一、计数器(固定窗口)算法
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。
此算法在单机还是分布式环境下实现都非常简单,使用redis的incr原子自增性和线程安全即可轻松实现。
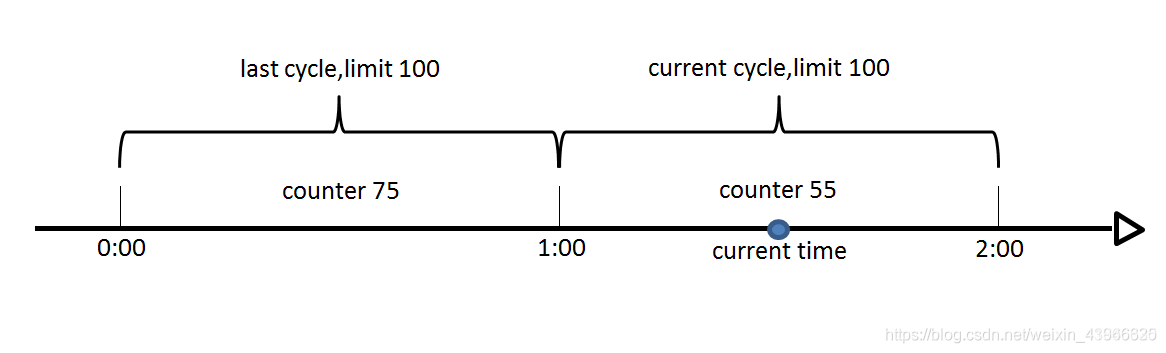
计数器算法对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题,如下图:
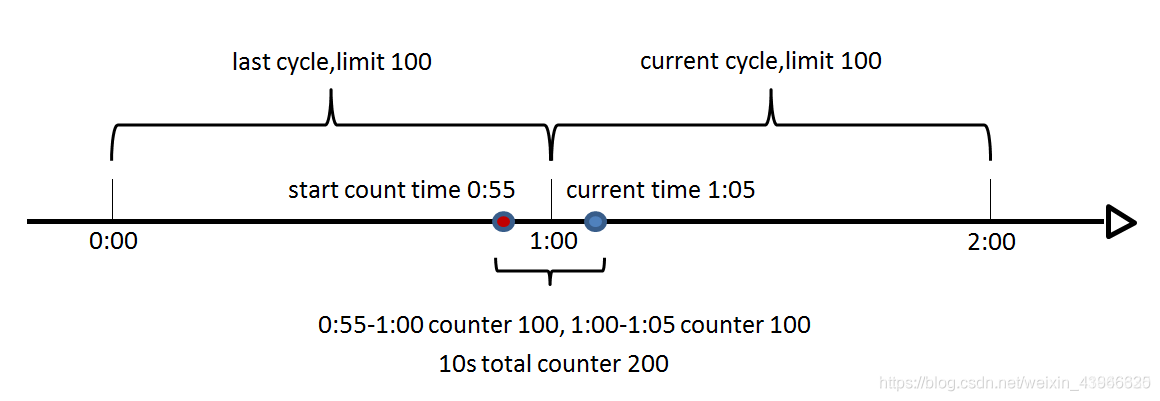
假设1min内服务器的负载能力为100,因此一个周期的访问量限制在100,然而在第一个周期的最后5秒和下一个周期的开始5秒时间段内,分别涌入100的访问量,虽然没有超过每个周期的限制量,但是整体上10秒内已达到200的访问量,已远远超过服务器的负载能力,由此可见,计数器算法方式限流对于周期比较长的限流,存在很大的弊端。
二、滑动窗口
滑动窗口算法是将时间周期分为N个小周期,每个小周期分别记录访问次数,并且根据时间滑动删除过期的小周期,添加新的小周期。小周期的访问次数和的最大值等于限流值。
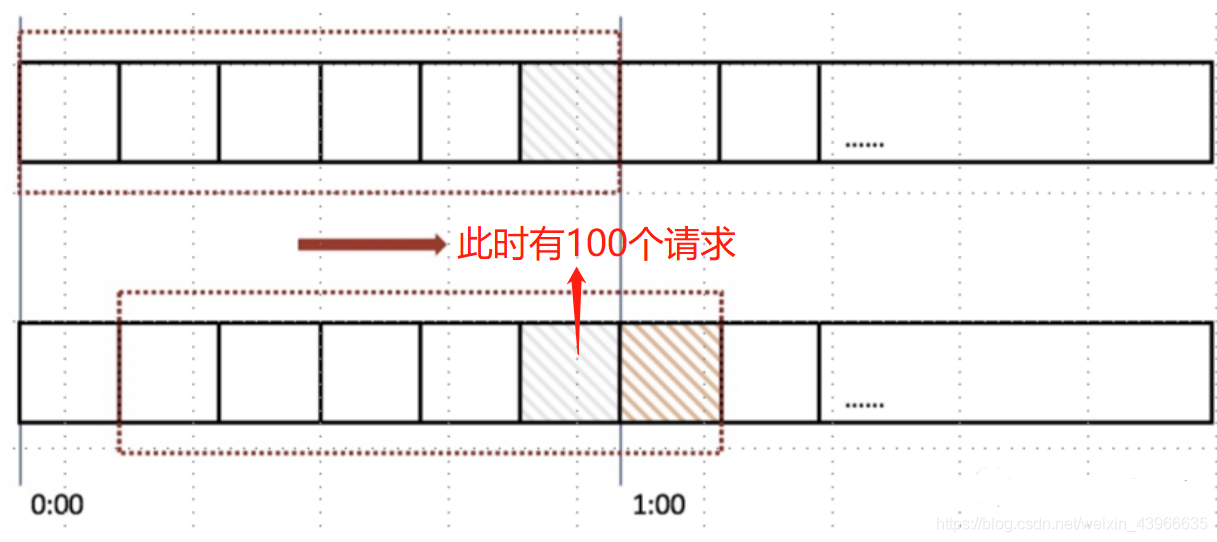
假设1分钟允许100个请求,然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口划成了6格,所以每格代表的是10秒钟。每过10秒钟,我们的时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器counter,比如当一个请求 在0:35秒的时候到达,那么0:30~0:39对应的counter就会加1。
滑动窗口如何解决临界问题:
当最后0:59和1:01都来了100个请求,在0:59所属的周期没有过期前,因为已经达到限流值,因此会出发限流,直到0:59所属的周期过期,才能接受新的请求,解决了临界问题。
回顾一下上面的计数器算法,我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
滑动窗口的缺点
滑动窗口的实现:简单的java实现滑动时间窗口限流算法
单机下可以通过队列实现,分布式下可以通过Redis的 zset 实现。滑动窗口需要记录每个请求的时间戳,因此内存消耗比较大,占用存储空间高,且不能保证请求稳定。
三、漏桶算法
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率,不允许突发流量。
