1. 如何设计数据库

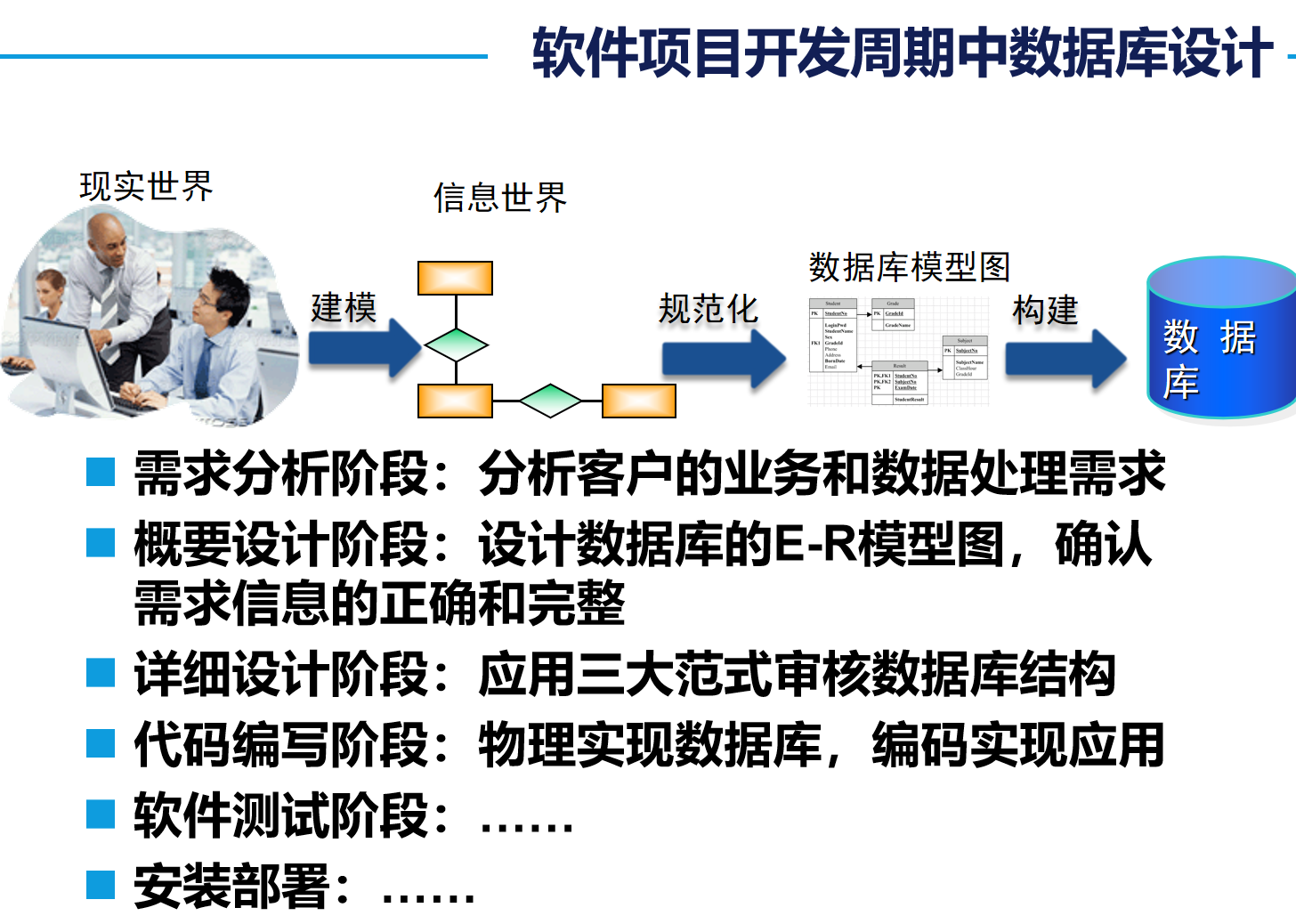
设计数据库步骤




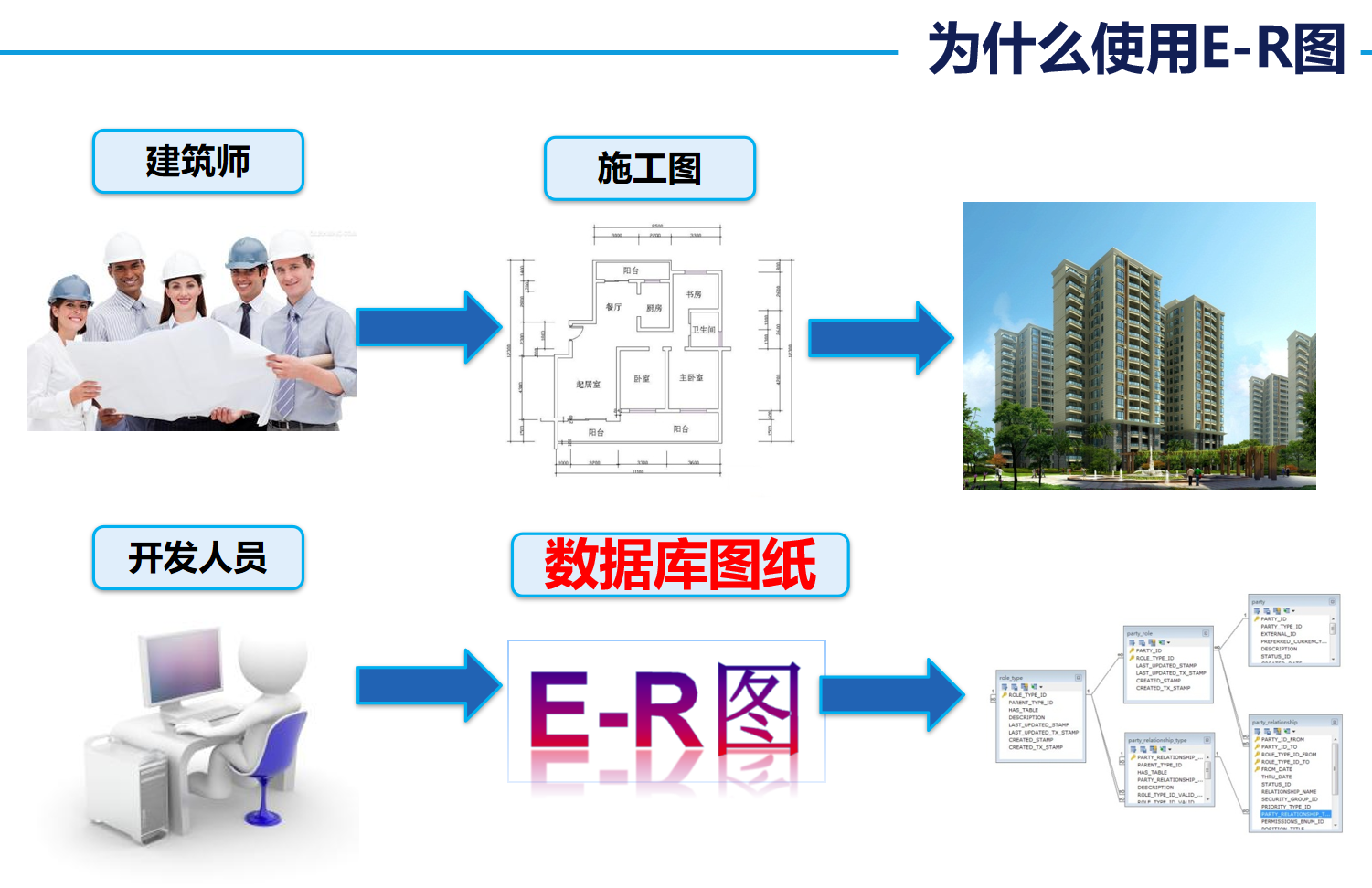
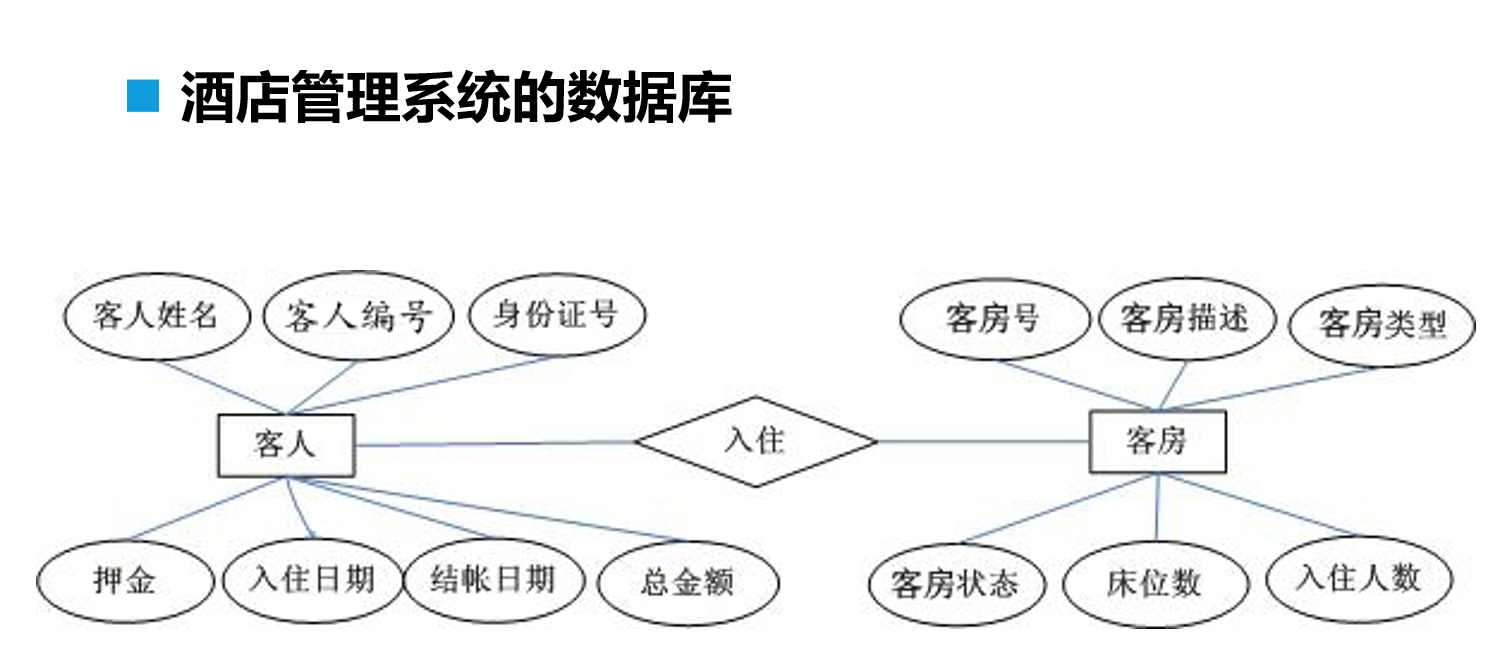
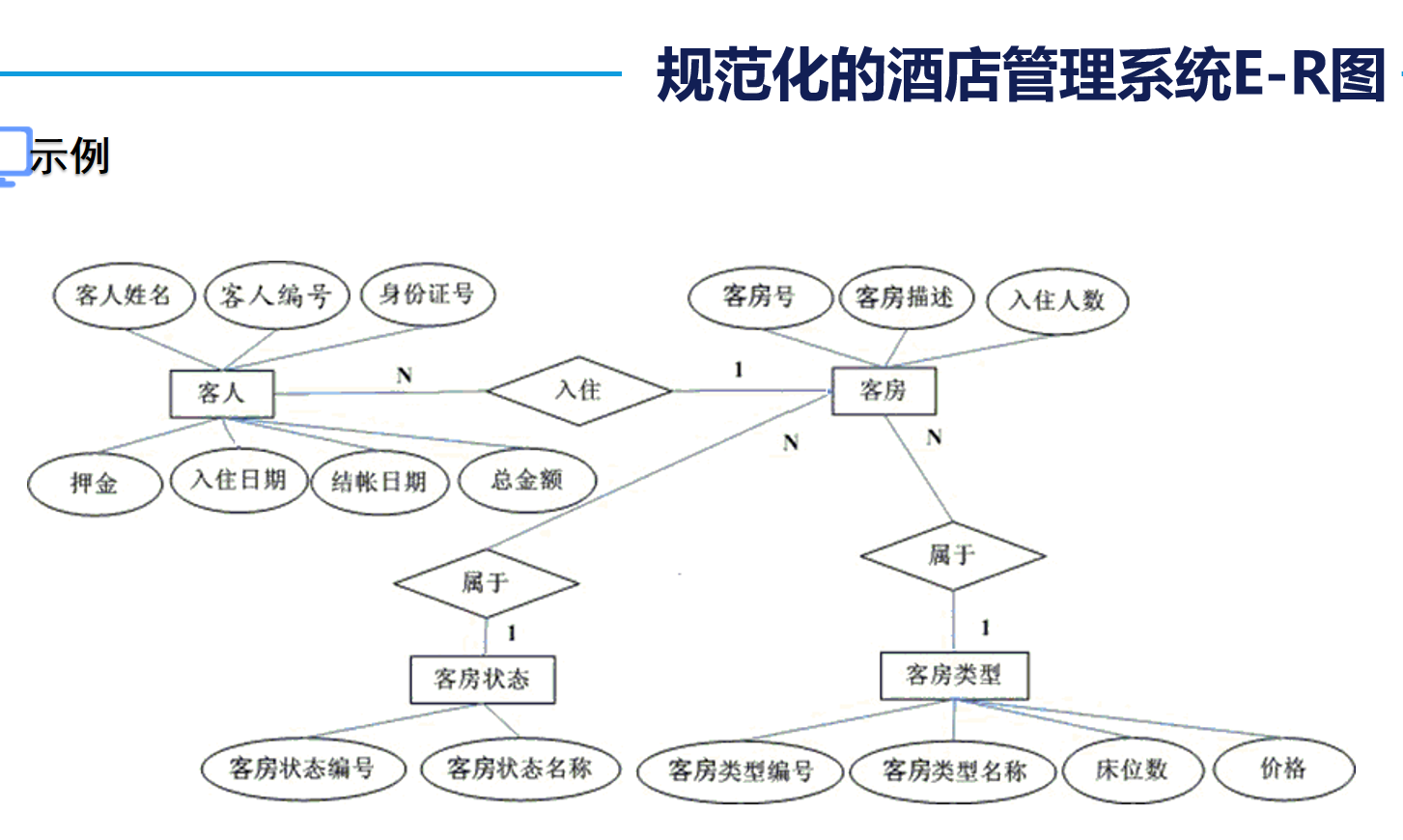
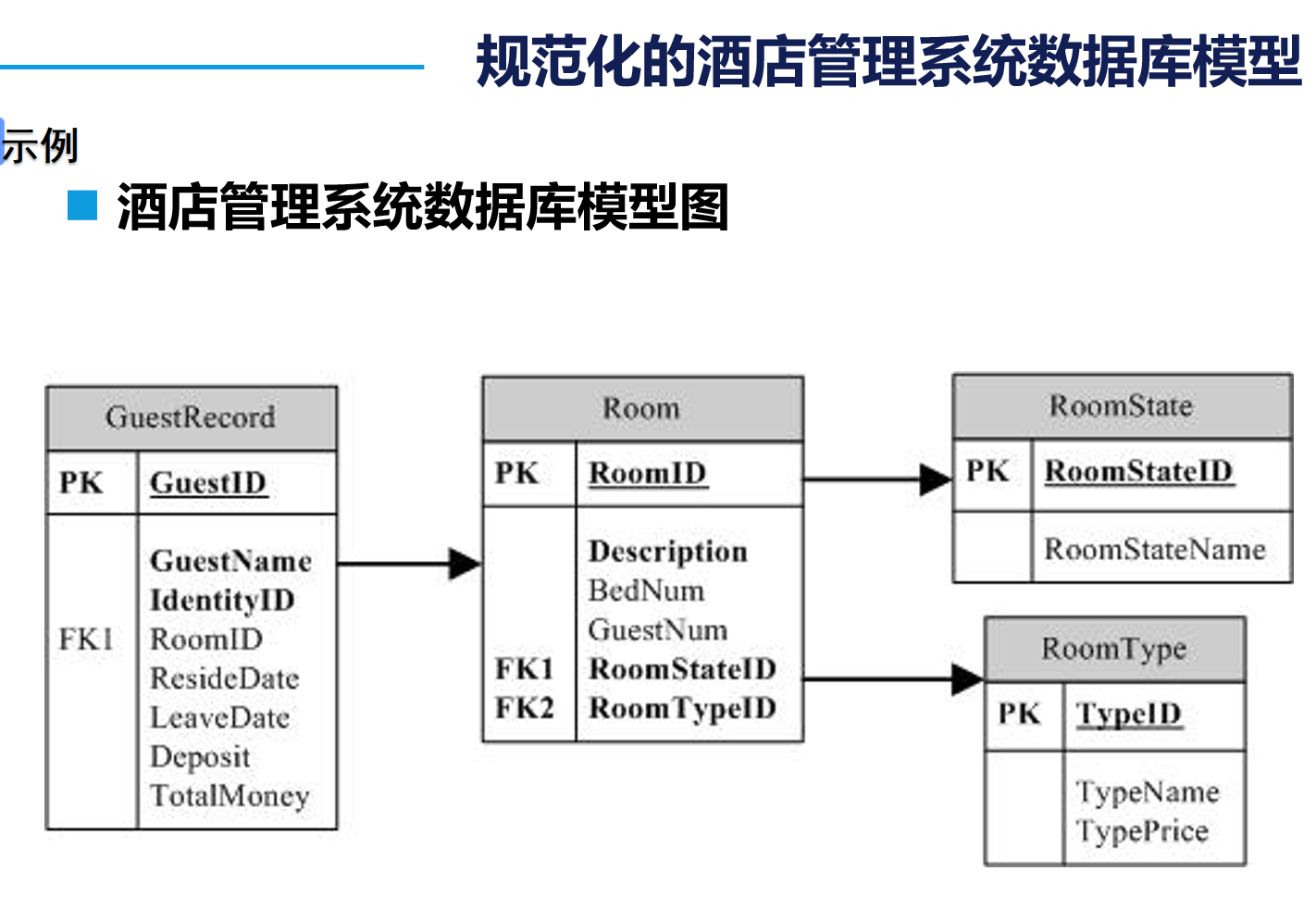
2. E-R图的使用
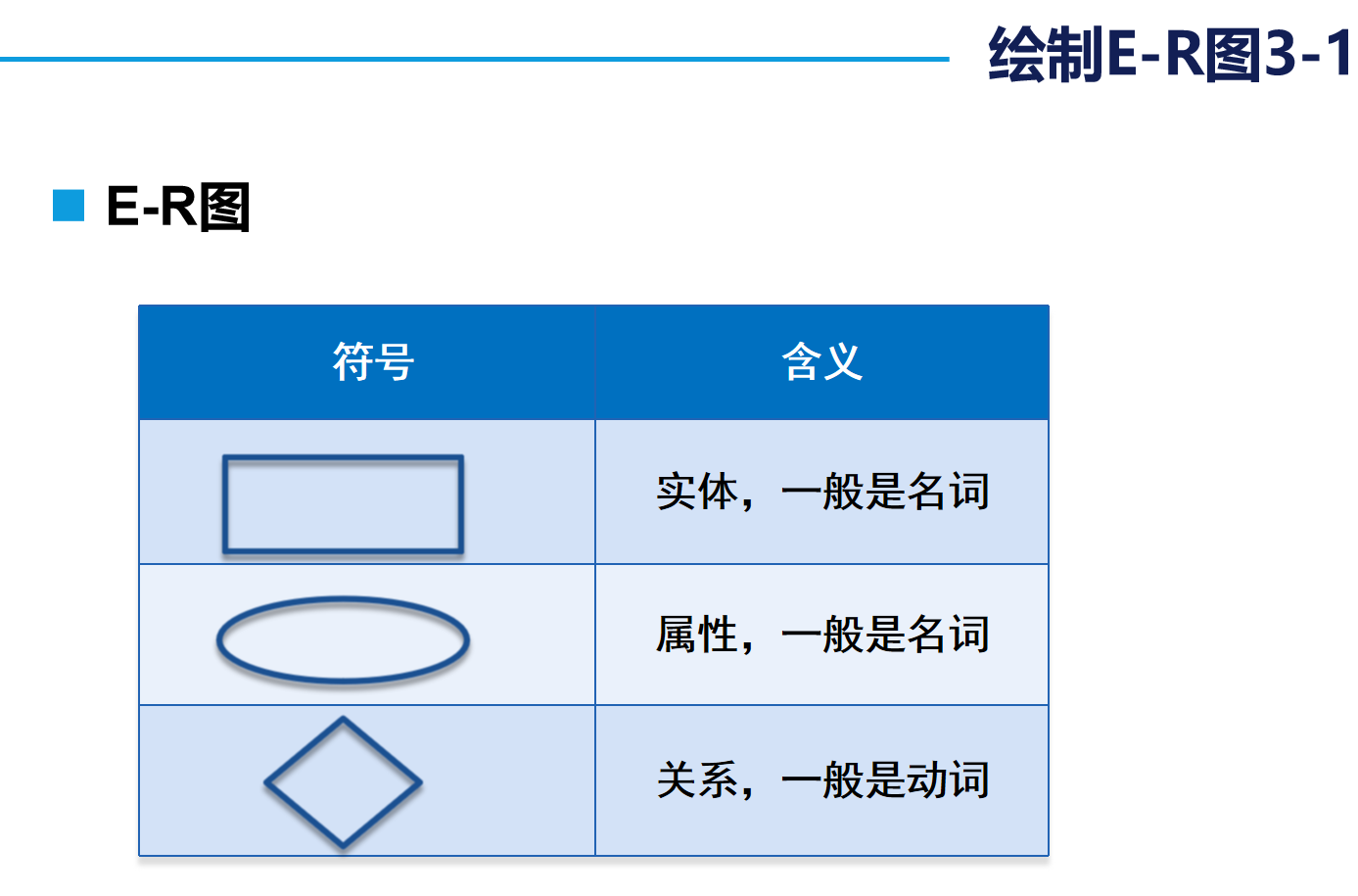
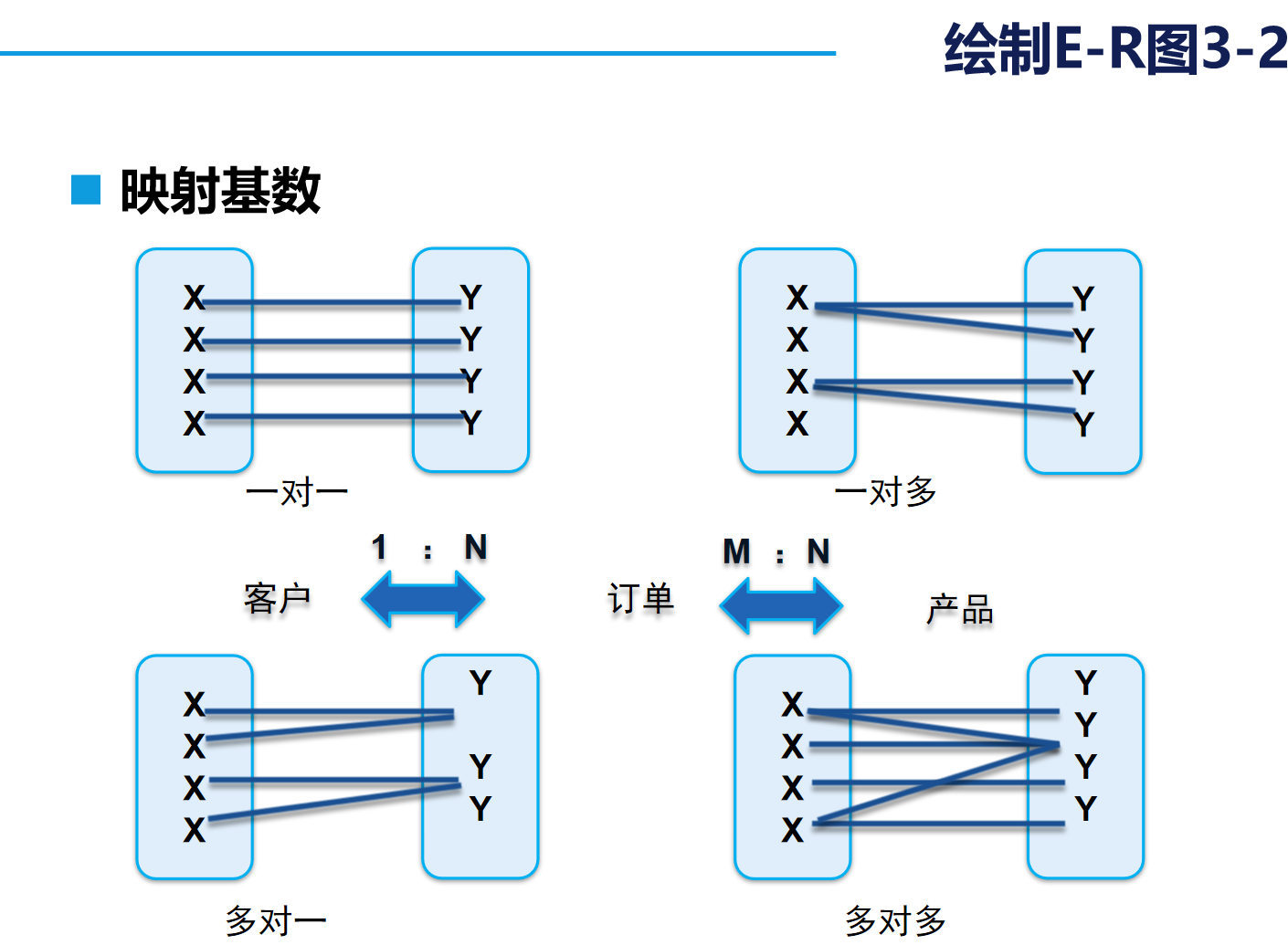
我们在日常设计的数据库多为“一对多”和“多对一”

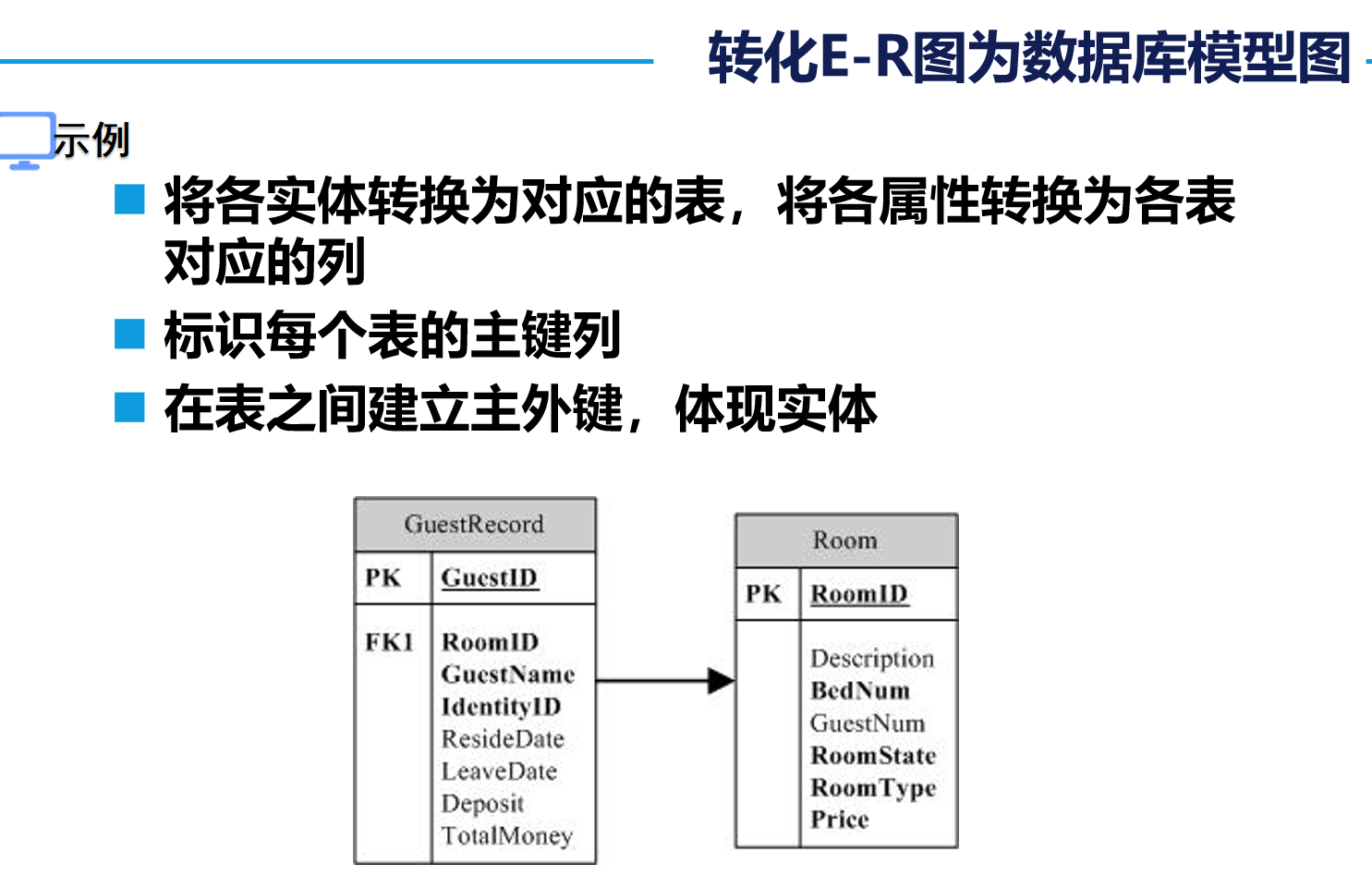
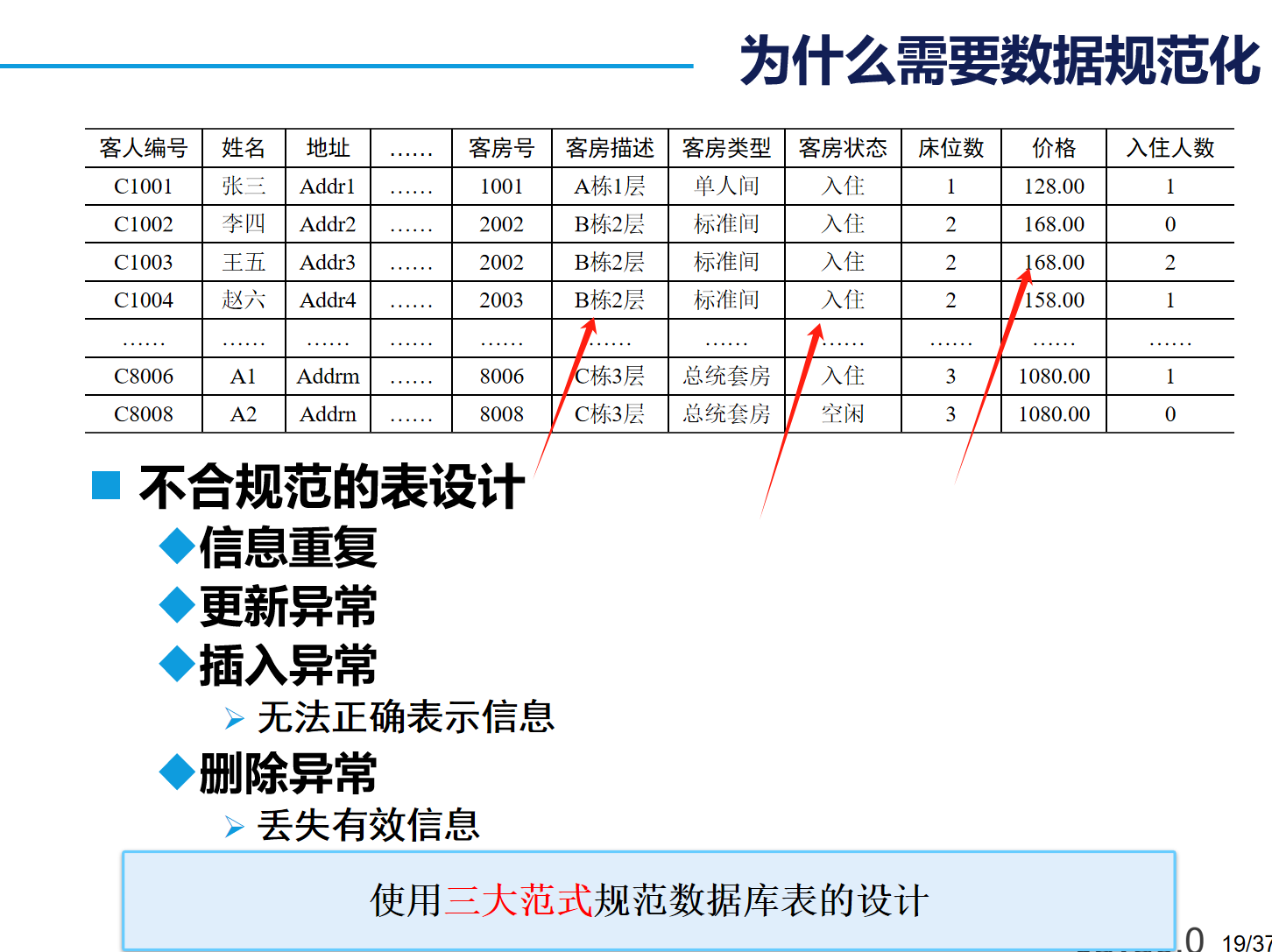
3. 设计数据库三大范式⭐
