Multi-lingual BERT
输入多种语言来训练BERT
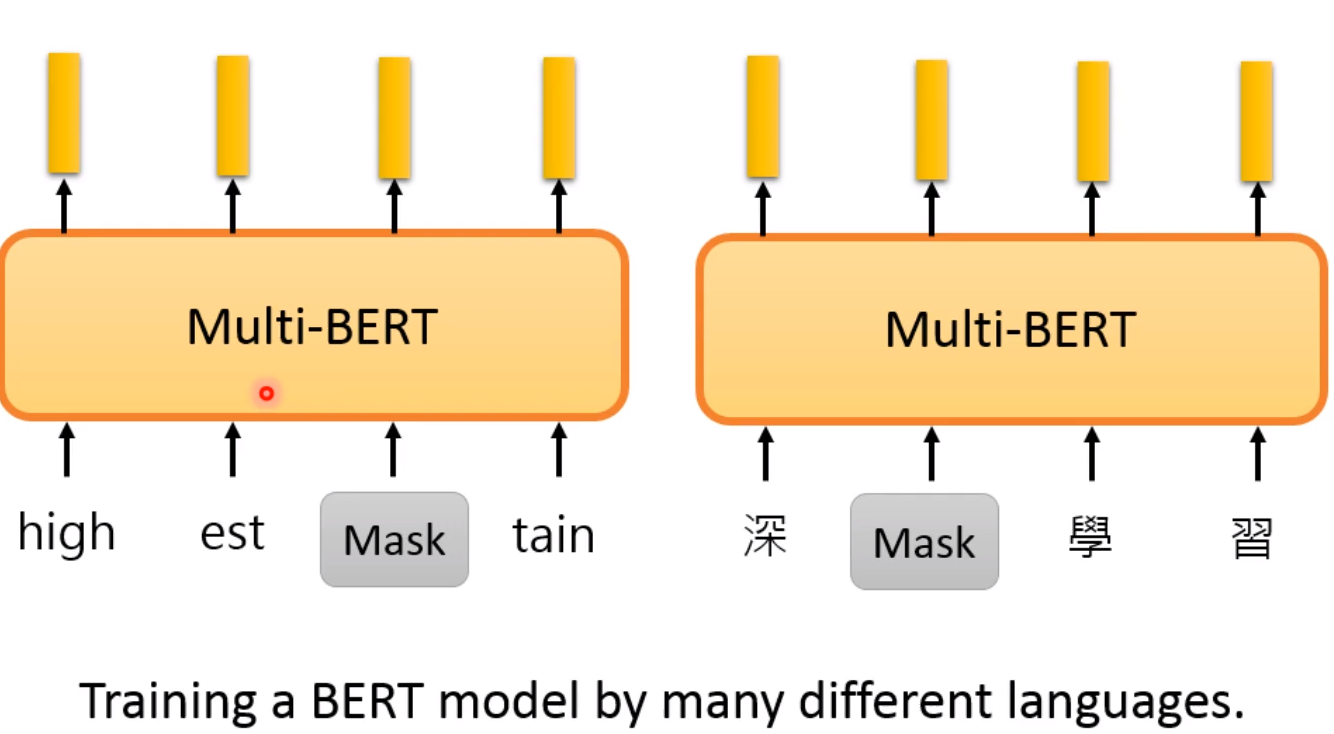
Zero-shot Reading Comprehension
首先模型是在104种语言上进行训练的!
并且以English的QA来training我们的模型,最后在回答问题的时候使用中文!
