传输层协议UDP和TCP
- 1、UDP
- 2、TCP
- 2.1、TCP协议段格式
- 2.2、确认应答(ACK)机制
- 2.3、超时重传机制
- 2.4、连接管理机制
- 2.5、理解CLOSE_WAIT状态
- 2.6、理解TIME_WAIT状态
- 2.7、流量控制
- 2.8、滑动窗口
- 2.9、拥塞控制
- 2.10、延迟应答
- 2.11、捎带应答
- 2.12、面向字节流
- 2.13、粘包问题
- 2.14、TCP异常情况
- 2.15、用UDP实现可靠传输
- 3、TCP全连接队列和tcpdump抓包
1、UDP
传输层:负责数据能够从发送端传输接收端。
再谈端口号:端口号(Port)标识了一个主机上进行通信的不同的应用程序。
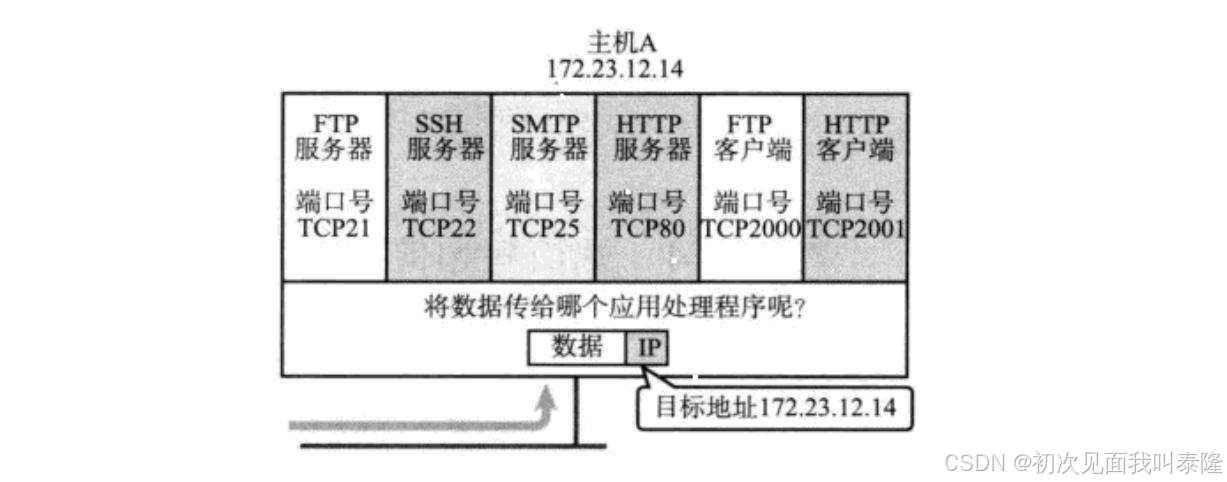
如图,主机A上有许多服务,那么当传输层接收到数据,如何得知要将数据交给上层的哪个进程呢?网络通信本质就是进程间通信。所以就需要端口号来标识要将数据交给上层的哪个进程。一个端口号只能被一个进程绑定,而一个进程可以绑定多个端口号。
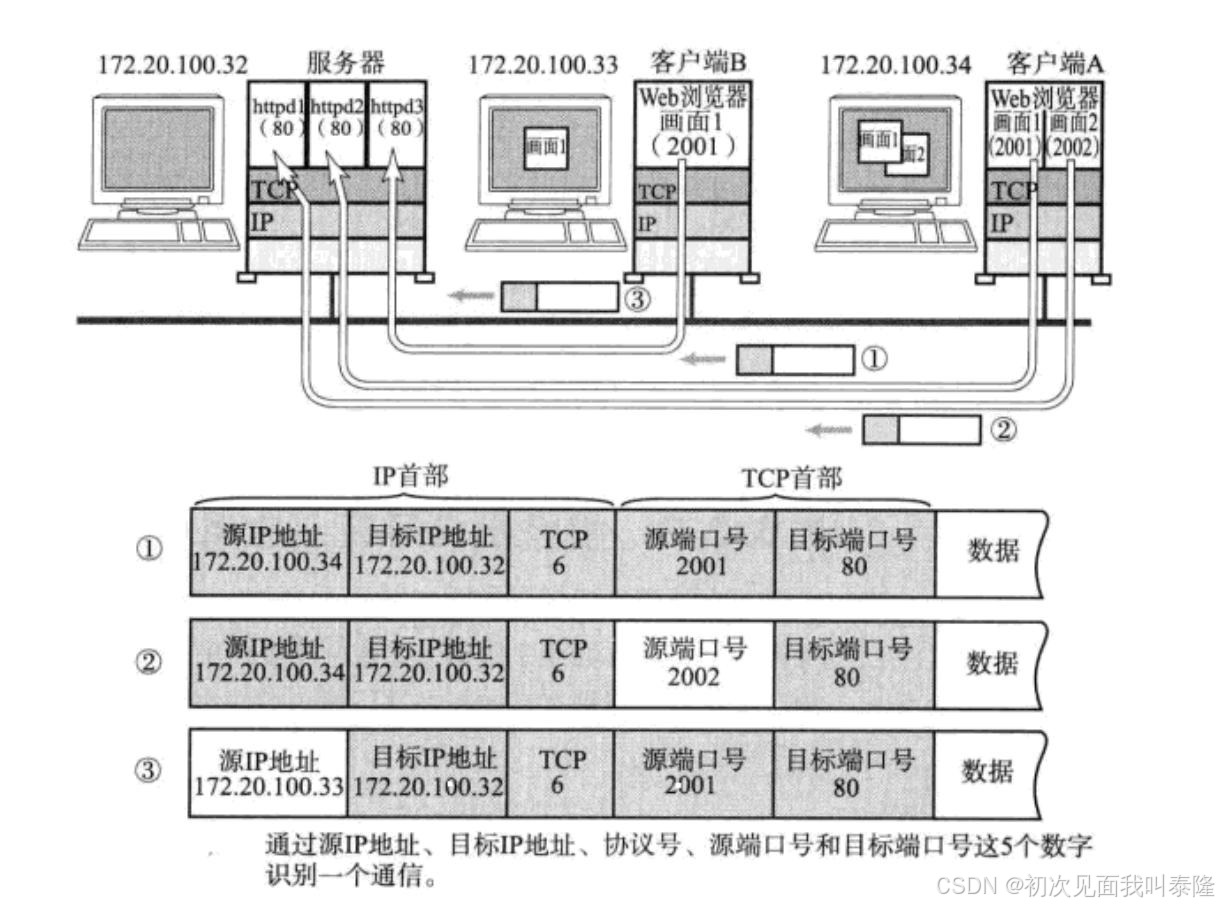
如图:客户端B向服务器发起请求,客户端A的web浏览器有两个页面向服务器发起请求。服务器要将响应的资源返回,而请求的时候会携带自己的源IP地址和源端口号,因此服务器将来返回的时候就可以根据IP地址找到主机,但是对于客户端A的浏览器请求了两个不同的页面,所以还需要端口号来区分要交给谁,而不会给反了或给错了。
所以之前我们是通过源IP+源端口+目的IP+目的端口四元组来标识一个网络通信的。那么实际上源IP和目的IP是添加在IP报头中的,然后源端口和目的端口是添加在TCP首部的,并且还需有一个协议号来标识传输层用的是什么协议。所以现在就通过上面的四元组+协议号来标识一个通信。
0 - 1023:知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议,他们的端口号都是固定的。
1024 - 65535:操作系统动态分配的端口号. 客户端程序的端口号,就是由操作系统从这个范围分配的。
cat /etc/services:可以查看一些知名端口。
UDP协议:
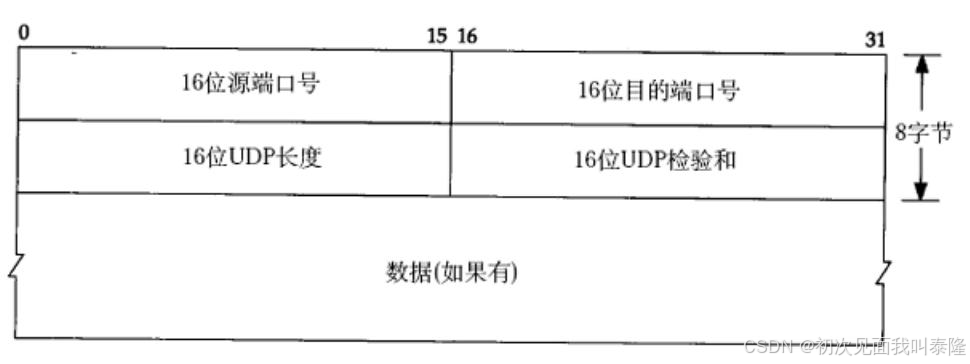
UDP协议报文如图:第一行32位,4个字节,前十六位表示源端口号,后十六位表示目的端口号。第二个四字节表示16位UDP长度和16位校验和。16位UDP长度是整个报文的长度,也就是报头8个字节加上数据的长度。如果校验和出错,就会直接将报文丢弃。
1、UDP如何做到解包的?
