Hello !朋友们,这是我在学习过程中梳理的笔记,以作以后复习回顾,有时略有潦草,一些话是我用自己的话描述的,可能不够准确,还是感谢大家的阅读!
目录
一、并查集Quickfind
二、两种算法
1)QuickFind[快查找]
思想:
代码框架:
2)QuickUnion[快合并]
思想:
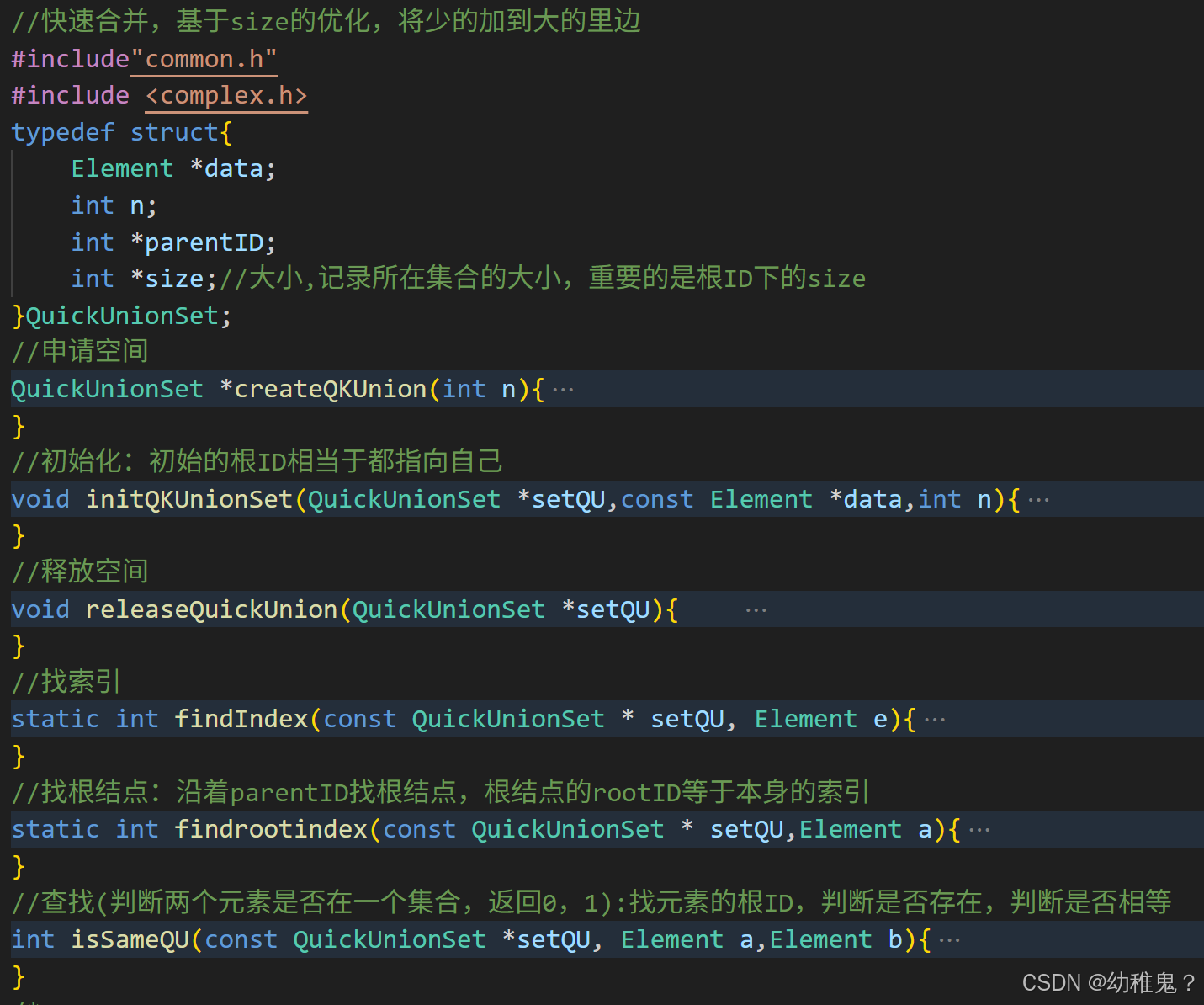
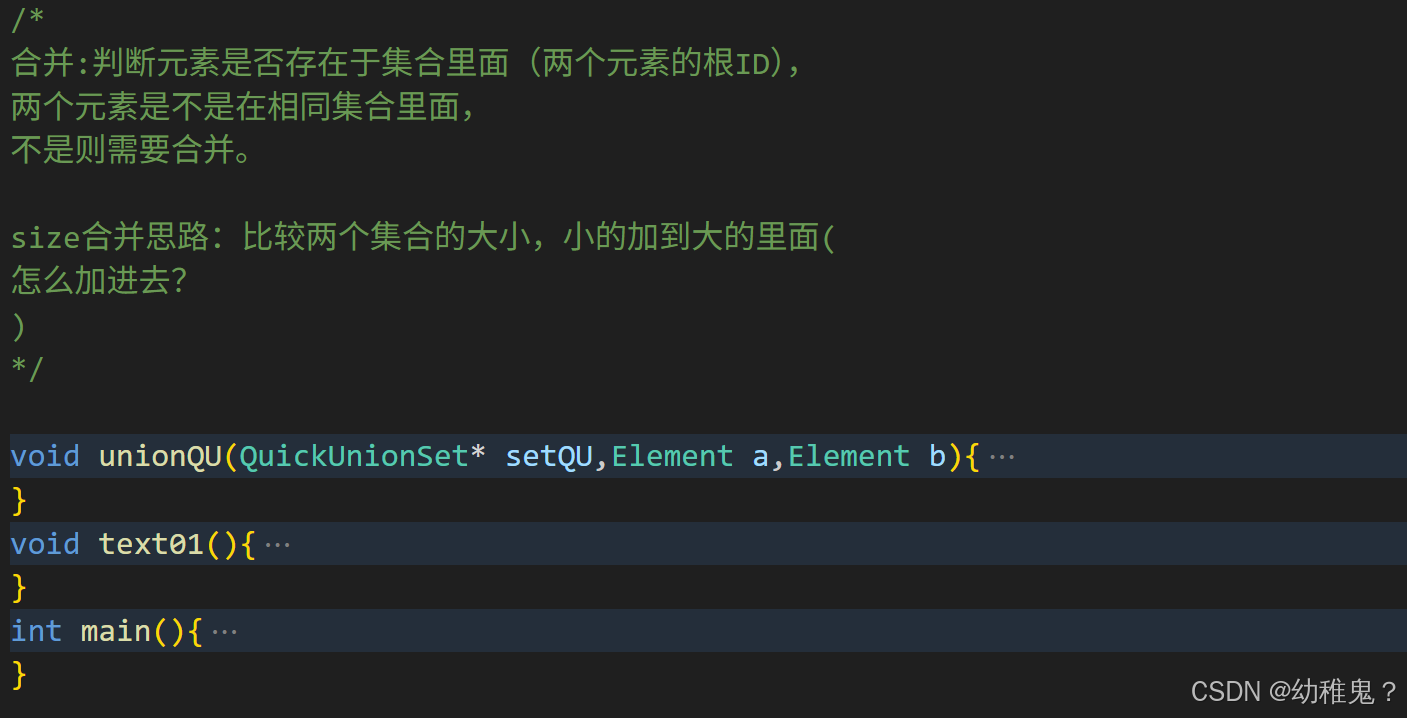
基于size的算法优化:元素少的树,嫁接到元素多的树
基于rank的算法改进:矮的树,嫁接到高的树
路径压缩:所有元素都指向根结点
代码实现步骤:
代码框架:
一、并查集Quickfind
