
文 | 智商掉了一地
如何才能让大型语言模型按照我们的要求去做?这篇文章给出了回答——
近期在 NLP 领域风很大的话题莫过于 Prompt,尤其当大型语言模型(LLM)与其结合,更是拉近了我们与应用领域之间的距离,当 LLM 在包括小样本学习在内的各种任务中表现出非凡的效果和通用性时,也存在着一个问题亟待解决:如何让 LLM 按照我们的要求去做?这也是本篇论文的一个重要出发点。
本文作者将 LLM 视为执行由自然语言指令指定程序的黑盒计算机,并研究如何使用模型生成的指令来控制 LLM 的行为。受经典程序合成和人工提示工程方法的启发,作者提出了自动提示工程师 (Automatic Prompt Engineer, APE) 用于指令自动生成和选择,将指令视为“程序”,通过搜索由 LLM 提出的候选指令池来优化,以使所选的评分函数最大化。
作者通过对 24 个 NLP 任务的实验分析指出,自动生成的指令明显优于先前的 LLM Baseline,且 APE 设计的提示可以用于引导模型真实性和信息量,以及通过简单地将它们预设为标准上下文学习提示来提高小样本学习性能。
论文题目:
Large Language Models are Human-Level Prompt Engineers
论文链接:
https://openreview.net/pdf?id=92gvk82DE-
问题探索
大模型在各种任务上的通用性和卓越表现引发广泛关注,同时关于引导大模型朝着理想方向的研究也在不断进行着,最近几年的工作考虑了微调(fine-tuning)、上下文学习(in-context learning)和几种形式的 prompt 生成,包括可微分软提示(differentiable tuning of soft prompts)和自然语言提示工程(natural language prompt engineering),而自然语言提示工程则更是让公众对 prompt 设计和生成也产生了兴趣。
比如,近年来具有自然语言界面的大型模型,包括用于文本生成和图像合成的模型,已经越来越多地被公众使用。由于人们很难找到正确的 prompt,因此开发了许多关于提示工程的指南以及帮助发现 prompt 的工具,链接如下:
https://blog.andrewcantino.com/blog/2021/04/21/prompt-engineering-tips-and-tricks/
https://techcrunch.com/2022/07/29/a-startup-is-charging-1-99-for-strings-of-text-to-feed-to-dall-e-2/
https://news.ycombinator.com/item?id=32943224
https://promptomania.com/stable-diffusion-prompt-builder/
https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion
在公众的这种兴趣背后,潜藏着这样的事实——简单的语言提示并不总产生期望的结果,即使这些结果可以通过其他指令生成。