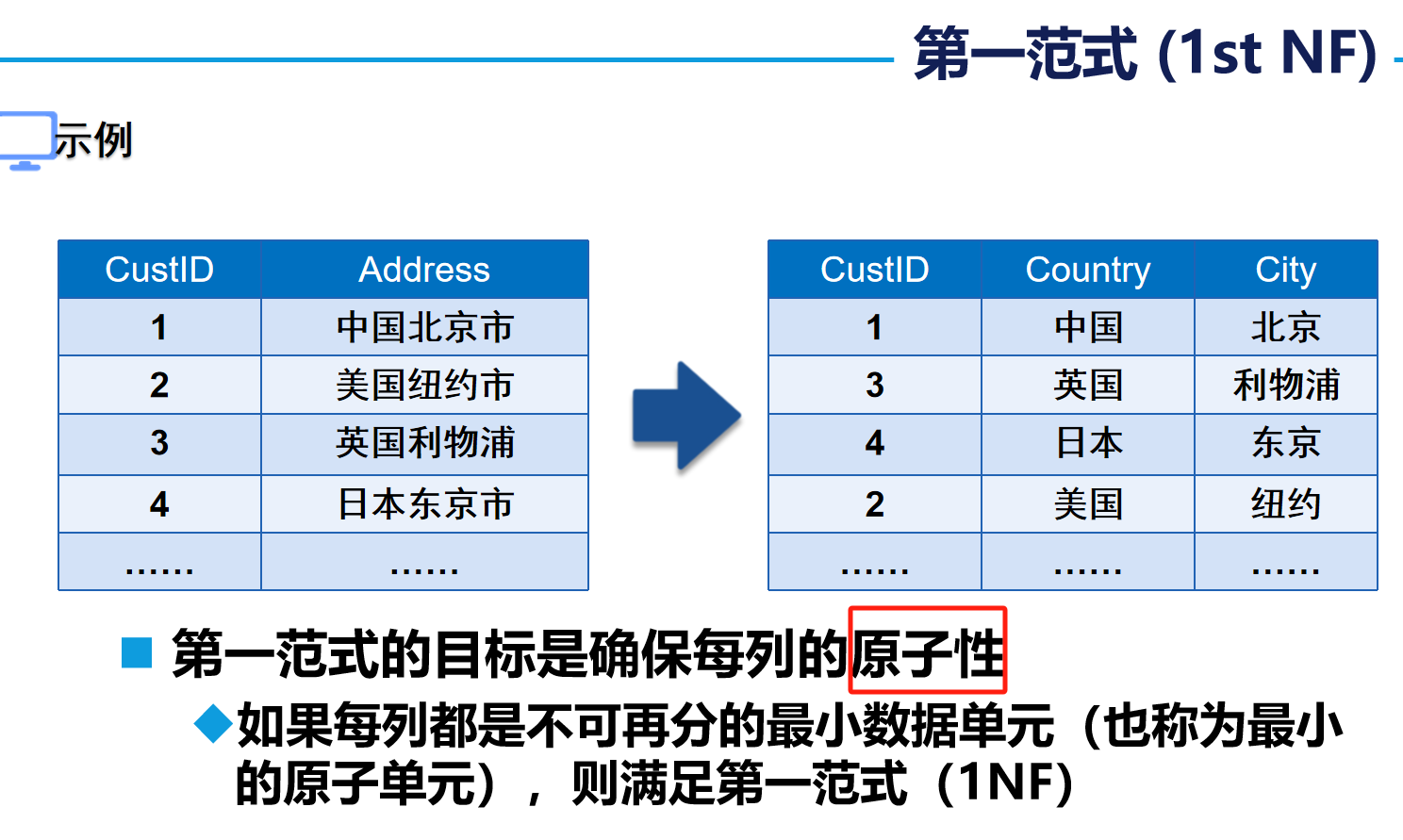
第一范式(1st NF):确保每列的原子性
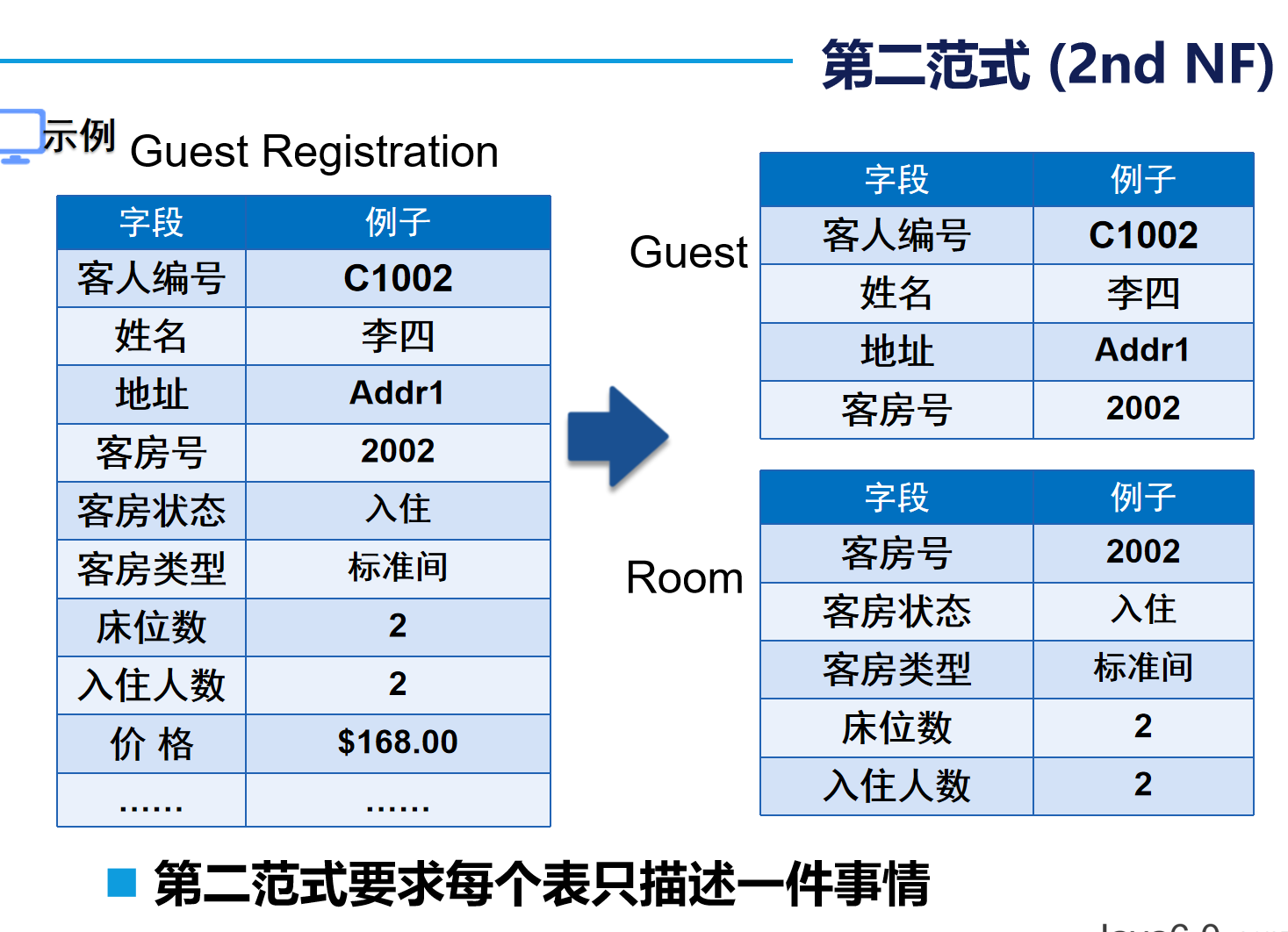
第二范式(2st NF):每个表只描述一件事情
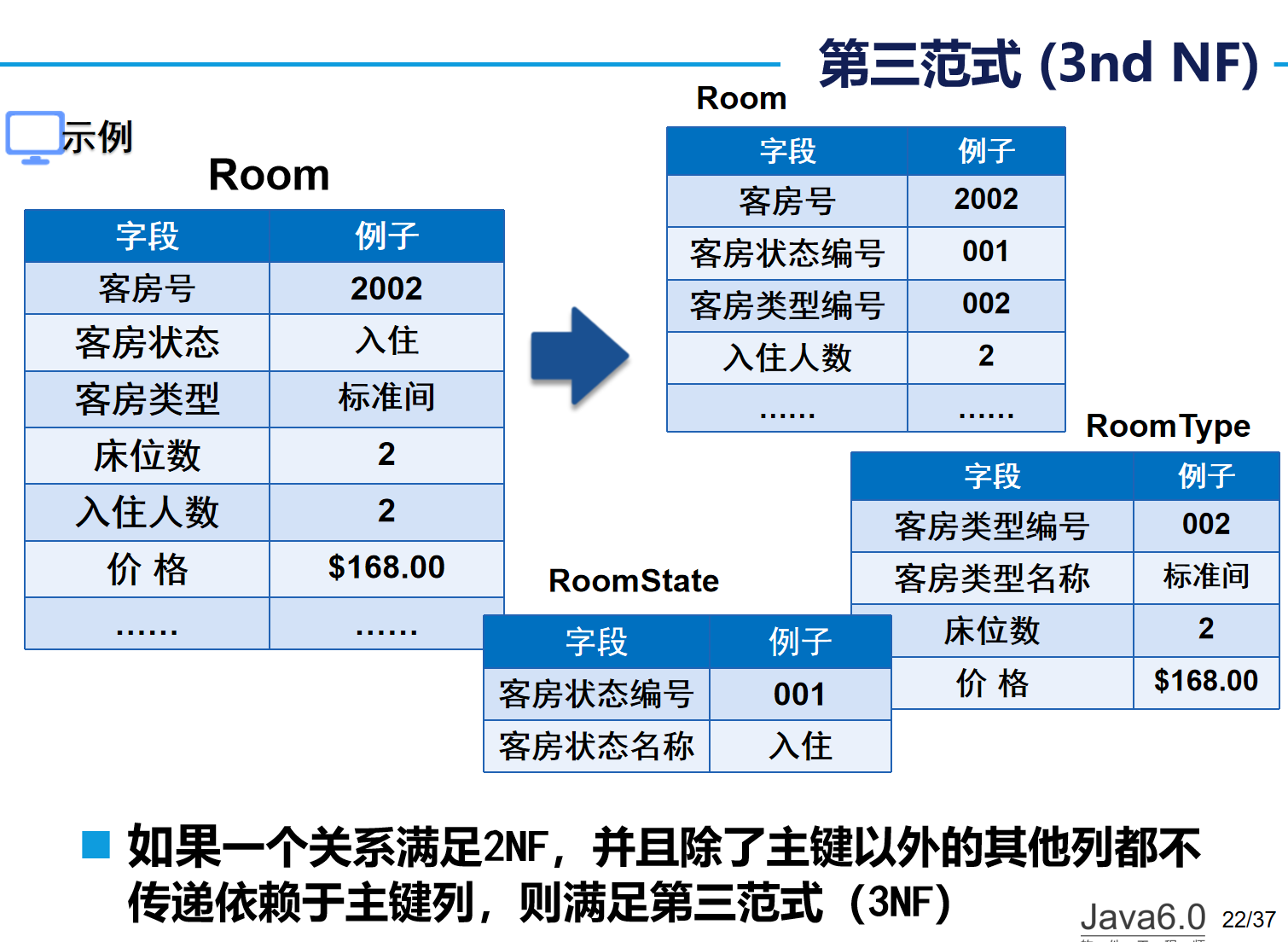
第三范式 (3nd NF):表中各列必须和主键直接相关,不能间接相关
4. 三大范式补充
1. 第一范式(1NF)
核心要求:确保每列具有原子性,即不可再分。
- 通俗理解:表中的每个字段必须是不可分割的最小数据单元,不能包含集合、数组或复合结构。例如,“地址”字段若包含省份、城市、街道等信息,需拆分为多个独立字段。
- 示例:若“家庭信息”列包含“地址+成员”,需拆分为“地址”和“家庭成员”两列以满足1NF。
2. 第二范式(2NF)
核心要求:在1NF基础上,非主键属性必须完全依赖于主键(而非部分依赖)。
