接CNN
如何解决一堆向量的问题?
输入
一个单词一个编码,一句话是一堆向量

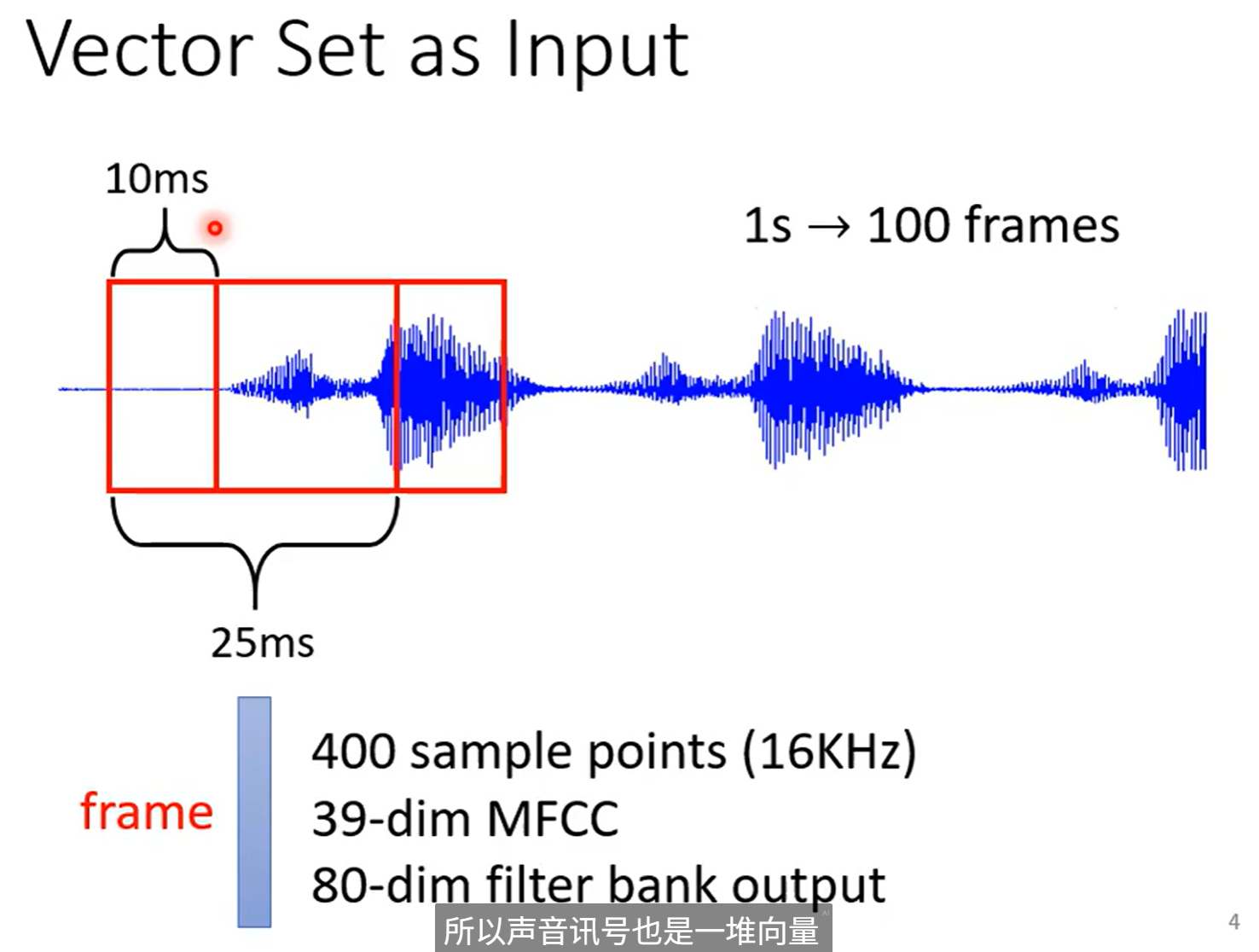
声音信号是一堆向量
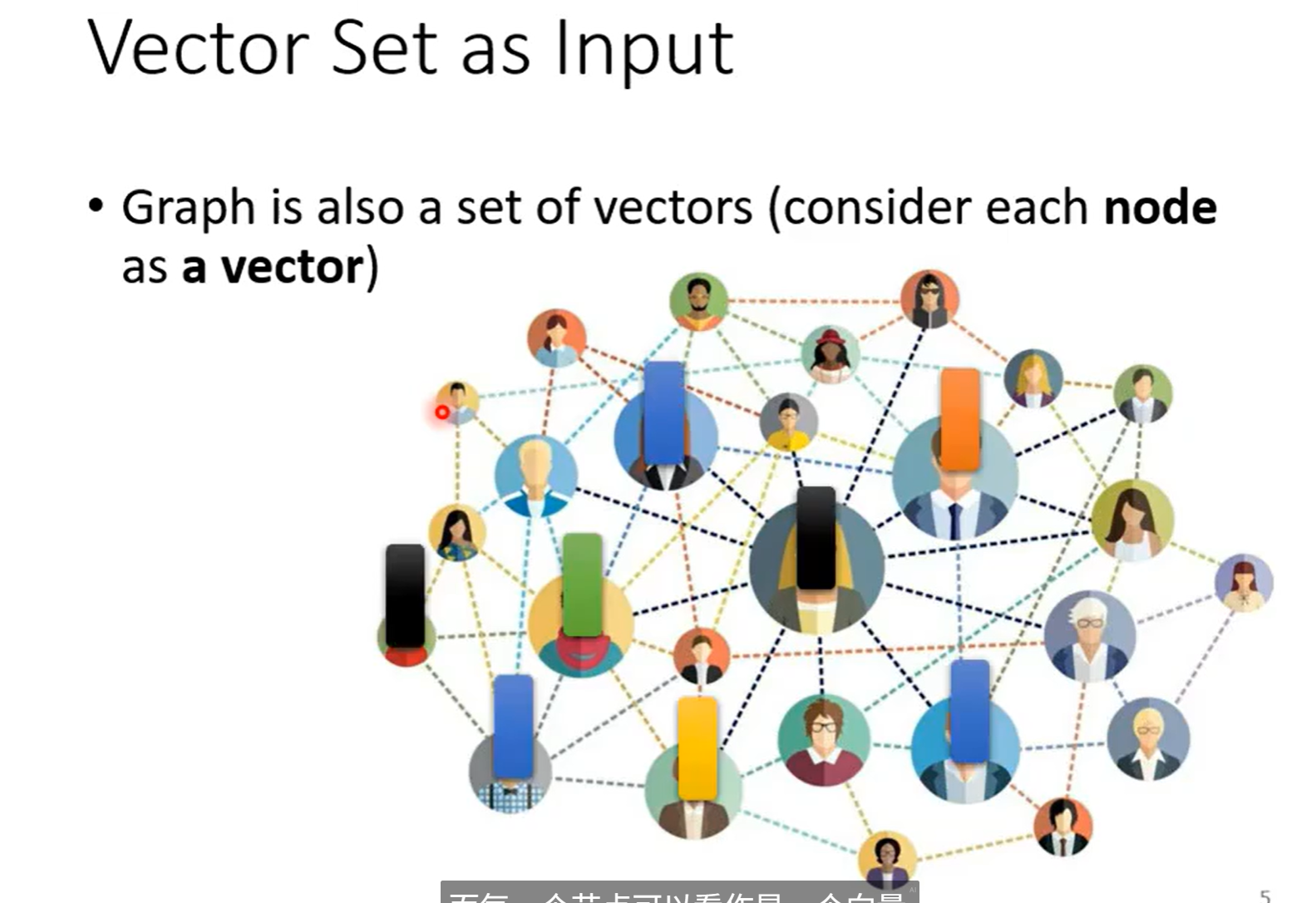
一个图也是一堆向量

输出
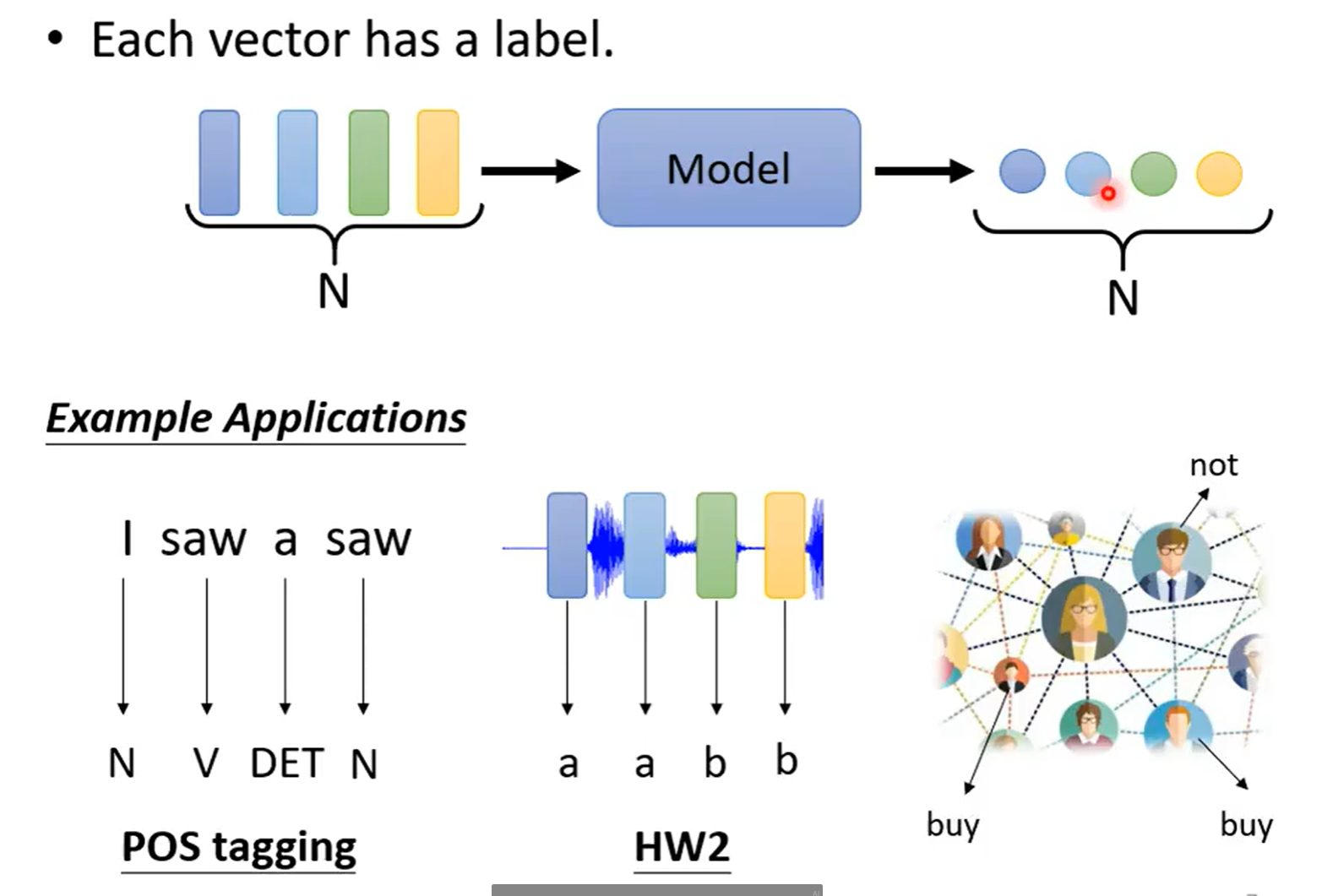
