一、ViT 的诞生背景
在计算机视觉领域的发展中,卷积神经网络(CNN)一直占据重要地位。自 2012 年 AlexNet 在 ImageNet 大赛中取得优异成绩后,CNN 在图像分类任务中显示出强大能力。随后,VGG、ResNet 等深度网络架构不断出现,推动了图像分类、目标检测、语义分割等任务的性能提升,促进了计算机视觉技术的快速发展。
然而,CNN 也逐渐显露出一些局限性。一方面,CNN 依赖局部感知,通过卷积核捕获局部区域的特征。尽管多层卷积可以提取高维语义信息,但在处理长距离依赖关系(如图像的全局信息)时,由于卷积核感受野有限,CNN 的能力受限,可能需要增加层数或设计复杂架构来弥补,这增加了模型复杂度和训练难度。另一方面,随着网络深度增加,CNN 的参数数量和计算量显著增长,对硬件资源的需求也随之提高,增加了部署成本,并限制了其在资源受限设备上的应用。
为了解决这些问题,研究者开始探索其他架构,其中 Transformer 架构受到广泛关注。Transformer 最初在自然语言处理(NLP)领域提出,凭借自注意力机制在捕捉序列中任意位置依赖关系方面的优势,成为 NLP 主流模型。受此启发,研究者尝试将其应用于视觉领域,Vision Transformer(ViT)因此诞生,为视觉任务提供了新的方法,标志着视觉模型发展的重要转变。
二、ViT 的核心原理
(一)Transformer 架构回顾
Transformer 架构于 2017 年在论文《Attention Is All You Need》中提出,最初用于解决自然语言处理中的机器翻译任务。在此之前,循环神经网络(RNN)及其变体(如 LSTM、GRU)是处理序列数据的主要模型,但这些模型存在梯度消失或爆炸问题,难以捕捉长距离依赖,且计算效率较低,难以并行化。