因此,由于对指令与特定模型的兼容性知之甚少,用户必须尝试各种提示以指导 LLM 走向期望的行为。我们可以通过将 LLM 看作是由自然语言指令指定执行程序的黑盒计算机来理解这一点:虽然它们可以执行广泛的自然语言程序,但这些程序的处理方式对人类来说可能并不直观,而且只有在下游任务中执行这些指令时才能衡量其质量。
因此,为了减少创建和验证有效指令所涉及的人工成本,作者提出将用自动提示工程师 (Automatic Prompt Engineer, APE)算法来生成有效指导 LLM 的指令,即自然语言程序合成(natural language program synthesis),如下图 (a) 所示,将其作为黑盒优化问题处理,使用 LLM 生成和搜索一些可行的候选解决方案。
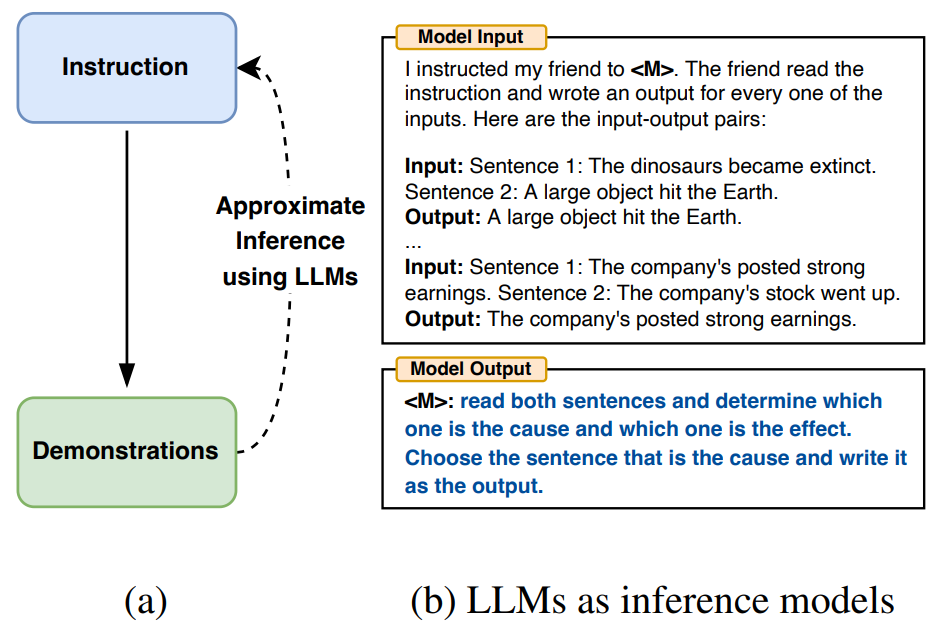
作者将以三种方式来利用 LLM 的通用能力:
首先,基于“输入-输出对”形式的小集合,使用 LLM 作为推理模型生成候选指令,如上图(b)所示,使用 LLM 作为推理模型来填充空白,此算法涉及到搜索推理模型所提出的候选指令。
其次,通过为想要控制的 LLM 下的每条指令计算一个分数来指导搜索过程。
最后,提出一种迭代蒙特卡洛搜索方法,LLM 通过提出语义相似的指令变体来改进最佳候选指令。
总之,该算法要求 LLM 根据示例生成一组候选指令集,然后再评估其中哪些更有效。即自动地为通过输出示例指定的任务生成指令:通过直接推理或基于语义相似性的递归过程生成几个候选指令,用目标模型执行它们,并根据计算出的评估分数选择最合适的指令。
算法介绍
对于一个包含从总体 中采样的输入-输出示例的数据集 和一个提示模型 指定的任务,自然语言程序合成的目标是找到这样的一条指令 ρ,使得当用指令和给定输入的拼接 ρ 提示 时, 产生相应的输出 。即将其构建为一个优化问题,为找到指令 ρ,使每个样本分数 ρ 的期望最大化,超过可能的 :
ρρρρ
本文的算法 APE 在 proposal 和评分这两个关键模块中都使用 LLM。如下图和算法 1 所示,APE 首先提出几个候选提示,然后根据选定的评分函数对候选集合进行筛选和精炼,最终选择得分最高的指令。
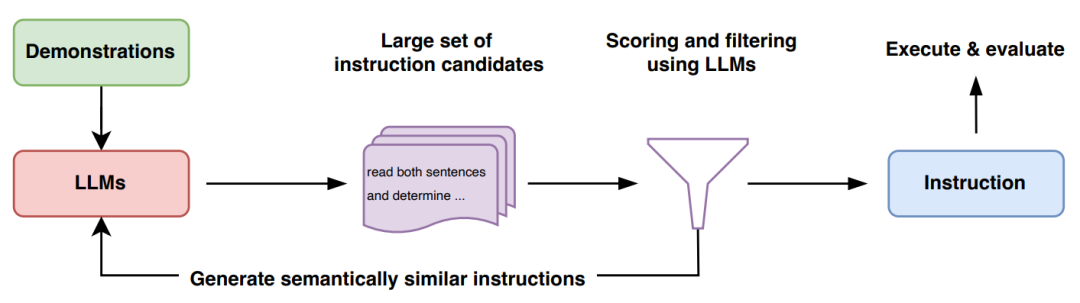

初始 proposal 分布
由于搜索空间无限大,导致很难找到正确的指令,这也是自然语言程序合成历来的难点。作者考虑用一个预训练的 LLM 找到很好的候选集 来指导整个搜索过程,虽然来自 LLM 的随机样本不太可能产生所需的 对,但可以让 LLM 在给定输入/输出示例的情况下近似推断出最有可能的高分指令,即从 ρρ 中近似采样。
从 ρρ 中生成高质量候选项有两种方法:
首先,采用一种基于“正向”模式生成的方法,将这个分布 翻译成单词。例如使用如下图方法提示 LLM:
 这表明输出是根据指令生成的,因此其分数函数将很高。尽管“正向”模型对大多数预训练的 LLM 来说都是开箱即用的,但将 ρρ 转换为单词需要跨不同任务的定制工程。这是因为“正向”模型只从左到右生成文本,而我们希望模型在演示之前预测缺失的上下文。