在读取UDP报文的时候,直接读取前八个字节,就是UDP报文的报头,剩下的就是有效载荷了。
2、UDP如何做到分用?
UDP报头里面就有16位目的端口号,根据16位目的端口号就可以找到进程。
3、接收方收到的UDP报文可能有多个黏在一起,这就是粘包问题。那么操作系统是如何准确的把一个UDP报文读上来呢?
UDP报文的前八个字节就是固定的报头,读取前八个字节将16位UDP长度提取出来,然后将长度减8算出来的就是有效载荷的长度,就可以根据这个长度去读取数据了。
16位UDP长度,这种自己报头里会描述有效载荷的特性我们称为自描述字段。
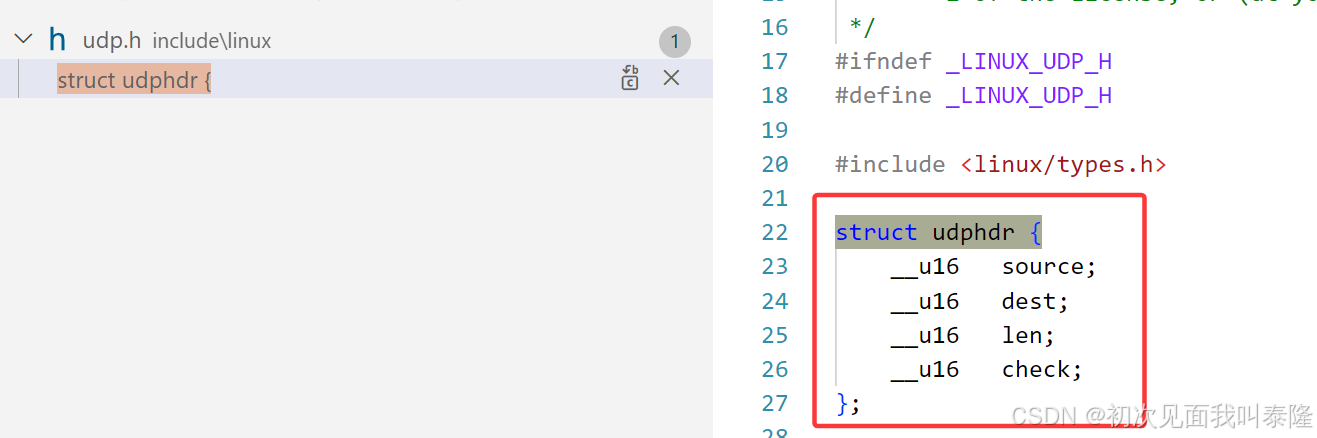
上图就是Linux内核中UDP报头的结构体信息。
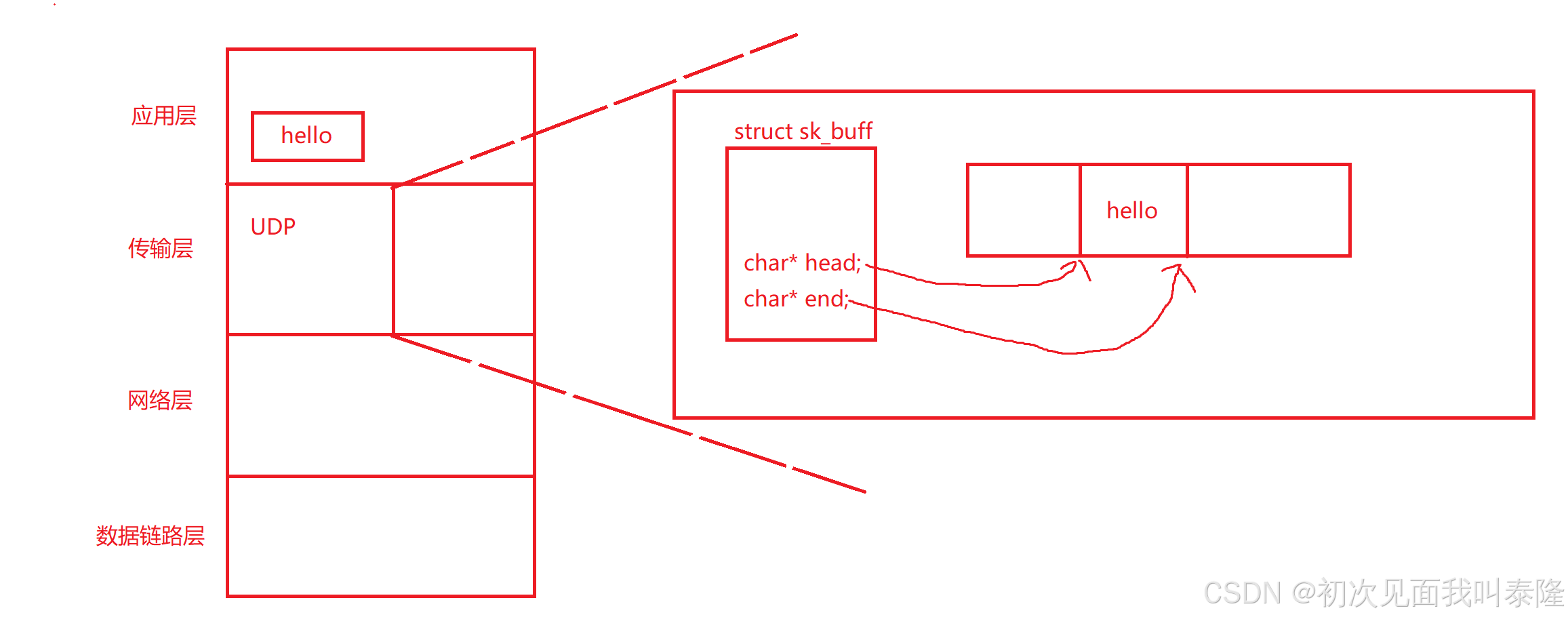
应用层发送数据hello,交给下层,我们知道操作系统要对报文进行管理,所以struct sk_buff就是一个一个的报文。head指针指向数据头部,end指向尾部。并且之前也说了TCP全双工是存在两个队列的,一个接收队列一个写队列。
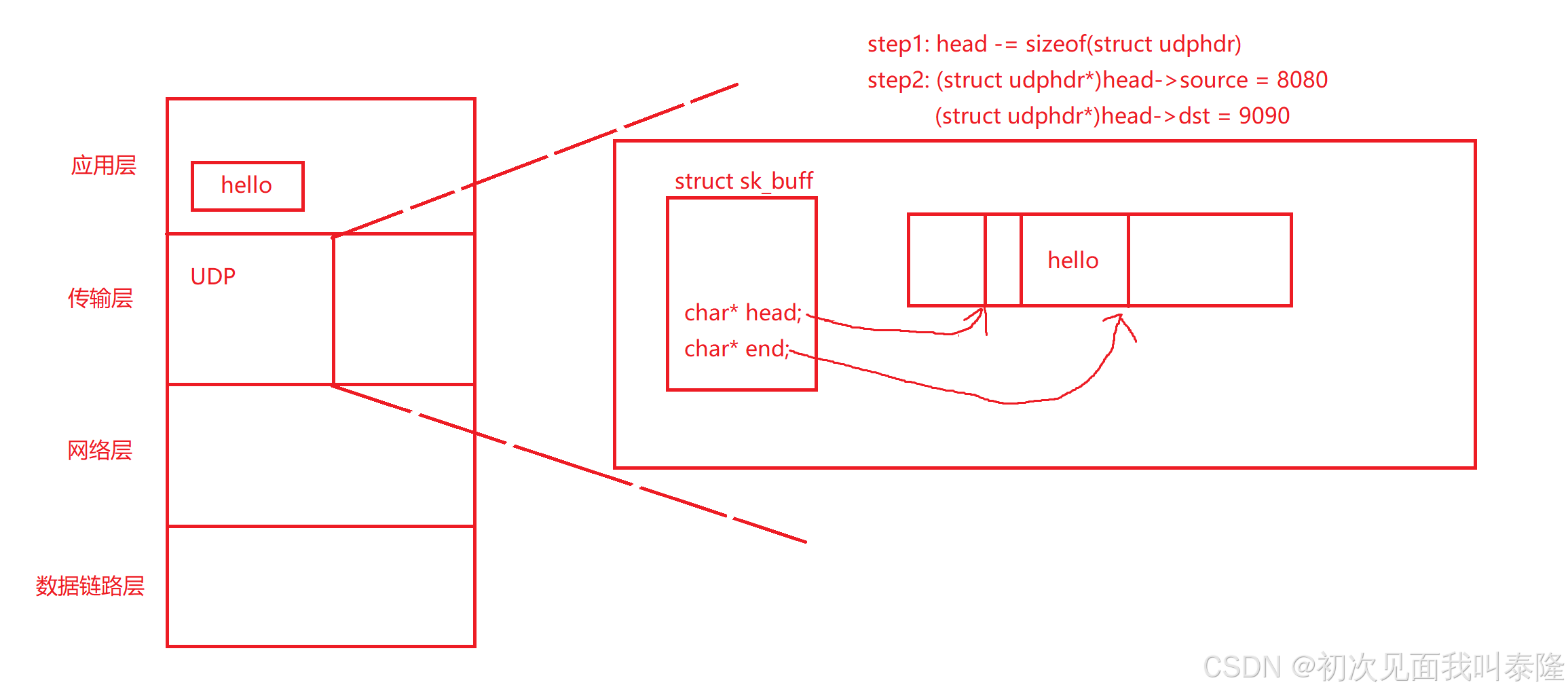
那么现在报头无非就是两步,第一步:将head指针往前移动udphdr大小个字节。第二步:接着将指针强转成struct udphdr*然后就可以访问里面的成员,对里面的成员进行赋值。
UDP的特点:
无连接:知道对端的IP和端口号就直接进行传输,不需要建立连接。