Transformer 的核心是自注意力机制,通过计算输入序列中每个位置与其他位置的关联程度,动态分配注意力权重,聚焦于关键信息。
例如,在处理句子“苹果从树上掉下来,小明捡起了它”时,自注意力机制能让模型在处理“它”时关注“苹果”,准确理解其指代对象。相比 RNN 按顺序处理序列,自注意力机制允许模型直接参考整个序列,大幅提升捕捉长距离依赖的能力。
多头注意力机制是自注意力机制的扩展,通过并行多个注意力头,每头学习不同的表示并拼接结果,增强模型从不同角度捕捉信息的能力。例如,在分析复杂句子时,不同注意力头可分别关注语法结构、语义关系等。
此外,Transformer 引入位置编码来弥补自注意力对顺序不敏感的缺陷,通过为每个位置添加唯一编码向量,将位置信息融入输入;前馈网络则对注意力输出进行非线性变换,提升特征学习能力。
(二)ViT 架构设计
前面我们在 计算机视觉 |解锁视频理解三剑客——ViViT 中简单介绍了 VIT 架构,本文我们将详细介绍它的架构设计。
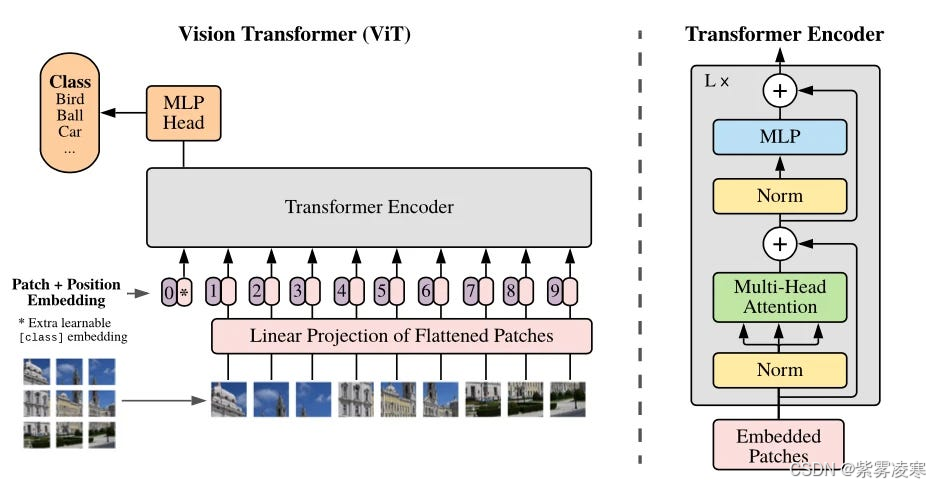
1. 图像分块
ViT 首先将输入图像划分为固定大小的 patch。例如,输入图像为 224 × 224 224\times224 224×224,通常划分为 16 × 16 16\times16 16×16 的 patch,生成 14 × 14 = 196 14\times14 = 196 14×14=196 个 patch。每个 patch 展平为一维向量,形成序列,作为 Transformer 的输入。这种分块将图像转化为序列形式,使 Transformer 能以处理序列的方式处理图像,突破 CNN 局部卷积的限制,直接捕捉不同区域间的长距离依赖。
2. 线性嵌入
展平后的 patch 通过线性投影嵌入到低维空间。使用可学习的线性变换矩阵(全连接层),将每个 patch 向量映射为固定维度的嵌入向量。例如,若 patch 展平后维度为 16 × 16 × 3 16\times16\times3 16×16×3(RGB 三通道),目标嵌入维度为 d d d(如 d = 768 d = 768 d=768),则通过 ( 16 × 16 × 3 ) × d (16\times16\times3)\times d (16×16×3)×d 的权重矩阵变换,得到维度为 d d d 的嵌入向量。嵌入维度影响表达能力和计算复杂度,需在性能和资源间权衡。
3. 位置编码
由于自注意力机制对输入顺序不敏感,而图像的空间位置信息重要,ViT 引入位置编码。默认使用可学习的 1D 位置编码,将二维 patch 按固定顺序展平为一维序列,为每个位置分配编码向量并与嵌入向量相加,使模型感知 patch 的相对位置。可选的正弦/余弦固定位置编码也常用于提供丰富位置信息。
4. Transformer 编码器
Transformer 编码器是 ViT 的核心,由多个 Transformer 块组成。每个块包含多头自注意力和前馈网络两个子层。
多头自注意力层通过计算不同头的注意力权重,捕捉图像中不同尺度和语义的依赖关系。输入嵌入向量序列通过线性变换生成查询、键、值矩阵,计算点积并经缩放和 Softmax 归一化后,得到注意力权重,再与值矩阵加权求和。例如,12 个头可分别关注物体轮廓、纹理等,最后拼接输出。
前馈网络对注意力输出进行非线性变换,包含两个线性层和激活函数(如 GELU),增强特征学习能力。残差连接和层归一化用于加速训练和稳定优化。
5. 分类头
分类头位于 ViT 末端,用于图像分类。在编码器输出序列中添加分类标记,与其他 patch 嵌入向量一起计算,仅作为分类标识。编码器处理完成后,提取分类标记的输出向量,通过全连接层映射到分类结果。例如,在 1000 类任务中,输出 1000 维向量,经 Softmax 转换为概率分布。
三、ViT 的训练与优化
(一)预训练与微调
ViT 通常在大规模数据集上预训练以学习通用图像特征。例如,在 JFT-300M 数据集(1400 万张图像)上预训练,通过最小化交叉熵损失更新参数,使用 AdamW 优化器(学习率约 1e-4,权重衰减 0.05),模型逐渐收敛。
预训练后,ViT 可在下游任务中微调。例如,在 CIFAR-10 上微调时,替换分类头为 10 类输出,使用较小学习率(如 1e-5)训练,适应新任务并提升准确率。
(二)数据增强
数据增强是提升 ViT 性能的重要方法。常见技术包括旋转、翻转、裁剪、缩放、颜色抖动等,增强模型对角度、方向、局部特征、光照变化的鲁棒性。
新兴方法如 TransMix 基于注意力图混合标签,改进传统 Mixup,根据像素重要性权重生成新样本。在 ImageNet 上,TransMix 可提升 ViT 的 top-1 准确率约 0.9%,增强泛化能力。
(三)优化器与超参数调整
AdamW 是 ViT 常用的优化器,加入权重衰减防过拟合,参数 β1=0.9、β2=0.999、eps=1e-8 确保优化稳定。
超参数如分块大小、嵌入维度、层数、注意力头数、学习率、Dropout 概率需调整。分块大小影响全局与细节捕捉,嵌入维度和层数影响表达能力,注意力头数影响细节关注,学习率需通过调度(如余弦退火)优化,Dropout(0.1-0.3)防过拟合。可用网格搜索等方法优化超参数。
四、ViT 的性能分析
(一)与 CNN 的对比
在大数据集上,ViT 凭借全局建模能力优于 CNN。例如,在 JFT-300M 预训练后,ViT 在 ImageNet 上准确率超过传统 CNN,特别在复杂全局结构图像中表现更佳。
