1. 注意力认知和应用
AM: Attention Mechanism,注意力机制。
根据眼球注视的方向,采集显著特征部位数据:

注意力示意图:
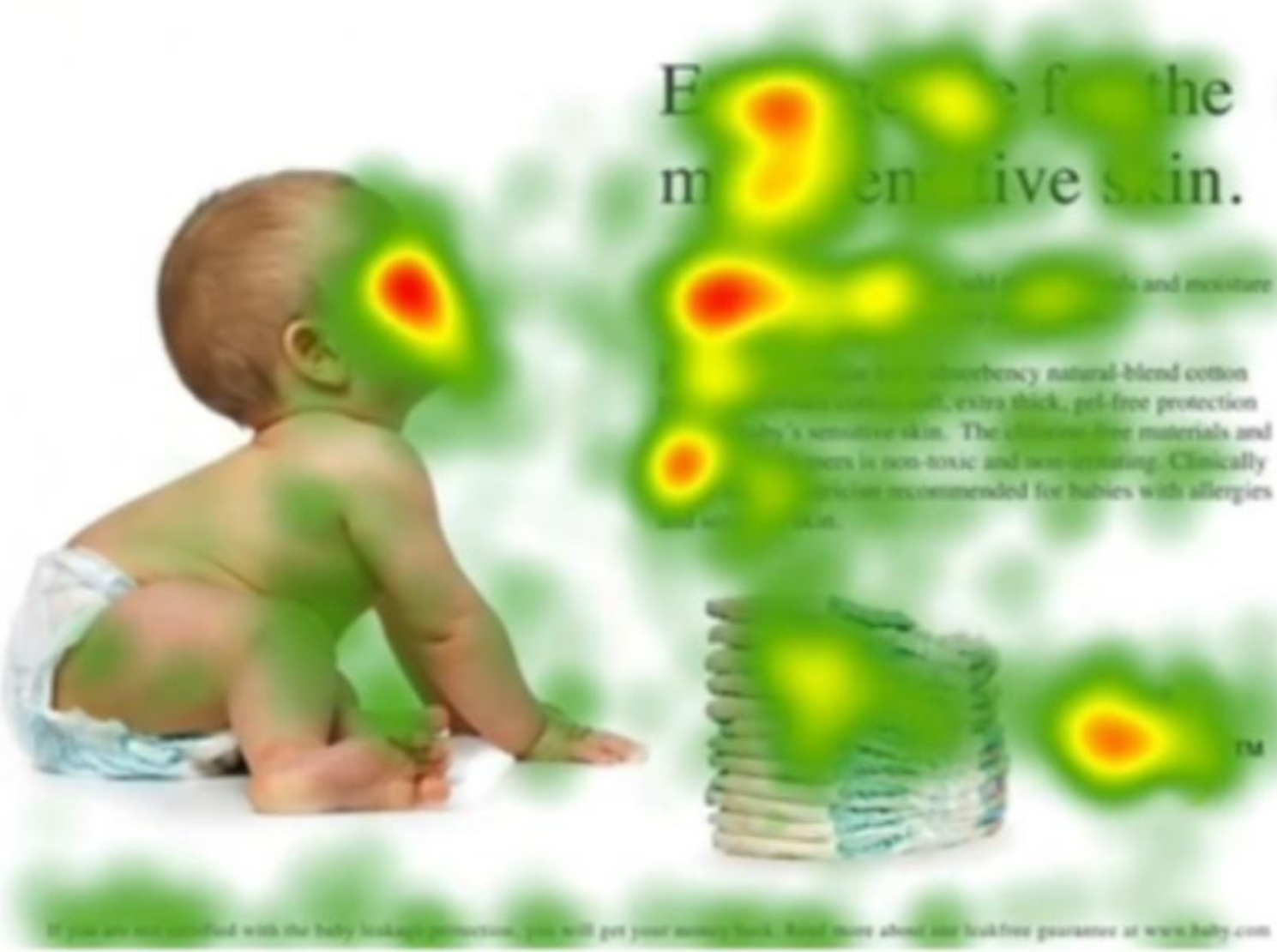
注意力机制是一种让模型根据任务需求动态地关注输入数据中重要部分的机制。通过注意力机制,模型可以做到对图像中不同区域、句子中的不同部分给予不同的权重,从而增强感兴趣特征,并抑制不感兴趣区域。
注意力机制最初应用于机器翻译(如Transformer),后逐渐被广泛应用于各类任务,包括:
1. NLP:如机器翻译、文本生成、摘要、问答系统等。
|
|
|
|---|---|
| 机器翻译 | 关键词提取,摘要生成:输入句和参考摘要之间的重叠关键词(红色)涵盖了输入句的重要信息,可根据这些关键字生成摘要 |
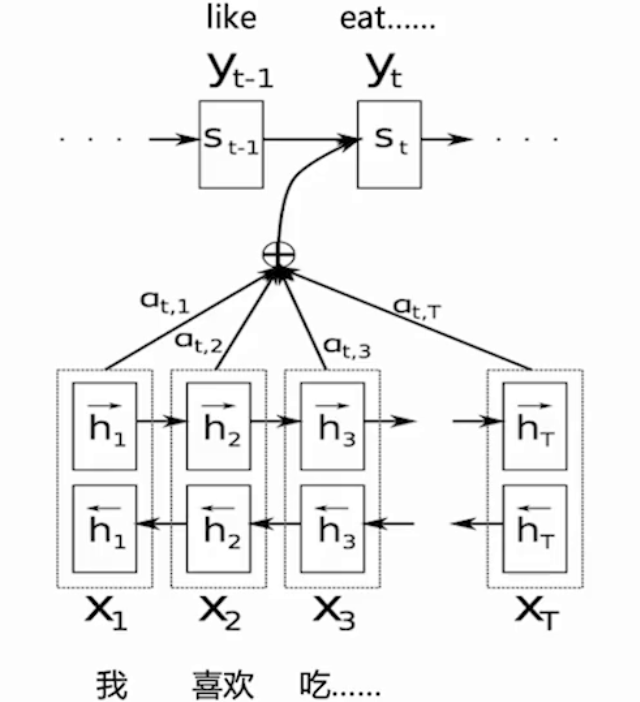

2. 计算机视觉:如图像分类(细粒度识别)、目标检测(显著目标检测)、图像分割(图像修复)等。
|
|
|
| 细粒度识别 | 图像修复:监控摄像头去除雨线、雨滴等 |
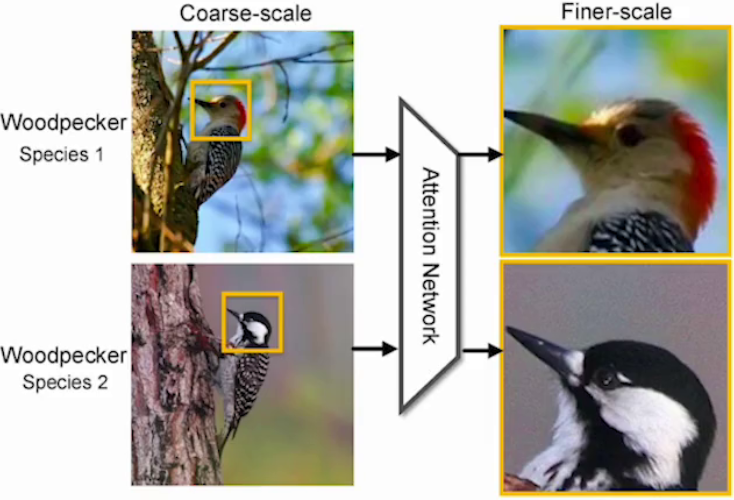
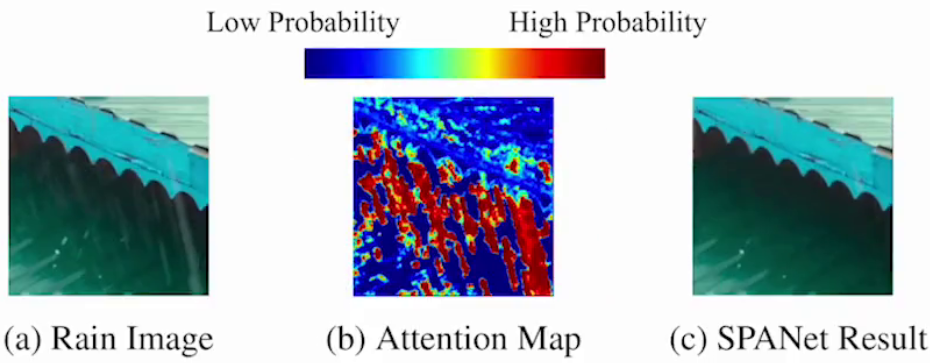
3. 跨模态任务:如图文生成、视频描述等。
这里我们学习下视觉处理中常见的典型注意力机制,如特征注意力、空间注意力以及混合注意力。
2. 通道注意力
对不同的特征通道进行增强或抑制,也就是赋予不同的权重参数。96个卷积核卷之后会得到不同的96个特征图谱:边缘、形状、颜色等,不同的通道关注不同的特征

2.1 SENet
Squeeze-and-Excitation Networks:挤压 - 和 - 激活、激发。
SENet模型论文: https://arxiv.org/pdf/1709.01507
2.1.1 基本认知
Filter SENet采用具有全局感受野的池化操作进行特征压缩,并使用全连接层学习不同特征图的权重,模型流程图如下:
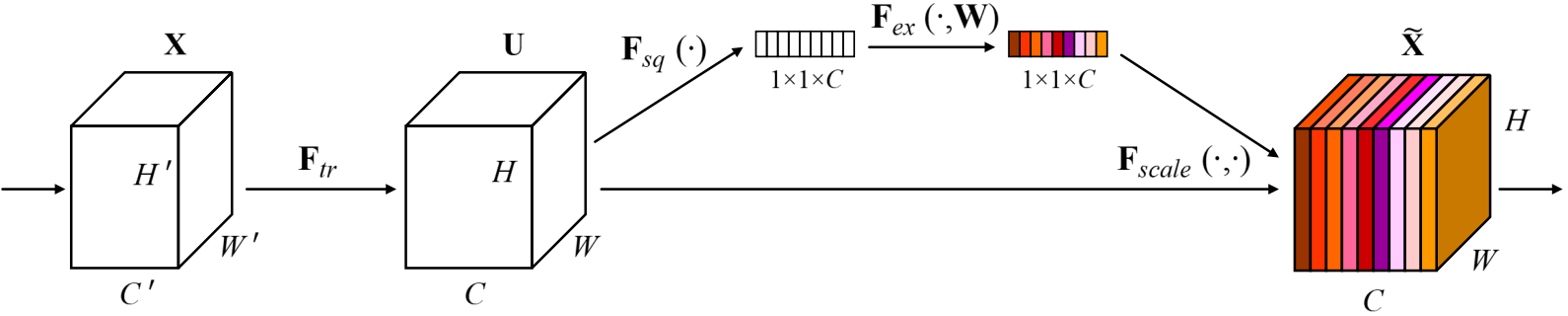
2.1.2 流程详解
1. Squeeze阶段:该阶段通过全局平均池化完成全局信息提取,公式如下:
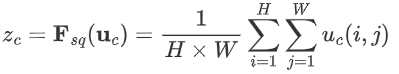
示意图如下:

# Squeeze:压缩、降维、挤压
self.sq = nn.AdaptiveAvgPool2d(1)2. Excitation阶段:Squeeze的输出作为Excitation阶段的输入,经过两个全连接层,动态地为每个通道生成权重,公式如下:
![]()
示意图如下:
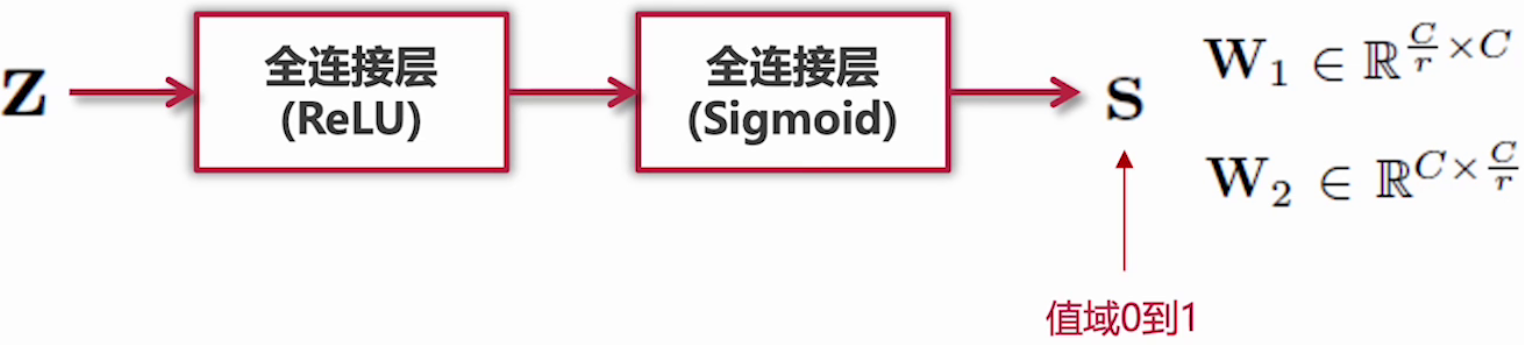
全连接层加入激活函数,用于引入非线性变化:
-
第一个全连接层(ReLU),将通道数从C降维为C/r。
-
r 是缩放因子,Ratio,比例的意思,用以减少运算量和防止过拟合。
-
通过第二个全连接层(si4)将维度恢复为C,输出一个1 \times 1 \times C的权重向量。
-
权重归一化:使用sigmoid确保权重在0~1之间。
-
该向量代表每个通道的重要性,也就是注意力的权重。
# Excitation:激活
self.ex = nn.Sequential(nn.Linear(inplanes, inplanes // r),nn.ReLU(),nn.Linear(inplanes // r, inplanes),nn.Sigmoid(),
) 3. 输出阶段:特征和 Excitation阶段产出的
进行相乘操作,用于对不同的通道添加权重:
![]()

def forward(self, x):# 缓存xintifi = xx = self.sq(x)x = x.view(x.size(0), -1)x = self.ex(x).unsqueeze(2).unsqueeze(3)return intifi * x2.1.3 融入模型
作为一种即插即用模块,可以添加到任意的层后,只要保证输出通道不变即可,如把SE融入到ResNet模型,如下:
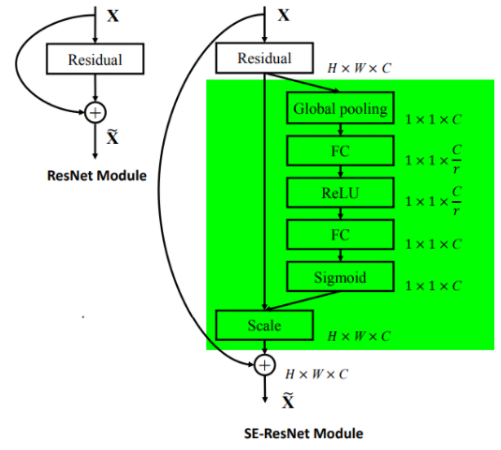
给ResNet-50加入SE注意力:
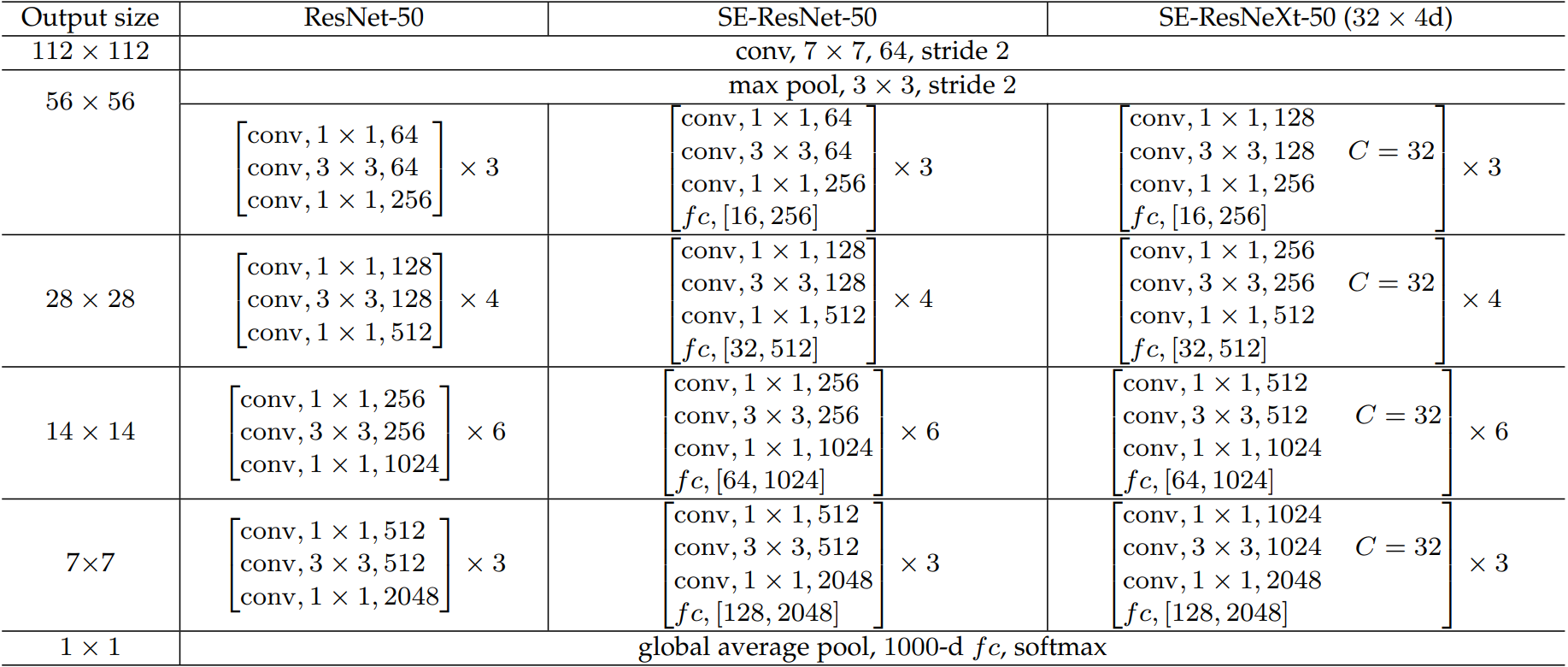
注解:表格中的 fc 后面的值,如 (16, 256) 或 (32, 512),表示在SE模块中的两个全连接层的维度变化。
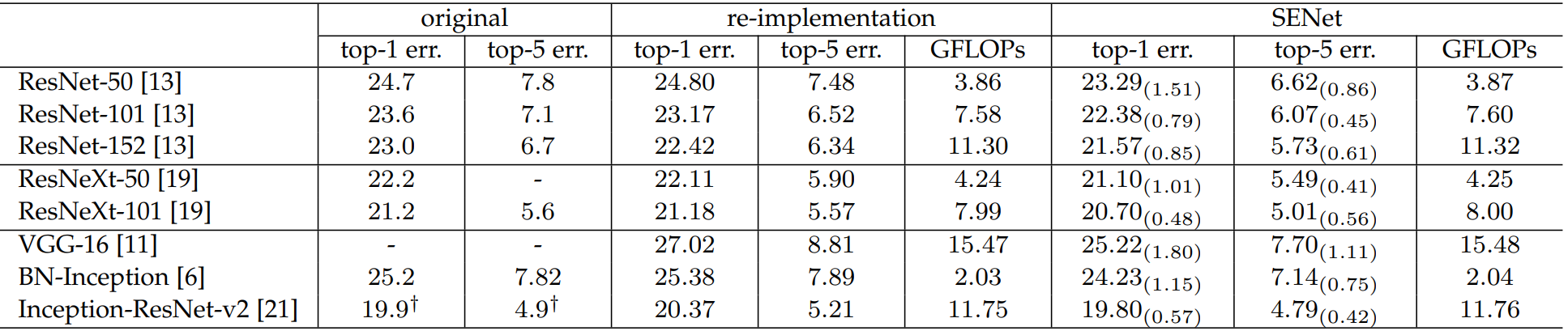
2.1.4 性能对比
加入SE后的性能对比表:re-implementation是SE作者复现效果
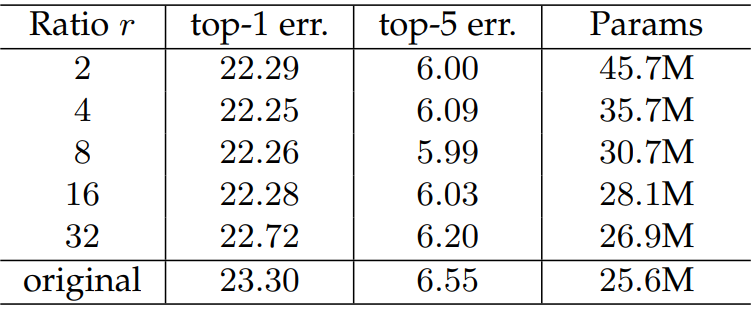
2.1.5 缩放因子
太小参数量大,容易过拟合。太大的话特征丢失严重,整体看8或16是比较不错的选择,具体的还是根据业务来定。
2.1.6 有无Squeeze
我们可以考虑不要Squeeze做平均池化,直接在Excitation阶段进行卷积操作。从下标看的出来,这个Squeeze阶段还是很有必要的。