不可靠:没有确认机制,没有重传机制。如果因为网络故障该段无法发到对方,UDP 协议层也不会给应用层返回任何错误信息。
面向数据报:不能够灵活的控制读写数据的次数和数量。应用层交给 UDP 多长的报文,UDP原样发送,既不会拆分,也不会合并。
UDP的缓冲区:
UDP没有真正意义上的发送缓冲区。调用 sendto 会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作。
UDP具有接收缓冲区。但是这个接收缓冲区不能保证收到的UDP报文的顺序和发送UDP报文的顺序一致。如果缓冲区满了,再到达的 UDP 数据就会被丢弃。
比如主机A给主机B发送的顺序是ABC,而主机B接收到的顺序可能就是BCA,这也是属于不可靠传输的一种。
我们注意到,UDP协议首部中有一个16位的最大长度。也就是说一个UDP能传输的数据最大长度是64K(包含 UDP首部)。然而64K在当今的互联网环境下,是一个非常小的数字。如果我们需要传输的数据超过 64K,就需要在应用层手动的分包,多次发送,并在接收端手动拼装。
基于UDP的应用层协议:
NFS:网络文件系统
TFTP:简单文件传输协议
DHCP:动态主机配置协议
BOOTP:启动协议(用于无盘设备启动)
DNS:域名解析协议
2、TCP
TCP全称为"传输控制协议(Transmission Control Protocol)"。人如其名,要对数据的传输进行一个详细的控制。
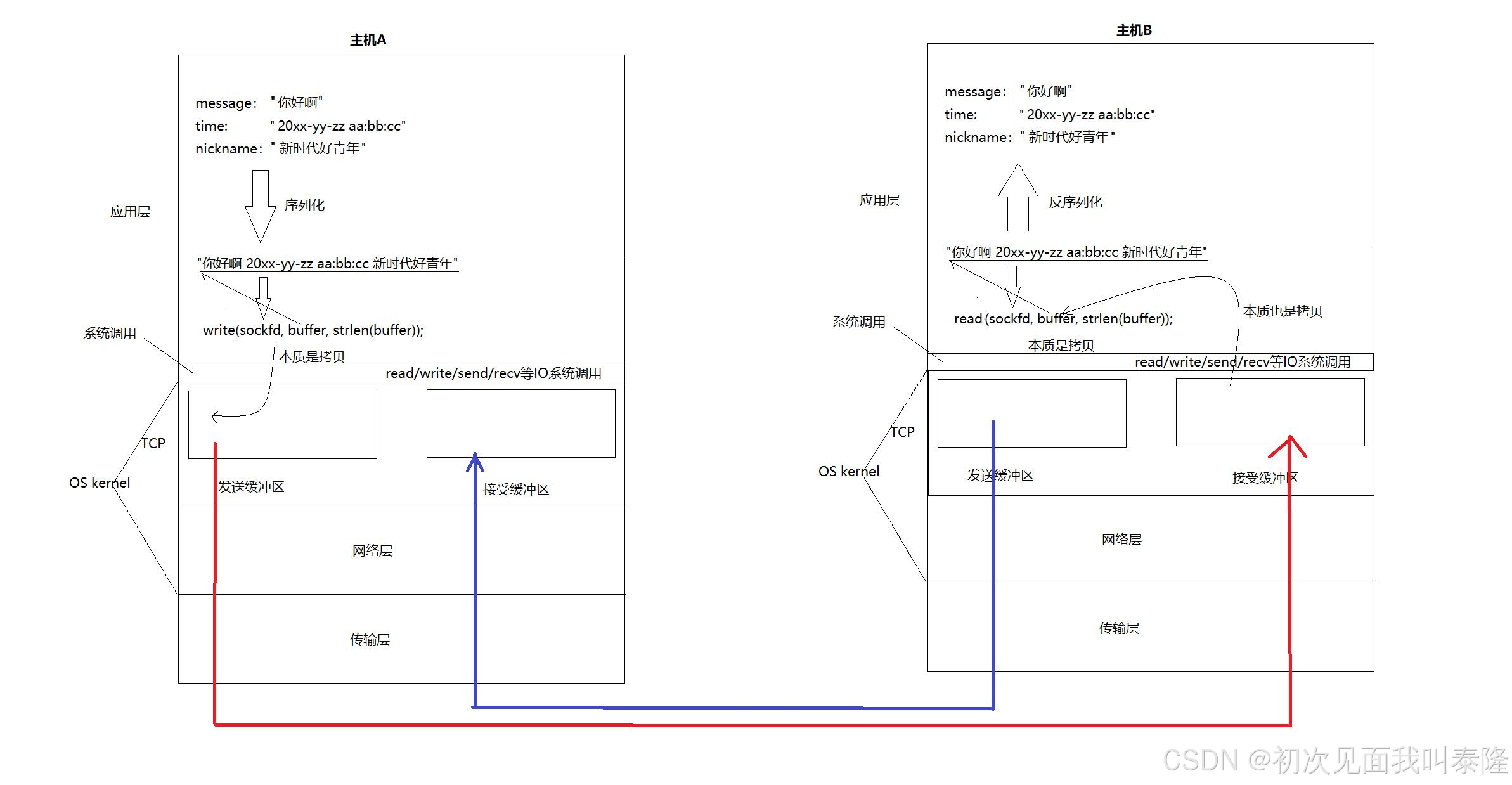
