事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过日志实现。Mysql的日志可以分为:
- binlog:server层实现
- 事务日志:包括redo log、undo log,引擎层(innodb)实现
redo log
redo log是用于备份事务中操作得到的最新数据的地方,记录数据页的物理修改。
redo log通常是物理日志,记录的是数据页的物理修改,而不是记录某一行或某几行的修改,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
在innoDB的存储引擎中,事务日志通过重做日志(redo log)和innoDB存储引擎的日志缓冲(redo Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
即事务在修改数据时,innodb只修改数据的内存拷贝,然后把修改行为记录到持久在磁盘的事务日志(redo log)中,在事务日志持久化后,内存中被修改的数据在后台慢慢刷回磁盘。
即修改数据时需要写两次磁盘:
- 先将操作记录到redo log buffer,然后持久化redo log到磁盘
- 将redo log中记录的数据持久化到磁盘
为什么需要redo log(为什么采用两次写磁盘,而不直接持久化新数据?)
既然redo log是将数据持久化到磁盘上,那么必然也对应一次IO操作,那么每次修改数据直接将其刷新到磁盘的话,也是一次IO操作,按道理说效率应该一样,那么为什么还要引入redo log?
事实上,redo log写入文件尾是顺序写过程,虽然也是一次IO操作但磁头不需要移动(即事务日志采用追加的方式,因此是顺序IO)。而每次都将数据更新到磁盘其实是将 buffer pool中的数据缓存页写入磁盘的数据也中,其中涉及到要寻找数据页在哪的操作,这是一个随机写过程,需要移动磁头,磁盘的随机写过程更耗时,耗资源,因此引入redo log是很有必要的。
undo log
undo log是用于事务中,在操作数据之前,备份需操作的数据的地方,undo log 记录数据的逻辑修改。
undo log用来实现事务的原子性,在innodb引擎中还用来实现事务的多版本并发控制。
undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
即在操作数据库之前先将数据备份到一个地方,这个存储数据备份的地方就是undo log。然后再进行数据的修改,如果中途发生错误或者用户执行的rollback语句,系统就可以利用undo log中的备份将数据回复到事务开始前的状态。
undo log 是逻辑日志,可以理解为每次操作之前都会记录相反反操作:
- 当delect一条语句时,undo log 中会记录一条对应的insert语句
- 当insert一条语句时,undo log 中会记录一条对应的delect语句
- 当update一条语句时,undo log 中会记录一条相反的update语句
undo+redo事务的简化过程
假设有2个数值,分别为A和B,值为1,2
1. start transaction;2. 记录 A=1 到undo log;3. update A = 3;4. 记录 A=3 到redo log buffer;5. 记录 B=2 到undo log;6. update B = 4;7. 记录B = 4 到redo log buffer;8. 将redo log buffer 刷新到磁盘9. 执行器(Server层)生成写操作的binlog日志,并将binlog写入磁盘(通过XA事务保证redo log 和 binlog的一致性)10. commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-10之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在10之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。
所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。
binlog
binlog是server层的日志,记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。
当执行写操作的SQL(INSERT、UPDATE、DELETE…)时,会把相应的SQL写入到对应的binlog,可以简单理解为binlog是记录数据库增删改,不记录查询的二进制日志,可以利用binlog进行备份、数据恢复。
binlog的三种模式
(1)Row Level 行模式
日志中会记录每一行数据被修改的形式,然后在slave端再对相同的数据进行修改
- 优点:在row level模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条被修改。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。不会出现某些特定的情况下的存储过程或function,以及trigger的调用和触发无法被正确复制的问题