并查集是一种用于处理不相交集合的合并与查询问题的数据结构。以下是其相关概念:
- 基本操作
- 合并(Union):将两个不相交的集合合并为一个集合。
- 查找(Find):确定一个元素属于哪个集合,通常返回该集合的代表元素。
- 实现原理
- 并查集通常使用树结构来实现,每个集合对应一棵树。树中的节点代表集合中的元素,根节点作为集合的代表元素。
- 用一个数组来存储每个元素的父节点信息,通过不断查找父节点,最终找到根节点,从而确定元素所属的集合。
- 路径压缩优化:在查找操作中,为了提高效率,可以采用路径压缩的优化方法。即在查找元素的根节点时,将路径上的所有节点直接连接到根节点,这样下次查找时就可以更快地找到根节点。
- 应用场景
- 连通性问题:判断图中两个节点是否连通,例如在网络拓扑中,判断两个设备是否通过网络连接。
- 最小生成树:在构建最小生成树的过程中,用于判断两个顶点是否在同一个连通分量中,避免形成环。
- 集合划分:将一组元素划分为不同的不相交集合,例如将一群人按照不同的兴趣爱好划分成不同的小组。
二、两种算法
并查集有两种算法,一种是快查找(QuickFind),另一种是快合并(QuickUnion),两种都要实现查找和和合并,只不过使用的不同的方法。
1)QuickFind[快查找]
查找效率:O(1) 合并效率:O(N)
思想:
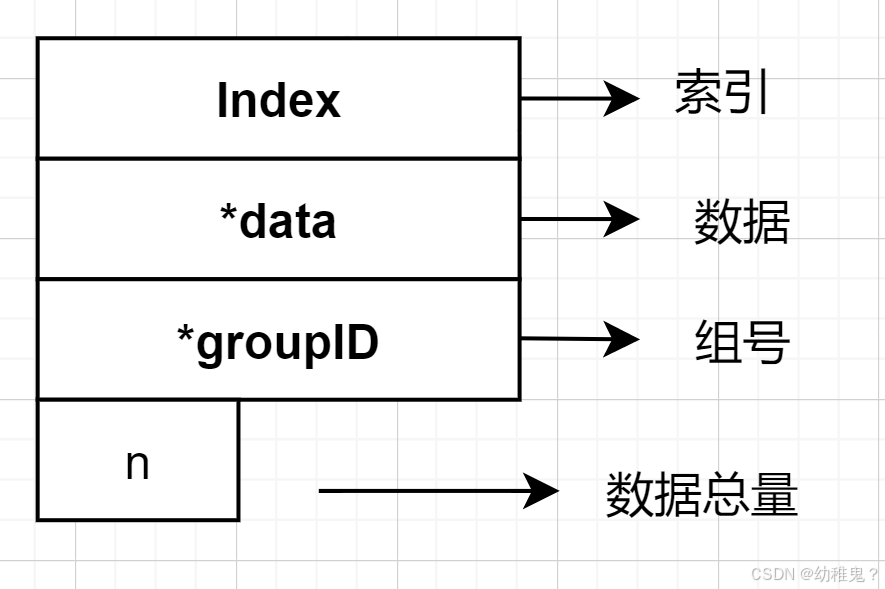
查找:查找两个数是否在一组,借用索引,看两个数的ID是否相等