TCP有两个缓冲区,一个发送缓冲区一个接收缓冲区,当我们调用write函数时,本质是将数据拷贝到发送缓冲区中,对方调用read获取数据时,本质上是从接收缓冲区中拷贝数据。而发送数据本质就是将主机A的发送缓冲区的数据拷贝到主机B的接收缓冲区中,所以网络通信的本质就是拷贝。
上层将数据拷贝到发送缓冲区,本质就是拷贝给操作系统,未来数据发送的相关问题:什么时候发、发多少、出错了怎么办等,都是由操作系统自主决定的,所以TCP叫做传输控制协议。而UDP不存在发送缓冲区,write之后将数据交给下层,UDP做不到传输控制。
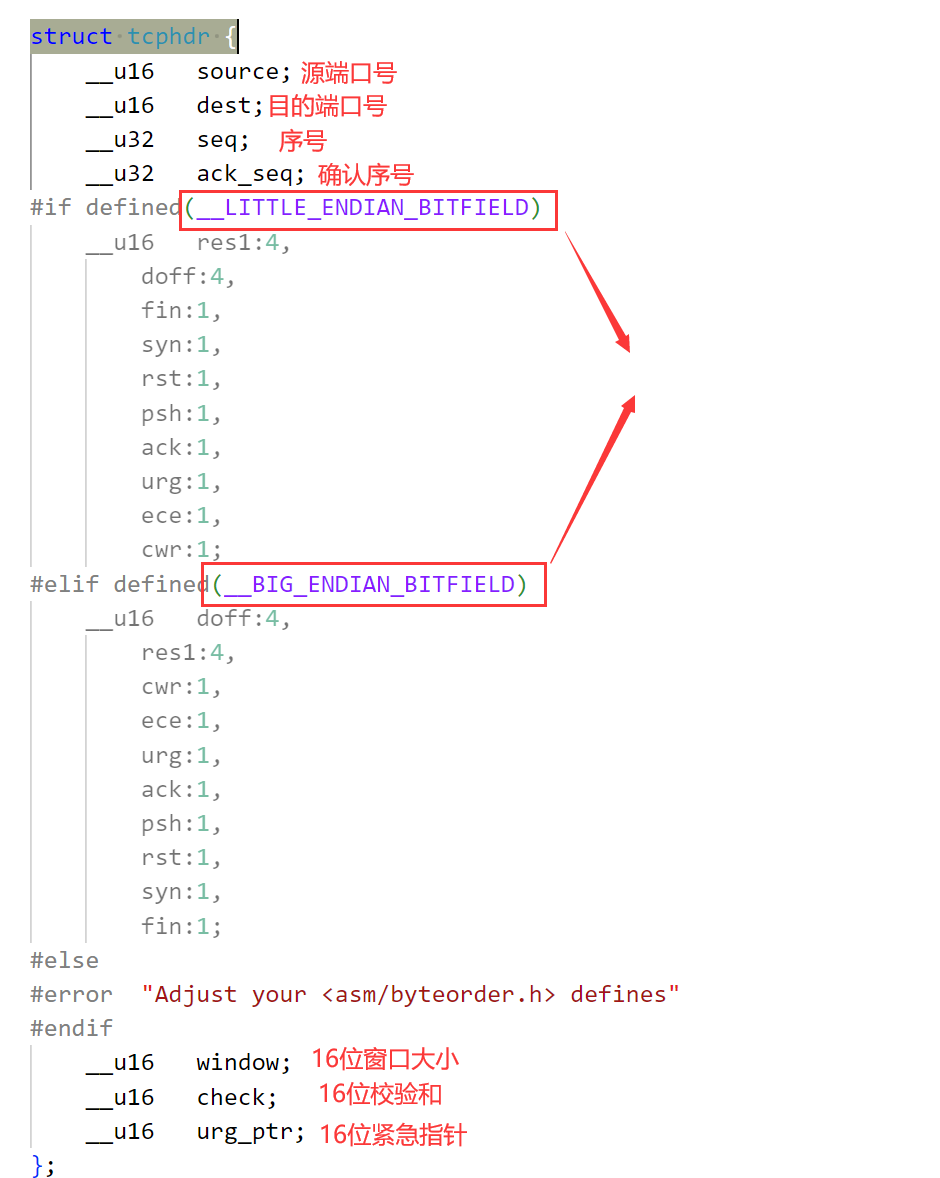
2.1、TCP协议段格式
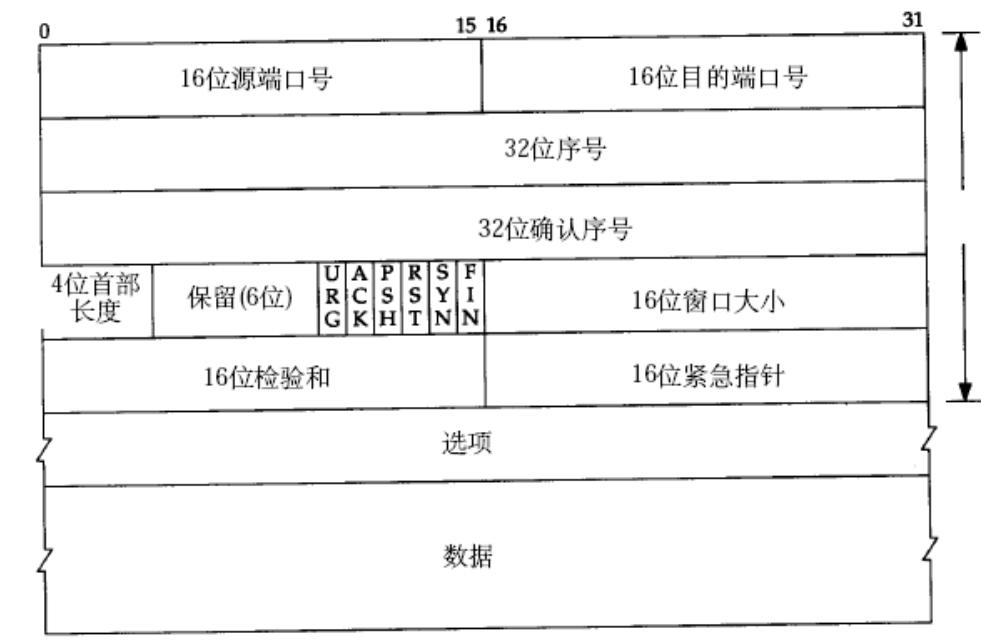
如图,TCP报文包含报头和数据,其中前20个字节是固定的,图中就是五行,每一行四个字节,总共20字节。第一行为16位源端口、16位目的端口。第二行32位序号。第三行32位确认序号。第四行,4位首部长度,保留六位,还有六个标志位,16位窗口大小。第四行有16位校验和与16位紧急指针。
另外TCP还可以携带选项,如果不带选项就是20字节的报头+数据。
1、TCP是如何解包的?
首先读取前20个字节的固定长度,然后提取4位首部长度,根据4位首部长度的大小就可以获取完整的TCP报头,这个4位首部长度是包含固定的20字节+选项的长度的。那有人就会说了,4位首部长度最大就是1111,转换成十进制就是15,连前二十个字节都表示不了?
4位首部长度是有基本计算单位的,它的基本单位是4字节。