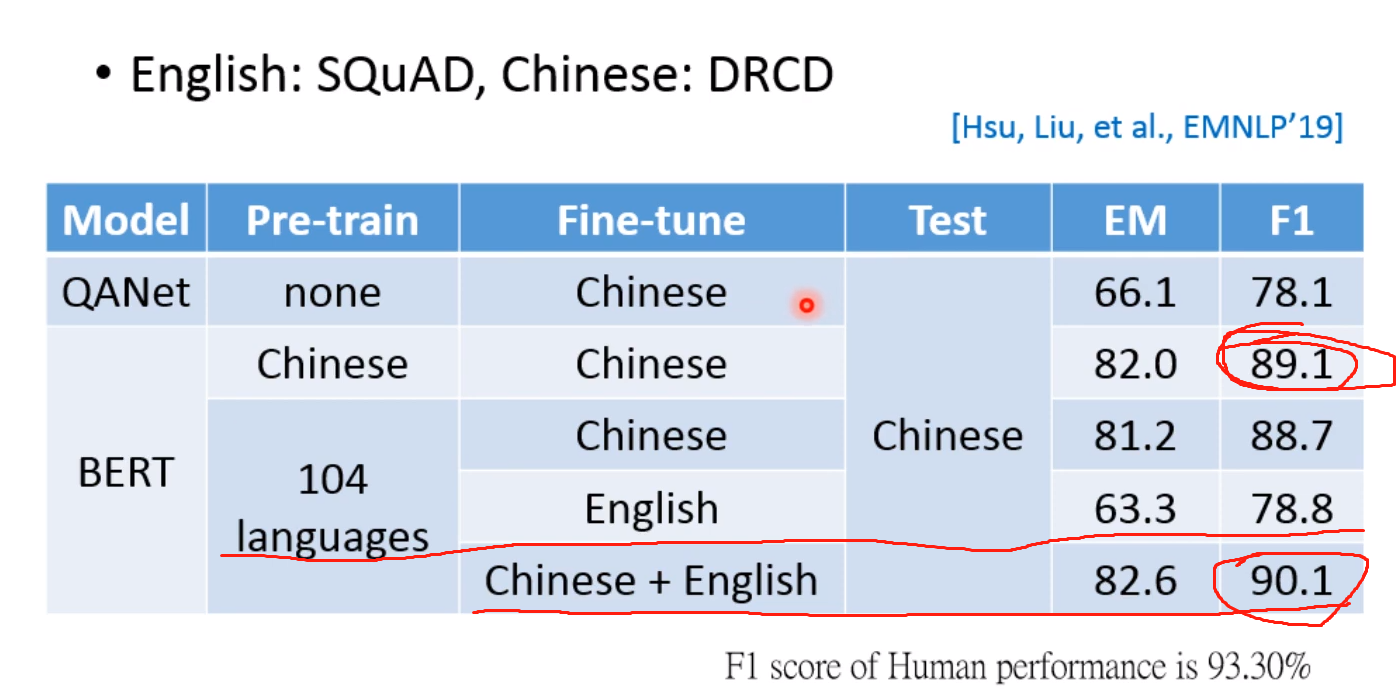
可以看到如果在104种语言pre-train,然后在Chinese+English上进行fine-tune得到的准确率是最高的!而两者均在Chinese上训练,得到的结果却不是很好! 这就是Multi-lingual 的神奇之处!
这里行坐标是在哪个语言上训练,列坐标是在哪个语言上测试! 所以下面的都是硬Train的,就是看模型懂不懂语言上的跨度!
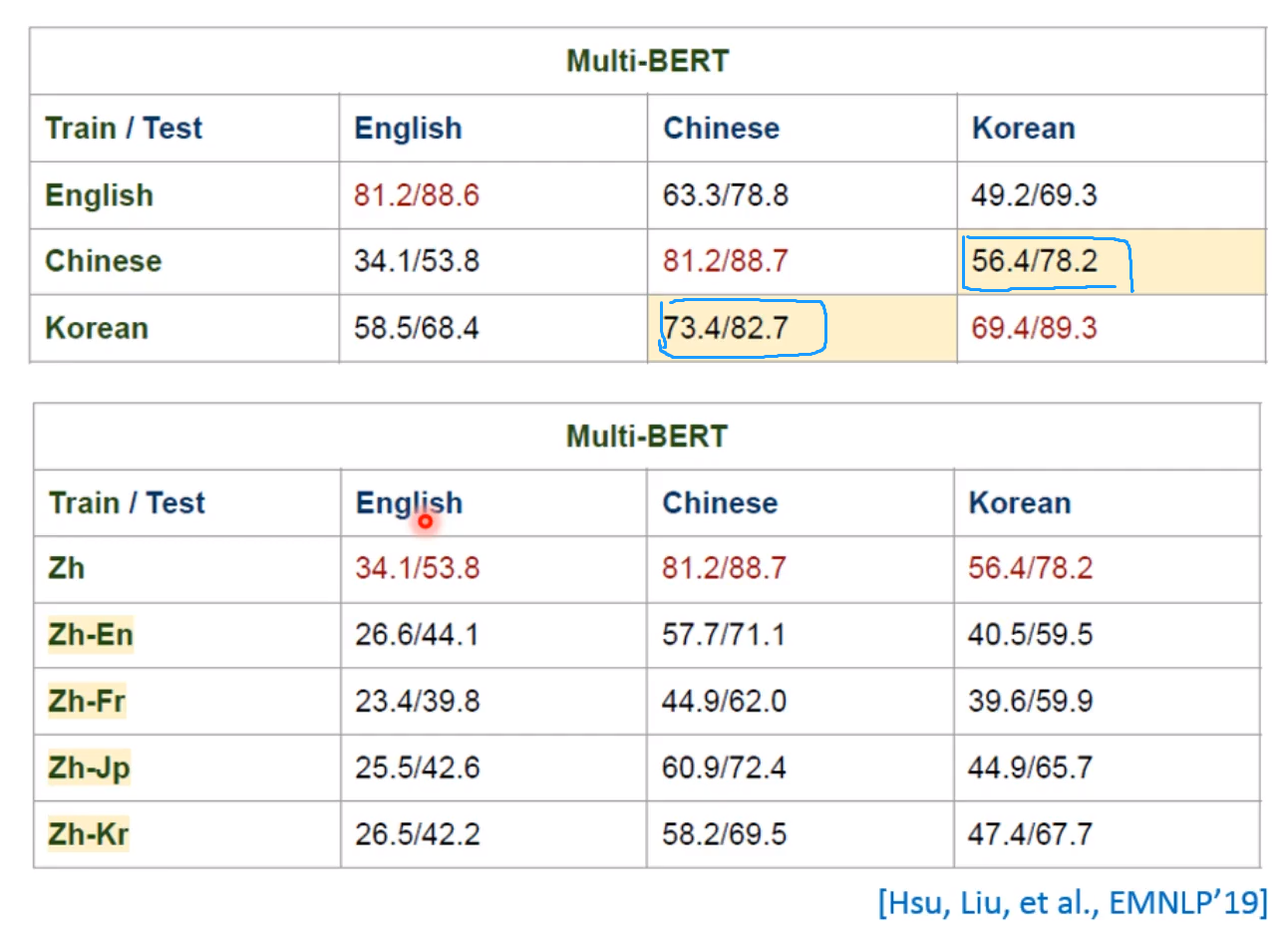
其它的证据也有很多,也能证明在一个语言上训练,其它语言上同样有效
Cross-Lingual Alignment?
