一、Mysql组织架构
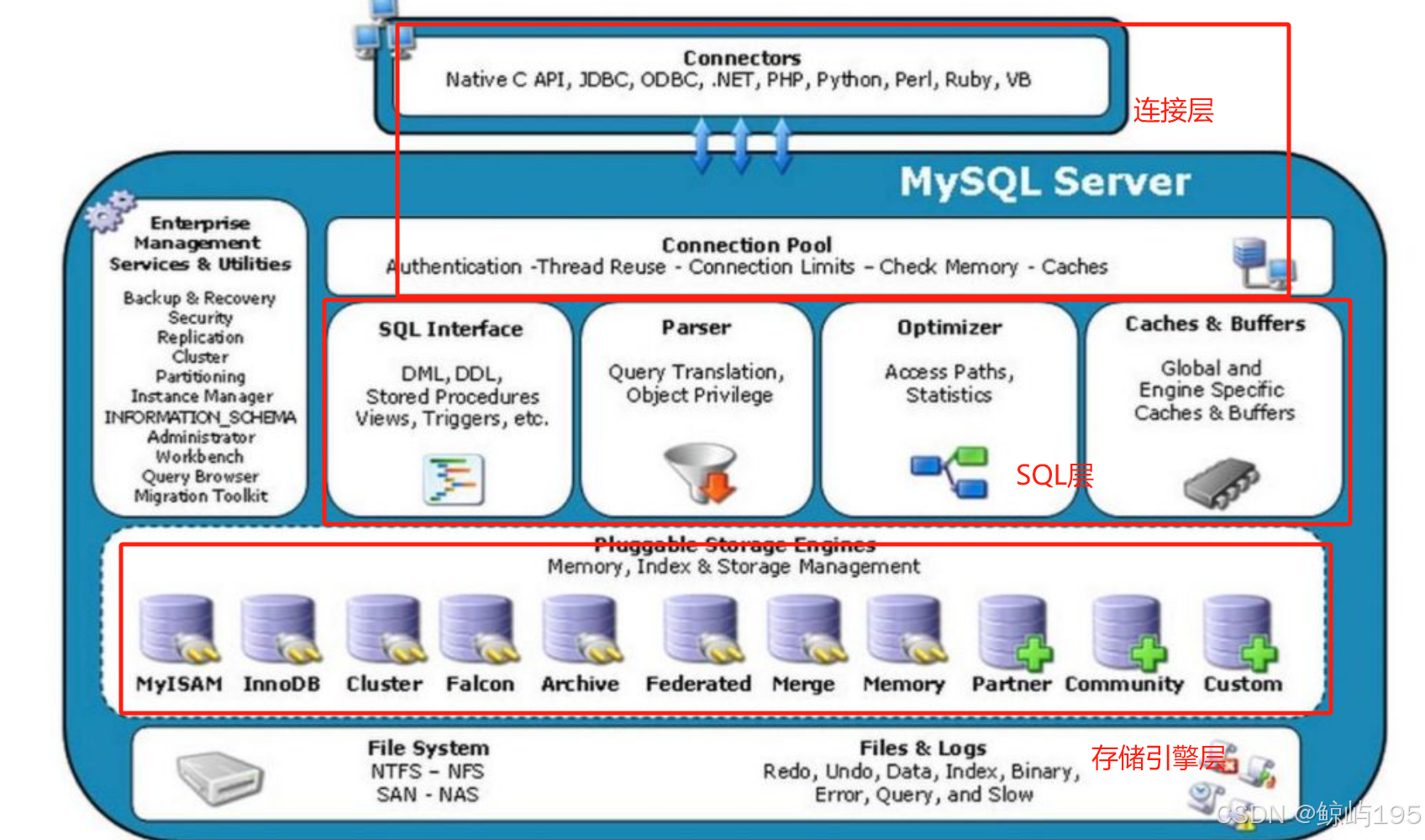
连接层
1.验证用户的身份,用户名密码是否匹配
2.提供两种连接方式(TCP/IP连接、socket连接)
3.连接层提供了一个与sql层交互的线程
SQL层
1.接收连接层传过来的SQL语句
2.验证执行的SQL语法
3.验证SQL的语义(DDL,DML,DQL,DCL)
4.解析器:解析SQL语句,生成执行计划
5.优化器:将解析器传来的执行计划选择最优的一条执行
6.执行器:将最优的一条执行
6.1 与存储引擎层建立交互的线程
6.2 将要执行的sql发给存储引擎层
7.如果有缓存,则走缓存
8.记录日志(如binlog)
存储引擎层
1.接收SQL层传来的语句
2.与磁盘交互,获取数据,返回给sql层
3.建立与sql层交互的线程
mysql数据库服务端-----》innodb存储引擎
操作系统------------》文件系统
计算机硬件----------》硬盘
二、存储引擎
定义
存储引擎------说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法,专门处理其对应的类型的表。
存储引擎决定了表的类型
存储引擎---------表
视频播放---------mp4
文本编辑器-------txt
#InnoDB 存储引擎 ----默认在内存中已经建立了自适应的hash索引
#MyISAM 存储引擎
只是读取和插入,不支持事务、表级锁设计、支持全文索引,不支持故障自动恢复,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。 (.frm表结构 .MYD表数据 .MYI表索引)
#Memory 存储引擎
正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。
#Infobright 存储引擎
第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。
#BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
innodb存储引擎概述(默认)
----------------三大特性
事务
行级锁:innodb支持行级锁,myisam是表级锁,锁的粒度越小并发能力越强(一次只运行一个,保障安全性)
支持外键MVCC 多版本并发控制
备份和恢复 innodb支持支持热备,myisam不支持
