1、安装 LLaMA Factory
输出:检查LLaMA Factory版本,日志或截图。
2、更新数据集
输出:样本数据集(zh.test.csv)处理后形成微调训练格式的json文件,部分数据或截图。
<数据集>
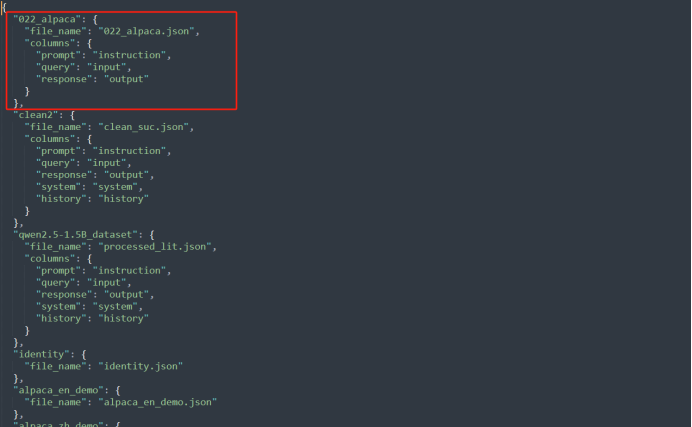
dataset_info.json文件指定
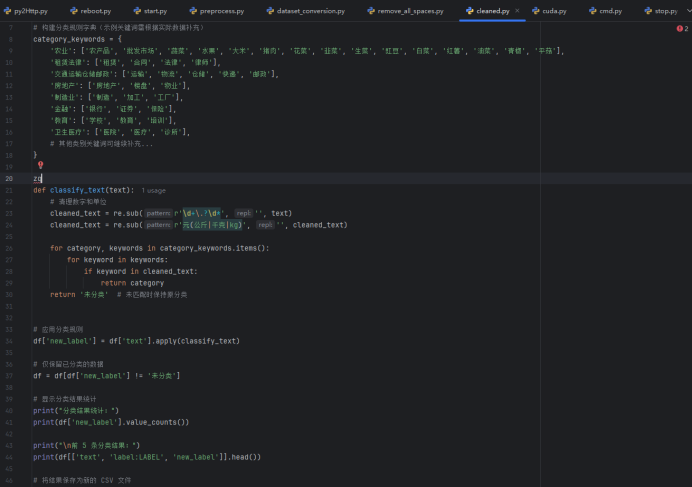
(1)格式转换,将原始数据集csv文件转换为Alpaca格式的json串,且符合LLamaFactory的指令监督微调数据集并且支持大模型Qwen1.5-0.5B训练,格式转换要求,将text列的文本内容转换为json文件的“人类输入”input字段的值,将label:LABEL列类型转换为json文件的“模型回答”output字段的值,json文件的指令instruction的值为“对文本进行分类”
