
文 | 兔子酱
最近,benchmanking又卷出了新高度,allen AI 前段时间发布了史上最强基准测试——NATURAL-INSTRUCTIONSv2,涵盖了1600+个任务、70+个不同任务类型、50+种不同语言,用来测试生成模型的泛化性。
论文标题:
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
论文地址:
https://arxiv.org/pdf/2204.07705.pdf
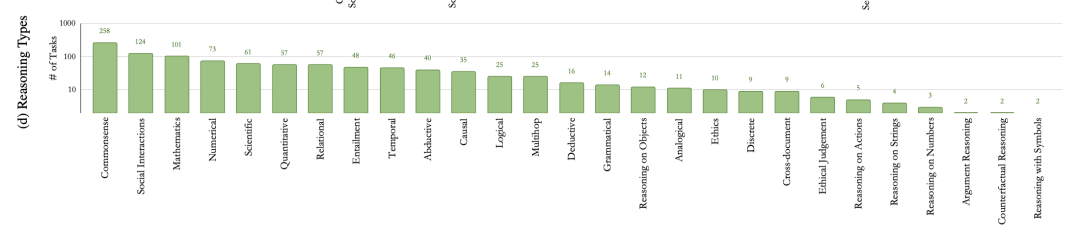
该基准是由众多NLP从业者共同创建发起,经过多次peer review后保证质量。先来直观感受下它涵盖的任务类型有多丰(恐)富(怖)

相比之下,PROMPTSOURCE(T0 subset)、FLAN、GPT3-INSTRUCT就是芝麻见绿豆了。
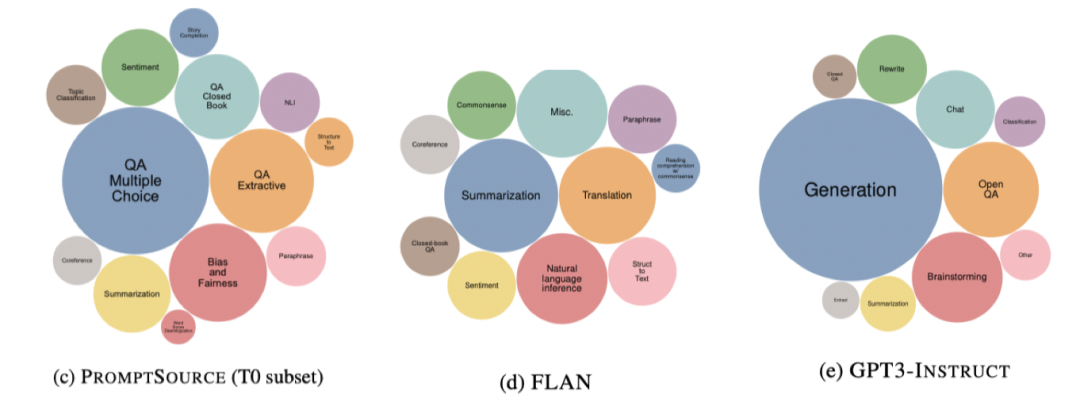
1616个task,76个task类型,16种推理类型, 非英文任务就有576个,每个任务平均有3k+个样本,工程如此浩大(nlper们光训练模型就已经够心累了,难道又要卡在评估上??)NATURAL-INSTRUCTIONSv2到底是何方神物,我们应该怎么使用它呢?下面从一个benchmark应该具备的3要素开始一探究竟吧~
测试目标:生成模型的泛化能力
测试工具:1616个任务
测试对象:T0、GPT3系列、T5、Tk-INSTRUCT
 基本介绍
基本介绍