2.1.7 池化方式
我们也可以考虑采用最大池化,不过效果不如平均池化。因为对注意力来讲更多的是维持原始信息,而不是强化特征。

2.1.8 激活函数
这里是针对第二个全连接层,我们想要的是一个概率向量,无疑返回值在(0 ~ 1)之间的Sigmoid是最好的选择。
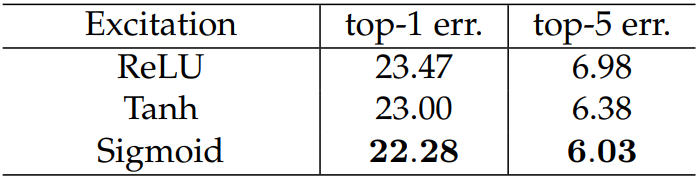
2.1.9 网络位置
SE模块灵活度较高,如下:
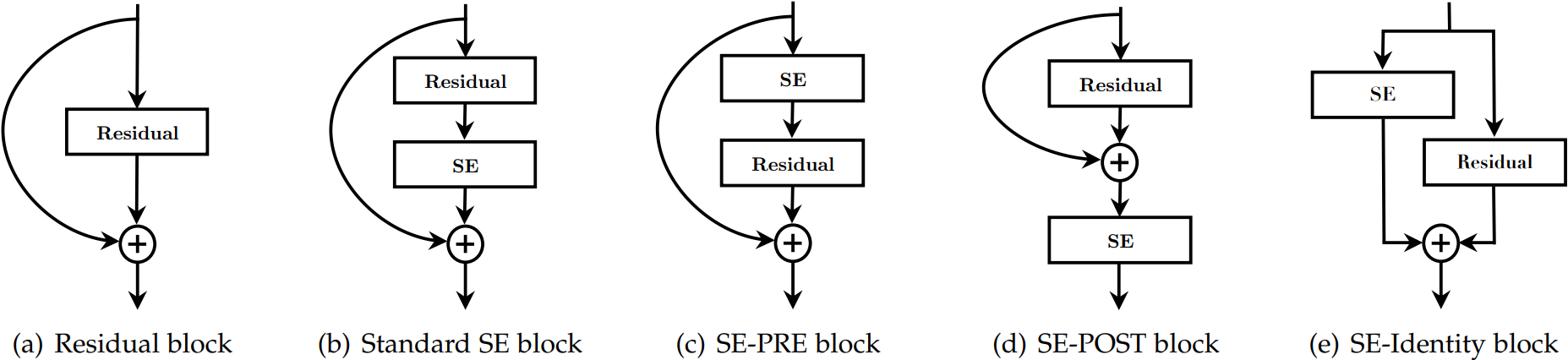
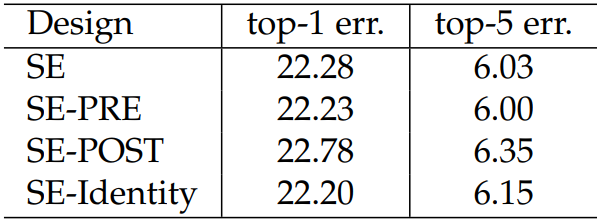
性能对比如下:POST模式最差
2.1.10 不同阶段添加
比如ResNet是分很多个阶段的,不同的阶段添加SE模块效果是不一样的。
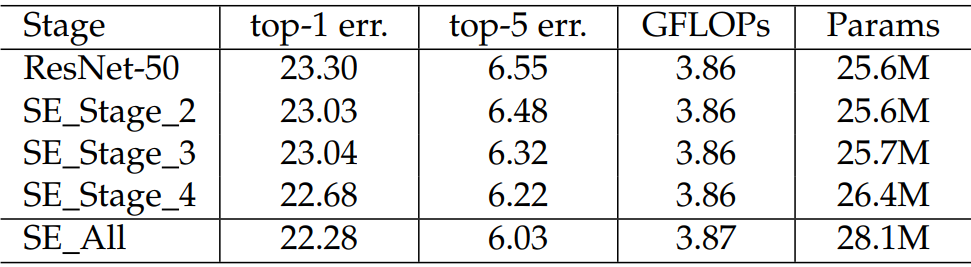
看的出来,越靠后的位置效果越好,因为越靠后特征学习的越好,此时加入效果就越好。当然全加SE的效果最好,不过参数量也不小。
2.2 SKNet
Selective Kernel Networks:可选择的 卷积核尺寸
目的:bSKNet中的神经元可以捕获不同尺度的目标物体,这验证了神经元根据输入自适应调整其感受野大小的能力。
SKNet论文地址:https://arxiv.org/pdf/1903.06586
2.2.1 基本认知
SK是对SE的改进版,可以动态调整感受野大小,分为Split-Fuse-Select共3个阶段,模型流程图如下:
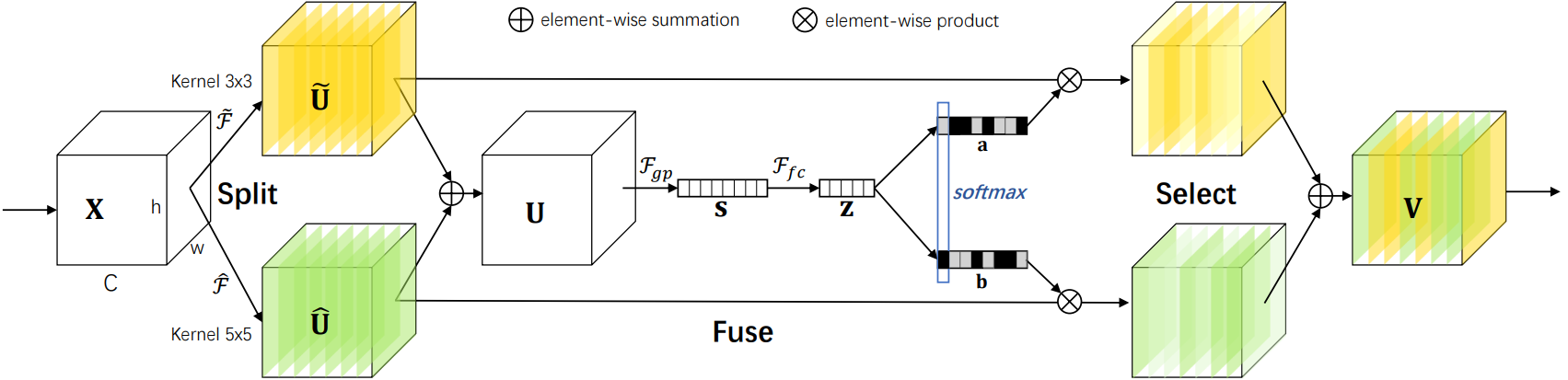
2.2.2 Split阶段
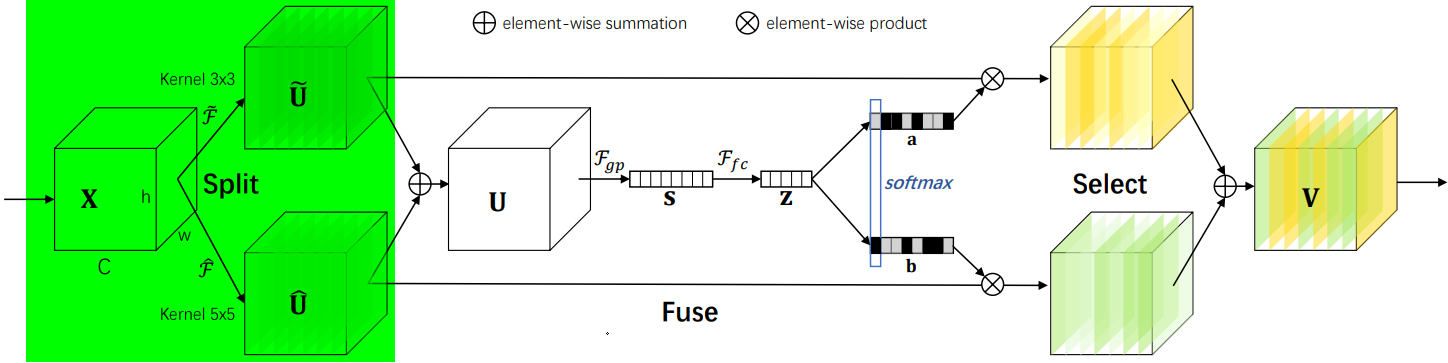
- 在Split阶段会分出多个分支,每个分支实现不同大小的感受野,从而捕获不同的特征。
- 为提高效率,传统的5×5卷积被替换为带有3×3卷积核和膨胀大小为2的膨胀卷积。
- 具体公式如下:
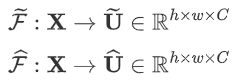
2.2.3 Fuse阶段
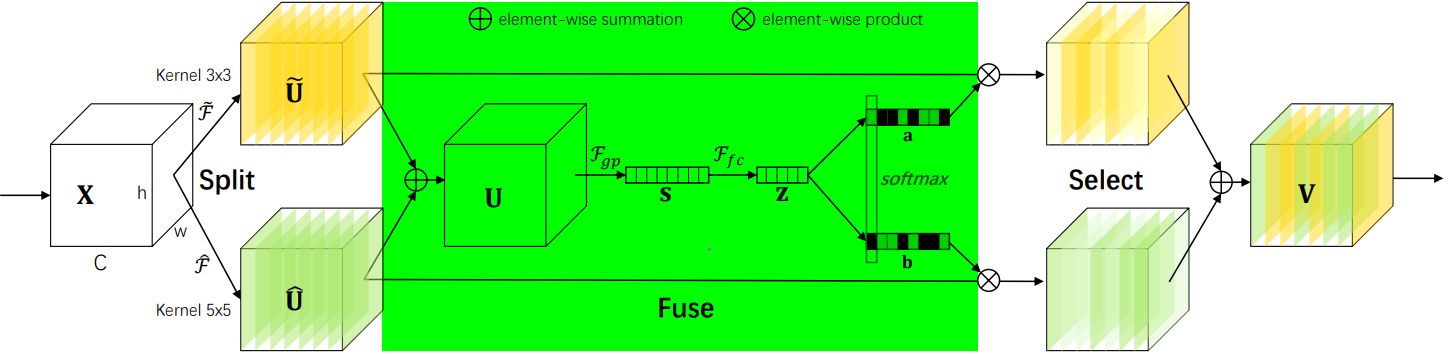
该阶段会整合分支信息,具体步骤如下:
1. 通过element-wise summation得到 U:
2. 通过global average pooling得到特征s:就是一个平均池化操作。
3. 通过FC全连接层得到:
,其中
是batch normalization,
是ReLU,
。注意这里通过reduction ratio r 和阈值 L 两个参数控制 z 的输出通道 d:
,L 默认值为32。
4. 通过两个不同的FC层(即矩阵A、B)分别得到 a 和 b,这里将通道从 d 又映射回原始通道数 C。
5. 对 a,b 对应通道 c 处的值进行 softmax 处理。
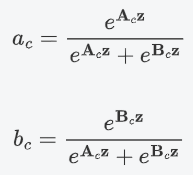
在公式中,,
和
分别代表不同(3×3、5×5)的卷积核经过全局池化(
)和全连接层(
)后得到的特征。a,b分别表示
和
的注意力系数。
2.2.4 Select阶段
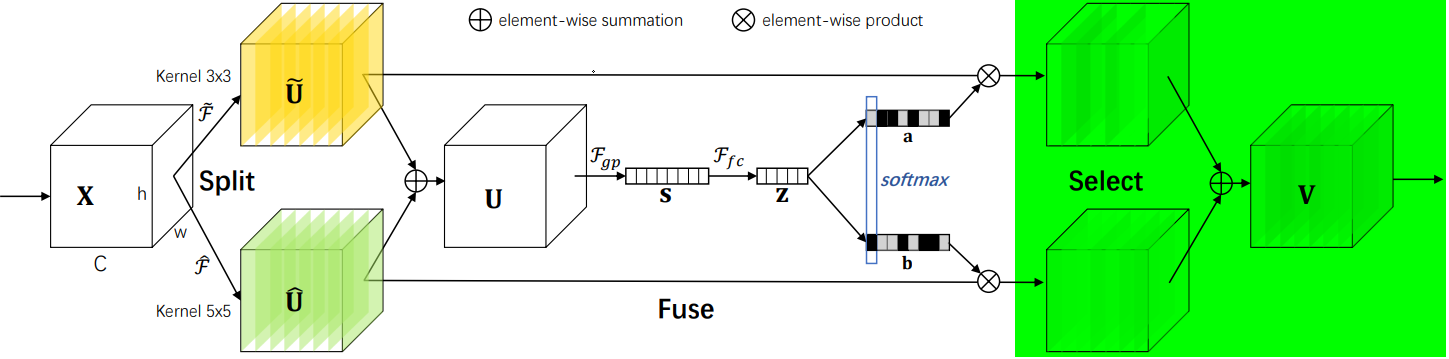
具体步骤如下:
1. 和
分别与 sofmax 处理后的 a,b 相乘,再相加,得到最终输出的 V 和原始输入 X 的维度一致。
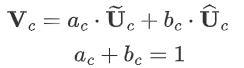
其中
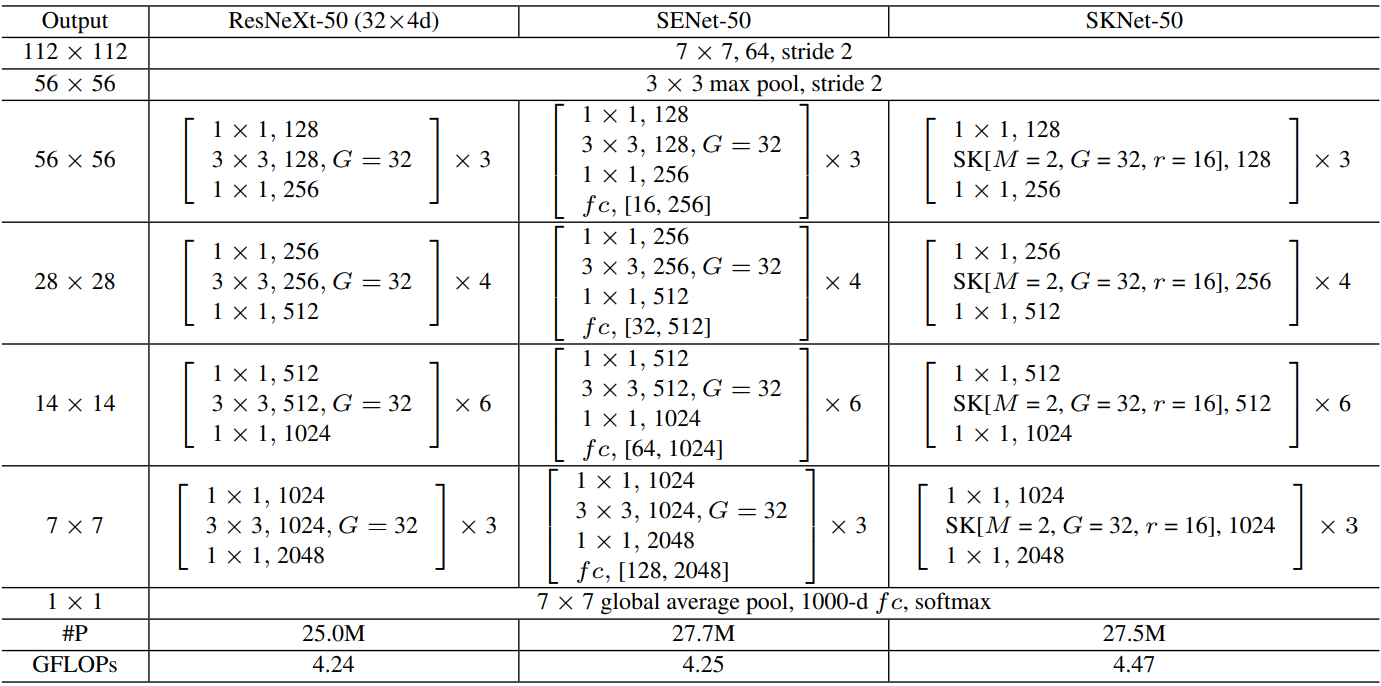
2.2.5 融入模型
ResNeXt加入SE和SK:
2.2.6 注意力权重分析
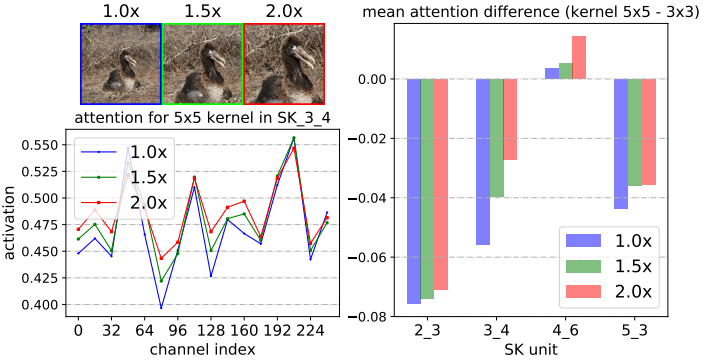
图标注解:
-
通过中心裁剪和随后的调整大小,逐步将中心对象从1.0× 扩大到2.0×
-
SK_X_Y 中的 X 代表网络的不同层级(Stage),数字越大表示层越深。
-
Y 代表该层级中的第几个SK模块。
-
不同的SK模块在不同的层级负责提取不同尺度、不同语义的特征。
-
从第2层到第5层,特征从低级(如边缘、纹理)逐渐过渡到高级语义信息(如物体、场景等)。
-
channel index(32、64、96等) 表示不同通道编号。
-
activation表示每个通道上的注意力权重值。这个值越高,表明网络对该通道上的特征越重视。
结论:
1. 当目标物体增大时,对大核(5×5) 的关注权值增大,这表明神经元自适应地变大。
2. 我们发现了一个关于自适应选择跨深度作用的令人惊讶的模式:目标对象越大,越会将更多的注意力分配给更大的对象。
3. 随着网络加深,5x5卷积核的权重值也逐渐在变大,但在更高层时又不同。
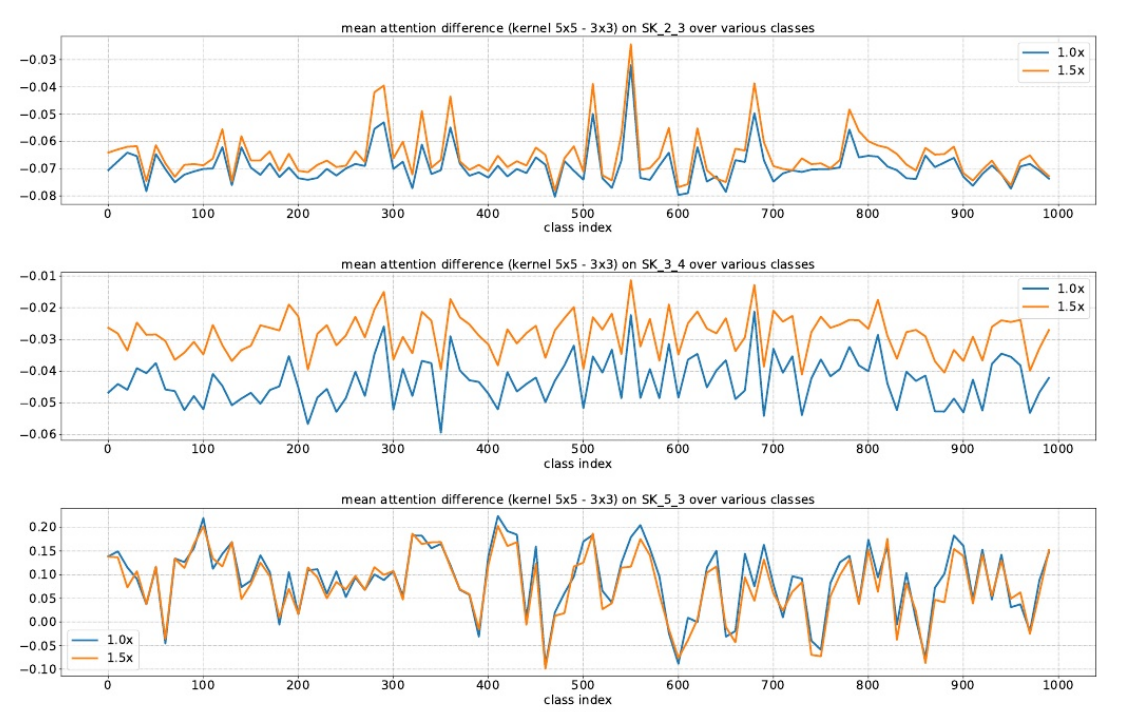
对于使用ImageNet上所有验证样本的1000个类别中的每一个,在SKNet-50的SK单元上的平均注意差(内核的平均注意值5×5减去内核的平均 注意值3×3)。在低级或中级SK单元(例如,SK 2.3, SK 34 4)上,如果目标对象变大(1.0x→1.5x),则明显更强调5×5核。
结论:在低级和中级阶段(例如,SK 23 3, SK 34 4),通过选择性核机制的核。然而,在更高的层次(例如,SK 53 3),所有的尺度信息都丢失了,这样的模式消失了。
这表明在网络的前期,可以根据对象大小的语义感知选择合适的核大小,从而有效地调整这些神经元的RF大小。然而,这种模式不存在于像SK 5.3这样的非常高层中,因为对于高层表示, “尺度”部分编码在特征向量中,与低层的情况相比, 内核大小的影响较小。
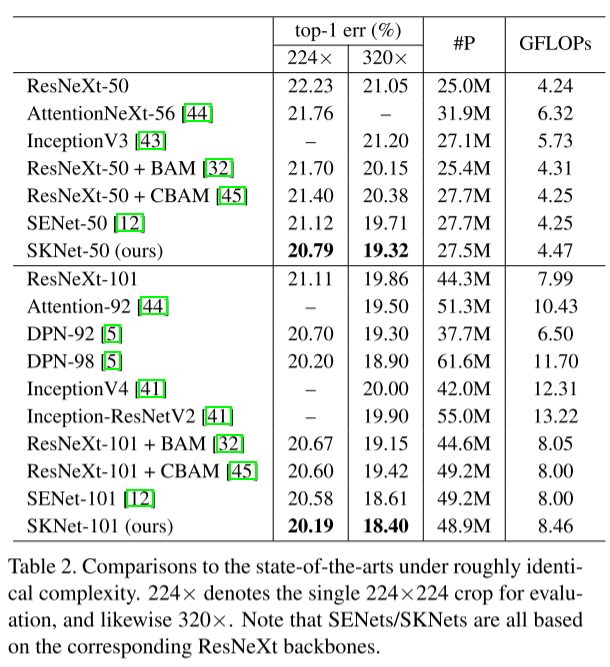
2.2.7 性能对比
3. 空间注意力
空间注意力(Spatial Attention)是一种专注于特征图的空间维度的重要性分配的机制。它通过对特征图中的特定空间位置进行加权,从而突出对任务最有贡献的区域,抑制无关或冗余的区域,以提高模型的性能
3.1 Spatial Attention Module
这里介绍的空间注意力是 CBAM 中的组成模块。
论文地址:https://arxiv.org/pdf/1807.06521
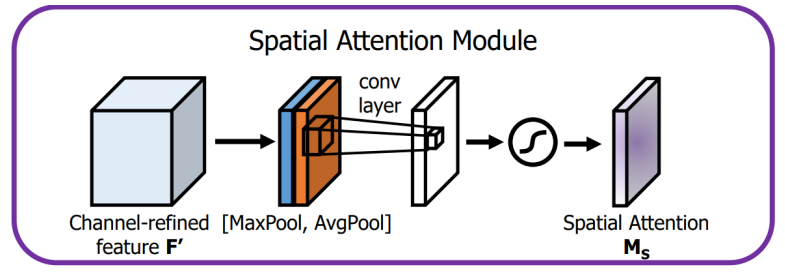
空间注意力模块通过卷积操作为特征图的每个空间位置生成权重,聚焦在图像中的关键区域,这是对通道注意力的补充。
-
空间注意力模块计算公式如下:
-
表示通道中的平均池化特征
-
表示通道中的最大池化特征
-
表示滤波器大小为 7×7 的卷积操作
-
表示 sigmoid 激活函数
-
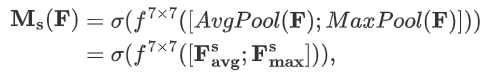
-
空间注意力模块布局如下:
-
输入特征:通道注意力模块的输出 F' 就是空间注意力模块的输入。
-
池化操作:
-
在 F' 的通道维度上进行全局的 MaxPool 和 AvgPool,生成 2 个二维特征图,维度为 1 × H × W。
-
-
卷积层:
-
把池化得到的特征图连接起来
。
-
使用一个
的卷积核对拼接后的特征图进行卷积操作,经 Sigmoid 激活后,生成空间注意力图
,维度为
。
-
-
输出:
-
空间注意力图M_S与经过通道注意力增强后的特征图 F' 逐元素相乘,输出最终的增强特征图。
-
-
3.1.1 实验结论
这个实验结论是 CBAM 论文中给出的,不仅仅是添加了空间注意力,还添加了通道注意力,可以看出都比不用(baseline)效果要好