输入多少,输出多少(Sequence labeling)
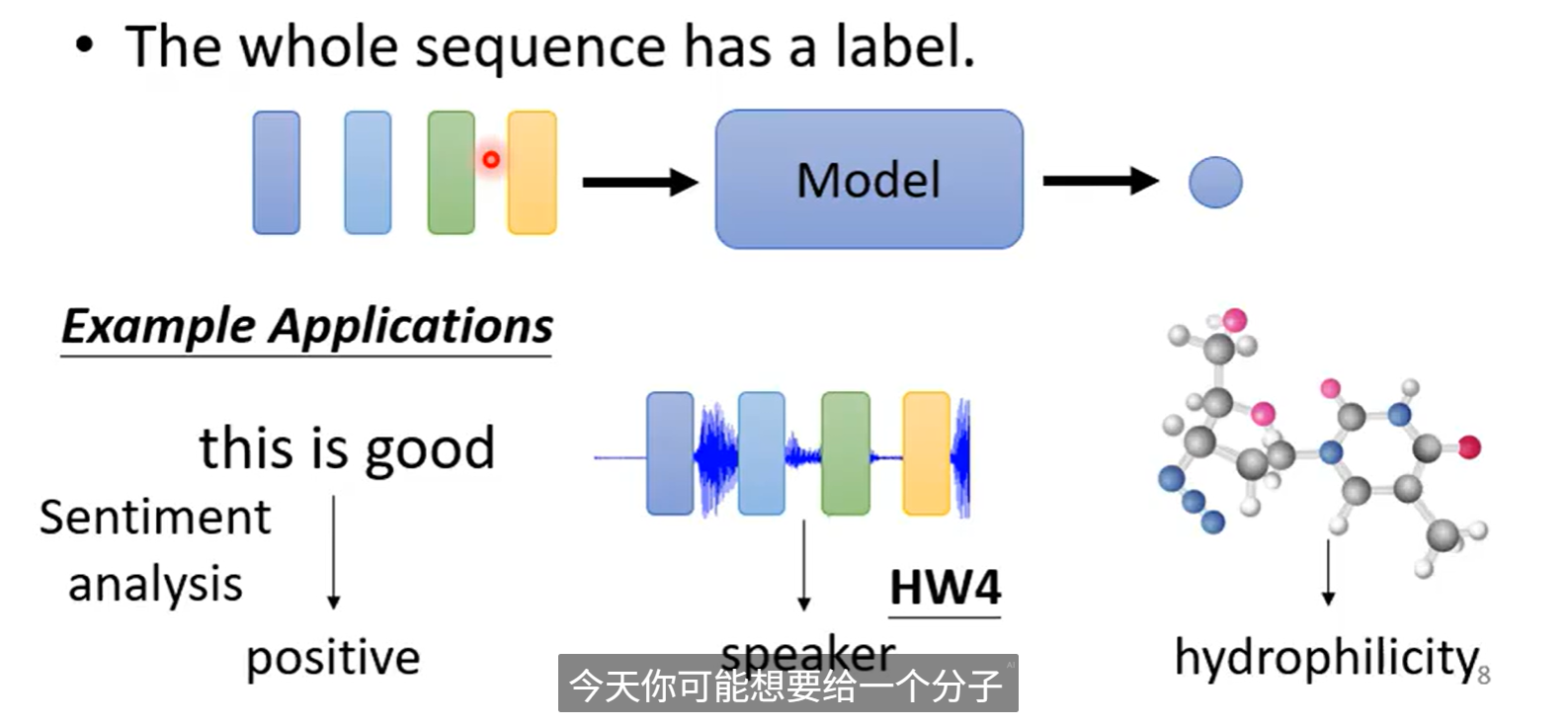
输入很多,输出一个
输入很多,但不知道输出多少,让机器自己决定
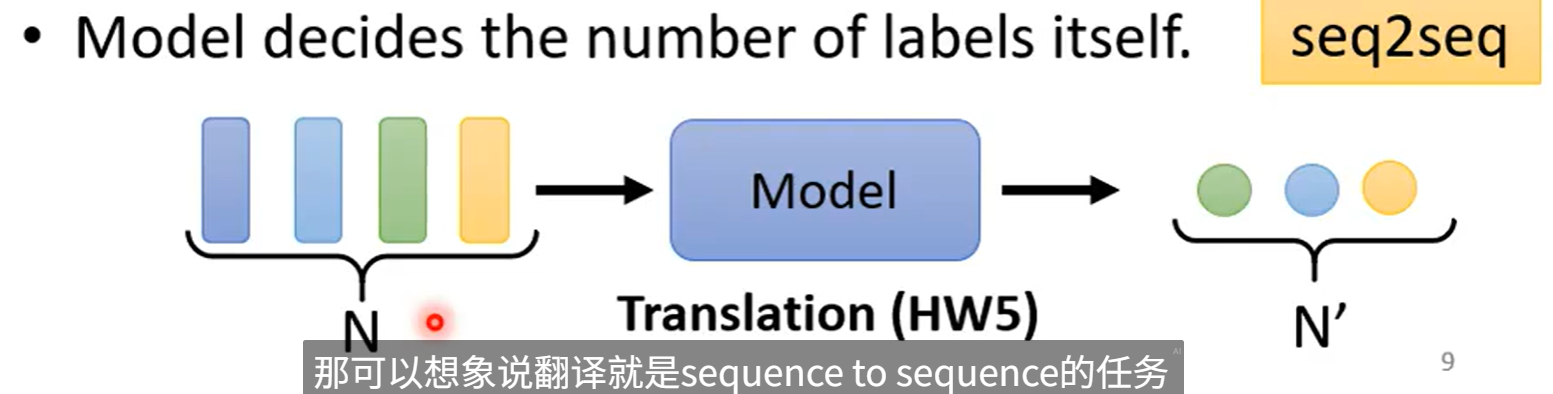
输入多少,输出多少(Sequence labeling)
