
目录
- 引言
- 第一节:集合的“诞生”——自动出现还是手动打造?🤔
- 第二节:集合的“查阅”——看看这个数据库里有哪些柜子?📂👀
- 第三节:集合的“重命名”——给文件柜换个名字!✏️
- 第四节:集合的“销毁”——丢掉这个文件柜!💥👋
- 第五节:集合与模式 (Schema) 的那些事儿 🤔↔️📄
- 第六节:总结与展望 (集合篇) 🎉📄
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
来,各位csdn的佬友们!💻📱 这是一篇专门为你量身定制的,关于如何“驯服”MongoDB 数据库(而不是里面的数据)的干货文章!请接收!👇
看之前可以先了解一下MongoDB是什么:【MongoDB篇】万字带你初识MongoDB!
引言
各位未来的技术大牛们,你们好!👋 上一篇咱们聊透了 MongoDB 的“房间”——数据库。现在,咱们的目光转向房间里那些用来分门别类存放数据的“文件柜”——集合 (Collection)!
了解数据库操作请看:【MongoDB篇】MongoDB的数据库操作!
在传统的关系型数据库里,你把数据放在“表”里,表有固定的列,每行数据都得按照表的结构来。而在 MongoDB 里,这个概念被“集合”取代了。集合是文档 (Document) 的容器,它最大的特点是:同一个集合里的文档,可以有不同的结构! 🤯
想象一下,你的文件柜里不再是整齐划一的文件夹,而是各种形状、大小、内容都不一样的“包裹”(文档),只要你能把它们塞进同一个柜子(集合)里,就行!📦➡️📁
这种灵活的设计,让 MongoDB 在处理多样化、结构不固定的数据时如鱼得水!🚀
那么,对于这些灵活的“文件柜”,我们都能做些什么操作呢?
第一节:集合的“诞生”——自动出现还是手动打造?🤔
就像数据库一样,MongoDB 的集合也可以通过两种方式“诞生”:自动创建 (Implicit Creation) 和 手动创建 (Explicit Creation)。
1. 自动创建 (Implicit Creation) - 懒人模式!😴
这是 MongoDB 最常见的方式!当你第一次向一个不存在的集合中插入文档时,MongoDB 会自动创建这个集合。
示例:
假设你当前在 mydatabase 数据库里,并且里面还没有一个叫 users 的集合。
use mydatabase; // 切换到数据库
db.users.insertOne({ name: "张三", age: 30 }); // 向 users 集合插入第一个文档