为什么跨语言模型对齐能够成功?
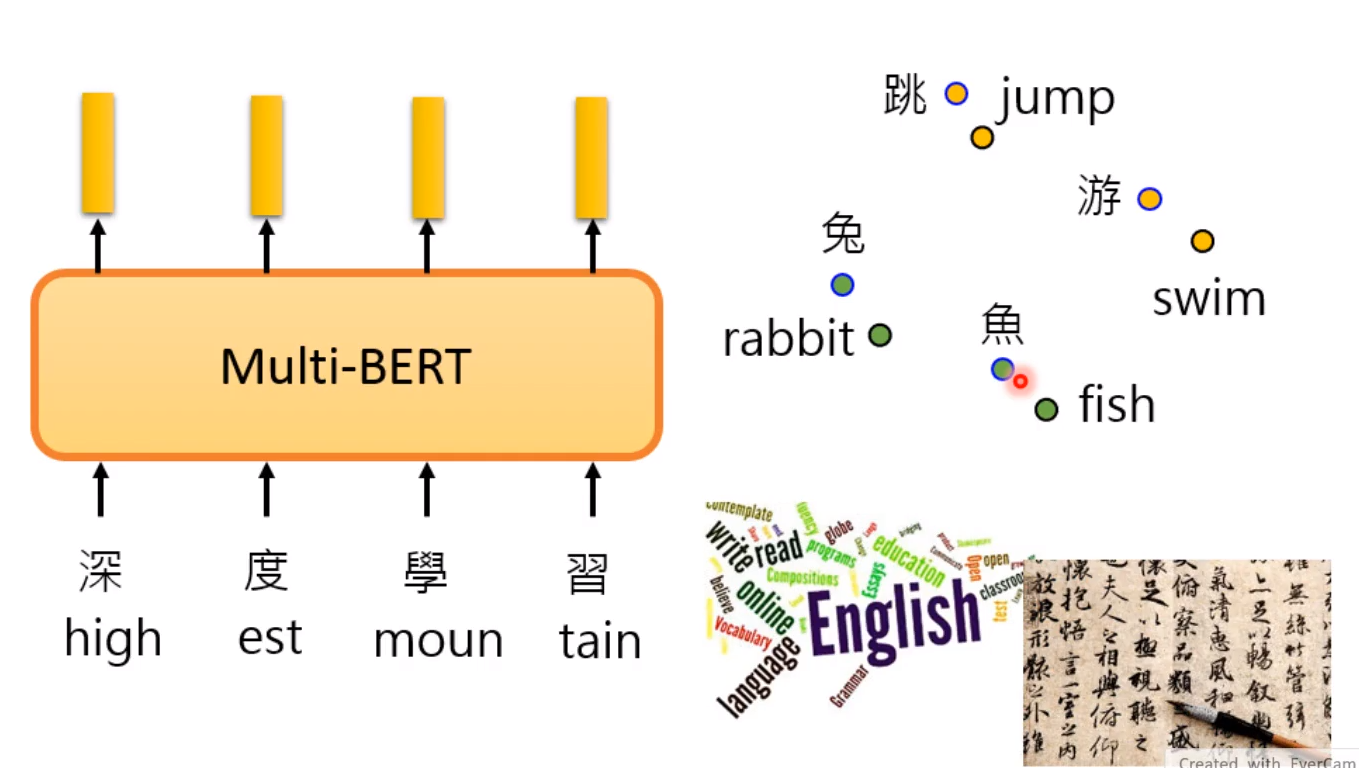
说明在word embedding上,两个语言的嵌入是相近的!
真的会嵌入到相同的位置吗?
