前情提要
论文名称: Language Models are Few-shot learners
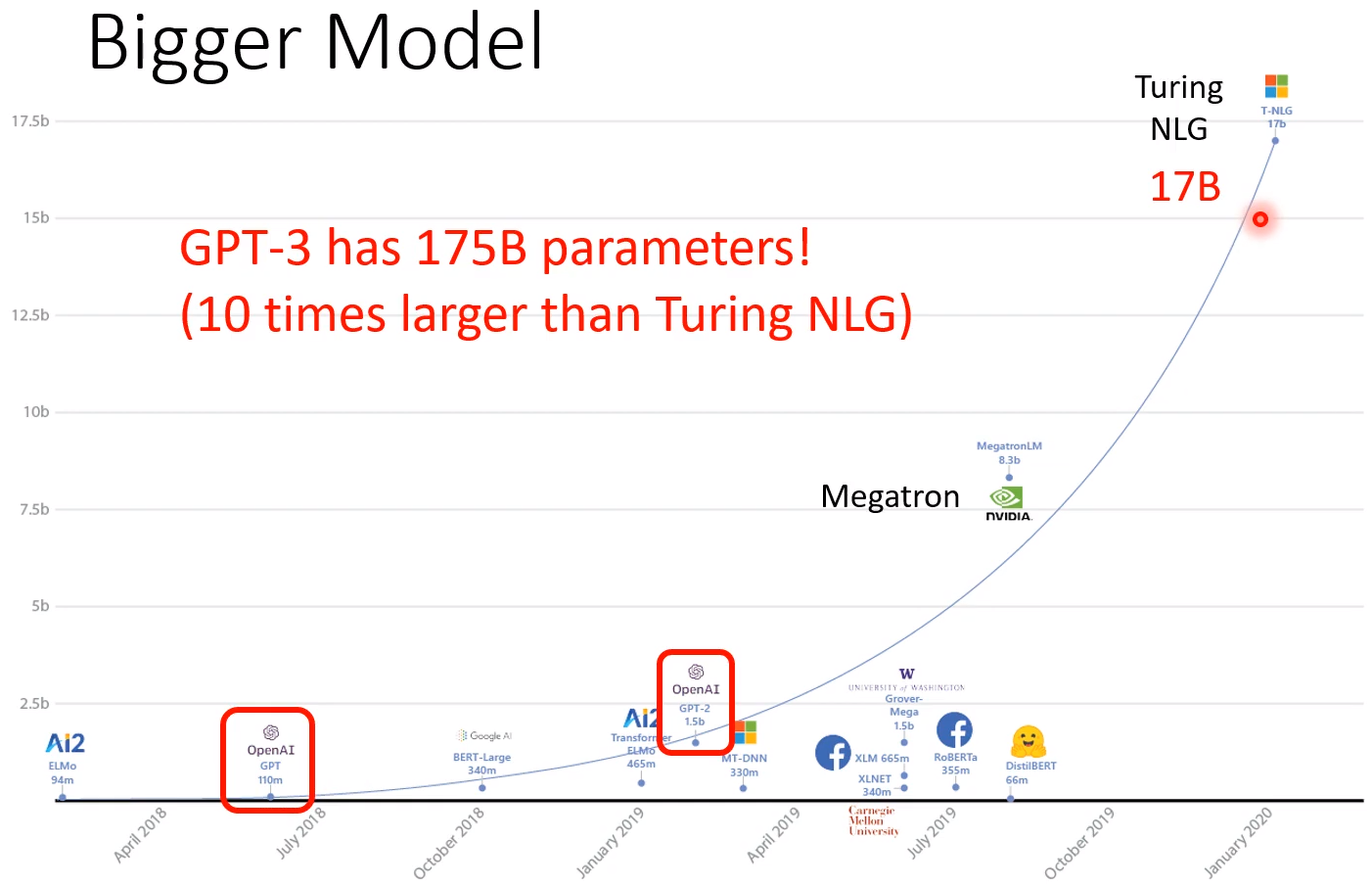
但是GPT-3的缺点在于,太过巨大! 它有多大呢? 原来最大的时候是Turing NLG,有17B,而GPT-3是它的10倍!
