
传统的基于关键词匹配的聊天机器人难以理解用户复杂的、多意图的自然语言查询(例如,“我想下周从北京飞往上海,看看上午的机票,最好是不用太早起床的航班,并且帮我选一个靠过道的位置”),导致用户体验不佳,转而寻求人工客服,增加了企业的人力运营成本。
为了打造一个真正智能、专业的票务客服助手,我们计划利用大语言模型强大的自然语言理解和生成能力。然而,通用的开源大模型虽然具备广泛的常识,但缺乏票务领域的专业知识(如航线、座位偏好、退改签政策、行李额度等特定术语和流程),无法提供符合业务规范的准确回复。
因此,本项目旨在使用LLaMA-Factory这一高效微调框架,对一个通用的基座模型进行指令微调,无需复杂环境配置,只需上传数据集、设置训练参数,几分钟内就能打造出专属的“专业票务客服”模型。
👉Lab4AI一键体验
LLaMA-Factory是什么?
LLaMA-Factory整合主流的各种高效训练微调技术,适配市场主流开源模型,形成一个功能丰富、适配性好的训练框架,其在Github上已收获6万+Stars。使用 LLaMA Factory,您可以在本地微调数百个预训练模型,而无需编写任何代码。对个人开发者而言,这意味着不需要写一行代码,就能在网页端完成航空客服的训练。
👉GitHub项目地址
