文本到图像(T2I)生成模型的发展速度超出很多人的预期。从SDXL到Midjourney,再到最近的FLUX.1,这些模型在短时间内就实现了从模糊抽象到逼真细腻的跨越。但问题也随之而来——如何让模型生成的不仅仅是"一张图",而是"正确的那张图"?这涉及到如何让AI理解人类在审美、风格和构图上的真实偏好。
强化学习(RL)成为解决这个问题的关键技术。通过将人类偏好分数作为奖励信号,可以对这些大模型进行微调。群体相对策略优化(GRPO)是近期比较热门的方案。但清华大学和快手的研究团队最近发现,这个方法存在一个隐藏的根本性缺陷。
这个缺陷会让模型学错东西,即便最终生成的图像看起来还不错。论文"SAMPLE BY STEP, OPTIMIZE BY CHUNK: CHUNK-LEVEL GRPO FOR TEXT-TO-IMAGE GENERATION"提出了一个叫Chunk-GRPO的解决方案,思路直接并且效果出众,算是训练生成模型思路上的一次转向。
GRPO的问题:不准确的优势归因
要理解Chunk-GRPO做了什么,得先搞清楚现有方法的问题出在哪。论文把这个问题叫做**"不准确的优势归因"**(inaccurate advantage attribution)。
可以用一个类比来说明。假设你在教学徒做酸面团面包,整个流程有17个步骤。学徒做了两个面包——面包A各方面都很棒,面包B勉强及格。作为师傅,你给A打了高分(+10),给B打了低分(+2)。
标准GRPO的做法相当于告诉学徒:"面包A的每一个步骤都比B好。"它把最终的高分奖励追溯性地分配给制作A的所有17个步骤。
但实际情况可能是,做A的第3步时学徒差点打翻面团,而做B的第3步手法其实很标准。标准GRPO仍然会奖励A的糟糕第3步,惩罚B的正常第3步,就因为最终结果不同。这就是"不准确的优势归因"——模型被强化的某个具体动作,单独看其实是个错误。训练几千次之后,这种错误的反馈信号会让模型困惑,导致训练不稳定,效果也达不到最优。
论文用图像生成的真实案例展示了这个问题: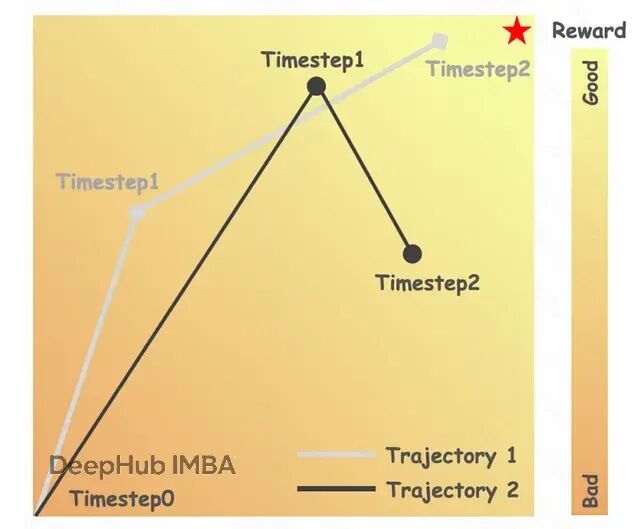
https://avoid.overfit.cn/post/801e16bc6ddb464bbeb532f74cdceb91
















)