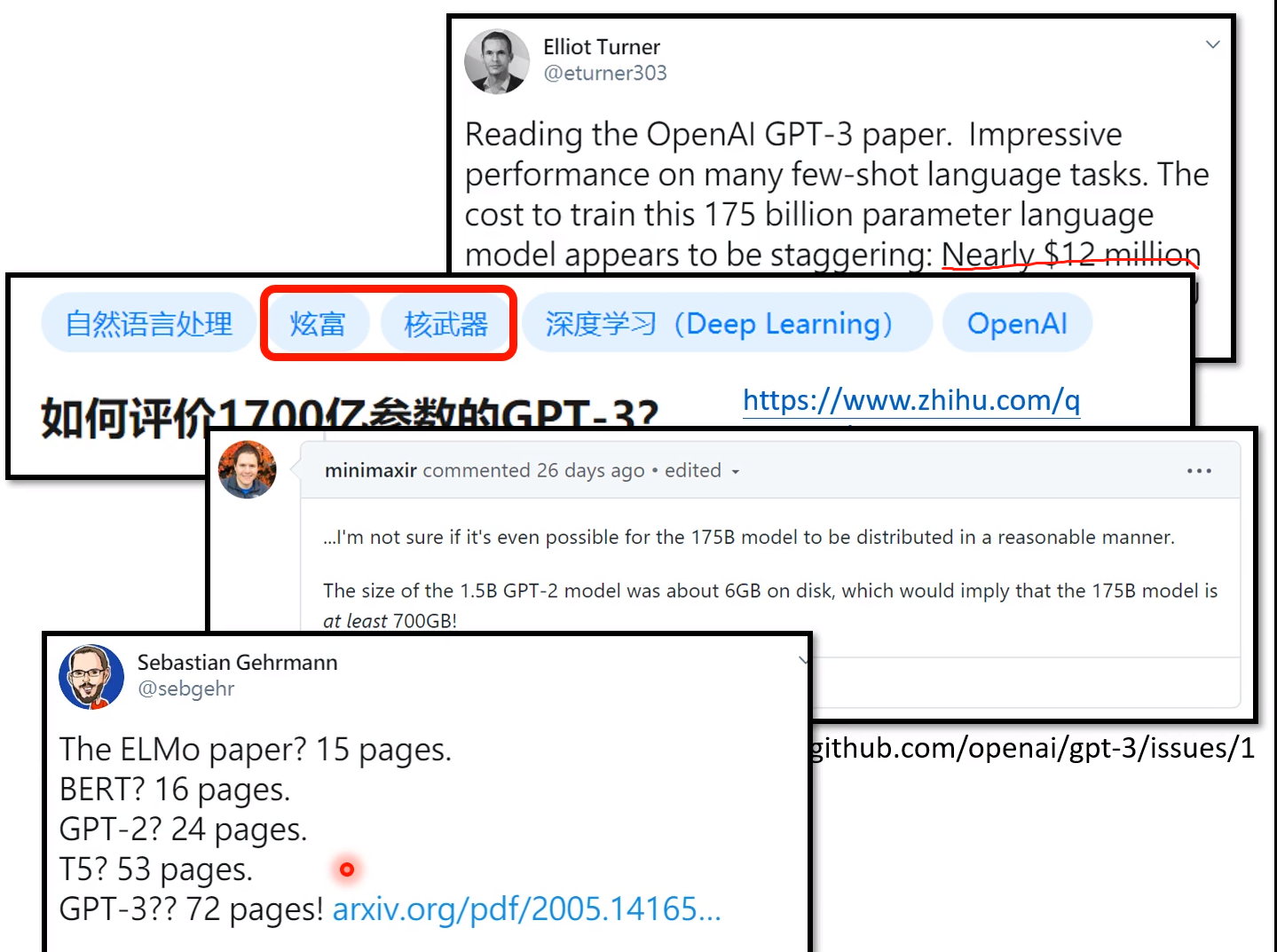
对GPT-3的评价:
GPT-3要干什么事呢? 它是为了ZERO-shot的learning! 所以你现在要训练你的BERT还是需要训练一些资料的! 而GPT-3的目的就是说不再需要fine-tune,直接一个模型就解决所有!!!
GPT系列的野望
就是给出你问题,你在读了问题后就知道怎么解答这个试题!
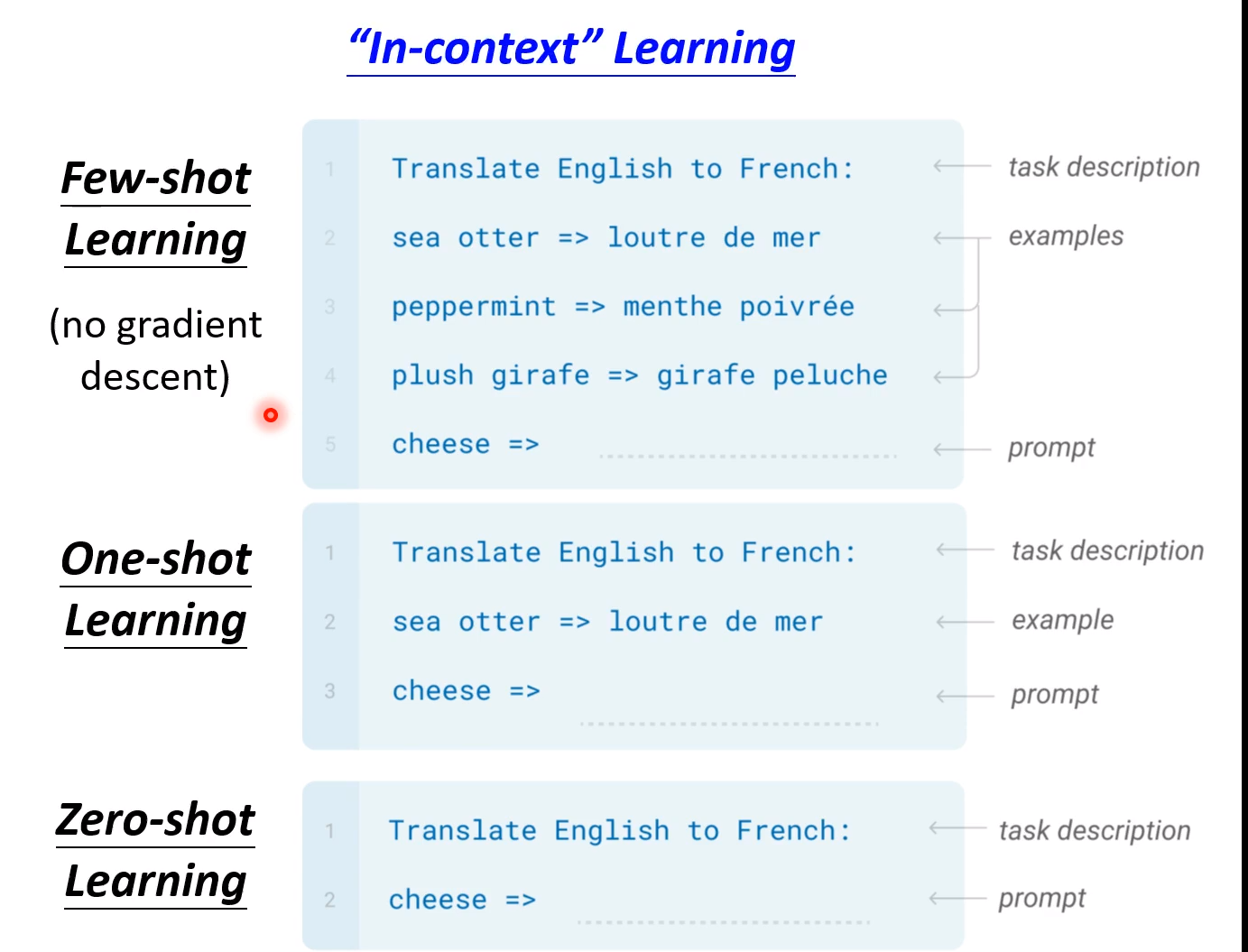
具体一点,该模型主要做了三个事! GPT-3的目的直接zero-shot,而不需要例子,只需要给出描述就可以了! 在论文中就叫做“In-context” learning!!