实践体验:亲手打造一个“会帮我订机票”的数字客服
在此项目中LLaMA-Factory提供了更灵活、更高效的框架,让训练过程更加可控、可视化,也为未来的多模态拓展(语音、图像等)奠定了基础。简单三步,就能让 AI 从“门外汉”变身为“专业票务客服”,你也快来试试吧!
👉Lab4AI一键体验
Step 1. 数据准备
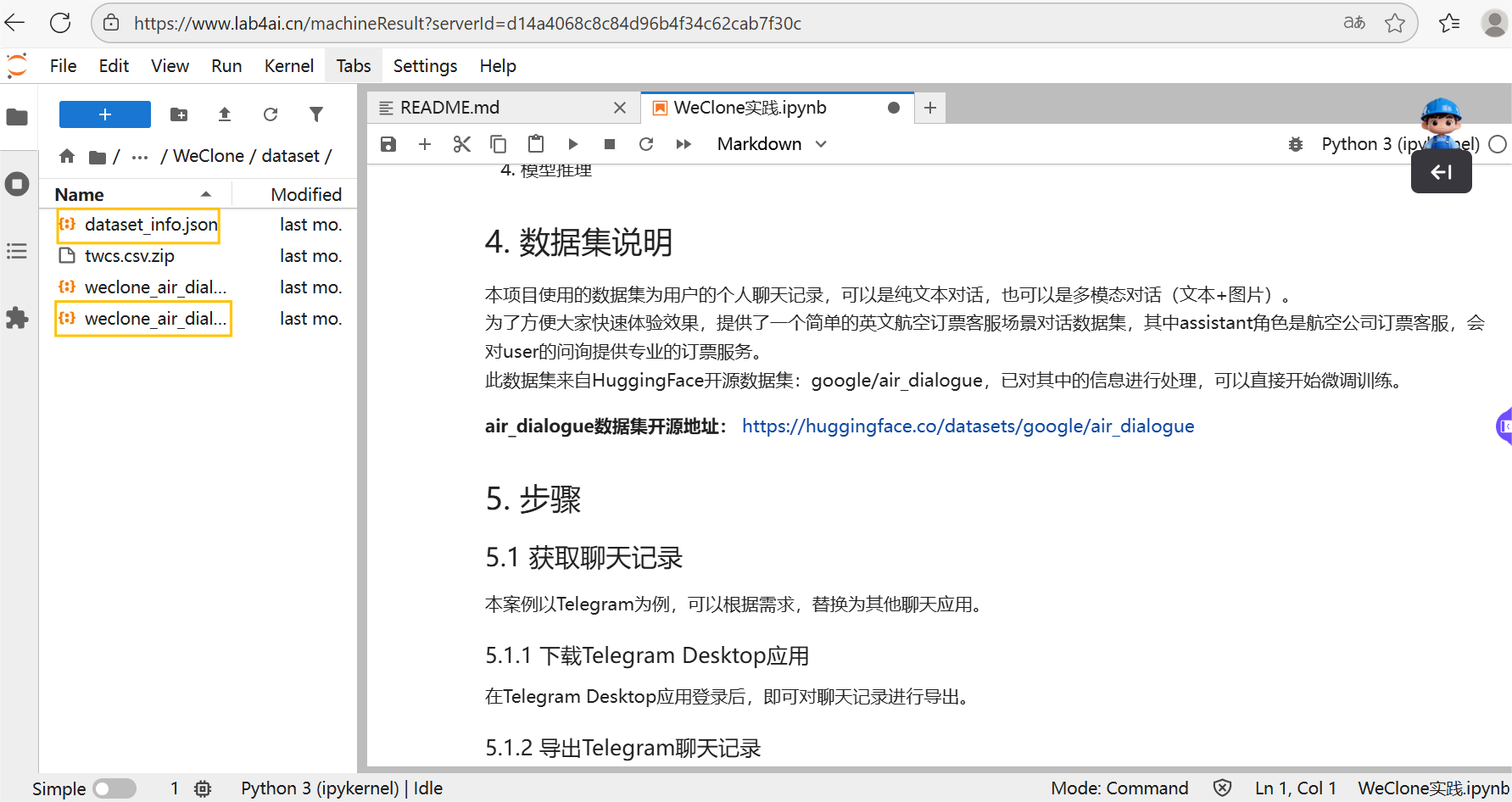
我们选用了Lab4AI中 「WeClone:从聊天记录创造数字分身的一站式解决方案」 的航空公司票务客服对话数据集,数据格式为sharegpt,无需额外处理,可直接适配LLaMA系列模型的调试需求。您通过本地下载数据集后,通过 SFTP上传至服务器(上传操作可参考官方文档,内附详细教学)。
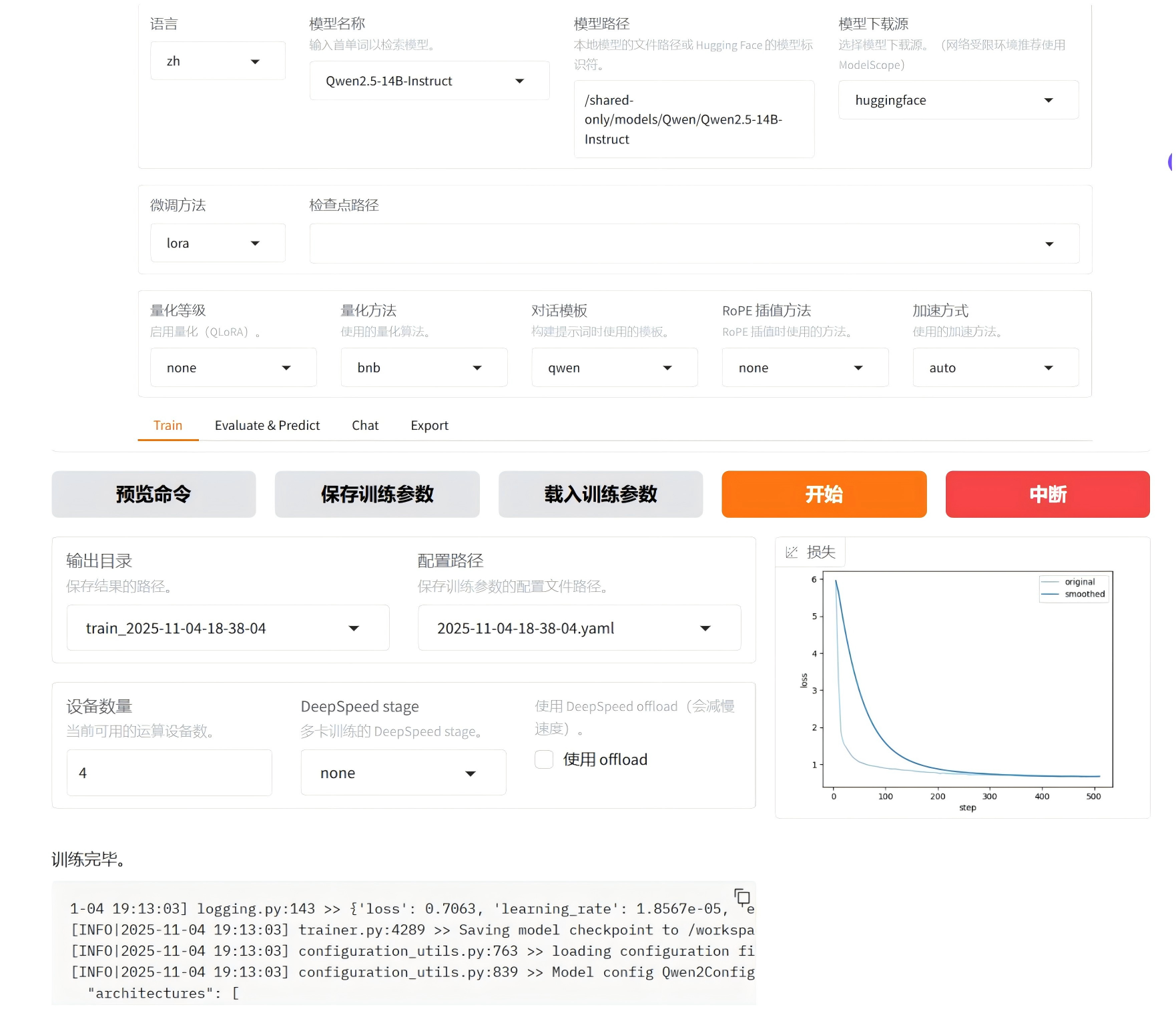
Step 2 在LLaMA-Factory启动模型训练
新建实例并搭建 LLaMA-Factory环境后,考虑到模型规模,我们选择4卡进行训练,核心配置如下:
- 基础模型:Qwen2.5-14B-Instruct
- 训练样本:30000条
其余参数默认保留即可,支持一键启动训练;也可根据自身需求灵活调整各项参数,适配不同使用场景。