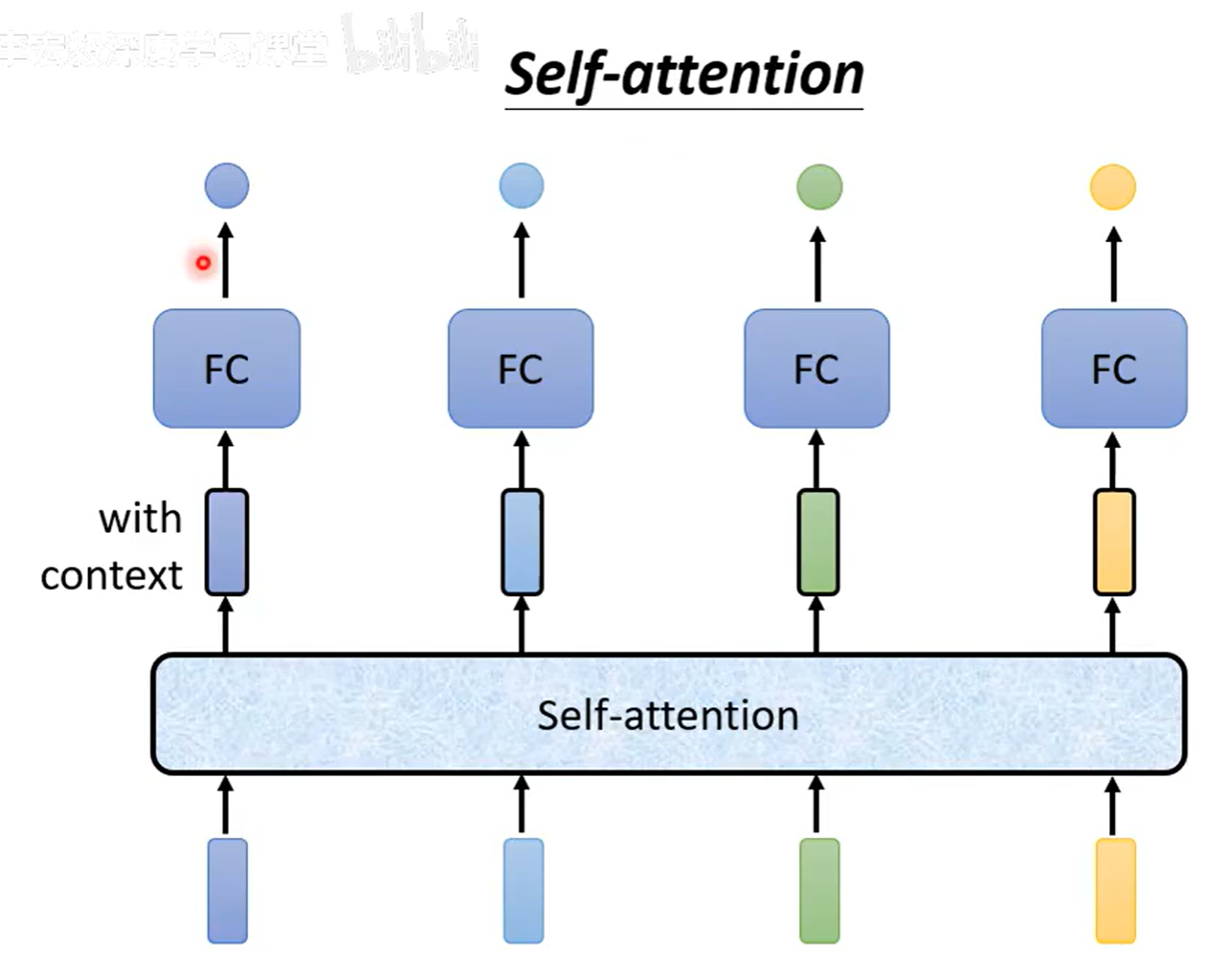
self-attention 会考虑所有的上下文,得到特定的向量
FC 是 fully connected
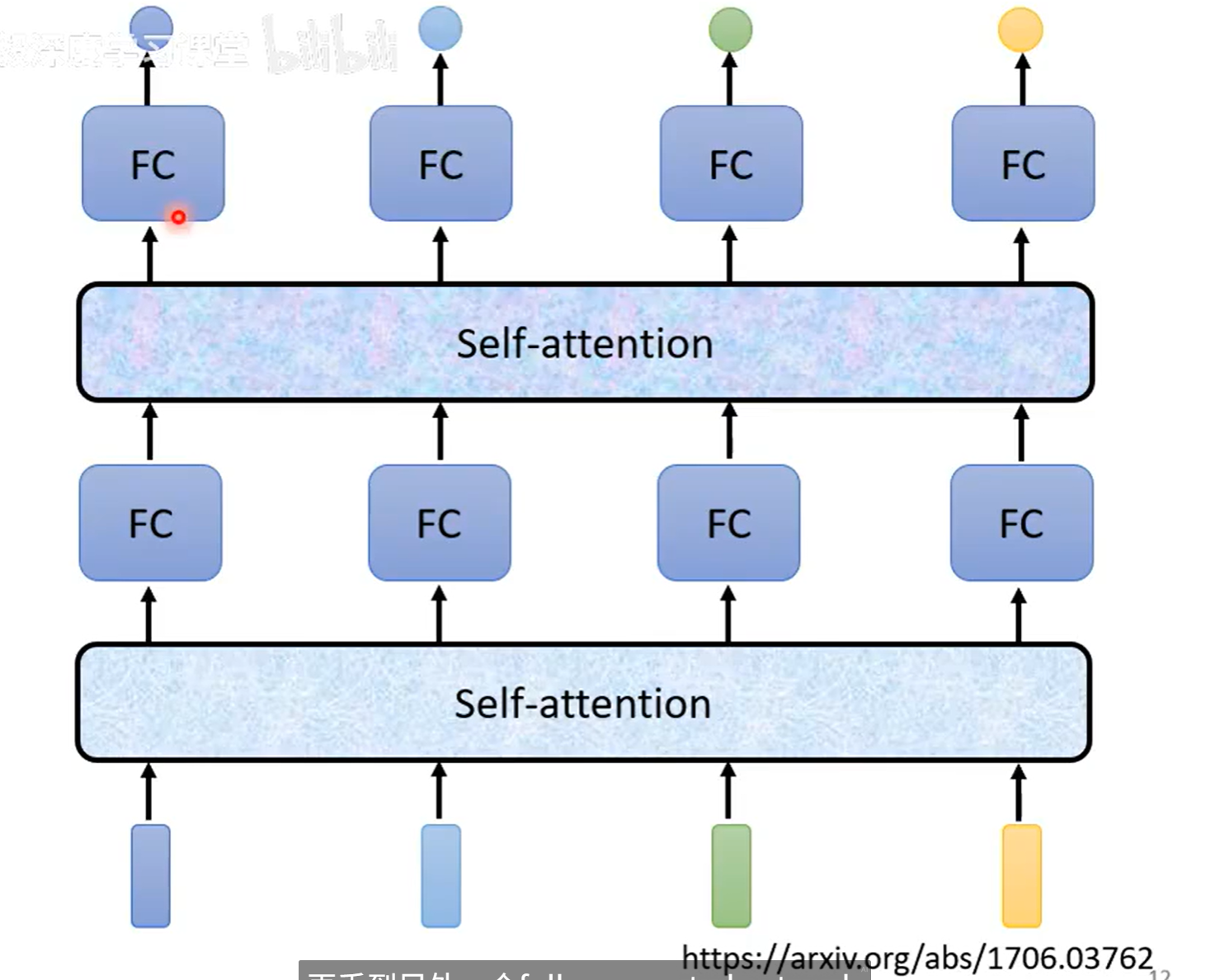
self-attention 可以叠加很多次
