同样来自模拟赛 T4。
引入
考虑如下问题:
给定一个初始为空的数列 \(a\),有 \(c\) 次操作,每次操作形如:
- \(1\) \(x\):将值 \(x\) 放入 \(a\) 的末尾。(保证这个操作有 \(n\) 次,\(n\) 在一开始给定)
- \(2\) \(x\):查询当前序列所有长度为 \(x\) 的区间的价值和,答案对 \(998244353\) 取模。
其中一个长度为 \(x\) 的区间的价值定义为:在输入一开始会给定一个定值 \(m\),若 \(x<m\) 则这个区间的价值为区间内的数的乘积,否则区间的价值为区间内前 \(m\) 大的数的乘积。
数据范围&要求:\(1\le n\le 10^5,1\le m\le 200,1\le c \le 2\times 10^5,1\le V \le 10^7\),其中 \(V\) 为一操作中 \(x\) 的值域。保证一操作的所有数互不相同,强制在线。
初步思考
题目要求强制在线,所以一个直接的想法是我们在每次加入一个数之后实时维护新产生的区间的价值(也就是所有后缀)。由于这个价值涉及到区间前 \(m\) 大,所以我们显然需要想个办法去维护出每个后缀的前 \(m\) 大。又发现当 \(m=1\) 时,这个问题很像单调栈,所以我们尝试往单调栈的方向想。
扩展单调栈(Ex Monotonic Stack)
真的叫这个名字吗。
首先有一个很显然的每次 \(O(n\log n)\) 维护的办法:每次新加入一个数从后往前扫,维护一个堆,若当前堆的大小 \(<m\) 则直接加入,否则若堆顶小于当前数则删去堆顶加入当前数,并用逆元维护价值。
我们都知道普通单调栈维护的是当前的所有后缀最大值,也可以认为,他维护了所有后缀最大值发生变化的位置。回到上面的暴力,我们实际上关心的也只是那些后缀前 \(m\) 大发生变化的位置(即让堆发生变化的位置),我们称 \(S_{l,r}\) 为区间 \([l,r]\) 前 \(m\) 大构成的集合,则我们称一个位置 \(x\) 为关键位置,当且仅当 \(x=n\) 或者 \(S_{x,n}\ne S_{x+1,n}\)(\(n\) 为当前序列的长度)。那么若 \(i\) 后面第一个关键位置为 \(x\) 则 \(S_{i,n}=S_{x,n}\)。
我们用一个链表维护当前所有的关键位置,接下来我们考虑加入一个数 \(a_{n+1}=w\) 时,关键位置的变化。