- 联合主键场景:若主键由多列组成(如订单号+产品号),非主键字段(如产品价格)必须依赖整个主键,而非仅依赖产品号。
- 违反示例:订单表中“订单日期”仅依赖订单号(主键的一部分),需拆分表以消除部分依赖。
3. 第三范式(3NF)
核心要求:在2NF基础上,消除非主键属性间的传递依赖。
- 传递依赖问题:若字段A依赖字段B,而B依赖主键,则A应直接依赖主键。例如,订单表中不应直接存储客户姓名(依赖客户编号),应通过外键关联客户表。
- 优点:减少数据冗余(如避免重复存储客户信息)并避免更新异常。
注意事项
- 实际应用:三大范式虽规范,但可能影响查询性能。阿里巴巴建议关联表不超过3张,需平衡规范性与性能。
- 更高范式:存在BCNF、4NF等,但1NF~3NF最常用。
- 反范式设计:为提高查询效率,允许适度冗余(如统计字段),但需权衡数据一致性风险
5. 实际案例演示

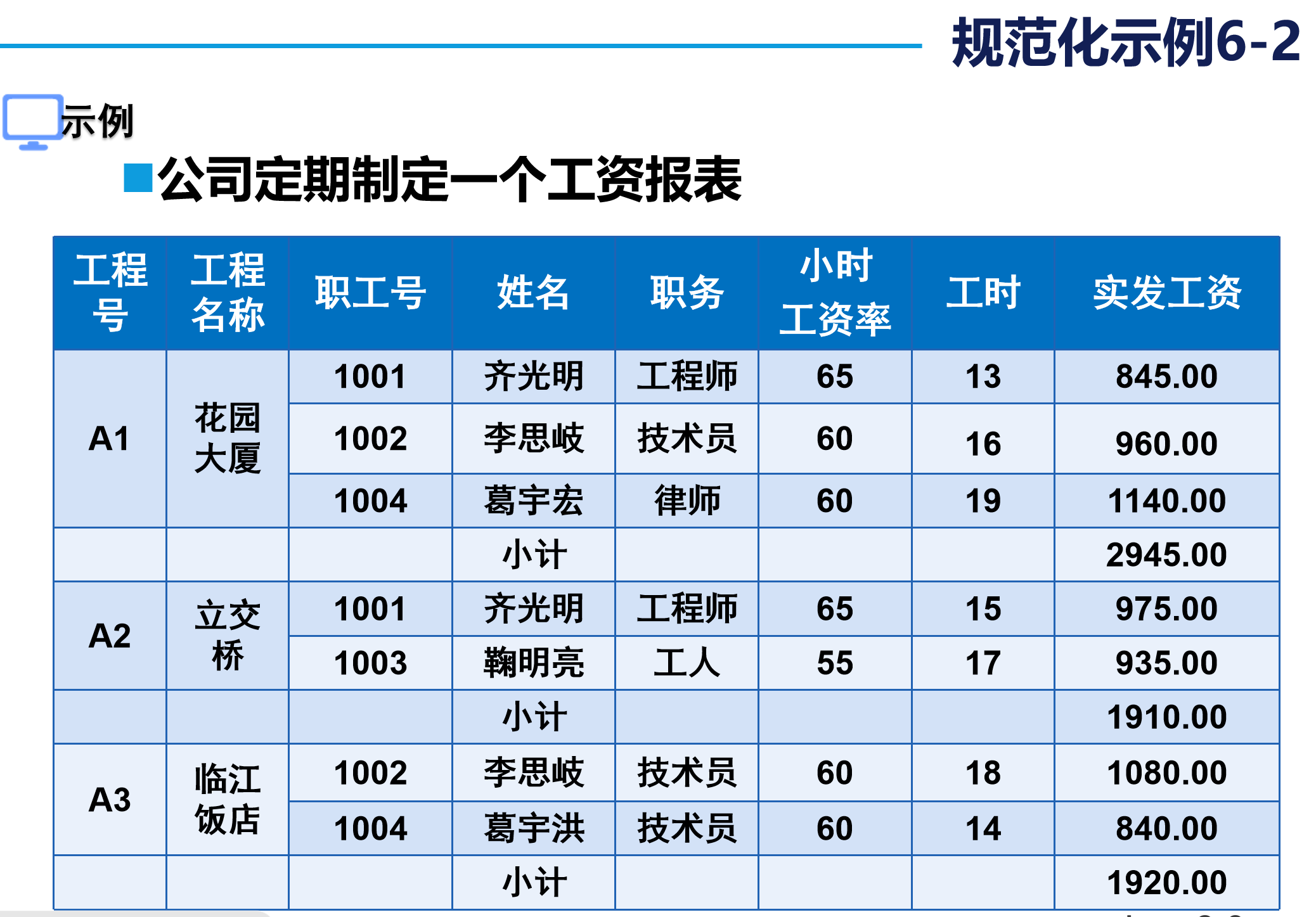