3.1.2 构建
import torch
import torch.nn as nn# 空间注意力模块
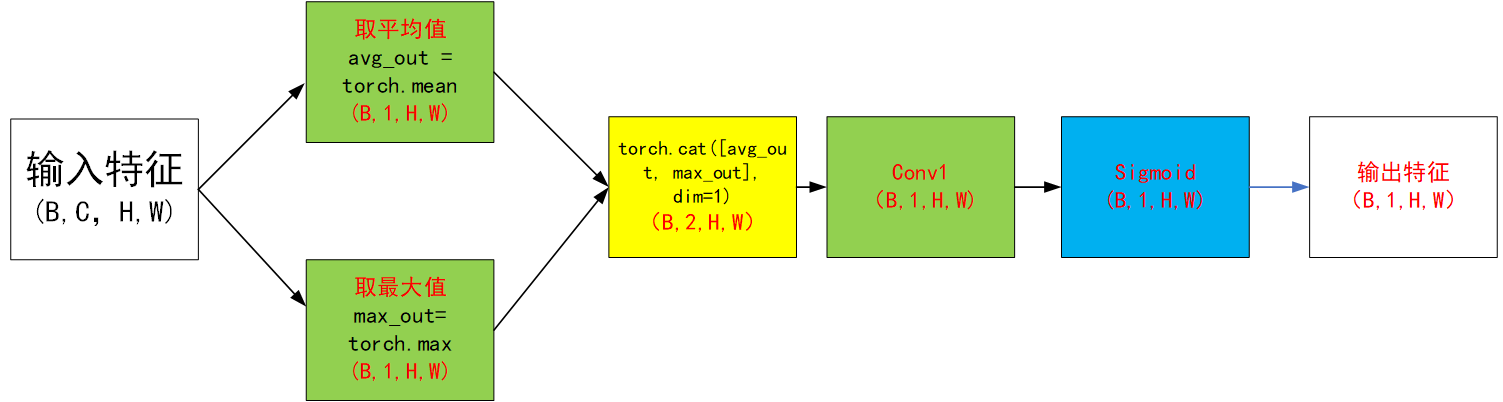
class SpatialAttentionModule(nn.Module):def __init__(self):super(SpatialAttentionModule, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3),nn.Sigmoid(),)def forward(self, x):max_pool = torch.max(x, dim=1, keepdim=True)[0]avg_pool = torch.mean(x, dim=1, keepdim=True)pool = torch.cat([max_pool, avg_pool], dim=1)out = self.conv(pool)return out3.2 Learn to Pay Attention
论文地址:https://arxiv.org/pdf/1804.02391。
源代码地址:https://github.com/SaoYan/LearnToPayAttention。
空间注意力(Spatial Attention)主要用于CV,它在空间维度上选择性地关注输入特征图的不同位置,从而提升模型对关键区域的感知能力。其实现原理是基于不同像素位置,生成对应概率掩码,是比较低层的注意力机制。
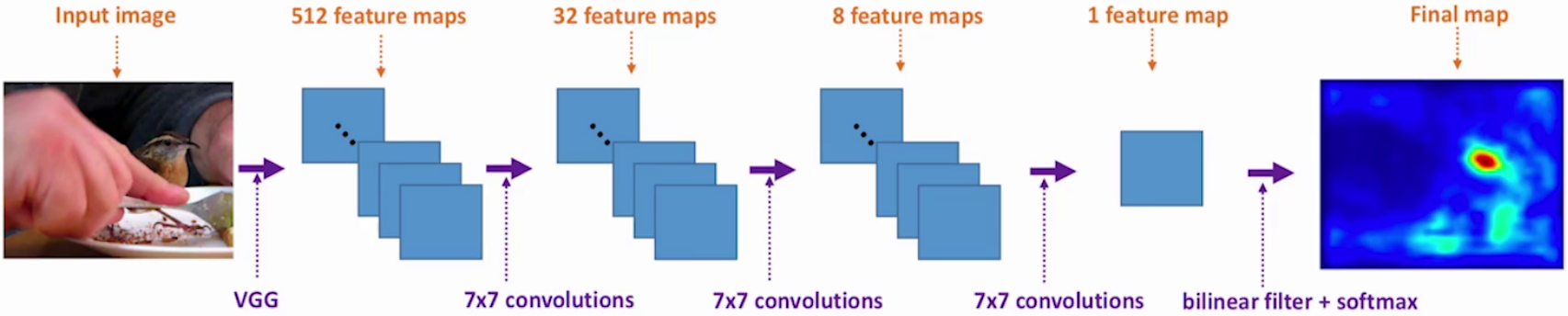
3.2.1 基本认知
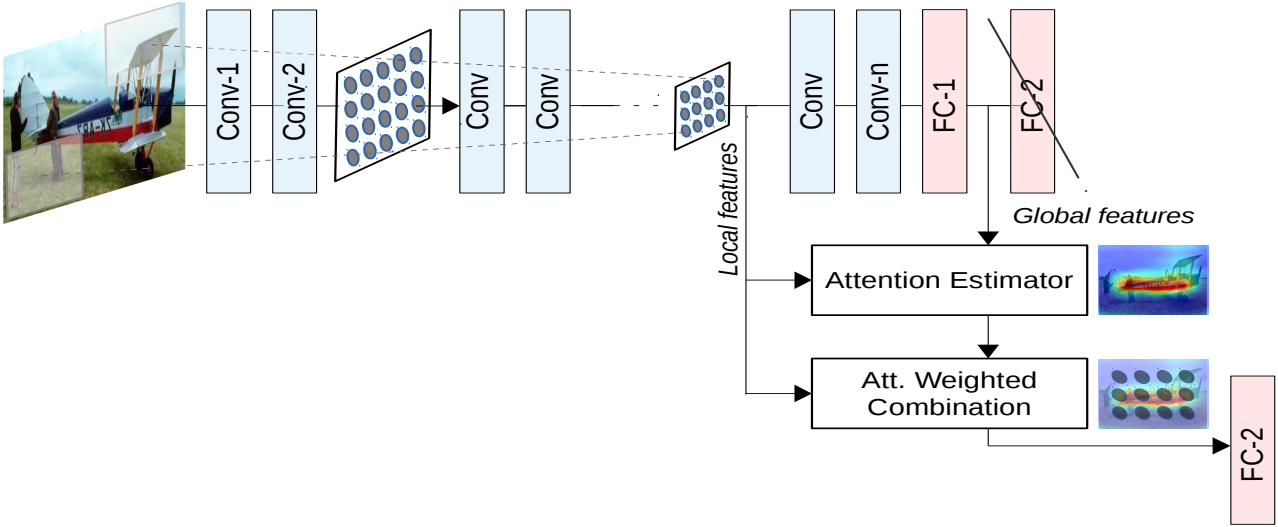
结合全局特征和局部特征获得注意力机制,使用加权的局部特征来识别目标。
-
Local features:局部特征
如头部、轮子、尾翼、发动机、机身标志或窗户等,包含丰富的细节,对于识别飞机的具体种类、型号等非常有帮助。
-
Global features:全局特征
如整体形状、轮廓、大小、相对背景中的位置等;对于识别是什么飞机很重要,如战斗机、客机还是直升机。
-
特征融合:
在生成注意力权重前会对输入的局部和全局特征进行融合。通过全局池化(Global Average Pooling)来获得全局上下文信息。
-
Attention Estimator:
对输入特征图进行多层卷积、池化、激活等操作,用来挖掘特征之间的关系,从而生成注意力权重图。权重图的每个位置对应特征图中的一个空间位置,表示该位置的重要性。
-
Att. Weighted Combination:
将生成的注意力图与原始特征图逐点相乘,得到加权后的特征图。
3.2.2 融入模型
基于VGG16网络的多层注意力融合:是为了适配不同大小的目标。
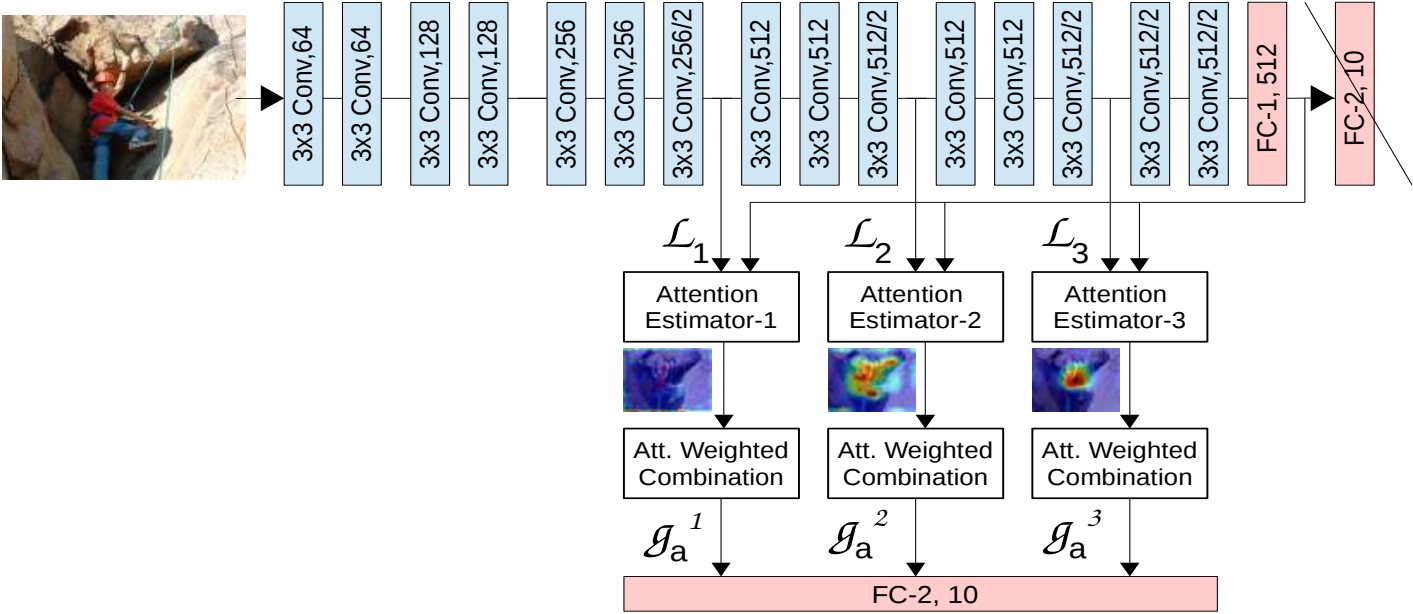
通过多层注意力估计器,模型能够学会在不同的特征层次上关注有用的信息,提升分类性能。
1)流程概述:
-
局部特征向量,s表示特征图层数:
-
(
)为VGG不同层级的局部特征向量,将
FC-1, 512的输出 G 视作全局特征,同时移除FC-2, 10层。 -
Attention Estimator 接收 L_n 和 G 作为输入,计算出注意力权重图(Attention map),挖掘特征之间的关系。
-
Attention map作用于 L_n 的每个channel得到 Weighted local feature
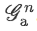 。
。 -
把各个层级下的
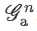 进行连接操作后得到
进行连接操作后得到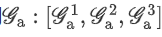
-
最后将
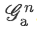 送入全连接层
送入全连接层FC-2, 10进行分类。
2)![]() 计算过程:
计算过程:
计算过程及关联数学公式如下:
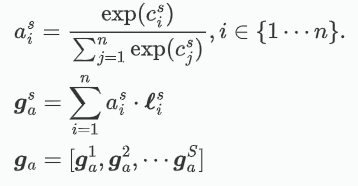
公式注解:
-
:第 s 层特征图在位置 i 处的兼容性分数(compatibility score)。
-
:通过 softmax 计算得到的第 s 层特征图在位置 i 处的注意力权重。
-
:经过注意力加权后的第 s 层特征图的全局加权特征向量。
-
:第 s 层特征图在位置 i 处的局部特征向量。
-
:注意力权重
相乘,表示该位置在注意力机制中的贡献。
-
:最终得到的全局加权特征向量,它是不同层的加权特征向量
-
2)兼容性得分计算:
兼容性得分,compatibility score,论文给出了两种方式:
-
内积法:两个特征直接做点乘得到:
-
有参法:将两个张量逐元素相加后,再经过一个全连接层进行学习, 下式中 \boldsymbol{u} 就是学习到的线性映射:
3.2.2 实验效果
从可视化和数据化两个方面进行观察。
1)效果可视化:

图阅读注解:
proposed:表示加入LTPA注意力机制。
existing:表示加入传统的注意力机制。
2)效果数据化
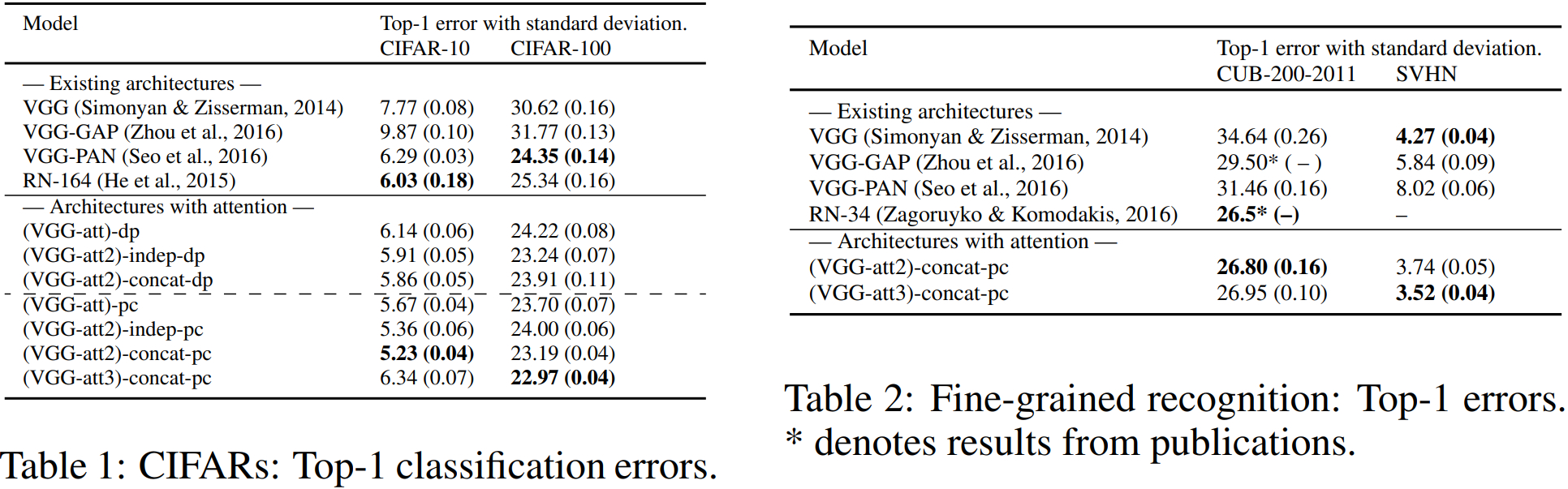
表阅读注解:注意力获取方法:pc表示有参法,dp表示内积法,最终预测策略:concat表示特征拼接后预测,indep表示多尺度独立预测结果相加
4. 混合注意力
混合注意力机制(Hybrid Attention Mechanism)是一种结合空间和通道注意力的策略,旨在提高神经网络的特征提取能力。
4.1 CBAM
Convolution Block Attention Module :卷积块注意力模块
论文地址:https://arxiv.org/pdf/1807.06521
4.1.1 基本认知
CBAM是一种轻量级的注意力模块,它通过增加空间和通道两个维度的注意力,来提高模型的性能。
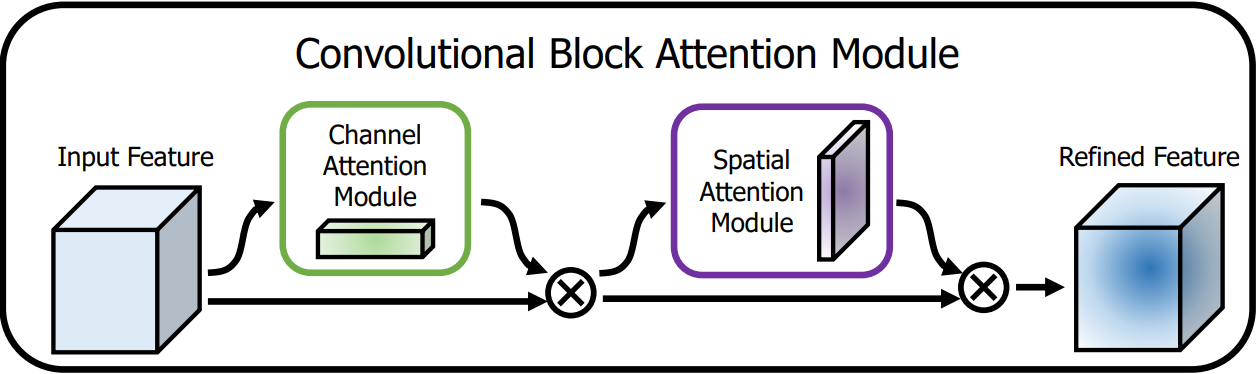
一维的通道注意力图:
二维的空间注意力图:
整个注意力过程可以概括为:
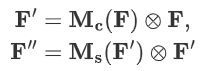
4.1.2 通道注意力模块
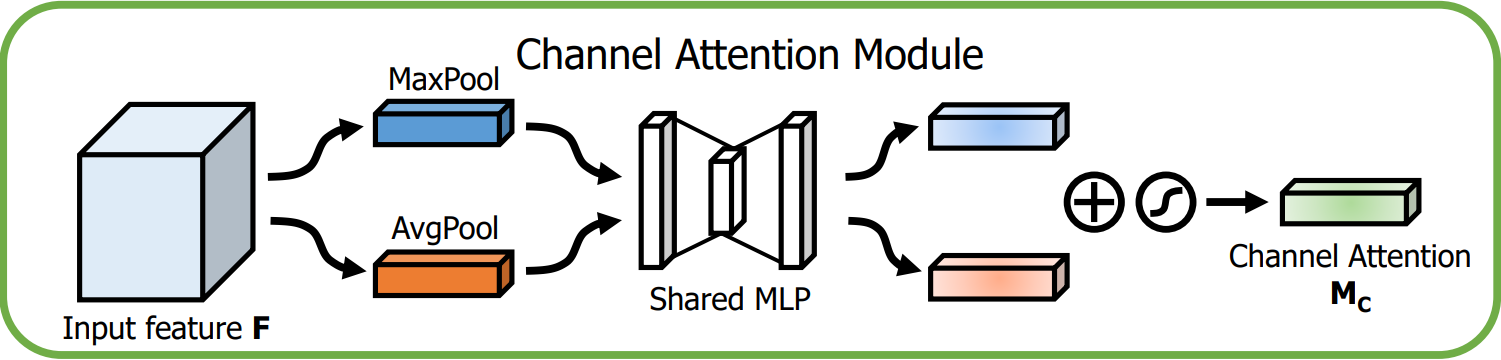
通道注意力模块的目的是为每个通道生成一个注意力权重,整体流程如下图:
通道注意力模块机制公式如下:
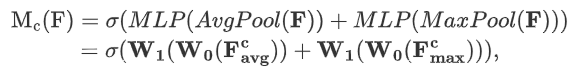
其中:r是缩放因子,用以减少参数量
通道注意力模块机制详情如下:
-
输入特征:输入特征图 F 的尺寸为 H × W × C。
-
全局池化:
-
首先对 F 进行全局的MaxPool和AvgPool,得到两个特征图,尺寸为 1×1×C。
-
MaxPool提取了局部强响应特征,AvgPool提取了全局视角。
-
-
共享多层感知器(MLP):
-
池化后的2个特征向量分别送入一个共享MLP,它包含两个全连接层,用来处理和生成通道注意力。
-
MLP的共享权重减少了参数量,同时确保两个特征向量的变换方式是一致的。
-
MLP首先会降维为 C/r,然后升维为 C。
-
-
加法与激活:
MLP输出的两个特征向量逐元素相加后经Sigmoid后,生成维度为 1 × 1 × C的通道注意力图
,表示每个通道的重要性。
-
输出:
通道注意力图
4.1.3 空间注意力模块
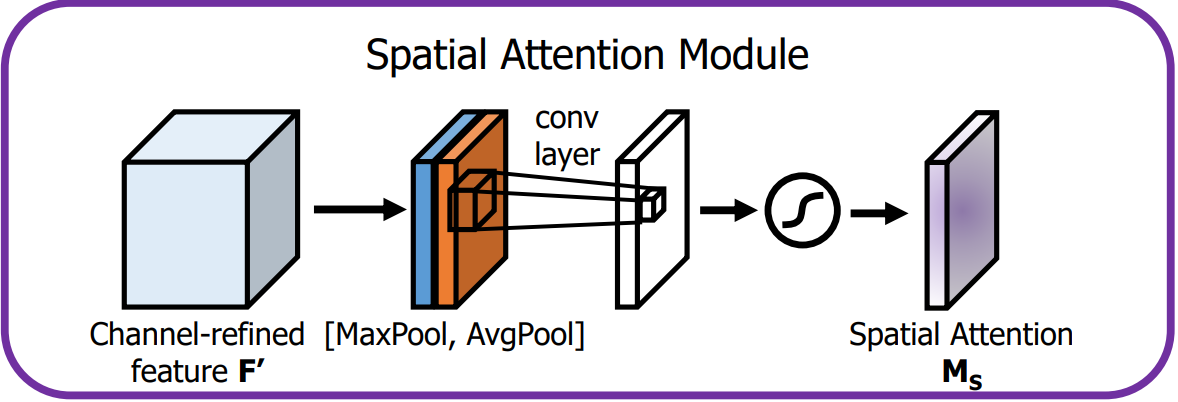
空间注意力模块通过卷积操作为特征图的每个空间位置生成权重,聚焦在图像中的关键区域。
空间注意力模块机制公式如下:
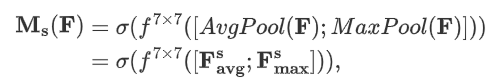
其中:
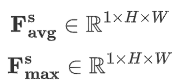
空间注意力模块机制详情如下:
-
输入特征:通道注意力模块的输出 F' 就是空间注意力模块的输入。
-
池化操作:
-
首先在 F' 的通道维度上进行全局的MaxPool和AvgPool,生成2个二维特征图,维度为 H × W × 1。
-
这样可以分别提取空间上最重要的局部和全局信息。
-
-
卷积层:
将池化得到的两个特征图按通道维度进行连接,形成一个 H × W × 2 的特征图,并通过大小为 7 × 7 的卷积层处理。
-
激活与输出:
-
卷积层的输出经Sigmoid激活后,生成单通道的空间注意力图
-
空间注意力图与经过通道注意力增强后的特征图 F' 逐元素相乘,输出最终的增强特征图。
-
4.1.4 不同策略效果对比
1)通道注意力:加入通道注意力:可以看的出来都比不用(baseline)效果要好。

