文章目录
- 一、引言
- 二、系统架构设计
- 2.1、整体架构概览
- 2.2、数据库设计
- 2.3、后端服务设计
- 三、实战:从零构建排行榜
- 3.1、开发环境准备
- 3.2、用户与战区 数据管理
- 3.2.1、MySQL 数据库表创建
- 3.2.2、实现用户和战区数据的 CURD 操作
- 3.3、实时分数更新
- 3.4、排行榜查询
- 3.5、数据同步服务实现
- 四、Demo 演示与成果展示
- 五、总结
摘要: 本文将通过构建一个模拟《王者荣耀》战区排行榜的实战项目,深入展示 CodeBuddy 作为“中国版 Cursor”的强大能力。探讨如何利用 CodeBuddy 的智能代码生成(Craft)、对话理解(Chat)以及数据库控制平面(MCP)等核心功能,驱动 Redis 和 MySQL 双引擎协同工作,实现高性能、高可用的排行榜系统。项目将涵盖数据库设计、数据同步机制、实时排名查询、以及 CodeBuddy 在整个开发流程中的具体应用,为开发者提供一个 AI 辅助复杂系统开发的实战范例。
一、引言
软件开发领域,效率是衡量竞争力的关键指标之一。因此,人工智能(AI)编程工具应运而生,并迅速发展,比如 Cursor。从早期的代码自动补全、语法检查,到如今能够理解自然语言需求、生成复杂代码逻辑、甚至辅助系统设计的智能编程助手,AI 正在深刻地改变着开发者的工作方式。这些工具旨在解放开发者的双手,让他们能够将更多精力投入到高价值的创意和架构设计上,从而显著提升开发效率和软件质量。
什么是 CodeBuddy ?
腾讯云代码助手 CodeBuddy 是腾讯自主研发的 AI 编程辅助工具,旨在显著提升开发工作效率。CodeBuddy 依托腾讯混元和 DeepSeek 混合模型驱动,为开发提供强大的 AI 编程能力。
CodeBuddy的官网地址: https://copilot.tencent.com
它不仅仅是一个简单的代码编辑器插件,而是集成了多项核心能力,旨在为中国开发者提供更贴合本土开发环境和习惯的智能辅助。
CodeBuddy 的核心能力包括:
-
Craft (智能代码生成): 能够理解开发者用自然语言描述的需求,并生成高质量、符合最佳实践的代码片段、函数甚至复杂的业务逻辑代码。它内置了丰富的领域知识和代码模式,能够针对不同的技术栈生成相应的代码。
-
Chat (智能对话与问答): 提供一个交互式的对话界面,开发者可以直接提问、寻求帮助、讨论技术方案、 debug 代码。CodeBuddy 能够理解上下文,提供精准的解答和建议。
-
MCP (多模态控制平面): 这是一个关键特性,使得 CodeBuddy 能够与各种开发工具和环境进行深度集成和交互,例如直接操作数据库、调用命令行工具、与版本控制系统交互等。这使得 CodeBuddy 不仅仅是生成代码,还能“执行”代码和操作环境。
-
领域知识库: CodeBuddy 内置了涵盖前端、后端、移动开发、数据库、算法、特定框架等广泛领域的知识,使其能够提供专业、准确的帮助。
支持多种编程语言和编辑器:
正是凭借这些强大的能力,CodeBuddy 可以称为“中国版Cursor”。
本文将以《王者荣耀》战区排行榜为模拟场景,详细介绍如何利用 CodeBuddy 的各项智能能力,从零开始构建一个基于 Redis + MySQL 双引擎驱动的排行榜系统 Demo。重点展示 CodeBuddy 如何在数据库设计、核心业务逻辑实现(分数更新、排名查询)、数据同步机制构建等关键环节提供智能辅助,帮助开发者更高效、更便捷地完成开发任务。通过这个实战项目,亲身体验 CodeBuddy 作为智能开发伙伴的强大之处,并了解如何在实际项目中应用 AI 工具提升开发效率。

二、系统架构设计
构建一个高性能、高可用的排行榜系统,清晰合理的架构设计是成功的基石。这里将基于 Redis + MySQL 双引擎驱动的《王者荣耀》战区排行榜系统的架构设计,包括整体概览、数据流转、数据库设计以及后端服务划分。
2.1、整体架构概览
排行榜系统采用分层架构,主要包括用户端(模拟游戏客户端)、后端服务层、以及数据存储层(Redis 和 MySQL)。核心思想是将对实时性要求极高的排行榜读写操作放在内存数据库 Redis 中,而将需要持久化、结构化存储的用户信息和历史数据放在关系型数据库 MySQL 中。一个独立的数据同步服务负责在 Redis 和 MySQL 之间进行数据同步,保证数据的一致性。
系统的整体架构概览图:
图 2-1 系统整体架构图
架构图上,游戏客户端通过后端服务层的 API 与系统交互。后端服务层又细分为处理实时请求的“排行榜 API 服务”和负责数据同步的“数据同步服务”。排行榜 API 服务直接与 Redis 和 MySQL 交互,其中排行榜相关的实时读写主要针对 Redis,而用户信息的读取可能涉及 MySQL。数据同步服务则独立运行,负责协调 Redis 和 MySQL 之间的数据流动。
数据流转:
-
玩家分数更新流程: 将分数更新请求发送给后端服务 -> 后端服务(排行榜 API 服务)接收请求 -> 同时更新 Redis 中该玩家的总分和战区分数(使用
ZINCRBY等命令) -> 异步或定期触发将更新后的分数同步到 MySQL(通过数据同步服务) -> 后端服务响应客户端。图 2-2 玩家分数更新数据流
-
排行榜查询流程: 查看全局榜或战区榜 -> 发送查询请求给后端服务 -> 后端服务(排行榜 API 服务)接收请求 -> 查询 Redis 中对应的 Sorted Set 获取排名数据(使用
ZREVRANGE等命令) -> 根据获取到的用户 ID,从 MySQL 查询用户昵称、头像等附加信息 -> 后端服务整合数据并响应客户端。图 2-3 排行榜查询数据流
-
数据同步流程: 数据同步服务根据预设策略(如定时、增量)运行 -> 从 Redis 读取需要同步的数据(如排行榜全量或增量变化) -> 将数据写入 MySQL 的排行榜快照表或用户分数表 -> 保证 Redis 和 MySQL 数据的一致性。
图 2-4 数据同步数据流
2.2、数据库设计
合理的数据库设计是系统稳定运行的基础,需要分别设计 MySQL 和 Redis 的数据结构。
MySQL 主要用于存储基础信息、战区信息、历史分数记录以及排行榜快照,以保证数据的持久化和结构化管理。
用户表 (users): 存储玩家基本信息。
| 数据库值 | 说明 |
|---|---|
id | 唯一ID (Primary Key) |
nickname | 用户昵称 |
current_zone_id | 当前所属战区ID (Foreign Key to zones) |
total_score | 用户总分 (冗余字段,方便查询,但以 Redis 为准) |
created_at | 创建时间 |
updated_at | 更新时间 |
CodeBuddy 辅助: 通过自然语言描述“需要一个用户表,包含ID、昵称、头像URL、当前战区ID和总分”,让 CodeBuddy 生成对应的 CREATE TABLE 语句,并询问 CodeBuddy 关于索引的建议(例如,在 current_zone_id 和 total_score 上创建索引)。
战区信息表 (zones): 存储战区信息。
| 数据库值 | 说明 |
|---|---|
id | 战区唯一ID (Primary Key) |
name | 战区名称 (e.g., “北京市”, “上海市”) |
level | 战区级别 (e.g., “市”, “省”) |
CodeBuddy 辅助: 通过自然语言描述“需要一个战区信息表,包含ID、名称和级别”,让 CodeBuddy 生成 CREATE TABLE 语句。
排行榜快照表 (leaderboard_snapshots): 定期存储 Redis 排行榜的快照,用于历史查询或系统恢复。
| 数据库值 | 说明 |
|---|---|
id | 快照记录ID (Primary Key) |
zone_id | 战区ID (0表示全局榜) |
user_id | 用户ID |
score | 用户在该榜单的得分 |
rank | 用户在该榜单的排名 |
snapshot_time | 快照生成时间 |
CodeBuddy 辅助: 通过自然语言描述“需要一个表存储排行榜快照,记录战区、用户、分数、排名和时间”,让 CodeBuddy 生成 CREATE TABLE 语句,并询问 CodeBuddy 如何高效地查询历史排名数据。