从后往前扫描链表,假设当前扫到的位置为 \(x\),若 \([x,n]\) 中有 \(\ge m\) 个 \(>w\) 的数,则 \(w\) 一定不会对 \(x\) 及以前的位置产生影响,直接结束遍历;否则 \(w\) 一定是 \([x,n+1]\) 的前 \(m\) 大。而当 \([x+1,n+1]\) 中有 \(\ge m\) 个数 \(>a_x\) 时,\(x\) 就不再是关键位置了,要把它从链表中删除,不难证明这种情况等价于 \(a_x\) 原先是 \([x,n]\) 的第 \(m\) 大。
所以不管是从判定一个位置是否仍然是关键位置的角度,还是从维护区间价值的角度(因为维护区间价值的时候你需要删去最小值的贡献加入 \(w\) 的贡献),我们都应该去维护一个 \(mn_x\) 表示 \(S_{x,n}\) 的第 \(m\) 大的值。
那怎么维护呢,我们考虑从前往后更新(从你结束遍历的位置的后继开始到链表尾)。假设当前需要更新 \(x\) 的 \(mn_x\),他的前驱为 \(x'\) 已经更新好了,设加入 \(w\) 前 \(mn_{x'}\) 为 \(old_{x'}\),加入 \(w\) 后为 \(mn_{x'}\):
- \(n+1-x+1\le m\):直接令 \(\min(mn_x,w) \to mn_x\) 即可。
- 否则,由于我们在出现 \(\ge m\) 个 \(>w\) 的数时会直接退出,所以一定有 \(w>old_{x'}\),也就是说原先 \(old_{x'}\) 是 \([x',n]\) 的第 \(m\) 大,现在就是 \([x',n+1]\) 的第 \(m+1\) 大了:
- 若 \(a_{x'}=old_{x'}\),此时 \(a_{x'}\) 不再是 \([x',n+1]\) 的第 \(m\) 大,因此 \([x,n+1]\) 的第 \(m\) 大就是 \([x',n+1]\) 的第 \(m\) 大:\(mn_x=mn_{x'}\)
- 否则,\([x,n+1]\) 的第 \(m\) 大是 \([x',n+1]\) 的第 \(m+1\) 大,即原先的 \(old_{x'}\)(因为还要去掉 \(a_{x'}\)):\(mn_x=old_{x'}\)。
