分享笔者在学习 MegEngine 对 DTR 的实现时的笔记。关于 DTR 可以参考:【翻译】DTR_ICLR 2021
文章目录
- MegEngine 架构设计
- MegEngine 的动态图部分
- Imperative Runtime
- Imperative 与 MegDNN / MegBrain 的关系
- 静态图运行时管家 —— MegBrain
- 动态图接口 —— Imperative
- 总结
- Imperative Runtime 架构解析
- MegEngine Python 层的 Tensor 行为
- MegEngine 引入 DTR 的过程
- MegEngine 1.4 实现 DTR 的核心代码
- imperative/src/impl/interpreter/tensor_info.h
- imperative/src/impl/interpreter/interpreter_impl.h
- imperative/src/impl/interpreter/interpreter_impl.cpp
- 分配
- 删除
- 核心实现
- 辅助函数
- 启发式公式
- 重计算次数
- 空闲显存块大小
- 参考资料
MegEngine 架构设计
以下内容引用自:MegEngine 架构设计 — MegEngine 1.13.2 文档
MegEngine 整体由两部分 Runtime 加上底层的公共组件组成:
- 其中静态图部分(又称 Graph Runtime )主要提供 C++ 推理接口;
- 动态图部分(又称 Imperative Runtime )主要提供 Python 接口供动态训练使用;
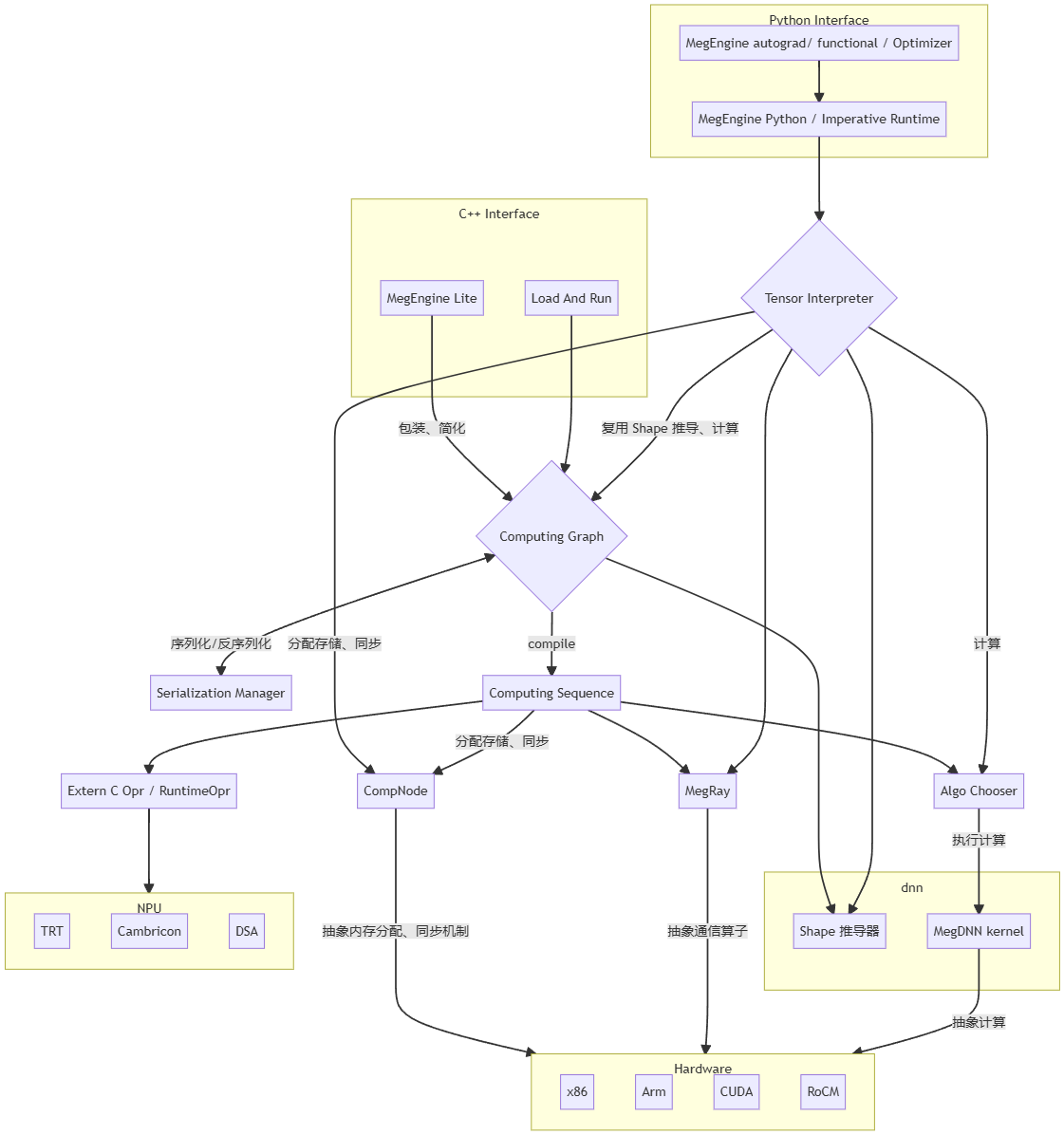
接口层
- MegEngine Imperative Runtime: 动态解释执行接口
- MegEngine Lite: C++ 静态图推理接口
- Load and run: 一份用于调试性能的工具(可看做一种推理代码的样例)
核心模块层
- Computing Graph: 一张以 OpNode 和 VarNode 依次相连的 DAG,用以表达全部计算依赖,是静态图的模式的核心。模块内部包含了图优化、静态推导、自动求导的各类功能。通过 compile 可以产生 Computing Sequence 以用于实际执行
- Computing Sequence: 一个带有依赖关系的执行序列,是 Computing Graph 的一种拓扑排序结果,其中包含了内存分配策略等资源信息,可以通过 execute 执行其中的全部 Op
- Tensor Interpreter: Tensor 解释器,用于解释执行动态模式下的计算操作;
- 其中部分操作是通过构建一张临时的 Computing Graph 来复用原有操作,
- 另一部分通过直接调用底层实现(以获得更高的性能)
工具模块
- Shape 推导器: 用于静态推导 shape
- Algo Chooser: 同一 Op 不同 kernel 的选择器,用以挑选在当前参数下最快的 kernel,是 Fastrun 机制的核心
- Serialization Manager: 对 Computing Graph 进行序列化 / 反序列化,提供无限向后兼容性 (backward compatible)
硬件抽象层(HAL)
- MegDNN kernel: 包含各类平台下的计算算子实现(部分简单算子直接在 megengine src 目录下实现,未包含在 dnn 中)
- Extern C Opr / Runtime Opr: 用于包装 DSA / TRT 等子图,对上层抽象为一个 Op
- CompNode: 对硬件的基本操作进行抽象,包括 执行计算、同步机制、内存分配、跨设备拷贝 等原语。一个 CompNode 对应一个 GPU stream 或 CPU 线程,部分硬件上实现了内存池以进一步提高性能
- MegRay: 对训练场景下的集合通讯、点对点通信进行了设备无关的抽象,底层对应了 nccl / rccl / ucx / 自研方案 等不同实现
硬件层
MegEngine 的动态图部分
以下内容引用自:Imperative Runtime — MegEngine 1.13.2 文档
Imperative Runtime
以下内容引用自:MegEngine/imperative at master · MegEngine/MegEngine
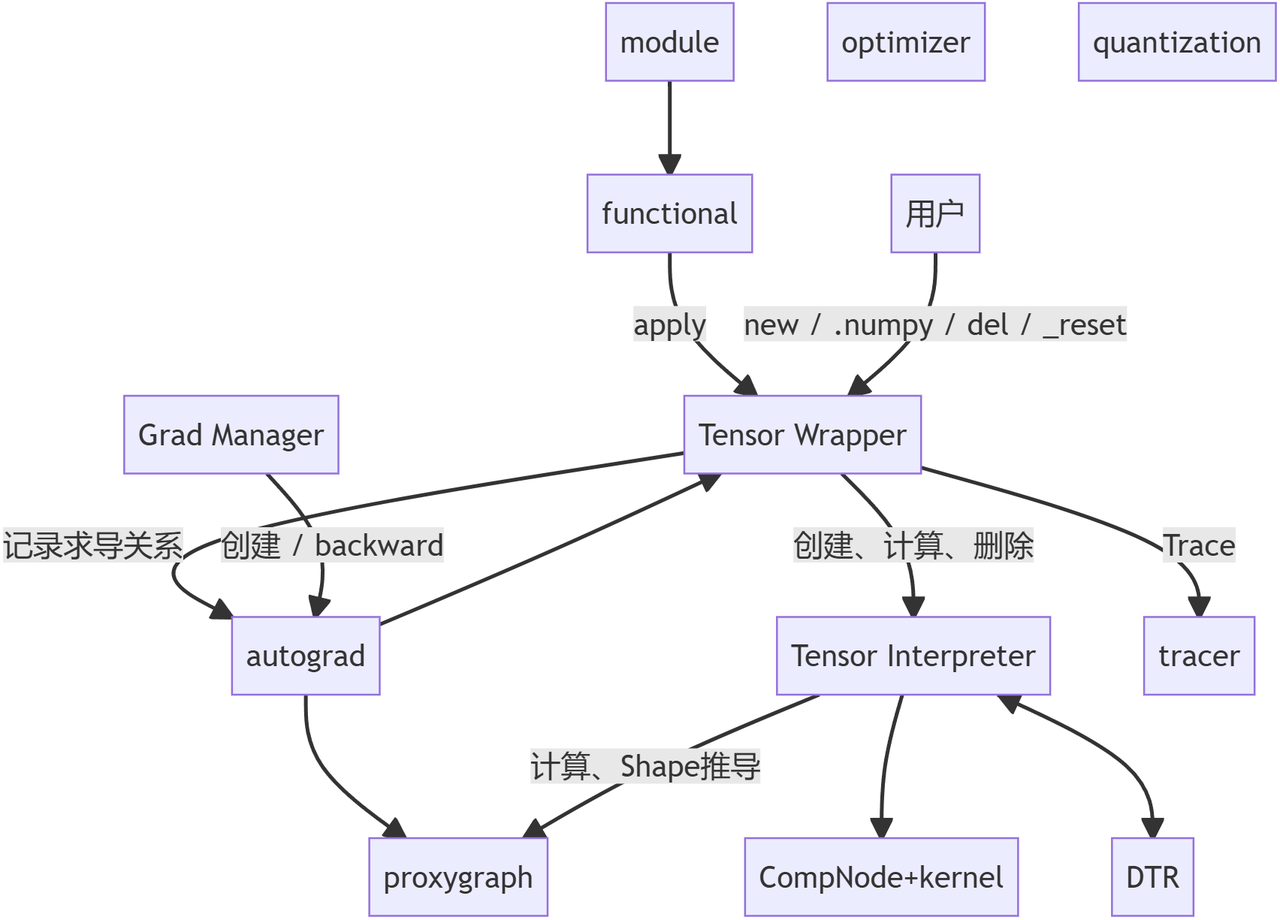
Imperative Runtime 是为了动态训练单独设计的一套新接口,其设计基本原则包含:
- 与 graph runtime 的计算行为尽可能复用相同的计算代码,确保训推一致性
- Pythonic 一切资源完全与 python 对象深度绑定
各类模块:
- module / optimizer 等:Python 模块
- functional: 各类计算函数,底层基本是直接调用 apply(OpDef, args)
- Tensor Wrapper: C++ 模块,从 Python 层可以直接看到的 tensor 类型,提供计算、自动微分、trace 等功能
- Tensor Interpreter:
- 一切计算的入口,提供 put tensor, apply(OpDef, tensor), get tensor 三大类功能
- 所有计算操作均为异步,因此除可被外界观测到的 put 和 get 外,其他操作均可被透明的调整顺序或优化
- 底层计算部分直接调用 kernel,部分通过 proxygraph 调用 graph runtime 实现
- DTR: 动态重计算模块,负责 Tensor Interpreter 的 drop 指令,确保记录计算过程,确保被 drop 掉的 tensor 在被需要时重新计算得到
- autograd: 自动微分机制,负责记录 Tensor Wrapper 的计算过程并通过 refcount 确保依赖的 tensor 不被释放
- tracer: 在 trace 模式下记录全部的计算过程,从而生成静态图
- proxygraph: 一系列桥接机制的统称,通过建立临时的计算图实现复用 graph runtime 中的计算、shape 推导的能力;其中的 graph 与用户实际计算无关,可随时清空。
Imperative 与 MegDNN / MegBrain 的关系
以下内容引用自:MegEngine 动态执行引擎-Imperative Runtime 概述
MegEngine 自上向下包含三个层次:Imperative、MegBrain 和 MegDNN。它们的角色定位分别是:
- Imperative:MegEngine 为动态训练设计的一套新接口,负责处理动态图运行时(Imperative Runtime)。
↑- MegBrain:负责处理静态图运行时(Graph Runtime)。
↑- MegDNN:MegEngine 的底层计算引擎。
静态图运行时管家 —— MegBrain
为了确保训练推理一致性, Imperative 中复用了 MegBrain 的计算代码。
MegBrain 负责处理静态图的运行时,主要提供 C++ 的训练和推理接口。
从 MegEngine 整体架构图可以看出,Imperative 通过 Tensor Interpreter (张量解释器)复用了许多 MegBrain 的代码。比如 shape 推导、计算、求导、Trace 等。
在 MegBrain 中,一个 Computing Graph 由 SymbolVar 以及许多 op(算子,operator)组成。SymbolVar 是在 MegBrain 层面 Tensor 的表示,可以理解为传递给 op 进行计算的数据。作个类比,
op是类似加减乘除这样的计算操作(在深度学习中常用的有convolution、pooling等),- SymbolVar 就是我们用来进行加减乘除的“数”(在深度学习中就是
Tensor)。
动态图接口 —— Imperative
因为 MegEngine 是动静合一的深度学习框架,MegBrain 解决了静态图的训练和推理问题,还需要有一个“组件”负责处理动态图的训练和推理、以及 Python 侧的训练接口,于是便有了 Imperative,也就是说,Imperative Runtime 是为了动态训练而单独设计的一套新接口。