这表明输出是根据指令生成的,因此其分数函数将很高。尽管“正向”模型对大多数预训练的 LLM 来说都是开箱即用的,但将 ρρ 转换为单词需要跨不同任务的定制工程。这是因为“正向”模型只从左到右生成文本,而我们希望模型在演示之前预测缺失的上下文。为了解决这个问题,还考虑了“反向”模式生成,它使用具有填充功能的 LLM(如 T5 和 InsertGPT)来推断缺失的指令。“反向”模型通过填充空白直接从 ρρ 中采样,使其成为比“正向”模型更通用的方法。如下所示:
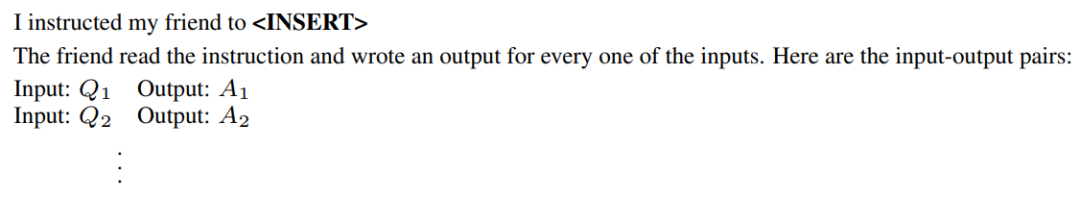
评分函数
为了将问题转化为黑盒优化,选择了一个评分函数,该函数可以精确度量数据集和模型生成的数据之间的对齐程度。在 TruthfulQA 实验中,主要关注前人提出的自动化指标,类似于执行准确率。在每个case中,使用等式 (1) 来评估生成指令的质量,并对测试集 计算期望。
执行准确率。使用Honovich等人提出的执行准确率矩阵来评估指令 ρ 的质量,将其表示为 。大多数情况下,执行准确率被简单地定义为 0-1 loss,而在某些任务中,则会考虑到不变量。
对数概率。进一步提出一个更偏向 soft 概率的评分函数,假设它可能会通过在搜索低质量候选指令时提供更细粒度的信号来改进优化,尤其考虑了目标模型 下给定指令和问题的期望答案的对数概率,在每个样本的基础上它是 ρ。
有效的评分估计。通过计算所有指令候选的整个训练集的分数来估计分数开销很大,因此为减少计算开销,这里还采用了一种过滤方案,即分配计算资源时,有潜力的候选获得更多,而低质量则获得更少,这可以通过在算法 1 的第 2-9 行使用多阶段计算策略来实现。首先用训练集的一小部分来评估所有候选数据,对于分数大于某个阈值的候选指令,从训练集中采样并评估一个新的非重叠子集,以更新分数的移动平均值,然后,重复这个过程直到留下一小部分候选对象,并在整个训练集上对其进行评估。这种自适应过滤方案保持了高质量样本的精确计算代价的同时,也大大降低了低质量候选的计算代价,从而显著提高了计算效率。
迭代proposal分布
尽管想直接对高质量的初始候选指令进行采样,但可能出现的情况是,上述方法无法产生一个好的 proposal 集 (要么是因为缺乏多样性,要么是不包含任何具有合适高分的候选对象),因此作者又研究了重采样 的迭代过程。
迭代蒙特卡洛搜索。考虑在当前最佳候选对象周围局部探索搜索空间,而不仅从初始 proposal 中采样,这便可以生成更可能成功的新指令,作者称这个变体为迭代 APE。在每个阶段,都会评估一组说明,并筛选出得分较低的候选者,然后要求 LLM 生成与高分指令相似的新指令。这里使用 LLM 重采样 ,并对模型提示如下:

而实验结果表明,虽然这种方法提高了proposal 集 的整体质量,但随着阶段的增加,得分最高的指令往往保持不变,因此与前文中描述的生成过程的相对简单和有效性相比,迭代生成提供了边际改善。所以除非另有说明,否则后面的实验中将用没有迭代搜索的 APE。
APE 如何引导 LLM?
