DDD中的聚合模式是最难弄清楚的一种模式,在如何确定聚合边界这个问题上,更没有一个明确的指导原则,这导致DDD的落地比较难。不过,相信你读了这篇文章应该对聚合会有更深刻的理解。
本文分三部分来讲:
1、什么是聚合?
2、聚合解决了什么问题?
3、聚合的边界划分指导原则
1. 什么是聚合?
首先我们来看下聚合模式的定义:
将实体和值对象划分为聚合并围绕着聚合定义边界。选择一个实体作为每个聚合的根,并仅允许外部对象持有对聚合根的引用。作为一个整体来定义聚合的属性和不变量,并把其执行责任赋予聚合根或指定的框架机制。
这是典型的“模式语言”,说明了聚合是什么,聚合根(aggregation root)是什么,以及如何使用聚合。
但是,模式语言的问题在于过度精炼,对于还不熟悉这些模式的人,根本不知所云。为了能深入理解聚合模式的本质,我们还是要一步步回到聚合试图解决的问题上来。
2.聚合解决了什么问题?
我们先从一个问题域开始,拿大家都能理解的企业采购系统来举例:
- 提交人通过采购系统提交一个采购申请,采购申请中包含了本次要采购的若干办公用品(称为采购项)和对应的数量
- 主管对采购申请进行审批
- 审批通过后,生成订单发送到供应商出货
要设计这样的一个采购系统,不同人有不同的方法。
2.1 面向数据库设计
我见过大部分人首先想到的是库表结构的设计,也就是面向数据库编程。大部分人都能够设计出如下的几张表,如下图所示:
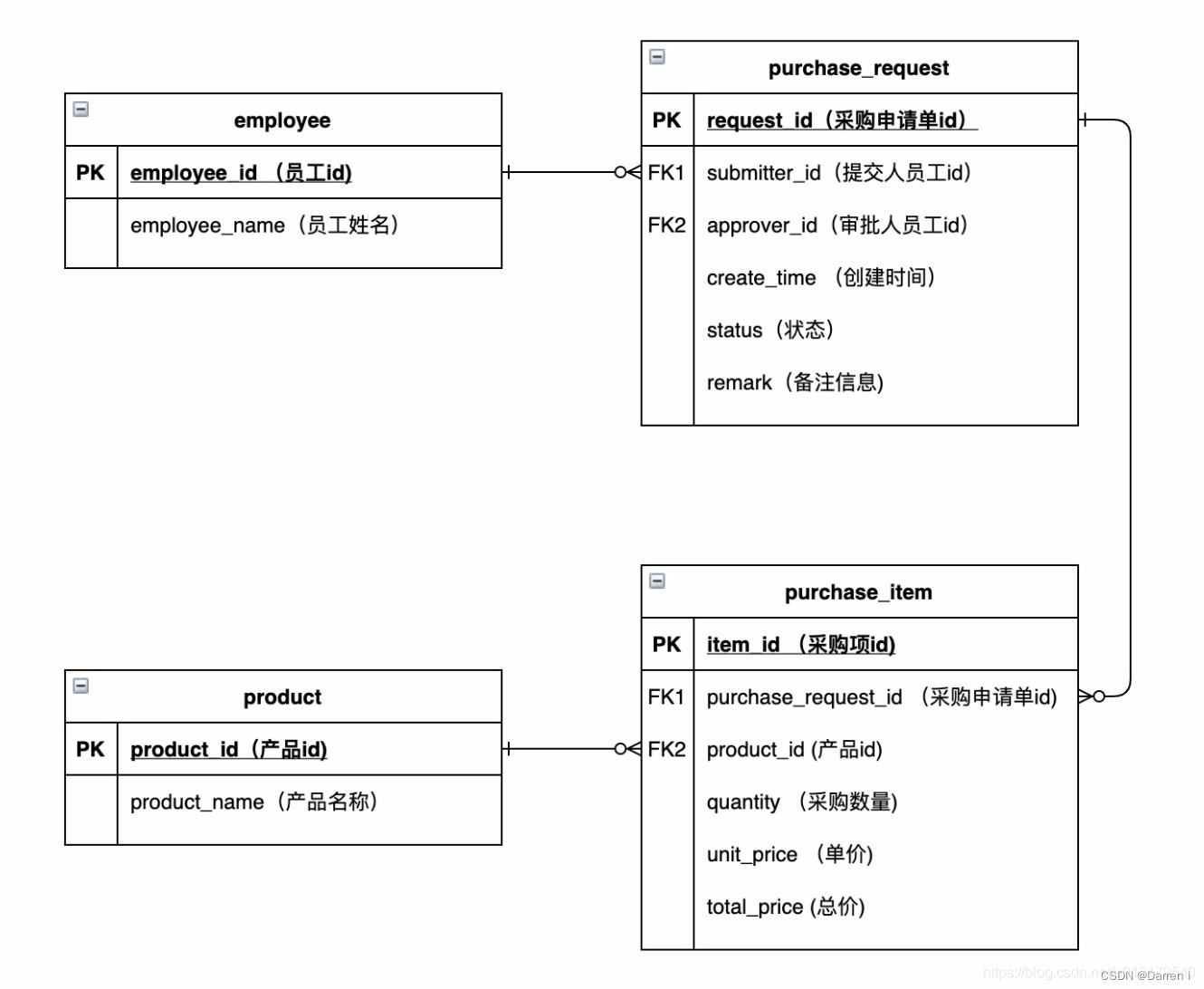
可能你会问,面向数据库的设计有什么问题呢?我一直都是这么做的啊!你一直这么做并不代表你的方法就是最合理的。
为了能够保证业务规则的正确性和数据一致性,在上面的采购系统中,我们需要考虑如下几个问题:
- 如果采购请求被删除,则和该采购请求相关的采购项是不是都应该被删除呢?
