一、行为设计模式
行为模式涉及算法和对象间职责的分配。行为模式不仅描述对象或类的模式,还描述它们之间的通信模式。这些模式刻画了在运行时难以跟踪的、复杂的控制流。它们将用户的注意力从控制流转移到对象间的联系方式上来。
行为类模式使用继承机制在类间分派行为。
其中Template Method 较为简单和常用。模板方法是一个算法的抽象定义,它逐步地定义该算法,每一步调用一个抽象操作或一个原语操作,子类定义抽象操作以具体实现该算法。
另一种行为类模式是Interpreter,它将一个文法表示为一个类层次,并实现一个解释器作为这些类的实例上的一个操作。
行为对象模式使用对象复合而不是继承。一些行为对象模式描述了一组对等的对象怎样相互协作以完成其中任一个对象都无法单独完成的任务。这里一个重要的问题是对等的对象。如何互相了解对方。对等对象可以保持显式的对对方的引用,但那会增加它们的耦合度。在极端情况下,每一个对象都要了解所有其他的对象。
Mediator 在对等对象间引入一个mediator对象以避免这种情况的出现。mediator提供了松耦合所需的间接性。
Chain of Responsibility提供更松的耦合。它让用户通过一条候选对象链隐式地向一个对象发送请求。根据运行时刻情况任一候选者都可以响应相应的请求。候选者的数目是任意的,可以在运行时刻决定哪些候选者参与到链中。
Observer 模式定义并保持对象间的依赖关系。典型的observer 的例子是Smalltalk 中的模型/视图/控制器,其中,一旦模型的状态发生变化,模型的所有视图都会得到通知。其他的行为对象模式常将行为封装在一个对象中并将请求指派给它。
Strategy模式将算法封装在对象中,这样可以方便地指定和改变一个对象所使用的算法。
Command 模式将请求封装在对象中,这样它就可作为参数来传递,也可以被存储在历史列表中,或者以其他方式使用。
State 模式封装一个对象的状态,使得这个对象的状态对象变化时,该对象可改变它的行为。
Visitor 封装分布于多个类之间的行为,而 Iterator抽象了访问和遍历一个集合中的对象的方式。
(一)Chain of Responsibility模式
1. 模式名称
责任链模式(Chain of Responsibility Pattern)
2. 意图解决的问题
责任链模式旨在解耦请求的发送者与接收者,通过使多个对象都有机会处理请求,避免了请求发送者需要明确指定接收者的情况。这样做的好处是,可以动态地改变处理一个请求的对象集合,同时允许接收者之间进行通信,但不需要直接知道下一个接收者的身份。
具体应用场景包括但不限于:
- 事件处理系统:如GUI框架中的事件分发机制。
- 异常处理:在不同的层级中定义异常处理器,尝试逐层处理异常直到找到合适的处理器。
- 审批流程:例如请假申请、报销单据等,根据金额或其他条件由不同级别的管理人员进行审批。
3. 模式描述
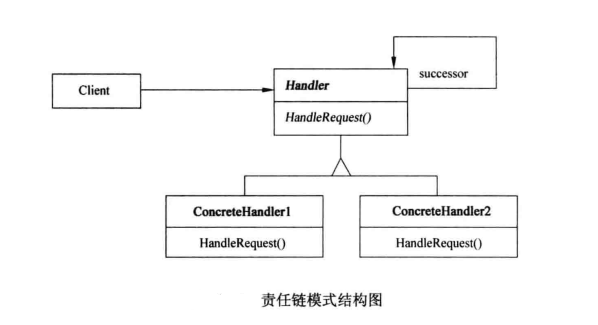
责任链模式包含以下几个关键角色:
- 抽象处理者(Handler):定义了一个处理请求的接口,并且可能包含一个指向下一个处理者的引用。它通常提供了一个设置后续处理者的方法。
- 具体处理者(Concrete Handler):实现了抽象处理者的接口,决定是否处理这个请求以及如何处理。如果当前处理者无法处理该请求,则将请求转发给下一个处理者。
- 客户端(Client):负责创建职责链,并向链上的第一个处理者提交请求。
(1)示例代码
//抽象处理者(Handler)
public abstract class Handler {protected Handler successor;public void setSuccessor(Handler successor) {this.successor = successor;}public abstract void handleRequest(String request);
}
// 具体处理者
public class ConcreteHandler1 extends Handler {@Overridepublic void handleRequest(String request) {if ("请求1".equals(request)) {System.out.println("ConcreteHandler1 处理了请求: " + request);} else if (successor != null) {successor.handleRequest(request);}}
}public class ConcreteHandler2 extends Handler {@Overridepublic void handleRequest(String request) {if ("请求2".equals(request)) {System.out.println("ConcreteHandler2 处理了请求: " + request);} else if (successor != null) {successor.handleRequest(request);}}
}
// 客户端(Client)
public class Client {public static void main(String[] args) {// 创建具体处理者对象Handler handler1 = new ConcreteHandler1();Handler handler2 = new ConcreteHandler2();// 设置责任链handler1.setSuccessor(handler2);// 提交请求handler1.handleRequest("请求1");handler1.handleRequest("请求2");handler1.handleRequest("未知请求"); // 无处理者能处理此请求}
}
在这个示例中:
- Handler 是抽象处理者类,定义了一个 handleRequest 方法和一个 setSuccessor 方法用于设置下一个处理者。
- ConcreteHandler1 和 ConcreteHandler2 是具体的处理者类,它们继承自 Handler 并实现了 handleRequest 方法。每个具体处理者会检查请求是否符合其处理条件,如果不符合则将请求传递给下一个处理者。
- Client 类是客户端,它创建了具体处理者对象并设置了责任链,然后提交请求进行处理。
通过这种方式,客户端无需 关心具体的处理逻辑或责任链的具体构成,只需将请求发送到责任链的第一个处理者即可。
4.应用场景
(1)场景背景:
设想一个公司有不同级别的员工(如普通员工、部门经理、总经理等),每个级别的员工有不同的权限来批准或拒绝请假申请。例如,普通员工的请假天数如果在3天以内可以直接由直接上级(部门经理)批准;如果超过3天,则需要总经理进一步审批。
(2)遇到的困难:
复杂性增加:
如果没有使用责任链模式,处理请假请求的逻辑可能会变得非常复杂。每次当一个新的请假请求到来时,系统需要根据不同的条件(如请假天数、员工级别等)判断应该由哪一级别的管理人员进行审批。这不仅增加了代码的复杂性,还可能导致难以维护和扩展。
紧耦合:
直接在代码中硬编码审批流程会导致客户端与具体的审批逻辑紧密耦合,这意味着任何对审批流程的修改都需要更改客户端代码,降低了系统的灵活性。
不易扩展:
如果未来需要添加新的审批层级或改变现有的审批规则,可能需要大幅修改现有代码,增加了开发成本和风险。
(3)Chain of Responsibility模式如何解决这个问题:
通过引入责任链模式,可以将审批流程中的每一个环节抽象为一个处理者(Handler)。这些处理者形成一条责任链,每个处理者负责检查当前请求是否属于自己的职责范围,并决定是自己处理还是传递给下一个处理者。
// 定义一个抽象类 Approver 作为所有审批者的基类,它包含了一个指向下一个审批者的引用以及一个处理请假请求的方法。
public abstract class Approver {protected Approver successor;public void setSuccessor(Approver successor) {this.successor = successor;}public abstract void processRequest(LeaveRequest request);
}public class TeamLeader extends Approver {@Overridepublic void processRequest(LeaveRequest request) {if (request.getDays() <= 3) {System.out.println("团队领导批准了 " + request.getName() + " 的请假请求,天数: " + request.getDays());} else if (successor != null) {successor.processRequest(request);}}
}
// 创建多个具体处理者类,如 TeamLeader、Manager 和 CEO,它们分别代表不同的审批级别,并实现了 processRequest 方法。
public class Manager extends Approver {@Overridepublic void processRequest(LeaveRequest request) {if (request.getDays() > 3 && request.getDays() <= 7) {System.out.println("经理批准了 " + request.getName() + " 的请假请求,天数: " + request.getDays());} else if (successor != null) {successor.processRequest(request);}}
}public class CEO extends Approver {@Overridepublic void processRequest(LeaveRequest request) {if (request.getDays() > 7) {System.out.println("CEO批准了 " + request.getName() + " 的请假请求,天数: " + request.getDays());} else if (successor != null) {successor.processRequest(request);}}
}// 创建一个简单的 LeaveRequest 类来封装请假请求的信息。
public class LeaveRequest {private String name;private int days;public LeaveRequest(String name, int days) {this.name = name;this.days = days;}public String getName() {return name;}public int getDays() {return days;}
}
// 客户端代码:
public class Client {public static void main(String[] args) {// 创建具体处理者对象Approver teamLeader = new TeamLeader();Approver manager = new Manager();Approver ceo = new CEO();// 设置责任链teamLeader.setSuccessor(manager);manager.setSuccessor(ceo);// 提交请假请求teamLeader.processRequest(new LeaveRequest("张三", 2)); // 团队领导批准teamLeader.processRequest(new LeaveRequest("李四", 5)); // 经理批准teamLeader.processRequest(new LeaveRequest("王五", 8)); // CEO批准}
}
解决方案带来的优势:
解耦请求发送者与接收者:
责任链模式使得请求的发送者不需要知道哪一个对象会最终处理这个请求,只需要将请求发送给第一个处理者即可。这样就避免了请求发送者与接收者之间的强耦合关系。
提高系统的可扩展性:
可以轻松地添加新的处理者或者修改现有的处理逻辑而无需更改现有代码,只需调整责任链的构成即可。
简化业务逻辑:
将复杂的业务逻辑分散到各个处理者中,使得每一段逻辑都更加清晰易懂,便于维护和管理。
综上所述,责任链模式非常适合用于需要动态设置处理对象集合的场景。在这个请假审批的例子中,它帮助我们构建了一个既灵活又易于扩展的解决方案,使得我们可以方便地调整审批流程以适应不同的业务需求。
5.效果
Chain ofResponsibility 模式适用于以下条件:
- 有多个的对象可以处理一个请求,哪个对象处理该请求运行时刻自动确定。
- 想在不明确指定接收者的情况下向多个对象中的一个提交一个请求。
- 可处理一个请求的对象集合应被动态指定。
(二)Command模式
1. 模式名称
命令模式(Command Pattern)
2. 意图解决的问题
命令模式旨在将一个请求封装成一个对象,从而使您能够用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。它解耦了请求的发送者和接收者,允许你通过执行命令来替代直接调用方法。
具体应用场景包括但不限于:
- 撤销操作:例如在文本编辑器中,用户可以撤销一系列操作。
- 事务处理:在数据库操作中,可以使用命令模式来实现事务,确保一组操作要么全部成功,要么全部失败。
- 异步任务调度:命令模式可以用来实现任务队列,使得任务可以在未来的某个时刻被执行。
- 宏命令:可以组合多个命令形成一个宏命令,以简化复杂的操作序列。
3. 模式描述
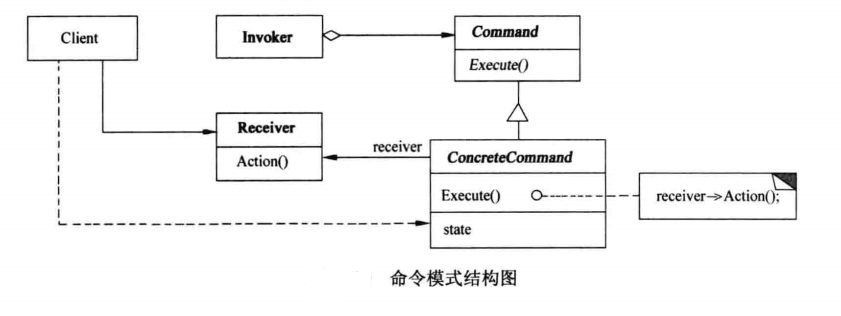
命令模式包含以下几个关键角色:
- 命令接口(Command):声明执行操作的接口,并在某个接收者上绑定加一的动作,调用接收者相应的操作,以实现Execute。
- 具体命令类(Concrete Command):实现了命令接口,定义了一个接收者和动作之间的弱耦合,通常会存储一个对接收者的引用,并且在execute()方法中调用接收者的相应方法。
- 接收者(Receiver):知道如何实施与执行一个请求相关的操作。任何类都可能作为一个接收者。
- 调用者/发起者(Invoker):要求该命令执行这个请求。持有命令对象,并在需要时调用其execute()方法。
- 客户端(Client):创建具体的命令对象,并设置其接收者。
(1)示例代码
// 命令接口(Command)
public interface Command {void execute();
}
//具体命令类(ConcreteCommand)
public class ConcreteCommand implements Command {private Receiver receiver;private String state;public ConcreteCommand(Receiver receiver) {this.receiver = receiver;}@Overridepublic void execute() {// 在执行命令时,可以设置或使用状态System.out.println("ConcreteCommand: Setting receiver state to " + state);receiver.action();}
}
// 接收者(Receiver)
public class Receiver {public void action() {System.out.println("Receiver: Performing the action.");}
}
// 调用者(Invoker)
public class Invoker {private Command command;public void setCommand(Command command) {this.command = command;}public void invoke() {if (command != null) {command.execute();} else {System.out.println("No command set.");}}
}
客户端(Client)
public class Client {public static void main(String[] args) {// 创建接收者对象Receiver receiver = new Receiver();// 创建具体命令对象,并将接收者传递给它ConcreteCommand concreteCommand = new ConcreteCommand(receiver);// 创建调用者对象,并将命令对象设置给它Invoker invoker = new Invoker();invoker.setCommand(concreteCommand);// 执行命令invoker.invoke();}
}
在这个示例中:
Command是一个接口,定义了一个 execute() 方法。ConcreteCommand是具体的命令类,实现了 Command 接口。它持有一个 Receiver 对象的引用,并在 execute() 方法中调用了 Receiver 的 action() 方法。Receiver是接收者类,它包含了一个 action() 方法,该方法代表了具体的业务逻辑。Invoker是调用者类,它持有一个 Command 对象的引用,并通过 invoke() 方法来执行命令。Client是客户端类,它负责创建接收者、命令和调用者对象,并将它们组装在一起。
通过这种方式,命令模式实现了请求发送者(客户端)与接收者(Receiver)之间的解耦,使得系统更加灵活和易于扩展。
4.应用场景
(1)场景背景:
在开发一个文本编辑器时,需要实现“撤销”(Undo)和“重做”(Redo)的功能。用户可以执行多种操作,如插入文本、删除文本、改变字体样式等,并且希望能够撤销这些操作以恢复到之前的状态。
(2)遇到的困难:
复杂性增加:
如果直接在代码中硬编码每一种操作的撤销逻辑,会导致代码非常复杂且难以维护。例如,对于每一个操作都需要编写相应的撤销方法,并确保它们正确地恢复到操作前的状态。
紧耦合问题:
操作的具体执行逻辑与撤销逻辑紧密耦合在一起,这使得代码难以扩展或修改。如果将来添加新的操作类型,必须同时更新执行和撤销的逻辑。
状态管理难题:
要支持撤销功能,系统需要记录每一次操作的状态变化。如果没有良好的设计,管理和追踪这些状态变化将变得十分棘手。
(3)Command模式如何解决这个问题
通过引入命令模式,可以将每个操作封装成一个具体的命令对象。这样做的好处是能够将请求发送者(如用户界面)与请求接收者(如文档模型)解耦,并且方便地实现撤销和重做功能。
//定义一个 Command 接口,包含两个方法:execute() 用于执行操作,undo() 用于撤销操作。
public interface Command {void execute();void undo();
}// 对于每种操作(如插入文本、删除文本等),创建一个实现了 Command 接口的具体命令类。每个命令类负责调用接收者的相应方法来执行或撤销操作。