分数记录表 (score_records): (可选)记录玩家每一次分数变化的详细信息,用于数据分析或回溯。
| 数据库值 | 说明 |
|---|---|
id | 记录ID (Primary Key) |
user_id | 用户ID |
zone_id | 发生变化的战区ID |
score_change | 分数变化量 |
new_total_score | 变化后的总分 |
change_time | 变化时间 |
game_id | 关联的游戏局ID (Optional) |
CodeBuddy 辅助: 通过自然语言描述“需要一个表记录每次分数变化,包括用户、战区、变化量、新总分和时间”,让 CodeBuddy 生成 CREATE TABLE 语句,并讨论如何处理大量写入的性能问题(例如,批量插入)。
Redis 主要利用其内存特性和 Sorted Set 数据结构来实现高性能的实时排行榜。
全局排行榜:
- 数据结构: Sorted Set
- Key:
global_rank - Member: 用户 ID (
user_id) - Score: 玩家总分 (
total_score)
CodeBuddy 辅助: 询问 CodeBuddy “如何在 Redis 中实现一个全局排行榜,根据总分排序?”,CodeBuddy 会建议使用 Sorted Set,并解释 ZADD, ZINCRBY, ZREVRANGE 等命令的使用。
战区排行榜:
- 数据结构: Sorted Set
- Key:
zone_rank:{zone_id}(例如:zone_rank:1001代表 ID 为 1001 的战区排行榜) - Member: 用户 ID (
user_id) - Score: 玩家在该战区的分数 (
zone_score)
CodeBuddy 辅助: 询问 CodeBuddy “如何为每个战区创建独立的排行榜?”,CodeBuddy 会建议使用带有战区 ID 的 Key 前缀,并解释如何管理多个 Sorted Set。
用户当前分数:
- 数据结构: Hash 或 String
- Key:
user_score:{user_id} - Value (Hash): 存储用户的总分 (
total) 和各战区的分数 (zone:{zone_id}),例如{ "total": 5000, "zone:1001": 1500, "zone:1002": 3500 }。 - Value (String): 仅存储用户总分,各战区分数从战区 Sorted Set 中获取。取决于实际需求和查询模式。
CodeBuddy 辅助: 询问 CodeBuddy “如何快速获取某个用户的总分和各战区分数?”,CodeBuddy 会分析 Hash 和 String 的优劣,并建议适合当前场景的数据结构。
2.3、后端服务设计
后端服务层负责处理来自客户端的请求,并协调与数据库的交互。将服务划分为排行榜 API 服务和数据同步服务。
排行榜 API 服务: 这是直接面向游戏客户端的服务,提供各种排行榜相关的接口。
API 接口示例:
POST /api/score/update: 玩家分数更新接口,接收用户ID、战区ID、分数变化量等参数。GET /api/leaderboard/global: 查询全局排行榜接口,可接受分页参数。GET /api/leaderboard/zone/{zone_id}: 查询特定战区排行榜接口,接受战区ID和分页参数。GET /api/user/{user_id}/rank/global: 查询某个用户在全局榜的排名和分数。GET /api/user/{user_id}/rank/zone/{zone_id}: 查询某个用户在特定战区榜的排名和分数。GET /api/user/{user_id}/profile: 查询用户基本信息(可能需要从 MySQL 获取)。
CodeBuddy 辅助: 通过自然语言描述“使用 Python Flask 框架,创建一个 /api/score/update 的 POST 接口,接收 user_id, zone_id, score_change 参数”,CodeBuddy 可以生成相应的路由和请求处理函数框架。
数据同步服务: 这是一个独立的后台服务,负责将 Redis 中的实时数据同步到 MySQL。同步策略可以是定时同步(例如每隔 5 分钟)或基于事件/消息队列的异步同步。
- 定时同步: 定时读取 Redis 中所有或有变化的排行榜数据,批量更新或插入到 MySQL 的排行榜快照表。
- 增量同步: 利用 Redis 的持久化特性(AOF)或监听 Redis 的 Key Space Notifications(如果数据量不大且对实时性要求更高),捕获分数变化事件,然后将变化同步到 MySQL。或者在分数更新时,将同步任务放入消息队列,由同步服务消费。
- 数据一致性: 需要考虑同步过程中的并发问题和数据丢失问题,可能需要引入版本号或时间戳来处理冲突。
CodeBuddy 辅助: 询问 CodeBuddy “如何实现 Redis 到 MySQL 的数据同步?”,CodeBuddy 会介绍不同的同步策略,并提供实现思路和代码片段。
除了核心的 Redis 和 MySQL 数据库,构建这个系统还需要选择合适的后端开发语言、Web 框架、以及可能的其他组件。
- 后端语言/框架: Python (Flask/Django), Java (Spring Boot), Go (Gin/Echo), Node.js (Express) 等。CodeBuddy 对多种主流语言和框架都有良好的支持。
- 消息队列(可选): 如果需要实现异步的数据同步或解耦服务,可以考虑使用 Kafka, RabbitMQ 等消息队列。
- 缓存(可选): 除了 Redis 用于排行榜,还可以使用 Redis 或 Memcached 作为通用的缓存层,缓存用户基本信息等不经常变动的数据,减轻 MySQL 的压力。
三、实战:从零构建排行榜
前面简单设计了系统的整体架构和数据库结构。现在可以进入实际的编码阶段,将详细介绍如何使用 CodeBuddy 实现排行榜系统的核心功能,包括用户和战区管理、实时分数更新、排行榜查询以及数据同步。以 Python + Flask 作为后端开发的示例技术栈。
3.1、开发环境准备
在开始编码之前,需要准备好开发环境。这包括安装 Python、Flask 框架、Redis 客户端库(如 redis-py)、MySQL 驱动(如 mysql-connector-python 或 PyMySQL),以及配置好 Redis 和 MySQL 服务器。
可以通过 CodeBuddy 的 Chat 功能询问如何安装这些依赖库,或者让 CodeBuddy 生成一个 requirements.txt 文件。
向 CodeBuddy 提问:
在 Python 中安装 Flask, redis-py 和 PyMySQL,请帮我生成一个包含 Flask, redis-py 和 PyMySQL 的 requirements.txt 文件内容。
CodeBuddy 经过思考后成功创建requirements.txt文件,内容如下:
Flask==2.3.2
redis==4.5.5
PyMySQL==1.0.3
SQLAlchemy==2.0.19
python-dotenv==1.0.0
安装这些依赖,运行以下命令:
pip install -r requirements.txt
安装完成后,可以继续开发排行榜系统的其他组件。
3.2、用户与战区 数据管理
这部分主要涉及与 MySQL 数据库的交互,实现用户和战区信息的创建、读取、更新等操作。
3.2.1、MySQL 数据库表创建
向 CodeBuddy 提问:
创建一个数据库,并在当前数据库中创建用户表 (users),包含 id (主键), nickname, avatar_url, current_zone_id, total_score, created_at, updated_at 字段。
CodeBuddy 会自动生成init_db.sql文件,执行该文件来初始化数据库,命令是:
mysql -u root -p < init_db.sql
如果系统没有安装MySQL,先执行下面的命令安装(以Ubuntu系统为例):
sudo apt install mysql-server
对于WSL 环境,使用传统 service 命令管理 MySQL:
# 启动 MySQL
sudo service mysql start# 查看状态
sudo service mysql status# 停止 MySQL
sudo service mysql stop
类似地,创建 zones 表。向 CodeBuddy 提问:
创建一个战区信息表 (zones),包含ID、名称和级别
CodeBuddy会更新 init_db.sql 文件,执行如下命令:
# 1. 备份现有数据库(如有需要)
mysqldump -u root -p game_leaderboard > backup.sql# 2. 执行更新后的脚本
mysql -u root -p < init_db.sql# 3. 验证表结构
mysql -u root -p -e "USE game_leaderboard; SHOW TABLES; DESCRIBE zones; DESCRIBE users;"
得到的数据库表结构如下:
+----------------------------+
| Tables_in_game_leaderboard |
+----------------------------+
| users |
| zones |
+----------------------------+
+------------+-------------+------+-----+-------------------+-----------------------------------------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+-------------------+-----------------------------------------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(50) | NO | | NULL | |
| level | int | YES | | 1 | |
| created_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
| updated_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
+------------+-------------+------+-----+-------------------+-----------------------------------------------+
+-----------------+--------------+------+-----+-------------------+-----------------------------------------------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------+------+-----+-------------------+-----------------------------------------------+
| id | int | NO | PRI | NULL | auto_increment |
| nickname | varchar(50) | NO | | NULL | |
| avatar_url | varchar(255) | YES | | NULL | |
| current_zone_id | int | YES | | 0 | |
| total_score | int | YES | | 0 | |
| created_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
| updated_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
+-----------------+--------------+------+-----+-------------------+-----------------------------------------------+
哦豁,好像忘记创建索引了,没事,让CodeBuddy帮我们创建。向CodeBuddy提问:
请在 users 表的 current_zone_id 字段上创建索引。
CodeBuddy会更新 init_db.sql 文。
最终 init_db.sql 文件内容如下:
-- 创建游戏排行榜数据库
CREATE DATABASE IF NOT EXISTS game_leaderboard DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;USE game_leaderboard;-- 创建战区信息表
CREATE TABLE IF NOT EXISTS zones (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50) NOT NULL COMMENT '战区名称',level INT DEFAULT 1 COMMENT '战区级别',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='战区信息表';-- 创建用户表
CREATE TABLE IF NOT EXISTS users (id INT AUTO_INCREMENT PRIMARY KEY,nickname VARCHAR(50) NOT NULL COMMENT '用户昵称',avatar_url VARCHAR(255) COMMENT '用户头像URL',current_zone_id INT DEFAULT 0 COMMENT '当前战区ID',CONSTRAINT fk_user_zone FOREIGN KEY (current_zone_id) REFERENCES zones(id),total_score INT DEFAULT 0 COMMENT '总积分',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户信息表';-- 在current_zone_id字段上创建索引
CREATE INDEX idx_user_zone ON users(current_zone_id);
执行如下命令完成更新:
# 如果之前执行过旧版本,建议先删除旧表
mysql -u root -p -e "DROP TABLE IF EXISTS game_leaderboard.users, game_leaderboard.zones;"# 执行更新后的脚本
mysql -u root -p < init_db.sql# 验证索引是否创建成功
mysql -u root -p -e "USE game_leaderboard; SHOW INDEX FROM users;"
索引创建成功:
+-------+------------+---------------+--------------+-----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+---------------+--------------+-----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| users | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
| users | 1 | idx_user_zone | 1 | current_zone_id | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL |
+-------+------------+---------------+--------------+-----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3.2.2、实现用户和战区数据的 CURD 操作
使用 ORM (Object-Relational Mapping) 来简化数据库操作,例如 SQLAlchemy。CodeBuddy 可以帮生成 ORM 模型类和基本的 CURD 函数。