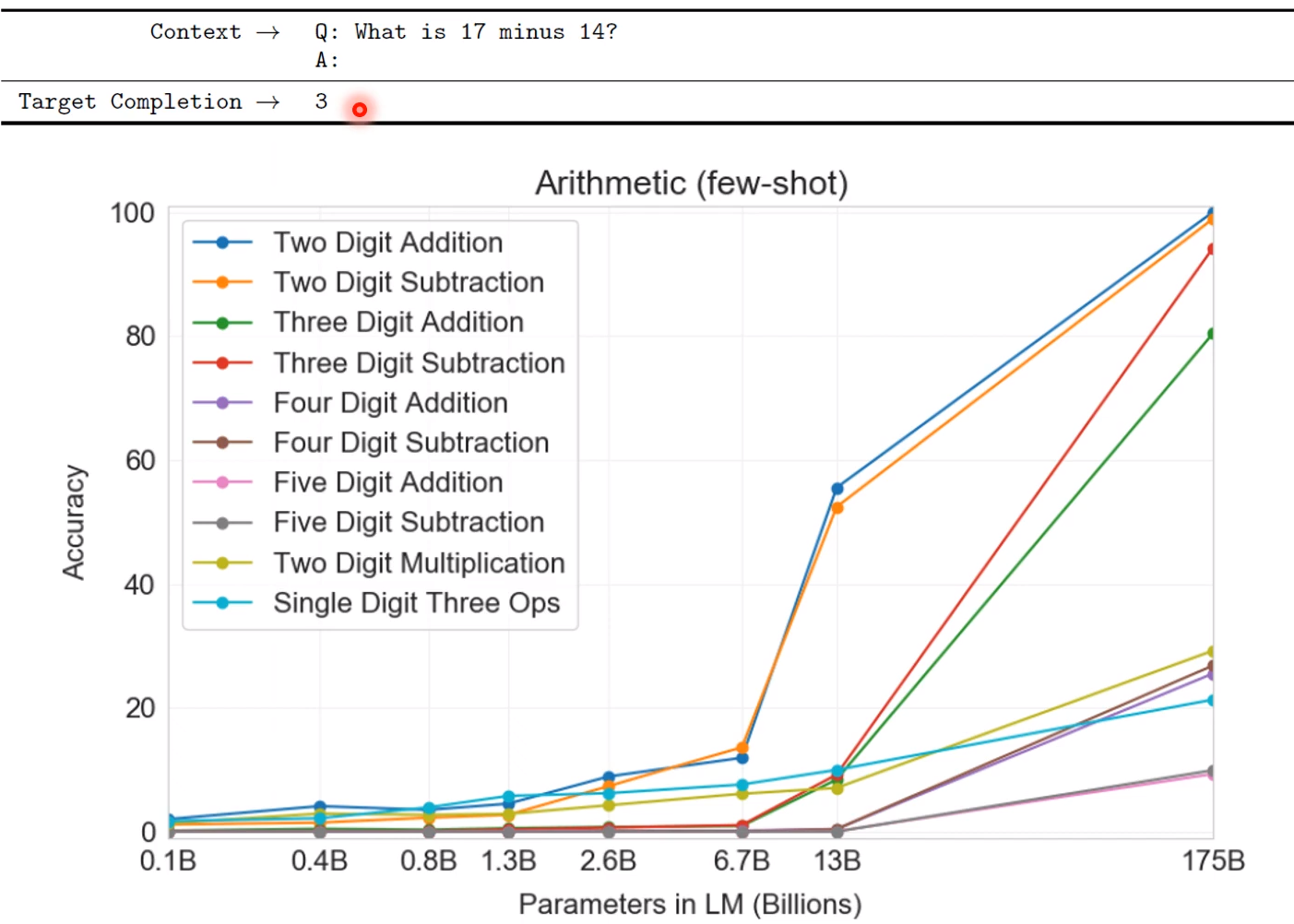
后面这个是GPT系列的准确率! 准确率是提高了,但是这种复杂度的提高值不值得就另当别论了!