合并:合并两个组,将第二个组里所有的值的组号改为第一个组的组号
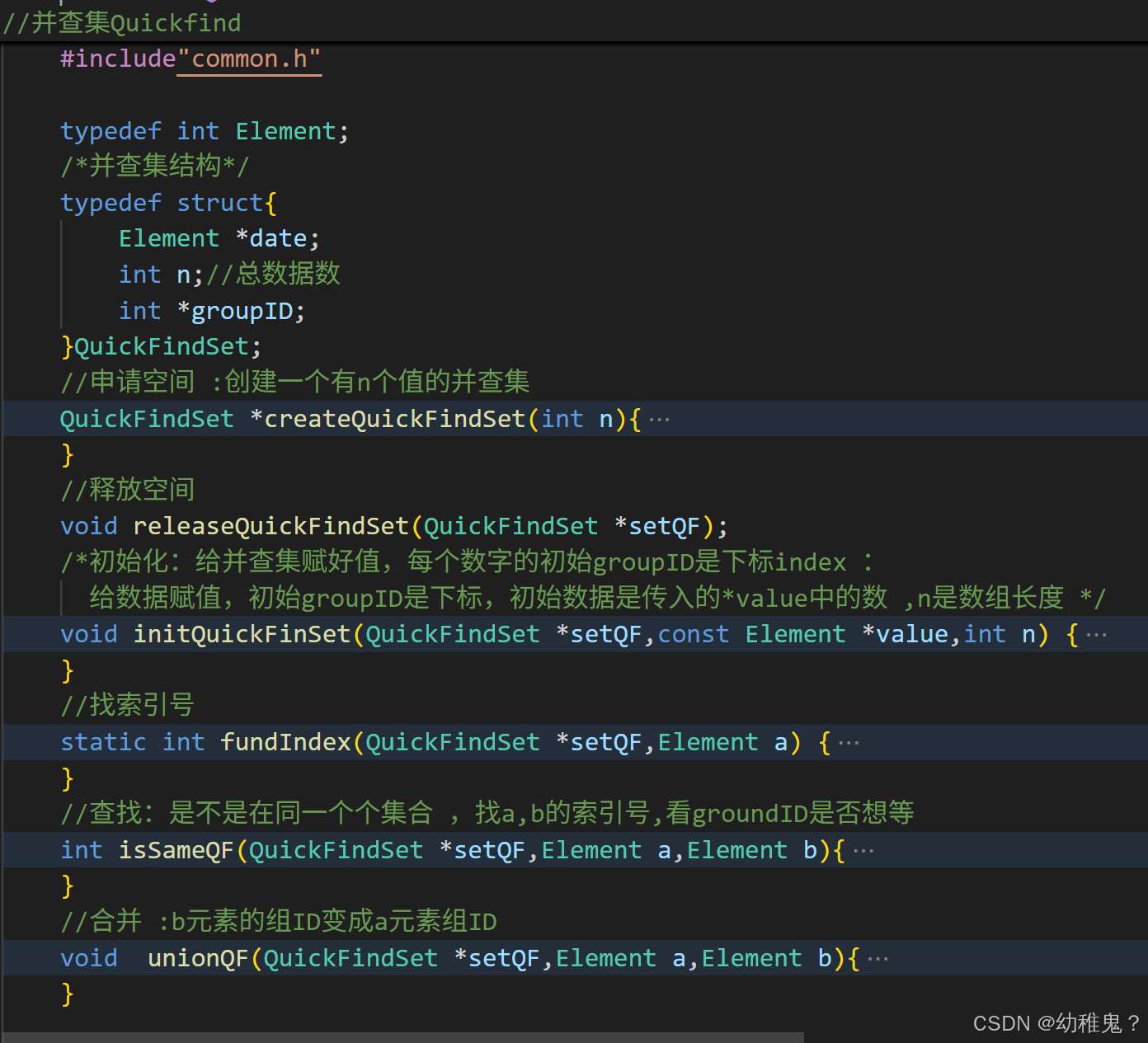
代码框架:
2)QuickUnion[快合并]
查找效率:O(logN) 合并效率:O(logN)
思想:
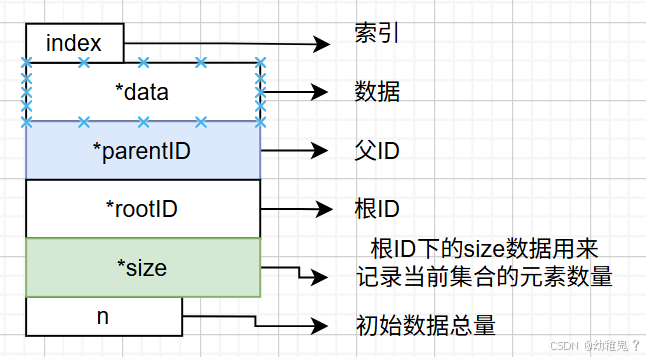
查找:查看两个数是否在一组,看两个数根ID是不是同一个,相等则是同一个,不等则不是同一组。
合并:不是合并a,b,而是a的根节点和b的根结点进行合并【合并a合并到b,b合并到a都不一定是最好的,所以需要优化算法】(掌握一个就可以)
基于size的算法优化:元素少的树,嫁接到元素多的树
(目前我是这样理解的,不知道有没有错)