但是这样你会发现第一个位置是没法更新的,不过由于只有这么一个位置,所以我们直接暴力重构计算出第 \(m\) 大即可。(这里的暴力只要复杂度跟你遍历过的位置个数线性就可以了,比如你可以用 STL 提供给你的 nth_element)。
最后 \(n+1\) 当然是一个关键位置,把他加入链表。
然后我们分析一下 ex 单调栈的复杂度:
- 对于遍历到的 \(>w\) 的数,我们只会遍历 \(\le m\) 个。
- 对于遍历到的 \(<w\) 的数,由于一个关键位置被 \(\ge m\) 个比他大的数遍历过之后他就不再是关键位置了,所以这样的数均摊下来也只会遍历 \(O(m)\) 个。
总复杂度均摊 \(O(nm)\)。
不难在这个过程中维护每一个后缀的价值的变化。
继续思考
(下面这些只是我自己的思考过程,可能会有点啰嗦,想直接看正解的可以跳过这一部分)
现在你历经千辛万苦成功发明出了 ex 单调栈,觉得这个题已经过了,但是你发现他求的是每个长度为 \(x\) 的区间的价值和。
我们来看我们现在维护出了什么,假设 \(val_l\) 表示 \([l,n]\) 的价值,我们现在已经可以在每次放入一个数 \(w\) 后,求出每个 \(val_l\) 的变化量是多少了(形如若干段区间加),所以这题如果问的是当前的某个后缀那么直接用线段树或树状数组维护区间加即可。
但是这题不一样,他询问的相当于是 \([n-x+1,n],[n-1-x+1,n-1],...,[1,x]\) 这些区间的价值和,由于他们的右端点不一样,所以仅仅用当前时刻(我们称为时刻 \(n\))的信息是不够的,我们还需要之前那些时刻的信息,碰到这样的问题,我们常见的工具有两种:
第一种是可持久化。
现在相当于是说我们需要在不同版本的单调栈上查询。所以我们可以想个办法保留下之前的所有版本。
注意我们只能求出变化量,而不能直接存下所有 \(val_l\) 现在是多少,一方面是因为如果你对每个 \(n\) 都存储每个 \(l\) 对应的 \(val_l\) 的值,信息量是 \(O(n^2)\) 的,空间不够;另一方面,是开头存在一段 \(l\) 的 \(val_l\) 是不变的,我们不可能每次都把这一段复制一遍,否则时间也是 \(O(n^2)\)。所以当你要知道现在 \(val_l\) 是多少,你就必须要知道上一个版本的 \(val_l\) 是多少,然后再加上这次的变化量才能得到真实的 \(val_l\),这就类似于可持久化线段树,我们每次仅仅只是在上一个版本进行一些增量得到当前的版本,但同时又会保留之前的版本,这样的维护方式可以让你比较轻松地求出任何一个版本的任何一个位置(或一段)的信息,同时也能在保留所有版本信息的基础上,保证每次维护信息的变化不会占用太多的时间和空间。