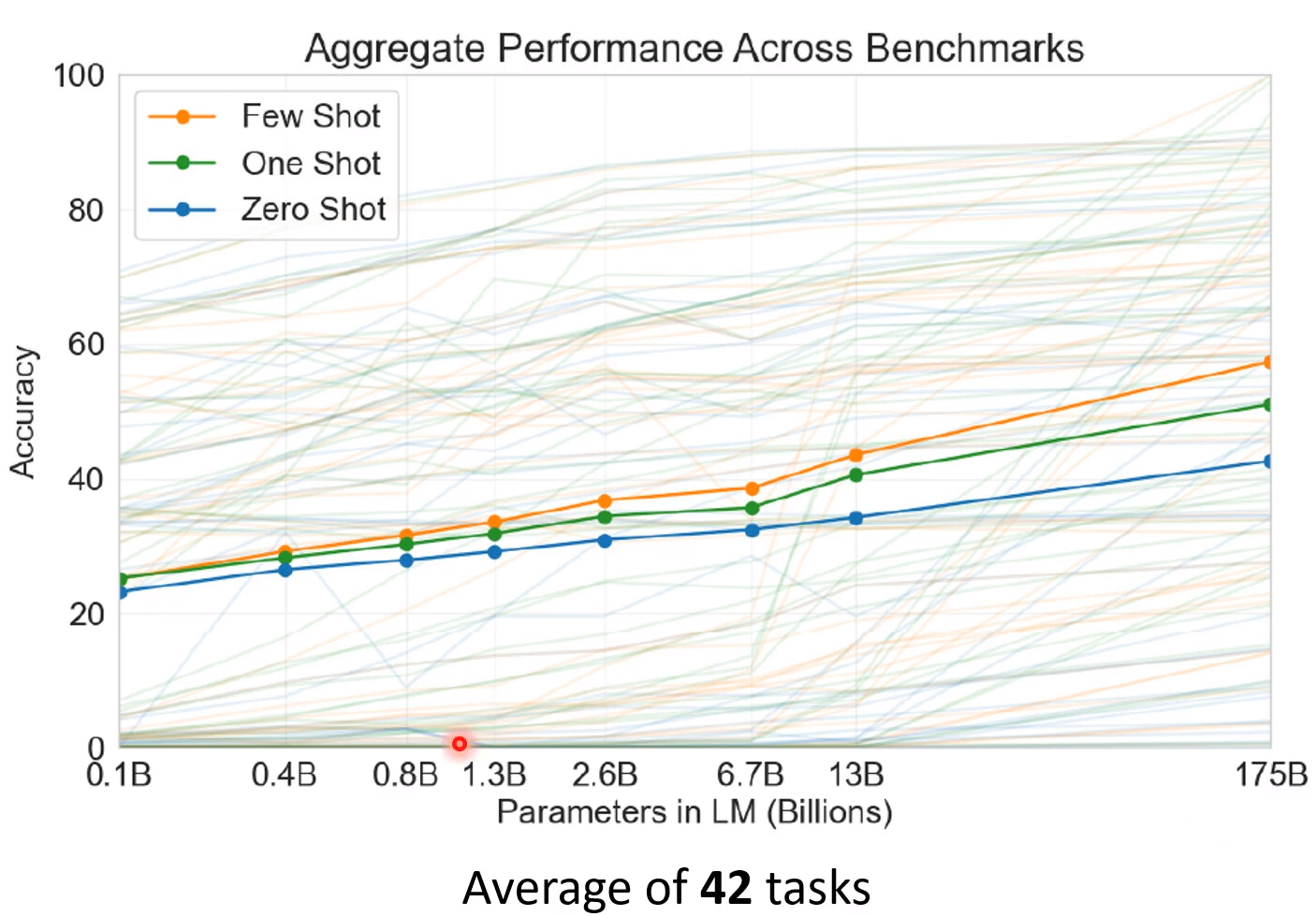
应用
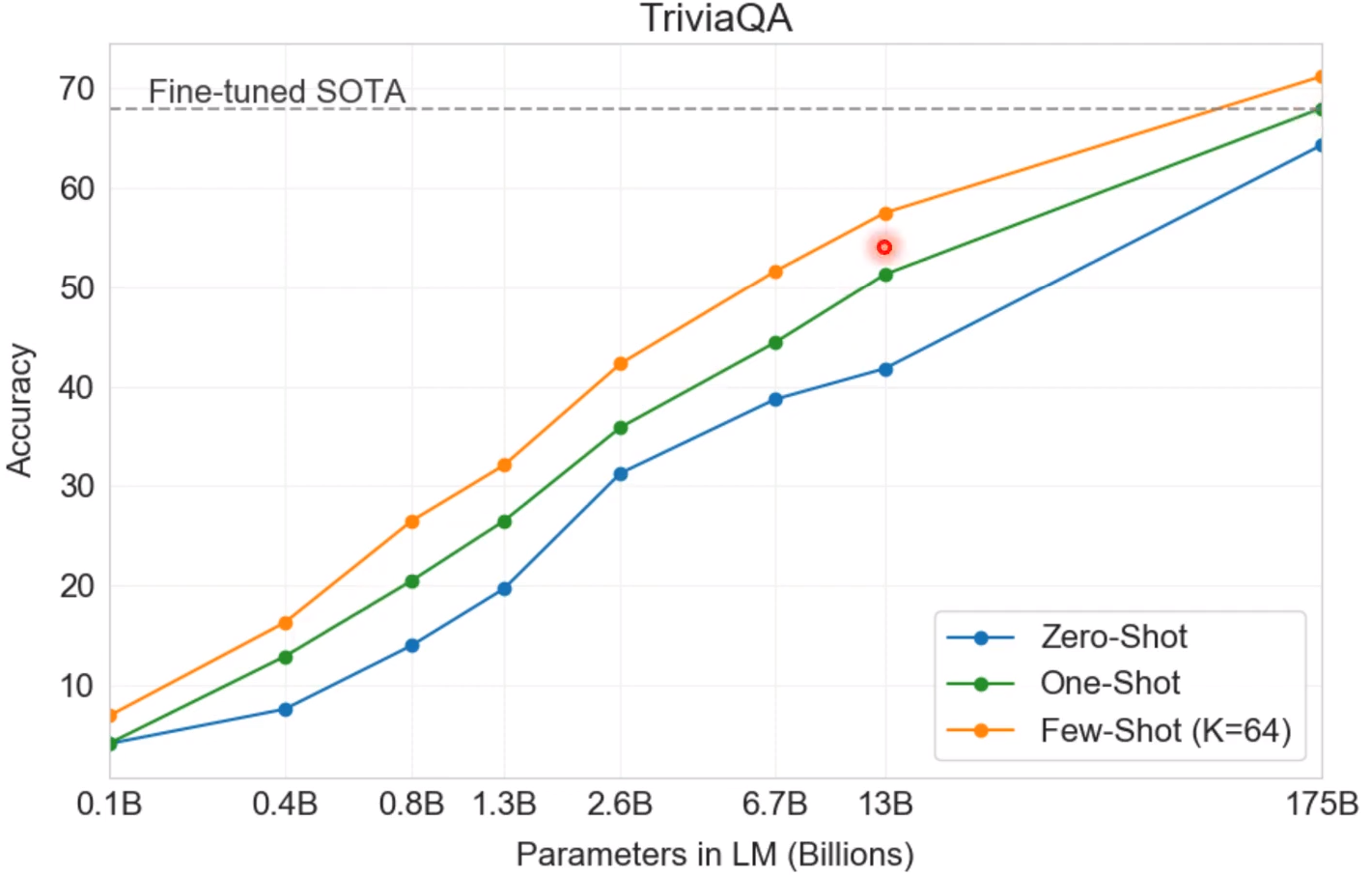
CLosed Book QA
