ✨ | Hidden Search Widget (交互式搜索框))








——QuickStart)