本文首发于本人微信公众号,原文链接:https://mp.weixin.qq.com/s/mh7pXnh6-SM6yqdGBGVm0Q
摘要
本文是CUDA矩阵乘法系列文章的上篇。
这个系列会从一个最简单的实现出发,逐步优化到cuBLAS标准库86%的性能,并详细介绍其中涉及到的CUDA性能优化技巧。
本文首先给出了一个开箱即用的实验源代码,然后介绍了GPU硬件知识以及3种简单实现,逐步展示了把性能从cuBLAS的0.39%优化到16%,即性能提升40倍的“魔法”。
写在前面
矩阵乘法在当今的AI世界扮演着至关重要的角色,神经网络的前向传播,注意力机制的计算等最终都可以使用矩阵乘法来实现,一次大模型的推理背后是数以亿计的矩阵乘法操作。因此,矩阵乘法的执行性能是一个需要重点关注的优化目标。
目前CUDA平台上已经有很多高效的矩阵乘法的实现,例如cuBLAS,CUTLASS。
为了探究这些高效实现背后的原理,本文会从一个最简单的矩阵乘法内核出发,通过逐步优化的方式来逐渐逼近cuBLAS的表现。
本系列文章会分为上下两篇,上篇会介绍一下实验环境,一些本系列会用到的GPU硬件知识,以及3种较为简单的实现;下篇会继续介绍剩下的4种更为复杂的实现。
参考资料
- 《How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog》,本文也是以这篇文章为主线展开的,文章链接 https://siboehm.com/articles/22/CUDA-MMM
- 《CUTLASS: Fast Linear Algebra in CUDA C++》,链接:https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/
- GodBolt:这是一个可以查看源代码对应的汇编代码的一个很好用的小工具,链接:https://godbolt.org/
实验环境
实验源代码
本文实验的源代码已开源到了GitHub,链接:
https://github.com/QZero233/CudaMM
项目中包含了一个带有正确性验证的profiling工具,感兴趣的朋友可以自行实现一些内核,然后使用这个工具来测试一下自己的实现的性能如何。
这个工具的运行结果如下图所示,我们主要关注其中倒数第二行的以GFLOPS为单位的性能。