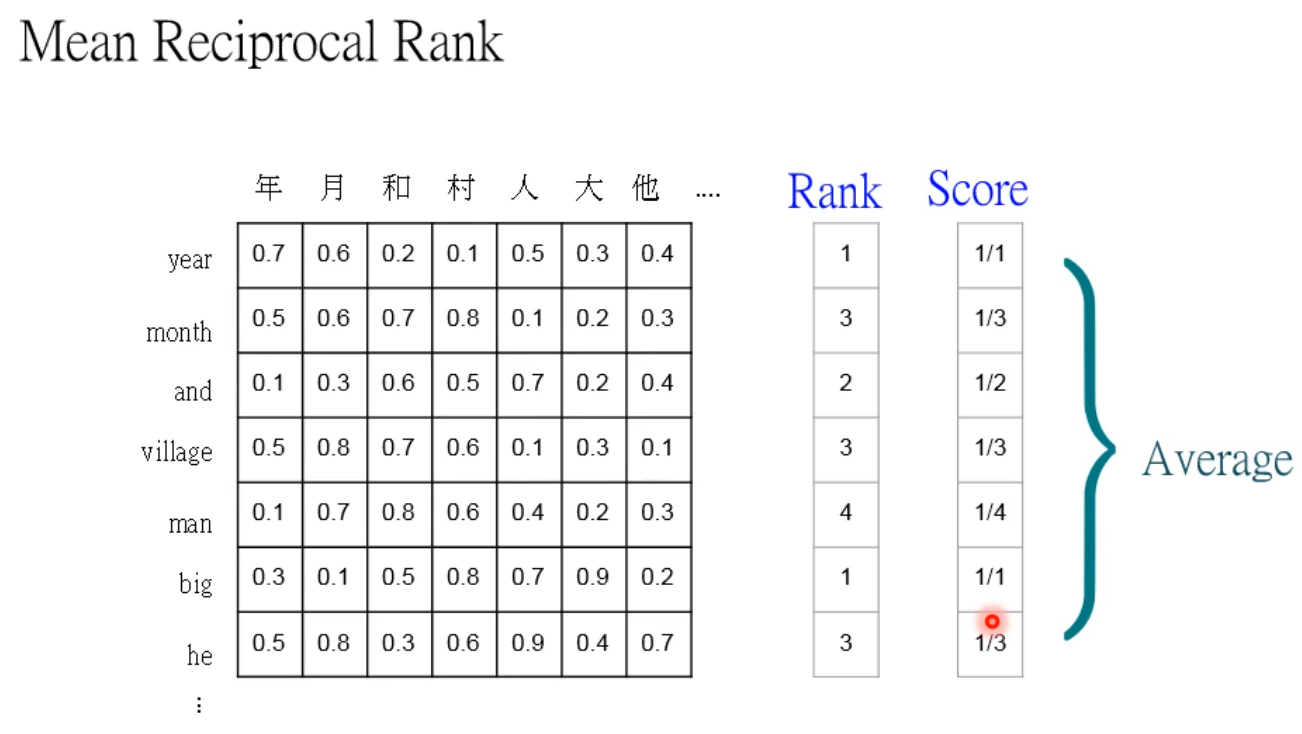
我们通过计算两个词汇的相似度,rank的意思是第几个才是正确的答案! 最后取平均!
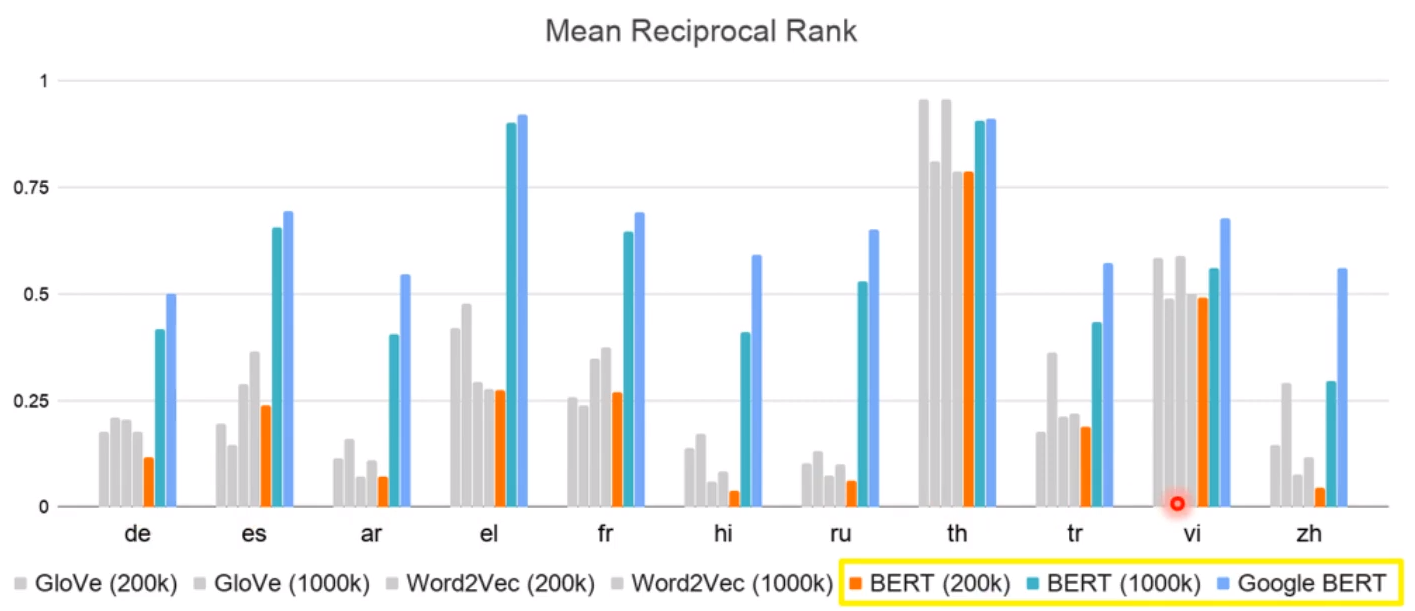
在不同的语言上进行实验我们的模型,后面的几百几千k是资料数! 会发现模型的效果很大程度上依赖于词汇量; 但是在控制词汇量之后,会发现有的模型即使词汇量很大,也难以达到像BERT一样的效果!