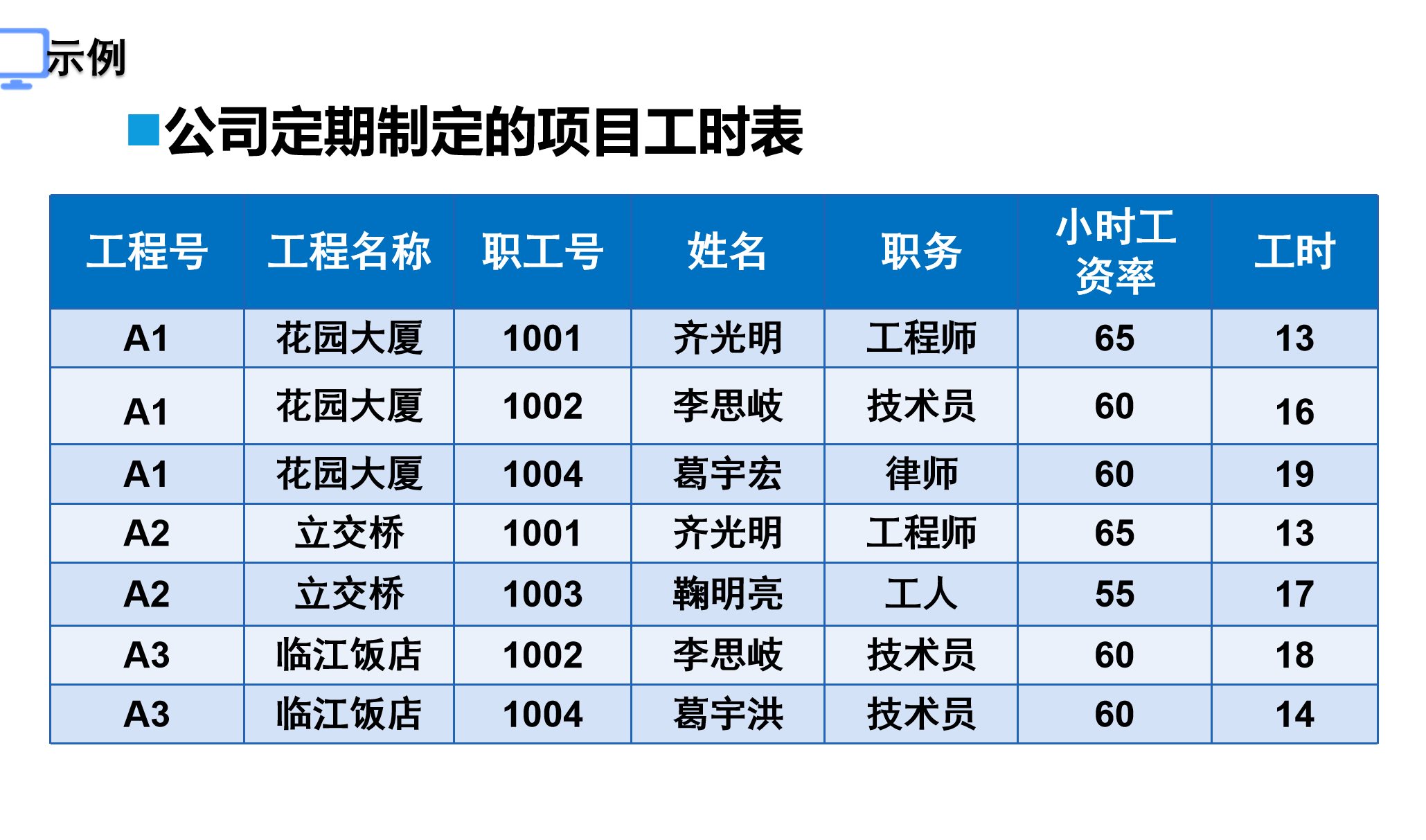

应用第一范式规范化
无可继续拆分的信息,无需应用
应用第二范式规范化
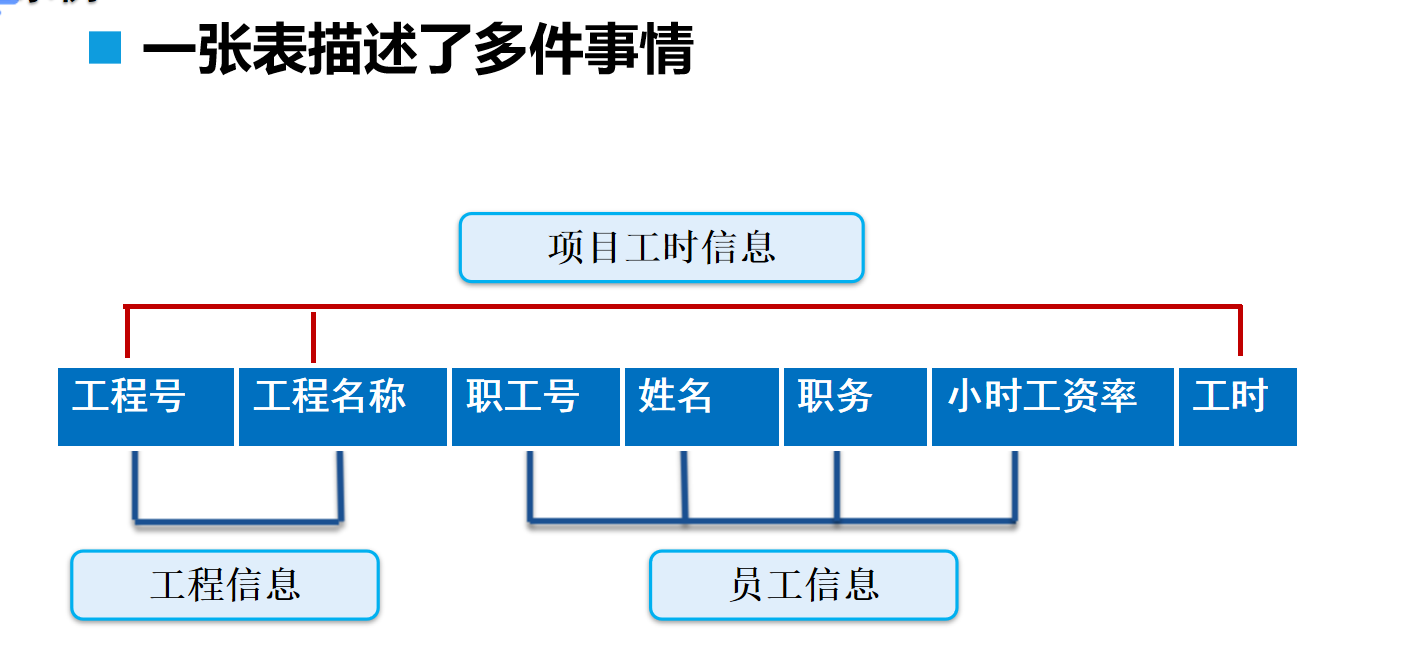
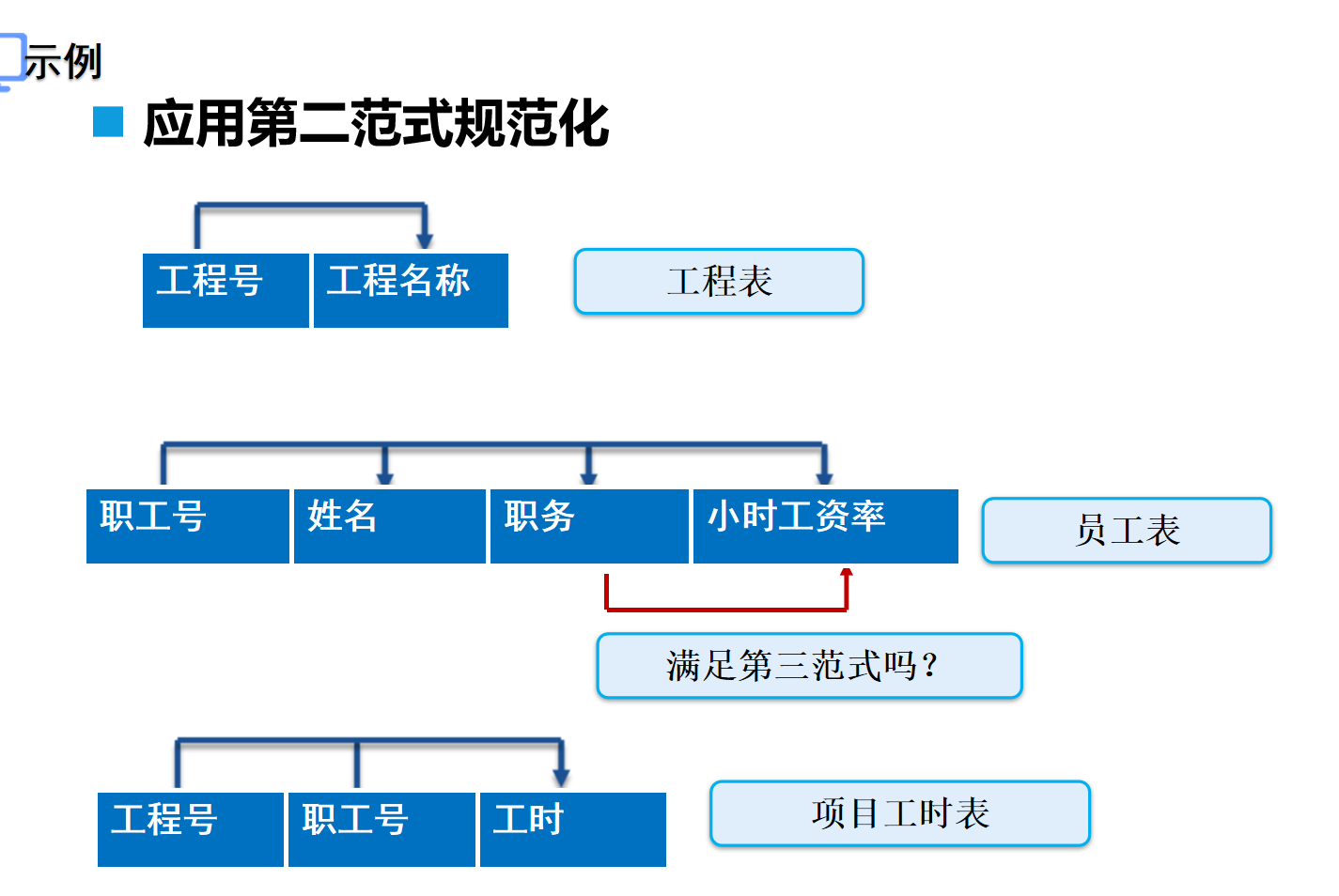
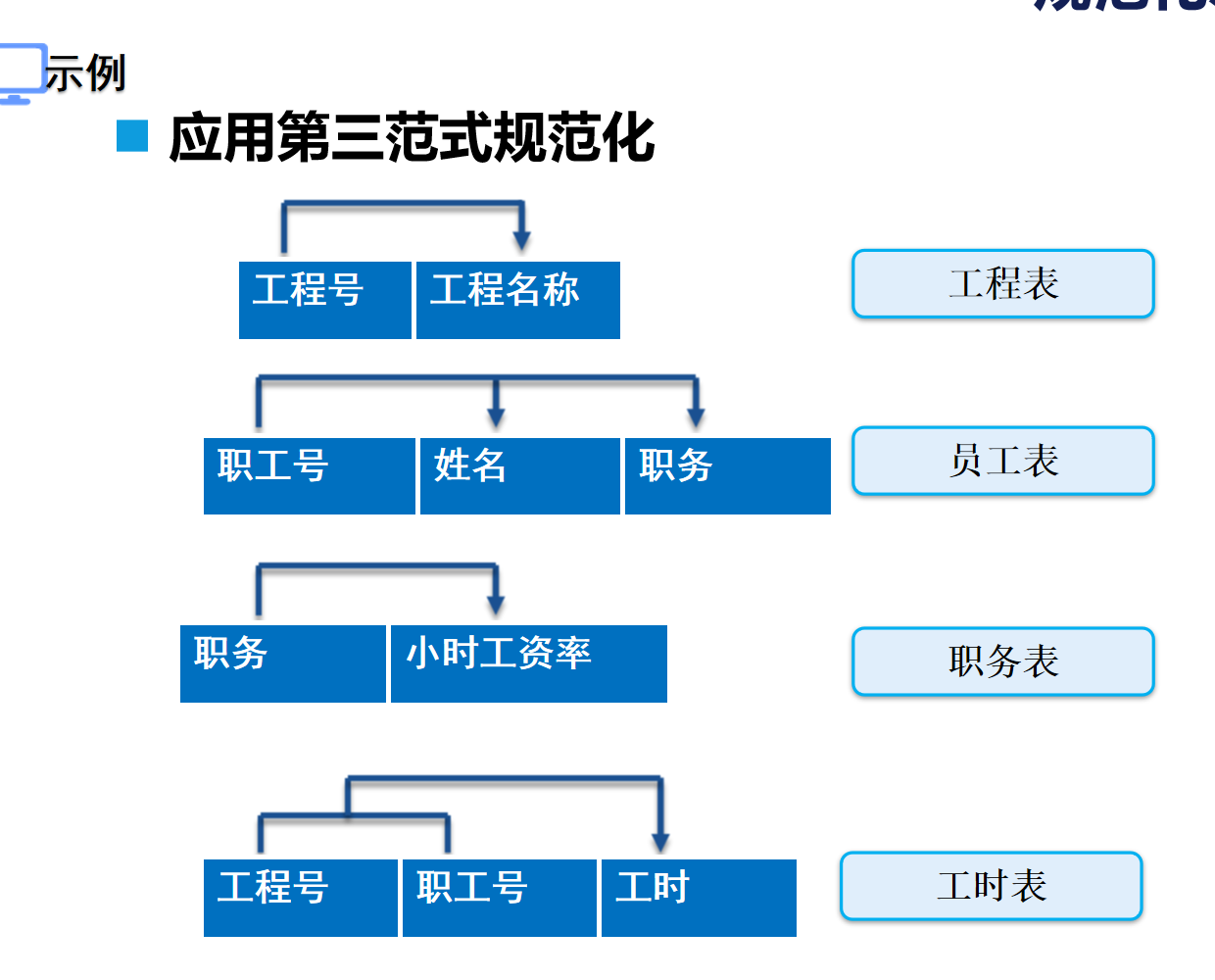
应用第三范式规范化
6. 反范式设计(补充说明)

一、基本概念
反范式设计是数据库设计中的一种优化手段,指在数据库建模过程中,通过适当违反范式规则(如增加冗余数据、合并表等),来提高数据库的读取性能。它是对范式设计(追求数据一致性和减少冗余)的一种权衡,适用于读取操作频繁、写入操作较少的场景。
二、核心思想
- 牺牲部分一致性,换取查询效率:通过引入冗余数据或合并表,减少查询时的表连接(JOIN)操作,从而提升查询速度。
- 平衡性能与维护成本:在数据冗余带来的查询优化和数据更新、维护成本之间寻找平衡点。