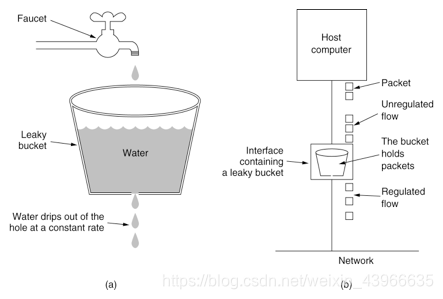
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发流量。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
四、令牌桶
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
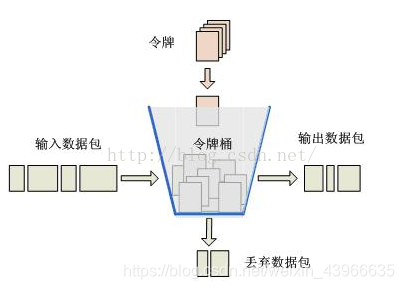
漏桶法和令牌桶的区别
两者主要区别在
- 漏桶算法能够强行限制数据的传输速率
- 令牌桶算法在能够限制数据的平均传输速率外,还允许某种程度的突发传输。在“令牌桶算法”中,只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,所以它适合于具有突发特性的流量。
令牌桶可以用来保护自己,主要用来对调用者频率进行限流,为的是让自己不被打垮。所以如果自己本身有处理能力的时候,如果流量突发(实际消费能力强于配置的流量限制),那么实际处理速率可以超过配置的限制。
漏桶算法,这是用来保护他人,也就是保护他所调用的系统。主要场景是,当调用的第三方系统本身没有保护机制,或者有流量限制的时候,我们的调用速度不能超过他的限制,由于我们不能更改第三方系统,所以只有在主调方控制。这个时候,即使流量突发,也必须舍弃。因为消费能力是第三方决定的。
总结:如果要让自己的系统不被打垮,用令牌桶。如果保证别人的系统不被打垮,用漏桶算法
小结
从上面看来好像漏桶和令牌桶比时间窗口算法好多了,那时间窗口算法有啥子用,扔了扔了?
并不是的,虽然漏桶和令牌桶对比时间窗口对流量的整形效果更佳,流量更加得平滑,但是也有各自的缺点(上面已经提到了一部分)。
拿令牌桶来说,假设你没预热,那是不是上线时候桶里没令牌?没令牌请求过来不就直接拒了么?这就误杀了,明明系统没啥负载现在。
再比如说请求的访问其实是随机的,假设令牌桶每20ms放入一个令牌,桶内初始没令牌,这请求就刚好在第一个20ms内有两个请求,再过20ms里面没请求,其实从40ms来看只有2个请求,应该都放行的,而有一个请求就直接被拒了。这就有可能造成很多请求的误杀,但是如果看监控曲线的话,好像流量很平滑,峰值也控制的很好。
再拿漏桶来说,漏桶中请求是暂时存在桶内的。这其实不符合互联网业务低延迟的要求。
所以漏桶和令牌桶其实比较适合阻塞式限流场景,即没令牌我就等着,这就不会误杀了,而漏桶本就是等着。比较适合后台任务类的限流。而基于时间窗口的限流比较适合对时间敏感的场景,请求过不了您就快点儿告诉我,等的花儿都谢了。