public class InsertTextCommand implements Command {private TextEditor textEditor;private String text;private int position;public InsertTextCommand(TextEditor textEditor, String text, int position) {this.textEditor = textEditor;this.text = text;this.position = position;}@Overridepublic void execute() {textEditor.insertText(text, position);}@Overridepublic void undo() {textEditor.deleteText(position, text.length());}
}
// 创建一个 TextEditor 类作为接收者,它包含了实际的业务逻辑,比如插入文本和删除文本的方法。
public class TextEditor {private StringBuilder content = new StringBuilder();public void insertText(String text, int position) {content.insert(position, text);System.out.println("Inserted: " + text + " at position " + position);}public void deleteText(int position, int length) {content.delete(position, position + length);System.out.println("Deleted " + length + " characters from position " + position);}
}
//创建一个 History 类作为调用者,它可以保存一组命令对象,并提供撤销和重做功能。
public class History {private Stack<Command> commands = new Stack<>();private Stack<Command> undoneCommands = new Stack<>();public void executeCommand(Command command) {command.execute();commands.push(command);undoneCommands.clear(); // Clear the redo stack when a new command is executed.}public void undo() {if (!commands.isEmpty()) {Command command = commands.pop();command.undo();undoneCommands.push(command);}}public void redo() {if (!undoneCommands.isEmpty()) {Command command = undoneCommands.pop();command.execute();commands.push(command);}}
}
// 客户端调用
public class Client {public static void main(String[] args) {TextEditor editor = new TextEditor();History history = new History();// 执行插入文本操作Command insertTextCommand = new InsertTextCommand(editor, "Hello", 0);history.executeCommand(insertTextCommand);// 执行另一个插入文本操作Command anotherInsertTextCommand = new InsertTextCommand(editor, " World", 5);history.executeCommand(anotherInsertTextCommand);// 撤销最后一个操作history.undo();// 重做最后一次撤销的操作history.redo();}
}
解决方案带来的优势:
解耦请求发送者与接收者:
命令模式将请求的发送者(如用户界面)与接收者(如文档模型)完全解耦。这意味着你可以独立地修改或替换任何一方,而不会影响另一方。
易于实现撤销和重做功能:
由于每个命令都包含了执行和撤销的逻辑,因此很容易实现撤销和重做功能。只需简单地存储命令对象的历史记录即可。
简化状态管理:
使用命令模式后,状态的变化由命令对象自己管理,这使得整个系统的状态管理变得更加清晰和容易控制。
综上所述,命令模式非常适合需要将请求封装为对象的场景,特别是在需要支持撤销/重做功能的情况下。在这个文本编辑器的例子中,命令模式帮助我们构建了一个既灵活又易于扩展的解决方案,使得我们可以方便地添加新的操作类型并实现复杂的编辑功能。
5.效果
Command模式适用于以下场景:
抽象出待执行的动作以参数化某对象
Command模式是过程语言中的回调(callback)机制的一个面向对象的替代品。它允许将一个请求封装成一个对象,从而可以使用不同的方法来指定、排列和执行请求。
在不同的时刻指定、排列和执行请求
一个Command对象可以有一个与初始请求无关的生存期。这意味着如果一个请求的接收者可以用一种与地址空间无关的方式表达,那么就可以将负责该请求的命令对象传递给另一个不同的进程并在那儿实现该请求。
支持取消操作
Command的Execute操作可以在实施操作前将状态存储起来,在取消操作时这个状态用来消除该操作的影响。为了支持撤销功能,Command接口必须添加一个Unexecute操作,该操作用于取消上一次Execute调用的效果。执行过的命令被存储在一个历史列表中,可以通过向后和向前遍历这一列表并分别调用Unexecute和Execute来实现重数不限的“取消”和“重做”。
支持修改日志
这样当系统崩溃时,这些修改可以被重做一遍。在Command接口中添加装载操作和存储操作,可以用来保持变动的一个一致的修改日志。从崩溃中恢复的过程包括从磁盘中重新读入记录下来的命令并用Execute操作重新执行它们。
用构建在原语操作上的高层操作构造一个系统
这样一种结构在支持事务(transaction)的信息系统中很常见。Command模式提供了对事务进行建模的方法。Command有一个公共接口,使得可以用同一种方式调用所有的事务,同时使用该模式也易于添加新事务以扩展系统。
(三)Interpreter模式(解释器)
1. 模式名称
Interpreter设计模式
2. 意图解决的问题
Interpreter设计模式主要用于解决如何定义一个语言的文法,并提供解释器用于解析该语言中的语句。它通常适用于需要处理小型、特定领域语言(DSL)的场景,通过构建抽象语法树(AST)来表示语言中的句子,并对这些句子进行解释执行。这种模式使得我们能够轻松扩展或修改语言的语法,而无需改变现有代码。
3. 模式描述
Interpreter设计模式的核心思想是为了解释一种语言的表达式,首先需要定义该语言的文法,然后创建相应的解释器类来解释这个语言中的每一条规则。以下是Interpreter模式的基本组成部分:
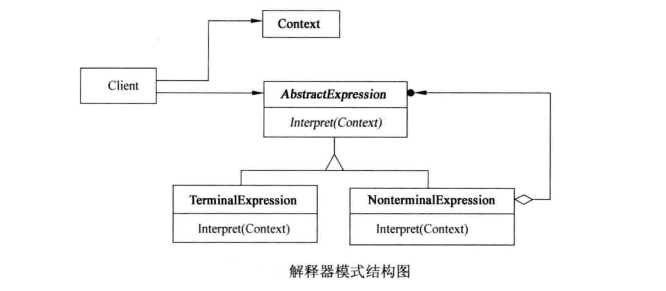
- 抽象表达式(Abstract Expression):声明一个抽象的解释操作,这个接口为所有具体表达式所遵循。
- 终结符表达式(Terminal Expression):实现与文法中的终结符相关的解释操作。每个终结符表达式类对应于文法中的一个终结符。
- 非终结符表达式(Nonterminal Expression):为文法中的每一条规则都至少需要一个非终结符表达式类。每个类都实现了对子表达式的解释方法,并通过组合其他表达式(包括终结符和非终结符表达式)来表示复杂的语法规则。
- 上下文(Context):包含解释器之外的一些全局信息。这些信息可能被解释过程中的不同表达式使用。
- 客户端(Client):构建(或被给定)表示该语言中特定句子或表达式的抽象语法树。这个抽象语法树由终结符表达式和非终结符表达式的实例组成。然后,客户端调用解释操作。
通过这种方式,Interpreter设计模式允许我们将复杂表达式的解释工作分散到多个小类中,每个类负责解释表达式的一个部分。这种方法不仅提高了代码的模块化程度,也使得添加新的解释逻辑变得相对简单。
然而,值得注意的是,当语言非常复杂或者有大量规则时,使用Interpreter模式可能会导致类的数量急剧增加,从而加大系统的复杂性。因此,它更适合应用于小型语言或特定领域的语言。
(1)示例代码
/*** 抽象表达式类是所有表达式的基类。* 它声明了一个 interpret 方法,用于解释表达式。*/
public abstract class AbstractExpression {public abstract void interpret(Context context);
}
/*** 终结符表达式代表语言中的终结符。* 它实现了抽象表达式接口,并提供了具体的解释逻辑。*/
public class TerminalExpression extends AbstractExpression {private String data;public TerminalExpression(String data) {this.data = data;}@Overridepublic void interpret(Context context) {// 如果输入字符串以当前终结符开头,则将其添加到输出中,并从输入中移除if (context.getInput().startsWith(data)) {context.setOutput(context.getOutput() + data);context.setInput(context.getInput().substring(data.length()));}}
}
/*** 非终结符表达式表示语言中的组合规则。* 它包含多个子表达式,并按顺序调用它们的 interpret 方法。*/
public class NonterminalExpression extends AbstractExpression {private AbstractExpression expression1;private AbstractExpression expression2;public NonterminalExpression(AbstractExpression expression1, AbstractExpression expression2) {this.expression1 = expression1;this.expression2 = expression2;}@Overridepublic void interpret(Context context) {// 依次解释两个子表达式expression1.interpret(context);expression2.interpret(context);}
}
/*** 上下文类用于存储解释过程中所需的信息。* 它包含了输入字符串和输出结果。*/
public class Context {private String input;private String output;public Context(String input) {this.input = input;this.output = "";}public String getInput() {return input;}public void setInput(String input) {this.input = input;}public String getOutput() {return output;}public void setOutput(String output) {this.output = output;}
}
/*** 客户端类负责构建抽象语法树并执行解释过程。*/
public class Client {public static void main(String[] args) {// 初始化上下文,输入为 "abc"Context context = new Context("abc");// 构建解释器:先解析 "a",再解析 "b"AbstractExpression expression = new NonterminalExpression(new TerminalExpression("a"),new TerminalExpression("b"));// 执行解释操作expression.interpret(context);// 输出最终的输入和输出结果System.out.println("Input: " + context.getInput());System.out.println("Output: " + context.getOutput());}
}
运行结果说明
在这个例子中,我们定义了一个简单的语言,其中包含两个终结符 “a” 和 “b”,以及一个非终结符,它表示 “a” 和 “b” 的组合。
- 输入:“abc”
- 处理过程:
- 第一步,匹配 “a”,将其加入输出,剩余输入变为 “bc”。
- 第二步,匹配 “b”,将其加入输出,剩余输入变为 “c”。
- 输出:“ab”
该示例展示了如何通过Interpreter设计模式实现对简单语言的解析。虽然这个例子非常基础,但在实际应用中,可以扩展更多的终结符和非终结符表达式,以支持更复杂的语法规则。Interpreter模式非常适合用于小型特定领域语言(DSL)的设计和实现。
4.应用场景
(1)场景背景:
在开发一个数据库管理系统时,需要实现一个 SQL 查询解析器。用户可以通过输入 SQL 语句来查询、更新或删除数据。系统需要将这些 SQL 语句转换为内部可执行的逻辑,并返回相应的结果。
(2)遇到的困难:
复杂的语法规则:
SQL 是一种结构化语言,包含多种语法结构,如 SELECT、FROM、WHERE、JOIN、GROUP BY 等。每种结构都可能有不同的语义和处理方式。直接硬编码所有语法规则会导致代码复杂且难以维护。
灵活性与扩展性不足:
如果未来需要支持新的 SQL 语法(例如添加对子查询的支持),必须大幅修改现有代码,这不仅增加了开发成本,还可能导致潜在的错误。
难以调试与测试:
将整个解析过程集中在一个类中,使得调试变得困难,同时也不利于单元测试的编写。
无法复用解析逻辑:
如果将来需要在其他项目中使用类似的 SQL 解析功能,由于代码耦合度高,很难直接复用现有的解析模块。
(3)Interpreter 模式如何解决这个问题:
通过引入解释器模式(Interpreter Pattern),可以将 SQL 语言的语法规则映射为一组对象结构,每个对象对应一个语法规则。这样可以将复杂的解析逻辑分散到多个小类中,从而提高系统的可维护性和可扩展性。
/*** 抽象表达式接口:定义了解释器的基本行为。* 所有具体的表达式(终结符/非终结符)都必须实现 interpret 方法。*/
public interface Expression {void interpret(Context context);
}
/*** 终结符表达式:表示 SQL 中的基本元素,如字段名或表名。*/
public class FieldExpression implements Expression {private String token;public FieldExpression(String token) {this.token = token;}@Overridepublic void interpret(Context context) {// 如果输入以当前 token 开头,则匹配成功if (context.getInput().startsWith(token)) {context.setOutput("识别到字段/表名: " + token + "\n");context.setInput(context.getInput().substring(token.length()).trim());} else {context.setOutput("错误:期望匹配 '" + token + "',但输入是: " + context.getInput() + "\n");}}
}
/*** 非终结符表达式:表示 SELECT 字段 FROM 表 的语法结构。*/
public class SelectClauseExpression implements Expression {private Expression fieldExpression;private Expression tableExpression;public SelectClauseExpression(Expression field, Expression table) {this.fieldExpression = field;this.tableExpression = table;}@Overridepublic void interpret(Context context) {context.setOutput("开始解析 SELECT 子句...\n");// 先解释字段部分fieldExpression.interpret(context);// 再解释表名部分tableExpression.interpret(context);context.setOutput("SELECT 子句解析完成。\n");}
}
/*** 上下文类:在解释过程中保存输入输出信息。*/
public class Context {private String input;private StringBuilder output;public Context(String input) {this.input = input.trim();this.output = new StringBuilder();}public String getInput() {return input;}public void setInput(String input) {this.input = input.trim();}public StringBuilder getOutput() {return output;}public void setOutput(String outputLine) {this.output.append(outputLine);}
}
/*** 客户端类:负责创建表达式树并启动解释过程。*/
public class Client {public static void main(String[] args) {// 输入 SQL 语句String sqlQuery = "SELECT name FROM users";System.out.println("原始 SQL 查询语句: " + sqlQuery);// 创建上下文Context context = new Context(sqlQuery);// 构建抽象语法树Expression fieldExpr = new FieldExpression("name");Expression tableExpr = new FieldExpression("users");Expression selectExpr = new SelectClauseExpression(fieldExpr, tableExpr);// 启动解释过程selectExpr.interpret(context);// 输出最终结果System.out.println("\n解析过程日志:\n" + context.getOutput());}
}
运行结果示例:
假设输入 SQL 是:“SELECT name FROM users”
输出将会是:
原始 SQL 查询语句: SELECT name FROM users解析过程日志:
开始解析 SELECT 子句...