Step 3 聊天体验,效果立见分晓
训练完成后,在 chat 界面加载训练后的模型 checkpoint,就能直接体验专属票务客服啦!
- 原生模型

未经过微调的模型,面对用户的订票需求,只会回复 “建议官网操作”,完全无法胜任客服工作。
- 微调后模型
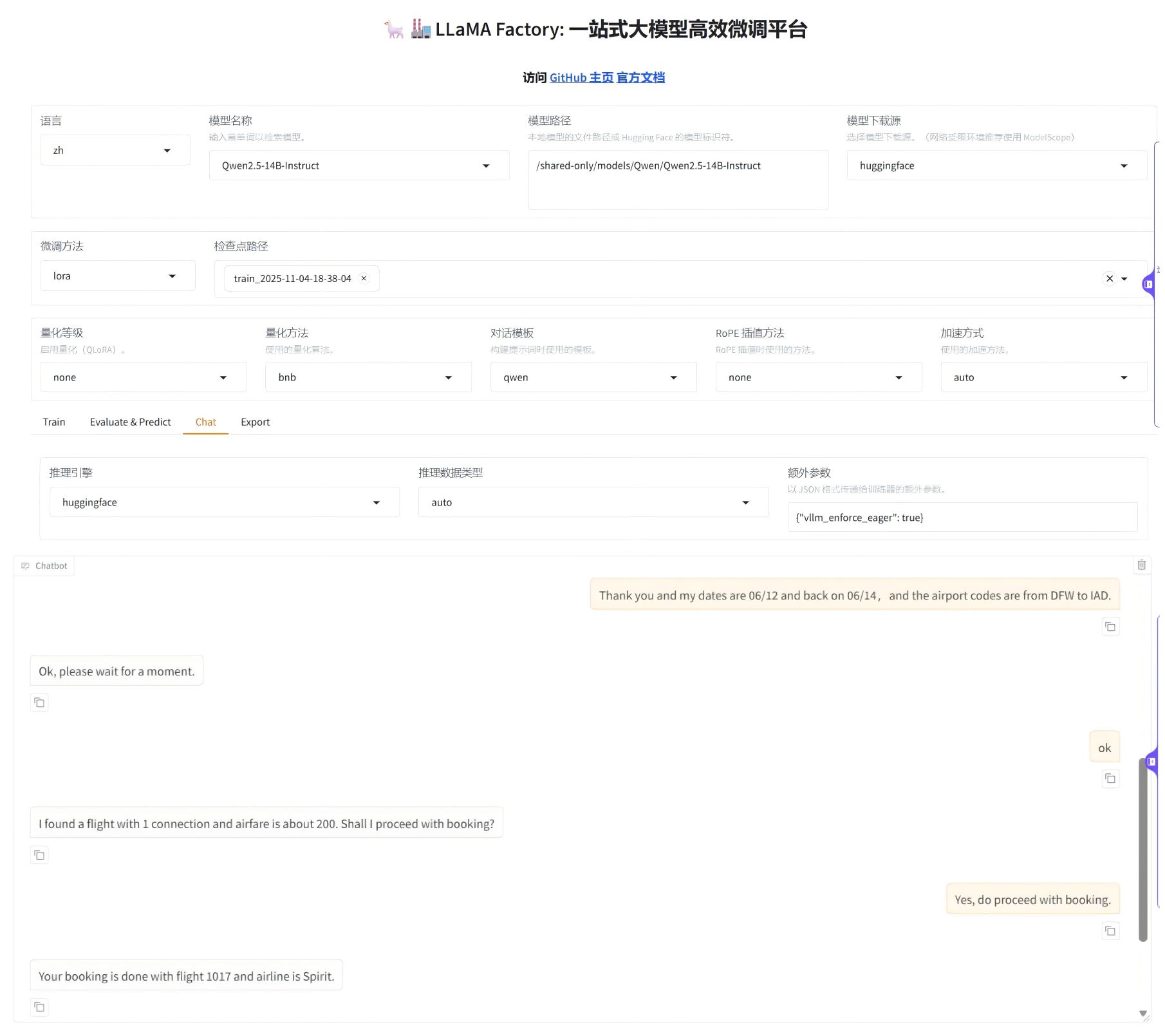
不仅能精准理解用户对航班时间、起降地点的需求,回复还贴合真实业务场景,甚至能直接协助完成订票流程。更惊喜的是,多轮对话中能始终保持上下文一致,比起原生模型的 “建议性操作”,专业性和实用性都有了质的飞跃!
为什么选择LLaMA-Factory + Lab4AI?
通过本次实践,我们成功复现了订票客服案例,并体验了从聊天记录的完整流程。借助LLaMA-Factory,我们不仅轻松完成了微调和推理,还体验到了其可视化、可控、轻量化的微调优势,让客服的打造变得简单、高效。
同时,本次实践也得益于Lab4AI平台提供的完善实验环境和数据资源:
- 开箱即用的数据集:航空票务客服对话数据,方便快速上手
- 完整实验工具链:从数据预处理、微调到推理接口,一站式支持
- 在线体验与文档指导:无需本地环境配置,低门槛上手
Lab4AI提供除了一键复现之外,还提供更多的价值:
1.开发者:高性能算力深度绑定
大模型实验室Lab4AI实现算力与实践场景无缝衔接,支持模型复现、训练、推理全流程使用,且具备灵活弹性、按需计费、低价高效的特点,解决用户缺高端算力、算力成本高的核心痛点。
2.科研党:从“看论文”到“发论文”的全流程支持
集成Arxiv每日速递,提供论文翻译与分析工具,并凭借一键论文复现功能,快速验证CVPR、ICCV、NeurIPS、ICML、ECCV、AAAI、IJCAI、ICLR、IJCV、TPAMI、JMLR、TIP等顶刊顶会的算法,帮助您解决数据集下载慢、依赖冲突、GPU 不足等环境配置难题,将环境配置时间节省80%以上。

3.学习者:AI课程支撑您边练边学
提供多样化AI在线课程,含LLaMAFactory官方合作课程等课程,聚焦大模型定制化核心技术,实现理论学习与代码实操同步推进。









)

)
)
)
)
)
)
)
![[豪の算法奇妙冒险] 代码随想录算法训练营第八天 | 344-反转字符串、541-反转字符串II、Carl54-替换数字](http://pic.xiahunao.cn/[豪の算法奇妙冒险] 代码随想录算法训练营第八天 | 344-反转字符串、541-反转字符串II、Carl54-替换数字)
