文章目录
- 1.关联式容器
- 2.set
- 2.1 find
- 2.2 lower_bound、upper_bound
- 3.multiset
- 3.1 count
- 3.2 equal_range
- 4.map
- 4.1 insert
- 4.2 operate->
- 4.3 operate[ ]
- 4.4 map的应用实践:随机链表的复制
- 5.multimap
- 希望读者们多多三连支持
- 小编会继续更新
- 你们的鼓励就是我前进的动力!
迄今为止,除了二叉搜索树以外的结构,我们学习到的顺序表,链表,栈和队列等都属于这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身
1.关联式容器
根据应用场景的不同,
STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高
键对值中的 key 表示键值,value 表示与 key 对应的信息
SGI-STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}
};
2.set

set 的主要特征可总结为:
set是按照一定次序存储元素的容器- 在
set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们 - 在内部,
set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序 set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代set在底层是用二叉搜索树(红黑树)实现的
🔥值得注意的是:
- 与
map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对(后面底层的博客会解释) set中插入元素时,只需要插入value即可,不需要构造键值对set中的元素不可以重复(因此可以使用set进行去重)。- 使用
set的迭代器遍历set中的元素,可以得到有序序列 set中的元素默认按照小于来比较,即1、2、3…的顺序set中查找某个元素,时间复杂度为: l o g 2 n log_2 n log2nset中的元素不允许修改set中的底层使用二叉搜索树(红黑树)来实现
2.1 find

由于 set 的基本功能,像 insert、erase、迭代器等都和 string、vector 等差不多,这里就不过多解释,详细的可以自行查看官方文档,本文将针对部分特殊的函数进行解析
find 简单来说,就是寻找特定的键值,那么可以提出一个问题:
set<int> s;
s.insert(3);
s.insert(2);
s.insert(4);
s.insert(5);
s.insert(1);
s.insert(5);
s.insert(2)
s.insert(5);auto pos = s.find(3);//第一种
auto pos = find(s.begin(), s.end(), 3);//第二种
s.erase(3);
哪一种 find 方式能更好的删除?显然是第一种
因为第一种是 set 里面的 find,会以平衡二叉搜索树的方式去查找,大的往左走,小的往右走,时间复杂度为 O(logN);第二种是 algorithm(算法头文件)中的 find,是以依次遍历的方式,即中序遍历的方式进行的,时间复杂度为 O(N)
2.2 lower_bound、upper_bound
set<int> myset;
set<int>::iterator itlow, itup;for (int i = 1; i < 10; i++) myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90itlow = myset.lower_bound(30); // ^
itup = myset.upper_bound(65); // ^myset.erase(itlow, itup); // 10 20 70 80 90cout << "myset contains:";
for (set<int>::iterator it = myset.begin(); it != myset.end(); ++it)cout << ' ' << *it;
cout << '\n';
因为迭代器的区间遵循左闭右开原则,所以 lower_bound 用于查找第一个大于等于给定值 val 的元素位置,upper_bound 用于查找第一个大于给定值 val 的元素位置
3.multiset

multiset 的主要特征可总结为:
multiset是按照特定顺序存储元素的容器,其中元素是可以重复的- 在
multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成的键值对,因此value本身就是key,key就是value,类型为T),multiset元素的值不能在容器中进行修改(因为元素总是const的),但可以从容器中插入或删除 - 在内部,
multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序 multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭代器遍历时会得到一个有序序列multiset底层结构为二叉搜索树(红黑树)
🔥值得注意的是:
multiset中再底层中存储的是<value, value>的键值对multiset的插入接口中只需要插入即可- 与
set的区别是,multiset中的元素可以重复,set是中value是唯一的 - 使用迭代器对
multiset中的元素进行遍历,可以得到有序的序列 multiset中的元素不能修改- 在
multiset中找某个元素,时间复杂度为 O ( l o g 2 N ) O(log_2 N) O(log2N) multiset的作用:可以对元素进行排序
3.1 count

multiset 同样是这几个,但是 count 和 equal_range 可以说是专门给 multiset 打造的,虽然 set 里也可以用,但是没什么意义
count 用于统计容器中某个值出现的次数
3.2 equal_range
set<int> mySet = {1, 2, 3, 3, 4, 5};
auto result = mySet.equal_range(3);for (auto it = result.first; it != result.second; ++it)
{cout << *it << " ";
}
cout << endl;
equal_range 用于查找重复元素之间的区间,返回一个 pair 对象,该对象包含两个迭代器:
- 第一个迭代器指向
multiset中第一个等于value的元素(如果存在),或者指向第一个大于value的元素(如果不存在等于 value 的元素) - 第二个迭代器指向
set中最后一个等于value的元素的下一个位置(如果存在等于value的元素),或者与第一个迭代器相等(如果不存在等于value的元素)
4.map