在小数据集上,CNN 因归纳偏置(如平移不变性)更具优势,ViT 易过拟合。例如,在 CIFAR-10 上,ResNet 通常优于未充分预训练的 ViT。
ViT 自注意力机制计算复杂度高,与序列长度平方成正比,高分辨率图像处理时资源需求大,而 CNN 卷积操作更高效。CNN 的卷积核可解释性也优于 ViT 的注意力权重。
(二)不同数据集上的表现
在大规模数据集(如 JFT-300M)上,ViT 性能卓越,充分利用数据学习复杂特征。在小数据集(如 MNIST、CIFAR-10)上,ViT 表现不如 CNN,易过拟合。数据规模增加时,ViT 准确率可提升 5%-10%,泛化能力增强。
五、ViT 的变体与改进
(一)DeiT
DeiT 通过知识蒸馏提升性能,引入蒸馏标记与分类标记共同优化,模仿教师模型(如 RegNet)预测。在 ImageNet 上,DeiT 准确率提升 3%-6%。
DeiT 采用 RandomErase、Mixup、Cutmix 等数据增强技术,结合优化参数初始化和学习率调度,提高训练效率和泛化能力。
(二)Swin Transformer
Swin Transformer 采用分层结构,通过多阶段下采样提取多尺度特征,适用于目标检测、语义分割等任务。
其滑动窗口注意力机制在窗口内计算自注意力,降低复杂度( O ( M 2 ⋅ H W ) O(M² \cdot \frac{H}{W}) O(M2⋅WH) vs. O ( H W 2 ) O(HW²) O(HW2)),移位窗口增强全局信息交互,适合高分辨率图像处理。
六、ViT 的应用场景
(一)图像分类
ViT 在图像分类中表现优异。例如,ViT-B/16 在 ImageNet 上达到 77.9% 的 top-1 准确率。在医疗影像(如肺炎分类,准确率超 90%)和工业检测(如缺陷识别,准确率约 95%)中应用广泛。
(二)目标检测
ViT 可作为骨干网络用于目标检测。例如,DETR 在 MS COCO 上 AP 达 42.0%。但计算复杂度高和对小目标检测效果较弱是其挑战。
(三)语义分割
ViT 的全局建模能力适合语义分割。例如,SegFormer 在 ADE20K 上 mIoU 达 45.1%。但高分辨率图像处理资源需求大,细节捕捉能力稍逊于 CNN。
七、总结与展望
Vision Transformer(ViT)是计算机视觉的重要创新,通过 Transformer 架构捕捉图像全局依赖,在图像分类、目标检测、语义分割中展现潜力。
其核心是将图像分块并嵌入,结合位置编码输入 Transformer 编码器,通过自注意力建模全局关系。预训练与微调、数据增强、优化器调整提升了性能。
ViT 在大规模数据集上表现优异,但小数据集易过拟合,计算复杂度高,可解释性待提升。DeiT 和 Swin Transformer 等变体优化了效率和性能。
未来可从效率优化、训练策略、可解释性、新领域应用(如多模态融合)等方面进一步发展 ViT,推动视觉技术进步。(CNN)一直占据重要地位。自 2012 年 AlexNet 在 ImageNet 大赛中取得优异成绩后,CNN 在图像分类任务中显示出强大能力。随后,VGG、ResNet 等深度网络架构不断出现,推动了图像分类、目标检测、语义分割等任务的性能提升,促进了计算机视觉技术的快速发展。
延伸阅读
-
计算机视觉系列文章
计算机视觉|从0到1揭秘Diffusion:图像生成领域的新革命
计算机视觉 |解锁视频理解三剑客——ViViT
计算机视觉 |解锁视频理解三剑客——TimeSformer
计算机视觉 |解锁视频理解三剑客——SlowFast
计算机视觉实战|Mask2Former实战:轻松掌握全景分割、实例分割与语义分割
计算机视觉|Mask2Former:开启实例分割新范式
计算机视觉|目标检测进化史:从R-CNN到YOLOv11,技术的狂飙之路
轻量化网络设计|ShuffleNet:深度学习中的轻量化革命
计算机视觉基础|轻量化网络设计:MobileNetV3
计算机视觉基础|数据增强黑科技——AutoAugment
计算机视觉基础|数据增强黑科技——MixUp
计算机视觉基础|数据增强黑科技——CutMix
计算机视觉基础|卷积神经网络:从数学原理到可视化实战
计算机视觉基础|从 OpenCV 到频域分析
-
机器学习核心算法系列文章
解锁机器学习核心算法|神经网络:AI 领域的 “超级引擎”
解锁机器学习核心算法|主成分分析(PCA):降维的魔法棒
解锁机器学习核心算法|朴素贝叶斯:分类的智慧法则
解锁机器学习核心算法 | 支持向量机算法:机器学习中的分类利刃
解锁机器学习核心算法 | 随机森林算法:机器学习的超强武器
解锁机器学习核心算法 | K -近邻算法:机器学习的神奇钥匙
解锁机器学习核心算法 | K-平均:揭开K-平均算法的神秘面纱
解锁机器学习核心算法 | 决策树:机器学习中高效分类的利器
解锁机器学习核心算法 | 逻辑回归:不是回归的“回归”
解锁机器学习核心算法 | 线性回归:机器学习的基石
-
深度学习框架探系列文章
深度学习框架探秘|TensorFlow:AI 世界的万能钥匙
深度学习框架探秘|PyTorch:AI 开发的灵动画笔
深度学习框架探秘|TensorFlow vs PyTorch:AI 框架的巅峰对决
深度学习框架探秘|Keras:深度学习的魔法钥匙


)

)

)
 - 2.5 渲染流程(上):HTML、CSS和JavaScript,是如何变成页面的?)

)
:工程的新建和如何将源文件生成二进制文件)
)
)


 练习与实践1)



![[mybatis]resultMap详解](http://pic.xiahunao.cn/[mybatis]resultMap详解)