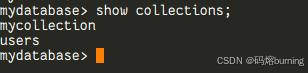
执行 db.users.insertOne(...) 命令后,MongoDB 会发现 mydatabase 数据库里还没有 users 这个集合,于是它会自动为你创建 users 集合,然后再把文档插入进去。
此时,如果你执行 show collections; 命令,你会看到 users 集合已经出现在列表里了!🎉
优点: 开发速度快,特别是在原型开发或数据结构变动频繁时,你不需要停下来先定义集合。
缺点: 无法在创建时指定一些高级选项,比如设置固定大小集合 (Capped Collection) 或添加数据验证规则 (Schema Validation)。
2. 手动创建 (Explicit Creation) - 精心打造模式!📐✨
如果你需要在创建集合时指定一些特殊的属性或行为,比如固定大小、数据验证规则等,你就需要使用 db.createCollection() 命令来手动创建集合。
db.createCollection(name, options)
name: 要创建的集合的名称(字符串)。options: 一个文档,用于指定集合的配置选项(可选)。
示例:
db.createCollection("my_logs"); // 创建一个最简单的集合 my_logs// 创建一个带选项的集合
db.createCollection("capped_logs", {capped: true, // 设置为固定大小集合size: 1024 * 1024 * 100 // 设置集合大小上限为 100MB (字节)
});// 创建一个带数据验证规则的集合
db.createCollection("strict_users", {validator: { // 验证规则$jsonSchema: { // 使用 JSON Schema 标准定义验证规则bsonType: "object", // 文档必须是对象类型required: ["name", "age", "email"], // 必须包含 name, age, email 字段properties: { // 定义字段的规则name: {bsonType: "string",description: "must be a string and is required"},age: {bsonType: "int", // 年龄必须是整数minimum: 0, // 最小值为 0description: "must be an integer >= 0 and is required"},email: {bsonType: "string",pattern: "^.+@.+\\..+$", // 邮箱格式验证description: "must be a string and match the email pattern and is required"},// 其他可选字段...status: {enum: ["active", "inactive", "pending"], // status 字段的值必须是列表中的一个description: "can only be one of the enum values"}}}},validationLevel: "strict", // 验证级别: "strict" (默认) 或 "moderate"validationAction: "error" // 验证失败时的动作: "error" (默认) 或 "warn"
});
createCollection 命令的常用选项详解:
capped: <boolean>:设置为true创建一个固定大小集合 (Capped Collection)。固定大小集合有以下特点:- 高性能写入:写入速度非常快,因为它只是在集合末尾追加数据。
- 插入顺序保留:文档始终按照插入顺序存储和读取。
- 达到上限时自动覆盖:当集合达到
size或max指定的上限时,最老的文档会被新的文档自动覆盖,就像一个循环缓冲区!🔄 - 不支持删除或更新导致的文档大小增加:通常用于存储日志、缓存、消息队列等需要快速写入、按时间排序且会自动清理旧数据的场景。
size: <number>:指定固定大小集合的最大容量(以字节为单位)。必须与capped: true一起使用。max: <number>:指定固定大小集合的最大文档数量。可选,与capped: true和size一起使用。如果同时指定了size和max,则哪个先达到,集合就达到上限。validator: <document>:指定集合的数据验证规则 (Schema Validation)。这是一个强大的功能,让你在 MongoDB 的灵活模式基础上,依然能对文档结构和内容进行一定程度的约束!你可以使用 JSON Schema 标准或者 MongoDB 特定的验证表达式来定义规则。- 验证规则定义在一个文档中。
$jsonSchema是最推荐的方式,因为它基于标准,易于理解和维护。- 你可以定义字段的类型 (
bsonType)、必填字段 (required)、字段的属性规则 (properties),甚至更复杂的逻辑。
validationLevel: <string>:验证级别,控制验证规则在什么时候执行:strict(默认):对所有的插入和更新操作都应用验证规则。moderate:只对现有的有效文档应用验证规则,对于插入操作和对无效文档的更新才应用验证规则。对于更新操作,如果更新会导致文档从有效变为无效,也会应用验证规则。
validationAction: <string>:验证失败时的动作:error(默认):验证失败时,拒绝插入或更新操作,并抛出错误。warn:验证失败时,记录警告日志,但仍然允许插入或更新操作。
collation: <document>:指定集合的排序规则 (Collation)。这对于进行字符串比较操作(比如排序、字符串相等比较、范围查询、聚合中的分组等)非常重要,特别是当你处理非英文字符(比如中文)时。可以指定语言、大小写敏感性、重音敏感性等。storageEngine: <document>:指定集合使用的存储引擎的特定选项。通常你不需要在这里指定,除非你有特殊的存储引擎配置需求。MongoDB 默认使用 WiredTiger 存储引擎。
通过 createCollection 命令并配合这些选项,你可以根据不同的业务场景,创建出满足特定需求的“文件柜”!🎯
注意: 手动创建的空集合也会立即出现在 show collections; 列表中!不像自动创建那样需要先有数据。
第二节:集合的“查阅”——看看这个数据库里有哪些柜子?📂👀
想知道你当前所在的数据库里有哪些集合?很简单!
使用 show collections; 命令。
use mydatabase; // 切换到数据库
show collections;
执行这个命令后,你会看到当前数据库中所有集合的名称列表。
注意: 这个命令只会列出当前数据库中的集合,不会列出其他数据库的集合。它就像是打开了当前房间的门,看看里面有哪些文件柜,而不会去隔壁房间看。🚪👀
第三节:集合的“重命名”——给文件柜换个名字!✏️
文件柜名字起得不好?想换个更贴切的名字?没问题!你可以重命名一个集合。
使用 db.collection_name.renameCollection("new_name") 命令。
use mydatabase; // 切换到集合所在的数据库
db.myoldcollection.renameCollection("mynewcollection"); // 将 myoldcollection 改名为 mynewcollection
db.myoldcollection: 指定要重命名的集合对象。renameCollection("mynewcollection"): 调用renameCollection方法,并传入新的集合名称。
注意: 重命名操作是原子性的,它会一次性完成。重命名后,原集合名称就不能再使用了。
第四节:集合的“销毁”——丢掉这个文件柜!💥👋
如果某个集合的数据已经不再需要,或者整个文件柜都要扔掉,你可以删除(销毁)一个集合。
警告: 删除集合是一个非常危险的操作! 一旦删除,该集合中的所有文档都将永久丢失!不可恢复! 在执行这个操作之前,请务必再三确认,并在生产环境谨慎至极,最好先进行备份!💣💾
删除集合的命令是 db.collection_name.drop()。
-
首先,你需要切换到包含要删除集合的数据库。
-
然后,指定要删除的集合名称,并调用
drop()方法。use mydatabase; // 切换到数据库 db.mycollection.drop(); // 删除名为 mycollection 的集合
执行这个命令后,MongoDB 会返回一个结果,告诉你操作是否成功。通常你会看到 true 或者一个包含成功信息的文档。
再运行 show collections;,你会发现刚才删除的集合已经不见了!💨