就是说不需要读特定的文章就可以回答问题! GPT-3的效果可以超过经过Fine-tuned的最好性能!
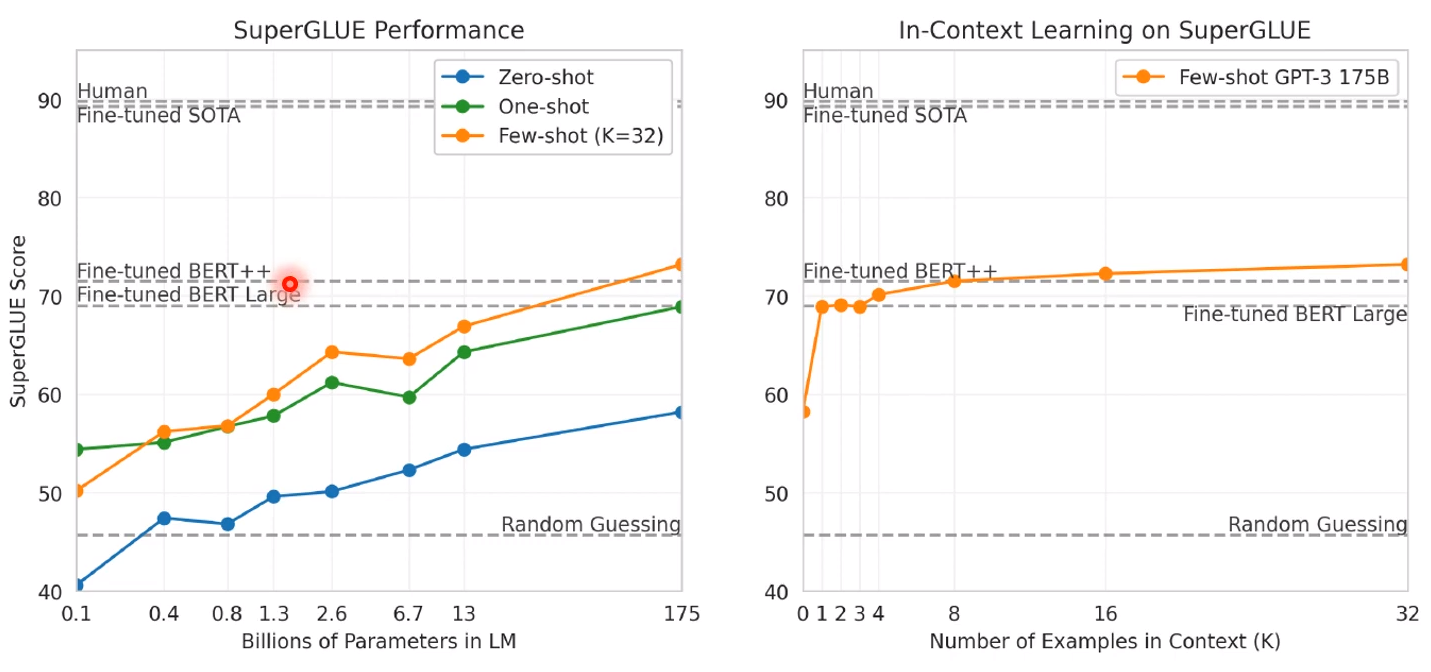
SuperGLUE上
效果也是还行的