实际上,在 MegBrain 的 Computing Graph 中已经有了非常多的算子实现,因此 MegEngine 的 Imperative 借助张量解释器 Tensor Interpreter 较多地复用了 MegBrain 中的 op。这样做的原因是:
- 重写算子代价高,且容易写错。
- 若 Imperative 的实现和 MegBrain 的实现不一致的话,容易导致训练推理不一致。
除了复用 MegBrain 的部分功能,Imperative 自身包含的模块主要有:
Module(定义深度学习网络的基础类的实现)Optimizer(一些优化器的实现)Functional(提供 python 层的训练接口)Interpreter(计算入口,底层会调用 kernel 或者 MegBrain 的算子实现)DTR(动态重计算模块)Tracer(记录计算图的计算过程)等
总结
简单来说,MegDNN 负责 MegEngine 中所有的计算操作在各个平台(CUDA 等)的最终实现,无论是 MegBrain 还是 Imperative 的 op,最终都需要通过调用 MegDNN kernel 来完成计算。
既然 MegDNN 包揽了计算的活儿,那么在训练推理过程中那些与计算无关的工作,自然就落到了 MegBrain 和 Imperative 的头上。这些工作包括:
- 求导
- 内存分配
- 对
Tensor的shape进行推导 - 图优化
- 编译等
MegEngine 整体上是有两部分 Runtime 以及底层的一些公共组件组成的。这两部分的 Runtime 分别叫做 Graph Runtime(对应 MegBrain) 和 Imperative Runtime(对应 Imperative)。
- Graph Runtime 负责静态图部分,主要提供 C++ 训练推理接口。实际计算时需要调用
MegDNN的实现。 - Imperative Runtime 负责动态图部分,主要为动态训练提供 Python 接口。实际计算时需要调用
MegBrain的已有实现或者直接调用MegDNN的 kernel。
Imperative Runtime 架构解析
以下内容引用自:MegEngine 动态执行引擎-Imperative Runtime 架构解析
计算图可以认为是对输入的数据(tensor)、op 以及 op 执行的顺序的表示。
计算图分为动态图和静态图。
- 动态图是在前向过程中创建、反向过程销毁的。前向逻辑本身是可变的,所以执行流程也是可变的(因此叫动态图),而静态图的执行流程是固定的。也就是说,动态图在底层是没有严格的图的概念的(或者说这个图本身一直随执行流程变化)。
- 对于动态图来说,graph 的 node 对应的概念是
function/ 算子,而 edge 对应的概念是tensor,所以在图中需要记录的是 graph 中node和edge之间的连接关系,以及tensor是function的第几个输入参数。 - 静态图需要先构建再运行,可以在运行前对图结构进行优化(融合算子、常数折叠等),而且只需要构建一次(除非图结构发生变化)。而动态图是在运行时构建的,既不好优化还会占用较多显存。
MegEngine Python 层的 Tensor 行为
以下内容引用自:MegEngine Python 层 Tensor 行为 — MegEngine 1.13.2 文档
从逻辑上来讲,各层之间的引用关系如下图所示:
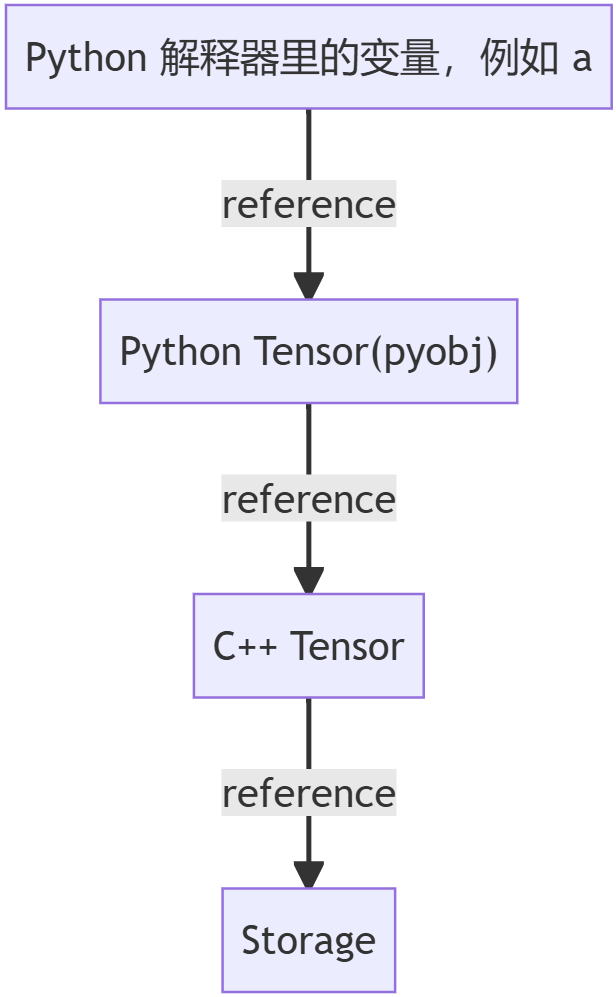
三者均通过 refcount 进行资源管理,在引用归零时就释放资源,其中:
- Python Tensor 只包含对 C++ Tensor 的引用;用户可通过 id(a) 是否一直来验证是否发生了变化
- C++ Tensor 包含:shape / stride / 对 Storage 的引用指针
Storage包含:一段显存,即ptr + length
MegEngine 引入 DTR 的过程
- v1.4.0
- 重构 DTR 相关的 API 并修复其中随机数算子相关的 bug。
- 在开启DTR训练时,可能会出现申请显存失败的报错日志,这说明当前正在进行碎片整理,整理后程序可能可以继续运行。
- v1.5.0
- DTR 升级
- 在 trace 的静态构造模式下支持用 DTR 算法优化计算图的显存峰值,与 Sublinear 相比,ResNet 50 单卡最大 batch size 350->450,八卡 300→450。
- 动态图模式下支持无阈值开启,用户无需指定 eviction_threshold。
- DTR 升级
- v1.6.0
- 修复开启 DTR 时由于重算链过长导致递归栈溢出的问题。
- DTR 优化,各模型测试速度平均提升约10%,ResNet50 8 卡最大 batchsize 达500, GL 8 卡最大 batchsize 达 110, ViT 8 卡最大 batchsize 达 300 。
- v1.7.0
- 修复禁止 DTR 功能时未释放相关资源的问题。
- 解决 DTR 平方根采样不随机的问题,解决后 resnet1202 训练速度可提升5%。
- 删除 DTR 中所有 swap 接口。
- 显存分配默认开启去碎片功能,去除 enable_defrag 接口。
- 训练时自动打开 defrag 功能,显存不够且显存碎片严重时可合并显存碎片。
- v1.10.0
- v1.10 trace 模式下 sublinear 和静态图 dtr 是失效的。
- v1.11.0
- 修复参数 tensor 初始化中未考虑 DTR 导致的卡死问题。
- v1.12.2
- 修复开启 DTR 时,使用 stack/concat 算子程序崩溃的问题。
- v1.12.4
- 修复了开启 DTR 情况下多卡训练概率性崩溃的问题。
MegEngine 1.4 实现 DTR 的核心代码
imperative/src/impl/interpreter/tensor_info.h
代码地址:MegEngine/imperative/src/impl/interpreter/tensor_info.h at release-1.4 · MegEngine/MegEngine
在网络训练的过程中,每个 tensor 的来源只有两种情况:
- 由外部数据加载进来,例如:输入数据;
- 是某个算子的输出,例如:卷积层的输出。
对于算子的输出,我们可以记录这个 tensor 的计算路径(Compute Path),结构体如下所示:
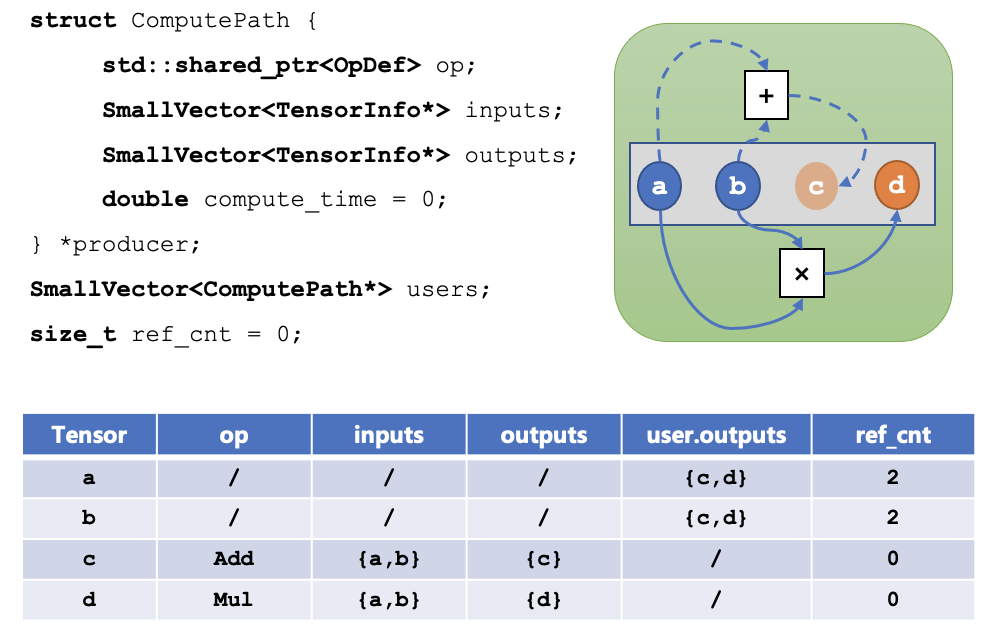
- 每个 tensor 都会有一个 producer,如果 producer 是空,就表示它是由外部数据加载进来的,否则它是一个计算路径,其中:
op表示产生这个 tensor 的算子;inputs表示这个算子需要的输入 tensor;outputs表示这个算子产生的输出 tensor;compute_time表示这个算子实际的运行时间;
users中存储的是所有依赖该 tensor 作为输入的计算路径;ref_cnt表示依赖该 tensor 作为输入的 tensor 数量。
// 定义了三种逐出(eviction)类型
enum EvictType {NONE = 0,SWAP = 1,DROP = 2,
};/*!* an identifier to specify a component of evicted tensors * 用于指定被逐出张量的组成部分的标识符* Each component tracks the sum of the compute costs of its elements, with the union of two components having the sum of each constituent cost.* 每个组件跟踪其元素的计算成本总和,两个组件的并集具有每个组成成本的总和。* * 对应 CheckpointTensorImpl.h 里的 struct EquivalentClassNode*/
struct DsuNode {DsuNode(double _t): t(_t) {}std::shared_ptr<DsuNode> parent;bool is_root() {return !bool(parent);}double t;
};struct TensorInfo;