- 如果你的主管正在对采购申请进行审批,而你又同时在修改采购申请中的采购项,那该如何进行并发处理呢?如果设计不当,要么你主管审批的就是过期的数据,要么你更新采购项会失败。
- 虽然上面的问题都有对应的技术解决办法,但是过早地陷入到技术细节的讨论中,会让我们错失和业务专家充分讨论的机会,而很多业务隐含的概念是在和业务专家协作过程中显现的;同时技术复杂性和业务复杂性混合在一起,让我们顾此失彼。
总之,在简单的场景下,采用面向数据库的设计简单直接,能快速实现需求。但是在较复杂的业务场景下,如果一上来就在数据库这么低的层次上考虑问题,我们会花大量的时间在表结构的设计上,而没有重视对重要的业务规则的梳理。随着业务的快速发展,由于我们最初设计考虑不当,我们会疲于应付不断出现的新需求和bug,我们会陷入沉重的泥潭,最后系统只能推倒重来。
那我们有没有一种方法能够让我们聚焦于问题领域,而不是过早地陷入到技术细节中呢?答案就是:面向对象设计
2.2 面向对象设计
面向对象设计有助于我们提高抽象的层级,在面向对象的世界中,我们看到的结构是这样的:
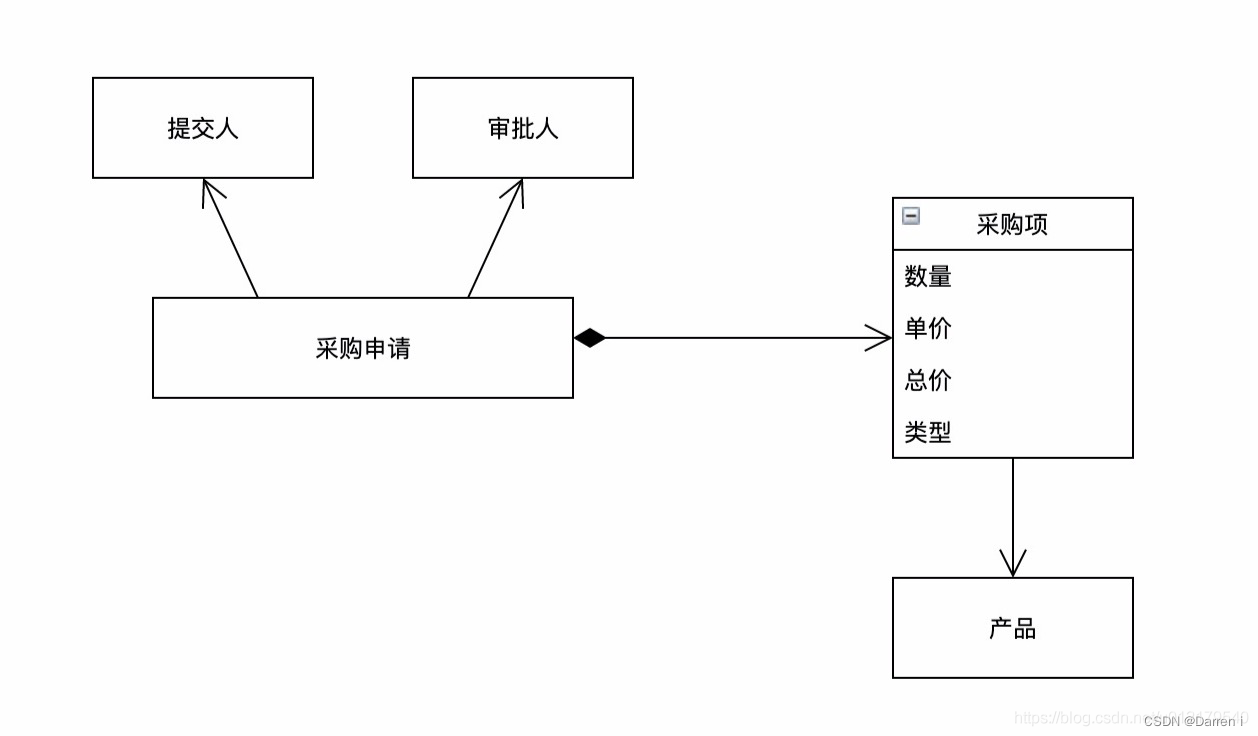
面向对象的设计方法提高了抽象层级,忽略一些不必要的技术细节(例如不用再关心表的外键、表的关联关系等技术细节了),让我们能够更加专注地聚焦到问题领域,同时业务人员也能够看懂,技术和业务专家也能够基于统一语言进行持续的交流协作。
但是,业务规则如何保证?在传统的面向对象的设计中,并没有很好的方法能够对业务规则进行约束。例如:
从业务规则上来看,当采购申请审批通过了,就不允许申请者再对采购申请中的采购项进行修改。但是在面向对象的设计中,你没法阻止程序员写出如下的代码:
PurchaseRequest purchaseRequest = getPurchaseRequest(requestId);