How alignment happens?
但是为什么模型就能让他们有更加近的vector的距离呢?
- Typical answer
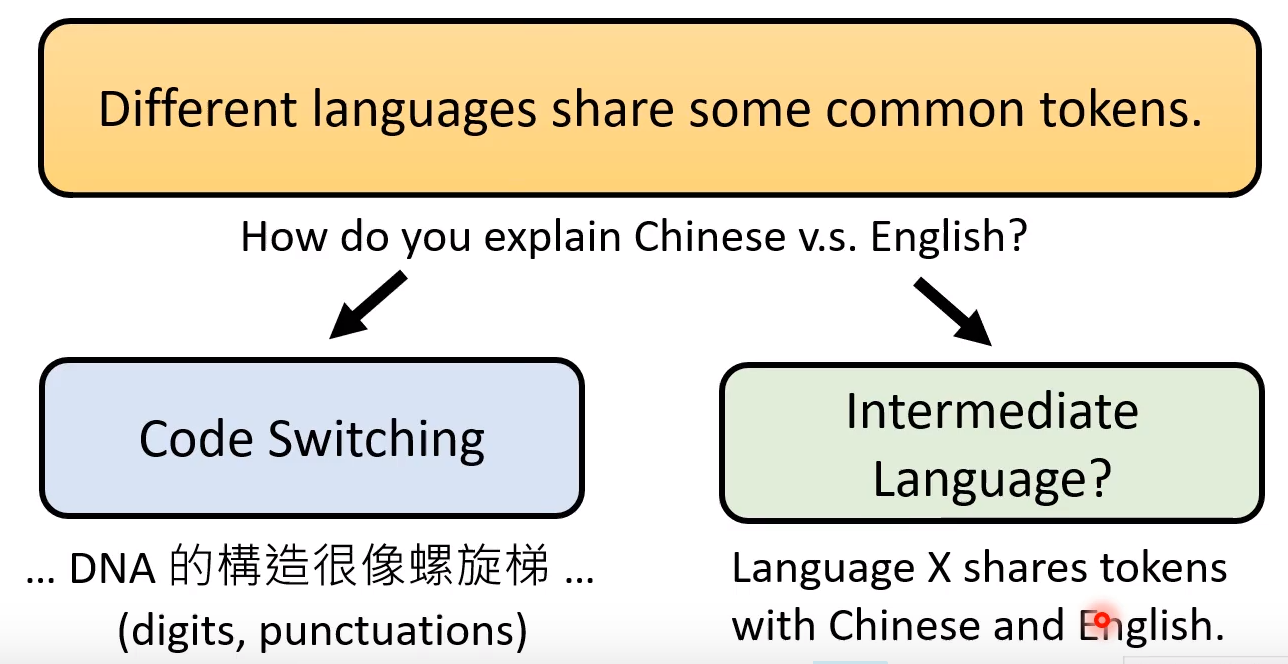
第一种解释是两种语言中有一些公用的tokens,比如数字、发音; 再比如中文和应为中语言X有相似的tokens
- 第二种解释
- 我们将English中的单词转化为fake-english作为输入,这样两者就不存在common Tokens,再去看实现效果! 比如红框里面,pre-train、trian和test后结果还是很好的!
