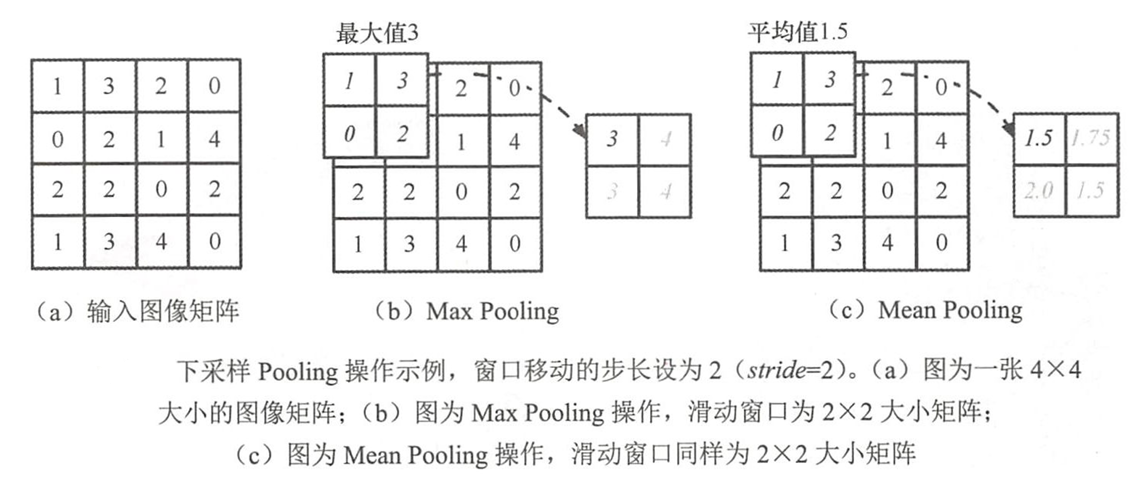
卷积神经网络的网络结构中,卷积层后接 P o o l i n g Pooling Pooling层。输入为 4 × 4 4×4 4×4大小的图像矩阵,卷积层参数为 ( p a d d i n g = s a m e , k e r n e l = 2 ) (padding=same,kernel=2) (padding=same,kernel=2),卷积层后输出特征矩阵大小为 [ 2 , 4 , 4 ] [2,4,4] [2,4,4]。(卷积层有n个卷积核对应输出有n个特征图)
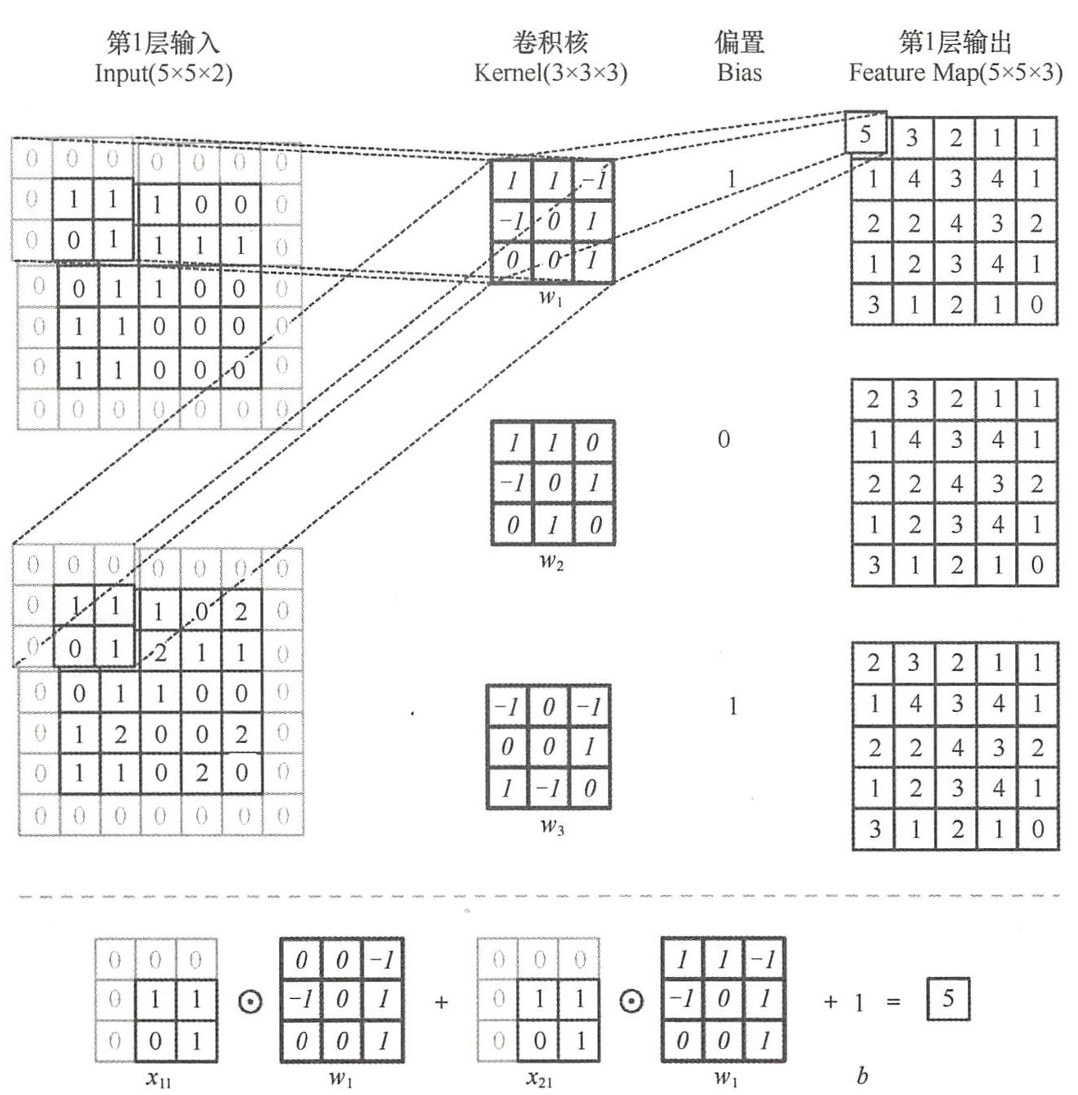
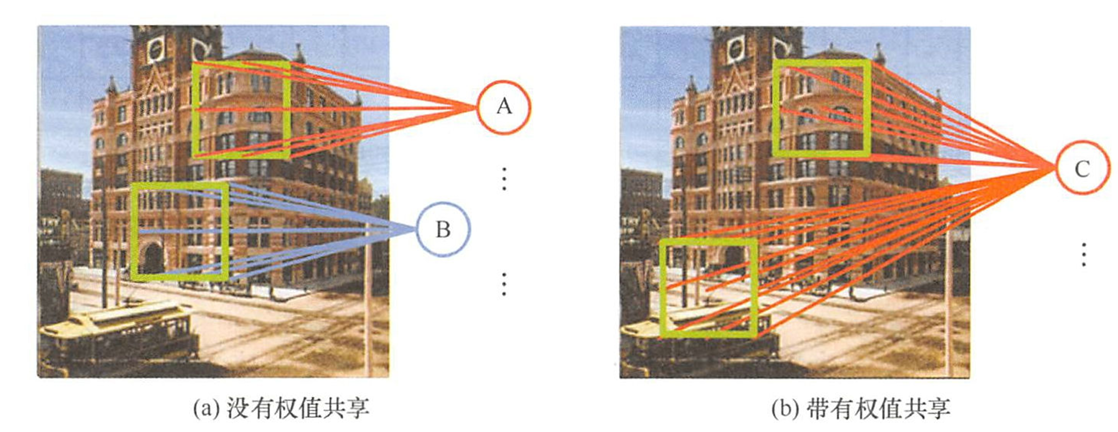
假设卷积层输入为一张4×4大小的图像矩阵(对应输入神经元有 16 (4×4)个〉,设定卷积核为2,经过卷积操作后产生2个4×4大小的特征图(对应输出特征神经元有32(2×4×4)个)。其中,卷积核大小为3×3(一个卷积核由9个神经元组合而成),即对应的权重参数连接线有18(2×3×3)条,输入神经元与特征神经元连接线均带有权值参数 w i w_i wi和偏置 b i b_i bi,而该权值参数则由卷积核组成。
