本教程将演示如何使用PyTorch框架对预训练模型进行微调,实现热狗与非热狗图像的分类任务。我们将从数据准备开始,逐步完成数据加载、可视化等关键步骤。
1. 环境配置与库导入
%matplotlib inline
import os
import torch
from torch import nn
from d2l import torch as d2l
import torchvision2. 热狗数据集准备
# 热狗数据集配置
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')# 下载并加载数据集
data_dir = d2l.download_extract('hotdog')
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))3. 数据可视化
# 可视化训练集样本
import matplotlib.pyplot as plt# 设置画布大小
plt.figure(figsize=(12, 8))# 绘制前16张图片
for i, (image, label) in enumerate(train_imgs[:16]):plt.subplot(4, 4, i+1)plt.imshow(image)plt.title('hotdog' if label == 0 else 'not hotdog')plt.axis('off')plt.tight_layout()
plt.show()输出结果:
array([<Axes: >, <Axes: >, <Axes: >, <Axes: >, <Axes: >, <Axes: >,<Axes: >, <Axes: >, <Axes: >, <Axes: >, <Axes: >, <Axes: >,<Axes: >, <Axes: >, <Axes: >, <Axes: >], dtype=object)
(实际运行时将显示4x4网格排列的16张图像,包含热狗和其他食品的图片)
4.数据增强
normalize = torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]
)train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),normalize
])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize(256),torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(),normalize
])
5.定义并修改预训练模型
# 使用预训练的ResNet18模型
pretrained_net = torchvision.models.resnet18(pretrained=True)
print(pretrained_net.fc) # 最后一层全连接层查看
输出结果:
Linear(in_features=512, out_features=1000, bias=True)
# 修改最后一层,以适应我们二分类任务
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)
6.微调模型
定义微调函数:
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolderdef train_fine_tuning(net, lr, batch_size=128, num_epochs=5, param_group=True):train_iter = DataLoader(ImageFolder(os.path.join(data_dir,'train'), transform=train_augs),batch_size=batch_size,shuffle=True)test_iter = DataLoader(ImageFolder(os.path.join(data_dir,'test'), transform=test_augs),batch_size=batch_size,shuffle=False)devices = d2l.try_all_gpus()loss = nn.CrossEntropyLoss(reduction='mean')if param_group:params_lx = [param for name, param in net.named_parameters()if name not in ['fc.weight', 'fc.bias']]optim = torch.optim.SGD([{'params': params_lx},{'params': net.fc.parameters(), 'lr': lr * 10}], lr=lr, weight_decay=0.001)else:optim = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=0.001)d2l.train_ch13(net, train_iter, test_iter, loss, optim, num_epochs, devices)
使用小的学习率进行微调:
train_fine_tuning(finetune_net, 5e-5)
输出:
loss 0.006, train acc 0.606, test acc 0.599
18.3 examples/sec on [device(type='cuda', index=0)]
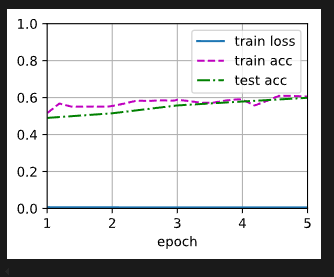
为了进行比较,所有模型参数初始化为随机值
scratch_net=torchvision.models.resnet18() # 没有预训练参数
scratch_net.fc=nn.Linear(scratch_net.fc.in_features,2) # 修改最后一层全连接层,输出为2
train_fine_tuning(scratch_net,5e-4,param_group=False) # param_group=False使得所有层的参数都为默认的学习率 输出:
loss 0.005, train acc 0.752, test acc 0.750
10.6 examples/sec on [device(type='cuda', index=0)]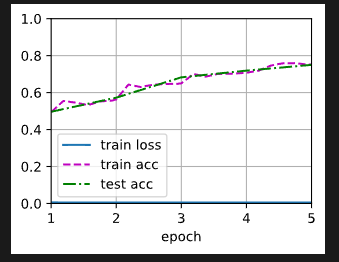
7.总结
本文完整展示了从数据准备到模型训练的热狗分类任务流程。关键步骤包括:
-
使用torchvision加载和预处理图像数据
-
可视化数据集样本
-
构建数据加载管道
-
修改预训练模型进行微调
-
训练和评估分类模型
实际应用中可以通过调整数据增强策略、尝试不同网络架构、优化超参数等方式进一步提升模型性能。后续可以扩展为部署到移动端的食品识别应用。
注意事项:
-
确保GPU环境加速训练
-
根据显存调整batch_size大小
-
适当调整学习率等超参数
-
添加早停机制防止过拟合
希望本教程能帮助您快速上手PyTorch模型微调任务!









——进一步完善内核)