map的主要特征可总结为:
map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素- 在
map中,键值key通常用于排序和唯一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair : typedef pair<const key, T>value_type - 在内部,
map中的元素总是按照键值key进行比较排序的 map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)map支持下标访问符,即在[]中放入key,就可以找到与key对应的valuemap通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))
由于 map 的基本功能,像 insert、erase、迭代器等都和 string、vector 等差不多,这里就不过多解释,详细的可以自行查看官方文档,本文将针对部分函数进行解析
4.1 insert
map 中的 insert 插入的是一个 pair 结构对象,下面将列举多种插入方式:
🚩创建普通对象插入
pair<string, string> kv1("insert", "插入");
dict.insert(kv1);
🚩创建匿名对象插入
dict.insert(pair<string, string>("sort", "排序"));
🚩调用make_pair函数插入
dict.insert(make_pair("string", "字符串"));
调用 make_pair 省去了声明类型的过程
🚩隐式类型转换插入
dict.insert({ "string","字符串" });
通常 C++98 只支持单参数隐式类型转换,到 C++11 的时候就开始支持多参数隐式类型转换
有这么一个问题:为什么加上了引用反而要加const
pair<string, string> kv2 = { "insert", "插入" };
const pair<string, string>& kv2 = { "insert", "插入" };
无引用情况: 对于 pair<string, string> kv2 = { "string", "字符串" }; ,编译器可能会执行拷贝省略(也叫返回值优化 RVO 或命名返回值优化 NRVO )。比如在创建 kv2 时,直接在其存储位置构造对象,而不是先创建一个临时对象再拷贝 / 移动过去
加引用情况: 使用 const pair<string, string>& kv2 = { "string", "字符串" }; 时,这里 kv2 是引用,它绑定到一个临时对象(由大括号初始化列表创建 )。因为引用本身不持有对象,只是给对象取别名,所以不存在像非引用对象构造时那种在自身存储位置直接构造的情况。不过,这种引用绑定临时对象的方式,只要临时对象的生命周期延长到与引用一样长(C++ 规则规定,常量左值引用绑定临时对象时,临时对象生命周期延长 ),也不会额外增加拷贝 / 移动开销
4.2 operate->
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{//it->first = "xxx";//it->second = "xxx";//cout << (*it).first << ":" << (*it).second << endl;cout << it->first << ":" << it->second << endl;++it;
}
cout << endl;
map 中并没有对 pair 进行流插入运算符重载,(*it).first 这样子的方式又不太简洁不好看,所以进行了 -> 运算符重载,返回的是 first 的地址,因此 (*it).first 等价于 it->->first,为了代码可读性,就省略一个 ->
4.3 operate[ ]
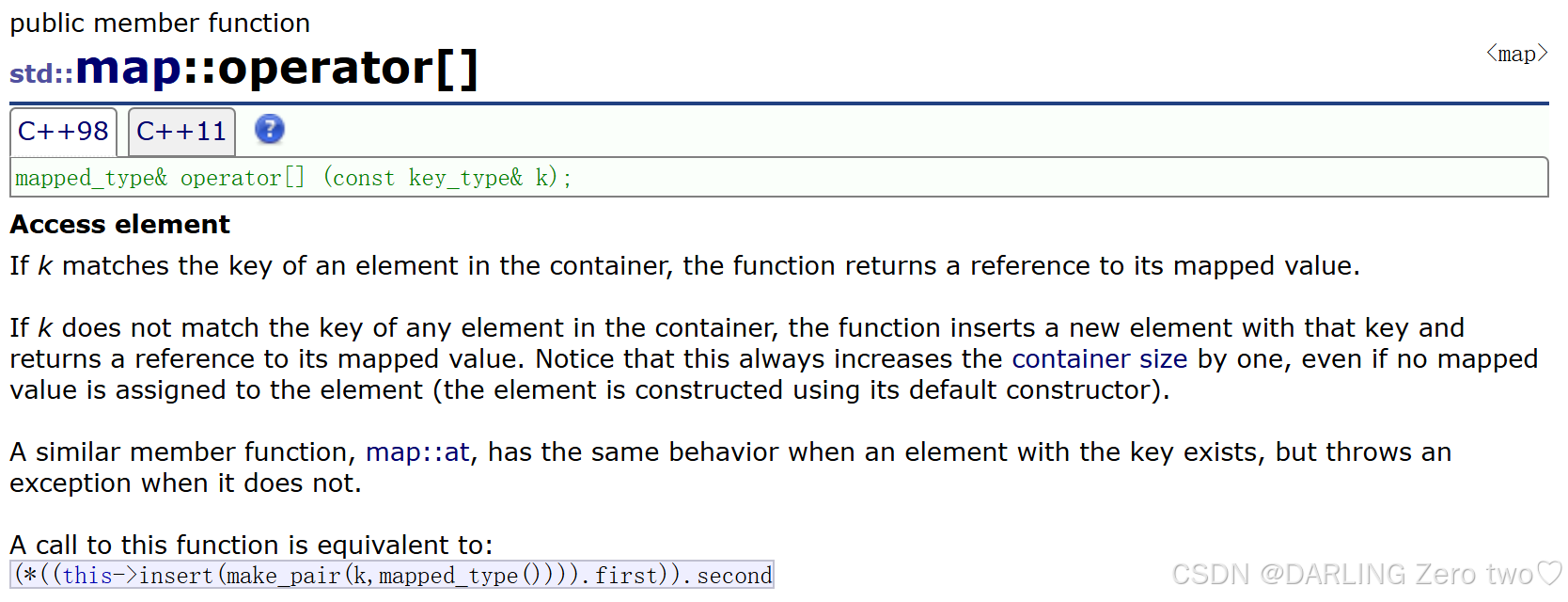
map 中提供了 [] 运算符重载,可以通过 key 来访问 value