如前面所说,本次发布的基准测试系统包括的任务数量之多,类型之丰富,质量把控之严格,都值得提名!作者们从多个维度对进行了对比介绍,比如是否有任务描述介绍,是否有非英任务,任务数据量、是否开源等等。总之就是一句话“没有最多,只有更多”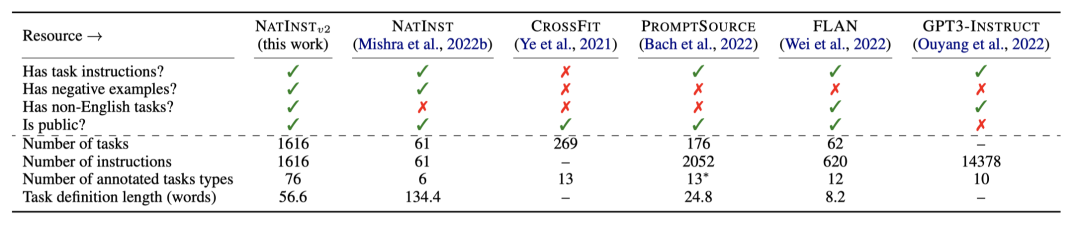
首先,所有任务都遵循统一的介绍模版,包括4个部分:
DEFINITOION:一段详细的任务介绍
正例 & 负例:样本和标签,附带简短的解释说明
INSTANCES:正负例集合,每一个实例都包括input和几个候选output。
这些任务是由88位人员从GitHub社区收集来的,覆盖了业界已公布的数据以及新构造的任务,并且添加了详尽的任务介绍,已确保满足读者的需求。其中包括机器翻译、QA,文本分类等任务类型,英语、西班牙语、日语等语种,涉及新闻、对话、数学等多个领域学科,可见其丰富程度。
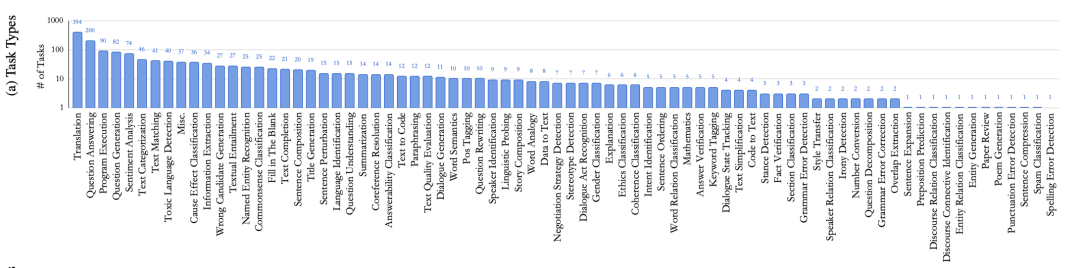

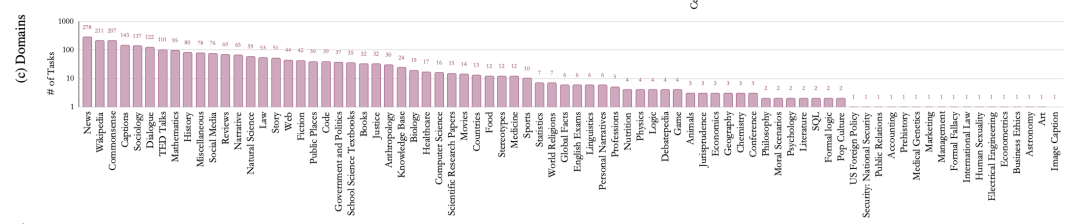
此外,基于T5,作者们训练出了一个有30亿参数的生成模型Tk-INSTRUCT,在119个英文测试任务上效果(ROUGE-L)超过了1750亿参数的GPT3-INSTRUCT,多语言变种模型mTk-INSTRUCT在35个非英文任务上表现同样超越了GPT3-INSTRUCT。
 跨任务的生成能力评估方法
跨任务的生成能力评估方法
本次发布了如此浩大体量的基准,希望可以评估模型在未知任务(只给定task instruction)上的泛化能力。那具体怎么衡量模型的泛化能力呢?