using TensorInfoPtr = std::shared_ptr<TensorInfo>;struct TensorInfo {enum Prop {Device, Shape, DType, DevValue, HostValue};uint64_t id;TensorPtr ptr; // 指向物理张量(TensorPtr)的指针。LogicalTensorDesc desc; // 逻辑张量描述double compute_time; // 计算时间size_t memory; // 占用的内存大小double last_used_time; // 最后使用时间// FIXME: broken by dropbool value_fetched = false;bool invalid = false;bool allow_delete = false;EvictType evict_type = NONE; // 逐出类型HostTensorND h_value; // 主机端的张量值// reserved for auto dropsize_t pinned = 0; // 固定计数,用于防止逐出。size_t recompute_times = 0; // 重新计算次数。size_t ref_cnt = 0; // 引用计数。表示依赖该 tensor 作为输入的 tensor 数量。std::shared_ptr<DsuNode> dsu_ptr; // 对应 CheckpointTensorImpl.h 里的 ecn_ptr 驱逐邻域struct ComputePath { // tensor 的计算路径std::shared_ptr<OpDef> op; // 表示产生这个 tensor 的算子SmallVector<TensorInfo*> inputs; // 表示这个算子需要的输入 tensorSmallVector<TensorInfo*> unique_inputs;SmallVector<TensorInfo*> outputs; // 表示这个算子产生的输出 tensordouble compute_time = 0; // 表示这个算子实际的运行时间size_t ref_cnt() {return outputs.size() - std::count(outputs.begin(), outputs.end(), nullptr);}// 对应 CheckpointTensorImpl.h 里的 Tensors CheckpointTensorImpl::makestatic ComputePath* make(std::shared_ptr<OpDef> op, SmallVector<TensorInfo*> inputs, SmallVector<TensorInfo*> outputs) {auto* path = new TensorInfo::ComputePath();path->op = op;path->inputs = inputs;path->outputs = outputs;// dedupSmallVector<TensorInfo*> unique_inputs = inputs;std::sort(unique_inputs.begin(), unique_inputs.end());unique_inputs.erase(std::unique(unique_inputs.begin(), unique_inputs.end()), unique_inputs.end());path->unique_inputs = unique_inputs;// attach usersfor (auto input: unique_inputs) {input->users.push_back(path);}// attach producerfor (auto output: outputs) {output->producer = path;}// update ref_cntfor (auto input: inputs) {input->ref_cnt += outputs.size();}return path;}}* producer = nullptr; // 每个 tensor 都会有一个 producer,如果 producer 是空,就表示它是由外部数据加载进来的,否则它是一个计算路径。// 改进的估价函数。对应 CheckpointTensorImpl.h 里的 struct CheckpointInfo → double cost(size_t memory, size_t staleness)double eval_func(double cost, double free_mem, double cur_time,double param_cost, double param_mem, double param_time, double param_recompute_times) {return pow(cost + 1e-3, param_cost) * pow(param_recompute_times, (double)recompute_times)/ (pow((memory + free_mem) / 1024.0 / 1024.0, param_mem) * pow((double)(cur_time - last_used_time + 1e-3), param_time));}void pin() { // 对应 CheckpointTensorImpl.h 里的 struct AliasPool → void lock()++pinned;}void unpin() { // 对应 CheckpointTensorImpl.h 里的 struct AliasPool → void unlock()--pinned;}void detach_producer() { // 断开当前 TensorInfo 对象与其 producer(ComputePath对象)的连接if (!producer) {return;}auto output = std::find(producer->outputs.begin(), producer->outputs.end(), this);mgb_assert(output != producer->outputs.end());*output = nullptr;if (producer->ref_cnt() == 0) {for (auto* input: producer->unique_inputs) {input->users.erase(std::find(input->users.begin(), input->users.end(), producer));}delete producer;}producer = nullptr;}bool size_exceeds_thd(size_t thd) { // 检查内存大小是否超过阈值return memory > thd;}SmallVector<ComputePath*> users; // 存储的是所有依赖该 tensor 作为输入的计算路径
};
对using TensorInfoPtr = std::shared_ptr<TensorInfo>;的理解:
std::shared_ptr是一个模板类,它接受一个模板参数,这里是TensorInfo,表示这个智能指针将管理TensorInfo类型的动态对象。std::shared_ptr通过引用计数机制来管理内存。当一个shared_ptr被复制时,它所指向的对象的引用计数会增加;当shared_ptr超出作用域被销毁时,引用计数会减少。当引用计数降到0时,shared_ptr会自动释放它所管理的内存。- 这里的
TensorInfoPtr是一个类型别名,它指向std::shared_ptr<TensorInfo>。这意味着TensorInfoPtr是一个指向TensorInfo对象的共享指针类型。当使用TensorInfoPtr来声明一个变量时,这个变量将是一个智能指针,它指向一个TensorInfo对象。
imperative/src/impl/interpreter/interpreter_impl.h
代码地址:MegEngine/imperative/src/impl/interpreter/interpreter_impl.h at release-1.4 · MegEngine/MegEngine