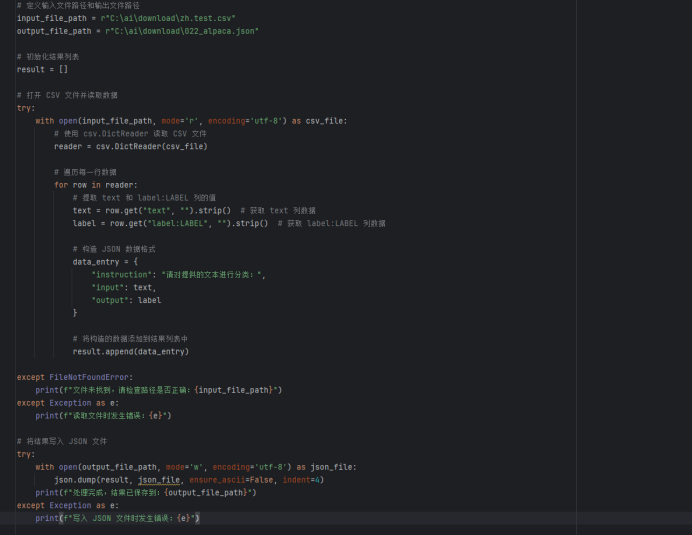
(2)数据清洗:去除空格、无效符号、对文本类型重新分类
去除空格:
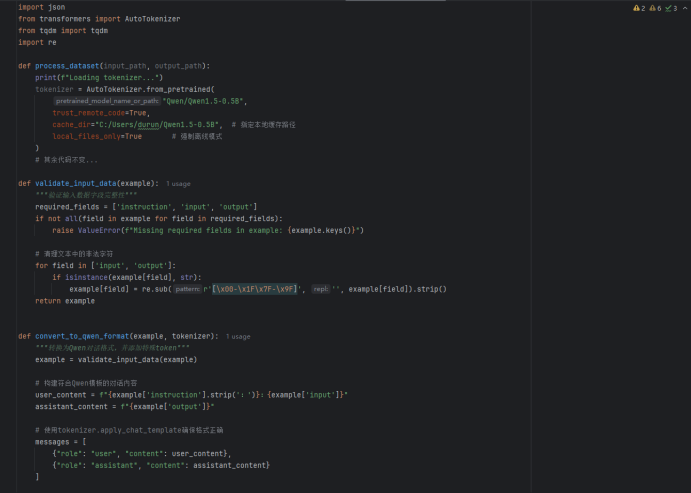
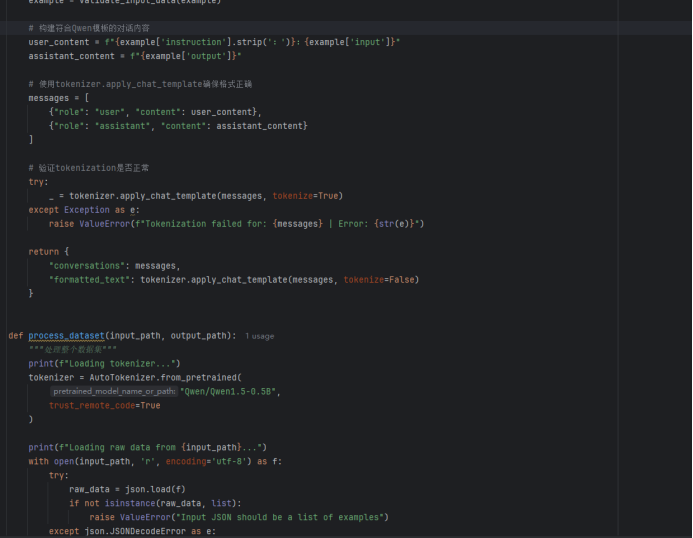
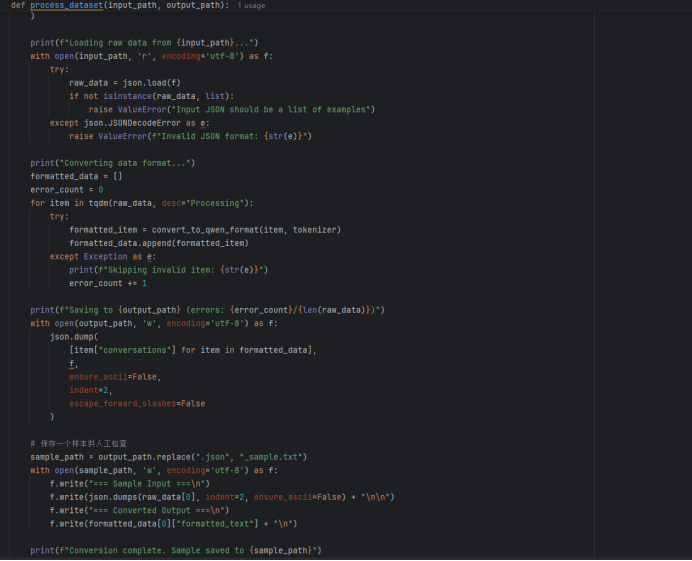
重新分类:
3、使用命令行或WebUI微调模型
输出:微调命令或WebUI执行完成后日志或截图。
<base模型>
chinese-bert-wwm或qwen2.5_0.5b
本地使用从魔塔社区下载的Qwen1.5-0.5B模型