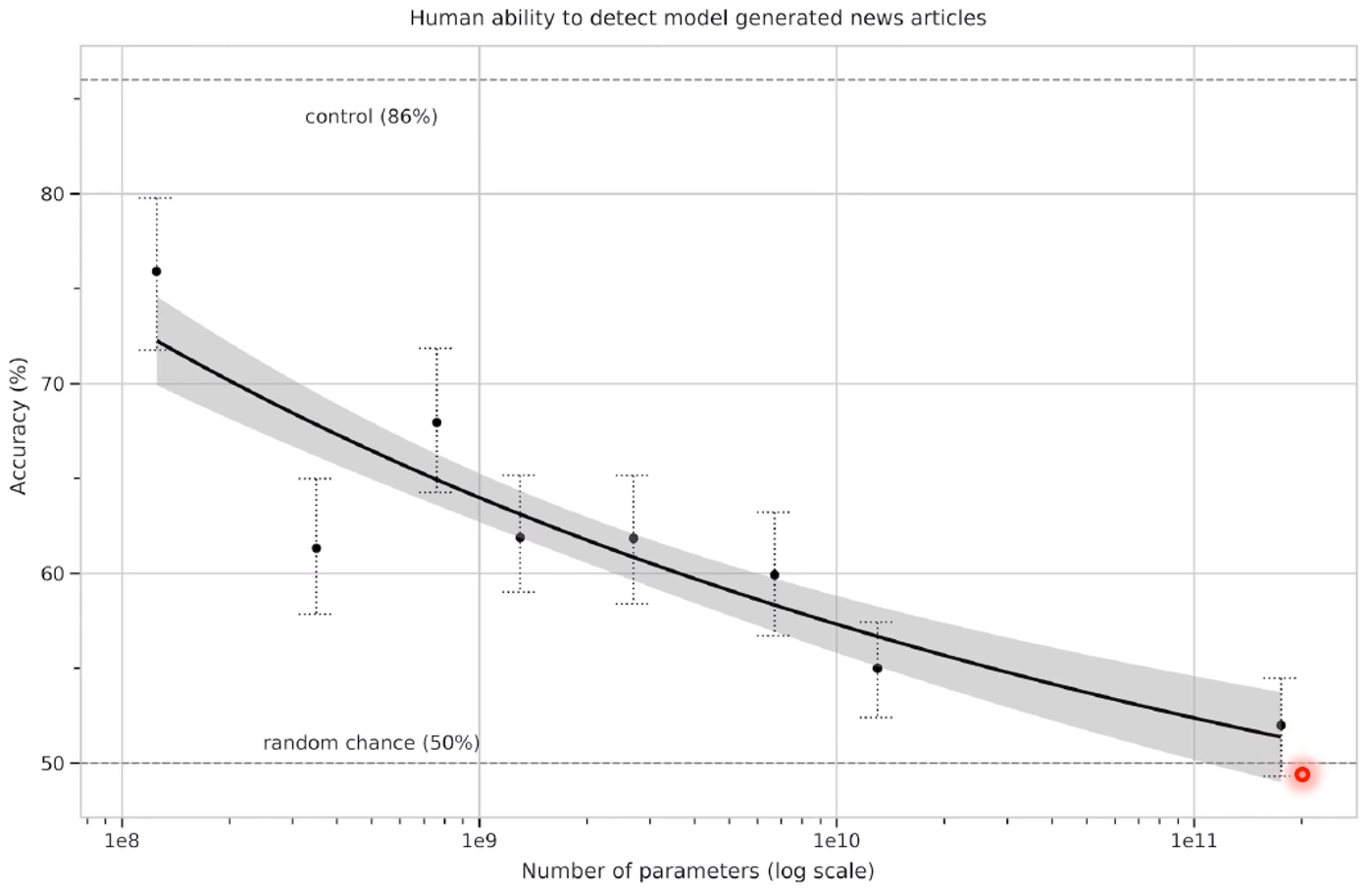
Generated new articles
只给出标题来生成文章! 横轴是参数的量,纵轴是准确率,就是能够骗过模型的准确率!准确率越低,说明人分辨生成的新闻能力越差!
