文章目录
- 一、GPU加速
- 1. 检查GPU可用性:
- 2. GPU不可用需要具体查看问题
- 3. 指定设备
- 4.将张量和模型转移到GPU
- 5.执行计算:
- 6.将结果转移回CPU
- 二、转移原理
- 1. 数据和模型的存储
- 2. 数据传输
- 3. 计算执行
- 4. 设备管理
- 5.小结
- 三、to方法的参数类型
一、GPU加速
.to(device)方法:- device是指定的设备,如果
'cpu','cuda'等。使用字符串'cpu'或torch.device('cpu')对象在功能上是等价的 .to()方法可以将数据传输到指定设备的存储空间中,如CPU内存:主存,GPU内存:显存。之后计算则会在对应设备上计算。这个数据.to()方法是Pytorch中张量tensor或模型继承自torch.nn.Module的类等中实现的方法,但是基本Python数据类型没有该方法。- 它的参数允许你指定目标设备、数据类型,以及其他几个选项,以适应不同的需求。
- device是指定的设备,如果
GPU加速是在深度学习和其他高性能计算任务中非常重要的技术。GPU(图形处理器)具有并行处理能力,能够同时处理成千上万的计算任务,这使得它们非常适合于执行深度学习模型的训练和推理过程,因为这些过程往往涉及到大量的矩阵和向量运算。
在PyTorch中,使用GPU加速可以显著提高张量运算的速度。这是通过将张量和模型从CPU传输到GPU来实现的。使用GPU加速,特别是在处理大型深度学习模型和数据集时,可以显著减少训练和推理时间。不过,值得注意的是,这需要你有一个支持CUDA的NVIDIA GPU。此外,与CPU相比,GPU上的内存(通常称为显存)可能更少,这可能限制你一次能处理的数据量大小。因此,在设计模型和选择批量大小时,需要考虑到显存的限制。
以下是一些基本步骤,展示了如何在PyTorch中使用GPU加速:
1. 检查GPU可用性:
首先,你需要检查GPU是否可用。
torch.cuda.is_available()函数来检查系统是否有可用的CUDA支持的GPUtorch.cuda.device_count()函数来检查系统有多少个可用GPU设备
import torch
# 检测系统中是否有可用的GPU
print("检测系统中是否有可用的GPU:",torch.cuda.is_available())if torch.cuda.is_available():# 输出可用的GPU设备数量print(f"GPU可用,可用的GPU设备数量:{torch.cuda.device_count()}")# 输出每个可用GPU设备的名称for i in range(torch.cuda.device_count()):print(f"GPU设备{i}: {torch.cuda.get_device_name(i)}")

2. GPU不可用需要具体查看问题
如果没有安装gpu版本的torch,则需要安装,并且在安装时,注意cuda的版本:命令行中输入nvidia-smi,可以查看可以安装的最高cuda版本。
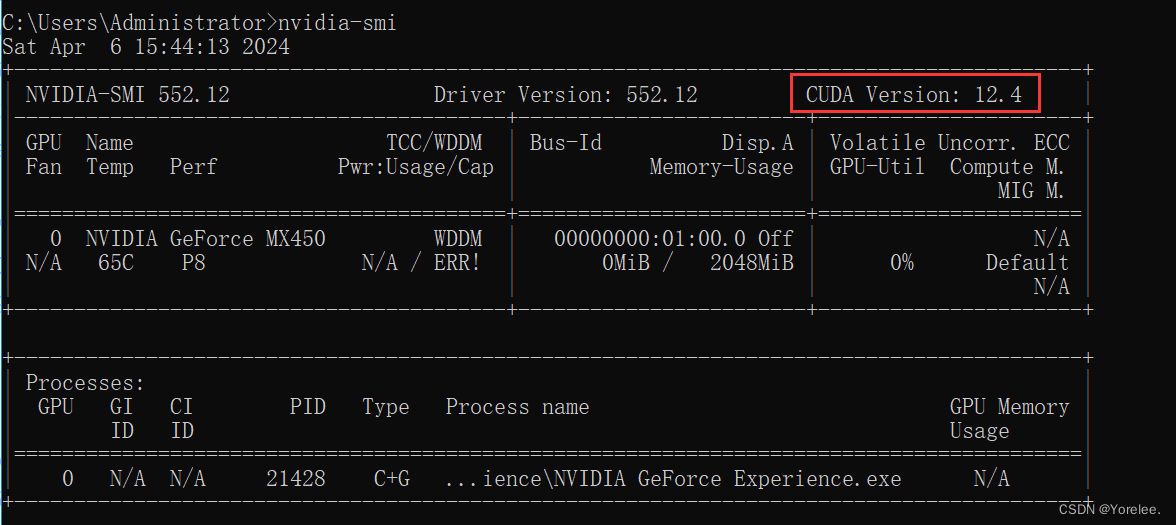
torch+cuda安装教程
下载NVIDIA驱动程序教程。
如果你已经安装了Pytorch等,在执行命令行下载时,建议新建虚拟环境并可以添加--force-reinstall选项来强制重新安装PyTorch及其相关库:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117 --force-reinstall --user
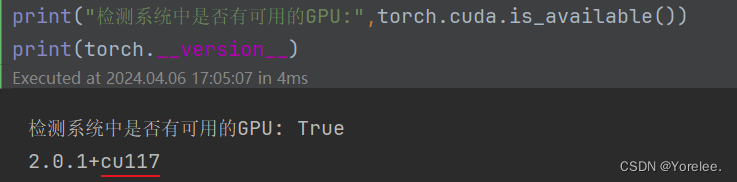
用以下命令查看是否可用,以及torch版本是否正确:
print("检测系统中是否有可用的GPU:",torch.cuda.is_available())
print(torch.__version__)
3. 指定设备
一旦确认GPU可用,你可以定义一个设备对象,用于后续将张量和模型转移到GPU。例如,device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")。这里"cuda:0"表示使用第一个CUDA支持的GPU,如果GPU不可用,则回退到CPU。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