训练完成截图
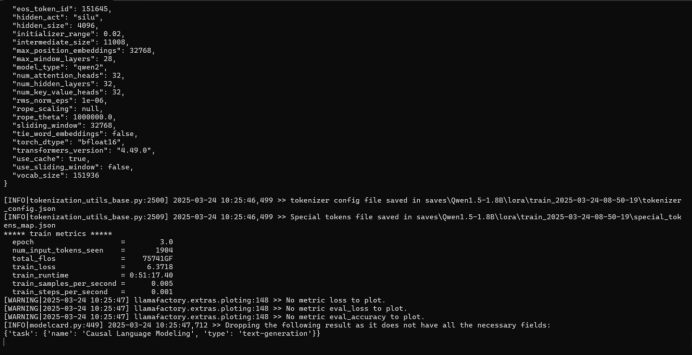
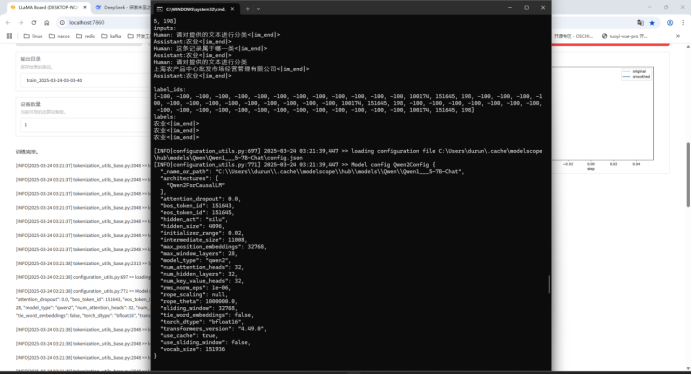
4、模型推理
输出:用微调后模型推理输出三条样本数据的结果,输出结果与样本数据集中分类一致,日志或截图。
选择训练后的模型,选择其中0324的版本进行验证
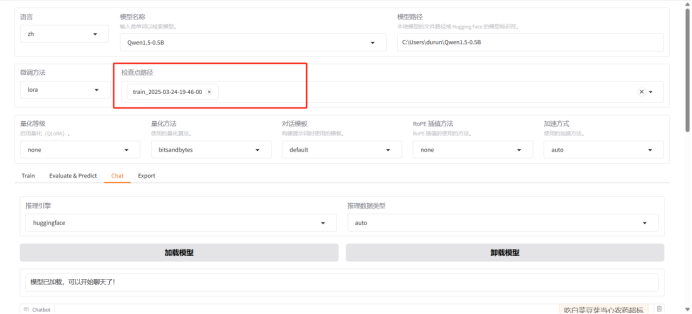
使用input对模型进行提问:
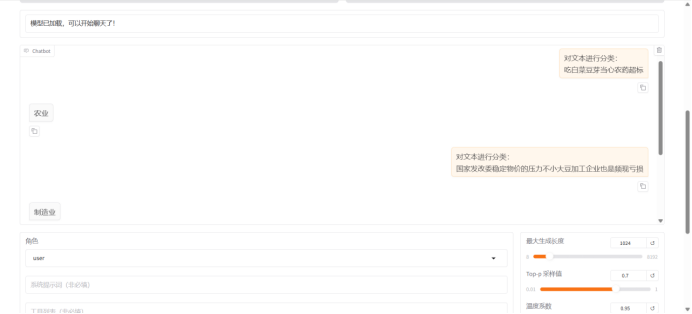
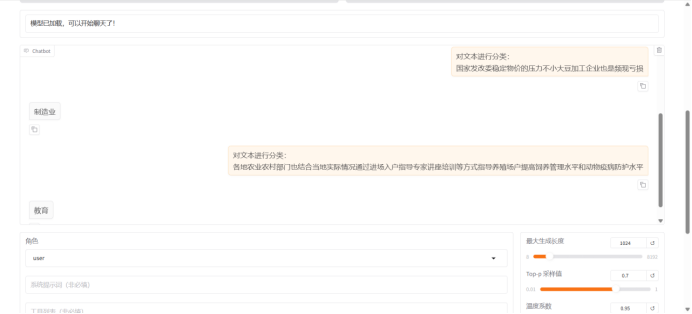
通过以上问答结果可以看出,指令监督微调训练成功了。
学习总结(非AI生成):
问题1:数据集应该怎样准备?