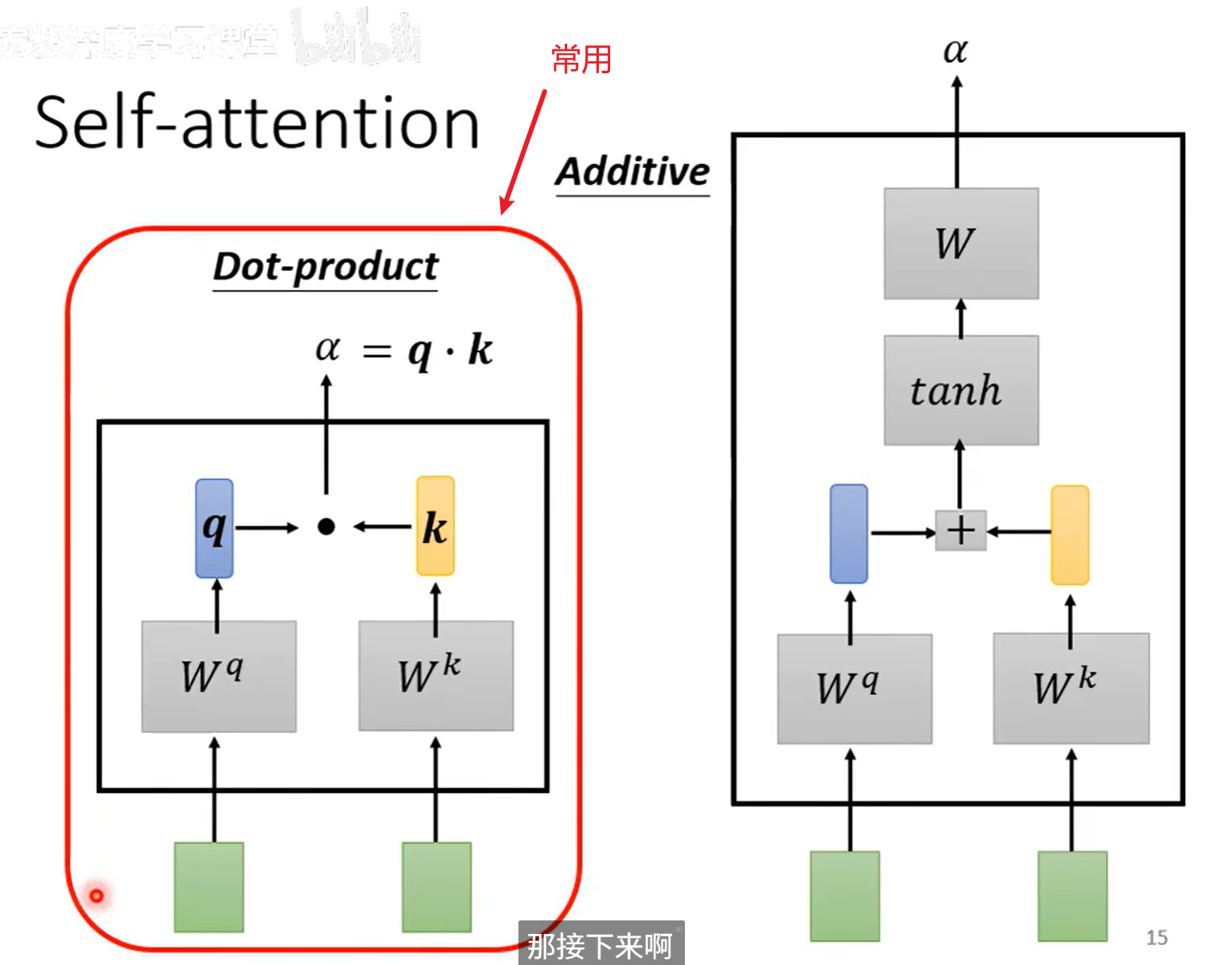
self-attention 是怎么运作的
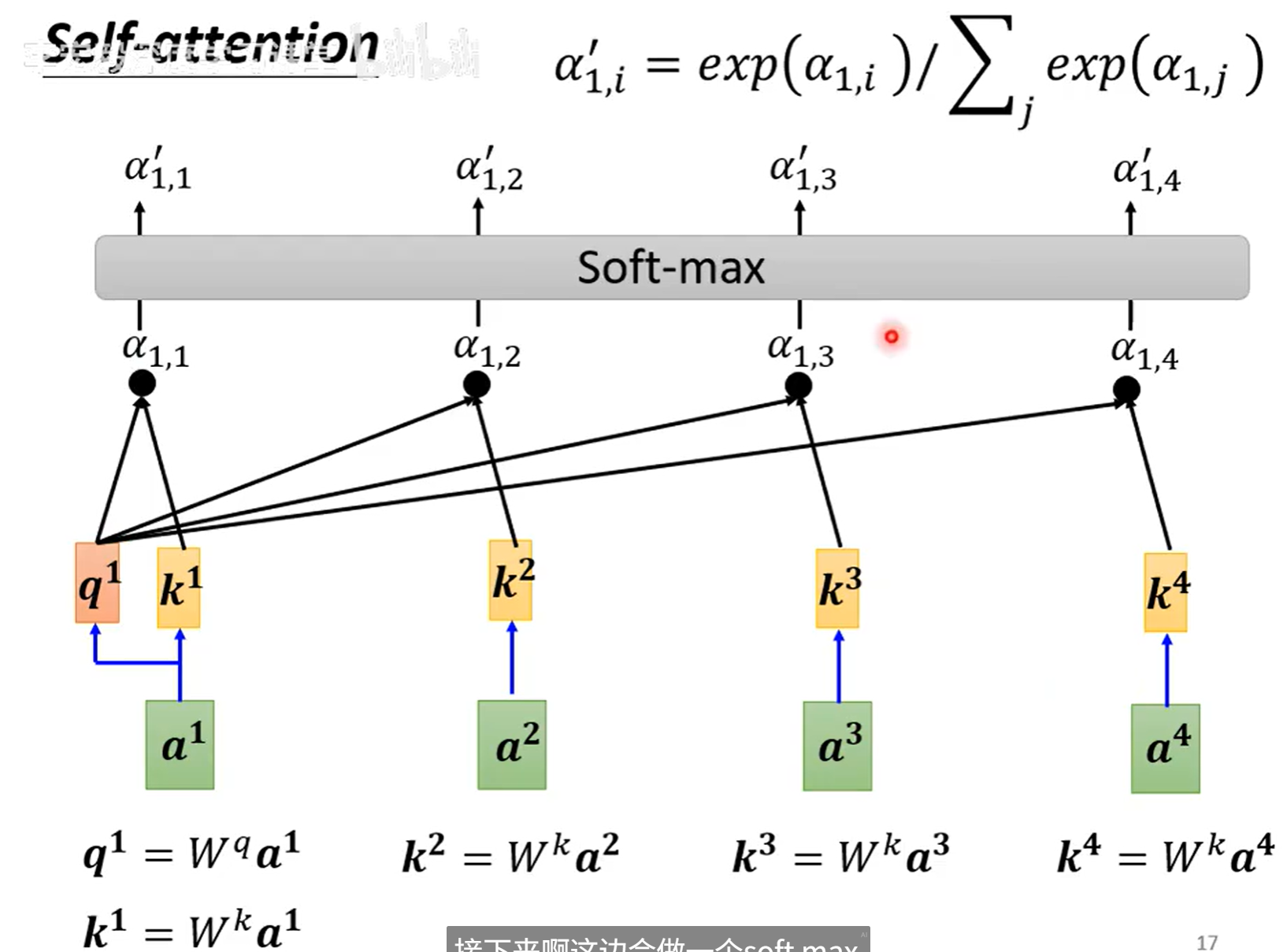
计算\(\alpha\)
\(w^q和W^k\)是两个矩阵,输入分别和\(w^q和W^k\)相乘得到矩阵q和k,q和k相乘得到\(\alpha\)