自动故障恢复 (CSR) Crash Safe Recovery[root@egon db1]# cd /var/lib/mysql/db1/
[root@egon db1]# ls
db.opt innodb_t1.frm innodb_t1.ibd innodb_t2.frm innodb_t2.ibd### .frm表的元数据文件(表结构) .ibd表的数据文件+索引文件
查看
MariaDB [(none)]> show engines\G #查看所有支持的存储引擎
MariaDB [(none)]> show variables like 'storage_engine%'; #查看正在使用的存储引擎#查看使用innodb的表有哪些
# table_schema字段的值即表所在的库
select table_schema,table_name,engine from information_schema.tables where engine='innodb';#mysql5.6以后默认使用innodb存储引擎
使用
1、建表时,使用不同的存储引擎
create table t1(id int)engine=blackhole;
create table t2(id int)engine=memory;
create table t3(id int)engine=myisam;
create table t4(id int)engine=innodb;
2、修改配置文件指定默认的存储引擎
/etc/my.cnf
[mysqld]
default-storage-engine=INNODB #指定
innodb_file_per_table=1 # 让每个表都有自己独立的的ibd文件,如果不指定的话,所有表 的数据文件都会集中在/var/lib/mysql/ibdata1这个共享数据文件中
案例:升级存储引擎
- 准备工作----一台新机器
源码包安装,二进制安装# 配置yum源
[mysql56-community]
name=MySQL 5.6 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.6-community/el/7/$basearch/
enabled=1
gpgcheck=0# 获取mysql5.7初始密码
grep "temporary password" /var/log/mysqld.log# 设置密码,密码已经不能再用弱密码了,弱密码会报错