- 缺点:row level,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,会产生大量的日志内容。
(2)Statement Level(默认)
每一条会修改数据的sql都会记录到master的bin-log中。slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行
- 优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约IO,提高性能,因为它只需要在Master上锁执行的语句的细节,以及执行语句的上下文的信息。
- 缺点:由于只记录语句,所以,在statement level下 已经发现了有不少情况会造成Mysql的复制出现问题,主要是修改数据的时候使用了某些定的函数或者功能的时候会出现。
(3) Mixed 自动模式
在Mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志格式,也就是在Statement和Row之间选择一种。如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
binlog与redolog 的区别
- binlog主要用于备份、主从同步;redo log用于实现事务的一致性和持久性,防止数据丢失。
- redo log 是innodb引擎特有的,而binlog由服务层实现是所有存储引擎都可以使用的
- redo log是物理日志,记录的是某页上具体的做的修改。binlog是逻辑日志,记录的是这个语句的原始逻辑。
- redo log是循环写过程,空间有限,空间不够时会覆盖之前的信息。binlog是追加写过程不会覆盖之前的信息。
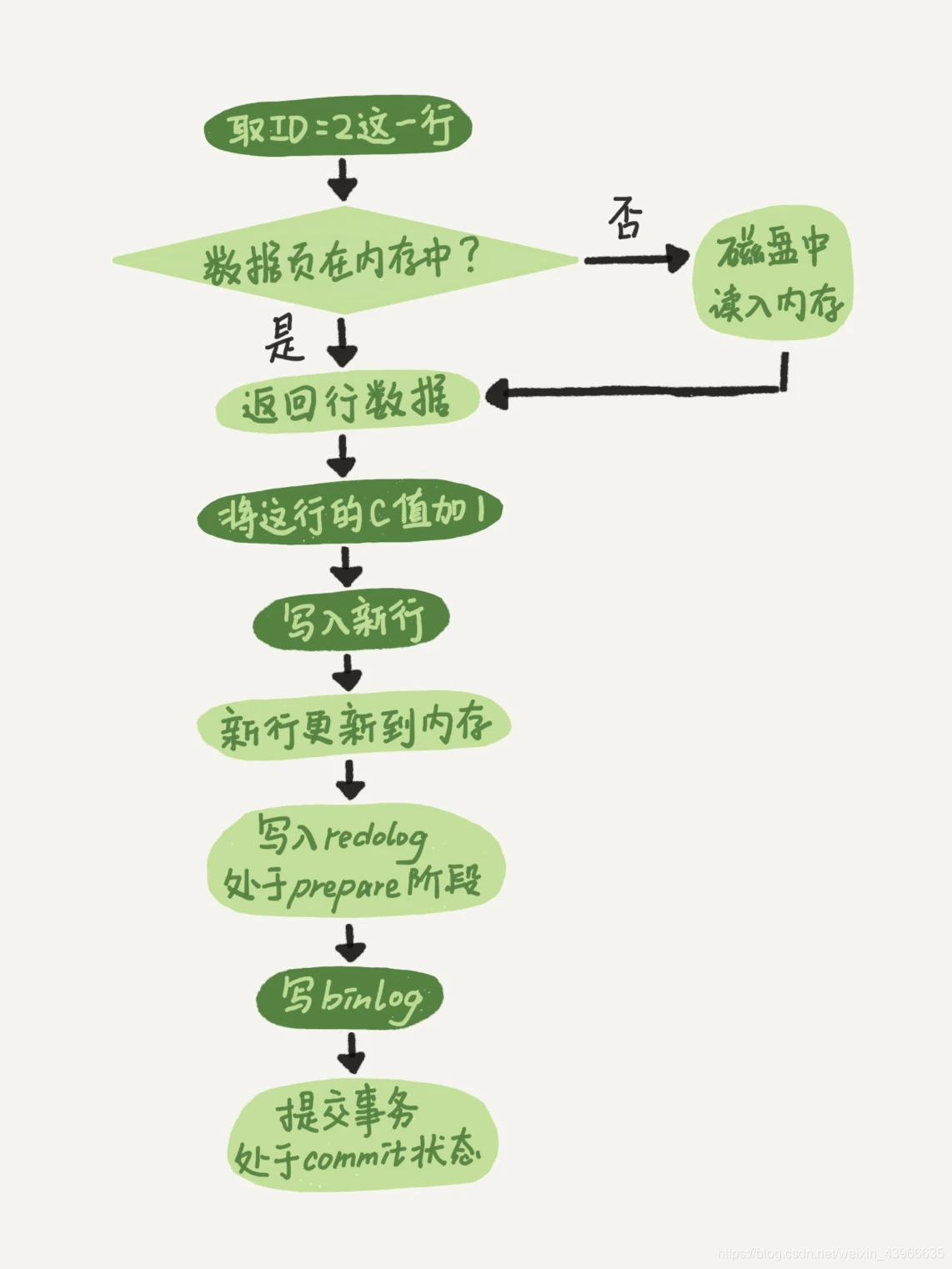
执行器(Server)和InnoDB引擎在执行update内部流程
1、执行器先找到ID=2这一行,ID是主键,引擎用树搜索找到这一行,如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器。否则需要从磁盘中读入磁盘中,然后再返回。
2、执行器拿到引擎给的行数据,把这个值加上1,得到一行新的数据,再调用引擎接口,写入这行数据。
3、引擎将这行新的数据写入到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态,然后告知执行器执行完成了,随时可以提交事务。
4、执行器生成这个操作的binlog日志,并将binlog写入磁盘。
5、执行器调用引擎的提交事务的接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
binlog 和 redo log一致性
此部分为引用,详细请阅读:MySQL中binlog和redo log的一致性问题
在MySQL内部,在事务提交时利用两阶段提交(内部XA的两阶段提交)很好地解决了binlog和redo log的一致性问题:
- 第一阶段: InnoDB Prepare阶段。此时SQL已经成功执行,并生成事务ID(xid)信息及redo和undo的内存日志。此阶段InnoDB会写事务的redo log,但要注意的是,此时redo log只是记录了事务的所有操作日志,并没有记录提交(commit)日志,因此事务此时的状态为Prepare。此阶段对binlog不会有任何操作。
- 第二阶段:commit 阶段,这个阶段又分成两个步骤。第一步写binlog(先调用write()将binlog内存日志数据写入文件系统缓存,再调用fsync()将binlog文件系统缓存日志数据永久写入磁盘);第二步完成事务的提交(commit),此时在redo log中记录此事务的提交日志(增加commit 标签)。
可以看出,此过程中是先写redo log再写binlog的。但需要注意的是,在第一阶段并没有记录完整的redo log(不包含事务的commit标签),而是在第二阶段记录完binlog后再写入redo log的commit 标签。还要注意的是,在这个过程中是以第二阶段中binlog的写入与否作为事务是否成功提交的标志。
通过上述MySQL内部XA的两阶段提交就可以解决binlog和redo log的一致性问题。数据库在上述任何阶段crash,主从库都不会产生不一致的错误。
参考
- 推荐阅读:MYSQL中的事务日志
- 推荐阅读:日志系统:redo log和binlog
- 好文:MySQL中的事务日志
- 详细分析MySQL事务日志(redo log和undo log)
- MySQL binlog三种模式
- 深入理解MySQL之redo日志







与Object.equals())
 VS (for…of))


如何保障微服务架构下的数据一致性?)

漫画:什么是分布式事务?)


web.xml 中的listener、 filter、servlet 加载顺序及其详解)


)