PurchaseItem item = purchaseRequest.getItem(itemId);
item.setQuantity(1000);
savePurchaseItem(item);
语句1取得了采购申请的实例,语句2获取了该采购申请中的一个采购项,语句3,4对采购项的数量进行修改并保存。如果该采购申请已经审批通过了,那这种修改就违背了业务规则。
可能你会说在修改之前,我先对purchaseRequest的状态进行校验,如果状态是已审批通过,就不允许修改。加上校验的代码如下:
PurchaseRequest purchaseRequest = getPurchaseRequest(requestId);
PurchaseItem item = purchaseRequest.getItem(itemId);
if (purchaseRequest.status == "HAS_APPROVED") {throw new BizException("采购申请已审批通过,不允许对采购进行修改")
}item.setQuantity(1000);
savePurchaseItem(item);
但是PurchaseItem在任何地方都能够被提取出来,并且PurchaseItem对象可以在方法间进行传递。
要满足上述的业务规则,你需要在每个对PurchaseItem修改的地方加上上面这段校验代码。如果设计不当,那这段校验逻辑就会散落在各个地方,未来要修改这段校验逻辑,你需要找出散落的每个地方进行修改,这成本可想而知。
没有设计上的约束,那要保证业务规则的正确性并不是一件很容易的事。
2.3 面向DDD的设计
让我们回到本质问题:采购项脱离了采购申请有单独存在的价值吗?
答案显然是没有什么卵用。既然采购项没有单独存在的价值,那对采购项的修改本质上是不是对采购申请的修改?