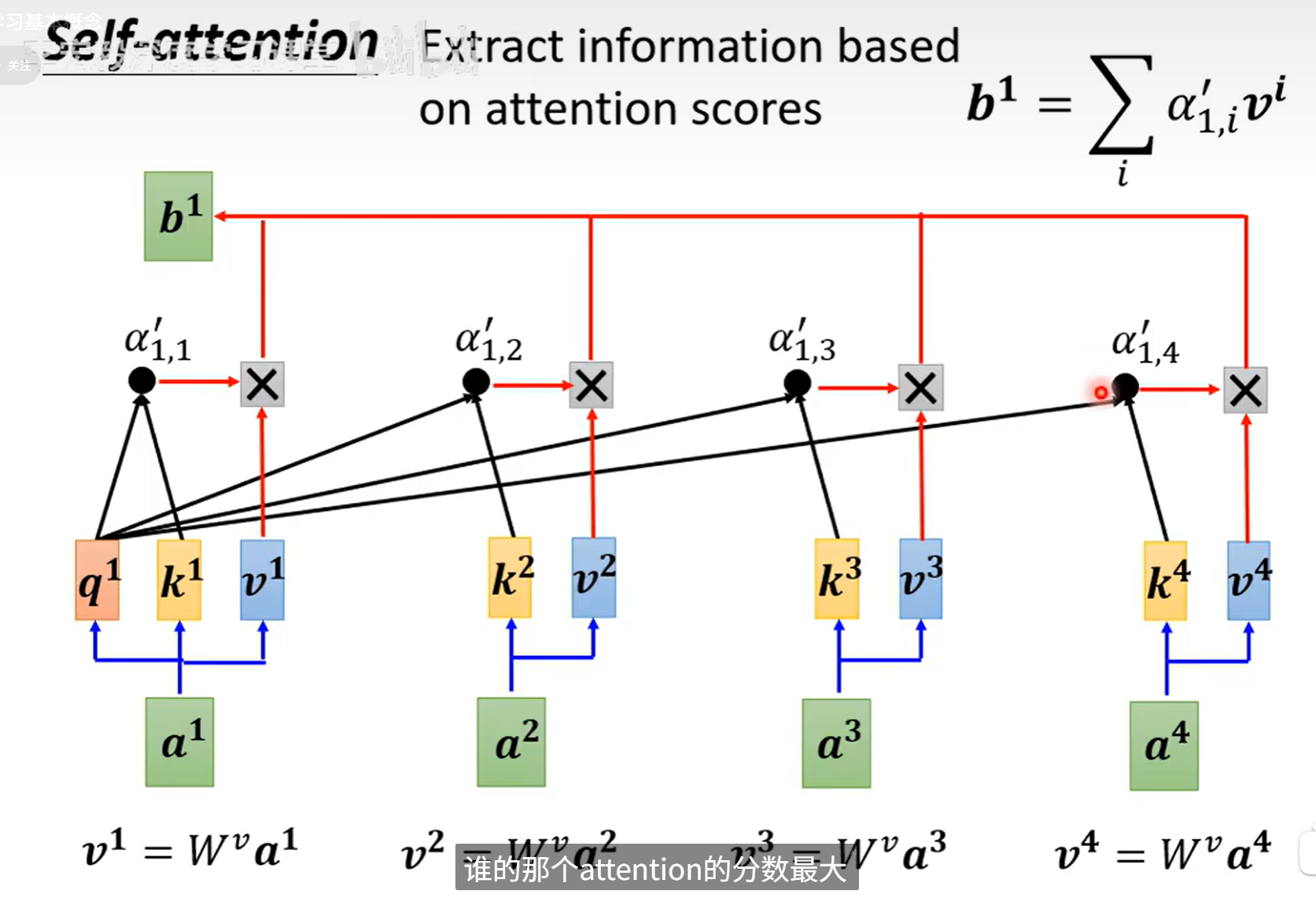
计算完之后知道哪个和a1是最有关联性的 ,然后根据这个关联性抽取资讯
假如a1和a2关联性最大,最后得到的b1可能和a2比较接近
完成上面的计算是一次性完成的(用矩阵)
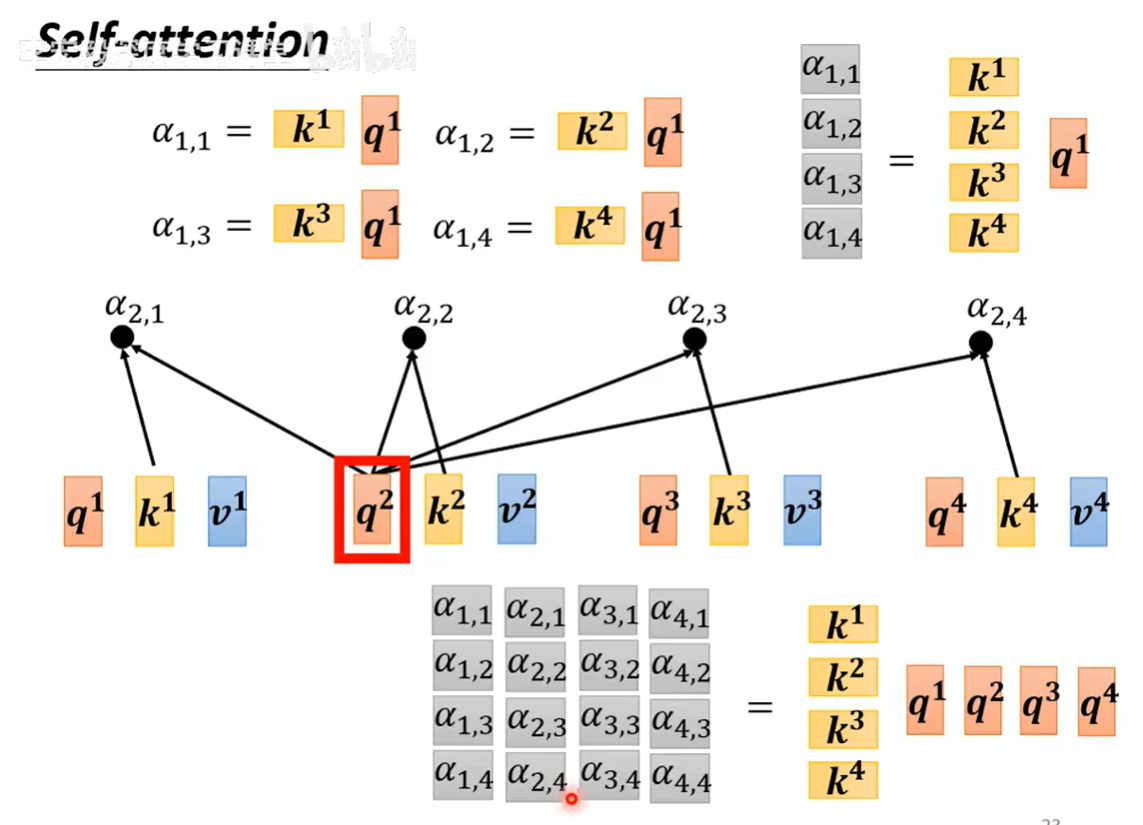
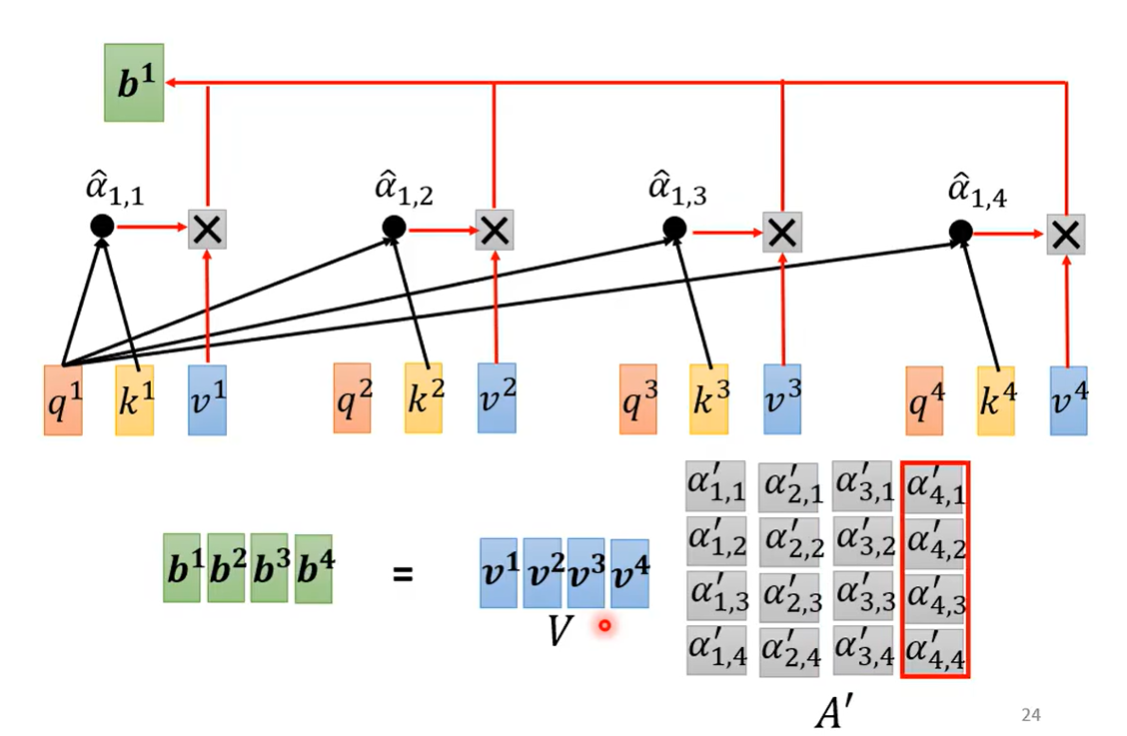