比如如果这题询问是给你一个 \(n'\) 和区间 \([l,r]\),然后求所有 \(i\in [l,r]\) 的区间 \([i,n']\) 的价值和,那么直接上主席树就可以了。但是可惜的是,这题询问的不是一个版本,而是所有版本,这样很多可持久化数据结构就干不了了。
第二种是维护历史和。
要求所有历史版本的和自然想到直接维护历史和,比如如果这题问的是给定左端点 \(l\) 求所有 \(r\in [l,n]\) 的 \([l,r]\) 的价值和的话,直接用线段树维护历史和就可以了,但可惜的是,他每个版本问的左端点都是不一样的,显然只查询一个位置的历史和是不行的;那能不能不以左端点为下标,而是直接以区间长度为线段树的下标呢?这显然更加不可行了。
发现询问固定左端点我们是会做的,固定右端点我们也是会做的,但是两个都不固定的话,我们就很难用现有的数据结构去维护了。我们得想个办法既保留之前的所有版本,又能快速查询所有历史版本的一些信息的和。
扫描线
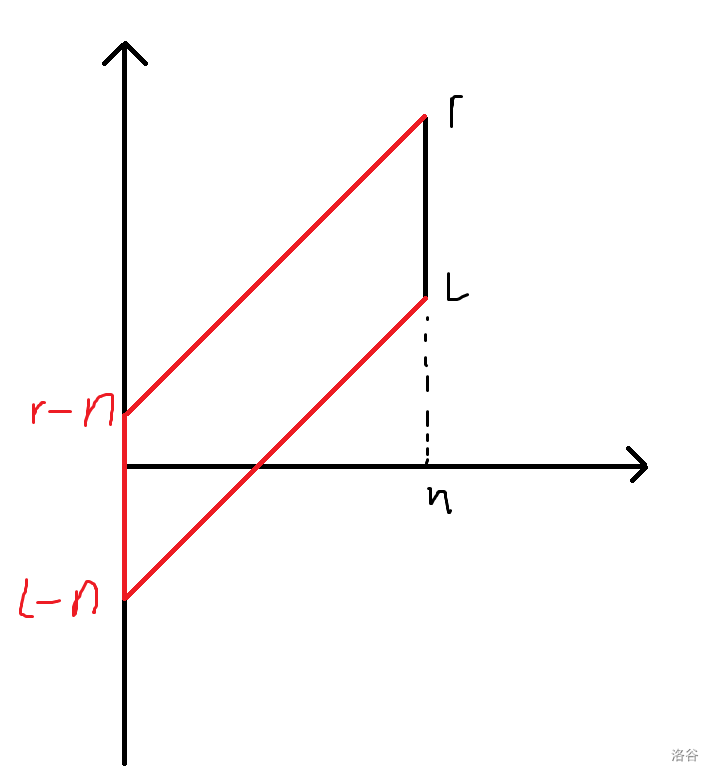
既然直接硬维护做不了,我们就从更宏观的角度考虑这个问题。我们把维护过程看成一个二维平面,横轴是时间轴,纵轴表示左端点,比如一个点 \((n,x)\) 就表示序列长度为 \(n\) 时,\([x,n]\) 这个后缀。
类似于上面可持久化的思想,我们也只保留每次的变化量,那么比如在时刻 \(n\) 我们把区间 \([l,r]\) 加了 \(d\),放到这个平面上就是把一条 \((n,l)\) 到 \((n,r)\) 的竖线上的点都加了 \(d\):
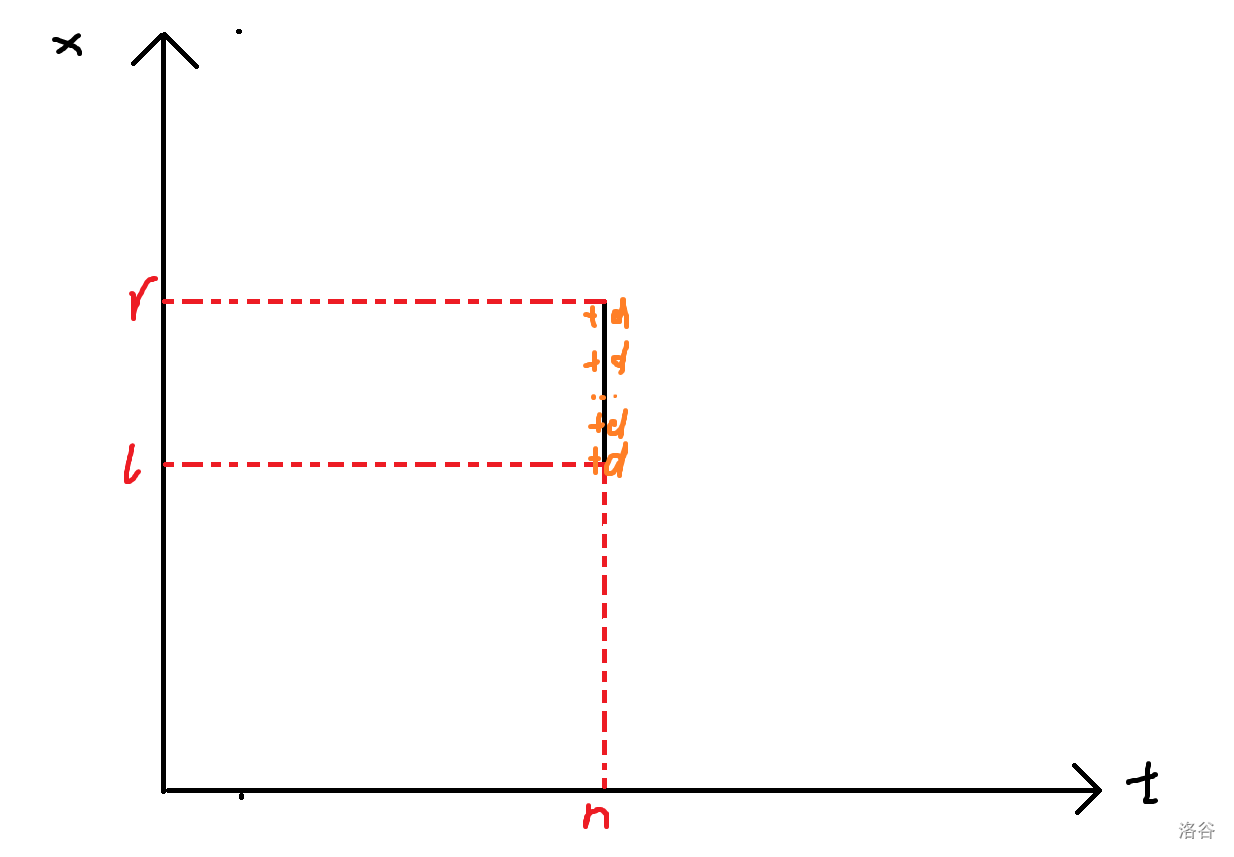
现在经历了若干次修改之后我们会得到很多条竖线(对应若干次不同时刻的区间加),假如我们要查询 \([x,n]\) 这个区间的价值,那就定位到时刻 \(n\),然后查询一下这及以前 \(x\) 这个位置加了多少东西,比如下图中框出来的部分的和就是答案:
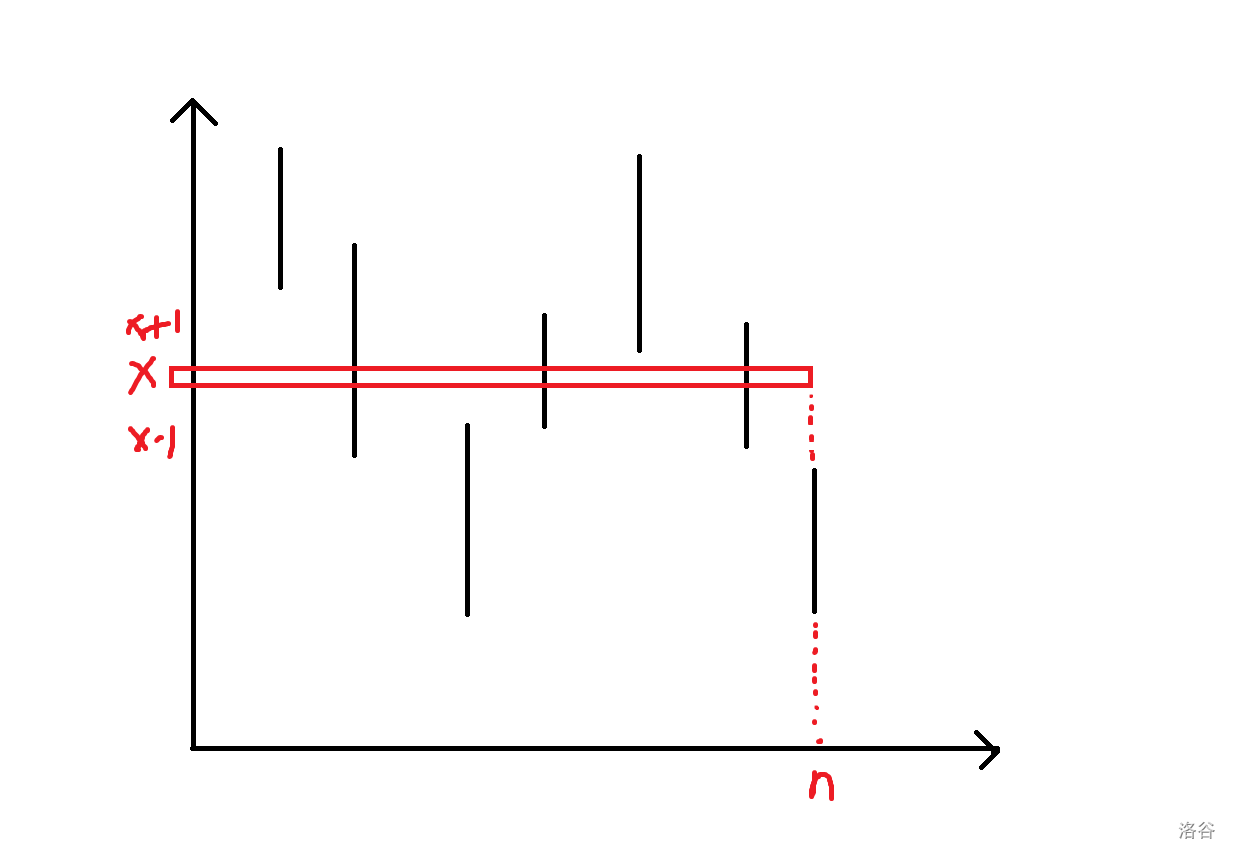
那对于序列长度为 \(n\) 时的一个询问 \(x\),问的东西就是一个直角梯形的和(包括边界),其中斜边的斜率为 \(1\):