/*!* \brief A framework of dynamic sublienar memory optimization 动态次线内存优化框架** Note: The main idea is that during the training process, if the memory usage exceeds the threshold, select some tensors to evict until the memory usage is below the threshold.* 注意:主要思想是在训练过程中,如果内存使用量超过阈值,则选择一些张量进行驱逐,直到内存使用量低于阈值。*/struct DynamicSublinear {/*!* \brief find an available tensor with the largest evaluation function 找到具有最大评估函数的可用张量** Note: An available tensor must satisfy: (1) has computing path, (2) is in memory, (3) is not pinned. Evaluation function refers to:* 注意:可用的张量必须满足:(1)具有计算路径,(2)在内存中,(3)未固定。* 评价函数是指:TensorInfo::eval_func.** \return the pointer of the best tensor; nullptr is returned if no available tensor is found 最佳张量的指针;如果没有找到可用的张量,则返回 nullptr*/TensorInfo* find_best_tensor();/*!* \brief estimate the cost of recomputing tensor ptr 估计重新计算张量 ptr 的成本** Note: We define the cost as the sum of the costs of each evicted components where all the neighbors of ptr are located.* 注意:我们将成本定义为 ptr 的所有邻居所在的每个被驱逐组件的成本之和。*/double estimate_neighbor_cost(TensorInfo* ptr);/*!* \brief update the last used time of the tensor ptr 更新张量 ptr 的最后使用时间*/void update_used_time(TensorInfo* ptr);/*!* \brief merge the two specified sets (the set in which the element x is located, and the set in which the element y is located)* 合并两个指定的集合(元素x所在的集合,和元素y所在的集合)*/void merge(std::shared_ptr<DsuNode> &x, std::shared_ptr<DsuNode> &y);/*!* \brief return the representative of the set that contains the element x 返回包含元素 x 的集合的代表*/std::shared_ptr<DsuNode> find_father(std::shared_ptr<DsuNode> &x);/*!* \brief update DSU after recomputing tensor ptr 重新计算张量 ptr 后更新 DSU** Delete ptr from the set where ptr is located. * 从ptr所在集合中删除ptr。* Since DSU does not support this operation, instead, we reset the DSU father of ptr, and subtract the recomputation cost of ptr from the cost of the original set.* 由于DSU不支持此操作,因此我们重置ptr的DSU父亲,并从原始集合的成本中减去ptr的重新计算成本。*/void update_dsu_after_recompute(TensorInfo* ptr);/*!* \brief update DSU after evicting tensor ptr 驱逐张量 ptr 后更新 DSU** Check the neighbors of x, that is, the input and output tensors, and if they are evicted, merge their respective sets.* 检查 x 的邻居,即输入和输出张量,如果它们被驱逐,则合并它们各自的集合。*/void update_dsu_after_evict(TensorInfo* ptr);/*!* \brief pin the tensors in vec 将张量固定在 vec 中*/void pin(const SmallVector<TensorInfo*>& vec);/*!* \brief unpin the tensors in vec 取消固定 vec 中的张量*/void unpin(const SmallVector<TensorInfo*>& vec);/*!* \brief add the tensor to the candidate set 将张量添加到候选集中** If the size of the tensor does not exceed the minimum threshold, it will do nothing.* 如果张量的大小没有超过最小阈值,则不会执行任何操作。*/void insert_candidate(TensorInfo* ptr);/*!* \brief erase the tensor from the candidate set 从候选集中删除张量** If the size of the tensor does not exceed the minimum threshold, it will do nothing.* 如果张量的大小没有超过最小阈值,则不会执行任何操作。*/void erase_candidate(TensorInfo* ptr);//! estimate the current time, in order to reduce the overhead of timer// 估计当前时间,以减少定时器的开销double estimate_timestamp = 0;//! the comp node where dynamic sublinear memory optimization works// 动态亚线性内存优化工作的 comp 节点CompNode comp_node;//! store all tensors that may be evicted // 存储所有可能被驱逐的张量std::unordered_set<TensorInfo*> candidates;//! whether the warning message has been printed 是否打印警告信息bool warn_printed = false;bool is_bad_op(std::string op_name) {return std::find(op_blacklist.begin(), op_blacklist.end(), op_name) != op_blacklist.end();}std::vector<std::string> op_blacklist = {"CollectiveComm", "InplaceAdd","ParamPackSplit", "ParamPackConcat", "GaussianRNG"};} m_dtr;//! automatically evict an optimal tensor 自动驱逐最佳张量void auto_evict();
imperative/src/impl/interpreter/interpreter_impl.cpp