硬件环境
- 显卡型号:NVIDIA GM107GL [Quadro K620]
- CUDA架构版本号:50
- CUDA版本:12.4
- NVCC版本:12
关于GPU你需要了解的那些事
从硬件视角看GPU
之前在CUDA并行规约那篇文章中提到过,在进行CUDA开发时,我们是以Grid,Block和Thread三级的层次结构来组织线程的,那么这三者是如何对应到具体的硬件实现的呢?
从硬件视角下看,一张显卡里有一个GPU,GPU内部有多个流式多处理器(Streaming Multiprocessor,以下简称SM),如下图所示:

接下来把视角转向SM内部,每个SM有多个处理器,线程就是在这些处理器上具体执行的。
除此之外,每个SM还有一块共享内存区域,之前文章里提到的共享内存(Shared Memory,以下简称SMEM)就是在这个区域,这个区域只能是SM内部的处理器访问。SM内部的每个处理器又有着只能是自己访问的寄存器(REGS)。
从这里也可以总结出GPU上内存访问的速度排序,寄存器(REGS)是最快的,但是只能线程自身访问;其次是SMEM,但是只能是Block内的线程访问;最慢的是GMEM,GMEM就是我们通过cudaMalloc申请到的内存,所有线程均可访问。
那么上述的线程层级架构又是怎么和这个硬件架构相对应的呢? 而且Warp在其中又是怎么体现的呢?这就得从线程调度的角度来看一个内核被启动的过程了。
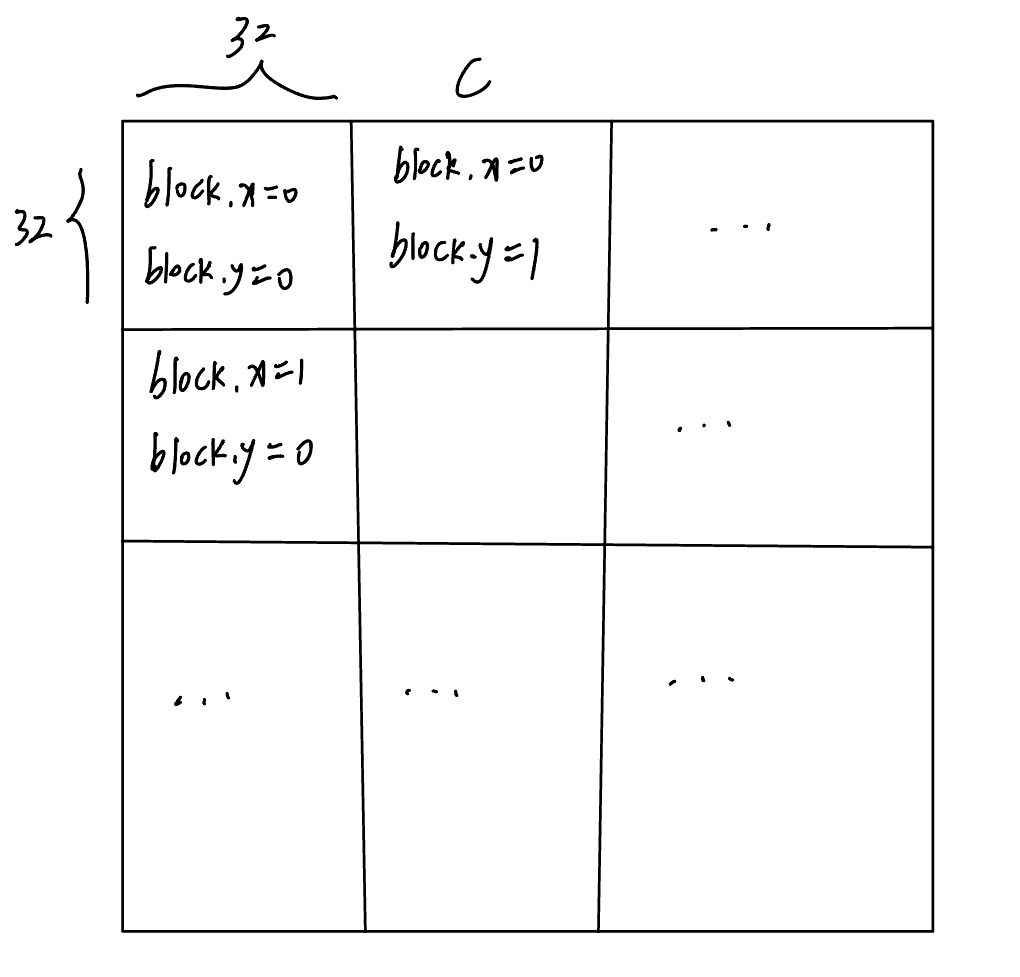
在启动内核时,我们会指定GridDim和BlockDim,这就使得内核有了一定数量的线程块(Block)需要执行,每个Block里有若干个Thread。在进行调度时,GPU会以Block为单位,把一个Block分给一个SM,这时候一个SM可能会被分到多个Block。
接下来就是SM的工作了,一个Block里连续的32个线程为一个Warp,SM会以Warp为单位进行调度,即SM会选择32个连续的线程,然后放到32个处理器上运行。上述过程如下图所示。

全局内存访问合并
同一个Warp里的线程有很多有意思的特性,对这些特性加以利用就能够达成不错的优化效果,全局内存访问合并(Global Memory Coalescing)就是其中之一。
