
 作者:louwill;转载自:机器学习实验室
作者:louwill;转载自:机器学习实验室
from sklearn import preprocessingle = preprocessing.LabelEncoder()le.fit(['undergraduate', 'master', 'PhD', 'Postdoc'])le.transform(['undergraduate', 'master', 'PhD', 'Postdoc'])array([3, 2, 0, 1], dtype=int64)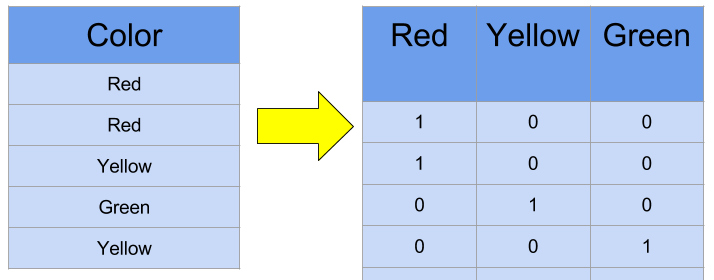 对于类别特征内部取值不存在明显的内在顺序时,即直接的硬编码不适用时,One-hot编码的作用就凸显出来了。但当类别特征取值过多时,One-hot编码很容易造成维度灾难,特别是对于文本类的特征,如果使用One-hot编码对其进行编码,基本上都是茫茫零海。所以,在类别特征取值无序,且特征取值数量少于5个时,可使用One-hot方法进行类别编码。有朋友可能会问,一定得是5个吗,6个行不行,当然也可以,这里并没有固定标准,但差不多就是这个数据左右。数量再多就不建议使用One-hot了。Pandas和Sklearn都提供了One-hot编码的实现方式,示例代码如下。
对于类别特征内部取值不存在明显的内在顺序时,即直接的硬编码不适用时,One-hot编码的作用就凸显出来了。但当类别特征取值过多时,One-hot编码很容易造成维度灾难,特别是对于文本类的特征,如果使用One-hot编码对其进行编码,基本上都是茫茫零海。所以,在类别特征取值无序,且特征取值数量少于5个时,可使用One-hot方法进行类别编码。有朋友可能会问,一定得是5个吗,6个行不行,当然也可以,这里并没有固定标准,但差不多就是这个数据左右。数量再多就不建议使用One-hot了。Pandas和Sklearn都提供了One-hot编码的实现方式,示例代码如下。import pandas as pddf = pd.DataFrame({'f1':['A','B','C'], 'f2':['Male','Female','Male']})df = pd.get_dummies(df, columns=['f1', 'f2'])df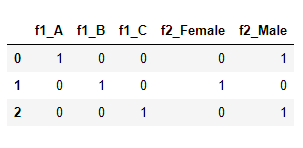
from sklearn.preprocessing import OneHotEncoderenc = OneHotEncoder(handle_unknown='ignore')X = [['Male', 1], ['Female', 3], ['Female', 2]]enc.fit(X)enc.transform([['Female', 1], ['Male', 4]]).toarray()array([[1., 0., 1., 0., 0.],[0., 1., 0., 0., 0.]])### 该代码来自知乎专栏:### https://zhuanlan.zhihu.com/p/40231966from sklearn.model_selection import KFoldn_folds = 20n_inner_folds = 10likelihood_encoded = pd.Series()likelihood_coding_map = {}# global prior meanoof_default_mean = train[target].mean() kf = KFold(n_splits=n_folds, shuffle=True)oof_mean_cv = pd.DataFrame()split = 0for infold, oof in kf.split(train[feature]):print ('==============level 1 encoding..., fold %s ============' % split)inner_kf = KFold(n_splits=n_inner_folds, shuffle=True)inner_oof_default_mean = train.iloc[infold][target].mean()inner_split = 0inner_oof_mean_cv = pd.DataFrame()likelihood_encoded_cv = pd.Series()for inner_infold, inner_oof in inner_kf.split(train.iloc[infold]):print ('==============level 2 encoding..., inner fold %s ============' % inner_split) # inner out of fold meanoof_mean = train.iloc[inner_infold].groupby(by=feature)[target].mean() # assign oof_mean to the infoldlikelihood_encoded_cv = likelihood_encoded_cv.append(train.iloc[infold].apply(lambda x : oof_mean[x[feature]]if x[feature] in oof_mean.indexelse inner_oof_default_mean, axis = 1))inner_oof_mean_cv = inner_oof_mean_cv.join(pd.DataFrame(oof_mean), rsuffix=inner_split, how='outer')inner_oof_mean_cv.fillna(inner_oof_default_mean, inplace=True)inner_split += 1oof_mean_cv = oof_mean_cv.join(pd.DataFrame(inner_oof_mean_cv), rsuffix=split, how='outer')oof_mean_cv.fillna(value=oof_default_mean, inplace=True)split += 1print ('============final mapping...===========')likelihood_encoded = likelihood_encoded.append(train.iloc[oof].apply(lambda x: np.mean(inner_oof_mean_cv.loc[x[feature]].values)if x[feature] in inner_oof_mean_cv.indexelse oof_default_mean, axis=1))lgb_train = lgb.Dataset(train2[features], train2['total_cost'], categorical_feature=['sex'])Label Encoding
类别特征内部有序
One-hot Encoding
类别特征内部无序
类别数值<5
Target Encoding
类别特征内部无序
类别数值>5
模型自动编码
LightGBM
CatBoost
排版:喵君姐姐
转载自:机器学习实验室

 行上行下 | 编程相关推文汇总心理学实验常用编程软件和学习资源汇总认知神经科学 | 脑电信号处理的机器学习机器学习: 心理学&管理学研究的新篇章?
行上行下 | 编程相关推文汇总心理学实验常用编程软件和学习资源汇总认知神经科学 | 脑电信号处理的机器学习机器学习: 心理学&管理学研究的新篇章?因为微信更改了推送规则,如果不想错过我们的精彩内容,请点『在看』以及星标⭐我们呦!



 指令实现 jmp from ring0 to ring3))


的轮流执行事件监听器功能被舍弃掉了)
 + 返回(ret) })

![日志服务器搭建及配置_[ELK入门到实践笔记] 一、通过rsyslog搭建集中日志服务器...](http://pic.xiahunao.cn/日志服务器搭建及配置_[ELK入门到实践笔记] 一、通过rsyslog搭建集中日志服务器...)
调用事件监听器(事件处理函数/事件处理程序/事件监听函数)时如何传递参数)