代码地址:MegEngine/imperative/src/impl/interpreter/interpreter_impl.cpp at release-1.4 · MegEngine/MegEngine
分配
/*** 被以下函数调用 * - Handle ChannelImpl::put* - void ChannelImpl::dispatch_kernel* * ★ 重要函数:分配一个新的 TensorInfo 对象,并将其加入到有效的处理列表中。*/
TensorInfo* ChannelImpl::alloc() {MGB_LOCK_GUARD(m_mutex);auto info = m_pool.alloc();m_valid_handle.insert(info);info->id = m_last_id++;if (m_channel_state.profiler->is_profiling()) {m_channel_state.profiler->record_host<TensorDeclareEvent>(info->id);}return info;
}
删除
当一个 tensor 不会再被用户和框架使用时,这个 tensor 就可以被删除,从而释放其占用的显存。MegEngine 通过引用计数来控制 tensor 的删除,当引用计数变为 0 的时候,这个 tensor 就会自动发一个删除的语句给解释器。这样带来的问题是,如果真的把这个 tensor 删除的话,它确实可以立即节省显存,但会让整体的策略变得非常局限。
比如下面这张图是某张计算图的子图,可以看到一个 9MB 的 tensor 经过一个卷积算子,得到了一个 25MB 的 tensor,再经过一个 Elemwise 算子,得到一个 25MB 的 tensor,再经过 BatchNorm 算子和 Elemwise 算子,得到的都是 25MB 的 tensor。

注意到,由于这里的 Elemwise 算子都是加法,所以它的输入(两个红色的 tensor)在求导的时候都不会被用到。因此,求导器不需要保留住两个红色的 tensor,在前向计算完之后它们实际上是会被立即释放掉的。这样的好处是可以立即节省显存,但在引入 DTR 技术之后,如果真的删掉了这两个红色的 tensor,就会导致图中绿色的 tensor 永远不可能被释放,因为它们的计算源(红色 tensor)已经丢失了,一旦释放绿色的 tensor 就再也恢复不出来了。解决方案是在前向的过程中用释放来代替删除,也就是“假删除”——保留 tensorInfo,只是释放掉 tensorInfo 下面对应的显存。这样只需要保留 9MB 的 tensor 就可以释放掉后面 4 个 25MB 的 tensor,并且可以在将来的任意时刻恢复出它们。

上图就是 MegEngine 中对 tensor 的删除的伪代码实现,
在解释器收到 Del 指令时,会对 tensorInfo 调用 Free()函数,根据当前的状态是否是前向计算来决定做真删除还是假删除。
- 假删除的实现很简单,打上删除标记,释放掉 tensorInfo 管理的显存即可;
- 真删除的实现比较复杂,
- 首先更新产生该 tensor 的输入 tensor 的 ref_cnt,
- 然后调用 RemoveDep()检查所有依赖该 tensor 作为输入的 tensor,如果它们不在显存中,必须现在调用 Regenerate 恢复出它们,因为一旦当前 tensor 被真删除,这些 tensor 就恢复不出来了。
- 做完了上述操作之后,就可以真正释放掉该 tensor 对应的 tensorInfo 了。释放完还需要递归地检查 x 的计算历史输入 tensor,如果这些 tensor 中有 ref_cnt=0 且被打上删除标记的,就可以执行真删除。
/*** 被 void ChannelImpl::process_one_task 调用 * * ★ 重要函数*/
void ChannelImpl::free(TensorInfo* ptr) { // 在解释器收到 Del 指令时,会对 tensorInfo 调用 Free()函数if (m_worker_state.options.enable_dtr_auto_drop) {// Evicting a tensor, rather than freeing it, can avoid pinning potentially exploding amounts of memory and allow us to save more memory.// 驱逐张量而不是释放它可以避免固定可能爆炸的内存量,并允许我们节省更多内存。ptr->allow_delete = true;// 如果引用计数(ref_cnt)为零,则递归地释放 tensor(recursive_free),否则执行假删除(do_drop)。if (!ptr->ref_cnt) {recursive_free(ptr);} else {do_drop(ptr);}} else {real_free(ptr);}
}/*** 被以下函数调用* - void ChannelImpl::free* - void ChannelImpl::auto_evict* - void ChannelImpl::process_one_task* * ★ 重要函数*/
void ChannelImpl::do_drop(TensorInfo* ptr, bool user=false) { // 假删除的实现很简单,打上删除标记,保留 tensorInfo,释放掉 tensorInfo 管理的显存if (!ptr->producer) {if (user) { // 生成张量 ptr 的输入已被删除,此删除操作将被忽略mgb_log_warn("the input that produced tensor %p has been deleted, this drop operation will be ignored", ptr);}return;}if (ptr->evict_type != EvictType::NONE) {return;}ptr->evict_type = EvictType::DROP; // 打上删除标记release_tensor(ptr); // 释放掉 tensorInfo 管理的显存
}/*** 被以下函数调用* - void ChannelImpl::do_drop* - void ChannelImpl::process_one_task* * ★ 重要函数*/
void ChannelImpl::release_tensor(TensorInfo* dest) { // 释放掉 tensorInfo 管理的显存MGB_LOCK_GUARD(m_mutex);dest->ptr.reset(); // 通过重置 ptr 来释放与之关联的 Tensor 对象
}/*** 被 void ChannelImpl::free 调用* * ★ 重要函数*/
void ChannelImpl::recursive_free(TensorInfo* ptr) { SmallVector<TensorInfo*> inps(0);if (ptr->producer) {for (auto i : ptr->producer->inputs) {if (i && --i->ref_cnt == 0) { // 更新产生该 tensor 的输入 tensor 的 ref_cntinps.push_back(i); // 如果引用计数降至零,则将这些输入加入到递归释放的列表中。}}}real_free(ptr); // 真正释放掉该 tensor 对应的 tensorInfo// 释放完还需要递归地检查 x 的计算历史输入 tensor,如果这些 tensor 中有 ref_cnt=0 且被打上删除标记的,就可以执行真删除。for (auto i : inps) {if (i->allow_delete) {recursive_free(i);}}
}/*** 被以下函数调用* - void ChannelImpl::free* - void ChannelImpl::recursive_free* * ★ 重要函数*/