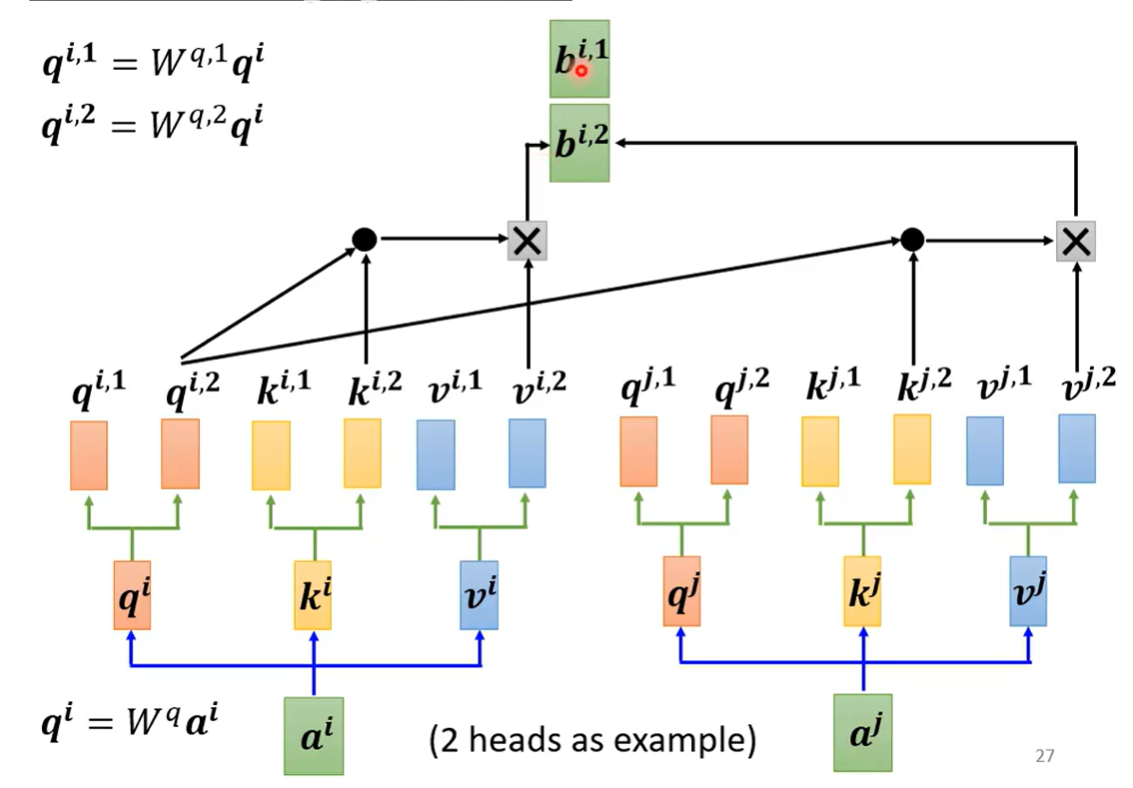
同时可能有很多的特征\(q\)
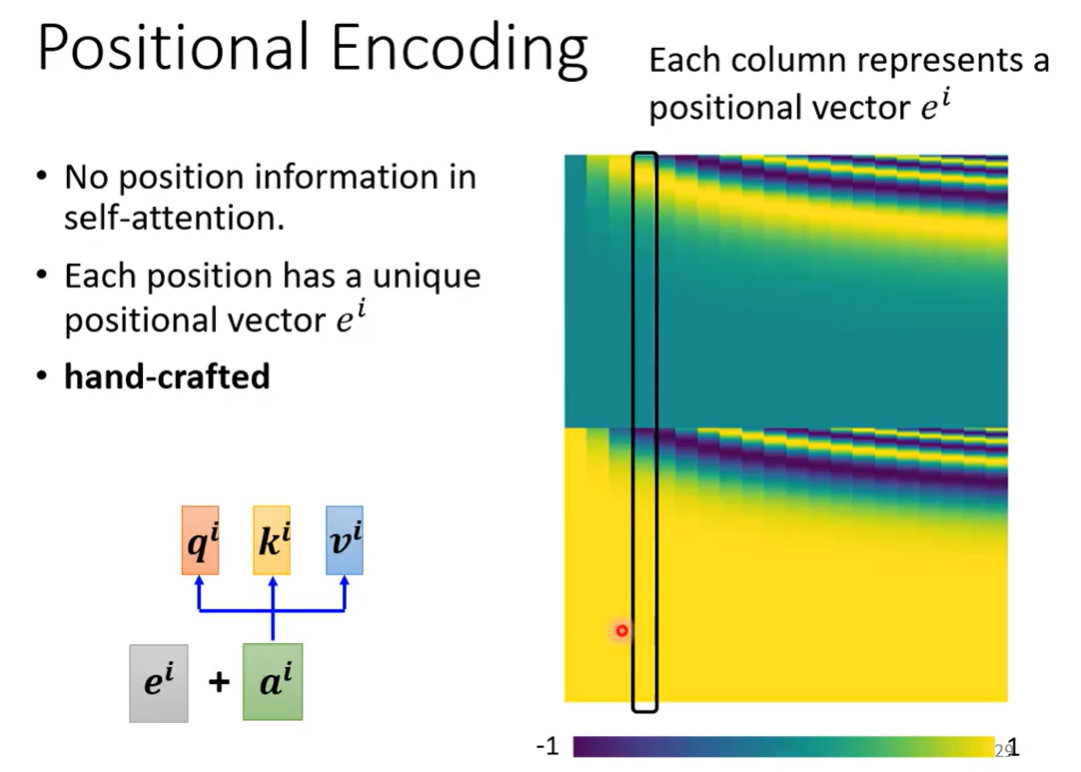
可以给每个输入加上一个位置positional Encoding
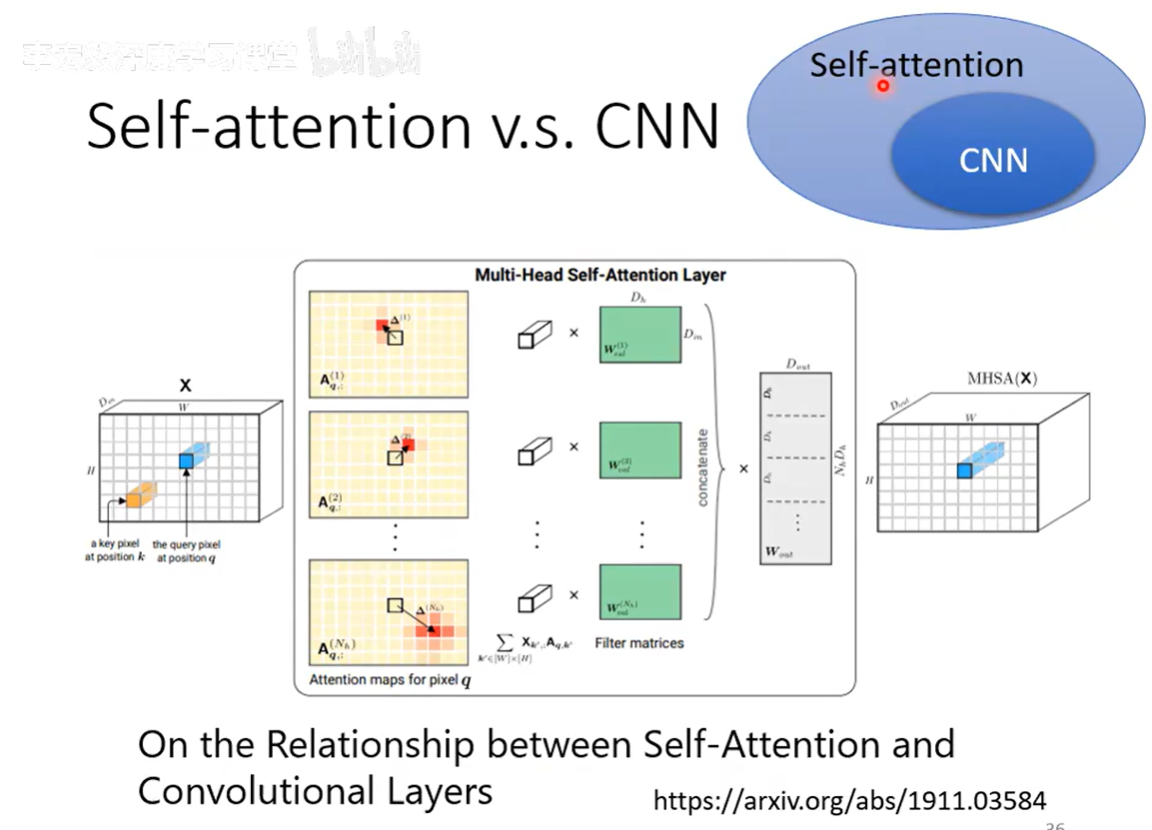