识别到字段/表名: name
识别到字段/表名: users
SELECT 子句解析完成。
5.效果
Interpreter模式适用于当有一个语言需要解释执行,并且可将该语言中的句子表示为一个抽象语法树时,以下情况效果最好:
该文法简单。对于复杂的发文,文法的类层次变得庞大而无法管理。此时语法分析程序生成器这样的工具是更好的选择。它们无须构建抽象语法树即可解释表达式,这样可以节省空间还可能节省时间。
效率不是一个关键问题。最高效的解释器通常不是通过直接解释语法分析树实现的,而是首先将它们转换成另一种形式。不过,即使在这种情况下,转换器仍然可用该模式实现。
(四)Iterator
1. 模式名称
Iterator(迭代器)模式
2. 意图解决的问题
Iterator设计模式主要用于解决遍历集合的接口问题,它提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。这种模式可以让你在不暴露底层实现细节的情况下,为遍历不同的数据结构提供统一的接口,从而简化了集合的遍历过程,并且支持多种遍历方式(如前向、后向等),同时也让算法与集合的数据结构解耦,增强了程序的灵活性和可维护性。
3. 模式描述
Iterator模式的核心在于将数据的遍历行为从聚合对象中分离出来,封装进一个独立的迭代器对象。这样,聚合对象只负责其核心职责——管理和组织数据,而迭代器则专门负责遍历这些数据。具体来说,这个模式涉及以下几个关键角色:
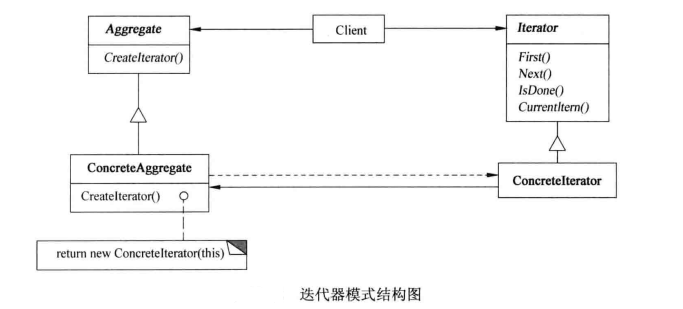
- Aggregate(聚合):定义创建Iterator对象的接口。
- ConcreteAggregate(具体聚合):实现了Aggregate接口,返回一个ConcreteIterator的具体实例。
- Iterator(迭代器):定义访问和遍历元素的接口,通常包含hasNext()和next()两个基本方法。
- ConcreteIterator(具体迭代器):实现了Iterator接口,同时跟踪当前遍历的元素位置,并提供了获取下一个元素的方法。
通过这种方式,Iterator模式使得我们可以透明地遍历聚合对象的不同数据结构(比如数组、链表等),而无需关心这些数据结构的具体实现细节。这样一来,不仅提高了代码的复用性,也增加了设计的灵活性。例如,在需要更改遍历算法或数据结构时,只需调整迭代器的实现即可,不需要修改使用这些迭代器的代码。
// 定义Iterator接口
public interface Iterator {Object first();Object next();boolean isDone();Object currentItem();
}
// 定义Aggregate接口
public interface Aggregate {Iterator createIterator();
}
// 实现具体聚合类ConcreteAggregate
public class ConcreteAggregate implements Aggregate {private List<Object> items = new ArrayList<>();public ConcreteAggregate() {// 初始化一些数据for (int i = 0; i < 5; i++) {items.add("Item " + i);}}@Overridepublic Iterator createIterator() {return new ConcreteIterator(this);}public Object getItem(int index) {return items.get(index);}public int getCount() {return items.size();}
}
// 实现具体迭代器类ConcreteIterator
public class ConcreteIterator implements Iterator {private ConcreteAggregate aggregate;private int currentIndex = 0;public ConcreteIterator(ConcreteAggregate aggregate) {this.aggregate = aggregate;}@Overridepublic Object first() {currentIndex = 0;return aggregate.getItem(currentIndex);}@Overridepublic Object next() {Object ret = null;if (currentIndex < aggregate.getCount()) {ret = aggregate.getItem(currentIndex);currentIndex++;}return ret;}@Overridepublic boolean isDone() {return currentIndex >= aggregate.getCount();}@Overridepublic Object currentItem() {return aggregate.getItem(currentIndex);}
}
// 客户端代码
public class Client {public static void main(String[] args) {ConcreteAggregate aggregate = new ConcreteAggregate();Iterator iterator = aggregate.createIterator();while (!iterator.isDone()) {System.out.println(iterator.next());}}
}
4.应用场景
(1)场景描述
想象一下一个图书馆的书籍管理系统,该系统需要管理大量的书籍信息。这些书籍可能存储在不同的数据结构中,比如一些书籍信息存储在数组中,另一些则存储在链表或哈希表中。为了提供一致的用户体验,系统需要支持对所有书籍进行遍历操作,无论它们存储在何种数据结构中。
(2)遇到的困难
- 多样性问题:不同数据结构有不同的遍历方式,如果直接使用这些数据结构提供的方法来遍历元素,代码将会依赖于具体的数据结构实现。
- 扩展性问题:如果将来需要增加新的数据结构来存储书籍信息,那么现有的遍历逻辑可能需要修改,这违背了开闭原则(对扩展开放,对修改关闭)。
- 维护性问题:直接与数据结构交互的代码会变得难以维护和理解,尤其是当有多种遍历需求时(如顺序遍历、逆序遍历等)。
(3)Iterator模式如何解决问题:
Iterator模式通过将遍历集合的行为抽象出来,提供了一个统一的接口用于访问聚合对象中的各个元素,从而解决了上述问题。
- 统一接口:为所有的聚合对象定义一个标准的迭代器接口,使得客户端代码可以不考虑底层数据结构的具体实现,只通过这个接口来进行遍历操作。这样就解决了多样性的问题。
- 封装变化:迭代器模式将遍历算法封装在其自身内部,因此即使改变了聚合对象的内部结构,只要迭代器接口保持不变,客户端代码就不需要做任何改动。这有助于提高系统的可扩展性和灵活性。
- 简化客户端代码:客户端不需要了解聚合对象的内部结构,只需要知道如何获取一个迭代器,并通过它来遍历元素即可。这大大简化了客户端代码,使其更加简洁且易于理解。
例如,在上述图书馆书籍管理系统中,我们可以为每种存储书籍信息的数据结构创建相应的迭代器类。这样一来,无论是哪种数据结构,客户端代码都只需调用createIterator()方法获取对应的迭代器,然后通过next()、hasNext()等方法来遍历书籍信息,而无需关心具体的遍历细节。这样不仅提高了代码的复用性,也增强了系统的可维护性和灵活性。
// 迭代器通用接口
public interface Iterator {boolean hasNext(); // 是否还有下一个元素Object next(); // 获取下一个元素
}// 聚合对象通用接口
public interface Aggregate {Iterator createIterator(); // 创建对应的迭代器
}
// 使用数组存储书籍的具体聚合类
public class ArrayBookCollection implements Aggregate {private String[] books;private int index = 0;public ArrayBookCollection(int size) {books = new String[size]; // 初始化固定大小的数组}public void addBook(String book) {if (index < books.length) {books[index++] = book; // 添加书籍到数组中}}@Overridepublic Iterator createIterator() {return new ArrayBookIterator(this); // 返回对应迭代器}// 提供给迭代器访问的方法public String getBookAt(int index) {return books[index];}public int getSize() {return books.length;}
}
// 针对数组的迭代器
public class ArrayBookIterator implements Iterator {private ArrayBookCollection collection;private int index = 0;public ArrayBookIterator(ArrayBookCollection collection) {this.collection = collection;}@Overridepublic boolean hasNext() {return index < collection.getSize() && collection.getBookAt(index) != null;}@Overridepublic Object next() {if (this.hasNext()) {return collection.getBookAt(index++);}return null;}
}
import java.util.LinkedList;// 使用链表存储书籍的具体聚合类
public class LinkedListBookCollection implements Aggregate {private LinkedList<String> books = new LinkedList<>();public void addBook(String book) {books.add(book);}@Overridepublic Iterator createIterator() {return new LinkedListBookIterator(this); // 返回链表专用的迭代器}// 提供给迭代器访问的方法public String getBookAt(int index) {return books.get(index);}public int getSize() {return books.size();}
}
// 针对链表的迭代器
public class LinkedListBookIterator implements Iterator {private LinkedListBookCollection collection;private int index = 0;public LinkedListBookIterator(LinkedListBookCollection collection) {this.collection = collection;}@Overridepublic boolean hasNext() {return index < collection.getSize();}@Overridepublic Object next() {if (this.hasNext()) {return collection.getBookAt(index++);}return null;}
}
public class Client {public static void main(String[] args) {// 使用数组存储的书籍集合ArrayBookCollection arrayCollection = new ArrayBookCollection(5);arrayCollection.addBook("Java编程思想");arrayCollection.addBook("设计模式之禅");// 使用链表存储的书籍集合LinkedListBookCollection linkedListCollection = new LinkedListBookCollection();linkedListCollection.addBook("Effective Java");linkedListCollection.addBook("Head First 设计模式");// 统一方式遍历不同结构的数据printBooks(arrayCollection);System.out.println("---------");printBooks(linkedListCollection);}// 客户端只需知道Aggregate和Iterator接口即可public static void printBooks(Aggregate aggregate) {Iterator iterator = aggregate.createIterator();while (iterator.hasNext()) {System.out.println("书籍:" + iterator.next());}}
}/* 输出结果:
书籍:Java编程思想
书籍:设计模式之禅
---------
书籍:Effective Java
书籍:Head First 设计模式
*/
5.效果
Iterator 模式适用于:
- 访问一个聚合对象的内容而无须暴露它的内部表示。
- 支持对聚合对象的多种遍历。
- 为遍历不同的聚合结构提供一个统一的接口。
(五)Mediator
1. 模式名称
Mediator(中介者)设计模式
2. 意图解决的问题
Mediator设计模式旨在解决对象之间复杂的交互问题。在没有使用Mediator模式时,系统中的对象可能会直接相互引用并进行通信,这会导致高度耦合的系统,增加维护难度,并降低系统的可扩展性。具体来说,它试图解决以下问题:
- 减少对象间的依赖:当多个对象需要相互通信时,如果没有中介者,它们之间的关系会变得非常复杂,形成一个复杂的网状结构。
- 提高模块的独立性:通过引入中介者对象来封装一系列对象的交互细节,使得各个对象不需要显式地相互引用,从而提高了模块的独立性和可复用性。
- 简化对象协议:将对象间的通信逻辑集中到中介者中管理,可以大大简化对象间原本需要定义的协议和接口。
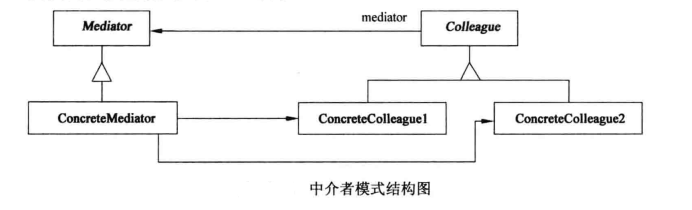
3. 模式描述
Mediator模式是一种行为设计模式,它将一组对象的交互逻辑封装在一个单独的中介者对象中,而不是让这些对象直接相互引用。这样就减少了它们之间的依赖关系,促进了松散耦合。以下是Mediator模式的基本组成部分:
- 抽象中介者(Mediator):定义了同事对象(Colleague)用来发送请求的一个接口,但不实现具体的业务逻辑。通常是一个接口或抽象类。
- 具体中介者(Concrete Mediator):实现了中介者接口,并协调各同事对象之间的交互。了解并维护它的同事对象,并负责转发他们的请求给其他适当的同事对象。
- 抽象同事类(Colleague):定义了各同事对象与中介者通信的方法。每个同事类都知道它的中介者对象,且与中介者通信而非直接与其他同事通信。
- 具体同事类(Concrete Colleague):每一个具体同事类都实现了抽象同事类中的方法,每个同事对象负责处理自己的行为,但将同事之间的交互委托给中介者对象。
通过这种方式,Mediator模式允许你以较小的代价对同事对象进行修改、替换或扩展,而无需改变其他同事对象或中介者本身的行为。这种模式特别适用于那些对象之间存在大量复杂交互的场景,如图形用户界面(GUI)组件之间的交互,或是分布式应用中不同服务之间的协作等。
(1)示例代码
// 定义中介者接口
interface Mediator {// 声明一个方法,用于同事对象之间的通信void send(String message, Colleague colleague);
}// 定义具体中介者类
class ConcreteMediator implements Mediator {private ConcreteColleague1 colleague1;private ConcreteColleague2 colleague2;// 设置同事对象public void setColleague1(ConcreteColleague1 colleague1) {this.colleague1 = colleague1;}public void setColleague2(ConcreteColleague2 colleague2) {this.colleague2 = colleague2;}@Overridepublic void send(String message, Colleague colleague) {if (colleague == colleague1) {colleague2.receive(message); // 如果发送者是同事1,则由同事2接收消息} else {colleague1.receive(message); // 如果发送者是同事2,则由同事1接收消息}}
}// 定义同事类接口
interface Colleague {void receive(String message); // 接收消息的方法void send(String message, Mediator mediator); // 发送消息的方法
}// 定义具体同事类1
class ConcreteColleague1 implements Colleague {private Mediator mediator;public ConcreteColleague1(Mediator mediator) {this.mediator = mediator;}@Overridepublic void receive(String message) {System.out.println("同事1接收到消息:" + message);}@Overridepublic void send(String message, Mediator mediator) {System.out.println("同事1发送消息:" + message);mediator.send(message, this);}
}// 定义具体同事类2
class ConcreteColleague2 implements Colleague {private Mediator mediator;public ConcreteColleague2(Mediator mediator) {this.mediator = mediator;}@Overridepublic void receive(String message) {System.out.println("同事2接收到消息:" + message);}@Overridepublic void send(String message, Mediator mediator) {System.out.println("同事2发送消息:" + message);mediator.send(message, this);}
}// 测试类
public class MediatorPatternDemo {public static void main(String[] args) {ConcreteMediator mediator = new ConcreteMediator();ConcreteColleague1 colleague1 = new ConcreteColleague1(mediator);ConcreteColleague2 colleague2 = new ConcreteColleague2(mediator);mediator.setColleague1(colleague1);mediator.setColleague2(colleague2);colleague1.send("你好", mediator);colleague2.send("你好", mediator);}
}
4.应用场景
(1)背景介绍:
想象一个简单的在线聊天室系统,其中多个用户可以实时发送消息给彼此。在没有中介者模式的情况下,每个用户(或客户端)需要直接与其他所有用户建立连接,并且当有新的消息时,需向其他所有用户广播该消息。
(2)遇到的困难:
- 复杂度增加:随着用户数量的增加,每个用户都需要与系统中的其他用户保持连接,这会导致网络复杂度和管理难度的急剧增加。
- 耦合性高:每个用户都必须了解其他用户的存在以及如何与之通信,这导致了高度的耦合,降低了系统的可维护性和扩展性。
- 难以管理的状态:由于每个用户都需要跟踪自己的状态以及其他用户的响应情况,这使得状态管理和同步变得困难。
(3)中介者模式是如何解决问题的?