这里将从zero-shot性能、few-shot性能和真实性这三个角度进行研究。
指令归纳(Instruction Induction)
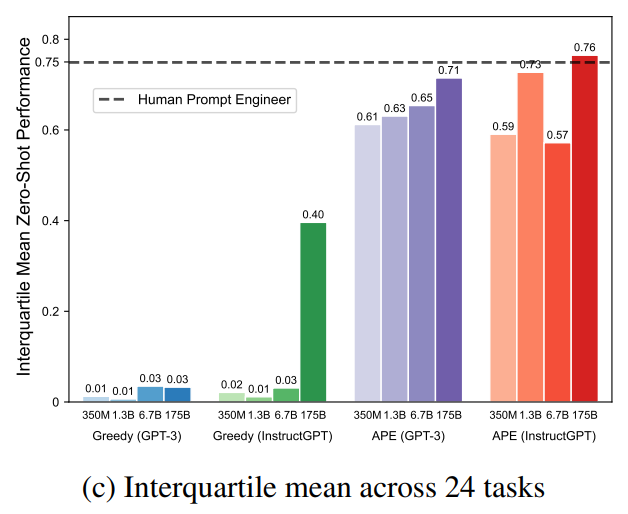
作者在前人提出的 24 个指令归纳任务上评估了zero-shot和few-shot上下文学习的有效性,这些任务从简单的短语结构到相似性和因果关系的识别,涵盖了语言理解的许多方面。对于每个任务,从训练数据中采样 5 个输入-输出对,并使用算法 1 选择最佳指令,然后通过在 InstructGPT 上执行指令来评估其质量,用不同的随机种子重复 5 次实验,得到如下图所示每种情况下最佳性能结果的平均值和标准差,在24 项任务中,APE 实现了 21 项与人类水平相当的性能。
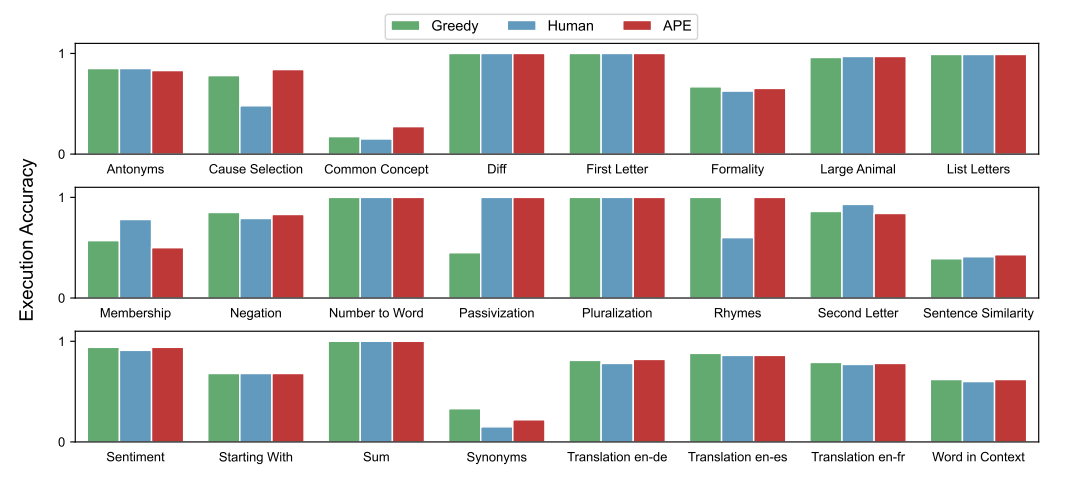
zero-shot 学习。作者在这里将本文的方法与两个 Baseline 进行比较:人工提示工程师和贪婪模型生成指令算法。如下图所示,在 24 项任务中,有 19 项达到了人类水平,甚至有的任务表现优于人工的。
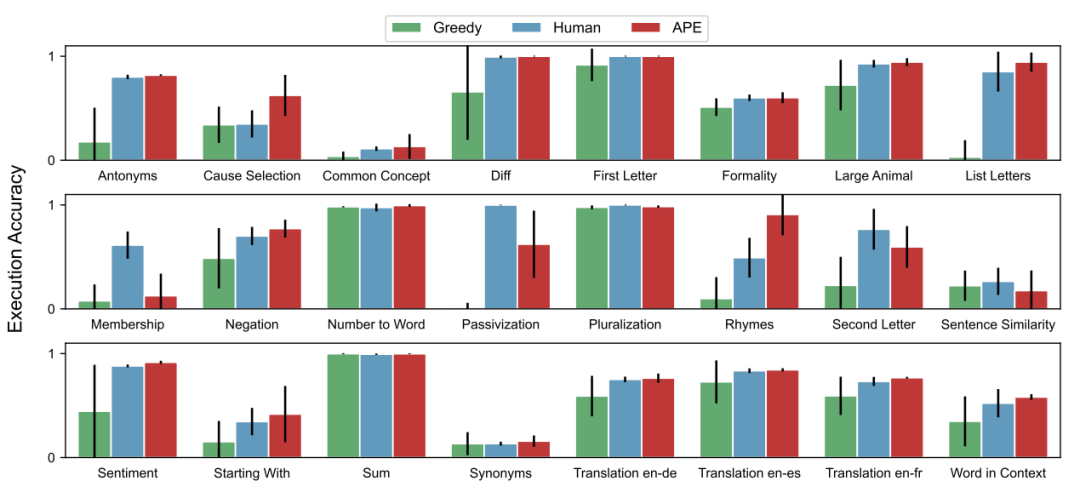
然而上面两图的对比,可以观察到不同的上下文示例组合可能产生明显不同的结果,这也证明了初始 proposal 阶段基于不同的示例生成候选指令的重要性。
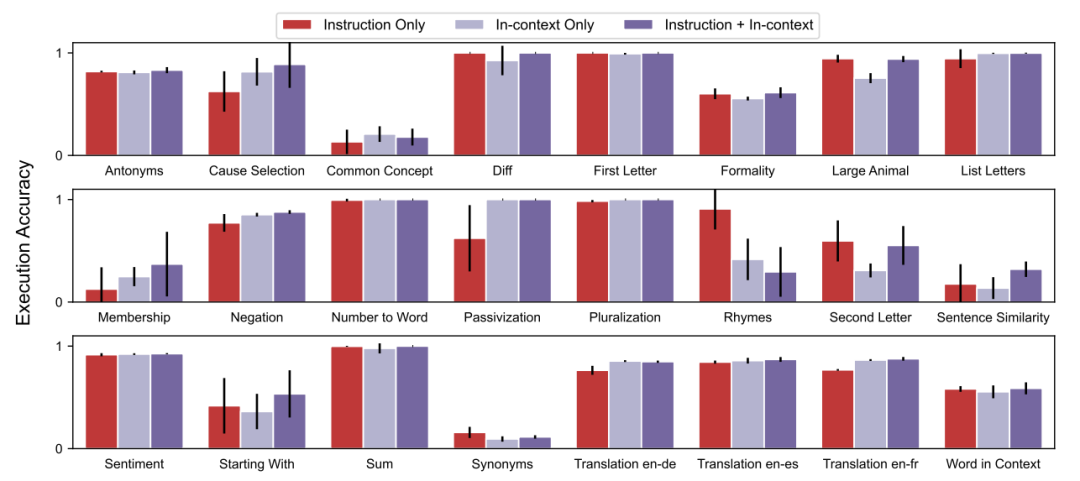