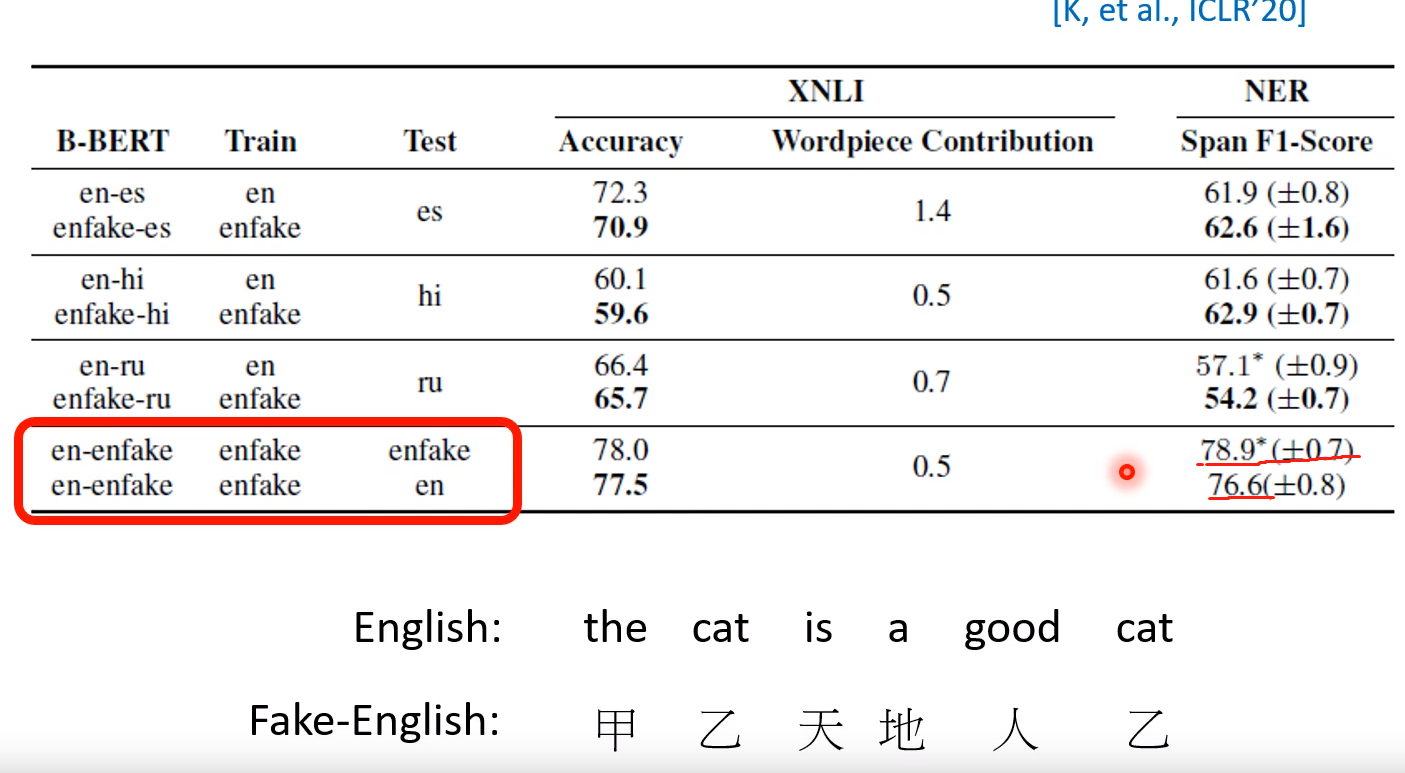
- 这是一个尚待研究的问题
Sounds weird?
我们已经知道的就是两者的token embedding肯定是相近的。 这里面肯定有语言信息!
不同语言的平均还是有差异的!
语言的平均用来相加:
我们计算两种语言(平均)的差异,我们的假设是可能一种语言在另一种语言的同一侧!
那么我们用两者之间的差异,加到一种语言上,那么会得到另一种语言!