set password=password("Egon@123");- 在旧机器上备份生产库数据
# –triggers (默认导出触发器,使用–skip-triggers屏蔽导出)
# -R:–routines,导出存储过程以及自定义函数mysqldump -uroot -p123 -B db1 --triggers -R > /tmp/db1.sql- 处理备份数据(更改默认存储引擎)
[root@db01 ~]# sed -i 's#ENGINE=MYISAM#ENGINE=INNODB#gi' /tmp/db1.sql- 将备份的数据传到新的数据库服务器上并将修改后的备份恢复到新库
scp rsync 硬件设备 NFS
mysql -uroot -p123 < /tmp/db1.sql- 应用测试环境连接新库,测试所有功能
- 停止应用,将备份之后的生产库发生的新变化补偿到新库
- 应用切割到新数据库
Innodb逻辑架构
mysql数据库服务端---》innodb存储引擎--》用户态内存空间(应用程序的内存空间)
操作系统------------》文件系统--------》os cache(操作系统缓存)
计算机硬件----------》硬盘------------》硬盘结构(硬盘中的数据)
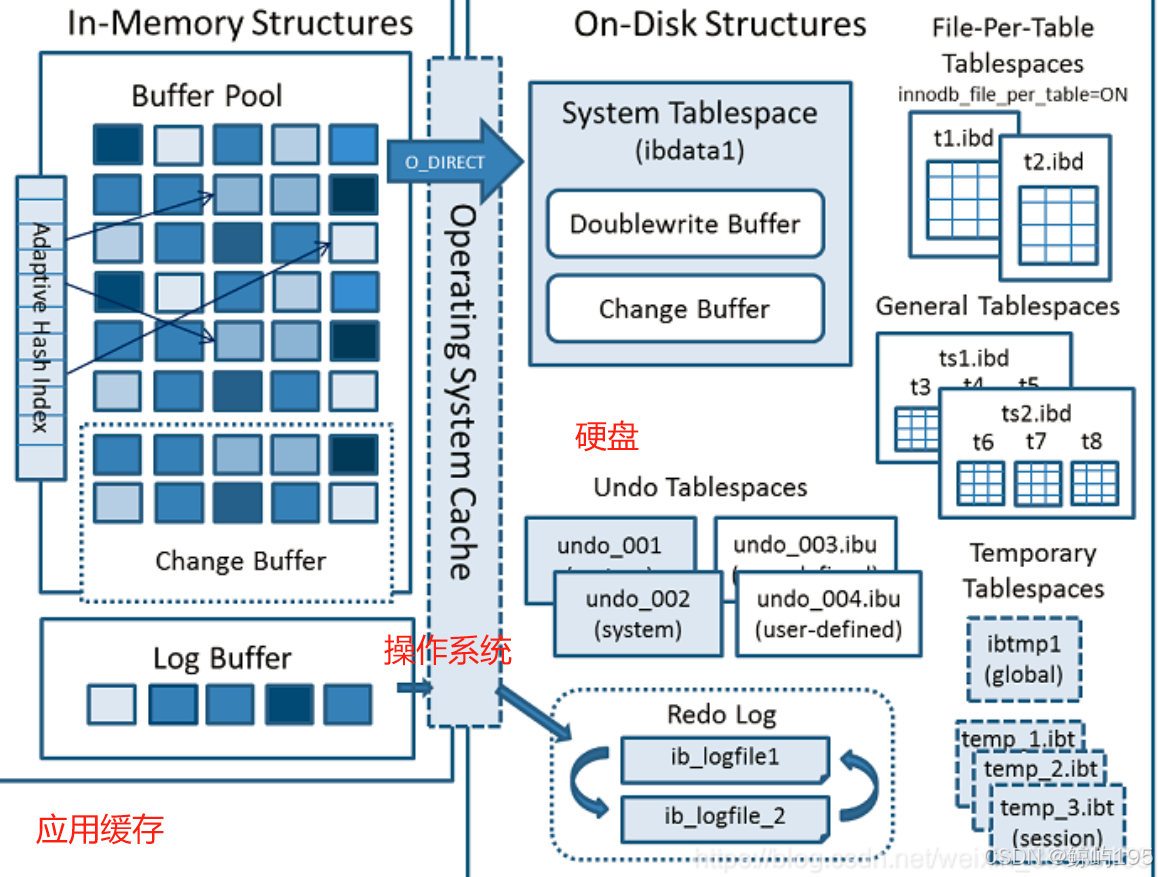
内存架构
innodb内存
- 缓冲池(优化读)
- 写缓冲(优化写)
- 日志缓冲
- 自适应哈希索引
操作系统缓存
为了提升性能而降低磁盘IO的次数(攒一波再写入),在InnoDB的缓存体系与磁盘文件之间,加了一层操作系统的缓存/页面缓存。用户态innodb存储引擎的进程向操作系统发起write系统调用时,在内核态完成页面缓存写入后即返回,如果想立即将页面缓存的内容立即刷入磁盘,innodb存储引擎需要发起fsync系统调用才可以。
两个系统调用(按一定频率配合使用):
- write:将数据写入操作系统的页面缓存后立即返回(存在丢失数据的风险)
- fsync:将数据立即提交到硬盘中,强制硬盘同步(大量进行会出现性能瓶颈)
O_DIRECT
选项是在Linux系统中的选项,使用该选项后,对文件进行直接IO操作,不经过文件系统缓存,直接写入磁盘
硬盘上的架构
- 表 文件----一堆二进制乱码
- 表空间 ibd文件
- 索引
- 双写缓冲:位于表空间,记录innodb缓存改动之前的数据
- redo日志:记录尚未完成的操作,断电则用其重做(崩溃恢复)
