《DriveMM: All-in-One Large Multimodal Model for Autonomous Driving》2024年12月发表,来自中山大学深圳分校和美团的论文。
大型多模态模型(LMM)通过整合大型语言模型,在自动驾驶(AD)中表现出卓越的理解和解释能力。尽管取得了进步,但当前的数据驱动AD方法往往专注于单个数据集和特定任务,忽视了它们的整体能力和泛化能力。为了弥合这些差距,我们提出了DriveMM,这是一种通用的大型多模式模型,旨在处理各种数据输入,如图像和多视图视频,同时执行广泛的AD任务,包括感知、预测和规划。最初,该模型经过课程预训练,以处理各种视觉信号并执行基本的视觉理解和感知任务。随后,我们增强和标准化了各种与AD相关的数据集,以微调模型,从而为自动驾驶提供了一个一体化的LMM。为了评估总体能力和泛化能力,我们对六个公共基准进行了评估,并在一个看不见的数据集上进行了零样本传输,其中DriveMM在所有任务中都实现了最先进的性能。我们希望DriveMM能够成为现实世界中未来端到端自动驾驶应用的有前景的解决方案。
1. 研究背景与问题
自动驾驶(AD)领域的数据驱动方法通常专注于单一数据集和特定任务(如目标检测、路径规划),导致模型泛化能力不足。现有大型多模态模型(LMMs)虽在视觉-语言任务中表现优异,但缺乏对复杂驾驶场景的全面理解和多任务协同能力。本文提出DriveMM,一个全合一的多模态模型,旨在统一处理多种数据输入(图像、视频、多视角数据)并执行感知、预测、规划等多样化任务,同时提升泛化能力。
2. 核心贡献
-
全合一多模态模型(DriveMM):
支持多传感器输入(单/多视角图像、视频、LiDAR),通过视角感知提示区分数据来源(如不同摄像头视角),并整合感知、预测、规划任务。 -
综合基准测试:
首次提出涵盖6个公共数据集、4种输入类型、13项任务的评估框架,覆盖复杂驾驶场景。 -
课程学习方法:
分阶段训练(语言-图像对齐→单图像预训练→多能力预训练→驾驶微调),逐步提升模型处理复杂数据的能力。 -
数据增强与标准化:
利用GPT-4o扩展问答对的多样性,统一不同数据集的标注格式(如目标位置标准化为0-100范围),促进多数据集协同训练。
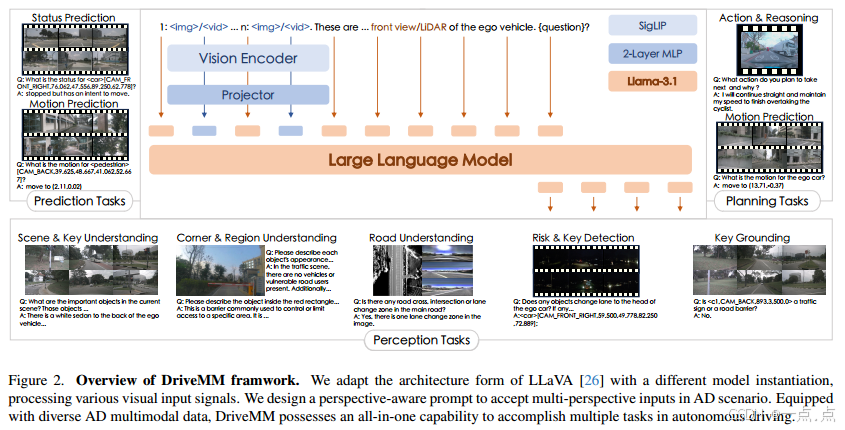 3. 方法论
3. 方法论
-
模型架构:
-
视觉编码器(SigLIP):处理多模态输入(图像、视频、LiDAR投影的BEV/范围视图)。
-
投影器(2层MLP):将视觉特征映射到语言模型的词嵌入空间(LLaMA-3.1)。
-
视角感知提示:通过占位符(
<image>/<video>)和视角标签(如CAM.BACK)增强模型对空间关系的理解。
-
-
数据策略:
-
多源数据整合:包括通用多模态数据(LCS-558K、COCO)、感知数据(COCO、nuScenes)和自动驾驶数据(CODA-LM、DriveLM等)。
-
问答增强:利用GPT-4o生成多样化问答对,将开放式问题转为多选题,提升模型泛化能力。
-
-
训练流程:

分四阶段逐步提升能力:-
语言-图像对齐:冻结视觉编码器和语言模型,仅训练投影器。
-
单图像预训练:优化整体模型参数,增强单图像理解。
-
多能力预训练:引入视频、多视角数据,提升时空推理能力。
-
驾驶微调:在6个自动驾驶数据集上联合微调,实现多任务协同。
-
4. 实验结果
-
性能优势:
DriveMM在6个数据集(CODA-LM、MAPLM、DriveLM等)的13项任务中均达到SOTA,平均性能提升显著(如Nulnstruct任务提升26.17%)。 -
泛化能力:
在零样本迁移测试(BDD-X数据集)中,DriveMM的GPT-Score(43.10)远超单数据集训练的专家模型(最高39.67)。 -
消融实验验证:
-
视角感知提示:提升多视角数据任务性能(如DriveLM、Nulnstruct)。
-
问答增强与标准化:显著改善数据多样性受限的任务(如CODA-LM)。
-
多数据集联合训练:相比单数据集训练,混合训练平均性能提升1-5%。
-
5. 创新与局限性
-
创新点:
-
首次提出全合一自动驾驶LMM,统一多任务、多数据输入。
-
视角感知提示机制和课程学习方法为多模态模型设计提供新思路。
-
-
局限性:
-
实际道路测试尚未验证,需进一步部署验证。
-
模型参数量大(基于LLaMA-3.1 8B),计算成本较高。
-
6. 应用前景
DriveMM为端到端自动驾驶系统提供了高效的多任务解决方案,可适配不同传感器配置(摄像头、雷达),适用于城市道路、高速公路等多种场景。未来可结合实时控制模块,进一步探索其在动态决策中的潜力。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!



