Self-attention也可以做图像
如果把\(Self-attention\)加上一些限制就是CNN
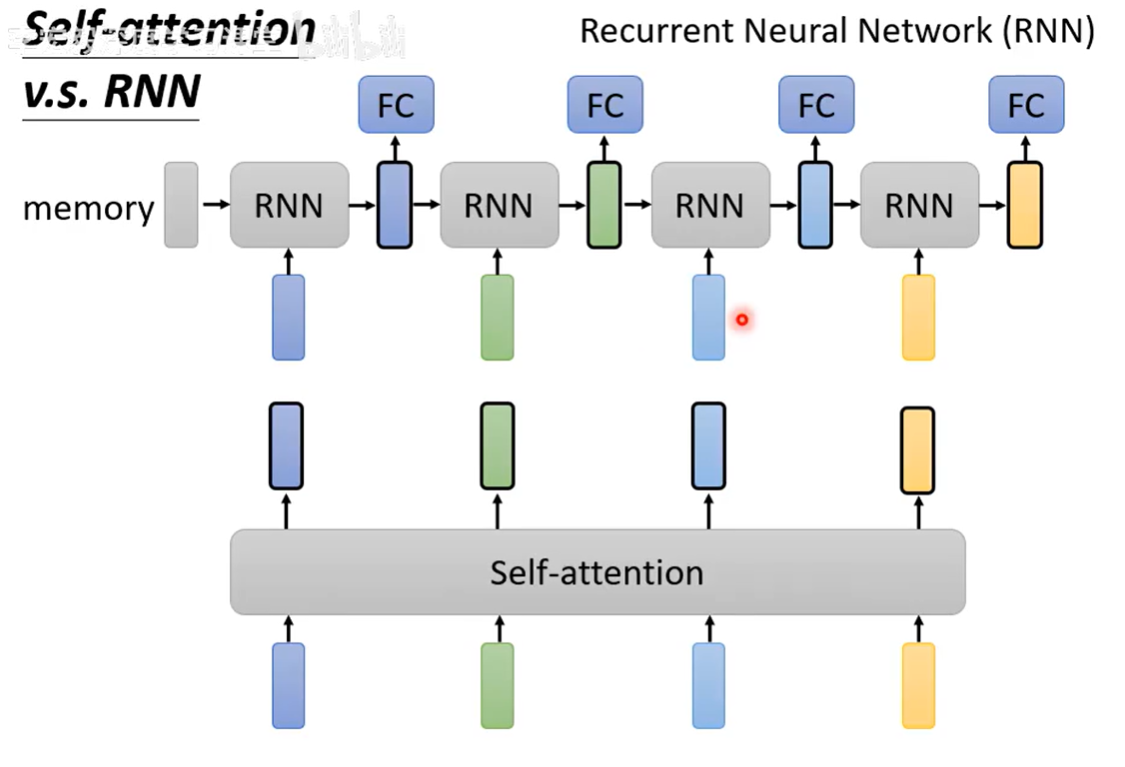
Self-attention VS RNN
RNN 会考虑前一个的输出,把前一个的输出当作下一个输入的一部分,而Self-attention是考虑全体