这个特性是:如果一个Warp里的线程访问的内存恰好是连续的32个4B的浮点数,那么GPU就只会做一次长度为128B的访存操作, 把128B的数据读取之后分发给32个线程。这里参考资料作者的精美的手绘图可以很形象地说明这一点:

一些约定
在开始正式实现前,首先需要把一些容易混淆的设定给明确了。
- 本文默认所有矩阵都是行优先存储的
- 本文中的x都是指行下标,y都是指列下标
如下图所示:
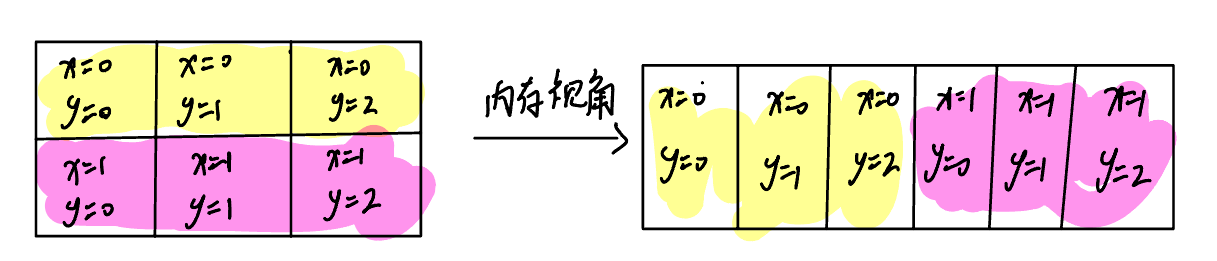
(注:本文所有的内核实现都只是在大小为4096的方阵下进行了正确性验证,如果要适配任意形状需要考虑很多corner case,这有点偏离主线了,所以本文就暂时不做这方面的适配工作了。)
V42:cuBLAS
这里先放出cuBLAS实现的性能数据,供后续比较和参考

V1:Naive Kernel
对于矩阵乘法\(C = A \times B\),一个最朴素的想法就是让每个线程都计算C中的一个元素,所以只需要一个Block,使用Thread的x和y表示要计算的C的元素坐标,然后2个for循环计算即可。
这个想法没问题,只是在实现的时候,由于一个Block里面最多有1024个线程,所以需要进行一次分块。
具体而言,可以把C分成若干个\(32 \times 32\)的块(Tile),每个Tile交给一个Block进行计算,如下图所示:

对于每个线程而言,首先需要根据计算出当前线程需要处理的C的坐标,然后用2个for循环计算结果并写回即可。
至于布局,每个Block里自然是\(32 \times 32\)个线程,而Grid则是需要用向上取整的除法来分配尽量多的Block。
(注:理清楚每个线程需要计算哪些C的元素是不被后面更复杂的分块绕晕的关键)
最终得到的源代码如下所示:
__global__ void MatmulKernelV1(const scalar_t *a, const scalar_t *b, scalar_t *out, uint32_t M, uint32_t N, uint32_t P) {uint32_t x = blockIdx.x * blockDim.x + threadIdx.x;uint32_t y = blockIdx.y * blockDim.y + threadIdx.y;if (x < M && y < P) {scalar_t tmp = 0;for (uint32_t k = 0; k < N; k++) {// out[i][j] = a[i][k] * b[k][j]tmp += a[x * N + k] * b[k * P + y];}out[x * P + y] = tmp;}
}void MatmulCoreV1(const scalar_t *a, const scalar_t *b, scalar_t *out, uint32_t M, uint32_t N, uint32_t P) {dim3 grid(std::ceil(M / 32.0), std::ceil(P / 32.0), 1);dim3 block(32, 32, 1);MatmulKernelV1<<<grid, block>>>(a, b, out, M, N, P);
}
实验数据
最终的性能数据如下所示:
性能只有cuBLAS的0.39%,可以说是相当拉垮了。
理论分析
这里先插入一段理论分析,来分析一下Naive Kernel可能的性能瓶颈在哪。
首先计算一下理论最快的运行时间,进行一个4096方阵的乘法所需要浮点运算次数为\(2 \times 4096^3\)(因为C有\(4096^2\)个元素,每个元素需要进行4096次乘法和加法),大约为137GFLO;
而内存读取最低需要\(2 \times 4096^2 \times 4\,\text{B}\),约134MB,写入需要\(4096^2 \times 4\,\text{B}\),约67MB。
实验用的显卡浮点数计算性能为870GFLOPS,显存带宽为29GB/s,所以理论上计算最快需要157ms,访存共需要6.9ms,也就是说,理论上来讲,矩阵乘法应该是计算瓶颈的。
但是我们的Naive Kernel似乎并不是这样的,下面来详细分析一下。
在计算次数上,如果不考虑计算下标的开销,那它的计算次数就是和理论最低值相等的;
在内存访问上,实际上每个线程都会访问\(2 \times 4096\)次全局内存(GMEM),如果这些访问没有经过任何优化,那么这个内核一共就会有
\(4096^2 \times 2 \times 4096 \times 4\,\text{B} = 549\,\text{GB}\)