4.将张量和模型转移到GPU
你可以使用.to(device)方法将张量和模型转移到指定的设备(GPU或CPU)。例如,tensor_gpu = tensor.to(device)和model.to(device)。这样,张量和模型的所有计算都将在GPU上进行,从而利用其并行计算能力加速运算。其中tensor和model分别是torch中定义的张量和模型。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x=torch.tensor([1,1,2,3]).to(device)
x=torch.tensor([1,1,2,3]).to(torch.device("cpu"))
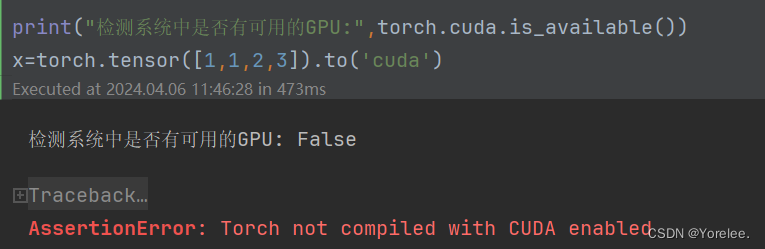
x=torch.tensor([1,1,2,3]).to('cuda')#直接转移至GPU
如果没有GPU还要转移到GPU上,会产生如下报错:AssertionError: Torch not compiled with CUDA enabled
5.执行计算:
在张量和模型转移到GPU后,你可以正常执行计算。计算会自动在GPU上进行,利用其高性能加速计算过程。
6.将结果转移回CPU
如果需要将结果转回CPU,可以使用.to('cpu')方法。例如,result_cpu = result_gpu.to('cpu')。
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x=torch.tensor([11,2,5,6]).to(device)
result=x*2
#以上tensor计算都在GPU上#将结果转入cpu,以后处理在CPU上
result=result.to('cpu')
result=result*2
二、转移原理
将张量或模型转移到GPU以及将结果转回CPU,是深度学习中常见的做法,用于利用GPU进行高速计算的同时,确保与其他不支持GPU计算的操作或数据兼容。这一过程的背后原理涉及数据在不同硬件设备之间的传输,以及计算设备的管理。
1. 数据和模型的存储
首先,了解CPU和GPU 有各自独立的内存空间 是很重要的:
- CPU内存:通常称为主内存,由RAM(随机存取存储器)构成,用于存储程序运行中需要的数据和指令。也就是说计算机的内存是用CPU处理的,并且内存到磁盘的转移也需要用CPU协调。
- GPU内存:也称为显存,是专门为GPU设计的,用于存储GPU处理的数据,比如渲染图形的纹理数据或进行科学计算的矩阵。
2. 数据传输
当你将一个张量或模型“转移到GPU”时,实际上是将数据从CPU内存复制到GPU内存。相应地,从GPU“转回”数据到CPU也涉及到一个从GPU内存到CPU内存的复制过程。这些操作通常通过PCI Express (PCIe)总线完成,PCIe是一种高速串行计算机扩展总线标准,用于连接主板和外部设备,比如GPU。
3. 计算执行
- 在GPU上执行计算:将数据或模型转移到GPU后,CUDA或其他GPU加速库可以利用GPU的并行计算能力执行复杂的数学运算,如矩阵乘法、卷积等操作,这些操作是深度学习中的基本构件。
- 处理结果:计算完成后,通常需要将结果数据从GPU内存复制回CPU内存,以便进行进一步的处理或分析,因为某些操作可能只能在CPU上执行,或者你需要将数据保存到磁盘,这通常是通过CPU来完成的。
4. 设备管理
在PyTorch等深度学习框架中,通过特定的API(应用程序接口,比如一些函数,我们只会使用,不会其实现原理这就是一种接口)调用来管理数据在设备之间的移动。例如,使用.to(device)方法指定数据或模型应该在哪个设备上运算。这种灵活性允许开发者编写设备无关的代码,框架负责在后台处理数据的移动和计算设备的选择。
5.小结
- 转移至GPU:是一个数据从CPU内存复制到GPU内存的过程,旨在利用GPU的并行计算能力加速运算。
- 转回至CPU:是将数据从GPU内存复制回CPU内存的过程,以便进行非GPU加速的操作或持久化存储。
这一过程核心在于,不同的计算任务根据其特性和所需的计算资源,可以在最适合的硬件上执行,从而优化整体的计算效率和性能。如果需要快速计算,那么计算时,将计算的数据放入GPU内存用GPU处理,计算完如果需要进入内存,存入磁盘等操作,那么就再把数据放入CPU内存(主存),然后在处理。


















)