基于rank的算法改进:矮的树,嫁接到高的树
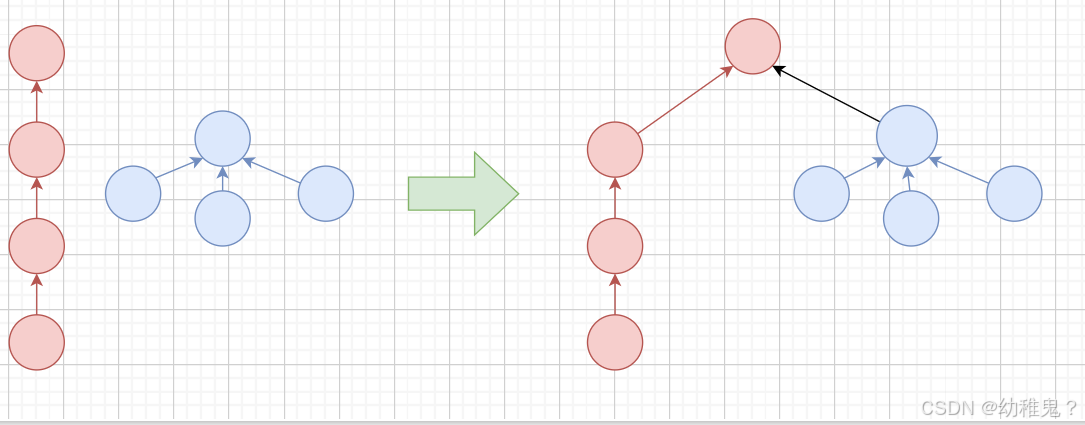
路径压缩:所有元素都指向根结点
- 使路径上的所有结点都指向根结点,从而降低树的高度
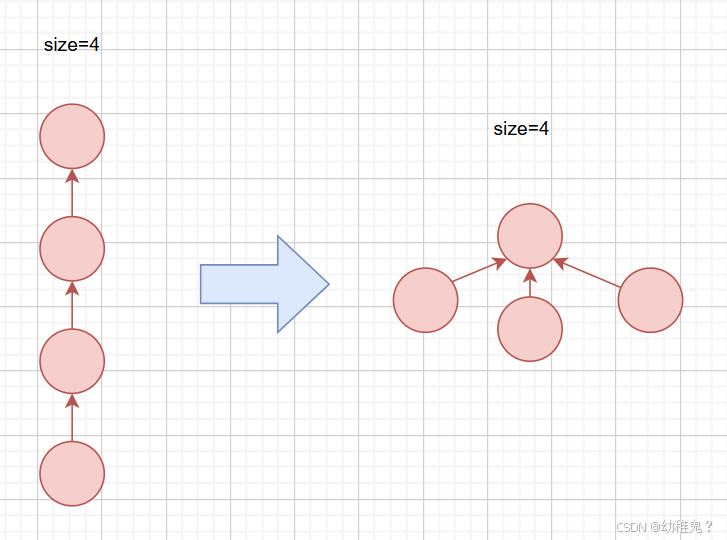
代码实现步骤:
1、申请空间:根据需要给每个部分都申请出空间
2、初始化:给每个部分赋上初始的值
找索引
找根ID
3、查找:(判断两个元素是否在一个集合,返回0,1)判断两个元素的根结点是否相同,则需要找到该借点,然后沿着起父节点找到根结点,最后比较根ID的值。
4、合并:
5、释放空间:
代码框架:
技术详解)



)