如果我们认同:‘对采购项的修改就是对采购申请的修改’这个结论,那我们就不应该将采购项和采购申请分开来看待,而应该如下图所示:
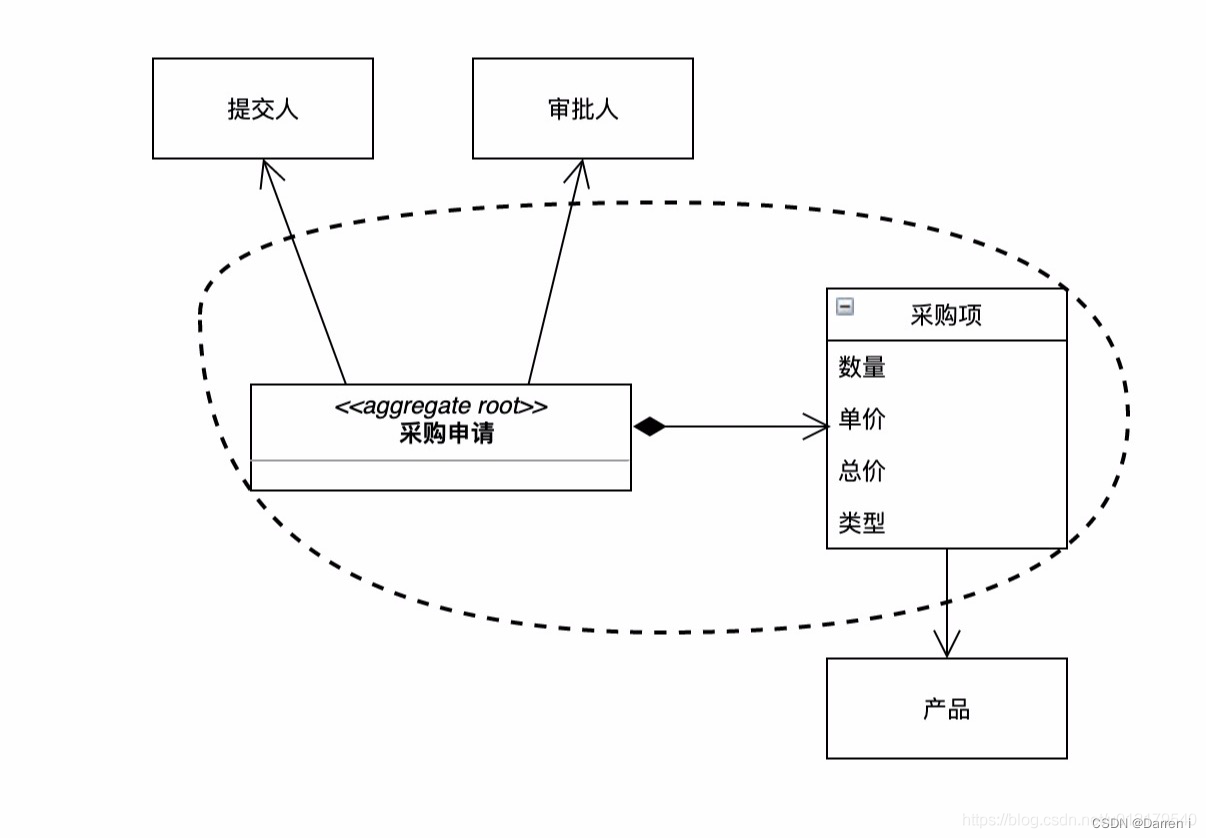
我们把“采购申请”和“采购项”看做是一个整体,这个比对象更大粒度的整体就称为“聚合”。(讲了这么多,终于看到聚合两个字了)
这个聚合内部的业务逻辑,例如“采购申请审批通过后,不得对采购项进行修改”,应该内建于聚合内部。为了实现这一目标,我们约定:一切对采购项的操作(增删改查),都是对采购请求对象的操作。
也就是说,在代码中从来就不应该出现savePurchaseItem()这种方法,应该用purchaseRequest.modifyPurchaseItem()和purchaseRequest.savePurchaseItem()方法代替。
现在对purchaseItem的访问必须通过purchaseRequest对象,purchaseRequest对象作为访问聚合的入口,称为“聚合根”(又是一个重要的概念)。由于聚合是一个整体,对聚合的任何操作只能通过聚合根来进行,从而业务规则在聚合内部得到了保证。
读到这里大家大致明白聚合是什么了吧。
聚合的本质就是建立了比对象粒度更大的边界,聚合了那些紧密联系的对象,形成了一个业务上的整体。使用聚合根作为对外交互的入口,从而保证了多个互相关联的对象的一致性。
3.聚合的边界划分原则
虽然到目前我们大致理解了聚合模式的概念以及聚合模式解决的问题,但聚合的边界又该如何划分呢?可能有的人会问:
既然采购项是采购申请这个聚合的一部分,那产品是不是也是该聚合的一部分?如果说是为了业务规则得到保证,那审批人、提交人都放到采购申请这个聚合岂不是更好?