首先我们知道 insert 的返回值 key 的部分是一个迭代器,value 的部分是个布尔值,文档中对该返回值的解释是:
key已经在树里面,返回pair<树里面key所在节点的iterator,false>,false表示不用插入了key不在树里面,返回pair<树里面key所在节点的iterator,true>,true表示需要插入新节点

再来看,左边是官方文档的原始定义,那么转化成右边的定义能够更直观理解其底层
这里 V 代表值类型,K 代表键类型 。operator[] 是操作符重载函数,接受一个常量引用类型的键 key ,返回值类型 V 的引用。这样设计是为了支持对容器内元素的读写操作。例如,可以通过 map[key] = newValue; 来修改值,或者通过 auto value = map[key]; 来读取值
然后通过 insert 判断是否插入新节点,最后返回指定节点的 value 值
4.4 map的应用实践:随机链表的复制
✏️题目描述:

✏️示例:
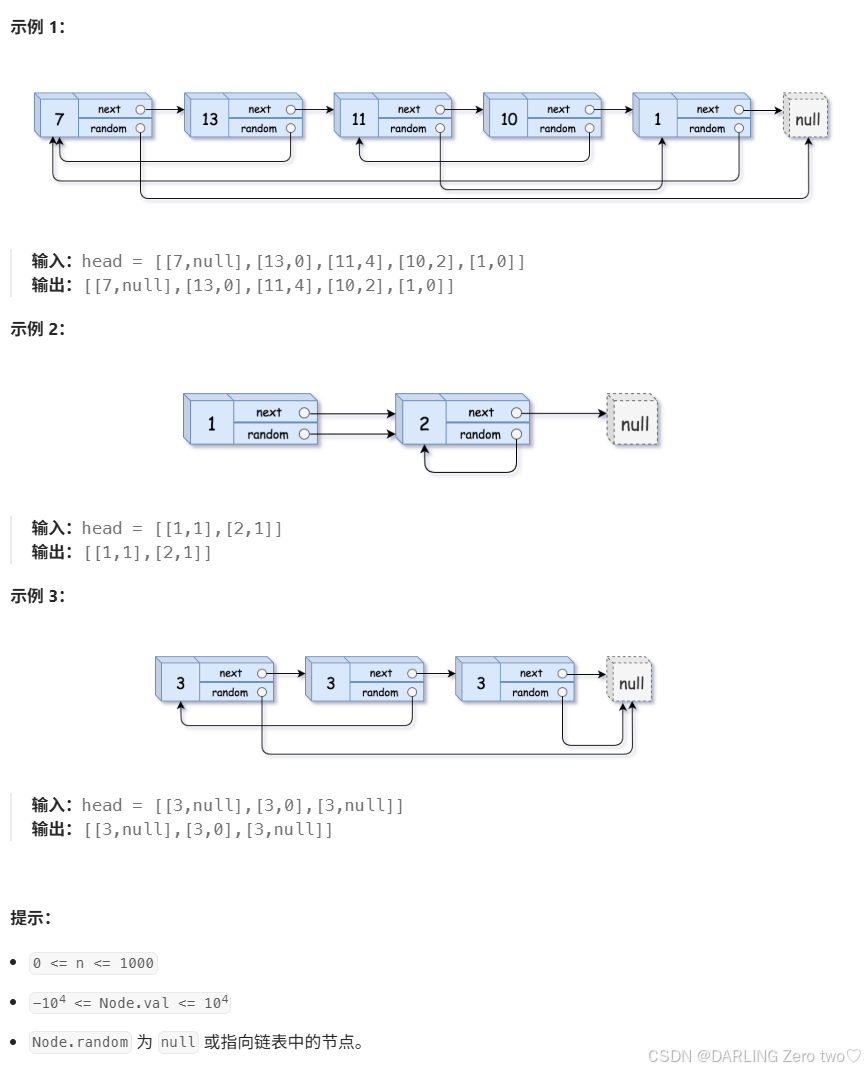
传送门: 随机链表的复制
题解:
利用 map 的映射机制,首先,在第一次遍历原链表时,为原链表的每个节点创建一个对应的新节点,并将原节点和新节点的映射关系存储在 map 中。然后,在第二次遍历原链表时,对于原链表中的每个节点 cur,我们可以通过 cur->random 找到其随机指针指向的原节点,再利用之前存储的映射关系,在 map 中查找该原节点对应的新节点,将这个新节点赋值给当前新节点 copynode 的随机指针 copynode->random
🔥值得注意的是:
记录的不是cur和newnode的关系吗,为什么可以通过cur->random找到newnode->random?
假设原链表有三个节点
A、B、C,节点A的随机指针指向节点C
建立映射阶段: 会为A、B、C分别创建对应的新节点A'、B'、C',并在nodeCopyMap中记录映射关系:{A->A',B->B',C->C'}。
设置随机指针阶段: 当处理节点A时,cur指向A,cur->random指向C。由于C作为键存在于nodeCopyMap中,通过nodeCopyMap[cur->random]也就是nodeCopyMap[C]可以找到C',接着把C'赋值给A'的随机指针A'->random,这样新链表中节点A'的随机指针就正确地指向了节点C',和原链表中节点A的随机指针指向C相对应
💻代码实现:
class Solution {