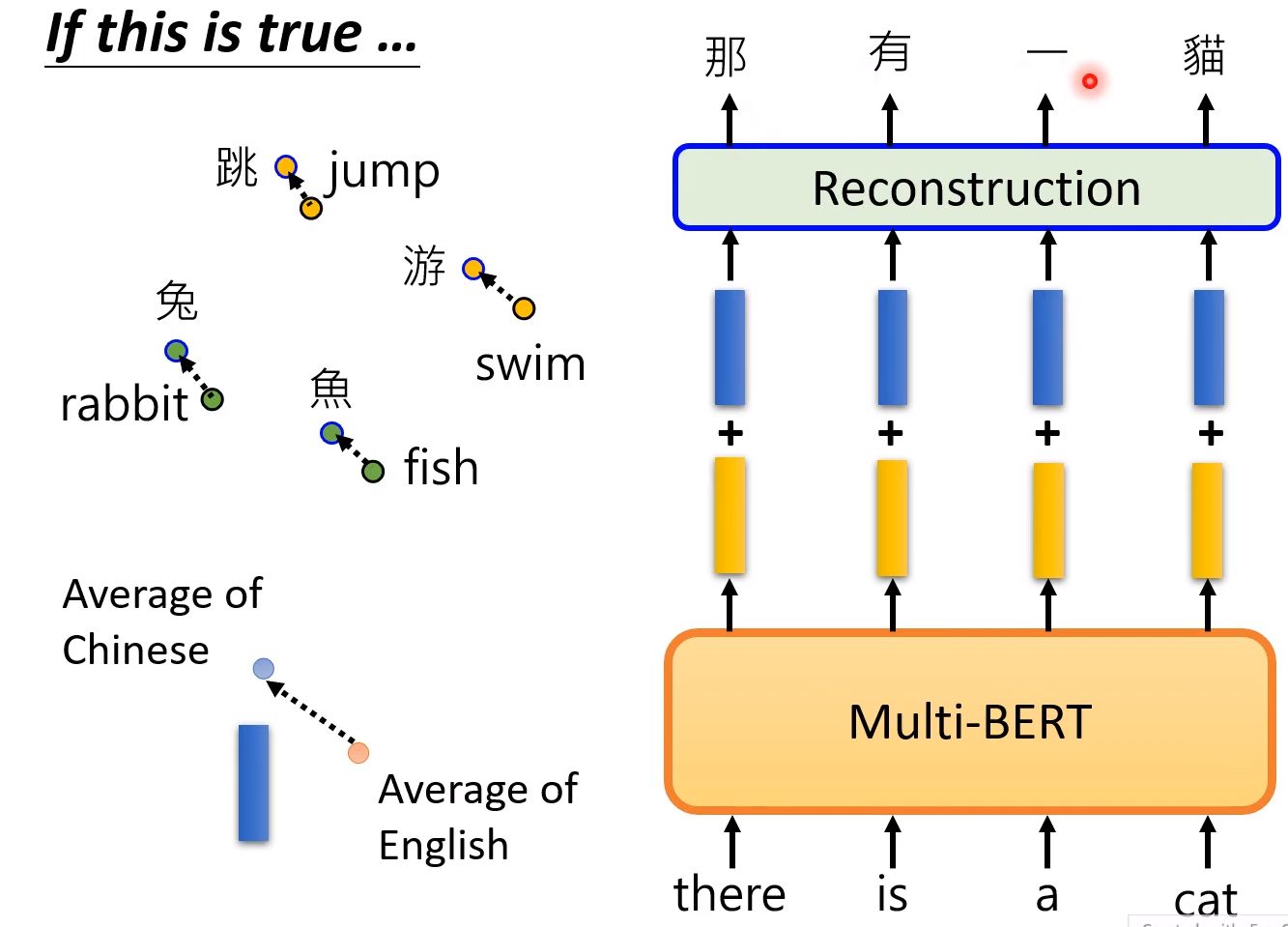
这确实是有用的,我们加上两倍的,三倍的蓝色的向量后会发现文字全部翻译成了中文! 虽然在翻译上是问题的,但是说明语言信息的存在性

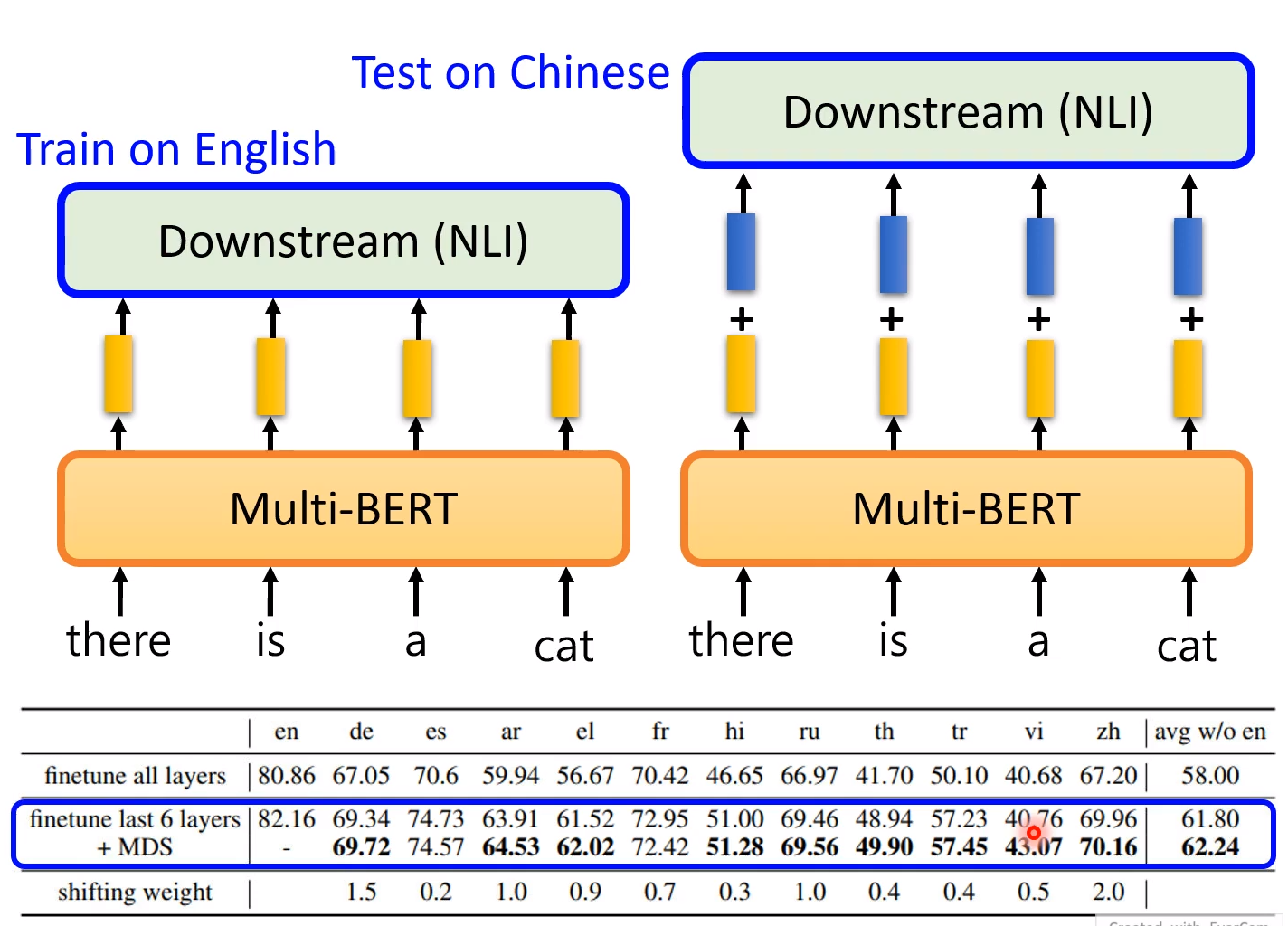
下面的例子中常规的测试,只是加入了蓝色的向量,会发现效果会变好!