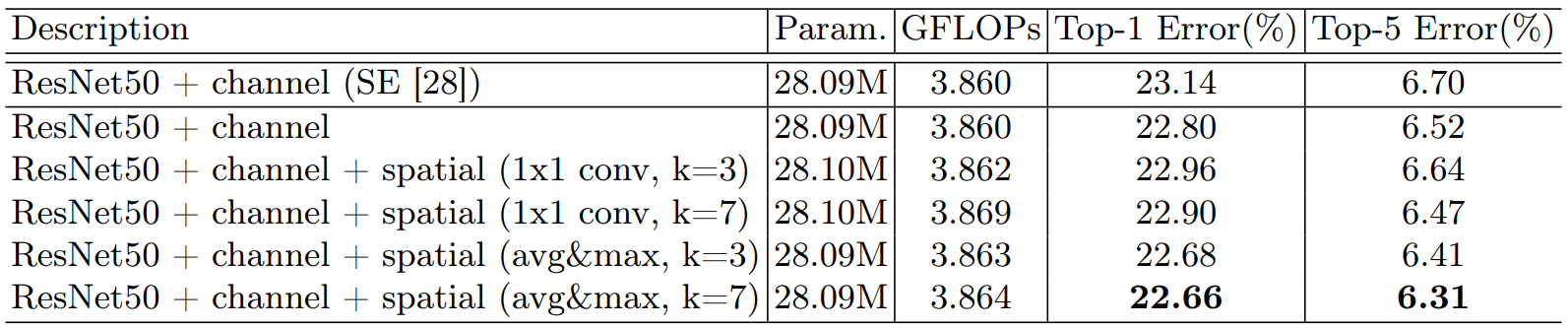
2)叠加空间注意力:在通道注意力的基础之上加入空间注意力,就是混合注意力:效果最好的就是CBAM,并且池化不需要参数。
3)叠加顺序:空间注意力和通道注意力位置调整效果对比:还是CBAM的效果好。