的访存,需要耗时18.9s,已经是计算的120倍了,所以很显然,目前的首要任务是优化内存访问。
(注:这里内存访问事实上并没有计算的那么多,因为有一些Warp层的自动优化,这个后面马上会提到)
V2:Global Memory Coalescing
这里可以像防止Bank Conflict那样,通过调整每个线程负责的区域来实现Coalescing。
我们首先分析一下V1里面每个线程都在计算C的哪一个元素。通过代码可以知道,线程计算的C的x坐标就是threadIdx.x,y坐标就是threadIdx.y,并且threadIdx是x先变化的,所以第一个线程计算的是(0, 0),第二个是(0, 1),以此类推,如下图所示(用背景色来区分T0和T1加载的数据):
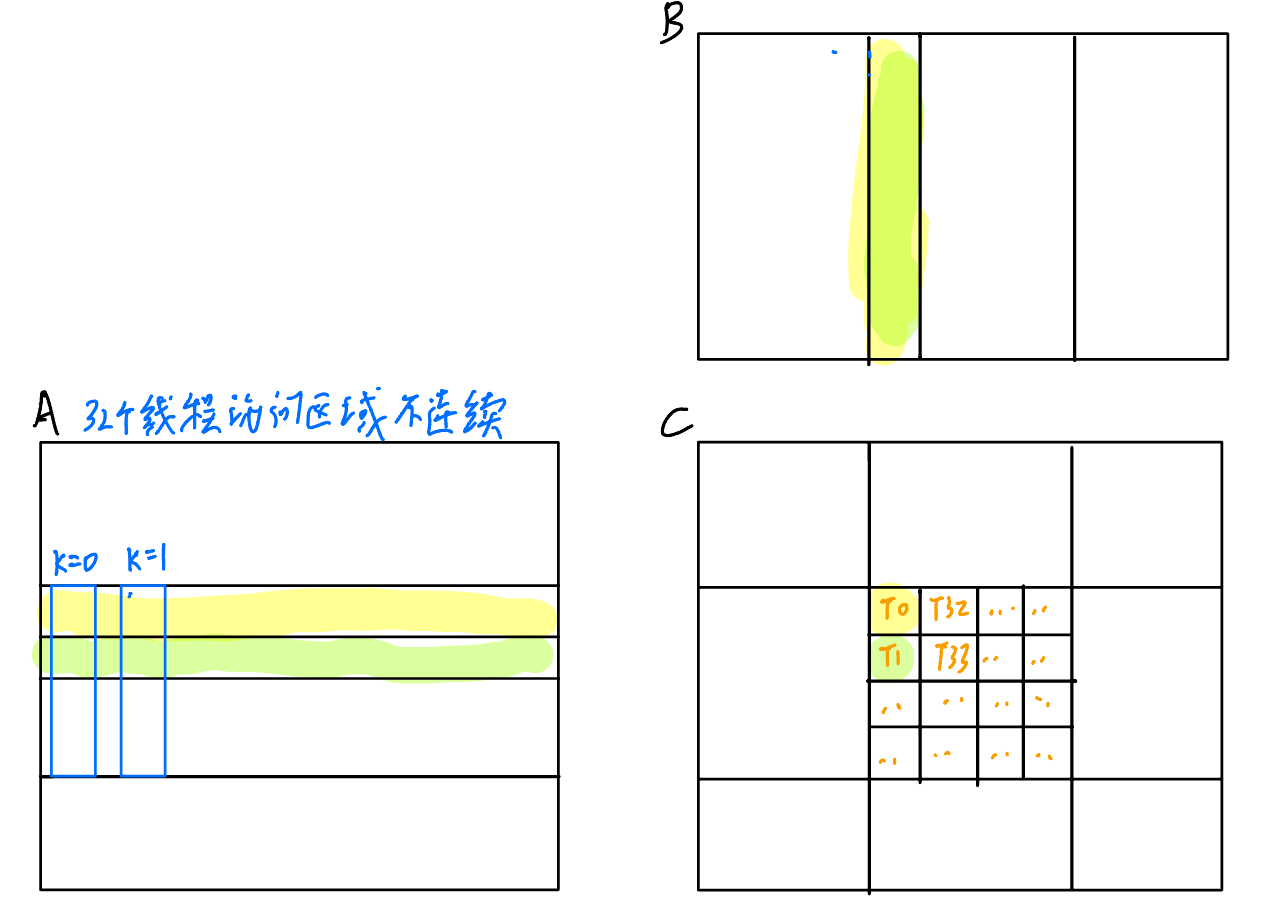
可以发现,一个Warp里计算的其实是C中的某一列,那么同一时刻,Warp里的线程访问的A一定不是连续的,所以访问A的部分一个Warp需要\(32 \times 4096\)次访存,而访问B的部分,由于一个Warp里的线程在同一时刻访问的都是同一个B,所以这里只会有一次访存开销,那么访问B总共就会有4096次访存。
这里如果我们让一个Warp计算C中的一行会怎么样呢?那么访问A就只需要4096次访存,但是访问B的时候,在同一时刻,线程们访问的数据是连续的,此时就可以触发Global Memory Coalescing,把32次访存压缩为1次,如下图所示:
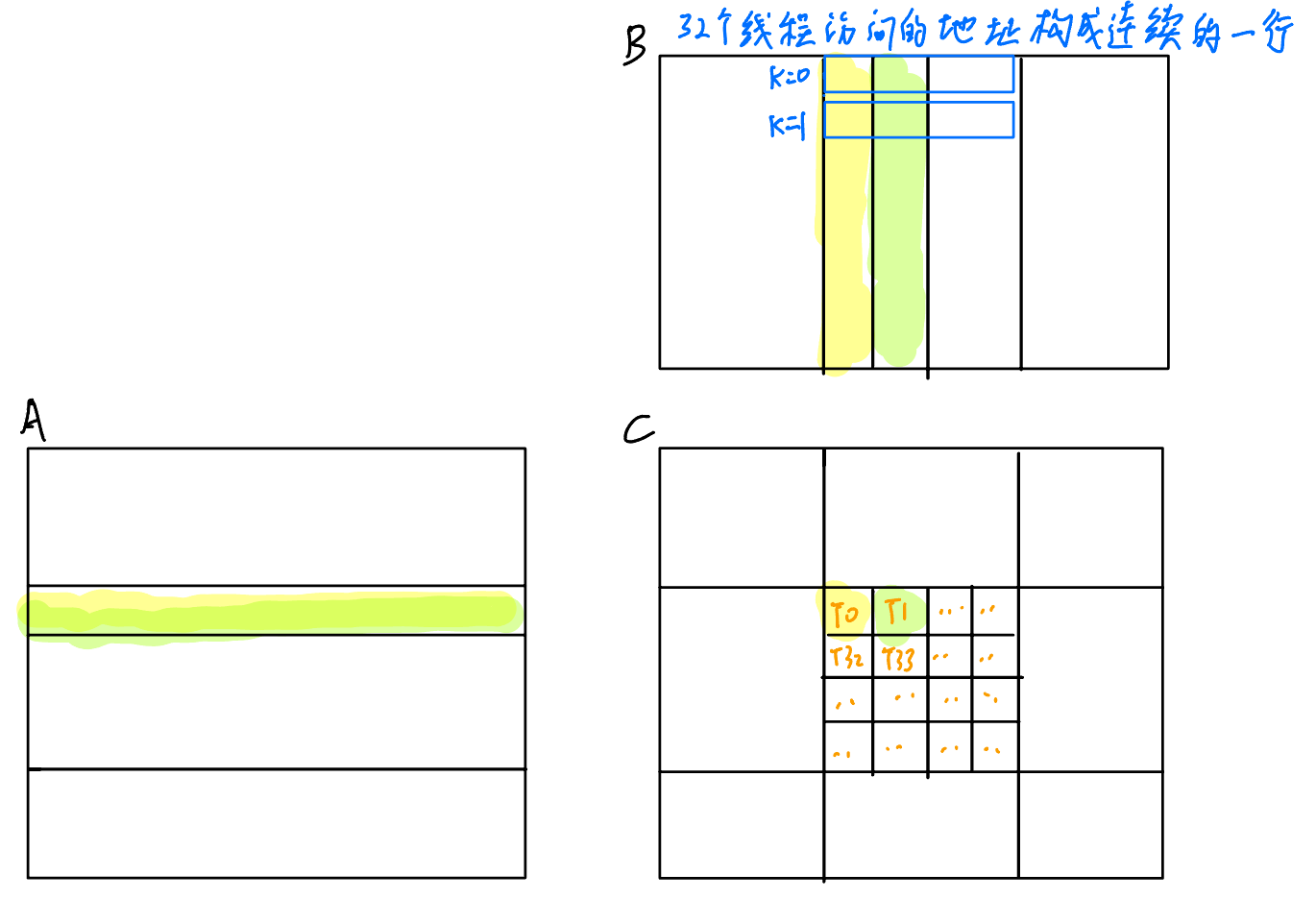
实验数据

这里仅仅是对换一下x和y,性能就提升了接近8倍。
但是和cuBLAS相比,还是有不小的差距,目前也还只有cuBLAS性能的2%。
关于实现方式
具体实现时,只需要把x和y对换一下就行了。
参考资料作者在这里的实现是取消了threadIdx.y这个维度,然后把x维度的大小扩展为了1024,之后在线程内部根据threadIdx.x以及BlockSize来计算当前线程对应到C的坐标,如下所示:
constexpr uint32_t BLOCK_SIZE = 32;