向 CodeBuddy 提问:
使用 SQLAlchemy,为 users 表创建一个 ORM 模型类。
CodeBuddy 会创建SQLAlchemy ORM模型文件models.py。
from datetime import datetime
from sqlalchemy import Column, Integer, String, ForeignKey, TIMESTAMP
from sqlalchemy.sql import func
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationshipBase = declarative_base()class Zone(Base):"""战区信息模型"""__tablename__ = 'zones'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(50), nullable=False, comment='战区名称')level = Column(Integer, default=1, comment='战区级别')created_at = Column(TIMESTAMP, server_default=func.now(), comment='创建时间')updated_at = Column(TIMESTAMP, server_default=func.now(), onupdate=func.now(), comment='更新时间')class User(Base):"""用户信息模型"""__tablename__ = 'users'id = Column(Integer, primary_key=True, autoincrement=True)nickname = Column(String(50), nullable=False, comment='用户昵称')avatar_url = Column(String(255), nullable=True, comment='用户头像URL')current_zone_id = Column(Integer, ForeignKey('zones.id'), default=0, comment='当前战区ID')total_score = Column(Integer, default=0, comment='总积分')created_at = Column(TIMESTAMP, server_default=func.now(), comment='创建时间')updated_at = Column(TIMESTAMP, server_default=func.now(), onupdate=func.now(), comment='更新时间')# 定义与Zone的关系zone = relationship("Zone", backref="users")def __repr__(self):return f"<User(id={self.id}, nickname='{self.nickname}')>"
继续向 CodeBuddy 提问:
使用 SQLAlchemy,编写一个函数来根据用户 ID 查询用户信息。
使用 SQLAlchemy,编写一个函数来向 users 表插入一条新用户记录。
user_service.py文件成功创建。
from sqlalchemy.orm import Session
from models import User
from typing import Optional, Dict, Any
from sqlalchemy.exc import SQLAlchemyErrordef get_user_by_id(session: Session, user_id: int) -> Optional[User]:"""根据用户ID查询用户信息参数:session: SQLAlchemy会话对象user_id: 要查询的用户ID返回:User对象(如果找到)或None(如果用户不存在)"""try:# 使用session.query查询,可以添加.filter等链式调用user = session.query(User).filter(User.id == user_id).first()return userexcept Exception as e:# 记录错误日志(实际项目中应该使用logging模块)print(f"查询用户时发生错误: {e}")return Nonedef create_user(session: Session, user_data: Dict[str, Any]) -> Dict[str, Any]:"""创建新用户记录参数:session: SQLAlchemy会话对象user_data: 包含用户信息的字典,应有以下键:- nickname: 用户昵称(必需)- avatar_url: 头像URL(可选)- current_zone_id: 战区ID(可选,默认为0)- total_score: 总积分(可选,默认为0)返回:字典包含:- 'success': 操作是否成功- 'user': 新用户对象(成功时)- 'error': 错误信息(失败时)"""if not user_data.get('nickname'):return {'success': False, 'error': '昵称不能为空'}try:new_user = User(nickname=user_data['nickname'],avatar_url=user_data.get('avatar_url'),current_zone_id=user_data.get('current_zone_id', 0),total_score=user_data.get('total_score', 0))session.add(new_user)session.commit()session.refresh(new_user)return {'success': True,'user': new_user,'message': f'用户 {new_user.nickname} 创建成功,ID: {new_user.id}'}except SQLAlchemyError as e:session.rollback()return {'success': False,'error': f'数据库错误: {str(e)}'}类似地,为 zones 表生成 ORM 模型和 CURD 函数。太多了,这里就补贴上传的代码了。
3.3、实时分数更新
这是排行榜系统的核心功能之一,要求分数更新能够快速反映到排行榜中。首先更新 Redis 中的数据,然后通过某种机制触发同步到 MySQL。
当玩家分数发生变化时,需要更新全局排行榜和所属战区排行榜中的分数。
逻辑:
- 接收玩家 ID、战区 ID 和分数变化量。
- 使用 Redis 的
ZINCRBY命令原子性地增加全局排行榜 (global_rankSorted Set) 中该玩家的分数。 - 使用 Redis 的
ZINCRBY命令原子性地增加战区排行榜 (zone_rank:{zone_id}Sorted Set) 中该玩家的分数。 - (可选)更新用户分数 Hash 或 String 存储中的总分和战区分数。
- 触发数据同步机制(例如,将用户 ID 和更新后的分数放入一个待同步队列或直接调用同步服务接口)。
向 CodeBuddy 提问:
使用 redis-py 库,如何原子性地增加 Redis Sorted Set 中一个成员的分数?
编写一个 Python 函数update_score(user_id, zone_id, score_change),使用 redis-py 更新全局排行榜和指定战区排行榜中的分数。
在分数更新后,需要确保这些变化最终同步到 MySQL。这里采用一个简单的异步触发机制,将需要同步的用户信息放入一个队列(例如,一个 Redis List 或一个简单的 Python 列表,在实际场景应使用消息队列)。数据同步服务会消费这个队列。
逻辑: 在 update_score 函数中,分数更新 Redis 成功后,将 user_id 加入一个 Redis List,例如 sync_queue。
向 CodeBuddy 提问:
使用 redis-py 库,如何将一个元素添加到 Redis List 的末尾?