void ChannelImpl::real_free(TensorInfo* ptr) { MGB_LOCK_GUARD(m_mutex);if (m_channel_state.profiler->is_profiling()) {m_channel_state.profiler->record_host<TensorEraseEvent>(ptr->id);}if (ptr->size_exceeds_thd(m_worker_state.options.dtr_evictee_minimum_size)) {m_dtr.erase_candidate(ptr);}detach_users(ptr);ptr->detach_producer();m_pool.free(ptr);
}/*** 被 void ChannelImpl::real_free 调用* * ★ 重要函数*/
void ChannelImpl::detach_users(TensorInfo* dest) {SmallVector<TensorInfo::ComputePath*> users = dest->users;for (auto* user: users) { // 检查所有依赖该 tensor 作为输入的 tensorSmallVector<TensorInfo*> outputs = user->outputs;SmallVector<TensorInfo*> inputs = user->inputs;for (auto* output: outputs) {if (output == nullptr) {continue;}regenerate(output); // 如果它们不在显存中,必须现在调用 Regenerate 恢复出它们,因为一旦当前 tensor 被真删除,这些 tensor 就恢复不出来了。output->detach_producer();for (auto* input: inputs) {input->ref_cnt --;}}}mgb_assert(dest->users.size() == 0);//dest->users.clear();
}
核心实现
/*** 被以下函数调用* - void ChannelImpl::regenerate* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函数:创建一个新的张量,并将其与 TensorInfo 结构关联起来。对应 void CheckpointTensorCell::fill* * @param dest: 指向 TensorInfo 结构的指针,它将被用来存储有关新张量的信息。* @param ptr: 一个 TensorPtr,表示一个智能指针,指向新创建的 Tensor 对象。*/
void ChannelImpl::produce_tensor(TensorInfo* dest, TensorPtr ptr, bool notice=true) {auto lock = notice ? std::unique_lock<std::mutex>(m_mutex): std::unique_lock<std::mutex>();m_dtr.update_used_time(dest);if (notice && m_worker_state.profiler->is_profiling()) {m_worker_state.profiler->record_host<TensorProduceEvent>(dest->id, ptr->layout(), ptr->comp_node());}dest->value_fetched = ptr->value_fetched();// update tensor desc for static infer 更新静态推断的张量 descdest->desc.layout = ptr->layout();dest->desc.comp_node = ptr->comp_node();dest->memory = ptr->blob()->size();dest->ptr = std::move(ptr);dest->evict_type = EvictType::NONE;// 如果 notice 为 true 并且张量大小超过了某个阈值,则将该张量作为候选加入到动态内存优化的数据结构中。if (notice && dest->size_exceeds_thd(m_worker_state.options.dtr_evictee_minimum_size)) {m_dtr.insert_candidate(dest);}if (notice && m_waitee == dest) {m_cv.notify_all();}
}/** * 被以下函数调用* - void ChannelImpl::recompute* - void ChannelImpl::detach_users* - void ChannelImpl::process_one_task* * ★ 重要函数*/
void ChannelImpl::regenerate(TensorInfo* dest) {if (dest->evict_type == EvictType::DROP) { // 重新计算recompute(dest->producer);} else if (dest->evict_type == EvictType::SWAP) { // 从主机值创建张量produce_tensor(dest, Tensor::make(dest->h_value));}
}/*** 被 void ChannelImpl::regenerate 调用* * ★ 重要函数*/
void ChannelImpl::recompute(TensorInfo::ComputePath* path) {SmallVector<TensorPtr> inputs;inputs.reserve(path->inputs.size());m_dtr.pin(path->inputs);for (auto i : path->inputs) {if (!i->ptr) {regenerate(i); // 在 regenerate inputs 张量时,可能会 OOM}inputs.push_back(i->ptr);m_dtr.update_used_time(i); // 这里更新一下 update_used_time 合理吗?// 如果一个张量在当前的计算路径中被用作输入,那么它的使用时间应该被更新为当前时间,这样在内存紧张时,那些更久未使用的张量将更有可能被逐出。}if (m_worker_state.options.enable_dtr_auto_drop && m_worker_state.options.dtr_eviction_threshold > 0) {auto_evict();}auto outputs = OpDef::apply_on_physical_tensor(*path->op, inputs);m_dtr.estimate_timestamp += path->compute_time / 1e8;m_dtr.unpin(path->inputs);for (size_t i = 0;i < outputs.size();i ++) {auto&& o = path->outputs[i];if (o) {o->recompute_times ++; // 重计算次数if (!o->ptr) { // 如果输出张量的 ptr 为空(即之前被逐出了),则使用 produce_tensor 函数重新创建它。produce_tensor(o, std::move(outputs[i]), false);if (m_worker_state.options.enable_dtr_auto_drop) {m_dtr.update_dsu_after_recompute(o);}}}}
}/*** 被以下函数调用* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函数*/