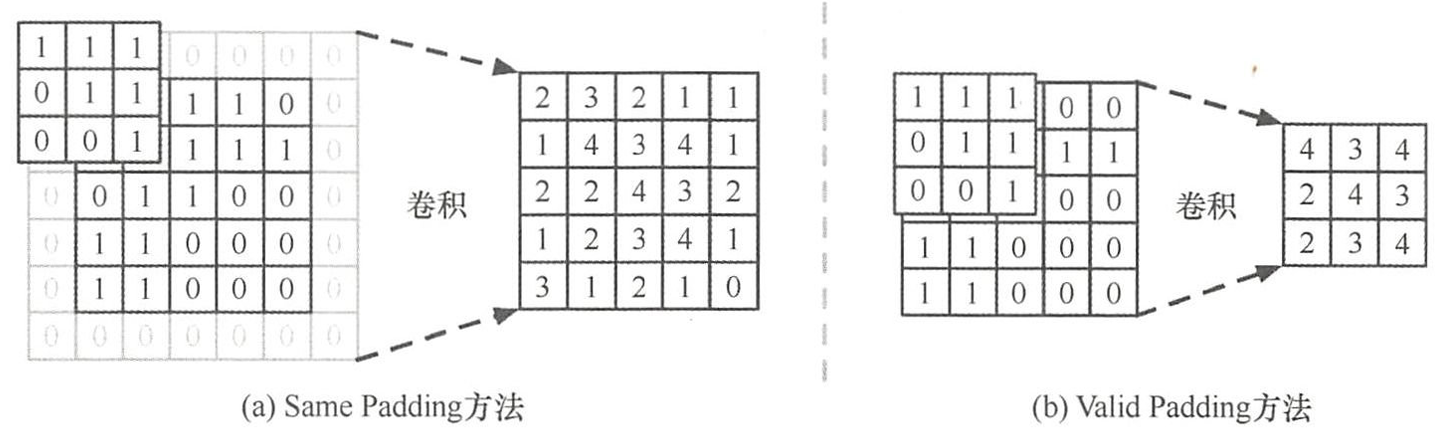
Same Padding是根据卷积核大小,对输入图像矩阵进行边界补充(一般填充零值),使得卷积后得到的特征矩阵与输入矩阵大小一致。避免边界信息被忽略,把边界信息纳入神经网络的计算范围内,否则随着神经网络层的深入,图像边缘信息的损失也会逐渐增大。
Valid Padding实际上不需要进行Padding操作
自定义Padding生成的特征图大小根据下式计算而来。 o u t p u t h = ( i n p u t h + 2 × p a d d i n g h − k e r n e l h ) / s t r i d e + 1 o u t p u t w = ( i n t p u t w + 2 × p a d d i n g w − k e r n e l w ) / s t r i d e + 1 o u t p u t 为输出矩阵, i n p u t 为输入矩阵, p a d d i n g 为边界填充数量 