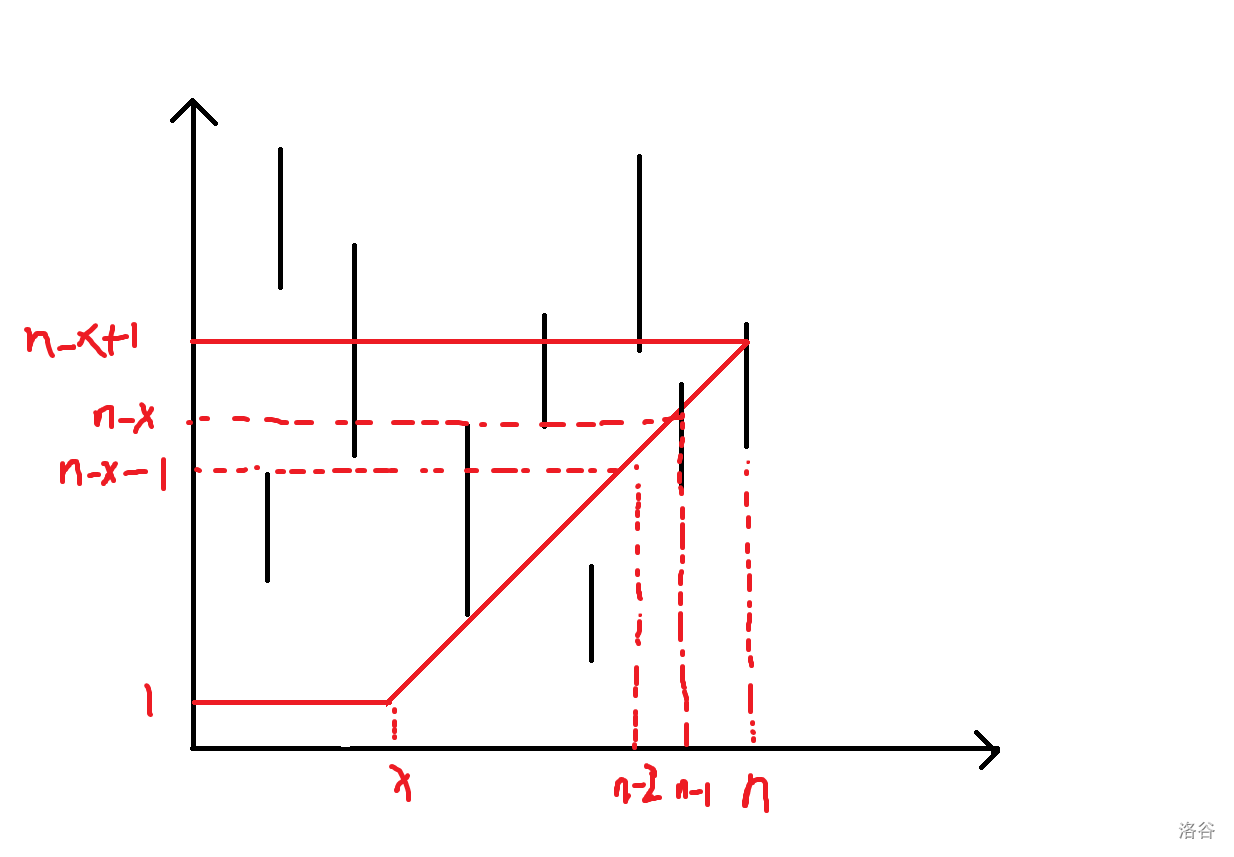
现在我们要维护竖线加,直角梯形求和,数据结构大师肯定发现了这是个扫描线板子,维护方法也有很多,但是为了防止有像我一样的小白看到这里,我们讲的详细一点。
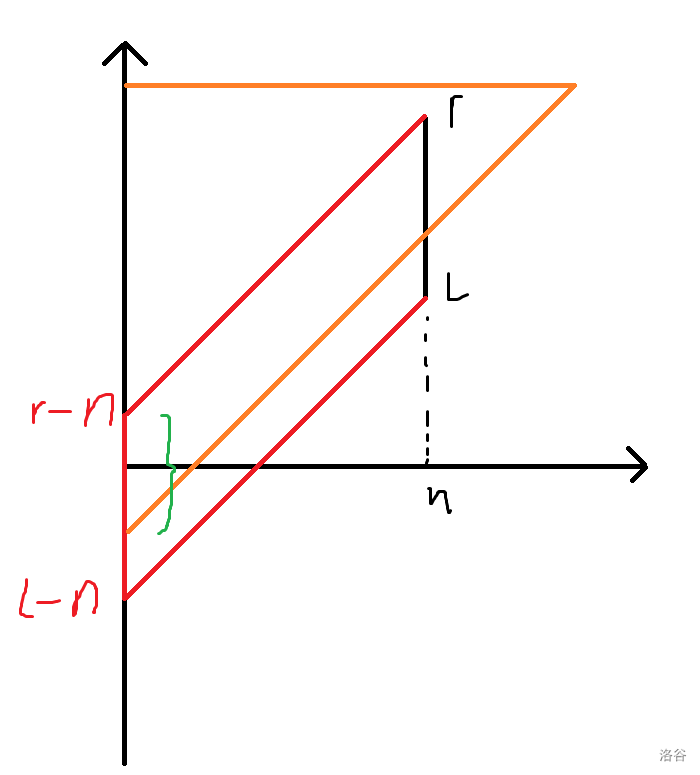
首先我们可以把这个直角梯形延伸一下,变成等腰直角三角形,如下图所示,那么答案就是这个橙色大等腰三角形减去那个绿色矩形部分(不难发现在时刻 \(n\) 蓝色部分一定全是 \(0\) 所以不用管):
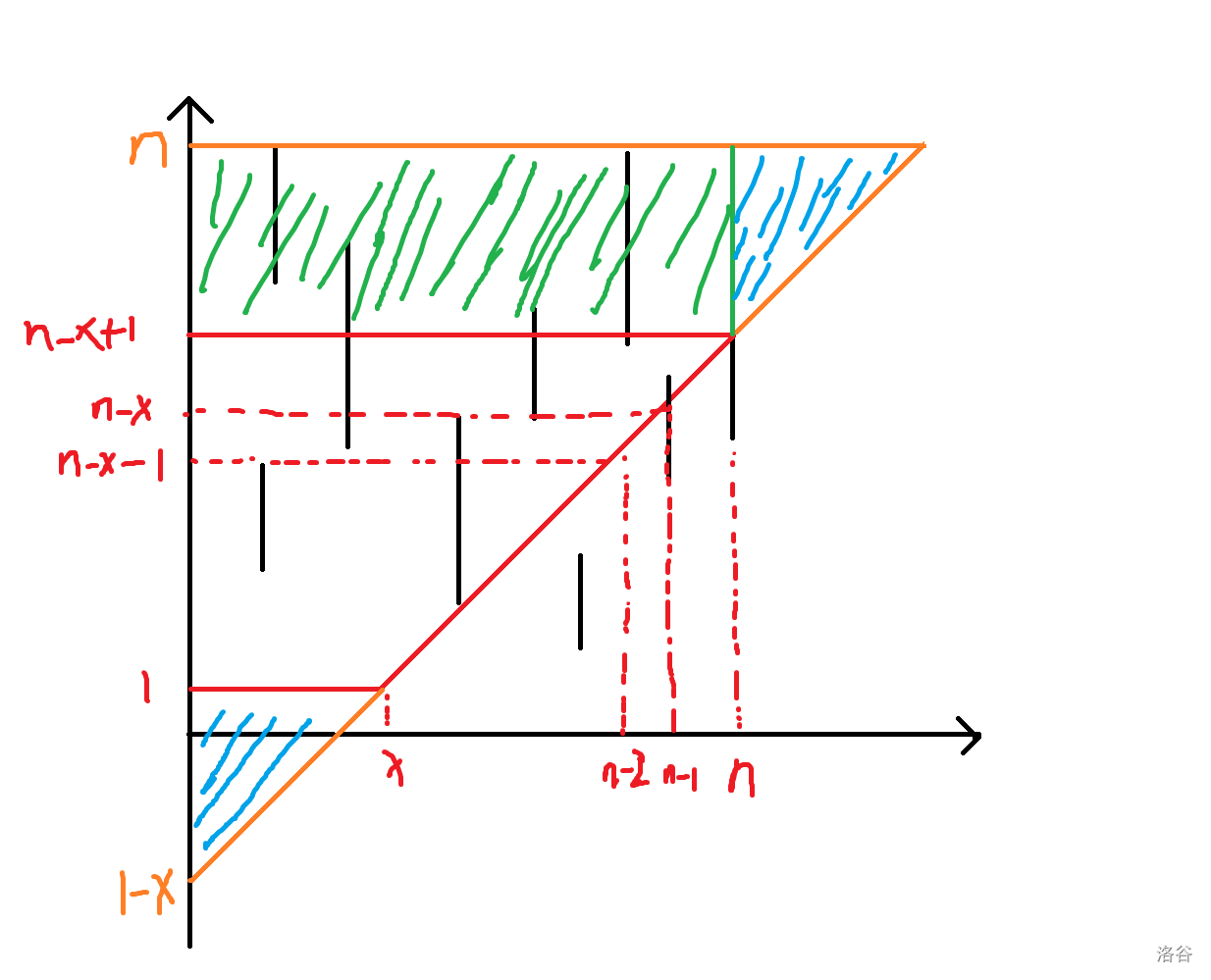
求绿色矩形部分的和简单扫描线即可,主要说一下怎么求大等腰三角形的和。
二维的情况不太好算,但是注意到这个三角形的斜边的斜率是确定的,而且很特殊,考虑把这些竖线全部映射到 \(y\) 轴上,具体的,你从两个端点分别画一条斜率为 \(1\) 的直线,映射到的区间就是这两条直线和 \(y\) 轴的交点构成的区间:
那么求一条竖线在大等腰三角形内的部分的和,相当于是求映射到 \(y\) 轴上之后的区间和大等腰三角形直角边的交(下图绿色):
于是这个问题也变成了简单的扫描线。
最后是用什么数据结构来维护扫描线的问题,发现我们要支持 \(O(nm)\) 次区间加,\(O(c)\) 区间查询,直接用线段树复杂度会多个 \(\log\),但是如果要用分块平衡的话,分块又好像不能支持 \(O(1)-O(\sqrt{n})\) 区间加区间查询。
不过可以发现,我们的区间查询始终查询的是一段后缀,所以对于一个区间 \([l,r]\) \(+d\) 的操作,我们把它拆成 \((-\infty,r] +d\),\((-\infty,l-1] -d\)。然后对于一个 \((-\infty,x] +d\) 的修改,他对 \([y,\infty)\) 这个查询的贡献是 \((x-y+1)\times d=xd-(y-1)d\),所以我们分别维护 \(xd\) 和 \(d\) 的和,就变成单点加后缀查询了,可以用 \(O(1)-O(\sqrt n)\) 的分块平衡。
总复杂度 \(O(nm+c\sqrt{n})\)。