void ChannelImpl::auto_evict() {if (!m_dtr.comp_node.valid()) {return;}size_t current_memory = m_dtr.comp_node.get_used_memory();while (current_memory > m_worker_state.options.dtr_eviction_threshold) {auto best = m_dtr.find_best_tensor();if (!best) {if (!m_dtr.warn_printed) {m_dtr.warn_printed = true;mgb_log_warn("No tensors on %s can be evicted automatically ""when memory usage is %.0lfMB. Maybe memory ""budget is too small.",m_dtr.comp_node.to_string().c_str(),current_memory / 1024.0 / 1024.0); // 确实,内存预算太小的话,可能找不到 best_tensor}break;}if (best->ptr.unique() && best->ptr->blob().unique()) {current_memory -= best->memory;}do_drop(best);if (best->evict_type == EvictType::DROP) {m_dtr.update_dsu_after_evict(best);}}
}/*** 被 void ChannelImpl::auto_evict() 调用* * ★ 重要函数*/
TensorInfo* ChannelImpl::DynamicSublinear::find_best_tensor() {double min_msps = -1;TensorInfo* best = nullptr;for (auto i : candidates) {if (i->producer && i->ptr && !i->pinned && i->evict_type == EvictType::NONE) {double neighbor_cost = estimate_neighbor_cost(i);// 引入了一些碎片相关的信息,希望换出的 tensor 除了自己占用的显存越大越好之外,还希望它在显存中两端的空闲显存块大小之和越大越好。size_t begin_ptr = reinterpret_cast<size_t>(i->ptr->blob()->storage().get());auto side_info = i->ptr->comp_node().get_free_left_and_right(begin_ptr, begin_ptr + i->ptr->blob()->size());double free_mem = side_info.first + side_info.second;double msps = i->eval_func(neighbor_cost, free_mem, estimate_timestamp, 1.0, 1.0, 1.0, 1.0001);if (min_msps < 0 || msps < min_msps) {min_msps = msps;best = i;}}}return best;
}
辅助函数
/*** 被以下函数调用* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函数*/
void ChannelImpl::DynamicSublinear::pin(const SmallVector<TensorInfo*>& vec) {for (auto i : vec) {i->pin();}
}/*** 被以下函数调用* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函数*/
void ChannelImpl::DynamicSublinear::unpin(const SmallVector<TensorInfo*>& vec) {for (auto i : vec) {i->unpin();}
}/** * 被 void ChannelImpl::recompute 调用* * ★ 重要函数:更新并查集(Disjoint Set Union,DSU)数据结构*/
void ChannelImpl::DynamicSublinear::update_dsu_after_recompute(TensorInfo* ptr) {auto&& dsu_fa = find_father(ptr->dsu_ptr);dsu_fa->t -= ptr->compute_time;ptr->dsu_ptr->parent.reset();ptr->dsu_ptr->t = ptr->compute_time;
}/*** 被 void ChannelImpl::auto_evict() 调用* * ★ 重要函数:更新并查集(Disjoint Set Union,DSU)数据结构*/
void ChannelImpl::DynamicSublinear::update_dsu_after_evict(TensorInfo* ptr) {for (auto i : ptr->producer->inputs) {if (i->evict_type == EvictType::DROP) {merge(i->dsu_ptr, ptr->dsu_ptr);}}for (auto i : ptr->producer->outputs) {if (i && i->evict_type == EvictType::DROP) {merge(ptr->dsu_ptr, i->dsu_ptr);}}
}/*** 被 TensorInfo* ChannelImpl::DynamicSublinear::find_best_tensor 调用* * ★ 重要函数*/
double ChannelImpl::DynamicSublinear::estimate_neighbor_cost(TensorInfo* ptr) {double cost = 0;for (auto i : ptr->producer->inputs) {if (i->evict_type == EvictType::DROP) {double t = find_father(i->dsu_ptr)->t;if (t < i->compute_time) {t = i->compute_time;}cost += t;}}for (auto i : ptr->producer->outputs) {if (i && i->evict_type == EvictType::DROP) {double t = find_father(i->dsu_ptr)->t;if (t < i->compute_time) {t = i->compute_time;}cost += t;}}return cost;
}/*** 被 void ChannelImpl::DynamicSublinear::update_dsu_after_evict 调用* * ★ 重要函数*/
void ChannelImpl::DynamicSublinear::merge(std::shared_ptr<DsuNode> &x, std::shared_ptr<DsuNode> &y) {auto&& f_x = find_father(x);auto&& f_y = find_father(y);if (f_x.get() == f_y.get()) {return;}f_y->t += f_x->t;f_x->parent = f_y;
}/*** 被以下函数调用* - void ChannelImpl::DynamicSublinear::update_dsu_after_recompute* - double ChannelImpl::DynamicSublinear::estimate_neighbor_cost* - void ChannelImpl::DynamicSublinear::merge* * ★ 重要函数*/
std::shared_ptr<DsuNode> ChannelImpl::DynamicSublinear::find_father(std::shared_ptr<DsuNode>& x) {if (x->is_root()) {return x;} else {auto&& fa = find_father(x->parent);return x->parent = fa;}