重要注意事项:
drop()方法总是删除你调用它的那个集合对象。确保你调用的是正确的集合!- 删除集合的操作也需要足够的权限,通常需要该集合所在数据库的
dropCollection或dbAdmin等角色权限。
第五节:集合与模式 (Schema) 的那些事儿 🤔↔️📄
前面我们一直强调,MongoDB 的集合是“模式灵活”的,同一个集合里的文档可以有不同的结构。这是它与关系型数据库“表”的最大区别之一。
这种灵活性带来了巨大的开发便利性,特别是在数据结构不稳定或多样化的场景。但同时,它也带来了一些挑战:
- Schema on Read vs Schema on Write: 传统关系型数据库是“Schema on Write”,你在写入数据前就定义好模式,写入时强制遵守。MongoDB 则是“Schema on Read”,它不强制写入时的模式(除非你使用了验证规则),而是在读取数据时由应用程序去理解和处理不同的文档结构。这意味着你的应用程序代码需要更灵活地处理可能存在的字段缺失或类型不匹配问题。
- 数据一致性: 如果没有验证规则,同一个字段在不同文档中可能有不同的数据类型(比如,某个文档的
age是数字,另一个是字符串),这可能导致查询或聚合操作出现意外结果。
这就是为什么 MongoDB 引入了数据验证 (Schema Validation) 这个功能!通过在集合层面定义验证规则,你可以在享受模式灵活带来的便利的同时,也能保证关键数据的结构和类型符合预期,提高数据质量和一致性!✅
选择是否使用以及使用多严格的验证规则,取决于你的业务需求和对数据一致性的要求。
第六节:总结与展望 (集合篇) 🎉📄
太棒了!关于 MongoDB 的“文件柜”——集合,我们已经从它的“出生”聊到了“死亡”,还深入了解了它灵活的模式以及如何通过验证规则进行约束!
核心要点回顾:
- 集合是文档的容器,模式灵活。
- 创建可以是自动(第一次写入数据时)或手动(
createCollection)。 createCollection可以指定固定大小 (capped)、数据验证 (validator)、排序规则 (collation) 等选项。- 查看集合使用
show collections;。 - 重命名集合使用
db.collection.renameCollection();。 - 删除集合使用
db.collection.drop();,危险! - 集合的模式灵活带来便利和挑战,数据验证是平衡两者的方式。
现在,我们已经掌握了如何在 MongoDB 这个“仓库”中划分“房间”(数据库),以及如何在房间里设置“文件柜”(集合)。接下来,就该看看文件柜里那些最最核心的“文件”——文档 (Document) 了!那可是真正的数据载体!📄
关注作者不迷路,下篇文章会讲解。


:从设计模式到实战应用)


)











)

完整讲解与实战应用)