三、常见方法
以下是反范式设计的常用手段,可根据具体场景组合使用:
1. 增加冗余字段
- 做法:在多个表中保留相同的字段,避免跨表查询。
例:订单表(Order)中包含用户姓名(User.Name),避免每次查询订单时 JOIN 用户表(User)。 - 适用场景:冗余字段更新频率低,且查询时频繁需要关联的场景。
2. 合并表
- 做法:将经常一起查询的多个表合并为一个表,减少 JOIN 操作。
例:将用户表(User)和用户详情表(UserDetail)合并为一个表。 - 适用场景:表之间存在强关联,且合并后不会导致大量空字段的场景。
3. 拆分表
- 垂直拆分:将表中不常用的字段拆分到单独的扩展表中,减少主表数据量,提升查询速度。
例:将用户表中的 “头像 URL”“简介” 等低频字段拆分到扩展表。 - 水平拆分:按条件(如时间、ID 范围)将表数据拆分到多个子表中,降低单表数据量。
例:按年份将订单表拆分为Order_2023、Order_2024等表。
4. 增加派生字段
- 做法:通过计算或聚合生成新字段,直接存储结果,避免查询时实时计算。
例:在用户表中存储 “总订单数” 字段,通过定时任务更新,避免每次查询时统计。
四、适用场景
反范式设计适用于以下场景:
- 读多写少:如报表系统、日志系统、历史数据查询等。
- 实时性要求高:如电商商品详情页(需快速展示商品、分类、商家等信息)。
- 单表数据量庞大:当范式设计导致 JOIN 操作性能低下时,可通过冗余减少关联。
- 允许一定数据延迟:如允许冗余字段定期同步,而非实时更新。
五、优缺点分析
| 优点 | 缺点 |
|---|---|
| 减少 JOIN 操作,提升查询性能 | 数据冗余可能导致不一致(如更新延迟) |
| 简化查询逻辑,降低开发复杂度 | 增加数据维护成本(如更新、删除) |
| 单表查询效率更高 | 占用更多存储空间 |
| 对 OLAP(联机分析处理)场景友好 | 设计不当可能导致后续扩展困难 |
六、实施注意事项