k e r n e l 为卷积核大小, s t r i d e 为步长大小, w 为操作矩阵的宽, h 为操作矩阵的长 output_h=(input_h+2\times padding_h - kernel_h)/stride+1 \\ output_w=(intput_w+2\times padding_w - kernel_w)/stride+1 \\ output为输出矩阵,input为输入矩阵,padding为边界填充数量 \\ kernel为卷积核大小,stride为步长大小,w为操作矩阵的宽,h为操作矩阵的长 outputh=(inputh+2×paddingh−kernelh)/stride+1outputw=(intputw+2×paddingw−kernelw)/stride+1output为输出矩阵,input为输入矩阵,padding为边界填充数量kernel为卷积核大小,stride为步长大小,w为操作矩阵的宽,h为操作矩阵的长
Padding操作的两种主要方式,如图(a)输入 5 × 5 5\times 5 5×5的图像矩阵。卷积核大小为 3 × 3 3\times 3 3×3。Same Padding方法设置padding参数为 1 1 1,使卷积的输出与输入矩阵大小一致。图(b) V a l i d P a d d i n g Valid Padding ValidPadding方法设置 p a d d i n g padding padding参数为 0 0 0,使得输出特征矩阵比输入矩阵要小。
一般默认卷积操作中使用 Same Padding 方法。通过对输入图像矩阵的边缘填充零像素值,使得输入的图像经过卷积后得到的特征矩 阵大小与输入的原图大小一致。
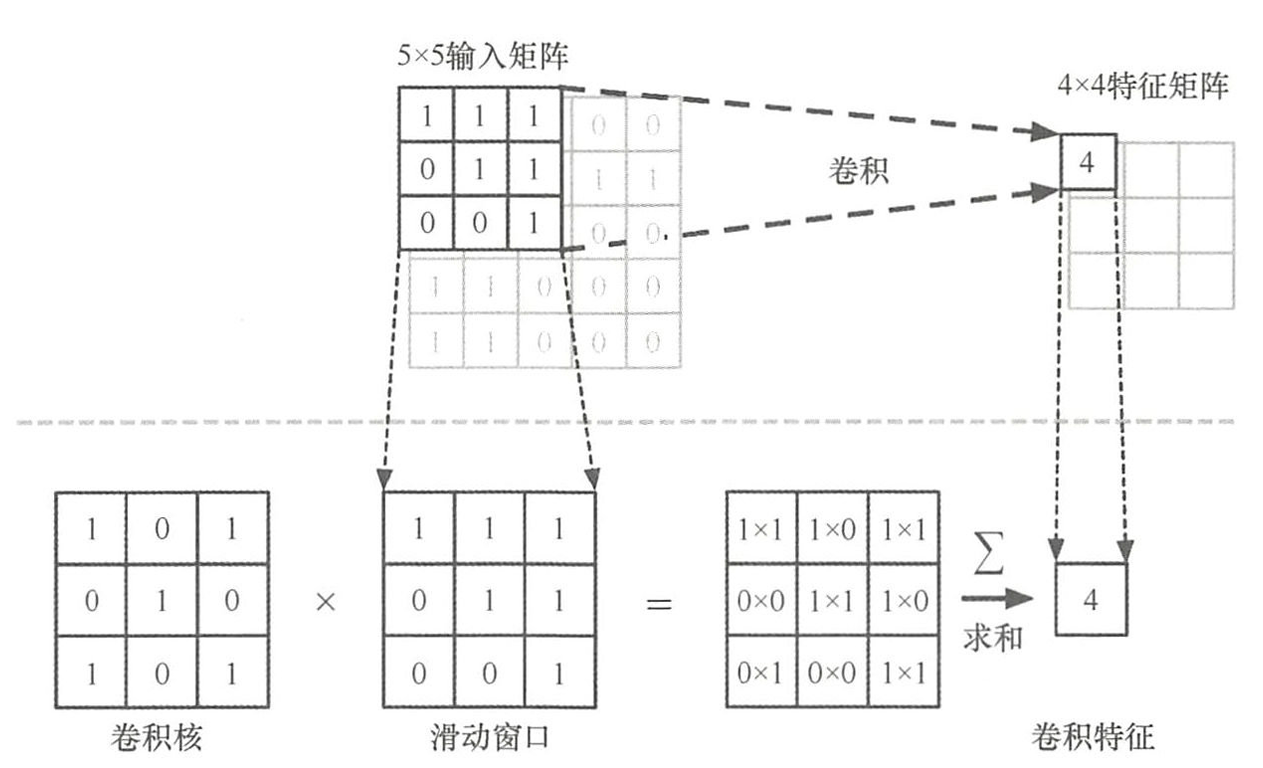
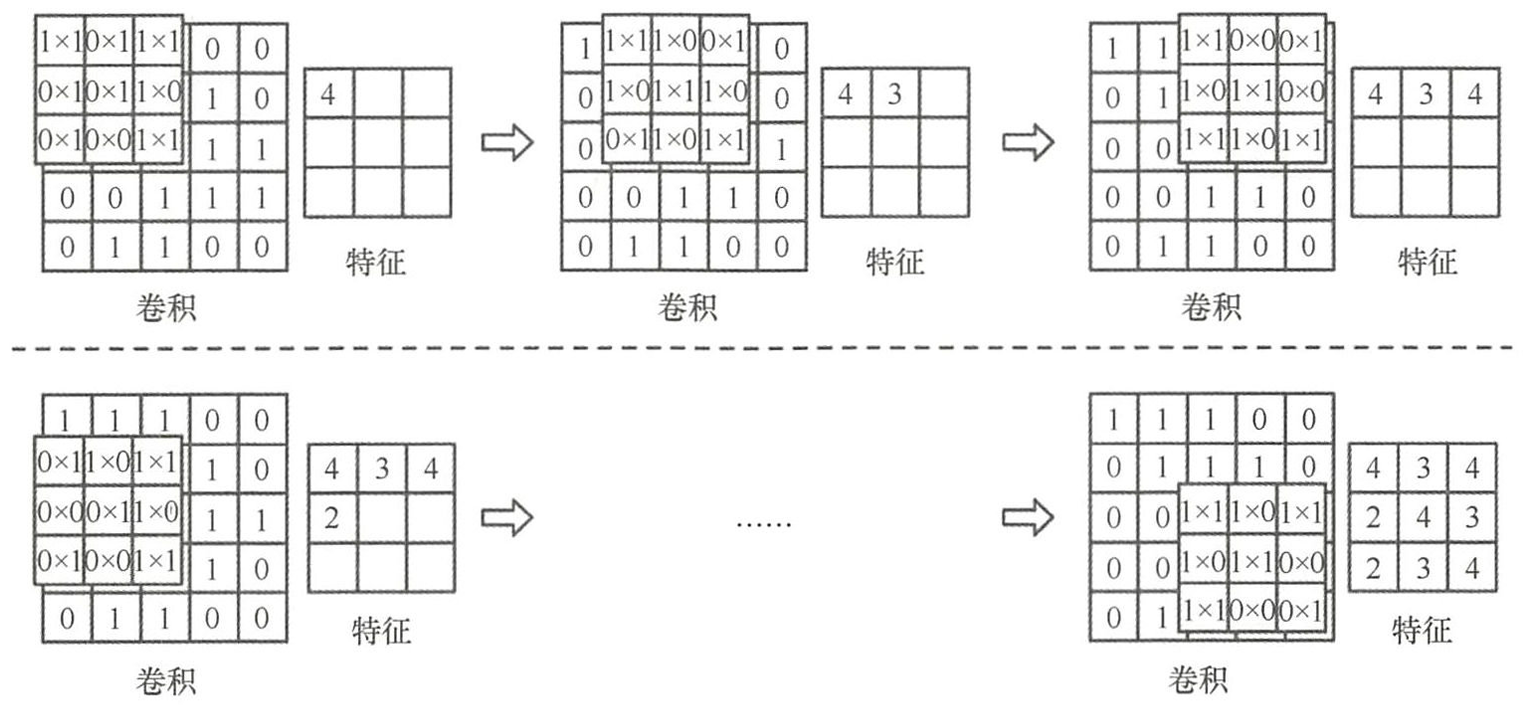
假设一个卷积核窗口在输入图像上滑动,滑动窗口每次移动的步长为 stride,那么每次滑动窗口后,把求得的值按照空间顺序组成一个特征图。该特征图的边长分别为: f e a t u r e m a p w = ( i m g w − k e r n e l w ) / s t r i d e + 1 f e a t u r e m a p w = ( i m g w − k e r n e l h ) / s t r i d e + 1 f e a t u r e m a p 为特征图矩阵的大小, i m g 为输入图像大小 k e r n e l 为卷积核大小, s t r i d e 为步长大小, w 为矩阵的宽, h 为矩阵的长。 feature map_w = (img_w - kernel_w) / stride +1 \\ feature map_w =(img_w - kernel_h) / stride+1 \\ feature map为特征图矩阵的大小,img为输入图像大小 \\ kernel为卷积核大小,stride为步长大小,w为矩阵的宽,h为矩阵的长。 featuremapw=(imgw−kernelw)/stride+1featuremapw=(imgw−kernelh)/stride+1featuremap为特征图矩阵的大小,img为输入图像大小kernel为卷积核大小,stride为步长大小,w为矩阵的宽,h为矩阵的长。
网络卷积层操作
在第 l l l层网络有 C C C个特征图作为输入,该卷积层有 k k k个卷积核,如何进行卷积操作产生 k k k个输出特征矩阵?