在引入中介者模式后,上述问题得到了有效的解决:
- 集中控制:通过引入一个中介者(如服务器端的聊天室控制器),所有的用户只需要与这个中介者进行交互,而不需要直接与其他用户建立连接。这样就大大简化了用户之间的通信逻辑。
- 降低耦合度:各个用户之间不再需要相互了解或直接通信,他们只需知道中介者的存在即可。这种设计极大地降低了系统的耦合度,提高了代码的可维护性和可扩展性。
- 简化状态管理:因为所有用户的通信都经过中介者,所以状态管理和同步变得更加容易。中介者可以负责处理消息的转发、状态的更新等任务,从而减轻了单个用户的工作负担。
具体实现方式: - 定义中介者接口:首先定义一个中介者接口,该接口包含必要的方法,比如发送消息的方法。
创建具体中介者类:然后创建一个具体的中介者类来实现这些接口方法。在这个例子中,具体中介者可以是聊天室服务器,它负责接收来自某个用户的消息并将其转发给其他用户。 - 同事类:同时,还需要定义同事类(即用户端),它们使用中介者来与其他同事进行通信。同事类只关心如何与中介者交流,而不必担心其他同事的具体实现细节。
通过这种方式,Mediator模式成功地解决了聊天室系统中的复杂度、耦合度和状态管理等问题,使得系统更加简洁、易于维护和扩展。
(4)示例代码
以下是基于中介者模式的简单聊天室系统的Java实现。这个示例包括了中介者(聊天室控制器)和同事(用户)之间的交互。
// 中介者接口
interface ChatRoomMediator {void showMessage(User user, String message); // 显示消息的方法
}// 具体中介者类
class ChatRoom implements ChatRoomMediator {@Overridepublic void showMessage(User user, String message) {System.out.println("[" + user.getName() + "] : " + message);}
}// 同事类接口
abstract class User {protected ChatRoomMediator mediator;protected String name;public User(ChatRoomMediator mediator, String name) {this.mediator = mediator;this.name = name;}public abstract void send(String message); // 发送消息的方法public abstract void receive(String message); // 接收消息的方法public String getName() { return name; } // 获取用户名字的方法
}// 具体同事类
class ChatUser extends User {public ChatUser(ChatRoomMediator mediator, String name) {super(mediator, name);}@Overridepublic void send(String message) {System.out.println(this.getName() + " 正在发送消息: " + message);mediator.showMessage(this, message); // 通过中介者发送消息}@Overridepublic void receive(String message) {System.out.println(this.getName() + " 收到了消息: " + message);}
}// 测试类
public class MediatorPatternDemo {public static void main(String[] args) {ChatRoomMediator chatRoom = new ChatRoom(); // 创建聊天室实例User user1 = new ChatUser(chatRoom, "张三"); // 创建用户张三User user2 = new ChatUser(chatRoom, "李四"); // 创建用户李四user1.send("你好,李四!");user2.send("嗨,张三,很高兴!");}
}
此代码展示了如何使用中介者模式来简化用户间的直接通信,降低了用户之间的耦合度,使得系统更加灵活、易于扩展和维护。
5.效果
Mediator 模式适用于:
- 一组对象以定义良好但是复杂的方式进行通信,产生的相互依赖关系结构混乱且难以理解。
- 一个对象引用其他很多对象并且直接与这些对象通信,导致难以复用该对象。
- 想定制一个分布在多个类中的行为,而又不想生成太多的子类。
(六)Memento模式(备忘录)
1. 模式名称
Memento(备忘录)设计模式
2. 意图解决的问题
Memento设计模式的主要意图是捕捉一个对象的内部状态,并在外部保存这个状态,以便以后可以恢复到这个先前的状态。这种模式允许你在不暴露对象实现细节的情况下进行状态的存储和恢复操作,从而支持撤销操作或回滚机制。
具体来说,Memento模式解决了以下问题:
- 如何在一个对象的外部保存该对象的状态,而不破坏封装性。
- 如何让对象能够轻松地恢复到之前的状态,而不需要知道这些状态是如何被保存或恢复的。
- 支持多级撤销和重做功能。
3. 模式描述
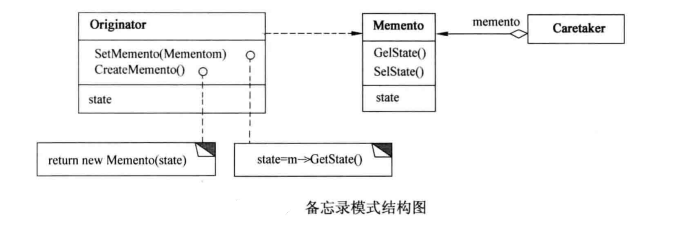
Memento模式包含三个主要角色:
- Originator(原发器):需要备份和恢复其内部状态的对象。它负责创建一个memento来记录它的当前内部状态,并使用memento来恢复其内部状态。
- Memento(备忘录):存储Originator的内部状态,并防止除了Originator之外的其他对象访问memento。Memento有两个接口:窄接口提供给其他对象以限制他们只能通过caretaker与memento交互;宽接口提供给originator,使其能访问所有数据用于恢复其状态。
- Caretaker(管理者):负责保存memento但并不修改它的内容。它持有memento对象,但只将其传递回originator,当originator请求时用来恢复状态。
Memento模式通常的工作流程如下:
- Originator当前的状态需要被保存时,它会创建一个memento对象并将自己的状态存储到memento中。
- 管理者caretaker获取并存储这个memento对象。
- 当需要恢复状态时,caretaker将memento返回给originator。
- Originator从memento中恢复其状态。
通过这种方式,Memento模式能够在不影响对象本身的前提下,安全地保存和恢复对象的状态,非常适合于实现如撤销/重做等特性。
(1)示例代码
// Memento类:存储Originator的内部状态
class Memento {private String state;// 构造函数,用于初始化状态public Memento(String state) {this.state = state;}// 获取状态的方法public String getState() {return state;}
}// Originator类:需要保存和恢复其内部状态的对象
class Originator {private String state;// 创建一个Memento对象来保存当前状态public Memento createMemento() {return new Memento(state);}// 使用Memento对象恢复到之前的状态public void setMemento(Memento memento) {state = memento.getState();}// 设置状态的方法public void setState(String state) {this.state = state;System.out.println("Originator: Setting state to " + state);}// 获取状态的方法public String getState() {return state;}
}// Caretaker类:负责保存Memento对象
class Caretaker {private List<Memento> mementos = new ArrayList<>();// 添加Memento对象到列表public void addMemento(Memento memento) {mementos.add(memento);}// 从列表获取最近保存的Memento对象并移除它public Memento getRecentMemento() {if (mementos.size() > 0) {return mementos.remove(mementos.size() - 1); // 移除并返回最后一个元素}return null;}
}// 测试类
public class MementoPatternDemo {public static void main(String[] args) {Originator originator = new Originator(); // 创建Originator对象Caretaker caretaker = new Caretaker(); // 创建Caretaker对象originator.setState("State #1"); // 设置初始状态caretaker.saveMemento(originator.createMemento()); // 保存状态到Mementooriginator.setState("State #2"); // 修改状态caretaker.saveMemento(originator.createMemento()); // 再次保存状态到Mementooriginator.setState("State #3"); // 再次修改状态System.out.println("Current State: " + originator.getState());// 恢复到上一个状态originator.setMemento(caretaker.getMemento());System.out.println("First undo: " + originator.getState());// 恢复到最初状态originator.setMemento(caretaker.getMemento());System.out.println("Second undo: " + originator.getState());}
}
4.应用场景
(1)背景介绍:
想象一个简单的文本编辑器,用户可以输入、修改文本内容,并希望能够撤销最近的一系列操作,返回到之前的状态。这要求系统能够记住文本在不同时间点的状态,并允许用户根据需要回退到这些状态。
(2)遇到的困难:
- 状态管理复杂:直接存储和恢复整个文本对象可能会很复杂,特别是当文本对象内部结构复杂时(例如包含格式信息、样式等)。
- 破坏封装性:为了实现撤销功能,可能需要暴露文本对象的内部状态,这会破坏对象的封装性,导致代码难以维护和扩展。
- 内存占用问题:如果需要保存大量历史状态以支持多级撤销,可能会消耗大量的内存资源。
(3)Memento模式是如何解决问题的?