few-shot上下文学习。作者在一个 few-shot 上下文学习场景(在上下文示例前插入指令)中评估了 APE 生成的指令,在下图中将其表示为“指令+上下文”,而在 24 个任务中的 21 个任务上,添加指令可获得与标准上下文学习性能相当或更好的测试性能。与直觉相反的是,为Rhymes、Large Animals和Second Letters添加上下文示例会降低模型的性能。
TruthfulQA
作者将本文的方法应用于 TruthfulQA 来了解 APE 生成的指令如何引导 LLM 生成不同风格的答案,并研究真实性和信息量之间的权衡。借助原始论文中的指标,用 APE 来学习最大化三个指标的指令:真实性 (% True)、信息量 (% Info) 以及两者的组合 (%True + %Info)。原始论文的作者使用人工来评估模型性能,但他们发现自动化指标在 90% 以上的时间都与人工预测保持一致。在本文的实验中,作者依靠前人微调的 GPT-judge 和 GPT-info 来评估分数。
TruthfulQA的提示工程。TruthfulQA 与指令归纳不同,作者想找到一个最佳指令提示,可以在涵盖健康、法律、政治和小说的所有 38 个类别问题中都有较好表现。而且,最终生成的所有指令都很通用且不包含数据集中的任何示例。
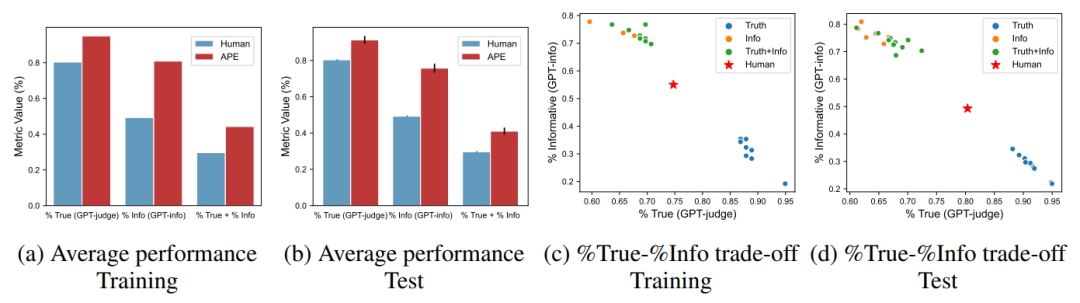
真实性与信息量的权衡。当 APE 在 InstructGPT 只提出 200 个候选提示的情况下优于人工提示工程。作者将生成的提示与 TruthfulQA 原始论文的 “help” (人工)提示进行比较,训练和测试性能如下图(a)(b)所示,结果是从 200 个候选中选择前 10 个可以很好地拓展到测试集,展示了三个指标的前 10 个指令的平均性能。