假设在第 l l l层卷积层输入为C个特征图,即该层输入C个矩阵,C个矩阵的大小均为 W × H W \times H W×H,可以得到一个 C × ( W × H ) C \times (W \times H) C×(W×H)的特征张量, C C C又称为输入矩阵的深度。该层设定有 C o u t Cout Cout个 K × K K \times K K×K大小卷积核,在使用 S a m e P a d d i n g Same Padding SamePadding的情况下将会产生 C o u t Cout Cout个大小为 W × H W \times H W×H的特征图作为输出,即可得到 C o u t × ( W × H ) Cout \times (W \times H) Cout×(W×H)的特征张量作为输出。
多层卷积操作类似于神经元的基本求和公式 z = ∑ w x + b z=\sum wx+b z=∑wx+b,卷积神经网络中 w w w对应单个卷积核, x x x为对应输入矩阵的不同数据窗口, b b b为该卷积核的偏置。这相当于卷积核与一个个数据窗口相乘求和后(矩阵内积计算),加上偏置b得到输出结果。 z = x 11 ⊙ w 1 + w 21 ⊙ w 1 + b = ( x 11 + x 21 ) ⊙ w 1 + b \begin{align*} z &=x_{11} \odot w_1+w_{21} \odot w_1+b \\ &=(x_{11}+x_{21}) \odot w_1+b \end{align*} z=x11⊙w1+w21⊙w1+b=(x11+x21)⊙w1+b
使用Image to column ( Im2col)算法把输入图像和卷积核转换成为规定的矩阵排列方式。
使用GEMM算法对转换后的两个矩阵进行相乘,得到卷积结果。
Im2col算法
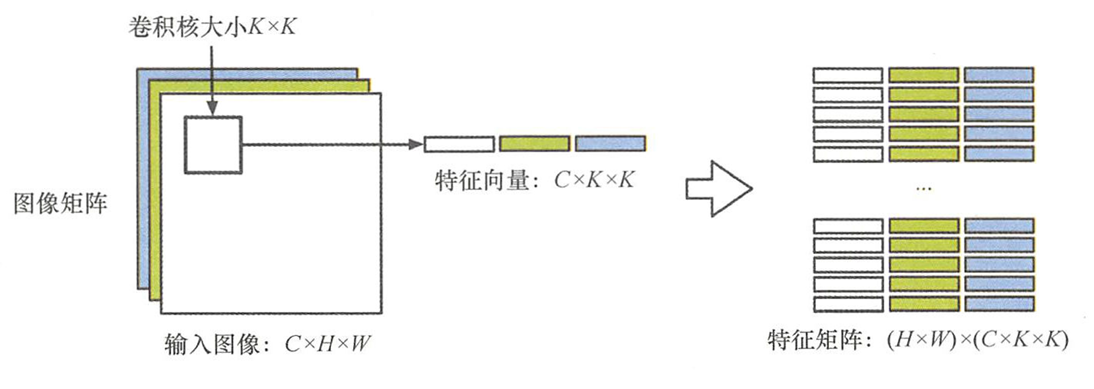
图像的Im2col操作:假设输入的图像大小为 C × H × W C \times H \times W C×H×W(其中H为图像的长, W W W为图像的宽, C C C为图像的深度)。卷积核的大小为 K × K K \times K K×K,那么对应输入图像中一个卷积窗口可以表示为 C × ( K × K ) C \times (K \times K) C×(K×K)的向量,即对输入图像中的某位置的数据按照卷积窗口进行从新排列,得到 C × ( K × K ) C\times (K \times K) C×(K×K)的特征向量。以步长为 1 ( s t r i d e = 1 ) 1 (stride=1) 1(stride=1) 从输入图像的左上角开始对原图进行特征转换,最终得到特征图大小为 ( H × W ) × ( C × K × K ) (H \times W)\times (C \times K \times K) (H×W)×(C×K×K)。
卷积核的Im2col操作:假设有 C o u t Cout Cout个卷积核,每个卷积核大小为 C × ( K × K ) C\times (K \times K) C×(K×K) ,把卷积核进行矩阵变换,得到单个卷积核的尺寸为 C × ( K × K ) C \times (K\times K) C×(K×K)。依此类推,最终得到 C o u t × ( C × K × K ) Cout \times (C \times K \times K) Cout×(C×K×K) 大小的过滤矩阵(Filter Matrix)。