Memento模式通过以下方式解决了上述问题:
- 保持封装边界:Memento模式允许原发器(Originator)创建一个备忘录(Memento),用于存储其内部状态,而无需暴露其实现细节。这意味着可以在不破坏对象封装性的前提下备份和恢复对象状态。
- 简化状态管理:备忘录只负责存储原发器的状态,而管理者(Caretaker)负责管理和传递备忘录。这样就将状态的存储和恢复逻辑与业务逻辑分离,使得代码更加清晰易懂。
- 优化内存使用:虽然Memento模式本身并不直接解决内存占用问题,但通过精心设计备忘录的内容,比如仅保存必要的状态信息而不是整个对象,可以有效地减少内存使用。此外,还可以结合其他策略如状态压缩来进一步优化。
具体来说,在文本编辑器的例子中,每当用户进行一次修改(如插入或删除字符),文本编辑器(作为原发器)都会创建一个备忘录对象来保存当前的文档状态,并将其交给管理者保存。当用户选择撤销操作时,管理者将相应的备忘录传回给原发器,原发器则从备忘录中恢复其状态,从而实现了撤销功能。
这种设计不仅保护了文本编辑器内部状态的封装性,还使得撤销功能易于实现和维护,同时也为未来可能的需求变化提供了良好的扩展性。
(4)示例代码
// 备忘录类,用于保存原发器的状态
class EditorMemento {private final String content;public EditorMemento(String content) {this.content = content;}// 提供给原发器访问备忘录内容的方法public String getContent() {return content;}
}// 原发器类,表示需要保存状态的对象(本例中为文本编辑器)
class TextEditor {private String content;public void setContent(String content) {this.content = content;}public String getContent() {return content;}// 创建并返回一个备忘录对象,包含当前的状态public EditorMemento createState() {return new EditorMemento(content);}// 从备忘录恢复状态public void restoreState(EditorMemento memento) {this.content = memento.getContent();}
}// 管理者类,负责保存和提供备忘录
class History {private final List<EditorMemento> mementos = new ArrayList<>();// 添加一个新的备忘录到历史记录public void addMemento(EditorMemento memento) {mementos.add(memento);}// 获取最近保存的备忘录,并将其从历史记录中移除public EditorMemento getRecentMemento() {if (!mementos.isEmpty()) {return mementos.remove(mementos.size() - 1); // 移除并返回最后一个元素}return null;}
}public class MementoPatternDemo {public static void main(String[] args) {TextEditor editor = new TextEditor(); // 创建文本编辑器实例History history = new History(); // 创建历史管理者实例editor.setContent("First draft");System.out.println("Initial state: " + editor.getContent());history.addMemento(editor.createState()); // 保存当前状态editor.setContent("Second draft, with corrections.");System.out.println("After first edit: " + editor.getContent());history.addMemento(editor.createState()); // 再次保存当前状态editor.setContent("Final version, ready for submission.");System.out.println("After second edit: " + editor.getContent());// 撤销到最后一次保存的状态editor.restoreState(history.getRecentMemento());System.out.println("Undo to second draft: " + editor.getContent());// 再次撤销到更早的状态editor.restoreState(history.getRecentMemento());System.out.println("Undo to initial state: " + editor.getContent());}
}
代码解释:
EditorMemento:这是备忘录类,它封装了文本编辑器的状态(在本例中是字符串content)。它的构造函数接受文本内容,并通过getContent()方法允许原发器恢复其状态。TextEditor:这是原发器类,代表文本编辑器。它拥有一个setContent()方法来改变文本内容,getContent()方法获取当前文本内容,createState()方法创建一个备忘录以保存当前状态,以及restoreState()方法从备忘录中恢复状态。History:这是管理者类,它使用一个列表来保存多个备忘录对象,以便支持多级撤销。addMemento()方法添加一个新的备忘录到历史记录,而getRecentMemento()方法则返回最近保存的备忘录并将其从历史记录中移除。MementoPatternDemo:这是测试类,演示了如何使用上述类来模拟文本编辑器的撤销功能。
5.效果
Memento 模式适用于:
- 必须保存一个对象在某一个时刻的(部分)状态,这样以后需要时它才能恢复到先前的状态。
- 如果一个用接口来让其他对象直接得到这些状态,将会暴露对象的实现细节并破坏对象的封装性。
(七)Observer模式(观察者)
1. 模式名称
Observer(观察者)设计模式
2. 意图解决的问题
Observer设计模式主要用于处理对象之间的一对多依赖关系,当一个对象的状态发生变化时,所有依赖于它的对象都会自动收到通知并更新。这种模式是实现分布式事件处理系统的基础,极大地提高了对象间通信的灵活性和可复用性。
具体来说,Observer模式解决了以下问题:
- 如何确保一个对象(主题或被观察者)状态的变化能够及时地通知给其他多个对象(观察者),而不需要这些观察者之间有直接的耦合。
- 如何让被观察者的状态变化影响到相关的对象,同时保持系统的松散耦合,使得观察者可以独立地改变和复用。
3. 模式描述
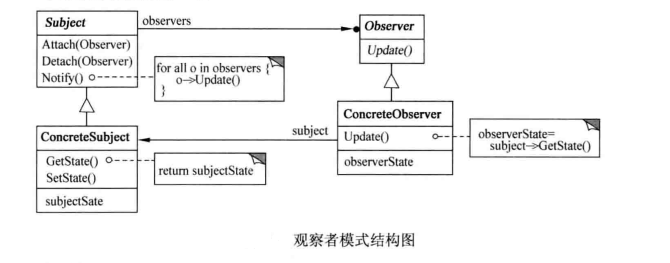
Observer设计模式包含四个主要角色:
- Subject(主题/被观察者):知道其观察者,并提供注册和删除观察者的接口。它还提供了通知所有观察者的机制,通常是在其状态发生改变的时候。
- Observer(观察者):定义了一个更新接口,用于接收来自主题的通知。这个接口通常包括一个update()方法,当主题状态改变时会调用该方法。
- ConcreteSubject(具体主题):实现了Subject接口,包含了可供观察者关注的状态信息。当状态变化时,它会通知已注册的观察者。
- ConcreteObserver(具体观察者):实现了Observer接口,并维护一个指向ConcreteSubject的引用。当ConcreteSubject状态改变并通过调用update()方法通知观察者时,ConcreteObserver可以相应地更新自己的状态或其他操作。
工作流程如下:
- 当ConcreteSubject对象的状态发生改变时,它会调用自身的方法来通知所有已注册的观察者。
- 观察者接收到通知后,通过调用ConcreteSubject提供的方法获取最新的状态,然后根据需要更新自身的状态或执行特定的操作。
- 主题与观察者之间维持着一种订阅关系,但两者之间的耦合度很低,因为它们并不直接相互依赖,而是通过抽象接口进行交互。
这种设计模式非常适合构建反应式系统,在这样的系统中,组件之间需要基于事件驱动的方式进行高效沟通,例如图形用户界面工具包、事件驱动模拟器等。通过使用Observer模式,可以使系统更加灵活、易于扩展和维护。
示例代码
// Observer接口定义了更新方法,所有具体观察者类都需要实现这个接口。
interface Observer {// 当被观察者状态改变时,调用此方法来更新观察者的状态。void update();
}// ConcreteObserver是具体的观察者类,它实现了Observer接口,并维护一个指向ConcreteSubject的引用。
class ConcreteObserver implements Observer {private String observerState;private ConcreteSubject subject;public ConcreteObserver(ConcreteSubject subject) {this.subject = subject;}@Overridepublic void update() {// 更新观察者的状态为被观察者的当前状态observerState = subject.getState();System.out.println("Observer state updated to: " + observerState);}
}// Subject接口定义了添加、删除和通知观察者的方法。
interface Subject {// 添加一个新的观察者到观察者列表中void attach(Observer observer);// 从观察者列表中移除一个观察者void detach(Observer observer);// 通知所有的观察者void notifyObservers();
}// ConcreteSubject是具体的被观察者类,它实现了Subject接口,并维护着自身的状态。
class ConcreteSubject implements Subject {private List<Observer> observers = new ArrayList<>();private String state;@Overridepublic void attach(Observer observer) {observers.add(observer);}@Overridepublic void detach(Observer observer) {observers.remove(observer);}@Overridepublic void notifyObservers() {for (Observer observer : observers) {observer.update(); // 通知每个观察者更新其状态}}// 获取当前状态public String getState() {return state;}// 设置新的状态,并在状态改变后通知所有观察者public void setState(String state) {this.state = state;notifyObservers(); // 状态改变后通知所有观察者}
}public class ObserverPatternDemo {public static void main(String[] args) {ConcreteSubject subject = new ConcreteSubject(); // 创建被观察者实例// 创建两个观察者实例,并将它们注册到被观察者上ConcreteObserver observer1 = new ConcreteObserver(subject);ConcreteObserver observer2 = new ConcreteObserver(subject);subject.attach(observer1);subject.attach(observer2);// 改变被观察者的状态,这将触发所有观察者的update方法subject.setState("First State");subject.setState("Second State");}
}
代码解释:
Observer接口:定义了一个update()方法,所有具体观察者类都必须实现这个方法。当被观察者状态改变时,会调用这个方法来更新观察者的状态。ConcreteObserver类:这是具体的观察者类,实现了Observer接口。它包含了一个指向ConcreteSubject的引用,以便能够获取被观察者的状态。update()方法用于更新观察者的状态为被观察者的当前状态。Subject接口:定义了添加、删除和通知观察者的方法。attach()方法用于添加一个新的观察者到观察者列表中,detach()方法用于从观察者列表中移除一个观察者,notifyObservers()方法用于通知所有的观察者。ConcreteSubject类:这是具体的被观察者类,实现了Subject接口。它维护着自身的状态,并且有一个观察者列表。当它的状态改变时,会调用notifyObservers()方法来通知所有的观察者。ObserverPatternDemo类:这是测试类,演示了如何使用上述类来模拟观察者模式。首先创建了一个被观察者实例和两个观察者实例,并将观察者注册到被观察者上。然后通过改变被观察者的状态来触发观察者的更新操作。
4.应用场景
(1)背景介绍:
想象一个简单的天气预报系统,其中包含多个显示组件(例如当前温度、湿度和压力的显示器),这些组件需要根据气象站的数据变化实时更新。气象站是数据源,它会持续地从传感器获取最新的天气数据,并且每当有新的数据时,所有显示组件都需要同步更新。
(2)遇到的困难:
- 紧密耦合:如果直接在每个显示组件中硬编码与气象站的交互逻辑,这会导致显示组件与气象站之间产生紧密的耦合关系,使得代码难以维护和扩展。
- 状态同步问题:当气象站的数据发生变化时,如何确保所有相关的显示组件都能及时得到通知并更新其显示内容?
- 可扩展性差:如果有新的显示组件需要添加到系统中,或者想要移除某些现有的显示组件,直接修改气象站的代码来适应这些变化将变得复杂且容易出错。
(3)Observer模式是如何解决问题的?
Observer模式通过以下方式解决了上述问题:
- 解耦设计:在Observer模式下,气象站(作为被观察者或主题)与各个显示组件(作为观察者)之间保持了一种松散的耦合关系。气象站不需要知道具体的显示组件是谁,只需要知道有哪些观察者订阅了它的状态变化。这种设计极大地提高了系统的灵活性和可维护性。
- 自动通知机制:每当气象站的数据发生改变时,它会自动通知所有已注册的观察者(即显示组件)。观察者接收到通知后,可以根据需要更新自身的状态或执行特定的操作。这种方式保证了所有依赖于气象站的对象都能够及时响应数据的变化。
- 易于扩展:由于使用了Observer模式,可以非常方便地添加或删除观察者。例如,如果要增加一个新的显示组件,只需让它订阅气象站的状态变化即可;同样地,如果要移除某个显示组件,也只需取消订阅操作,而无需修改气象站的代码。
具体来说,在这个天气预报系统的例子中,气象站作为被观察者,提供了一个接口让显示组件能够注册为观察者。每当气象站获取到新的天气数据时,它就会调用一个方法来通知所有的观察者进行更新。这样,即使显示组件的数量增加或者减少,也不会影响到气象站的功能实现,同时也保证了各组件之间的独立性和可复用性。
(4)示例代码
// Observer接口定义了更新方法,所有具体观察者类都需要实现这个接口。
interface Observer {// 当被观察者状态改变时,调用此方法来更新观察者的状态。void update(float temperature, float humidity, float pressure);
}// DisplayElement接口用于显示元素,所有具体的观察者都实现了这个接口。
interface DisplayElement {void display();
}// ConcreteObserver是具体的观察者类,它实现了Observer和DisplayElement接口。
class CurrentConditionsDisplay implements Observer, DisplayElement {private float temperature;private float humidity;private Subject weatherData;public CurrentConditionsDisplay(Subject weatherData) {this.weatherData = weatherData;weatherData.attach(this); // 注册为观察者}@Overridepublic void update(float temperature, float humidity, float pressure) {this.temperature = temperature;this.humidity = humidity;display(); // 更新并显示数据}@Overridepublic void display() {System.out.println("Current conditions: " + temperature + "F degrees and " + humidity + "% humidity");}
}// Subject接口定义了添加、删除和通知观察者的方法。
interface Subject {void registerObserver(Observer o); // 添加一个新的观察者到观察者列表中void removeObserver(Observer o); // 从观察者列表中移除一个观察者void notifyObservers(); // 通知所有的观察者
}// ConcreteSubject是具体的被观察者类,它实现了Subject接口,并维护着自身的状态。