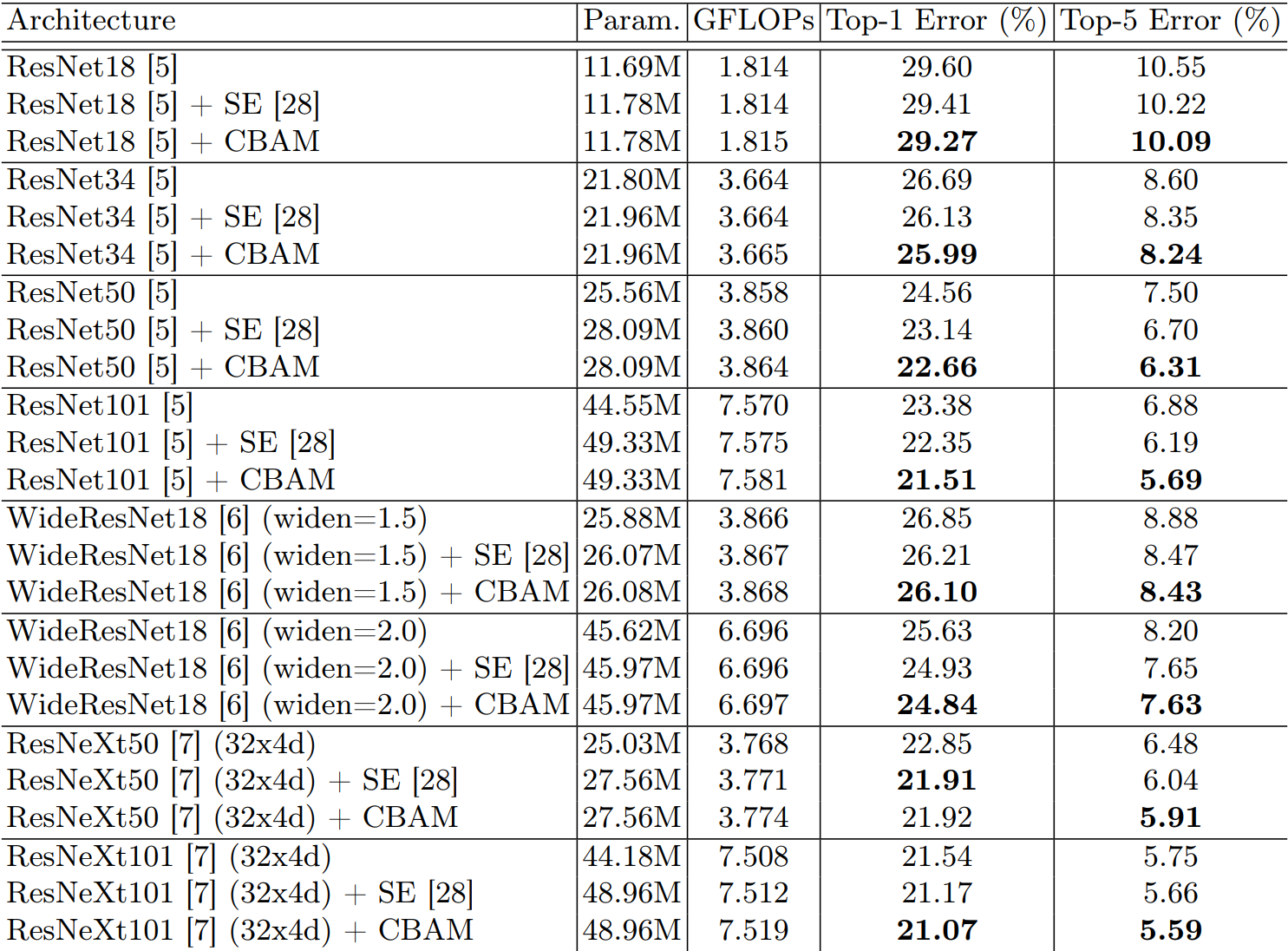
4)不同模型:不同模型对比:主打一个CBAM就是好。
5)轻量级模型:在一些轻量级模型上的效果还是很明显的。
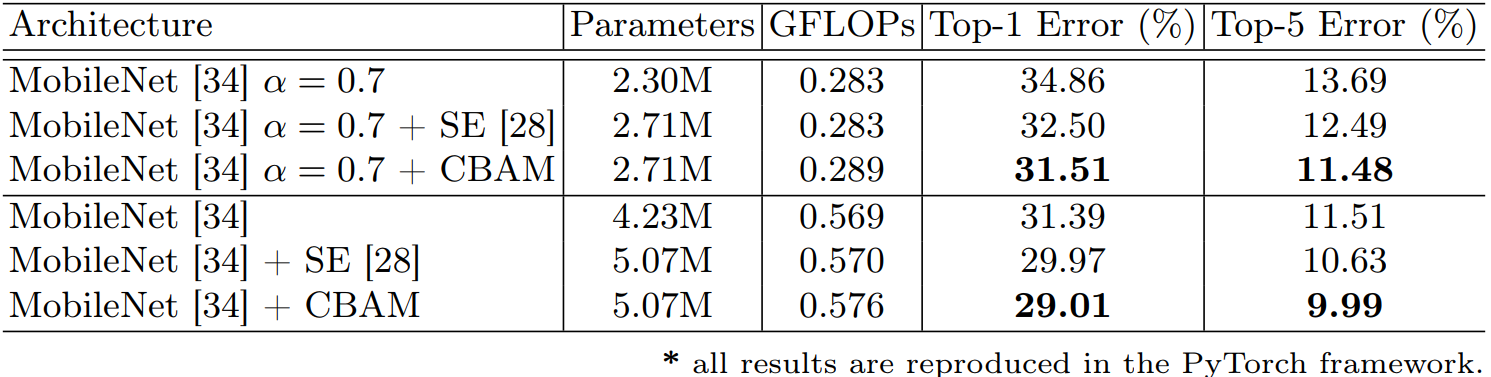
6)注意力可视化:可视化的方式对比。

