
介绍
本Apache Spark教程将说明Apache Spark的运行时架构以及主要的Spark术语,例如Apache SparkContext,Spark shell,Apache Spark应用程序,Spark中的任务(Task),作业(job)和阶段(stage)。
此外,我们还将学习Spark运行时体系结构的组件,例如Spark driver,集群管理器(cluster manager)和Spark executors。最后,我们将看到Apache Spark如何使用这些组件工作。
Apache Spark的工作原理–运行时Spark架构
在这里,我们将学习Apache Spark的工作原理。在Apache Spark中,中央协调器称为driver。当您在spark中输入代码时,驱动程序(driver)中的SparkContext将在我们调用Action时创建作业(job)。该作业(job)提交给DAG Scheduler,DAG Scheduler创建操作员图(operator graph),然后将其提交给Task Scheduler。任务计划程序通过集群管理器(cluster manager)启动任务。因此,借助集群管理器,Spark Application在一组计算机上启动。
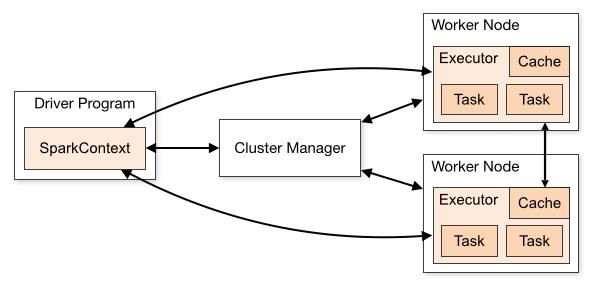
现在,让我们了解下Spark的架构原理。
2. Apache Spark工作原理的内部原理
Apache Spark是一个开放源代码,通用分布式计算引擎,用于处理和分析大量数据。就像Hadoop MapReduce一样,它也可以与系统一起在整个群集中分发数据并并行处理数据。Spark使用主/从体系结构,即一个中央协调员(driver)和许多不同节点的workers。在这里,中央协调员称为驱动程序(driver)。
驱动程序(driver)在其自己的Java进程中运行。这些驱动程序与可能称为executor的大量分布式executors进行通信。每个执行程序都是一个单独的java进程。一个Spark应用是驱动程序(driver)和其拥有的executors的组合。在集群管理器的帮助下,Spark Application在一组计算机上启动。Standalone cluster manager是Spark的默认内置cluster manager。除了内置的群集管理器外,Spark还可以与某些开源群集管理器(如Hadoop Yarn,Apache Mesos等)一起使用。
Spark的术语
- Apache SparkContext
SparkContext是Spark应用程序的核心。它建立与Spark执行环境的连接。它用于创建Spark RDD,累加器(accumulators)和广播变量(broadcast),访问Spark服务并运行作业(jobs)。SparkContext是Spark执行环境的客户端,并充当Spark应用程序的主要部分。Spark Context的主要工作是:
- 获取Spark应用程序的当前状态
- 取消工作
- 取消Stage(一个阶段)
- 同步运行job
- 异步运行job
- 访问持久化的RDD
- 释放一个持久化的RDD
- 可编程动态资源分配
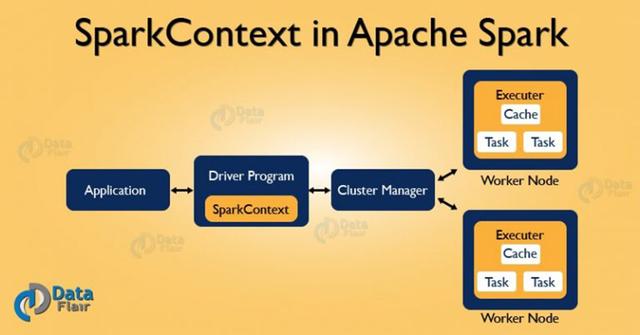
- Apache Spark Shell
Spark Shell是用Scala编写的Spark应用程序。它提供具有自动完成功能的命令行环境。它有助于我们熟悉Spark的功能,这些功能有助于开发自己的独立Spark应用程序。因此,该工具有助于了解Spark,也是Spark之所以在处理各种大小的数据集方面如此有用的原因。
$spark-shell --master yarn --num-executors 3 --executor-cores 2 --executor-memory 500M- Spark Application
Spark应用程序是一个独立的计算,可以运行用户提供的代码来计算结果。即使没有运行作业(job),Spark应用程序也可以代表其运行进程。
- 任务(Task)
一个任务是被发送到执行程序(executor)的工作单元。每个阶段都有一个任务,每个分区分配一个任务。同一任务是在RDD的不同分区上完成的。
- 作业(Job)
Job是并行计算的单元,由多个任务组成,这些任务是响应Apache Spark中的Actoion而产生的。