}/*** 被 void ChannelImpl::produce_tensor 调用* * ★ 重要函数*/
void ChannelImpl::DynamicSublinear::insert_candidate(TensorInfo* ptr) {candidates.insert(ptr);if (!comp_node.valid()) {comp_node = ptr->ptr->comp_node();}
}/*** 被 void ChannelImpl::real_free 调用* * ★ 重要函数*/
void ChannelImpl::DynamicSublinear::erase_candidate(TensorInfo* ptr) {candidates.erase(ptr);
}/** * 被以下函数调用* - void ChannelImpl::produce_tensor* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函数
*/
void ChannelImpl::DynamicSublinear::update_used_time(TensorInfo* ptr) {ptr->last_used_time = estimate_timestamp;
}
启发式公式
( cost + 1 0 − 3 ) param_cost ⋅ ( param_recompute_times ) recompute_times ( memory + free_mem 1024.0 × 1024.0 ) param_mem ⋅ ( cur_time − last_used_time + 1 0 − 3 ) param_time \frac{\left( \text{cost} + 10^{-3} \right)^{\text{param\_cost}} \cdot \left( \text{param\_recompute\_times} \right)^{\text{recompute\_times}}}{\left( \frac{\text{memory} + \text{free\_mem}}{1024.0 \times 1024.0} \right)^{\text{param\_mem}} \cdot \left( \text{cur\_time} - \text{last\_used\_time} + 10^{-3} \right)^{\text{param\_time}}} (1024.0×1024.0memory+free_mem)param_mem⋅(cur_time−last_used_time+10−3)param_time(cost+10−3)param_cost⋅(param_recompute_times)recompute_times
对于函数中的四个属性,增设了一些超参数,这样我们可以通过改变这些超参数来使启发式策略侧重于不同的属性。
重计算次数
我们引入了重计算次数这一惩罚系数,希望每个算子被重算的次数尽量均匀。
void ChannelImpl::recompute(TensorInfo::ComputePath* path) {SmallVector<TensorPtr> inputs;inputs.reserve(path->inputs.size());m_dtr.pin(path->inputs);for (auto i : path->inputs) {if (!i->ptr) {regenerate(i); // 在 regenerate inputs 张量时,可能会 OOM}inputs.push_back(i->ptr);m_dtr.update_used_time(i); // 这里更新一下 update_used_time 合理吗?// 如果一个张量在当前的计算路径中被用作输入,那么它的使用时间应该被更新为当前时间,这样在内存紧张时,那些更久未使用的张量将更有可能被逐出。}if (m_worker_state.options.enable_dtr_auto_drop && m_worker_state.options.dtr_eviction_threshold > 0) {auto_evict();}auto outputs = OpDef::apply_on_physical_tensor(*path->op, inputs);m_dtr.estimate_timestamp += path->compute_time / 1e8;m_dtr.unpin(path->inputs);for (size_t i = 0;i < outputs.size();i ++) {auto&& o = path->outputs[i];if (o) {o->recompute_times ++; // 重计算次数if (!o->ptr) { // 如果输出张量的 ptr 为空(即之前被逐出了),则使用 produce_tensor 函数重新创建它。produce_tensor(o, std::move(outputs[i]), false);if (m_worker_state.options.enable_dtr_auto_drop) {m_dtr.update_dsu_after_recompute(o);}}}}
}
空闲显存块大小
获取显存碎片相关信息的过程是通过计算一个张量在其内存块两侧的空闲内存量来实现的。这种方法可以帮助确定逐出操作后可能获得的内存整理效果。
TensorInfo* ChannelImpl::DynamicSublinear::find_best_tensor() {double min_msps = -1;TensorInfo* best = nullptr;for (auto i : candidates) {if (i->producer && i->ptr && !i->pinned && i->evict_type == EvictType::NONE) {double neighbor_cost = estimate_neighbor_cost(i);// 获取 TensorInfo 对象所关联的张量数据的内存地址,并将这个地址以 size_t 类型的数值形式存储在变量 begin_ptr 中。size_t begin_ptr = reinterpret_cast<size_t>(i->ptr->blob()->storage().get());// 调用计算节点(comp_node)的 get_free_left_and_right 方法,传入张量的起始地址和结束地址(起始地址加上大小)。// 返回一个包含两部分空闲内存的 side_info:// - side_info.first:张量左侧的空闲内存量。// - side_info.second:张量右侧的空闲内存量。auto side_info = i->ptr->comp_node().get_free_left_and_right(begin_ptr, begin_ptr + i->ptr->blob()->size());// 将两侧的空闲内存量相加,得到张量两侧的总空闲内存量 free_mem。double free_mem = side_info.first + side_info.second;double msps = i->eval_func(neighbor_cost, free_mem, estimate_timestamp, 1.0, 1.0, 1.0, 1.0001);if (min_msps < 0 || msps < min_msps) {min_msps = msps;best = i;}}}return best;
}
参考资料
- MegEngine 1.13.2 文档
- MegEngine 架构设计 — MegEngine 1.13.2 文档
- Imperative Runtime — MegEngine 1.13.2 文档
- MegEngine Python 层 Tensor 行为 — MegEngine 1.13.2 文档
- 使用 DTR 进行显存优化 — MegEngine 1.13.2 文档
- MegEngine/MegEngine: MegEngine 是一个快速、可拓展、易于使用且支持自动求导的深度学习框架
- 国产开源深度学习框架,深度学习,简单开发-旷视天元MegEngine
- MegEngine 架构系列:静态内存分析







)
实现指南)








)