然而,作者指出 APE 发现的指令在回答 “No comment” 这样的答案时可以达到很高的真实性,但这些回答提供的信息却很少,于是用最佳候选进一步调查真实性和信息性之间的权衡,在下图(c)(d) 所示的真实性-信息量图上,将三个指标中的前10个样本可视化。虽然 APE 在提供真实性和信息量的答案时达到了超过 40% 的准确率,但所发现的指令往往是针对这个 %true-%info 帕累托边界的两端。
定量分析
作者在这部分进行定量分析,从而改进本文方法的三个主要组成部分:proposal 分布、评分函数和迭代搜索。
用于 proposal 分布和评分的 LLM
随着模型大小的增加,proposal 质量如何变化?为了解模型大小如何影响初始 proposal 分布的质量,本文研究了 8 个不同的模型。为每个模型生成 250 个指令,并在 50 个测试数据上计算执行准确率,从而评估 proposal 分布的质量。我们在下图 (a) 中可视化了一个简单任务的生存函数(测试准确率大于某个阈值的指令所占百分比)和测试准确率直方图。正如两图所示,较大的模型往往比较小的产生更好的 proposal 分布,经过微调而遵循人类指令的模型也是如此。在简单任务中,由最佳模型 InstructGPT 生成的所有指令都具有合理的测试准确率,与此形成鲜明对比的是,有一半的指令偏离了主题,在执行准确率上表现不佳。
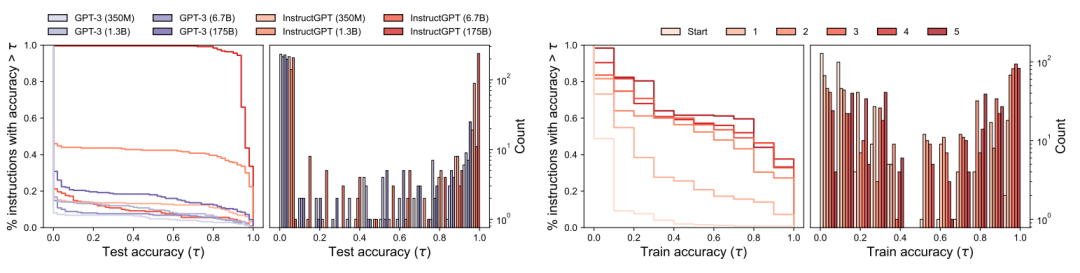
proposal 的质量在选择中重要吗?