一般矩阵乘法(General Matrix Matrix Multiply, GEMM)将由卷积核产生的过滤矩阵乘以原图产生的特征图矩阵(Feature Matrix)的转置,得到大小为 C o u t × ( H × W ) Cout \times (H \times W) Cout×(H×W)的输出特征图矩阵。 f e a t u r e m a p = F i l t e r M a t r i x ⋅ F e a t u r e M a t r i x T = [ ( C o u t × ( C × H × W ) ) ] ∗ [ ( ( C × H × W ) × ( H × W ) ) ] = C o u t × H × W \begin{align*} feature map &=Filter Matrix \cdot Feature Matrix^T \\ &=[(Cout\times (C \times H \times W))]^\ast [((C \times H \times W)\times(H \times W))] \\ &=Cout\times H \times W \end{align*} featuremap=FilterMatrix⋅FeatureMatrixT=[(Cout×(C×H×W))]∗[((C×H×W)×(H×W))]=Cout×H×W
本文提供一种解决 Buildroot SIGSTKSZ 报错途径
解决途径来源参考:Buildroot error when building with Ubuntu 21.10 其出现原因在于 GNU C Library 2.34 release announcement: Add _SC_MINSIGSTKSZ and _SC_SIGSTKSZ. When _DYNAMIC_STACK_SIZE_SOU…
VS-Assistant: Versatile Surgery Assistant on the Demand of Surgeons
➡️ 论文标题:VS-Assistant: Versatile Surgery Assistant on the Demand of Surgeons ➡️ 论文作者:Zhen Chen, Xingjian Luo, Jinlin Wu, Danny T. M. Chan, Zhen Lei, Jinqi…
目录
一、核心特点
二、原生 IP 的常见应用
三、原生 IP vs. 数据中心 IP
四、如何获取原生 IP?
五、原生 IP 的优缺点
六、实际案例 原生 IP(Native IP) 是指由互联网服务提供商(ISP)直接分配给用户的 IP 地址&…
在日常办公或学习中,我们经常需要将 Word 文档(.docx格式)转换为 PDF 文件。这不仅有助于保持文档格式的一致性,还能确保接收者无需特定软件即可查看文件内容。本文将详细介绍几种常见的方法来实现从 DOCX 到 PDF 的转换ÿ…



)


)


![[人机交互]理解界面对用户的影响](http://pic.xiahunao.cn/[人机交互]理解界面对用户的影响)


)


)




:如何创建一个地形)