4位首部长度的取值范围为0000->1111,也就是[0,15],还需要再乘以4,所以最后4位首部长度可以表示的范围就是[0,60]。但是TCP前面20字节是固定的,因此实际取值返回就是[20,60]。
比如提取出来的4位首部长度是8,乘以基本单位4字节就是32字节,32字节减去固定的20字节还剩下12字节,说明剩下的12字节就是选项的长度。这样就可以读取整个TCP报头,那么剩下的就是数据了。那么如果今天TCP报头没有选项,TCP报头就只有20字节,那么对应的首部长度就是20/4=5。
2、TCP是如何分用的?
读取固定长度的前20个字节,报头中含有16位目的端口号,提取出16位目的端口号,就可以知道要将数据交付给上层的哪个进程。
下面来看一下Linux内核中的TCP报头结构体:
2.2、确认应答(ACK)机制
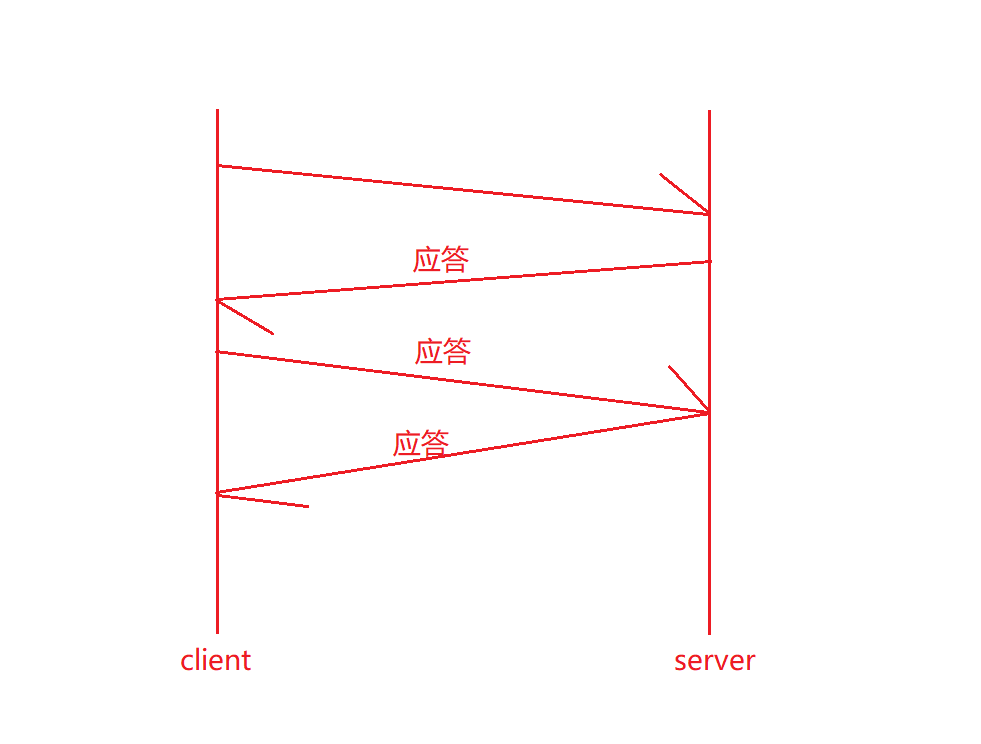
客户端给服务器发送数据,这个报文在网络上跑也是需要花时间的。那么客户端怎么知道我发出去的报文是否被服务端收到了呢?我发出去的报文是否因为某些原因丢失了呢?客户端是无法得知的。因此就需要服务端对客户应答,当服务端接收到客户端发送的报文后,需要对客户端做应答。
同样的,服务端给客户端发数据,客户端也需要应答,这种策略就是确认应答机制。
那么服务端给客户端作应答,表示我收到你发给我的报文了,那么服务端如何得知客户端是否收到我的应答呢?所以就需要客户端对服务端的应答继续做应答,然后客户端又需要知道服务端是否接收到我的应答,所以又需要服务端继续做应答。那么如果这样就会陷入了死循环。我们发现长距离通信的时候,其实没有100%的可靠性!因为总有一条最新的消息是没有应答的!