__global__ void MatmulKernelV2(const scalar_t *a, const scalar_t *b, scalar_t *out, uint32_t M, uint32_t N, uint32_t P) {// 相当于首先把OUT分成若干个32*32的Block,V1和V2都是如此,它们的区别在于Block内部的分配方式// 这里blockIdx.x * BLOCK_SIZE, blockIdx.y * BLOCK_SIZE 就是在定位Block的起始x和yconst uint32_t x = blockIdx.x * BLOCK_SIZE + threadIdx.x / BLOCK_SIZE;const uint32_t y = blockIdx.y * BLOCK_SIZE + threadIdx.x % BLOCK_SIZE;
......
个人认为这种实现肯定是不如直接对换x和y的,因为这种实现引入了除法和求余数这种非常昂贵的操作,但是实际测试下来两种实现的性能是几乎一致的。
于是我看了下两种实现对应的PTX汇编,如下图所示

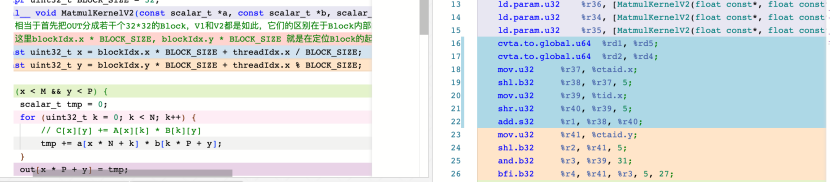
发现两者指令数量几乎都差不多,可能是因为这里BlockSize为2的整数次幂的关系吧,这种特性使得编译器可以对求余数指令做优化,一般的求余数指令是需要用除法+减法来实现的。
如下图所示,可以看到,在把BlockSize换成34之后,确实多出来了一条sub指令。
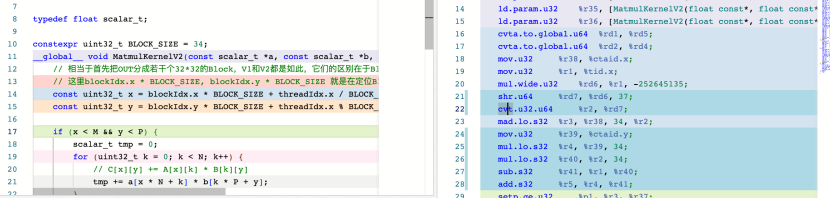
在把BlockSize改成31然后实际运行后,确实出现了性能的损失。

所以,有时候大小为2的整数倍确实能带来一些额外的惊喜。
V3:Shared Memory Cache-Blocking
前文提到过,存储访问速度是REGS > SMEM > GMEM,最理想的情况是每个线程所需的所有数据都加载到REGS里,但是这显然不现实;
那么退而求其次地,如果能把每个Block所需要的数据都加载到SMEM里,也能减少很多GMEM的访问次数。
虽然一个线程所需计算C的大小是固定的,比如\(32 \times 32\),C只需要A的32行和B的32列,但是A和B的形状是不固定的,如果A的列很多,那也会挤爆SMEM。
这时候很自然的就能想到,如果我们用类似于滑动窗口的方法,每次加载固定大小的A和B到SMEM里,计算完成之后再继续加载下一个窗口,并计算,这样是否可行呢?