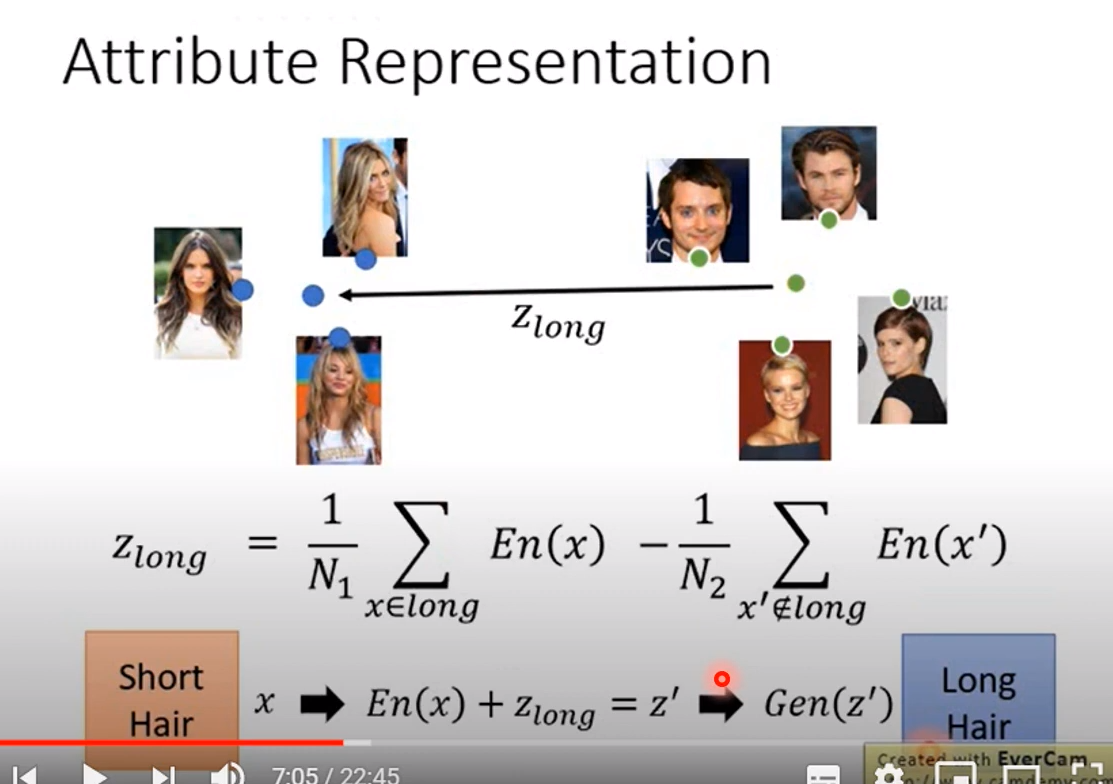
先求短发的平均,再求长发的平均,短发加(长发和短发之间的距离)就是本人的长发模样
![[转]详细介绍如何做关联](http://pic.xiahunao.cn/[转]详细介绍如何做关联)
)

)

GPT-3)



【转】推荐系统遇上深度学习(二十六)--知识图谱与推荐系统结合之DKN模型原理及实现)



【转】秒懂词向量Word2Vec的本质)