- 任务阶段(Stage)每个Job都分成一些较小的任务集,称为 相互依赖的 阶段(Stage)。Stage被分类为计算边界。不能在单个Stage中完成所有计算。Job通过许多个阶段(Stage)来完成。
Spark运行时架构的组件
- Apache Spark驱动(Driver)
该程序的main()方法在驱动程序(Driver)中运行。驱动程序(Driver)是运行用户代码的过程,该用户代码创建RDD,执行转换(transformation)和操作(action)以及创建SparkContext。启动Spark Shell时,这表示我们已经创建了驱动程序(Driver)。在驱动程序终止时,应用程序将结束。
驱动程序(Driver)将Spark应用程序拆分为Task,并安排它们在Executors上运行。任务计划程序驻留在驱动程序中,并在executors之间分配任务。驱动程序(Driver)的两个主要关键角色是:
- 将用户程序转换为任务(task)。
- 在执行程序(executor)上调度任务(task)。
Spark程序的高层结构是:RDD由一些输入数据源组成,使用各种转换(transformations)从现有RDD派生出新的RDD,然后在执行Action来计算数据之后。在Spark程序中,操作的DAG(有向无环图)是隐式创建的。当驱动程序运行时,它将Spark DAG转换为物理执行计划。
- Apache Spark集群管理器
Spark依靠群集管理器来启动执行程序,在某些情况下,甚至驱动程序也可以通过它启动。它是Spark中的可插入组件。在集群管理器上,Spark Scheduler以FIFO方式在Spark应用程序中调度作业和操作。可替代地,调度也可以以循环方式进行。Spark应用程序使用的资源可以根据工作负载动态调整。因此,应用程序可以释放未使用的资源,并在有需求时再次请求它们。在所有粗粒度群集管理器(即独立模式,YARN模式和Mesos粗粒度模式)上均可用。
- Apache Spark执行器
给定Spark作业中的单个任务在Spark执行程序中运行。执行程序在Spark应用程序的开头启动一次,然后在应用程序的整个生命周期内运行。即使Spark执行程序失败,Spark应用程序也可以轻松继续。执行者有两个主要角色:
- 运行组成应用程序的任务,并将结果返回给驱动程序。
- 为用户缓存的RDD 提供内存存储(cache ,persist)。
5.如何在Spark中启动程序?尽管使用了任何集群管理器,Spark都具有单个脚本的功能,该脚本可用于提交程序,称为spark-submit。它在集群上启动应用程序。通过各种方式,spark-submit可以连接到不同的集群管理器并控制应用程序获得多少资源。对于某些群集管理器,spark-submit可以在群集内运行驱动程序(例如,在YARN工作节点上),而对于其他群集管理器,它只能在本地计算机上运行。
6.如何在集群上运行Apache Spark应用程序
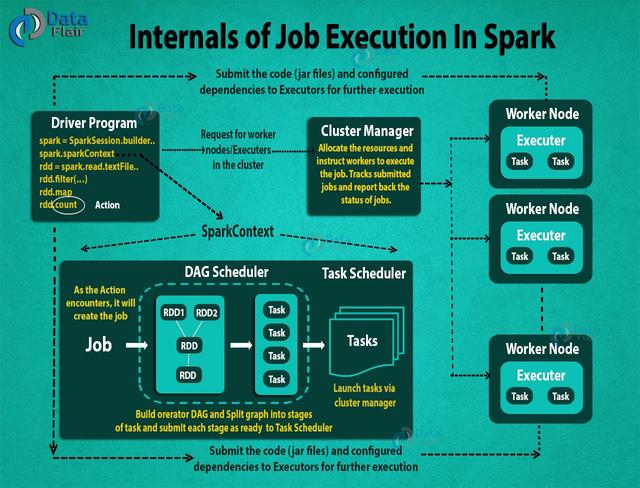
Apache Spark作业执行流程的完整图片。
- 使用spark-submit,用户提交Spark应用。
- 在spark-submit中,我们调用用户指定的main()方法。它还会启动驱动程序(driver)。
- 驱动程序(driver)向集群管理器(yarn or mesos)请求启动执行器所需的资源。
- 集群管理器代表驱动程序启动执行程序。
- 驱动程序进程(driver)在用户应用程序的帮助下运行。根据RDD上的动作(actions)和转换(transformation),驱动程序(driver)以任务(tasks)形式将工作发送给执行者(executors)。
- 执行者(executors)处理任务(task),结果通过集群管理器发送回驱动程序(driver)。
Spark-WebUI
Spark-UI是一个图形化的web工具,帮助理解代码执行流程以及完成特定作业所花费的时间。可视化有助于发现执行过程中发生的任何潜在问题,并进一步优化spark应用程序。
以上就是Apache Spark的工作方式。
如果发现任何不正确的地方,或者想分享有关上述主题的更多信息,欢迎反馈。



















![[Sdoi2010] 地精部落](http://pic.xiahunao.cn/[Sdoi2010] 地精部落)