对于矩阵乘法这个操作而言,确实是可行的。我们以C中的某一个元素为例,如下图所示:可以把A的对应行和B的对应列拆分为多个小块W0,W1......,只需把对应的块加载然后相乘之后累加,就能得到正确结果。
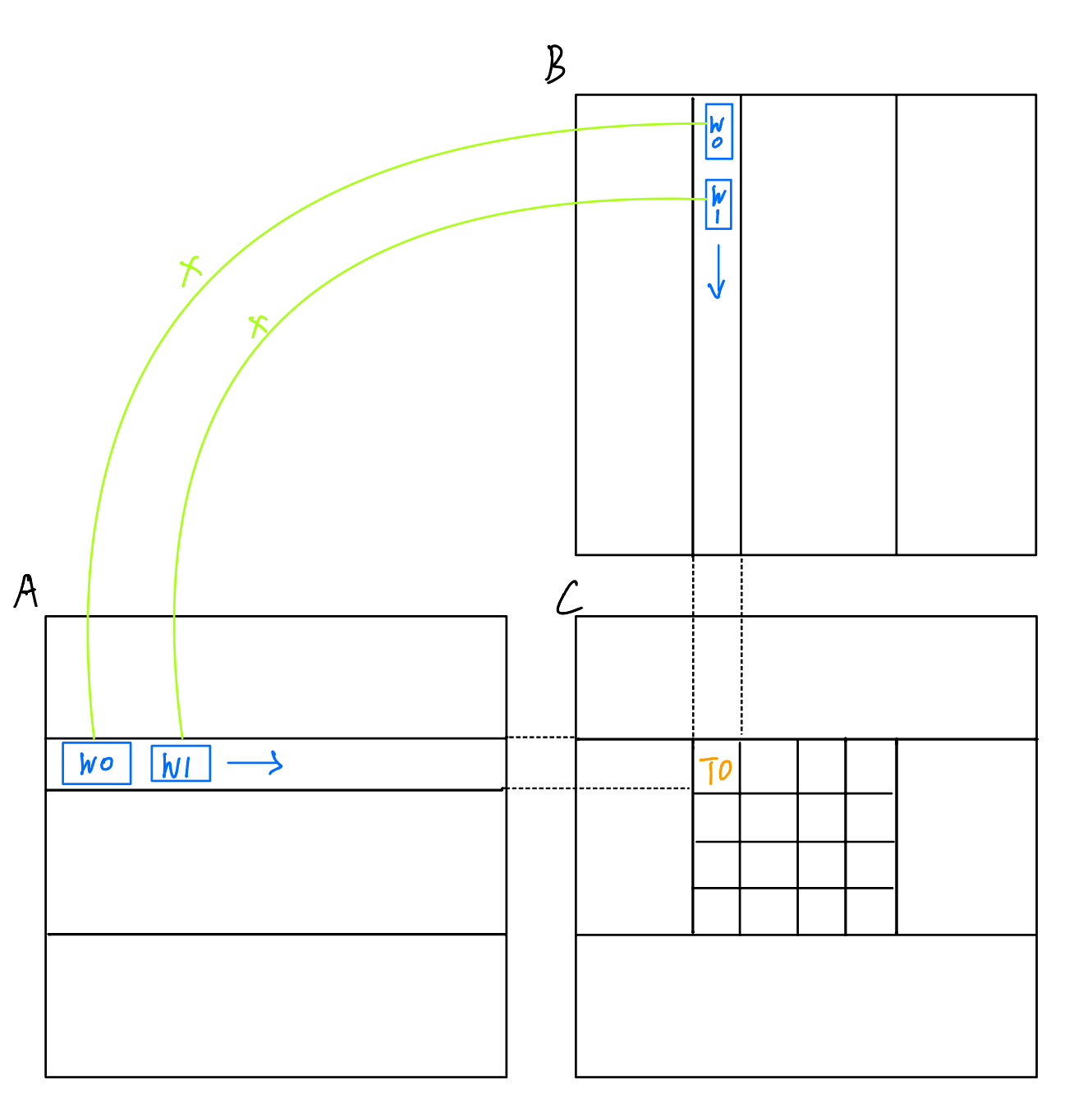
推广到整个Block,我们就可以只加载所需行和列的部分数据到SMEM里,然后在SMEM里完成计算后再继续加载,参考资料作者的图可以很清晰地说明这一点:

具体实现
这里我们选取SMEM大小为\(32 \times 32\),也就是刚好和线程数量相等,这样在加载数据到SMEM阶段,只需要每个线程加载一个元素即可,可以一一对应上。
从线程的视角来看,首先需要确认当前要计算的元素在C的坐标,然后还需要知道自己需要加载的元素的坐标,这里要加载的元素的坐标和线程在Block里的坐标是相同的,所以实现起来难度不大。
具体实现如下所示:
__global__ void MatmulKernelV3(const scalar_t *a, const scalar_t *b, scalar_t *out, uint32_t M, uint32_t N, uint32_t P) {__shared__ scalar_t As[BLOCK_SIZE * BLOCK_SIZE];__shared__ scalar_t Bs[BLOCK_SIZE * BLOCK_SIZE];const uint32_t x = blockIdx.x * BLOCK_SIZE + threadIdx.x / BLOCK_SIZE;const uint32_t y = blockIdx.y * BLOCK_SIZE + threadIdx.x % BLOCK_SIZE;if (x >= M || y >= P) {return;}// 记 threadX, threadY 为 (x, y) 