class WeatherData implements Subject {private List<Observer> observers;private float temperature;private float humidity;private float pressure;public WeatherData() {observers = new ArrayList<>();}@Overridepublic void registerObserver(Observer o) {observers.add(o);}@Overridepublic void removeObserver(Observer o) {int i = observers.indexOf(o);if (i >= 0) {observers.remove(i);}}@Overridepublic void notifyObservers() {for (Observer observer : observers) {observer.update(temperature, humidity, pressure); // 通知每个观察者更新其状态}}// 当气象站的数据发生变化时,调用此方法public void setMeasurements(float temperature, float humidity, float pressure) {this.temperature = temperature;this.humidity = humidity;this.pressure = pressure;measurementsChanged(); // 数据变化后通知所有观察者}public void measurementsChanged() {notifyObservers(); // 调用通知方法}
}public class WeatherStation {public static void main(String[] args) {WeatherData weatherData = new WeatherData(); // 创建气象站实例// 创建一个当前条件显示对象,并注册为观察者CurrentConditionsDisplay currentDisplay = new CurrentConditionsDisplay(weatherData);// 模拟气象站获取新数据的过程weatherData.setMeasurements(80, 65, 30.4f);weatherData.setMeasurements(82, 70, 29.2f);weatherData.setMeasurements(78, 90, 29.2f);}
}
代码解释:
Observer接口:定义了一个update()方法,所有具体观察者类(如CurrentConditionsDisplay)都必须实现这个方法。当被观察者状态改变时,会调用这个方法来更新观察者的状态。DisplayElement接口:提供了一个抽象方法display(),用于显示观测数据。虽然在这个例子中没有直接使用该接口进行功能扩展,但它为未来可能的其他类型的显示组件提供了基础。ConcreteObserver类(CurrentConditionsDisplay):这是具体的观察者类,实现了Observer和DisplayElement接口。它包含了一个指向WeatherData(被观察者)的引用,并且在构造函数中注册自己为观察者。update()方法用于接收新的气象数据,并调用display()方法更新显示内容。Subject接口:定义了添加、删除和通知观察者的方法。registerObserver()方法用于添加一个新的观察者到观察者列表中,removeObserver()方法用于从观察者列表中移除一个观察者,notifyObservers()方法用于通知所有的观察者。ConcreteSubject类(WeatherData):这是具体的被观察者类,实现了Subject接口。它维护着自身的状态(温度、湿度和压力),并且有一个观察者列表。当它的状态改变时,会调用notifyObservers()方法来通知所有的观察者。WeatherStation类:这是测试类,演示了如何使用上述类来模拟天气预报系统。首先创建了一个气象站实例和一个当前条件显示对象,并将显示对象注册为观察者。然后通过设置不同的气象数据来触发观察者的更新操作。
5.效果
Observer 模式适用于:
- 当一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这两者封装在独立的对象中以使它们可以各自独立地改变和复用。
- 当对一个对象的改变需要同时改变其他对象,而不知道具体有多少对象有待改变时。
- 当一个对象必须通知其他对象,而它又不能假定其他对象是谁,即不希望这些对象是紧耦合的。
(八)State
1. 模式名称
State设计模式
2. 意图解决的问题
State设计模式主要用于解决当一个对象的行为依赖于其状态,并且它必须在运行时根据状态改变其行为的情况。这种情况下,如果直接将所有状态逻辑编写在一个类中,会导致该类变得非常庞大且难以维护,同时也会违反单一职责原则(Single Responsibility Principle)。通过使用State设计模式,可以将每个状态的处理逻辑封装到单独的类中,从而简化主要对象的实现,使其更加清晰和易于扩展。
具体来说,State设计模式旨在解决以下问题:
- 复杂的状态管理:当一个对象需要根据内部状态改变其行为时,直接编码会导致代码冗长且难以理解。
- 扩展性差:每当添加新的状态或修改现有状态的行为时,都需要修改原来的类,这违背了开闭原则(Open/Closed Principle)。
- 降低耦合度:使状态逻辑与对象的核心逻辑分离,减少它们之间的耦合度,提高代码的可读性和可维护性。
3. 模式描述
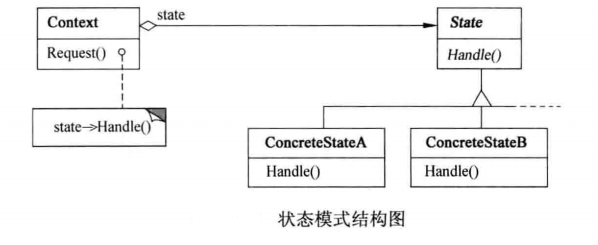
State设计模式允许一个对象在其内部状态改变时改变它的行为。看起来好像这个对象改变了它的类一样。其实现方式是通过定义一组表示各种状态的对象,以及一个持有当前状态引用的上下文(Context)对象。上下文(Context)会将状态相关的请求委托给当前状态对象处理,而状态对象则负责执行相应的行为并可能触发状态转换。
主要角色
- Context(上下文):定义客户端感兴趣的接口,并维护一个对State子类实例的引用。
- State(抽象状态角色):定义了一个所有具体状态都要实现的接口,此接口声明了特定于状态的方法。
- ConcreteState(具体状态角色):每个具体状态类实现了State接口中的业务方法,每一个类对应一种状态,每种状态下有不同的行为表现。
示例代码
// State接口定义了所有具体状态类需要实现的方法
interface State {void handle(Context context);
}// ConcreteStateA是具体的状态类之一,实现了State接口中的handle方法
class ConcreteStateA implements State {@Overridepublic void handle(Context context) {System.out.println("当前状态是A");// 根据业务逻辑,可能需要切换到其他状态context.setState(new ConcreteStateB());}
}// ConcreteStateB是另一个具体的状态类,同样实现了State接口中的handle方法
class ConcreteStateB implements State {@Overridepublic void handle(Context context) {System.out.println("当前状态是B");// 根据业务逻辑,可能需要切换到其他状态context.setState(new ConcreteStateA());}
}// Context类维护一个对State对象的引用,并提供请求处理方法
class Context {private State state;// 构造函数初始化状态public Context(State state) {this.state = state;}// 设置当前状态的方法public void setState(State state) {this.state = state;}// 请求处理方法,将请求委托给当前状态对象处理public void request() {state.handle(this);}
}public class StatePatternDemo {public static void main(String[] args) {// 创建初始状态为ConcreteStateA的Context对象Context context = new Context(new ConcreteStateA());// 发出请求,这将触发状态的变化context.request(); // 输出: 当前状态是A// 再次发出请求,由于状态已经改变,这次将执行不同的行为context.request(); // 输出: 当前状态是B}
}
实现步骤
- 定义状态接口:首先,定义一个状态接口(或者抽象类),其中包含状态变化引起的行为方法。
- 创建具体状态类:为每种状态创建具体的类,这些类实现状态接口中的方法。每个具体状态类负责实现对应状态下应有的行为。
- 构建上下文类:创建一个上下文类,用于维护当前状态,并提供设置状态的方法。上下文类通过调用状态接口中的方法来执行操作,而实际的操作是由当前状态的具体实现类提供的。
- 状态切换:在适当的情况下,上下文类可以通过调用状态对象的方法来改变当前状态,从而使系统能够动态地响应不同的状态变化。
通过这种方式,State设计模式有效地分离了不同状态下的行为,使得代码结构更加清晰,易于管理和扩展。此外,它还提高了系统的灵活性,因为可以在不修改原有代码的基础上轻松添加新的状态或修改已有状态的行为。
4.应用场景
(1)背景介绍:
想象一个在线购物平台的订单处理系统,订单从创建开始会经历多个状态,如“已下单”、“已支付”、“已发货”、“已完成”和“已取消”。每个状态下允许的操作是不同的,例如在“已下单”状态下可以进行支付操作,在“已支付”状态下可以发货等。随着业务的发展,可能会增加新的状态或修改现有状态的行为。
(2)遇到的困难:
- 复杂的状态管理:如果将所有状态逻辑都放在一个类中实现(比如Order类),会导致该类非常庞大且难以维护。每次添加新状态或修改现有状态的行为都需要修改Order类,这不仅增加了代码的复杂度,还可能引入错误。
- 违反单一职责原则:一个类承担了过多的责任,即不仅要处理订单的基本信息,还要管理订单的各种状态及其转换规则。
可扩展性差:当需要新增一种状态或者调整某个状态的行为时,必须对原有代码进行修改,这违背了开闭原则(Open/Closed Principle),使得系统不易于扩展和维护。
(3)State模式是如何解决问题的?
State模式通过以下方式解决了上述问题:
- 分离状态逻辑:通过定义一系列具体的状态类来表示不同状态下的行为,并将这些状态类与主要业务对象(在这个例子中为Order)分离开来。这样,每种状态都有其对应的处理逻辑,保持了代码的清晰性和简洁性。
- 提高可扩展性:由于每种状态都是独立的类,因此可以很容易地添加新的状态而不影响现有的代码。同样地,修改某个状态的行为也只需改动相应的状态类,而不会波及其他部分的代码。
- 遵循设计原则:State模式帮助实现了单一职责原则(每个状态类只负责特定状态下的行为),同时也支持开闭原则(易于扩展新状态,无需修改已有代码)。此外,它还能降低不同状态之间的耦合度,使整个系统更加灵活和易于维护。
具体来说,在这个订单处理系统的例子中,我们可以定义一个OrderState接口,以及几个实现该接口的具体状态类,如CreatedState、PaidState、ShippedState、CompletedState和CancelledState。Order类内部维护了一个当前状态的引用,并提供方法供客户端调用以执行对应状态下的操作。每当需要改变状态时,Order类就会更新其当前状态引用指向新的状态对象,从而触发相应的行为变化。
这种方式不仅简化了Order类的设计,使其专注于订单的核心属性和操作,而且使得状态管理和转换变得简单直观,极大地提高了系统的灵活性和可维护性。
(4)示例代码
// State接口定义了所有具体状态类需要实现的方法
interface OrderState {void handlePayment(Order order); // 处理支付void handleShip(Order order); // 处理发货void handleComplete(Order order); // 处理完成void handleCancel(Order order); // 处理取消
}// CreatedState是订单创建后的状态
class CreatedState implements OrderState {@Overridepublic void handlePayment(Order order) {System.out.println("订单已支付");order.setState(new PaidState()); // 转换到PaidState}@Overridepublic void handleShip(Order order) {System.out.println("当前状态不允许直接发货");}@Overridepublic void handleComplete(Order order) {System.out.println("当前状态不允许直接完成");}@Overridepublic void handleCancel(Order order) {System.out.println("订单已取消");order.setState(new CancelledState()); // 转换到CancelledState}
}// PaidState是订单支付后的状态
class PaidState implements OrderState {@Overridepublic void handlePayment(Order order) {System.out.println("订单已经支付,不能再次支付");}@Overridepublic void handleShip(Order order) {System.out.println("订单已发货");order.setState(new ShippedState()); // 转换到ShippedState}@Overridepublic void handleComplete(Order order) {System.out.println("当前状态不允许直接完成");}@Overridepublic void handleCancel(Order order) {System.out.println("订单已取消");order.setState(new CancelledState()); // 转换到CancelledState}
}// ShippedState是订单发货后的状态
class ShippedState implements OrderState {@Overridepublic void handlePayment(Order order) {System.out.println("订单已经发货,无法再进行支付");}@Overridepublic void handleShip(Order order) {System.out.println("订单已经发货,无法再次发货");}@Overridepublic void handleComplete(Order order) {System.out.println("订单已完成");order.setState(new CompletedState()); // 转换到CompletedState}@Overridepublic void handleCancel(Order order) {System.out.println("订单已经发货,无法取消");}
}// CompletedState是订单完成后的状态
class CompletedState implements OrderState {@Overridepublic void handlePayment(Order order) {System.out.println("订单已经完成,无需支付");}@Overridepublic void handleShip(Order order) {System.out.println("订单已经完成,无需发货");}@Overridepublic void handleComplete(Order order) {System.out.println("订单已经完成");}@Overridepublic void handleCancel(Order order) {System.out.println("订单已经完成,无法取消");}
}// CancelledState是订单取消后的状态
class CancelledState implements OrderState {@Overridepublic void handlePayment(Order order) {System.out.println("订单已经取消,无法支付");}@Overridepublic void handleShip(Order order) {System.out.println("订单已经取消,无法发货");}@Overridepublic void handleComplete(Order order) {System.out.println("订单已经取消,无法完成");}@Overridepublic void handleCancel(Order order) {System.out.println("订单已经取消");}
}// Context类维护一个对OrderState对象的引用,并提供请求处理方法