补充:可能有人会问,为啥这题强制在线还可以扫描线,这是因为他每次询问的都是当前所有长度为 \(x\) 的区间,所以它相当于已经帮你把修改和查询按照时间这一维排好序了,如果它问的是某一段前缀内所有长度为 \(x\) 的区间,那就需要离线之后按照时间排序了。
code
#include<bits/stdc++.h>
#define Debug puts("-------------------------")
#define eb emplace_back
#define PII pair<int,int>
#define fi first
#define se second
#define mk make_pair
using namespace std;
const int N=1e5+5,M=205,V=1e7+5,mod=998244353;
int type,n,Max,m,T,inv[V];
void Add(int &x,int y){ x=(x+y>=mod)?(x+y-mod):(x+y); }
PII operator + (const PII &x,const PII &y){ return mk((x.fi+y.fi)%mod,(x.se+y.se)%mod); }
struct DS{int B,n,len,t,L[N],R[N],id[N<<1]; //B:偏移量PII A[N<<1],a[N<<1]; void Init(int deta,int nn){B=deta,n=nn;len=sqrt(n)+1,t=(n+len-1)/len;for(int i=1;i<=t;i++){L[i]=R[i-1]+1,R[i]=min(n,i*len);for(int j=L[i];j<=R[i];j++) id[j]=i;}}void modify(int x,int w){x+=B;if(x<=0) return;PII d=mk(1ll*x*w%mod,w);a[x]=a[x]+d,A[id[x]]=A[id[x]]+d;}int ask(int x){ //查询 >x 的和 x+=B; if(x>n) return 0;PII sum=mk(0,0);for(int i=x+1;i<=R[id[x]];i++) sum=sum+a[i];for(int i=id[x]+1;i<=t;i++) sum=sum+A[i];return (sum.fi-1ll*sum.se*x%mod+mod)%mod; }