4.2 BAM
Bottleneck Attention Module:瓶颈注意力模块。
论文地址:https://arxiv.org/pdf/1807.06514
4.2.1 基本认知
BAM是通过在空间和通道两个维度上分别构建注意力模块,它们是**并行处理**的。
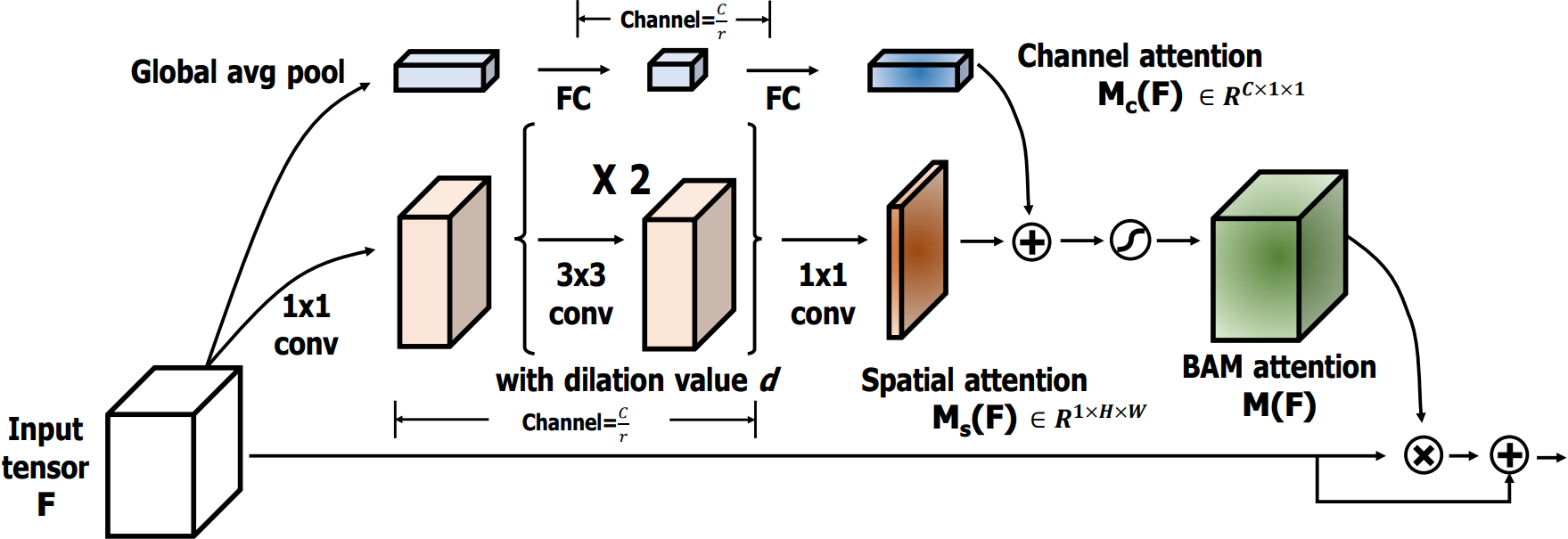
其中:形状不同的张量会自动进行广播机制。
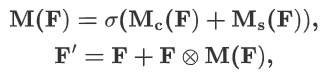
4.2.2 通道注意力模块
通道注意力公式表达如下:
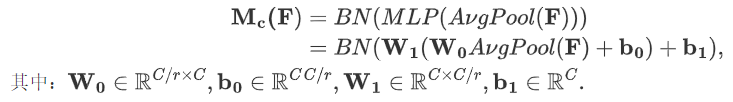
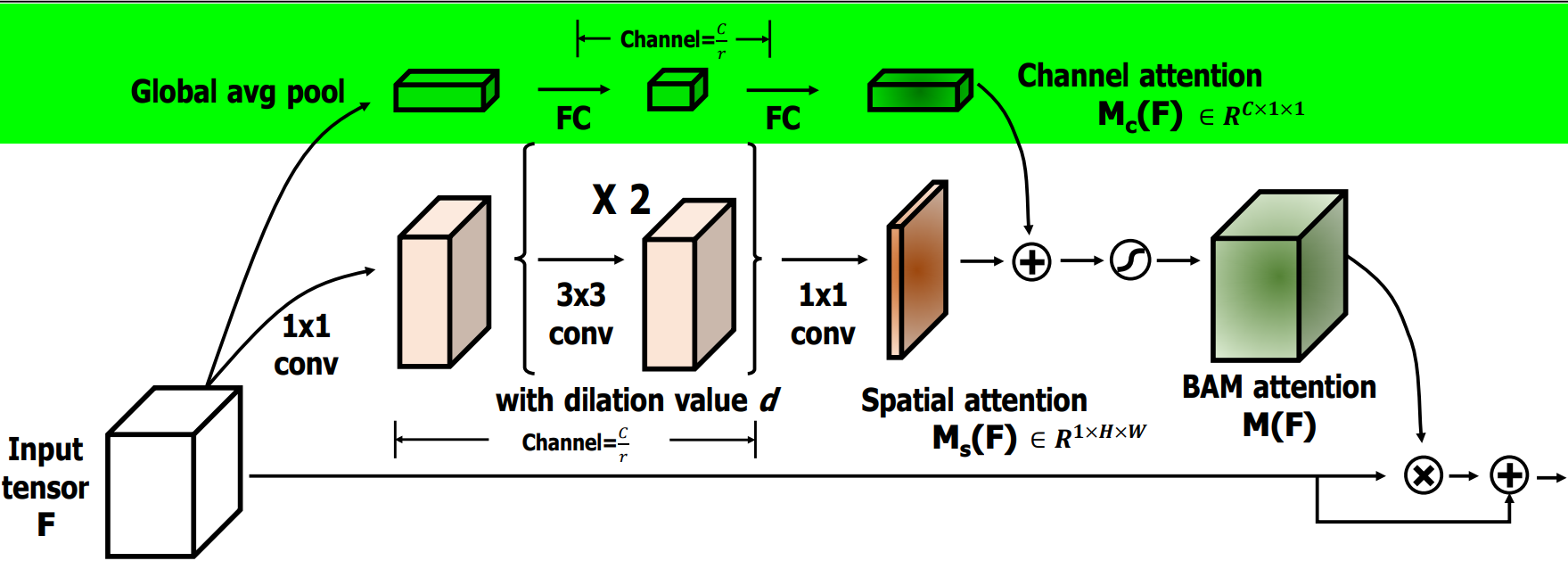
通道注意力流程如下:
-
全局平均池化:对输入特征 F 进行GlobalAvgPooling,保留通道的重要全局信息。
-
全连接层:池化后的特征通过两个FC,第一个FC降维,第二个FC则恢复到原通道数 C。这一过程可以学习通道间的依赖关系。
-
通道注意力:通过激活函数 Sigmoid 生成通道注意力图 M_c(F),用于对原始通道进行加权,强调重要通道,抑制不重要通道。
4.2.3 空间注意力模块
空间注意力公式表达如下:
![]()
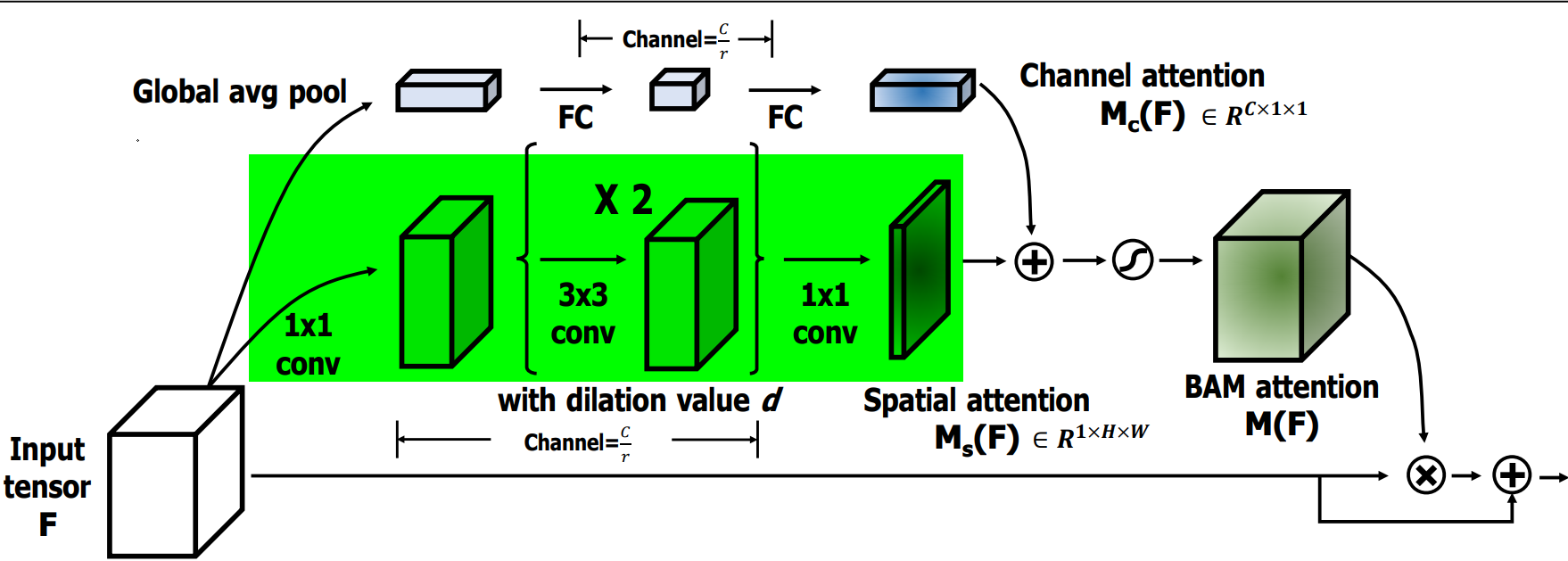
空间注意力流程如下:
-
1×1卷积:对输入特征 F 进行一次卷积操作,用于压缩通道维度并保持原始的空间信息,压缩因子是 r=16。
-
膨胀卷积:使用两层膨胀卷积(Dilated Convolution),膨胀率为 d=4。这样既扩大了感受野,又不增加参数量,帮助模型在空间维度上捕捉更广的上下文信息。
-
空间注意力生成:卷积操作生成一个空间注意力图 M_s(F),用于标识出空间维度上哪些位置更重要。
4.2.4 注意力融合
通道和空间注意力融合:和
相加后,通过Sigmoid处理,生成最终的注意力图
。
4.2.5 注意力应用
-
BAM注意力图 M(F) 应用到 F 上,从而对特征图进行重新加权。
-
残差连接:将加权后的特征图与输入特征 F 进行相加,形成残差连接。
这样不仅保留了原始特征信息,还让网络学习到重要的注意力区域。
4.2.6 实验结果
对比不同情况下的模型效果。
1)超参数配置:
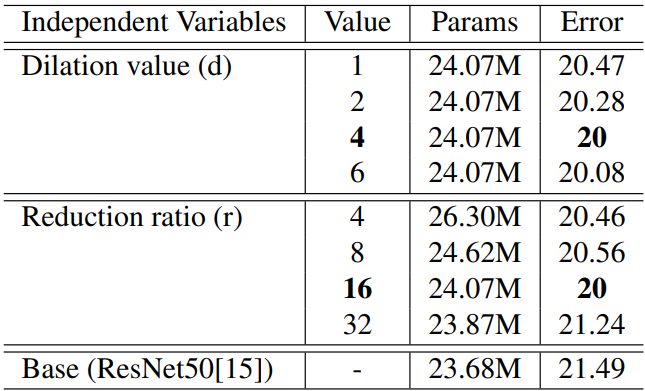
超参数:膨胀卷积的膨胀系数、FC的缩放因子
2)融合方式:
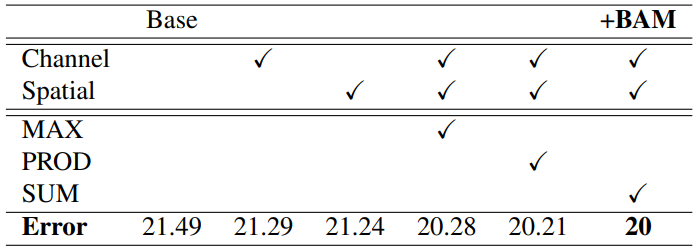
融合方式不同,效果也不同,最总就是两个注意力并行后相加效果最好。
3)模型横向对比:
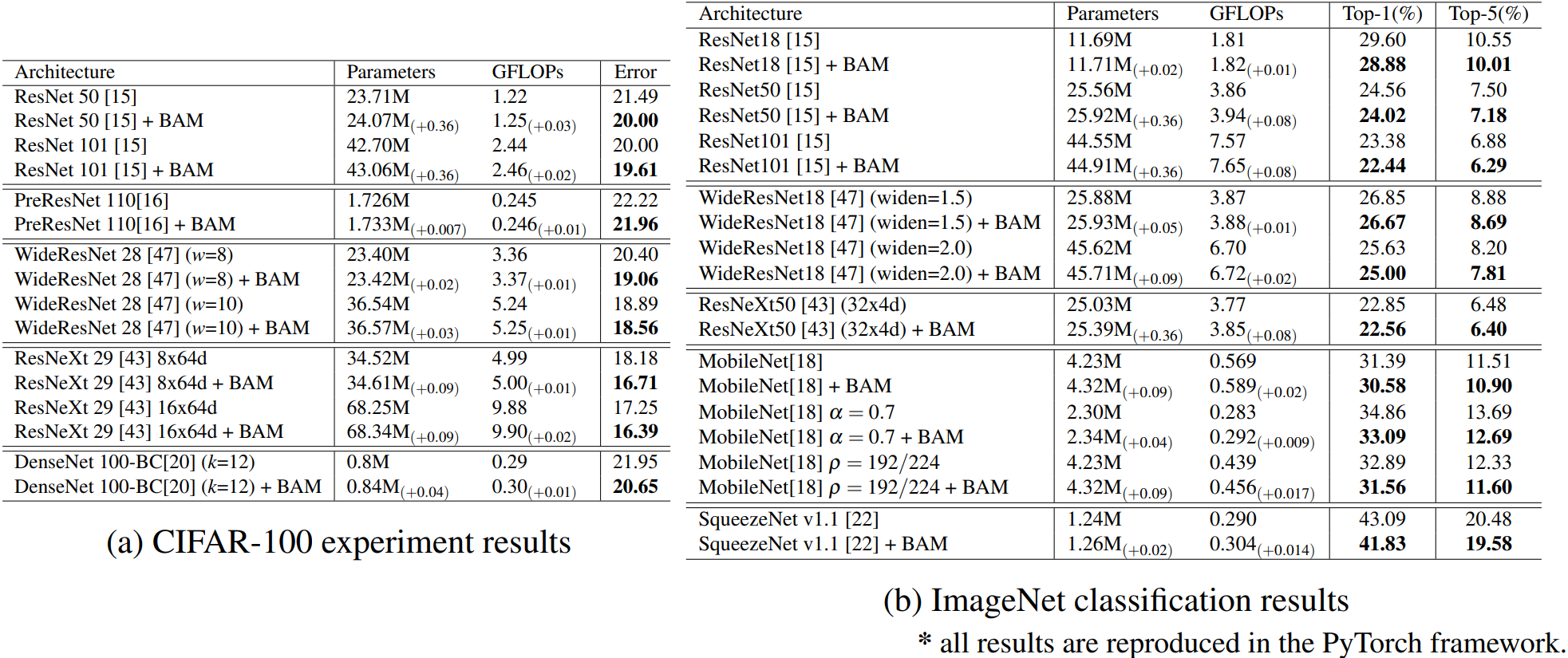
可以看的出来,加入BAM之后,都有明显的效果提升,说明这种方式是有效的且通用的。



完全指南】面向对象编程入门)



)





--- 版本1(Client端))