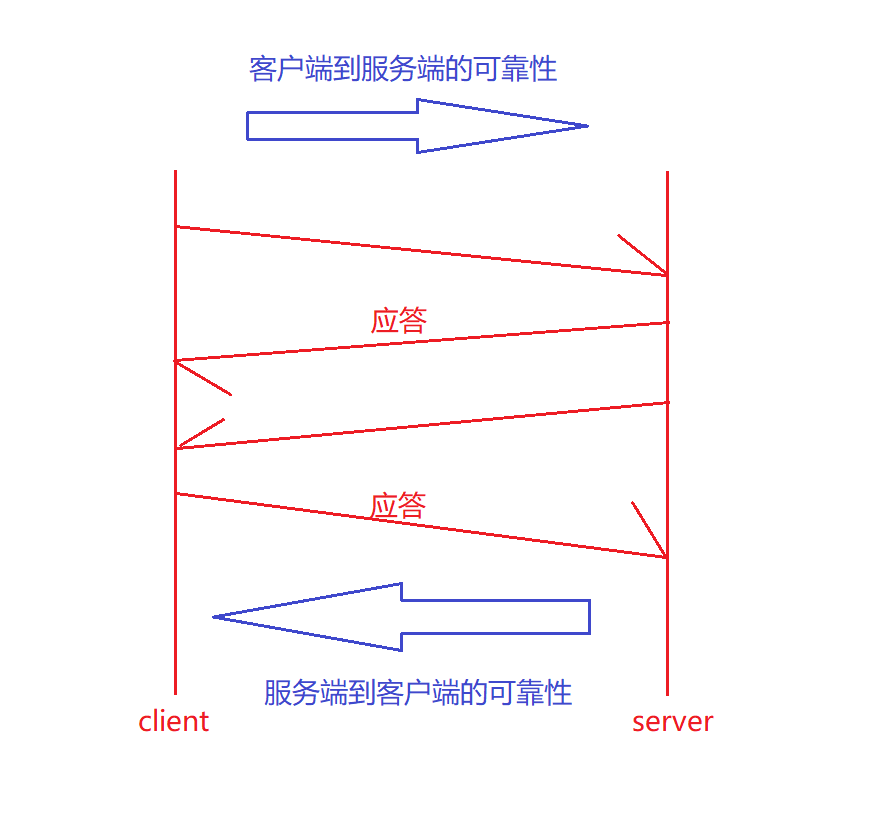
当客户端给服务端发送数据后,服务端接收到数据需要对客户端做应答,那么此时服务端就不再关心我的应答是否被客户端接收到了,因为是客户端要操心我的数据服务端有没有接收到。当客户端接收到应答就说明我之前发送的数据服务端接收到了,保证了老的消息是可靠的,保证了客户端到服务器的可靠性,不需要再对服务端的应答做应答了。如果客户端没有接收到应答,那么可能是服务端没有接收到数据,也可能是服务端的应答丢失了,这时候客户端会再去问服务端的。
所以老消息是有应答的,保证100%可靠。
那么此时从客户端到服务端就是可靠的。同样的,服务端给客户端发送数据,客户端也需要做应答,如此一来,也保证了服务端到客户端的可靠性。
所以TCP是可靠的,它的核心协议就是确认应答。
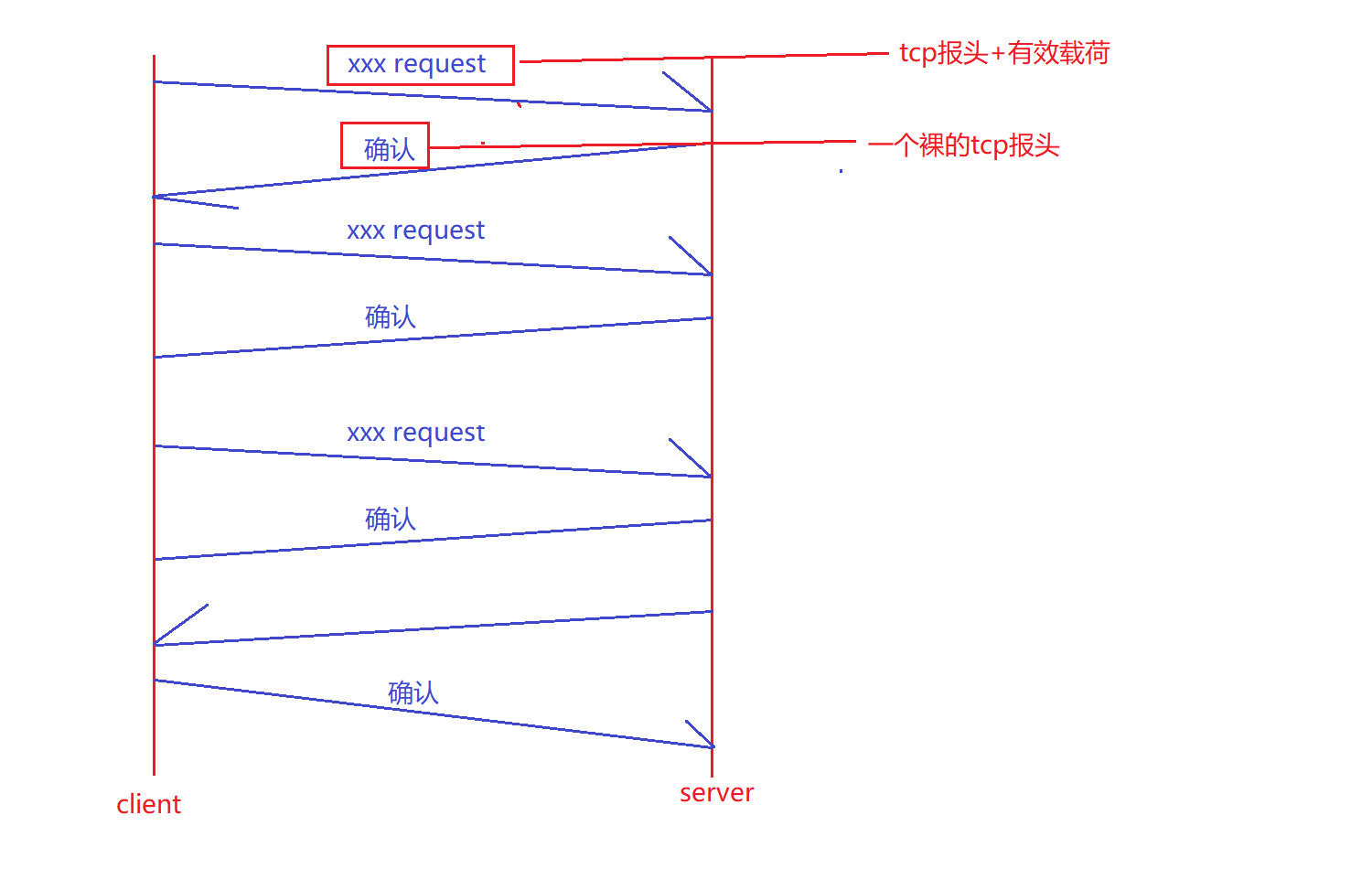
所以现在客户端发送request,服务端就需要确认应答。同样的,服务端给客户端发送数据,客户端也需要对服务端做应答。
此时客户端给服务端发送的request是TCP报头+有效载荷,也就是一个完整的报文。而服务端给客户端的确认应答是一个裸的TCP报头。所以双方在发送数据的时候,至少都要有一个报头。
再谈序号和确认序号:
上面我们的通信方式是:客户端给服务端发送消息,然后服务端做应答,客户端接收到确认应答后然后再给服务端发送数据。这种通信方式是串行的,这是我们第一阶段的认识,那么这种通信方式效率就很低。
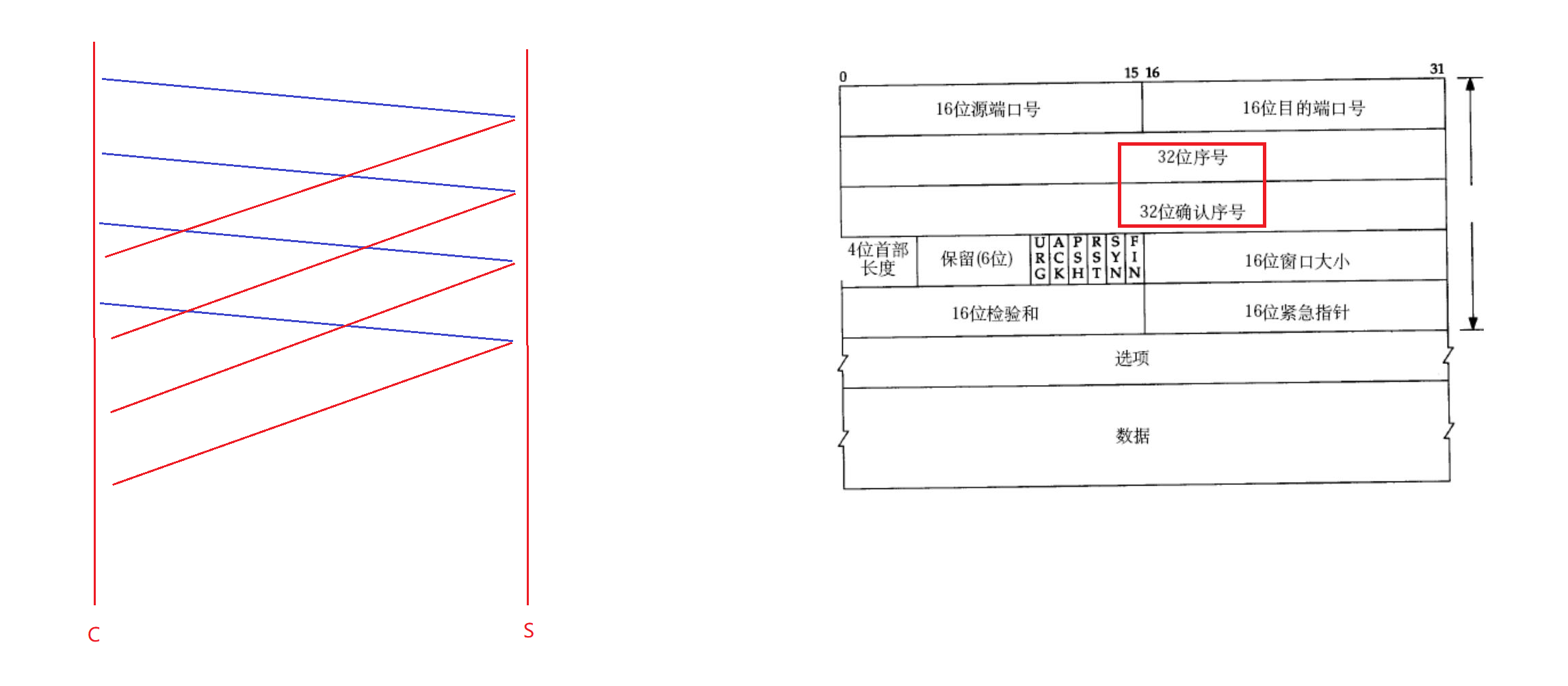