- undo日志:记录改动之前的旧数据,一旦改错可以回滚
### 默认情况下,创建InnoDB表的时候innodb_file_per_table参数是开启的,它表明用户创建的表和索引,会被以单表单文件的形式放入到file-per-table表空间中。如果禁用了该参数innodb_file_per_table,那么表及索引会被放入系统表空间(共享表空间)中
Innodb存储引擎执行流程
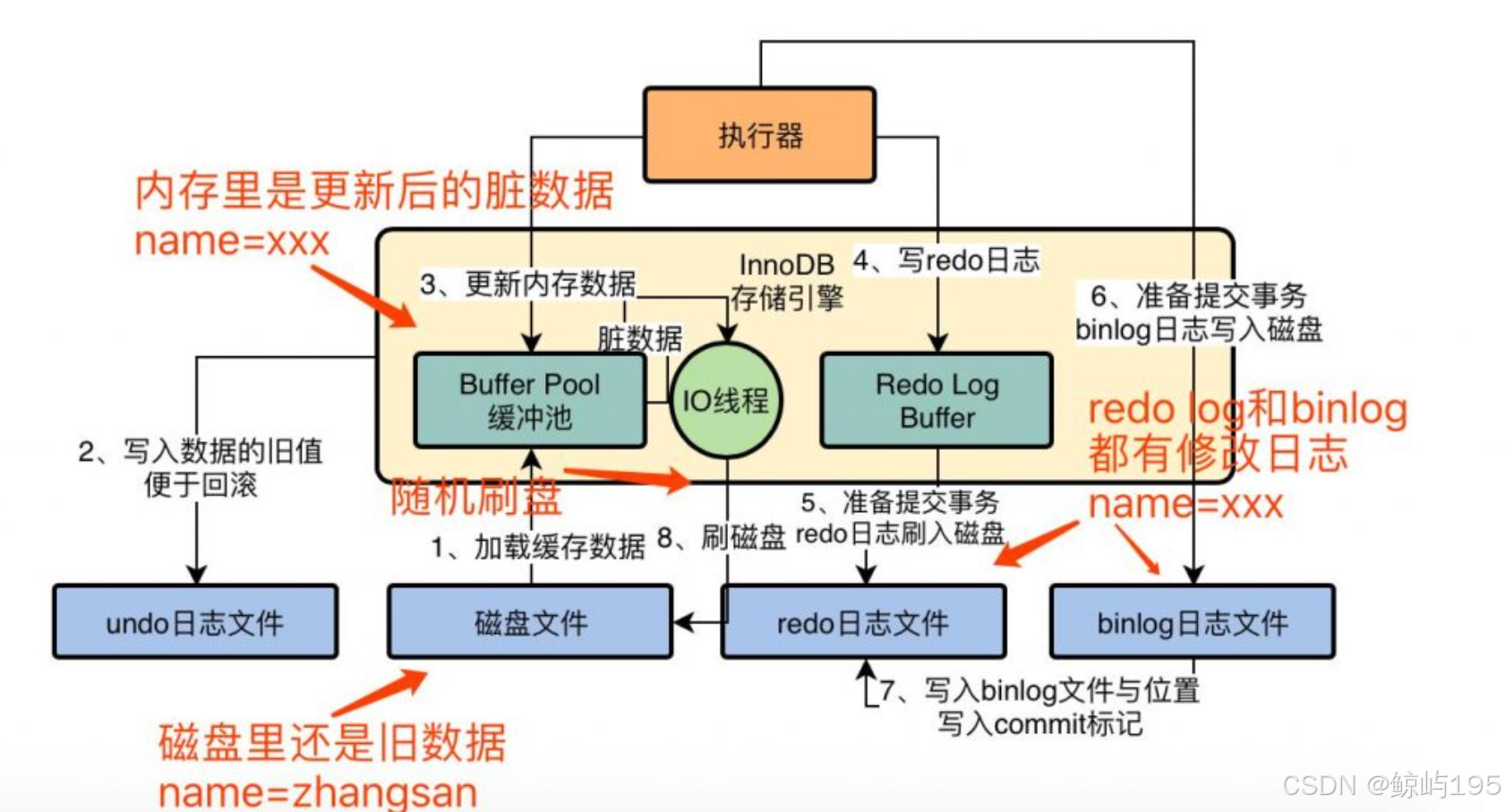
执行一条更新sql语句------三大阶段,8小步骤
- 执行阶段
数据加载到内存,写undo log,更新内存中的数据,写redo log buffer - 事务提交阶段
redo log 和 binlog 刷盘,commit标记写入redo log 中 - 最后
后台io线程随机把被内存中的脏数据刷到磁盘上
- 把该行数据从磁盘加载到buffer pool 中,并对该行数据进行加锁
- 把旧数据写入undo log以便修改出错的情况下进行回滚
- 在buffer pool 中的数据更新,得到脏数据
- 将修改后的脏数据写入redo log buffer中
- 准备提交事务,redo log 刷入磁盘
- 把修改的操作记录准备写入binlog日志(事务提交时)
- 把binlog的文件名和位置写入commit标记,commit标记写入redo log 中(redo log 中存放的修改后的数据与binlog中的修改操作对应上,双管齐下),事务的提交才算成功,否则不会成功
- IO线程buffer pool 中的脏数据刷入磁盘文件,完成最终修改
补充:
- redo接受脏数据(改动后的数据)-----先放到缓冲区再放到磁盘
binlog接受详细改动操作的信息-----直接写入磁盘 - 第八步IO操作最耗时间
- innodb_flush_log_at_trx_commit参数(redo log刷盘策略)
1 默认值,事务提交时必须把redo log从内存刷入磁盘(安全性最高,最耗时)
0 等待innodb主动执行刷新磁盘(风险最高)
2 直接把日志放到操作系统缓存,等待操作系统刷新磁盘(mysql挂了机器没挂数据不会丢失) - sync_binlog参数(binlog刷盘策略)
0





与持续检测键盘按键(Input.GetKey))



)




)

结构体、共用体、枚举、typedef关键字与位运算)


——visualize_dataset_html.py/visualize_dataset.py)