哪些对象该属于为一个聚合?哪些对象不属于一个聚合?也就是聚合边界的划分问题,有没有一个可指导的原则呢?
当然有。聚合边界的划分可以参考如下几个指导原则:
1、生命周期一致性原则
2、问题域一致性原则
3、场景一致性原则
4、聚合应尽可能地小
3.1 生命周期一致性原则
生命周期一致性是指聚合内部的对象,应该和聚合根具有相同的生命周期,聚合根消失,则聚合内部的所有对象都应该一起消失。
例如,在上面的例子中,聚合根采购请求被删除,那采购项也就没有存在的意义,但是申请人、审批人、产品和采购申请却不存在该关系。
如果违反生命周期一致性原则,会带来比较严重的后果。假如提交人也是采购申请这个聚合中的对象,代码如下:
public class PurchaseRequest {private Set<PurchaseItem> items;private User submitter;...
}
其中User对象的生命周期和PurchaseRequest对象的生命周期不一致。
那么当保存采购申请对象时,也会保存User对象的信息,代码如下:
r = purchaseRequestRepository.findOne(id);
//...一些修改
purchaseRequestRepository.save(r);
同时员工管理员也可以对同一个User对象进行修改,代码如下:
User user = userRepo.findOne(r.getSubmitter().getId());
//...一些修改
userRepo.save(user);
这将导致严重的后果:对于User对象的修改不确定性!
因此如果不确定是否应该将某个对象划入某个聚合,你不妨问下:
这个对象离开了这个聚合,是不是还有存在的价值?如果这个对象离开了这个聚合有单独存在的意义,那就不应该就它划入这个聚合。
回到上面那个例子:
- Submitter/Approver 对应的 User 对象脱离了 PurchaseRequest,仍然有单独存在的价值;
- Product 对象脱离了 PurchaseRequest,是可以单独存在的;
所以以上两个对象都不属于采购申请这个聚合。
3.2 问题域一致性原则
上面的生命周期一致性只是指导原则之一,有时如果只考虑生命周期一致性原则可能会引起问题。
让我们考虑一个在线论坛这样的场景:
一个在线论坛,用户可以对论坛上用户的文章发表评论。文章显然应该是一个聚合根。如果文章被删除,那么,用户的评论看起来也要同时消失。那么评论是否可以属于文章这个聚合?
现在让我们来考虑评论是否还有其他用处。
