1. FFN结构分解
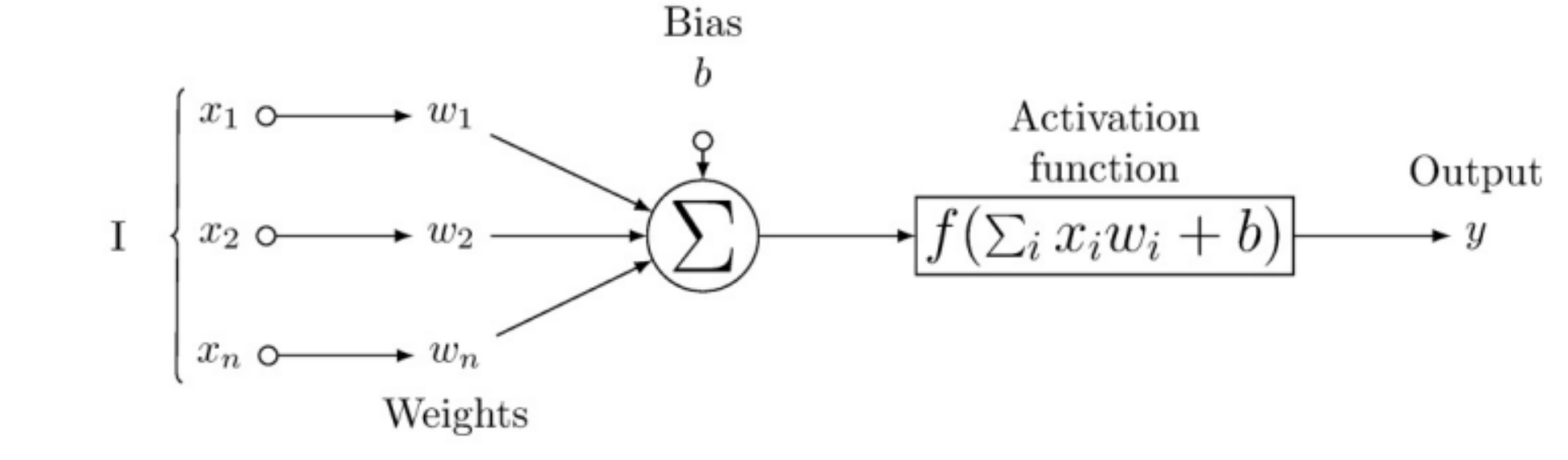
原始Transformer的FFN层
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂ # 原始论文公式
-
输入:自注意力层的输出
x(维度d_model=512) -
扩展层:
xW₁ + b₁(扩展为d_ff=2048) -
激活函数:
ReLU(即max(0, ⋅)) -
收缩层:
(⋅)W₂ + b₂(压缩回d_model=512)
2. ReLU的核心特性
| 特性 | 公式表现 | 作用 |
|---|---|---|
| 非线性 | f(x) = max(0, x) | 使模型能够学习复杂模式(否则多层线性变换等价于单层) |
| 梯度消失缓解 | f'(x) = 1 if x>0 else 0 | 正区间梯度恒为1,避免Sigmoid/Tanh的梯度指数衰减问题 |
| 计算高效 | 只需比较和取最大值操作 | 比Sigmoid(需指数运算)快3-6倍(实测在GPU上) |
3. 为什么选择ReLU?
-
实验验证:原始Transformer论文(《Attention Is All You Need》)通过消融实验确认ReLU优于Sigmoid/Tanh。
-
深层网络适配:Transformer通常堆叠6-12层,ReLU的梯度特性更适合深度训练。
-
稀疏激活:约50%神经元输出为0,可能提升特征选择性(但后续研究对此有争议)。
4. GELU的改进与数学细节
GELU公式

GELU(x) = xΦ(x) ≈ 0.5x(1 + tanh[√(2/π)(x + 0.044715x³)]) # 近似计算
-
与ReLU对比:
-
平滑性:GELU在
x=0处可导(ReLU二阶不可导) -
概率解释:
Φ(x)是高斯CDF,相当于对输入进行"随机门控"
-
BERT中的使用
-
在BERT-base中,GELU使MNLI任务准确率提升约0.5%(相比ReLU)
-
计算代价:GELU比ReLU慢约15%(因需计算tanh)
5. 关键代码实现对比
PyTorch中的FFN层
import torch.nn as nnclass TransformerFFN(nn.Module):def __init__(self, d_model=512, d_ff=2048):super().__init__()self.linear1 = nn.Linear(d_model, d_ff)self.linear2 = nn.Linear(d_ff, d_model)self.activation = nn.ReLU() # 或 nn.GELU()def forward(self, x):return self.linear2(self.activation(self.linear1(x)))
激活函数计算速度测试
import timeit x = torch.randn(10000, 10000).cuda()# ReLU timeit.timeit(lambda: nn.ReLU()(x), number=100) # 约0.12秒# GELU timeit.timeit(lambda: nn.GELU()(x), number=100) # 约0.18秒
6. 后续模型的发展
-
Switch Transformer:使用ReGLU(ReLU的GLU变体)提升稀疏性
-
GPT-3:保留ReLU,因模型足够大能弥补激活函数缺陷
-
Vision Transformer:部分研究采用LeakyReLU处理负值信息
)





:从设计模式到实战应用)


)