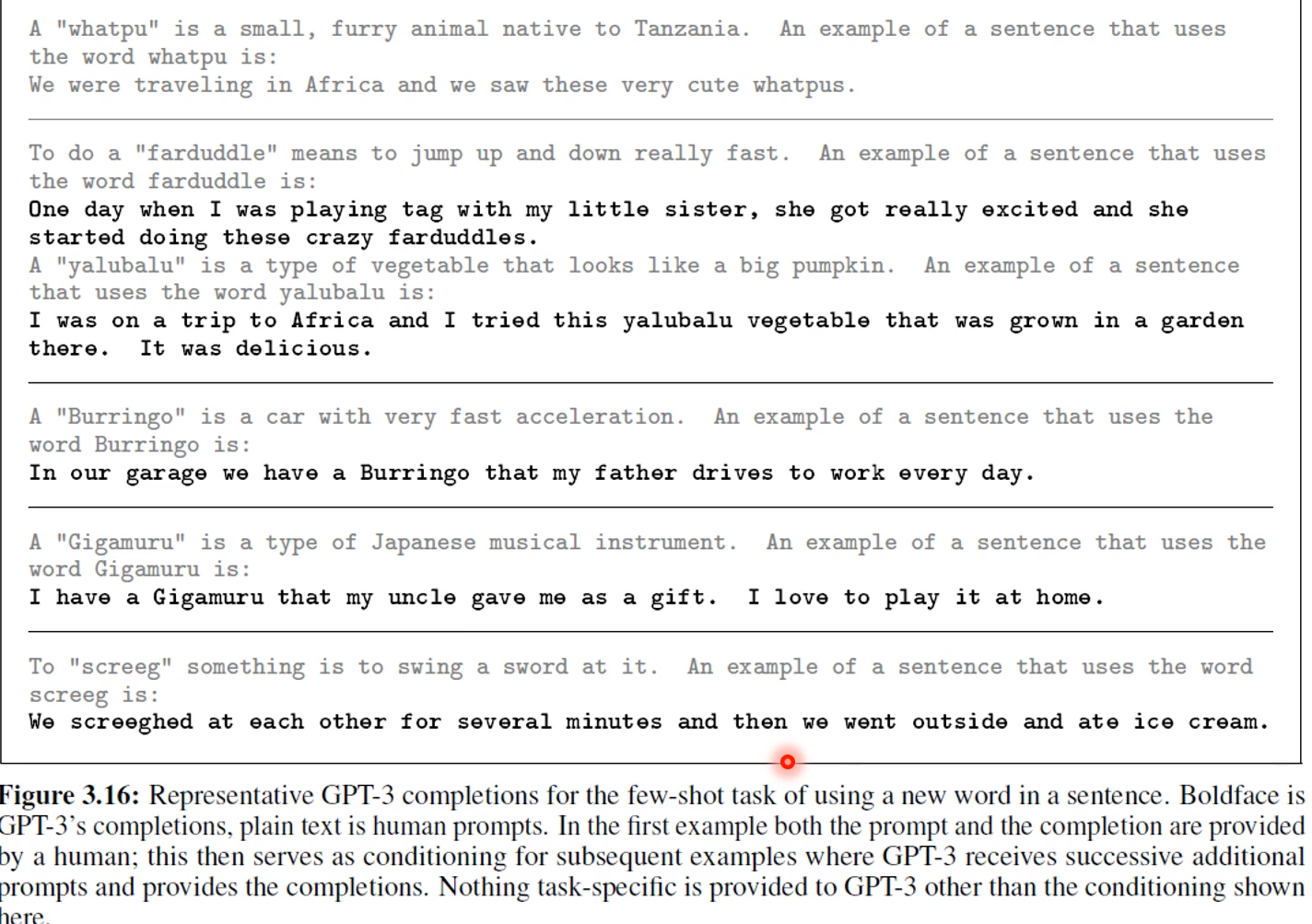
造句
数学问题
后面都是表现差的例子:
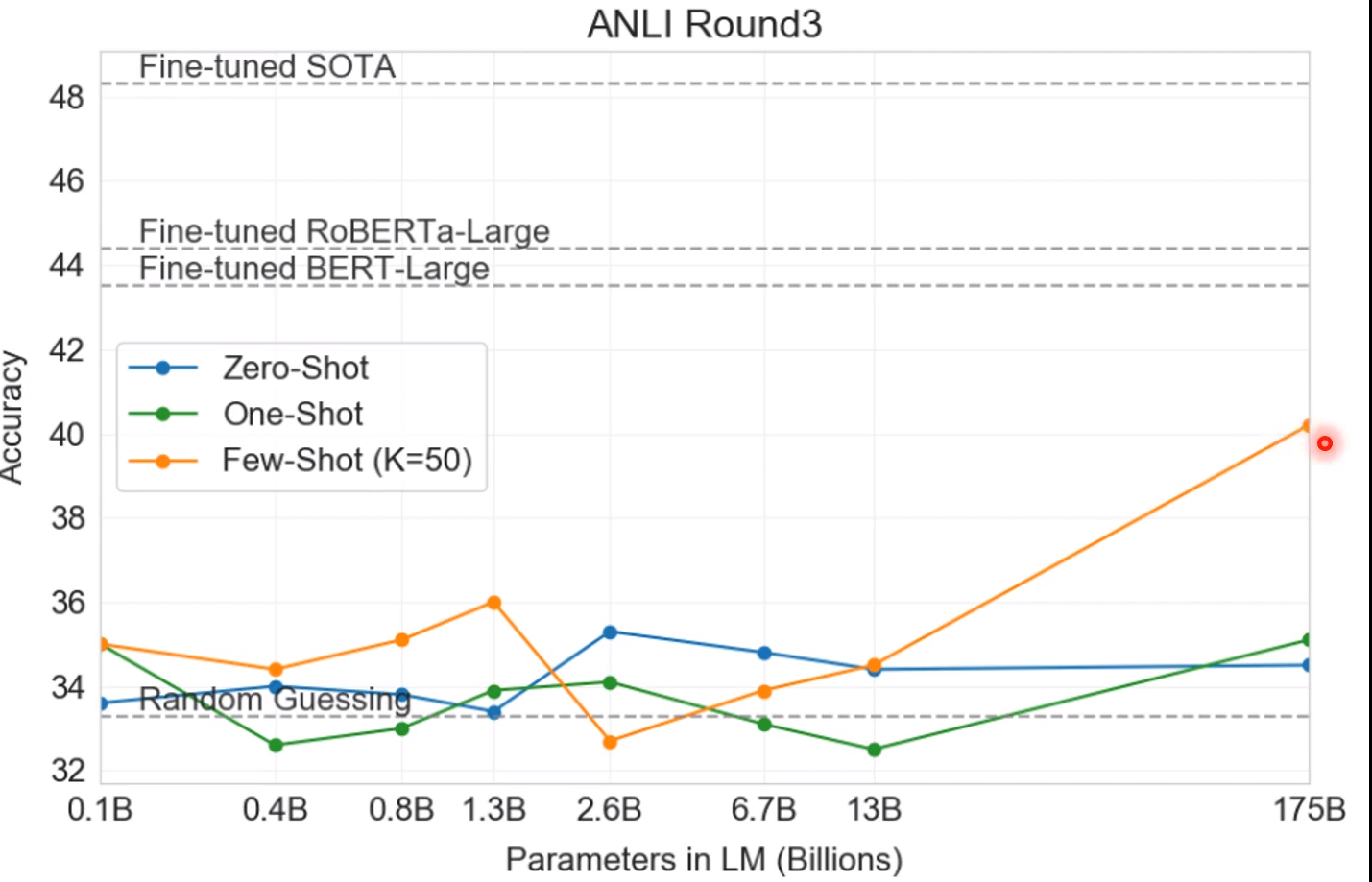
NLI(就是输入两个句子,看这两个句子是不是有矛盾)
Turing Advice Challenge
这是一个比赛,让看模型理解人的语言到什么程度! 内容一般是一个人提出自己的生活中的问题,然后让机器人回答怎么解决!