例如,用户可以对用户的文章发表评论,同时也可以对该论坛的电子图书发表评论。如果只是因为文章和评论之间存在逻辑上的关联,就让文章聚合持有评论对象,那么显然就约束了评论的适用范围。所以,我们得到了一个新的、凌驾于原则1之上的原则——不属于同一个问题域的对象,不应该出现在同一个聚合中。
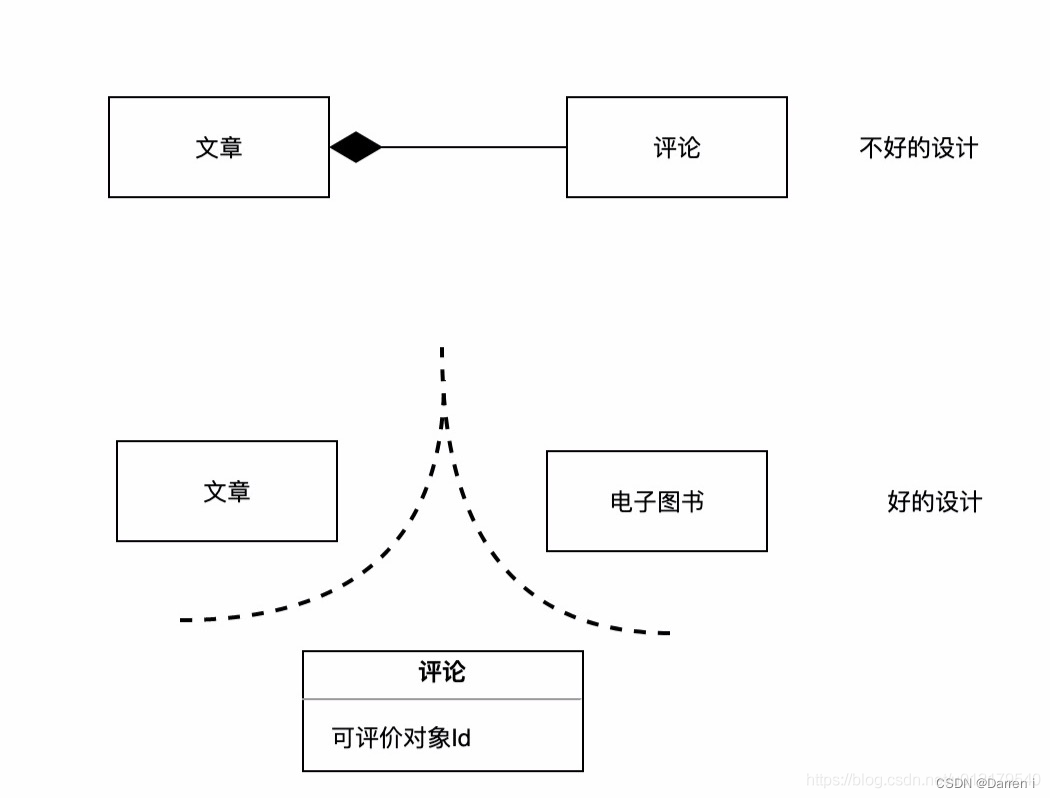
在上图中评论这聚合根可以持有其他聚合根的id(可评价对象id), 同时聚合之间的一致性通过最终一致性来保证(文章删除发送领域事件通知删除对应的评论)。
3.3 场景一致性原则
通过上面两个原则,我们基本能够划分清楚一个聚合的边界,但是仍然会存在一些复杂的情况。这时我们可以根据第三个原则来判断:场景一致性原则。
什么是场景一致性呢?场景一致性就是场景操作频率的一致性。
在很多业务场景中,我们会对领域对象进行查看、修改等各种操作。 经常被同时操作的对象,应该属于同一个聚合,而那些极少被同时关注的对象,即使上面两个原则都满足也不应该划为一个聚合。
不在同一个场景下操作的对象,放入同一个聚合意味着每次操作一个对象,就需要把其他对象的所有信息抓取到,这是非常没有意义的。这在日常开发中我也是深有体会。
从实现层次,如果不紧密相关的对象出现在同一个聚合中,会导致它们经常在不同的场景中被并发修改,也增加了这些对象之间冲突的可能性。
所以:大多数时候的操作场景都不一致的对象,应该把它们分到不同的聚合中
3.4 聚合应尽可能地小
在划分聚合时,除了应该满足上面三个指导原则外,我们还应该让我们的聚合尽可能地小。
通常,较小的聚合会让一个系统变得更快和更可靠,因为会传输较小的数据并且引发并发冲突的概率会较小。而设计一个大的聚合会带来各种问题:
-
大聚合会降低性能
聚合中的每个成员会增加数据的量,当这些数据需要从数据库中进行加载的时候,大聚合会增加额外的查询,导致性能降低 -
大聚合更容易受到并发冲突的影响
大聚合可能包含了很多职责,这意味着它要参与多个业务用例。随之而来的就是,有很大可能出现多个用户对单个聚合进行变更的情况,从而导致了严重的并发冲突,影响了程序的可用性和用户体验 -
大聚合扩展性差
大聚合意味着与更多的模型产生依赖关系,这会导致重构和扩展的难度增加。
原文链接
https://blog.csdn.net/u012179540/article/details/115152804
部署 Spring Boot 到远程 Docker 容器)
)







与Object.equals())
 VS (for…of))


如何保障微服务架构下的数据一致性?)

漫画:什么是分布式事务?)


web.xml 中的listener、 filter、servlet 加载顺序及其详解)
