- GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
- TL;DR
- Method
- Model
- 多模态数据
- 数据合成
- Experiment
- 效果可视化
- 总结与思考
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
link
时间:25.04
单位:香港理工大学、Tongyi
相关领域:使用MLLM做多模态检索
作者相关工作:GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
被引次数:38
项目主页:https://huggingface.co/Alibaba-NLP/gme-Qwen2-VL-2B-Instruct
TL;DR
多模态训练数据存在模态不平衡的问题,本工作改进:1.研发一种训练数据合成方法,构建了大规模、高质量多模态训练数据集;2.研发一种稠密的MLLM检索器名为GME(General Multimodal Embedding)。3.提出一个新的Benchmark名为UMRB(Universal Multimodal Retrieval Benchmark)。
多模态检索与之前单模态检索或者跨模态检索的差异
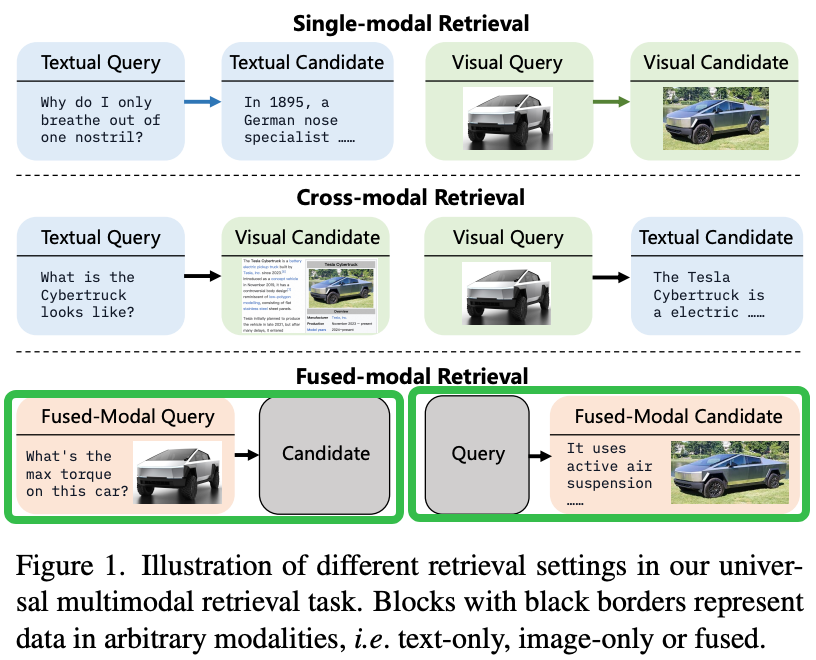
Method
Model
Loss: InfoNCE

负样本
Stage1:初始训练
- 使用随机选择的负候选进行训练
- 得到初始模型M1
Stage2:
- 使用M1为每个查询检索前K个候选
- 从非相关候选中选择硬负样本
- 使用这些硬负样本进一步训练M1,得到最终模型
![image]()

多模态数据
发现一:任务特异性优势
在单一数据类型上训练的模型在相应检索任务中表现最佳
例如:T→T数据训练的模型在文本检索任务中性能最优
发现二:混合数据优势
不同数据类型的平衡混合能增强各种设置下的性能
增加训练模态的多样性有效提升模型的整体检索能力
备注:IT(Image Text)、VD(Visual Document,指 包含丰富文本内容的图像,例如 图表等)

数据合成
workflow调用大模型生成condidate对应的多模态Query
Doc2Query生成:根据condidate过LLM生成Query
实体提取与查询重写:提取Query中的实体以及查询重写 (仍然使用LLM)
图像检索与生成:根据实体查询Google找到匹配图片,或者使用FLUX生成图片

Experiment

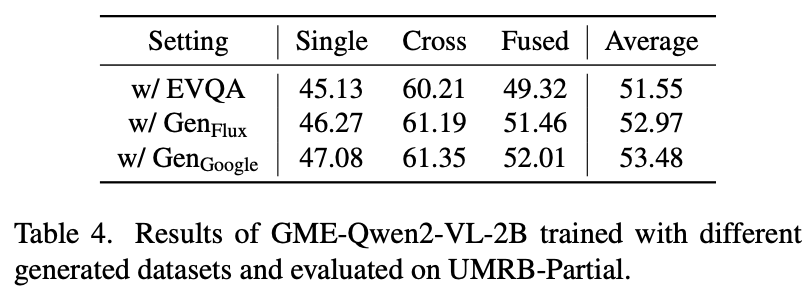
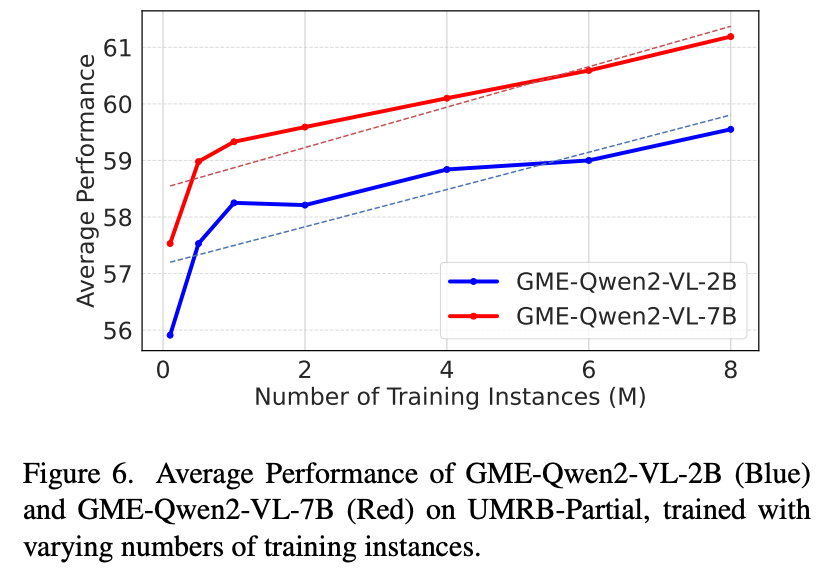
不同图片合成方法的影响
效果可视化
https://zhuanlan.zhihu.com/p/19360760482
https://zhuanlan.zhihu.com/p/1930993401488216568
总结与思考
无


归一化)







)