任务建模
首先,对模型建模可以表示成
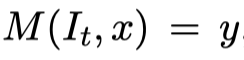
x是输入,It是task instruction(任务指令/指导),模型需要在给定It和x下生成目标答案。task instruction的schema如下图所示:

因为本次发布的基准涵盖的任务多且广,作者分成了验证集合和训练集合两个子集,一个用于评估,一个用于监督训练。其中人工挑选的验证集合包括12个类别154个任务,其中119个英文任务,35个跨语种任务。每个任务选出100个随机实例用来评估。
在评估指标上,选用文本生成中广泛使用的ROUGE-L,除此之外,对于输出较短且有限的任务,还引入了Exact Match,衡量模型推理出的字符串和标准输出完全匹配的比率。
评估模型&效果
为了让评估工作更全面可信,我们提供了基线效果、当前最具代表性的模型的效果、理论上限效果,具体评估的模型有三类:
第一类是启发式模型,
Copying Demo Output:用另一个随机实例的输出当作当前实例的预测结果
Copying Instance Input:用当前实例的输入当作输出
第二类是未经finetuned的预训练语言模型T5、GPT3,
第三类是经过instruction-finetuned的T0、GPT3-Instruct、Tk-INSTRUCT&mTk-INSTRUCT。
理论上限效果通过在labeled instances上finetune T5-3B得到。
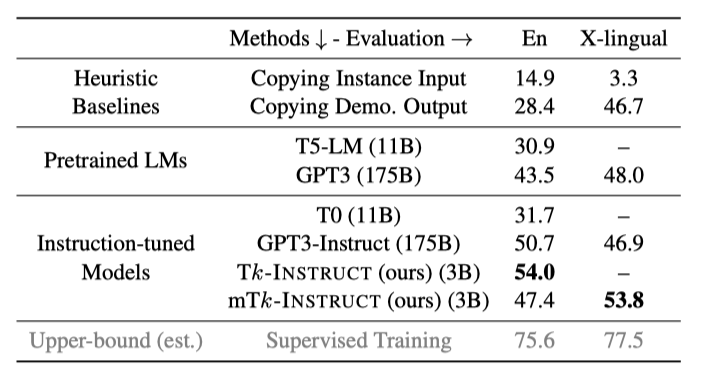
实验结论:经过instruction-finetuned的模型表现出了更强的泛化能力。
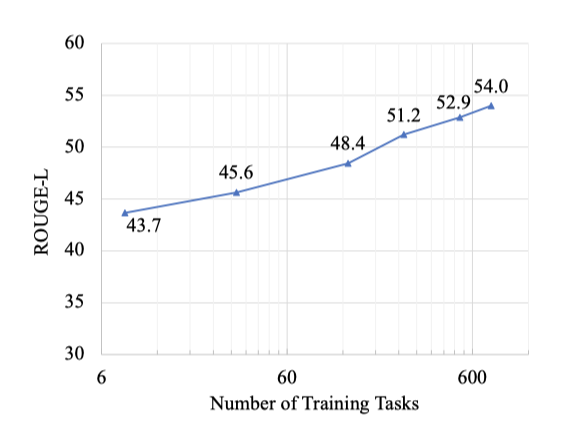