在OUT块中的位置// threadX = threadIdx.x / BLOCK_SIZE, threadY = threadIdx.x % BLOCK_SIZEuint32_t threadX = threadIdx.x / BLOCK_SIZE;uint32_t threadY = threadIdx.x % BLOCK_SIZE;scalar_t tmp = 0;for (int32_t k = 0; k < N; k += BLOCK_SIZE) {// 加载 A[x][k] - A[x + BLOCK_SIZE][k + BLOCK_SIZE] 到 As// 加载 B[k][y] - B[k + BLOCK_SIZE][y + BLOCK_SIZE] 到 Bs// 计算 SUM(As[threadX][:] * Bs[:][threadY]) 存储到 OUT[x][y]As[threadX * BLOCK_SIZE + threadY] = a[x * N + (k + threadY)];Bs[threadX * BLOCK_SIZE + threadY] = b[(k + threadX) * P + y];__syncthreads();// 注意:这里在矩阵大小<32时会出问题,因为As实际上没装满for (int32_t i = 0; i < BLOCK_SIZE; i++) {tmp += As[threadX * BLOCK_SIZE + i] * Bs[i * BLOCK_SIZE + threadY];}__syncthreads();}out[x * P + y] = tmp;}
实验数据
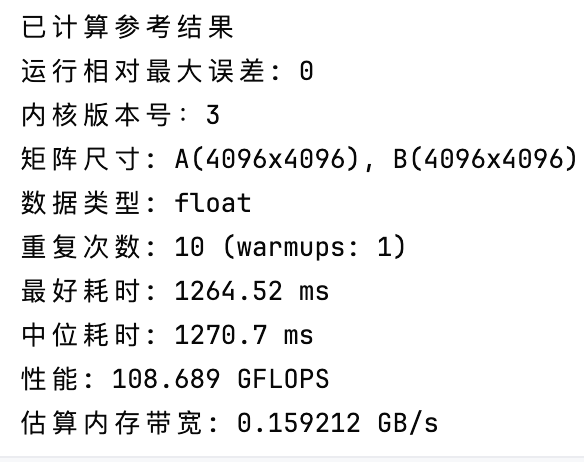
相较于V2,V3的性能直接提升了6倍多,此时的性能是cuBLAS的16%。


