修改update_score函数,在更新 Redis 后,将user_id添加到sync_queueList 中。
CodeBuddy 解释zincrby命令的使用并提供代码:
最终的代码内容:
import redis
from typing import Unionclass RedisRanking:def __init__(self, host='localhost', port=6379, db=0):"""初始化Redis连接"""self.redis = redis.Redis(host=host, port=port, db=db, decode_responses=True)def increment_member_score(self, key: str, member: str, increment: Union[int, float] = 1) -> float:"""原子性地增加Sorted Set成员的分数参数:key: Sorted Set的键名member: 成员标识increment: 要增加的分数(默认为1)返回:增加后的新分数"""try:# ZINCRBY是原子操作new_score = self.redis.zincrby(key, increment, member)return float(new_score)except redis.RedisError as e:print(f"Redis操作失败: {e}")raisedef bulk_increment_scores(self, key: str, member_scores: dict) -> bool:"""原子性地批量增加多个成员的分数参数:key: Sorted Set的键名member_scores: {成员: 增加分数}的字典返回:操作是否成功"""try:# 使用pipeline确保原子性with self.redis.pipeline() as pipe:for member, increment in member_scores.items():pipe.zincrby(key, increment, member)pipe.execute()return Trueexcept redis.RedisError as e:print(f"批量操作失败: {e}")return Falsedef update_score(self,user_id: str, zone_id: str,score_change: Union[int, float],max_queue_size: int = 10000) -> bool:"""更新全局和战区排行榜分数,并将用户ID添加到同步队列参数:user_id: 用户IDzone_id: 战区IDscore_change: 分数变化值(可正可负)max_queue_size: 同步队列最大长度(可选)返回:操作是否成功"""try:with self.redis.pipeline() as pipe:# 更新全局排行榜pipe.zincrby("global_leaderboard", score_change, user_id)# 更新战区排行榜pipe.zincrby(f"zone_leaderboard:{zone_id}", score_change, user_id)# 将用户ID添加到同步队列末尾pipe.rpush("sync_queue", user_id)# 可选: 限制队列长度if max_queue_size > 0:pipe.ltrim("sync_queue", -max_queue_size, -1)pipe.execute()return Trueexcept redis.RedisError as e:print(f"更新排行榜失败: {e}")return False3.4、排行榜查询
排行榜查询是用户最常进行的操作。主要从 Redis 中获取排名数据,然后从 MySQL 中获取用户的附加信息。
查询 Redis 排行榜数据, 逻辑:
- 全局榜: 使用 Redis 的
ZREVRANGE命令,根据分数倒序获取global_rankSorted Set 中指定范围(分页)的成员(用户 ID)及其分数。 - 战区榜: 使用 Redis 的
ZREVRANGE命令,根据分数倒序获取zone_rank:{zone_id}Sorted Set 中指定范围的成员(用户 ID)及其分数。 - 查询个人排名: 使用 Redis 的