实践过程:本次demo实施指令监督微调,选用alpaca的数据集格式
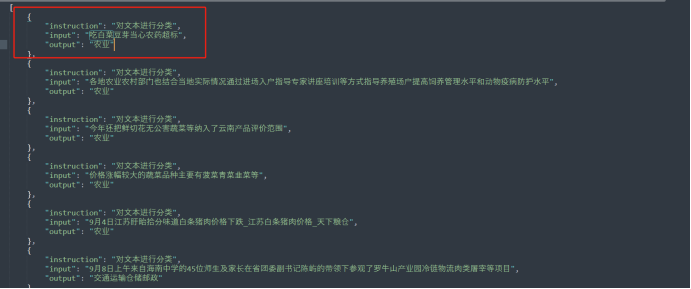
{
“instruction”: “对文本进行分类”,
“input”: “漳州华安离婚财产分割法律知识”,
“output”: “租赁法律”
}
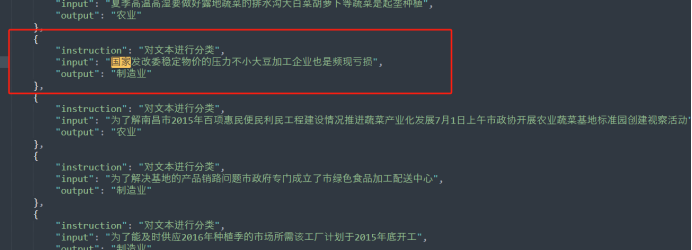
由于训练一直达不到预期效果,对数据进行重新清洗,将所有特殊的符号和空格进行整理,然后重新分类,分类时遇到一个问题,有很多文本的内容是摸棱两可的类型,所以在python生成脚本时,指定了按照文本包含的字段进行分类,比如包含’农产品’, ‘批发市场’, '蔬菜’的文本分类农业等,然后将能够分类的文本提取4000多条进行训练。
问题2:大模型应该怎么选型?那种模型适配本机设备Gtx1060显卡的显存
实践过程:最开始下载的模型为Qwen1.5-7B,由于体量太大电脑显存无法流畅的运行,换成Qwen1.5-0.5的模型进行训练,Qwen1.5-7B虽然精度较高显存占用为28G,但是对于Gtx1060属于超符合运行,如果不是开启4方量化,估计很难跑起来,于是选择了显存只占2G的Qwen1.5-0.5,虽然能力没有7B强,优势是可以在显存更小的机器上训练,并且能够满足文本分类指令微调的这种小demo。
问题3:大模型训练
实践过程:
对页面各种参数进行微调、调优
最开始使用500条、1000条、5000天等数据进行训练,学习轮次为1轮,学习率5e-5,批量8,梯度2,开启混合精度fp16,使用lora微调
后续优化:核心参数(学习轮次:10,验证集:0.2)
问题4:对“训练后”的大模型进行验证,始终没有实现预期效果
排查过程:
由于验证无效,之后更改了近10次配置后进行训练,一直无法让模型根据json文本的output进行输出,最终查阅相关资料解决,这里有一个致命的点就是过于依赖ai的问题排查思路,
出现了问题后直接抛给ai,由于ai并未回答出训练无效的真正问题点,以至于后续排查脱离问题点,时间浪费巨大,所以在之后的学习和工作中一定不能过度依赖ai。
这个问题我的最终解决的办法是在llamafactory的webui界面的检查点路径设置上选择执行后的模型进行测试,发现大模型能够按照数据集提供的output进行输出,对于指令监督微调的理解我的个人理解是:在AI模型问答上给定语言标记来触发指定答案进行输出。
)
)



带论文文档1万字以上,文末可获取,系统界面在最后面。)


)