单机限流和分布式限流
本质上单机限流和分布式限流的区别其实就在于 “阈值” 、窗口、漏斗存放的位置。
单机限流就上面所说的算法直接在单台服务器上实现就好了,而往往我们的服务是集群部署的。因此需要多台机器协同提供限流功能。
像上述的计数器或者时间窗口的算法,可以将计数器存放至 Tair 或 Redis 等分布式 K-V 存储中。
例如滑动窗口的每个请求的时间记录可以利用 Redis 的 zset 存储,利用ZREMRANGEBYSCORE 删除时间窗口之外的数据,再用 ZCARD计数。
像令牌桶也可以将令牌数量放到 Redis 中。
不过这样的方式等于每一个请求我们都需要去Redis判断一下能不能通过,在性能上有一定的损耗,所以有个优化点就是 「批量」。例如每次取令牌不是一个一取,而是取一批,不够了再去取一批。这样可以减少对 Redis 的请求。
不过要注意一点,批量获取会导致一定范围内的限流误差。比如你取了 10 个此时不用,等下一秒再用,那同一时刻集群机器总处理量可能会超过阈值。
其实「批量」这个优化点太常见了,不论是 MySQL 的批量刷盘,还是 Kafka 消息的批量发送还是分布式 ID 的高性能发号,都包含了「批量」的思想。
当然分布式限流还有一种思想是平分,假设之前单机限流 500,现在集群部署了 5 台,那就让每台继续限流 500 呗,即在总的入口做总的限流限制,然后每台机子再自己实现限流。
总结
(1)计数器限流算法:简单粗暴但边界值统计不准确(临界问题)
(2)滑动窗口限流算法:统计准确易理解,占用存储空间高,且不能保证请求稳定,适合时间敏感的场景
(3)令牌桶限流算法:相比滑动窗口限流算法占用空间少,可以限制平均流量和流量最大值,适合有突发流量需求的场景。存在误杀的问题,需要预热(启动时先放入一些令牌)。
(4)漏斗限流算法:相比滑动窗口限流算法占用空间少,可以严格限制流量。请求会先放在桶中,不适合低延迟的业务。
参考
- 重点好文:图解+代码|常见限流算法以及限流在单机分布式场景下的思考
- 推荐好文:高并发系统限流-漏桶算法和令牌桶算法
- 好文:大话常用限流算法与应用场景
- 接口限流算法:漏桶算法&令牌桶算法
- 精度不够,滑动时间来凑「限流算法第二把法器:滑动时间窗口算法」- 第301篇
- 限流的算法有哪些?



与Object.equals())
 VS (for…of))


如何保障微服务架构下的数据一致性?)

漫画:什么是分布式事务?)


web.xml 中的listener、 filter、servlet 加载顺序及其详解)


)