但是内存等有限,不可能全部一次性放入内存,则分批次
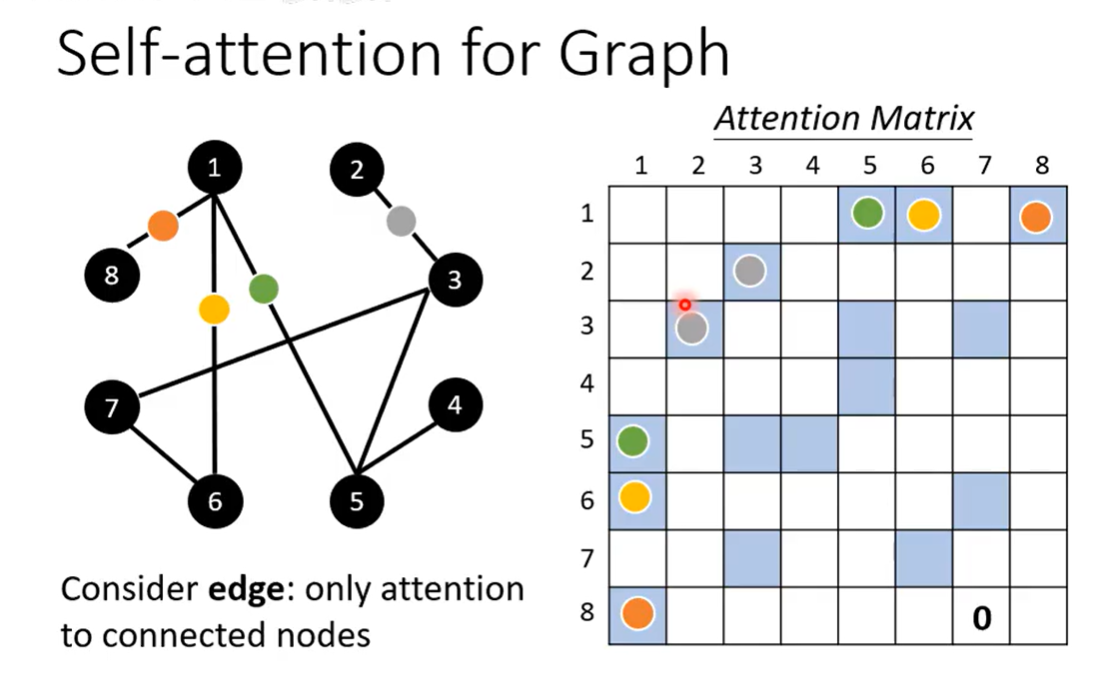
Self-attention 也可以用在图上
只考虑有联系的,互相之间有路径可走的
 Personality Test Online)
)















公司专业供应多型号钢管且服务完善)