}ds1,ds2;
void Init(){ ds1.Init(Max,2*Max),ds2.Init(0,Max); }
void Modify(int t,int l,int r,int d){ //在 t 时刻(即 n=t 的时刻)在 y 轴的 [l,r] 区间 +d。ds1.modify(r-t,d),ds1.modify(l-t-1,mod-d);ds2.modify(r,d),ds2.modify(l-1,mod-d);
}
int Query(int n,int x){ return (ds1.ask(1-x-1)-ds2.ask(n-x+1)+mod)%mod;
}
namespace Ex_Monotonic_Stack{int a[N],head,tail,pre[N],nxt[N],old[N],mn[N],res[N];int pos[N],tmp[N];void del(int x){int y=pre[x],z=nxt[x];Modify(n,y+1,x,(res[z]-res[x]+mod)%mod);if(x==head) head=z,pre[z]=0;else nxt[y]=z,pre[z]=y;}void push(int w){a[++n]=w;if(n==1){head=tail=n,pre[head]=nxt[tail]=0;mn[n]=res[n]=w,Modify(n,n,n,w);return;}int cnt=0,tot=0;for(int x=tail;x;x=pre[x]){if(a[x]>w) if((++cnt)==m) break;old[x]=mn[x],pos[++tot]=x;}if(tot>=m){int tn=0; tmp[++tn]=w;for(int i=1;i<=tot;i++) tmp[++tn]=a[pos[i]];nth_element(tmp+1,tmp+m,tmp+tn+1,greater<int>());mn[pos[tot]]=tmp[m]; } for(int i=tot;i>=1;i--){int x=pos[i];if(n-x+1<=m){ mn[x]=min(mn[x],w); continue; }else if(i!