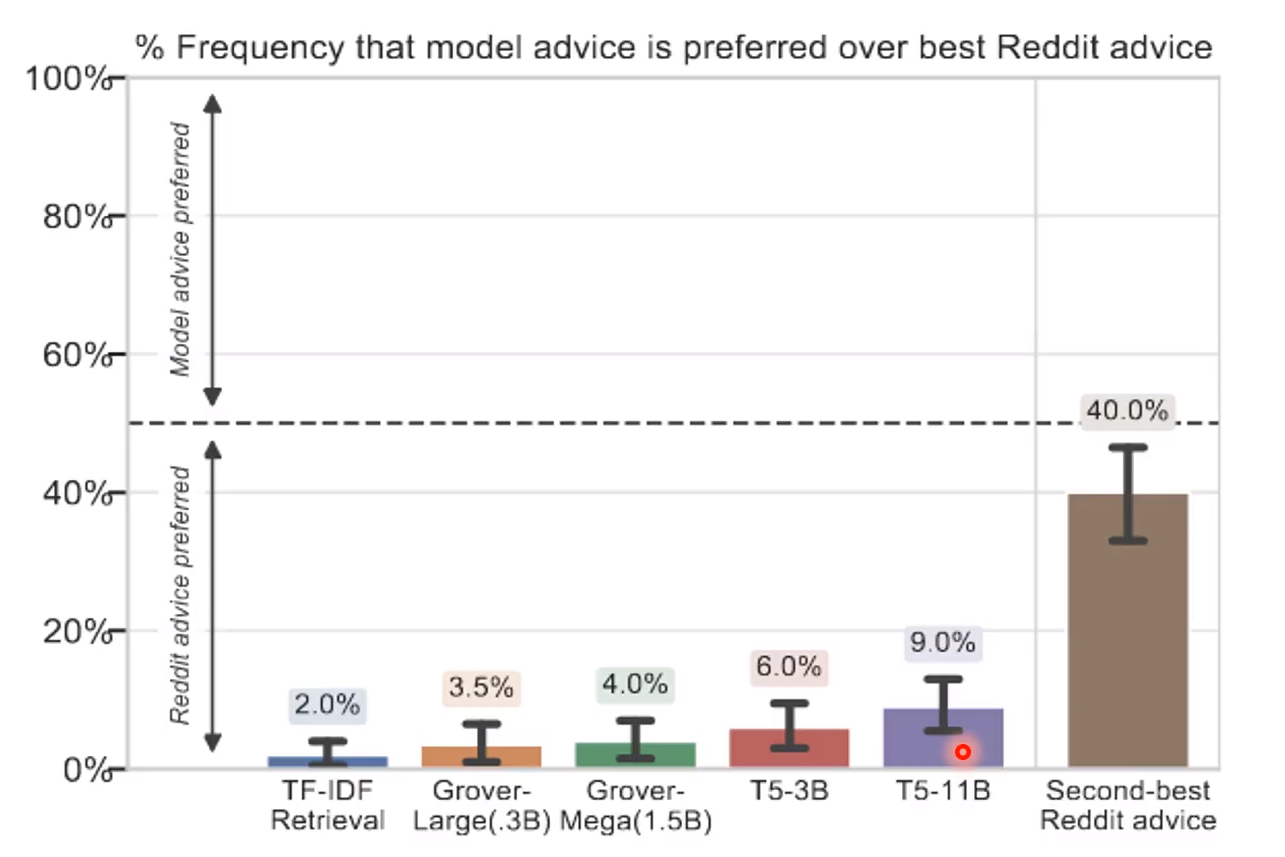
可以看到生成可用建议的准确度还不是很高! 只有9%,就算最好40%
图像上的应用: gpt: raster order
就是让图像自己有创造力,自己创造故事!




【转】推荐系统遇上深度学习(二十六)--知识图谱与推荐系统结合之DKN模型原理及实现)



【转】秒懂词向量Word2Vec的本质)






)

)

)
)