实际上,客户端会给服务端发送一批报文,比如上图客户端C给服务端S发送了四个报文,而每个报文都需要做应答,因此服务端在接收到报文后再给客户端做应答,每一个报文都要有应答。通过这种方式,既可以保证可靠性同时又提高了效率。但是问题是,服务端给客户端应答,如果客户端只收到了三个应答,那么客户端如何得知这三个应答针对的是哪三个报文呢?
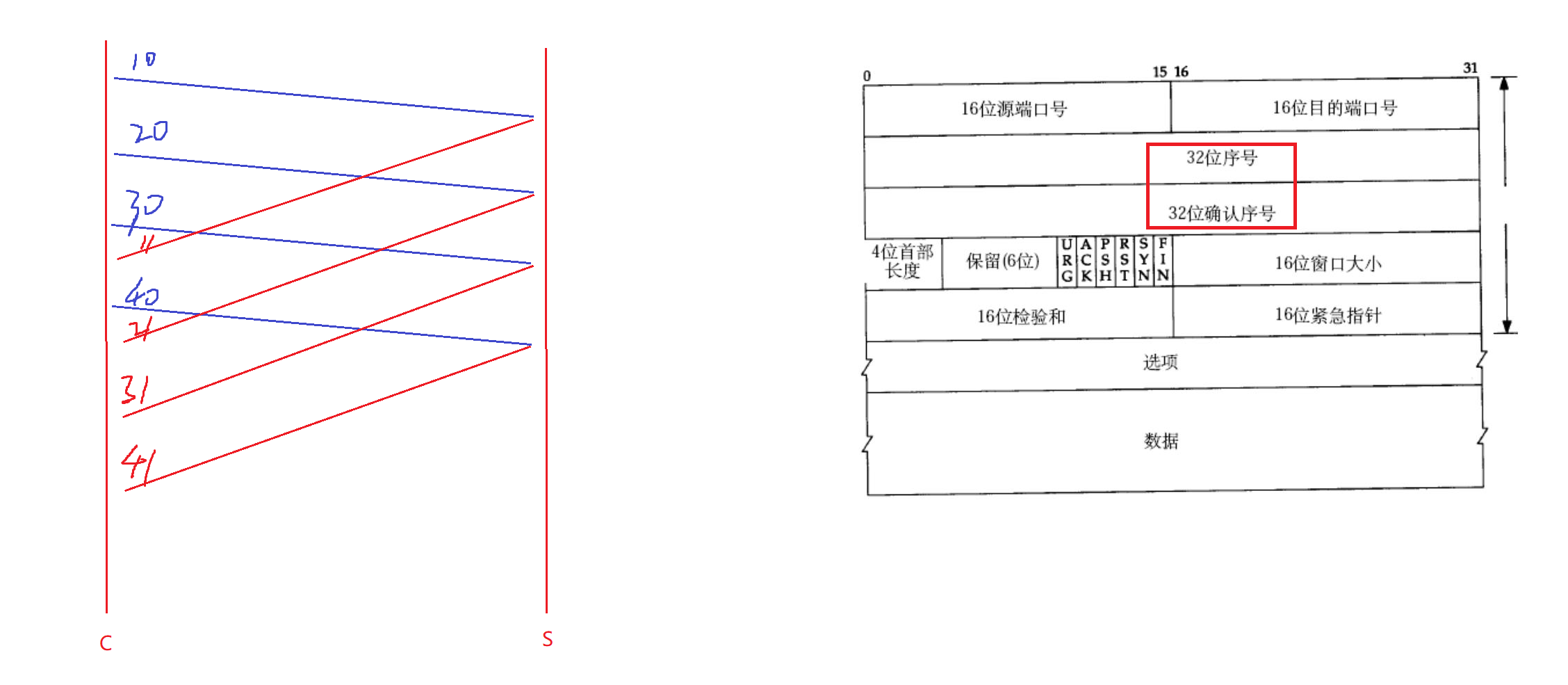
因此客户端给服务端发送数据的时候,需要给每个报文带上编号,这个编号就是序号。比如客户端给服务端发送的四个报文编号分别为10、20、30、40。将来服务端给客户端确认应答的时候,应答往往是收到的报文序号的值再加1,比如服务端收到客户端发送的编号位10的报文,将来应答的就是11,收到20,应答就是21。所以给报文带上序号,就可以对报文进行区分了。
服务端给客户端返回的序号称为确认序号,确认序号=序号+1。表示序号之前的内容已经全部收到了。
比如客户端给服务端发送的报文序号为10,服务端收到后给客户端作应答,确认序号为11。客户端再收到服务端的应答后就知道,11号之前的内容对方已经全部收到了。
报文携带序号还有另外一个意义。当客户端给服务端发送报文,比如按照10、20、30、40的顺序进行发送的,但是服务端在接受的时候并不一定是按照10、20、30、40的顺序接收的。因为网络可能存在各种各样的情况,所以可能后发送的先到了,先发送的反而后到。而报文如果是乱序的,也是不可靠的表现。因此就需要根据序号来对接收到的报文进行排序。
服务端在接收到报文后可以根据报文的序号进行升序排序,这样就保证了服务端缓冲区的报文是有序的。
为什么要有两个序号?