public:Node* copyRandomList(Node* head) {map<Node*, Node*> nodeCopyMap;Node* copyhead = nullptr;Node* copytail = nullptr;Node* cur = head;while (cur){Node* copynode = new Node(cur->val);if (copytail == nullptr){copyhead = copytail = copynode;}else{copytail->next = copynode;copytail = copynode;}nodeCopyMap[cur] = copynode;cur = cur->next;}Node* copy = copyhead;cur = head;while (cur){if (cur->random == nullptr){copy->random = nullptr;}else{copy->random = nodeCopyMap[cur->random];}cur = cur->next;copy = copy->next;}return copyhead;}
};
5.multimap
multimap的主要特征可总结为:
multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key, value>,其中多个键值对之间的key是可以重复的。- 在
multimap中,通常按照key排序和惟一地标识元素,而映射的value存储与key关联的内容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,value_type是组合key和value的键值对:typedef pair<const Key, T> value_type; - 在内部,
multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key进行排序的。 multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代器直接遍历multimap中的元素可以得到关于key有序的序列multimap在底层用二叉搜索树(红黑树)来实现
注意:multimap 和 map 的唯一不同就是:map 中的 key 是唯一的,而 multimap 中key 是可以重复的
🔥值得注意的是:
multimap中的key是可以重复的multimap中的元素默认将key按照小于来比较multimap中没有重载operator[]操作,因为一个key对应多个value,不知道找哪个value- 使用时与
map包含的头文件相同
multimap 和 mutiset 是差不多的,而且在实际应用中用的不多,所以这里就不细讲了
希望读者们多多三连支持
小编会继续更新
你们的鼓励就是我前进的动力!





)
实现指南)








)