ZREVRANK命令获取某个用户在 Sorted Set 中的排名(从 0 开始),然后根据排名计算实际名次。使用ZSCORE命令获取用户的分数。
向 CodeBuddy 提问:
使用 redis-py 库,如何获取 Redis Sorted Set 中分数最高的 N 个成员?
使用 redis-py 库,如何查询某个成员在 Redis Sorted Set 中的排名和分数?
编写函数来实现全局榜和战区榜的分页查询,以及查询个人排名和分数的功能。
需要实现以下几个功能:
-
获取Sorted Set中分数最高的N个成员(ZREVRANGE)
-
查询成员的排名(ZREVRANK)和分数(ZSCORE)
-
分页查询功能(ZREVRANGE + offset)
-
封装为全局榜和战区榜的查询方法
从 MySQL 获取用户附加信息: 从 Redis 获取到用户 ID 和分数后,需要根据用户 ID 从 MySQL 的 users 表中查询用户的昵称、头像等信息,以便在排行榜界面展示。
逻辑:
- 从 Redis 查询结果中提取用户 ID 列表。
- 使用 SQL 的
IN子句或多次查询,根据用户 ID 列表批量从users表中查询用户信息。 - 将从 Redis 和 MySQL 获取的数据进行整合。
向 CodeBuddy 提问:
使用 SQLAlchemy,如何根据一个用户 ID 列表批量查询 users 表?
修改排行榜查询函数,在获取 Redis 数据后,添加从 MySQL 查询用户信息的逻辑,并将两部分数据整合。
3.5、数据同步服务实现
数据同步服务是一个独立的后台进程,负责消费待同步队列,并将 Redis 中的最新数据同步到 MySQL。
逻辑:
- 循环监听或定时检查
sync_queueRedis List。 - 从队列中取出待同步的用户 ID。
- 根据用户 ID,从 Redis 中获取该用户的最新总分和各战区分数(可能需要查询
user_score:{user_id}Hash 或各个zone_rank:{zone_id}Sorted Set)。 - 根据获取到的分数,更新 MySQL 中
users表的total_score字段。 - (可选)根据同步策略,更新或插入到
leaderboard_snapshots表。 - 处理同步过程中的异常和并发问题。
向 CodeBuddy 提问:
使用 redis-py 库,如何从 Redis List 的头部取出一个元素?
如何编写一个简单的 Python 脚本,循环从 Redis List 中读取用户 ID,并打印出来?
使用 SQLAlchemy,如何根据用户 ID 更新 users 表的 total_score 字段?
帮助构建数据同步服务的核心逻辑代码,包括从 Redis 读取、从 Redis 获取最新分数、更新 MySQL 等步骤。处理批量同步和错误重试。
生成服务代码:
import redis
from typing import List, Dict, Optional
from sqlalchemy.orm import Session
from models import User
import time
from datetime import datetimeclass DataSyncService:def __init__(self, redis_conn, db_session):"""初始化同步服务参数:redis_conn: Redis连接实例db_session: SQLAlchemy会话"""self.redis = redis_connself.db = db_sessionself.batch_size = 100 # 每次同步的批量大小self.max_retries = 3 # 最大重试次数self.retry_delay = 1 # 重试延迟(秒)def _get_sync_queue(self) -> List[str]:"""从Redis同步队列获取待处理用户ID"""try:# 获取并清空当前批次user_ids = self.redis.lrange("sync_queue", 0, self.batch_size-1)if user_ids:self.redis.ltrim("sync_queue", len(user_ids), -1)return [uid.decode() if