服务端接收到客户端发送的数据,比如对应的报文序号为10,那么服务端直接设置序号11给客户端返回做确认应答就好了,也就是说它们使用一个序号不就可以了吗,为什么要有序号和确认序号呢?
服务端在给客户端做应答的时候,如果只是单纯的应答,那就是裸的TCP报头,但是有没有可能服务端也要给客户端发送数据呢?当然是有可能的,那么这时候服务端给客户端发送的就是一个报文,这个报文既是对客户端之前发送数据的应答,同时也给客户端发送数据。这种情况称之为捎带应答机制。TCP报文在很大的概率上,既是应答,又是数据。
所以这时候就需要序号和确认序号了,确认序号用来表示之前客户端给我发送的数据我服务端接收到了,同时我也要给客户端发送数据,所以也要给报文设置序号,方便将来客户端做应答。那么将来客户端如果还要发送数据,那发送的报文就是既是应答也是数据,如果没有数据要发送了,那就是单纯的应答。
因此,在TCP通信中,大部分情况下报文既是应答,又携带了数据。这才是真实的TCP通信。
再谈16位窗口大小:
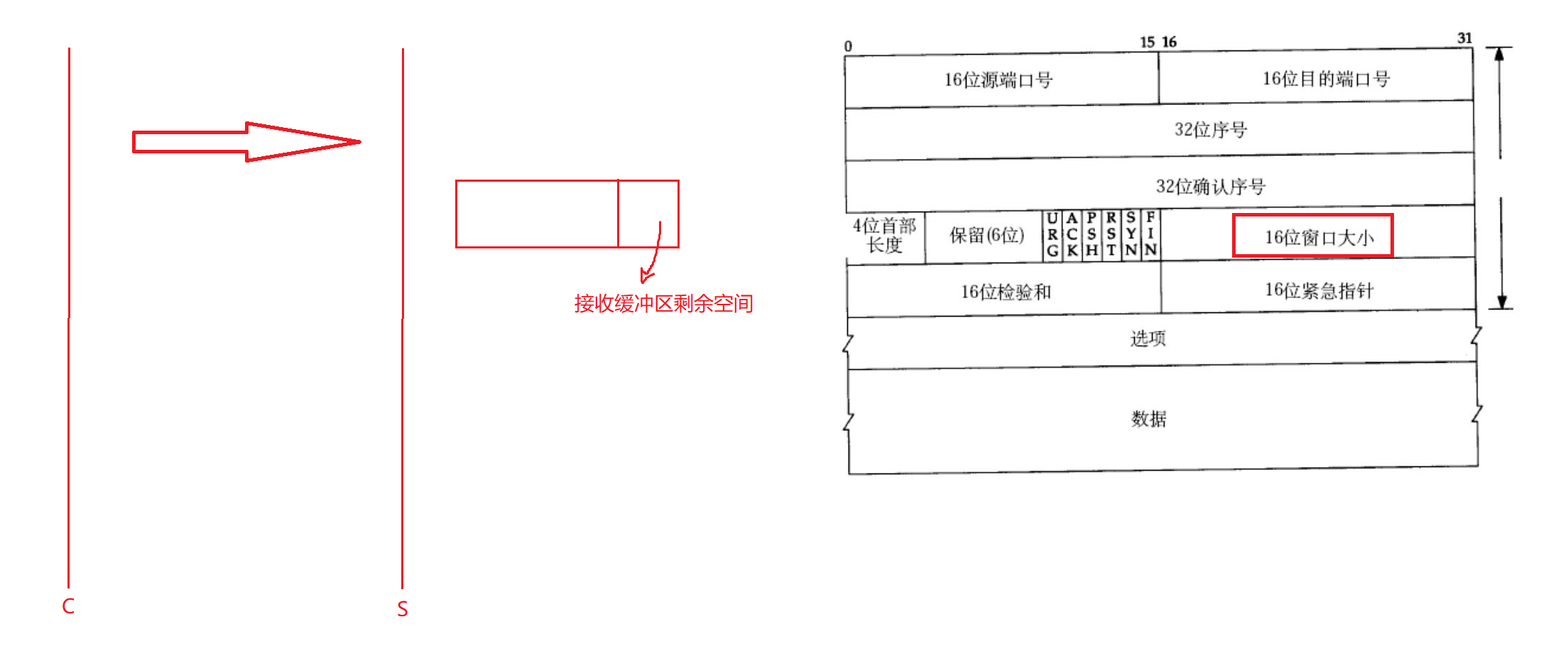
如果对方来不及接收数据呢?
客户端给服务端发送数据,假设服务端接收缓冲区有100字节,现在已经有80字节的数据了,还剩下20字节的数据。服务端上层还在进行数据的处理,来不及将这80个字节的数据取走,如果这时候客户端再给服务端发送一大批数据的话,那么接收缓冲区就会满,满了服务端就接收不了数据了,因此服务端就会将报文直接丢弃。那么这种做法当然是可以解决的,如果服务端直接将报文丢弃,就不会给客户端做确认应答,因此客户端没有接收到确认应答就会重新给服务端发送报文。
但是操作系统不做浪费时间,浪费空间的事情。
客户端今天发送了一个报文,这个报文经过网络千里迢迢到达了服务端,占用了各种网络资源,结果服务端直接就丢弃了,那不就

详细教程)

系统软件部署全攻略:Redis、RabbitMQ、MySQL 等集群搭建指南)






与持续检测键盘按键(Input.GetKey))



)




)