class Order {private OrderState state;public Order() {this.state = new CreatedState(); // 默认状态为CreatedState}public void setState(OrderState state) {this.state = state;}// 根据不同的业务需求调用对应的状态处理方法public void pay() {state.handlePayment(this);}public void ship() {state.handleShip(this);}public void complete() {state.handleComplete(this);}public void cancel() {state.handleCancel(this);}
}public class StatePatternDemo {public static void main(String[] args) {Order order = new Order(); // 创建一个新的订单实例// 模拟订单处理过程order.pay(); // 输出: 订单已支付order.ship(); // 输出: 订单已发货order.complete(); // 输出: 订单已完成order.cancel(); // 输出: 订单已经完成,无法取消}
}
代码解析:
- OrderState接口:定义了四种操作(支付、发货、完成和取消)的方法,每个具体状态类都需要实现这些方法来定义在该状态下允许的操作。
- 具体状态类(如CreatedState, PaidState等):实现了OrderState接口中的方法。每种状态下允许的操作不同,例如,在CreatedState下可以执行支付操作并转换到PaidState,而在CompletedState下则不允许任何进一步的操作。
- Order类:
- 维护了一个指向当前状态的引用state。
- 提供了pay()、ship()、complete()和cancel()方法,这些方法将请求委托给当前状态对象处理。
- setState()方法允许改变当前状态,以响应不同的业务逻辑需求。
- StatePatternDemo类:这是一个简单的测试类,展示了如何使用状态模式模拟订单从创建到完成的处理流程。通过调用相应的方法,可以看到系统如何根据当前状态动态地调整其行为。
这种设计使得订单处理系统的状态管理变得清晰且易于扩展。每当有新的状态或修改现有状态的行为时,只需添加或修改相应的状态类,而不需要改动核心的Order类。这不仅提高了代码的可读性和可维护性,也遵循了开闭原则。
5.效果
State 模式适用于:
- 一个对象的行为决定于它的状态,并且它必须在运行时刻根据状态改变它的行为。
- 一个操作中含有庞大的多分支的条件语句,且这些分支依赖于该对象的状态。这个状态常用一个或多个枚举常量表示。通常,有多个操作包含这一相同的条件结构。State模式将每一个条件分支放入一个独立的类中。这使得开发者可以根据对象自身的情况将对象的状态作为一个对象,这一对象可以不依赖于其他对象独立变化。
(九)Strategy模式
1. 模式名称
Strategy(策略)设计模式
2. 意图解决的问题
Strategy设计模式旨在解决算法或行为在运行时可互换使用的需求。具体来说,它允许定义一系列算法或行为,并将每个算法封装起来,使它们可以互相替换。这种模式让算法的变化独立于使用它的客户端程序。
常见应用场景包括:
- 当有许多相关的类仅仅是行为有异时,Strategy模式提供了一种用多个行为中的一个行为配置一个类的方法。
- 需要动态地在一组相关的行为中进行选择的场合。
- 希望避免由于使用大量的条件语句来选择不同行为的情况。
- 算法需要被委托给不同的组件,或者算法本身可能需要被切换、扩展或修改。
3. 模式描述
Strategy设计模式是一种行为设计模式,它定义了一系列算法或行为,并将每一个算法或行为封装起来,而且使它们可以互相替换。Strategy模式使得算法或行为可以在不影响客户端的情况下发生变化。
结构:
- Strategy接口:定义了一个所有支持的算法的公共接口。Context使用这个接口来调用ConcreteStrategy定义的算法。
- ConcreteStrategyA 和 ConcreteStrategyB:实现了Strategy接口的具体策略类,每种类实现一种特定的算法或行为。
- Context:持有一个对Strategy对象的引用,并且与一个Strategy对象协作以定义其行为。
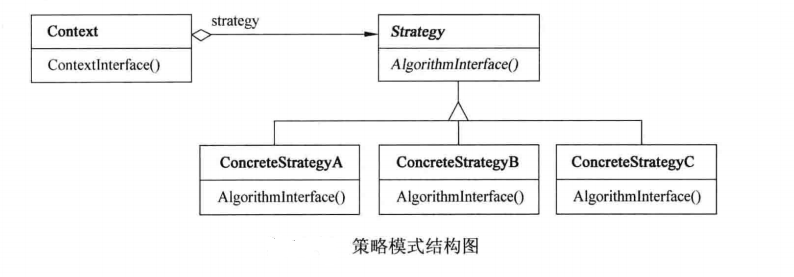
工作原理:
- Context通过构造器或setter方法接收一个Strategy对象。
- Context调用Strategy对象上的算法或行为,该行为由ConcreteStrategy类实现。
- 如果需要改变Context的行为,只需替换掉它所使用的Strategy对象即可。
优点:
- 提供了一种替代继承的方法来灵活地交换不同的算法或行为。
- 可以轻松地添加新的策略而无需修改现有代码,遵循开闭原则。
- 客户端代码不需要知道有关策略类的具体信息,只需要知道存在一个“策略”接口即可。
缺点:
- 如果策略家族经常添加新成员,则可能会导致过多的策略类,增加系统的复杂度。
- 客户端必须了解不同的策略以及如何选择合适的策略,这可能增加了客户端的复杂性。
通过使用Strategy模式,我们可以确保我们的代码更加灵活和易于维护,同时也能更好地适应变化的需求。例如,在支付系统中,可以选择不同的支付方式(如信用卡支付、PayPal支付等),这些支付方式就可以作为不同的策略实现。这样做的好处是支付逻辑的变化不会影响到核心业务逻辑,同时也便于扩展新的支付方式。
示例代码
// 定义策略接口(Strategy)
interface Strategy {// 定义算法方法void AlgorithmInterface();
}// 具体策略类A(ConcreteStrategyA)
class ConcreteStrategyA implements Strategy {@Overridepublic void AlgorithmInterface() {System.out.println("执行具体策略A的算法");}
}// 具体策略类B(ConcreteStrategyB)
class ConcreteStrategyB implements Strategy {@Overridepublic void AlgorithmInterface() {System.out.println("执行具体策略B的算法");}
}// 具体策略类C(ConcreteStrategyC)
class ConcreteStrategyC implements Strategy {@Overridepublic void AlgorithmInterface() {System.out.println("执行具体策略C的算法");}
}// 上下文类(Context),持有对策略对象的引用
class Context {private Strategy strategy;// 构造函数,传入具体的策略对象public Context(Strategy strategy) {this.strategy = strategy;}// 设置策略的方法public void setStrategy(Strategy strategy) {this.strategy = strategy;}// 上下文接口方法,调用策略对象的算法方法public void ContextInterface() {strategy.AlgorithmInterface();}
}public class StrategyPatternDemo {public static void main(String[] args) {// 创建上下文对象,并设置不同的策略对象Context context = new Context(new ConcreteStrategyA());context.ContextInterface(); // 输出: 执行具体策略A的算法context.setStrategy(new ConcreteStrategyB());context.ContextInterface(); // 输出: 执行具体策略B的算法context.setStrategy(new ConcreteStrategyC());context.ContextInterface(); // 输出: 执行具体策略C的算法}
}
4.应用背景
(1)背景介绍:
在电子商务平台中,用户可以选择不同的支付方式进行付款,如信用卡支付、支付宝支付、微信支付、PayPal等。每种支付方式的实现逻辑不同,并且未来可能会新增更多的支付方式。
为了提高系统的灵活性和可扩展性,我们希望将这些支付算法(即支付方式)独立封装起来,并能够在运行时根据用户的偏好动态切换支付方式。
(2)遇到的困难
复杂的条件判断逻辑:
如果不使用策略模式,通常会写出类似以下结构的代码:
if (paymentType.equals("CreditCard")) {// 执行信用卡支付逻辑
} else if (paymentType.equals("Alipay")) {// 执行支付宝支付逻辑
} else if (paymentType.equals("WeChat")) {// 执行微信支付逻辑
} else {throw new IllegalArgumentException("未知的支付方式");
}
这样的代码随着支付方式的增加会变得越来越臃肿,难以维护,也违反了开闭原则(对修改关闭,对扩展开放)。
业务逻辑与具体支付方式耦合严重:
客户端代码直接依赖于具体的支付类或条件分支,导致支付方式一旦变更或新增,就需要修改核心逻辑,容易引入错误。
难以测试和复用:
不同支付方式之间没有统一接口,导致每个支付逻辑无法被标准化地调用或复用,也不便于进行单元测试。
(3)Strategy模式是如何解决问题的?
Strategy模式通过以下方式解决了上述问题:
统一接口,解耦行为与使用方:
将所有支付方式抽象为一个公共接口(PaymentStrategy),每个具体支付方式作为实现类,使得客户端只需面向接口编程,而无需关心具体实现。
动态切换算法:
客户端可以在运行时根据用户选择或其他条件动态设置不同的策略对象,从而灵活地切换支付方式。
易于扩展和维护:
新增一种支付方式时,只需要添加一个新的策略类并实现接口方法,而不需要修改已有代码,完全符合开闭原则。
简化客户端逻辑:
客户端不再需要大量的if-else或switch-case语句,而是交给上下文(Context)去执行策略接口的方法,提高了代码的可读性和可测试性。
(4)示例代码
// 1. 定义策略接口
interface PaymentStrategy {void pay(int amount);
}// 2. 实现具体策略类
class CreditCardStrategy implements PaymentStrategy {@Overridepublic void pay(int amount) {System.out.println("使用信用卡支付: $" + amount);}
}class AlipayStrategy implements PaymentStrategy {@Overridepublic void pay(int amount) {System.out.println("使用支付宝支付: ¥" + amount);}
}class WeChatPayStrategy implements PaymentStrategy {@Overridepublic void pay(int amount) {System.out.println("使用微信支付: ¥" + amount);}
}// 3. 上下文类,持有策略引用
class ShoppingCart {private PaymentStrategy paymentStrategy;public void setPaymentStrategy(PaymentStrategy strategy) {this.paymentStrategy = strategy;}public void checkout(int amount) {if (paymentStrategy == null) {throw new IllegalStateException("未设置支付策略");}paymentStrategy.pay(amount);}
}// 4. 测试类
public class Client {public static void main(String[] args) {ShoppingCart cart = new ShoppingCart();// 用户选择支付宝支付cart.setPaymentStrategy(new AlipayStrategy());cart.checkout(299);// 用户切换为微信支付cart.setPaymentStrategy(new WeChatPayStrategy());cart.checkout(599);}
}
5.效果
Strategy 模式适用于:
- 许多相关的类仅仅是行为有异。“策略"提供了一种用多个行为中的一个行为来配置一个类的方法。
- 需要使用一个算法的不同变体。例如,定义一些反映不同空间的空间/时间权衡的算法。
- 当这些变体实现为一个算法的类层次时,可以使用策略模式。
- 算法使用客户不应该知道的数据。可使用策略模式以避免暴露复杂的、与算法相关的数据结构。
- 一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,将相关的条件分支移入它们各自的 Strategy类中,以代替这些条件语句。
(十)Template Method
1. 模式名称
Template Method(模板方法)设计模式
2. 意图解决的问题
Template Method设计模式旨在定义一个操作中的算法骨架,而将一些步骤延迟到子类中实现。它使得子类可以不改变算法结构的情况下重新定义该算法的某些特定步骤。这种模式适用于当多个类共享相同的算法结构,但其中某些具体步骤可能有所不同或需要扩展的情况。
常见应用场景包括:
- 当有一个通用的算法框架,但是其中部分步骤在不同情况下有不同的实现时。
- 希望将不变的行为移到超类,以消除代码重复,同时允许子类重写或扩展某些行为。
- 需要控制子类扩展的方式,确保它们不会改变算法的整体结构。
3. 模式描述
Template Method是一种行为设计模式,它提供了一种方式来定义算法的框架,同时将一些步骤的具体实现延迟到子类中。这样做的好处是,你可以通过继承来轻松地改变算法的一部分,而不必修改整个算法的结构。
主要角色:
- AbstractClass(抽象类):定义了算法的框架,包含了一系列的方法调用来表示算法的各个步骤,并且至少有一个方法是抽象的,留给子类去实现。
- ConcreteClass(具体类):实现了抽象类中定义的一个或多个抽象方法,这些方法代表了算法中变化的部分。
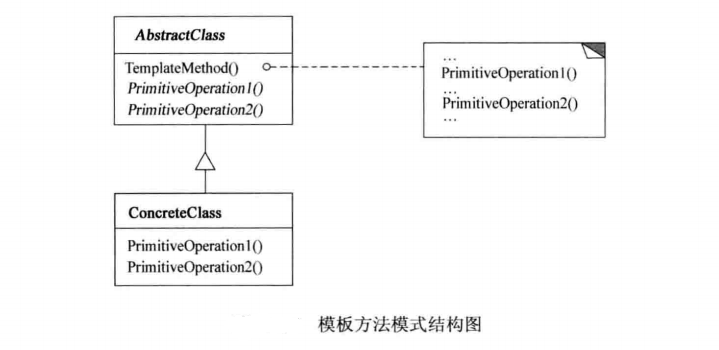
工作原理:
- 抽象类定义了一个模板方法,这个方法是一个具体的、最终的方法,它负责定义算法的框架,即一系列的步骤。
- 在模板方法内部,会调用若干个基本方法,有些是具体实现的方法,有些则是抽象方法,留给子类实现。
- 子类通过覆盖抽象方法来提供特定于应用程序的具体实现,从而完成算法的不同部分。
优点:
- 提供了很好的代码复用性,因为公共的算法逻辑被放置在父类中。
- 封装了不变的部分,扩展了可变的部分,有助于遵循开闭原则(对扩展开放,对修改关闭)。
- 控制了子类扩展的方式,确保了算法的核心结构不会被破坏。
缺点:
- 如果每个子类都需要完全不同的实现,那么使用模板方法模式可能会导致不必要的复杂性和冗余代码。
- 过度使用可能导致设计过于复杂,难以理解和维护。
示例代码
// 抽象类(AbstractClass),定义了算法框架和一些基本操作
abstract class AbstractClass {// 模板方法(TemplateMethod),定义了算法的骨架public final void TemplateMethod() {PrimitiveOperation1();PrimitiveOperation2();// 可以添加更多步骤或逻辑}// 基本操作1(PrimitiveOperation1),抽象方法,需要子类实现protected abstract void PrimitiveOperation1();// 基本操作2(PrimitiveOperation2),抽象方法,需要子类实现protected abstract void PrimitiveOperation2();
}// 具体类(ConcreteClass),实现了抽象类中的抽象方法
class ConcreteClass extends AbstractClass {@Overrideprotected void PrimitiveOperation1() {System.out.println("执行具体操作1");}@Overrideprotected void PrimitiveOperation2() {System.out.println("执行具体操作2");}
}public class TemplateMethodPatternDemo {public static void main(String[] args) {// 创建具体类对象,并调用模板方法AbstractClass concreteClass = new ConcreteClass();concreteClass.TemplateMethod(); // 输出: 执行具体操作1, 执行具体操作2}
}
4.应用场景
(1)背景介绍:
设想一个数据处理系统,该系统需要对不同类型的数据(如文本文件、图像文件、视频文件等)进行加载、处理和保存。虽然每种类型的数据处理流程大致相同(加载 -> 处理 -> 保存),但是具体的实现细节会有所不同。例如,加载文本文件与加载图像文件的方式显然不同;同样地,处理文本内容与处理图像数据的逻辑也会有很大差异。
(2)遇到的困难:
重复代码:
如果为每种数据类型都编写完整的加载、处理和保存逻辑,会导致大量的重复代码。比如,对于每个数据类型,都需要分别编写相似结构的“加载 -> 处理 -> 保存”的逻辑,尽管其中某些步骤的具体实现可能不同。
维护困难:
当算法的基本框架发生变更时(例如,增加了一个预处理步骤或改变了保存方式),必须在所有相关的具体类中逐一修改,这不仅耗时而且容易出错。
扩展不便:
每次添加新的数据类型时,都需要重新编写整个流程的代码,而不是仅需关注那些真正不同的部分,降低了系统的可扩展性。
(3)Template Method模式是如何解决问题的?