isinstance(uid, bytes) else uid for uid in user_ids]except redis.RedisError as e:print(f"获取同步队列失败: {e}")return []def _get_redis_scores(self, user_ids: List[str]) -> Dict[str, float]:"""从Redis获取用户最新分数"""try:with self.redis.pipeline() as pipe:for user_id in user_ids:pipe.zscore("global_leaderboard", user_id)scores = pipe.execute()return {user_id: float(score) if score is not None else Nonefor user_id, score in zip(user_ids, scores)}except (redis.RedisError, TypeError) as e:print(f"获取Redis分数失败: {e}")return {}def _update_mysql_users(self, user_scores: Dict[str, float]) -> int:"""批量更新MySQL用户分数"""if not user_scores:return 0updated_count = 0try:# 获取需要更新的用户ID列表user_ids = [int(uid) for uid in user_scores.keys()]# 批量查询用户users = self.db.query(User).filter(User.id.in_(user_ids)).all()# 创建用户映射user_map = {user.id: user for user in users}# 批量更新for user_id, score in user_scores.items():user_id_int = int(user_id)if user_id_int in user_map and score is not None:user = user_map[user_id_int]user.total_score = scoreuser.updated_at = datetime.now()updated_count += 1self.db.commit()return updated_countexcept Exception as e:self.db.rollback()print(f"更新MySQL失败: {e}")return 0def sync_batch(self) -> Dict[str, int]:"""执行一批数据同步返回:包含同步结果的字典:{'total': 总处理数量,'updated': 成功更新数量,'retries': 重试次数}"""result = {'total': 0, 'updated': 0, 'retries': 0}for attempt in range(self.max_retries):# 获取待同步用户user_ids = self._get_sync_queue()if not user_ids:breakresult['total'] = len(user_ids)# 获取最新分数user_scores = self._get_redis_scores(user_ids)# 更新MySQLupdated = self._update_mysql_users(user_scores)result['updated'] = updatedif updated == len(user_ids):break # 全部成功则退出重试result['retries'] += 1time.sleep(self.retry_delay)return resultdef continuous_sync(self, interval: int = 5):"""持续同步数据"""print(f"启动数据同步服务,间隔: {interval}秒")while True:try:batch_result = self.sync_batch()if batch_result['total'] > 0:print(f"同步完成: 处理={batch_result['total']}, "f"更新={batch_result['updated']}, "f"重试={batch_result['retries']}")time.sleep(interval)except KeyboardInterrupt:print("停止数据同步服务")breakexcept Exception as e:print(f"同步服务异常: {e}")time.sleep(interval)