=tot){int x=pos[i],x1=pos[i+1];if(old[x1]==a[x1]) mn[x]=mn[x1];else mn[x]=old[x1];}}nxt[tail]=n,pre[n]=tail,tail=n,nxt[n]=0;mn[n]=res[n]=w,Modify(n,n,n,w);for(int i=1;i<=tot;i++){ //从后往前删除不是关键的后缀(i 越大 pos[i] 越小) int x=pos[i];if(n-x+1<=m){Modify(n,x,x,(1ll*res[x]*w%mod-res[x]+mod)%mod);res[x]=1ll*res[x]*w%mod;}else{if(old[x]==a[x]) del(x);else{int lst=res[x];res[x]=1ll*res[x]*inv[old[x]]%mod*w%mod;Modify(n,pre[x]+1,x,(res[x]-lst+mod)%mod);}}}}
}
signed main(){freopen("formalized.in","r",stdin);freopen("formalized.out","w",stdout);double beg=clock();inv[1]=1;for(int i=2;i<V;i++) inv[i]=1ll*(mod-mod/i)*inv[mod%i]%mod;scanf("%d%d%d%d",&type,&Max,&m,&T);Init();int lstans=0;while(T--){int op,x; scanf("%d%d",&op,&x);if(type) x=x^lstans;if(op==1) Ex_Monotonic_Stack::push(x);else{if(x>n){ lstans=0; puts("0"); continue; }printf("%d\n",lstans=Query(n,x)); }} cerr << "Time: " << (clock()-beg) << endl;return 0;
}
:蛋白质 - DNA 互作研究的 基因解码器)





)






![P11664 [JOI 2025 Final] 缆车 / Mi Telefrico](http://pic.xiahunao.cn/P11664 [JOI 2025 Final] 缆车 / Mi Telefrico)

二叉树进阶算法题 - 详解)