Template Method模式通过以下方式解决了上述问题:
定义通用算法骨架:
在抽象基类中定义一个模板方法,这个方法包含了算法的主要步骤(如加载、处理、保存)。这些步骤构成了算法的骨架,但允许子类根据需要覆盖某些步骤的具体实现。
减少重复代码:
把所有共同的行为放在抽象基类中实现,避免了在每个具体类中重复编写相同的代码。这样可以显著减少代码量,并提高代码的复用性。
易于维护:
因为算法的核心结构被封装在基类中,如果需要改变算法的整体流程,只需修改基类中的模板方法即可,而不需要改动所有的具体实现类。
方便扩展:
新增一种数据类型时,只需要创建一个新的具体子类并重写必要的步骤,而无需关心其他不变的部分,使得系统更易于扩展。
(4)示例代码
// 定义抽象基类,包含模板方法和基本操作
abstract class DataProcessor {// 模板方法,定义了数据处理的框架public final void process(String filePath) {loadData(filePath);processData();saveData();}protected abstract void loadData(String filePath); // 加载数据protected abstract void processData(); // 处理数据protected abstract void saveData(); // 保存数据
}// 实现具体的文本数据处理器
class TextDataProcessor extends DataProcessor {@Overrideprotected void loadData(String filePath) {System.out.println("加载文本数据:" + filePath);}@Overrideprotected void processData() {System.out.println("处理文本数据");}@Overrideprotected void saveData() {System.out.println("保存文本数据");}
}// 实现具体的图像数据处理器
class ImageDataProcessor extends DataProcessor {@Overrideprotected void loadData(String filePath) {System.out.println("加载图像数据:" + filePath);}@Overrideprotected void processData() {System.out.println("处理图像数据");}@Overrideprotected void saveData() {System.out.println("保存图像数据");}
}public class Client {public static void main(String[] args) {DataProcessor textProcessor = new TextDataProcessor();textProcessor.process("path/to/text/file.txt");DataProcessor imageProcessor = new ImageDataProcessor();imageProcessor.process("path/to/image/file.png");}
}
/** 输出结果
加载文本数据:path/to/text/file.txt
处理文本数据
保存文本数据
加载图像数据:path/to/image/file.png
处理图像数据
保存图像数据
*/
5.效果
Template Method 模式适用于:
- 一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现。
- 各子类中公共的行为应被提取出来并集中到一个公共父类中,以避免代码重复。
- 控制子类扩展。模板方法旨在特定点调用“hook”操作(默认的行为,子类可以在必要时进行重定义扩展),这就只允许在这些点进行扩展。
(十一)Visitor模式
1. 模式名称
Visitor(访问者)设计模式
2. 意图解决的问题
Visitor设计模式旨在提供一种方法,使得可以在不修改已有类层次结构的情况下,向这些类添加新的操作。它主要用于处理涉及对象结构中的元素操作问题,尤其是当你需要对一组对象进行许多不相关的操作时,而不想修改这些对象的类。通过将操作集中到一个称为“访问者”的独立类中,可以避免改变这些对象的类或破坏封装性。
常见应用场景包括:
- 当你需要对一个复杂对象结构(如对象树)中的元素执行许多不同的并且互不相关的操作,而且你不想修改这些元素的类时。
- 需要定义新的操作而不改变被操作元素的类。
- 对象结构包含很多不同类型的对象,希望对这些对象执行一些依赖于具体类型的操作。
3. 模式描述
Visitor设计模式是一种行为设计模式,它允许你在不修改已存在类的前提下,向这些类增加新的功能。通过定义一个新的“访问者”类来实现这些新功能,并且在每个目标类(即被访问的对象)中添加一个接受访问者的接口方法。这样做的好处是,你可以为每种具体的访问者类型定义一套完整的新操作,而不需要修改原有的类结构。
主要角色:
- Visitor(访问者):声明了一个或者多个访问操作,用于访问每一个由ConcreteElement导出的具体元素类。
- ConcreteVisitor(具体访问者):实现了Visitor所定义的每个Visit操作,确定对于各类ConcreteElement访问时所需执行的具体工作。
- Element(元素):定义了一个接受访问的方法(例如accept(Visitor)),该方法通常使用一个抽象访问者作为参数。
- ConcreteElement(具体元素):实现了Element接口,同时提供了接受访问者调用其访问方法的能力。
- ObjectStructure(对象结构):能够枚举它的元素,可以提供一个高层接口以允许访问者访问它的元素。
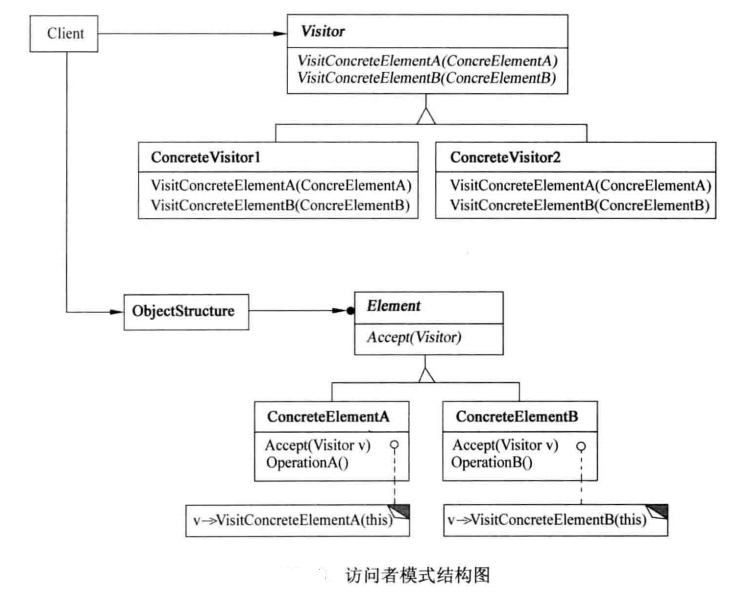
工作原理:
- 定义一个Visitor接口,其中包含针对各个ConcreteElement的visit方法。
- 创建具体的访问者类,实现Visitor接口中的方法。
- 在Element接口中声明一个accept(Visitor)方法,该方法接收一个Visitor对象作为参数。
- ConcreteElement类实现Element接口,并在accept方法中调用Visitor对象的相应visit方法。
- ObjectStructure类管理一系列ConcreteElement对象,并提供一个方法让客户端可以通过传递一个Visitor对象给所有元素来遍历它们。
优点:
- 增加新的操作变得简单,只需要新增一个具体的访问者类即可,无需修改现有的类。
- 可以分离算法和数据结构,使得算法可以独立于数据结构变化。
缺点:
- 增加了系统复杂度,尤其是在有很多ConcreteElement类时,需要为每个ConcreteElement编写相应的visit方法。
- 如果ConcreteElement类经常发生变化,则会导致访问者类也需要频繁更新。
通过使用Visitor设计模式,可以在不修改已有代码的基础上灵活地添加新的功能,尤其适用于那些具有稳定的数据结构但需要频繁添加新操作的场景。
示例代码
// Visitor接口定义了访问者可以访问的方法
interface Visitor {// 访问ConcreteElementA的方法void visitConcreteElementA(ConcreteElementA element);// 访问ConcreteElementB的方法void visitConcreteElementB(ConcreteElementB element);
}// ConcreteVisitor1实现了Visitor接口,定义了访问不同元素的具体行为
class ConcreteVisitor1 implements Visitor {@Overridepublic void visitConcreteElementA(ConcreteElementA element) {System.out.println("具体访问者1访问" + element.operationA());}@Overridepublic void visitConcreteElementB(ConcreteElementB element) {System.out.println("具体访问者1访问" + element.operationB());}
}// ConcreteVisitor2实现了Visitor接口,定义了访问不同元素的具体行为
class ConcreteVisitor2 implements Visitor {@Overridepublic void visitConcreteElementA(ConcreteElementA element) {System.out.println("具体访问者2访问" + element.operationA());}@Overridepublic void visitConcreteElementB(ConcreteElementB element) {System.out.println("具体访问者2访问" + element.operationB());}
}// Element接口定义了一个接受访问者访问的方法
interface Element {void accept(Visitor visitor);
}// ConcreteElementA实现了Element接口,并提供了一个供访问者访问的方法
class ConcreteElementA implements Element {@Overridepublic void accept(Visitor visitor) {visitor.visitConcreteElementA(this);}// 具体元素A的操作方法public String operationA() {return "具体元素A的操作";}
}// ConcreteElementB实现了Element接口,并提供了一个供访问者访问的方法
class ConcreteElementB implements Element {@Overridepublic void accept(Visitor visitor) {visitor.visitConcreteElementB(this);}// 具体元素B的操作方法public String operationB() {return "具体元素B的操作";}
}// ObjectStructure类管理了一系列元素,并提供一个方法让访问者访问这些元素
class ObjectStructure {private List<Element> elements = new ArrayList<>();// 添加元素到集合中public void attach(Element element) {elements.add(element);}// 移除集合中的元素public void detach(Element element) {elements.remove(element);}// 遍历所有元素,并调用它们的accept方法来接受访问者的访问public void accept(Visitor visitor) {for (Element element : elements) {element.accept(visitor);}}
}public class VisitorPatternDemo {public static void main(String[] args) {// 创建对象结构,并添加一些元素ObjectStructure objectStructure = new ObjectStructure();objectStructure.attach(new ConcreteElementA());objectStructure.attach(new ConcreteElementB());// 创建具体访问者1和2ConcreteVisitor1 visitor1 = new ConcreteVisitor1();ConcreteVisitor2 visitor2 = new ConcreteVisitor2();// 使用具体访问者1访问所有元素System.out.println("使用具体访问者1访问所有元素:");objectStructure.accept(visitor1);// 使用具体访问者2访问所有元素System.out.println("\n使用具体访问者2访问所有元素:");objectStructure.accept(visitor2);}
}
代码解析:
- Visitor接口:定义了访问者可以访问的方法,包括visitConcreteElementA和visitConcreteElementB。
- ConcreteVisitor1和ConcreteVisitor2类:实现了Visitor接口,分别定义了访问不同元素的具体行为。
- Element接口:定义了一个接受访问者访问的方法accept。
- ConcreteElementA和ConcreteElementB类:实现了Element接口,并提供了具体的访问方法和操作方法。
- ObjectStructure类:管理了一系列元素,并提供一个方法让访问者访问这些元素。它包含了添加、移除元素以及遍历所有元素并调用它们的accept方法的功能。
- VisitorPatternDemo测试类:创建了对象结构和具体访问者,并演示了如何使用访问者模式来访问不同的元素。
通过这个示例,我们可以看到访问者模式如何在不修改已有类的前提下,向这些类增加新的功能。
4.应用场景
(1)背景介绍:
考虑一个支持多种文档元素(如文本、图片、表格等)的文档编辑器,用户希望能够对整个文档应用不同的格式化操作,比如导出为PDF、HTML或进行打印预览。每种格式化操作对于不同类型的文档元素处理方式不同,例如,文本元素需要转换成相应的格式,而图片可能需要调整分辨率或者格式转换。
(2)遇到的困难:
多样的操作需求:
文档中包含多种类型的元素,且针对每种类型元素的操作逻辑都不相同。如果将所有操作逻辑都放在每个元素类中实现,则会导致这些类变得庞大且难以维护。每当需要添加新的操作时,都需要修改所有的元素类。
违反开闭原则:
每次添加新的操作(如新增一种导出格式),都需要修改现有的元素类来支持这种新操作,这违背了开闭原则(对扩展开放,对修改关闭),增加了系统维护的风险和复杂性。
代码重复与耦合度高:
不同操作之间可能存在重复的代码逻辑,而且各个操作逻辑紧密耦合在元素类内部,不利于代码复用和测试。
(3)Visitor模式是如何解决问题的?
Visitor模式通过以下方式解决了上述问题:
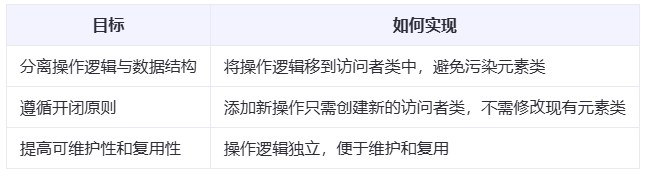
分离操作逻辑与数据结构:
将针对不同元素的操作逻辑从元素类中分离出来,放到访问者类中实现。这样,即使需要添加新的操作,也无需修改原有的元素类,只需创建一个新的访问者类即可。
遵循开闭原则:
新增操作只需要定义新的访问者类,而不需要修改已有的元素类,使得系统更易于扩展,同时降低了由于频繁修改带来的风险。
提高可维护性和复用性:
各个操作逻辑独立封装在各自的访问者类中,便于管理和维护。此外,因为操作逻辑与元素类分离,所以可以更容易地复用这些操作逻辑。
(4)示例代码
// 定义Visitor接口,声明了针对不同元素的操作方法
interface DocumentVisitor {void visitTextElement(TextElement element);void visitImageElement(ImageElement element);void visitTableElement(TableElement element);
}// 具体的访问者类,实现了特定的操作逻辑
class PDFExportVisitor implements DocumentVisitor {@Overridepublic void visitTextElement(TextElement element) {System.out.println("将文本元素导出为PDF格式");}@Overridepublic void visitImageElement(ImageElement element) {System.out.println("将图片元素导出为PDF格式并调整分辨率");}@Overridepublic void visitTableElement(TableElement element) {System.out.println("将表格元素导出为PDF格式");}
}// Element接口,定义了一个接受访问的方法accept
interface Element {void accept(DocumentVisitor visitor);
}// 具体的元素类,实现了accept方法,并提供自身的操作方法
class TextElement implements Element {@Overridepublic void accept(DocumentVisitor visitor) {visitor.visitTextElement(this);}// 其他方法...
}class ImageElement implements Element {@Overridepublic void accept(DocumentVisitor visitor) {visitor.visitImageElement(this);}// 其他方法...
}class TableElement implements Element {@Overridepublic void accept(DocumentVisitor visitor) {visitor.visitTableElement(this);}// 其他方法...
}public class DocumentEditor {public static void main(String[] args) {List<Element> document = new ArrayList<>();document.add(new TextElement());document.add(new ImageElement());document.add(new TableElement());// 创建PDF导出访问者DocumentVisitor pdfExporter = new PDFExportVisitor();// 使用访问者遍历文档并执行相应操作for (Element element : document) {element.accept(pdfExporter);}}
}
通过使用Visitor模式,文档编辑器成功实现了以下目标:
因此,Visitor模式非常适合用于那些具有稳定的数据结构但需要频繁添加新操作的场景,比如文档处理、图形界面组件管理、语法树解析等。它提供了一种有效的方式来组织代码,同时保持了灵活性和扩展性。
5.效果
Visitor 模式适用于:
- 一个对象结构包含很多类对象,它们有不同的接口,而用户想对这些对象实施一些依赖于其具体类的操作。
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而又想要避免这些操作“污染”这些对象的类。Visitor 使得用户可以将相关的操作集中起来定义在一个类中。当该对象结构被很多应用共享时,用 Visitor 模式让每个应用仅包含需要用到的操作。
- 定义对象结构的类很少改变,但经常需要在此结构上定义新的操作。改变对象结构类需要重定义对所有访问者的接口,这可能需要很大的代价。如果对象结构类经常改变,那么可能还是在这些类中定义这些操作较好。


)

)

)












)