四、Demo 演示与成果展示
已经构建了一个基于 Redis 和 MySQL 双引擎驱动的《王者荣耀》战区排行榜系统的核心功能。现在可以通过一个简单的 Demo 演示来展示系统的实际运行效果。
安装和启动redis:
sudo apt install redis-server # (如果未安装)
redis-server --version
sudo service redis-server start # 启动
sudo service redis-server stop # 停止(如果需要)
sudo service redis-server restart # 重启(如果需要)
安装依赖:
pip install -r requirements.txt
配置环境变量,复制.env.example文件为.env,并根据实际情况修改配置:
cp .env.example .env
# 编辑.env文件,修改数据库和Redis连接信息
初始化数据库:
mysql -u root -p < init_db.sql
启动应用:
# 启动所有服务(API服务和数据同步服务)
./run.sh
# 或
./run.sh all# 只启动API服务
./run.sh api# 只启动数据同步服务
./run.sh sync
数据同步服务负责在Redis和MySQL之间同步排行榜数据,确保数据一致性。默认同步间隔为5分钟,可通过.env文件中的SYNC_INTERVAL参数调整。
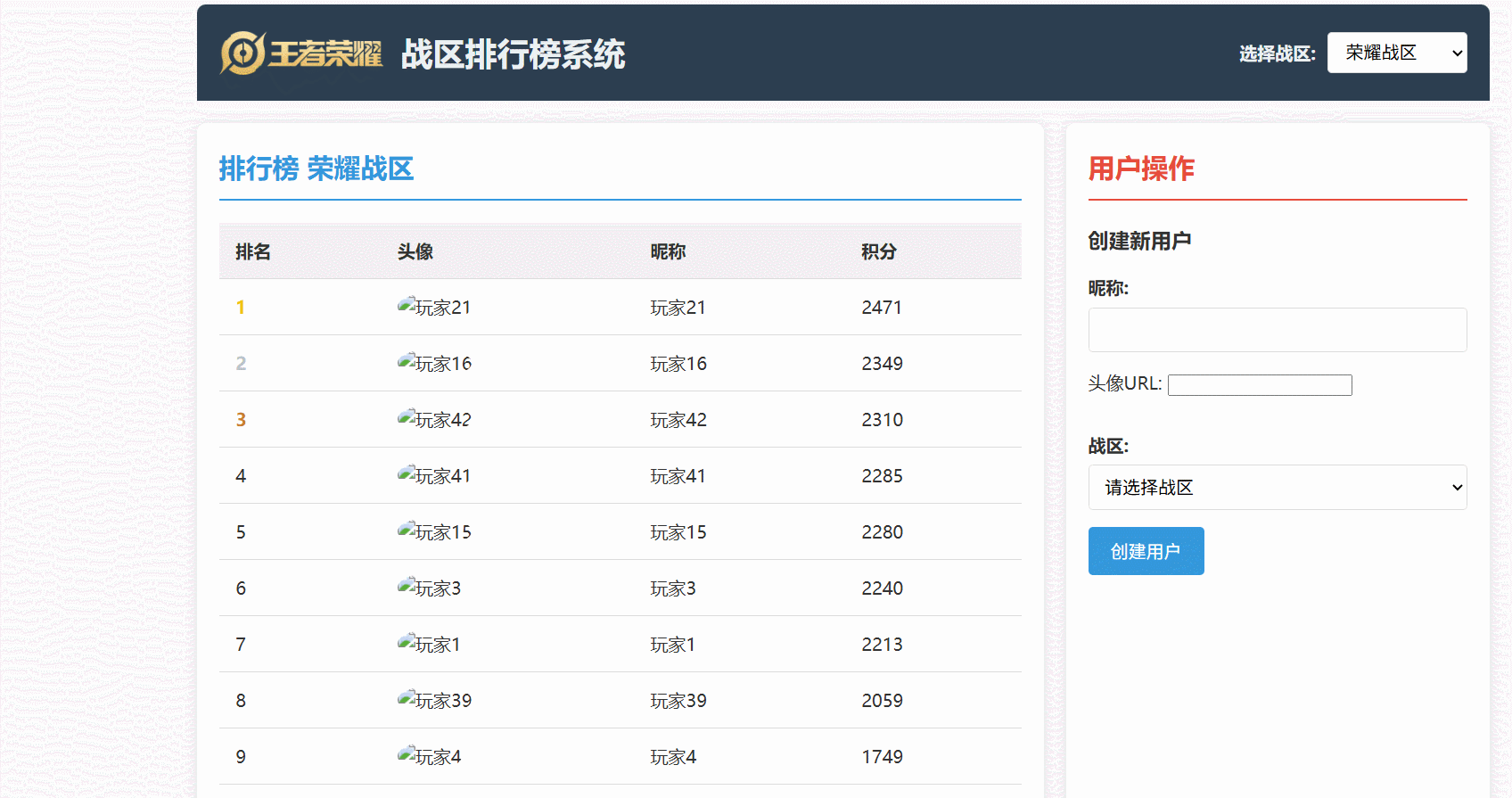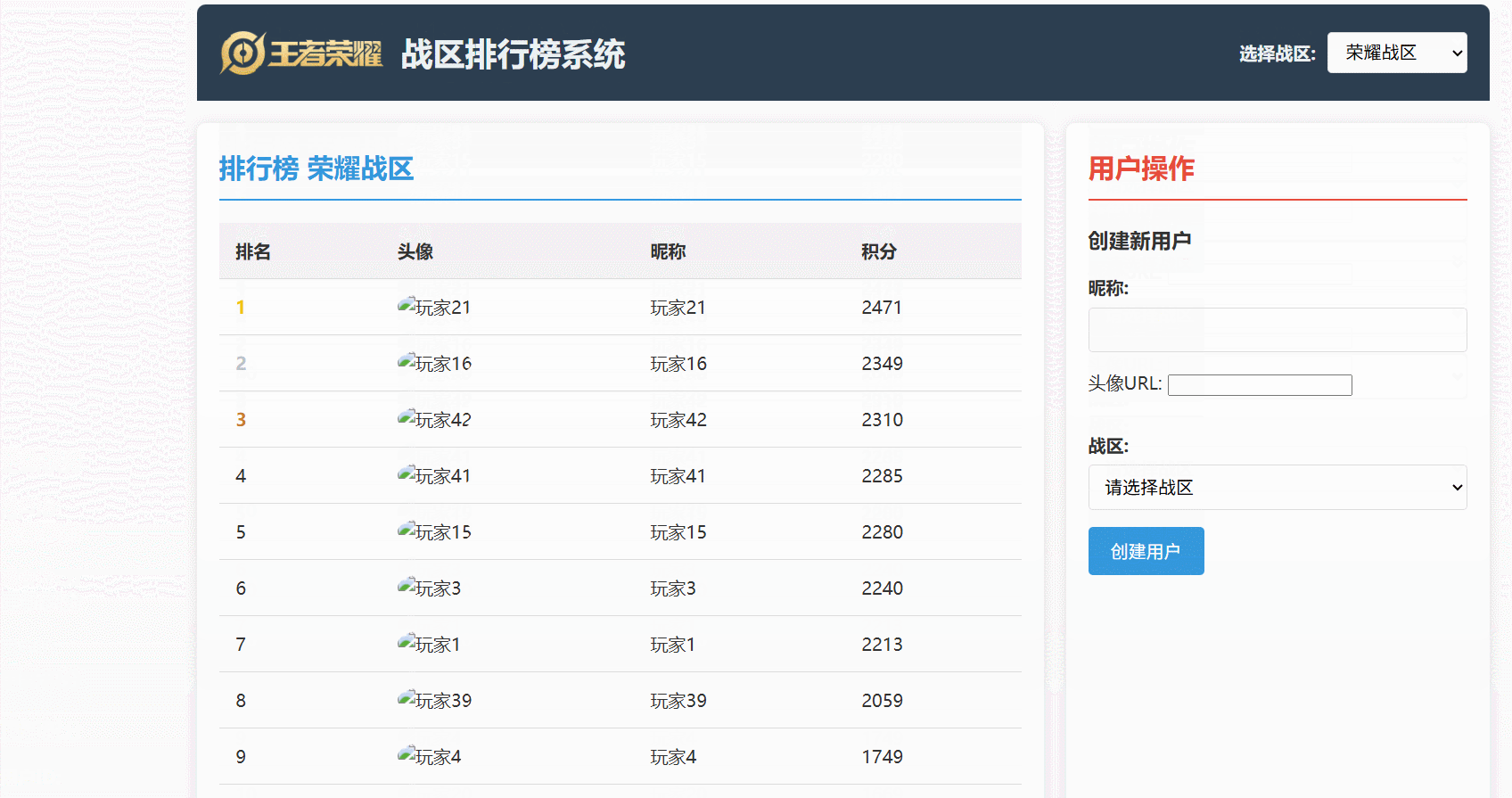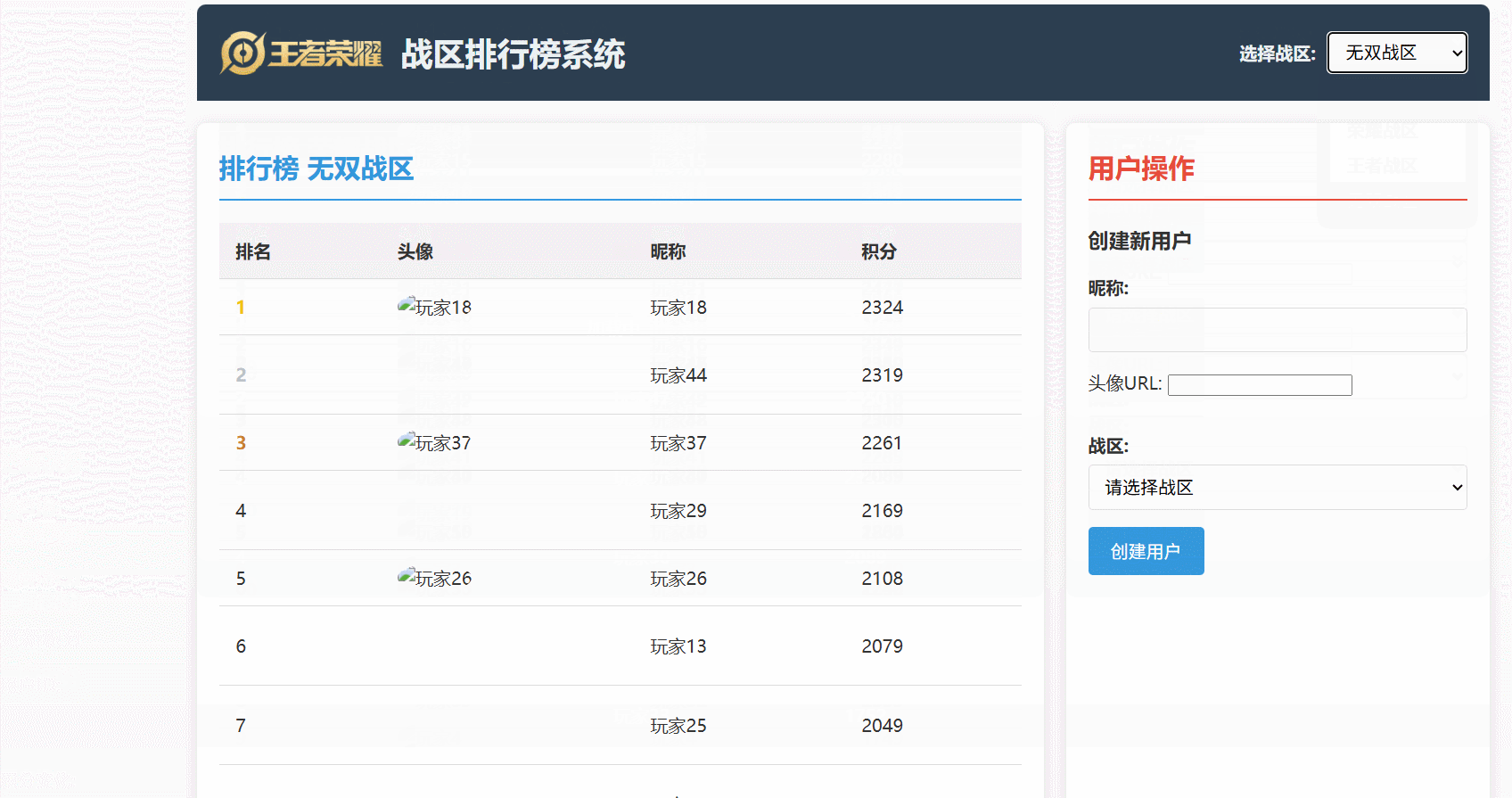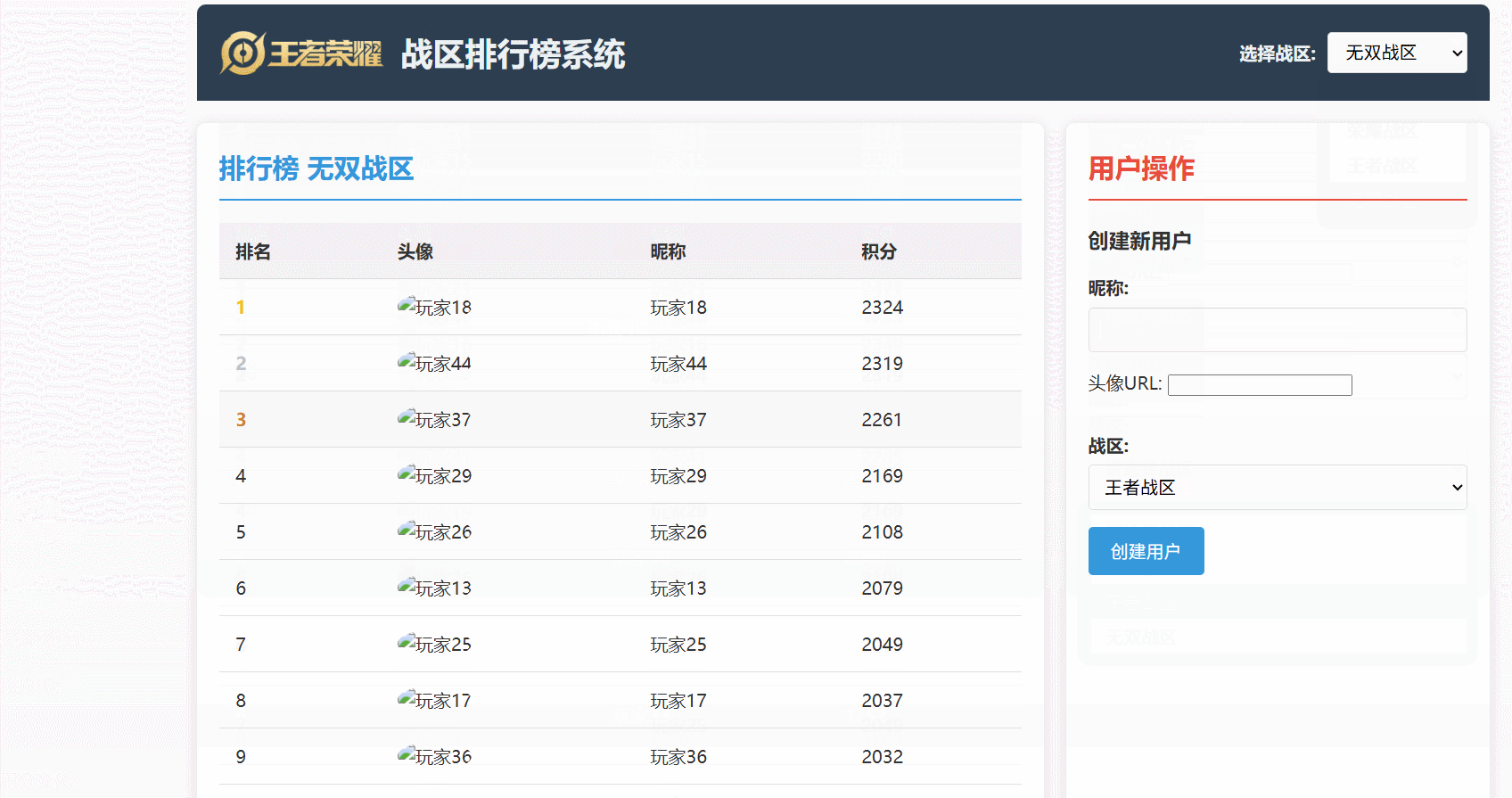
图 4-1 分数更新与同步演示流程
图 4-2 排行榜查询演示流程
可以直观地看到:
- 玩家分数更新后,Redis 中的排行榜数据能够几乎实时地反映变化。
- 排行榜查询能够快速地从 Redis 获取排名数据,并结合 MySQL 的用户信息进行展示。
- 数据同步机制确保了 Redis 和 MySQL 之间的数据最终一致性。
最后看一下运行效果:
项目代码已更新到GitHub:https://github.com/LongTengFly/Python。
通过利用 CodeBuddy 的智能辅助能力,在相对较短的时间内完成了这个双引擎驱动的排行榜系统的核心功能开发。CodeBuddy 极大地减少了编写样板代码的工作量,使得开发者能够更专注于业务逻辑的实现和架构的优化。
虽然核心功能已经实现并得到演示,但一个生产级别的排行榜系统还需要进一步的优化和扩展:
- 对高并发场景下的 Redis 和 MySQL 读写进行性能调优,例如连接池管理、批量操作、索引优化等。
- 引入更 robust 的数据同步机制,如基于消息队列的最终一致性方案,处理同步过程中的各种异常情况。
- 考虑 Redis 集群、MySQL 读写分离、后端服务水平扩展等。
- 更多排行榜类型: 支持周榜、月榜、好友榜等。
五、总结
已经完成了排行榜系统的架构设计、核心功能开发并在本地进行了简单的 Demo 演示,重点在 CodeBuddy 在这些环节中的辅助作用。
本文阐述了如何利用CodeBuddy构建一个基于Redis和MySQL双引擎的《王者荣耀》战区排行榜系统。从架构设计、数据库选型、核心功能开发,到Demo演示,全面覆盖项目生命周期。重点展示了CodeBuddy在代码生成、技术咨询、问题排查等方面的强大辅助能力,显著提升了开发效率。










)
![[案例四] 智能填写属性工具(支持装配组件还有建模实体属性的批量创建、编辑)](http://pic.xiahunao.cn/[案例四] 智能填写属性工具(支持装配组件还有建模实体属性的批量创建、编辑))
)



)