- 评估场景必要性:优先使用索引、缓存(如 Redis)等优化手段,避免过度反范式。
- 控制冗余程度:仅对高频查询且低更新的数据进行冗余,避免全表冗余。
- 数据一致性方案:
- 定期同步:通过定时任务(如 CRON)更新冗余数据。
- 触发器:在写入主表时,通过数据库触发器同步更新冗余字段(需注意性能影响)。
- 应用层控制:在业务代码中手动维护主表与冗余数据的一致性。
- 文档记录:明确标注反范式设计的字段和逻辑,方便后续维护。
- 监控与优化:定期分析查询性能和数据一致性,必要时调整设计。
七、与范式设计的对比
| 维度 | 范式设计 | 反范式设计 |
|---|---|---|
| 核心目标 | 数据一致性、减少冗余 | 读取性能优化 |
| 适用场景 | OLTP(联机事务处理)系统 | OLAP 系统、读多写少场景 |
| 典型场景 | 银行交易系统、电商订单系统 | 报表系统、商品详情页 |
| 设计复杂度 | 高(需遵循范式规则) | 中(需平衡冗余与维护) |
八、案例说明
场景:设计一个电商平台的 “商品详情页”,需展示商品信息、分类名称、商家名称。
- 范式设计:
- 表结构:
商品表(Goods)、分类表(Category)、商家表(Seller)。 - 查询:需 JOIN 三张表,性能可能较低(尤其在高并发场景)。
- 表结构:
- 反范式设计:
- 在
商品表中增加冗余字段category_name(分类名称)、seller_name(商家名称)。 - 查询:直接单表查询,性能显著提升;通过定时任务或商品 / 分类 / 商家更新时同步冗余字段。
- 在
九、总结
反范式设计是数据库优化的重要手段,但需谨慎使用。关键在于明确业务需求,在性能提升与数据维护成本之间找到平衡点。实际应用中,常采用 “混合设计”—— 核心业务遵循范式设计,高频查询场景辅以反范式优化,以兼顾一致性和性能。
7. 总结


)







:三层架构)








如何通过“思考时间”(即推理时的计算资源)提升推理能力)