作者通过进一步实验,比较不同模型规模、训练任务的数量、样本量对效果的影响,发现:
增加训练任务的数量, 模型的泛化性能呈现对数线性增长。
更多的训练样本无助于提高泛化性能。
模型规模越大,泛化效果越好。
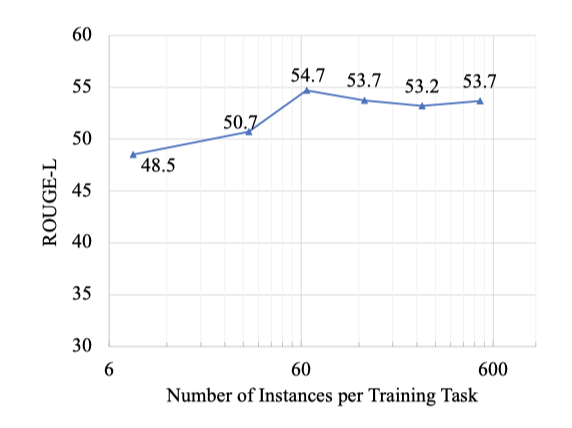
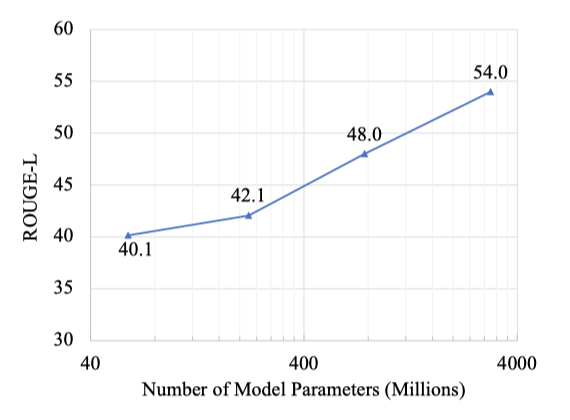
虽然以上实验结果表明引入instructions可以提高模型的泛化效果,但instructions中的哪些元素或者元素组合是最有效的呢?为此作者通过控制输入不同的元素,观察模型的表现。
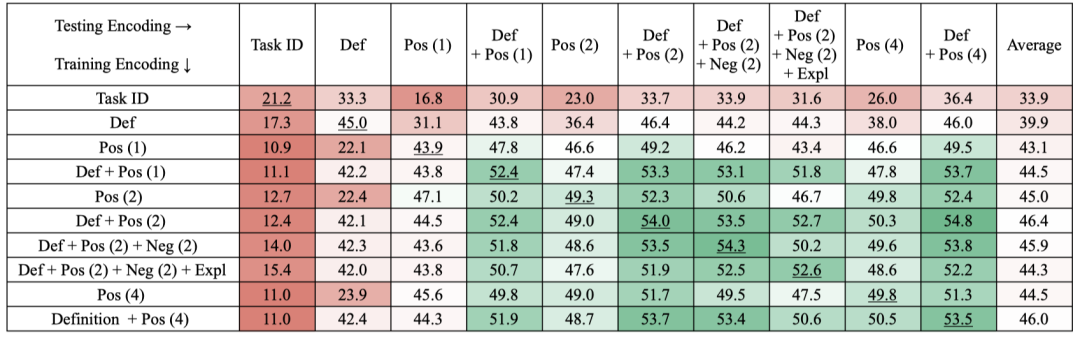
加入不同Instruction元素的影响
task definition和样本互补,对提升泛化能力有很大帮助
多个元素混合作用,也有一定帮助
加入更多instance区别不大
使用负例有微弱提升,但是instance的说明信息起到负向作用
此外,不同的任务类型的泛化能力也有所差异,其中在大部分任务上T0表现比启发式模型还差,GPT3-instruct和我们instruction-tuned后的模型表现比较好。
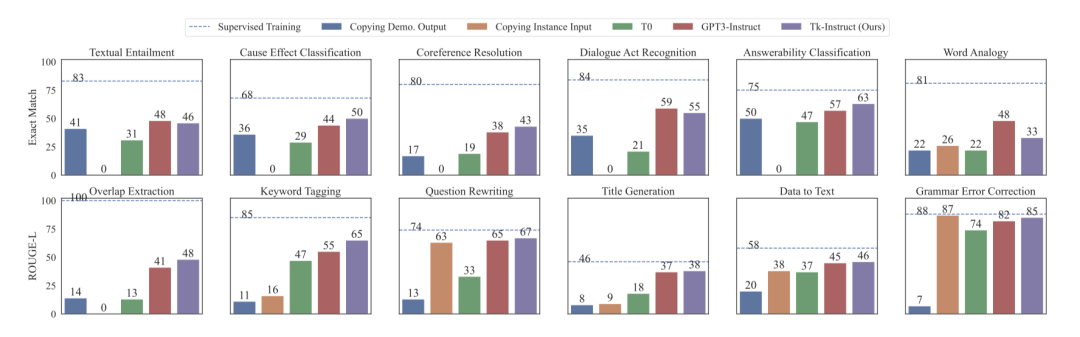
 总结
总结
总结下来,该工作发布了一个业界最大、最全的评估生成模型泛化能力的基准系统,并对这些数据任务进行了初步实验,展示其用途。(给大佬们鼓掌)
萌屋作者:兔子酱
一个颜值与智商双高的妹纸,毕业于明光村职业技术学校北邮。和小夕一起打过比赛,霸过榜。目前在百度做搜索算法。
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!


)


)


)