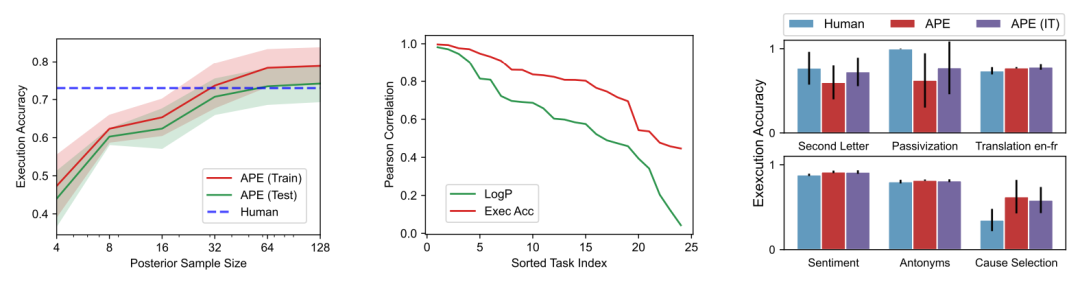
如果从 LLM 中采样的指令越多,就越有可能找到更好的。为了验证这一假设,作者将样本量从 4 增加到 128,并评估测试准确率的变化。下图(左)显示了当64个指令样本达到人类水平的性能时,单调增加的趋势与递减的回报,选择 50 作为默认样本容量,在这种配置下,研究了 proposal 分布如何影响算法选择的最佳指令的测试准确率。上图显示,尽管小模型生成好指令的机会很低,但如果对候选指令进行足够的采样,仍会生成一些好指令。因此,通过运行本文的选择算法,仍然可以在一个小模型中找到有潜力的指令,这也解释了为什么本文方法在 8 个模型上的性能明显优于贪婪方法。
哪种评分函数更好?作者在24个指令归纳任务上计算了测试准确率与两个指标之间的相关性,以研究提出的指标表现如何。在“正向”模式下使用 InstructGPT 为每个任务生成 250 条指令,并计算 10 个测试数据的指标分数和测试准确率。这里可视化了测试准确率和两个指标之间的 Pearson 相关性,下图(中间)显示了跨任务的执行准确率与测试性能更好地保持一致,因此将它作为默认指标。
迭代蒙特卡洛搜索
迭代搜索能提高指令质量吗?作者将 “Passivization” 任务的生存函数和测试准确率直方图可视化为图 7 (右)。生存图显示曲线随着轮次的增加而增加,这表明迭代搜索确实会产生更高质量的 proposal 集。我们观察到进一步选择轮次的收益递减,因为质量似乎在三轮之后趋于稳定。
本文需要迭代搜索吗?作者在 6 个任务上比较 APE 和迭代 APE。如图 9, 迭代搜索在 APE 表现不如人类的任务上略微提高了性能,但在其他任务上差不多。这与前面的假设一致,即迭代搜索对于生成良好初始 具有挑战性的任务最有用。
小结
本文为了减少创建和验证有效指令所涉及的人工成本,通过将提示工程过程描述为黑盒优化问题来将其自动化,作者使用 LLM 指导的高效搜索算法来解决该问题,APE 方法在多种任务上以最少的人工投入达到了和人类水平相当的性能。由于近些年来大模型展示出遵循人类指令的能力,因此可能许多未来的模型(包括那些用于正式程序合成的模型)都将会有自然语言界面,而本文的工作今后也可能将为控制和引导生成 AI 奠定基础,但这条路的探索还需要更多人的共同努力,任重而道远。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群


)







)




)


)
)
)