文章目录
- pycharm和typora快捷
- 环境配置及安装
- 两大函数
- pycharm及jupyter使用及对比
- pytorch加载数据
- Tensorboard使用
- transforms的使用
- torchvision中的数据集使用
- DataLoader的使用
- 神经网络nn
- 神经网络的骨架Containers
- 1. nn.Module的使用
- 2. nn.Sequential
- 卷积层Convolution Layers
- 1. 卷积操作nn.functional.Conv2d
- 2. Conv2d卷积函数
- 池化层Pooling Layers
- 1.最大池化MaxPool2d
- 非线性激活Non-linear Activations(other)
- 1.nn.ReIU
- 2.Sigmoid
- 线性层Linear Layers
- 1. nn.linear
- 2. Flatten
- 正则化层Normalization Layers
- Recurrent Layers
- Transformer Layers
- Sparse Layers
- Dropout Layers
- 搭建小实战
- 衡量误差,损失函数Loss Function
- 1. nn.L1Loss
- 2.nn.MSELoss
- 3. nn.CrossEntropyLoss
- 4. 反向传播
- 5. 损失函数
- 优化器
- 1. SGD
- 现有网络的使用和修改
- VGG6模型
- 模型的保存和加载
- 完整的模型训练套路
- 利用GPU训练
- 完整的模型验证(测试,demo)套路
存在问题
jupyter notebook打开网页中,选择环境之后,跳转的页面什么也没有显示pycharm和typora快捷
CTRL+P — 查询需要什么参数
代码补全(不区分大小写)
— 设置 - 编辑器 - 常规 - 代码补全 - 不区分大小写
./所在目录; …/ 上一级目录
pytorch目录里有demo,demo里面有torch.py
在torch.py里面: ./ 代表demo文件
…/ 代表pytorch文件
$\textcolor{red}{红色}$红色\textcolor{red}{红色}红色CTRL和+或-改变字体大小
==文本高亮==文本高亮下标:
H~2~OH2O上标:
x^2^x2组合式:
$C^m_n$CnmC^m_nCnm$C^{m1}_{n1}$Cn1m1C^{m1}_{n1}Cn1m1分式:
$\frac{1}{2}$12\frac{1}{2}21根号:
$\sqrt{2}$2\sqrt{2}2分割线:****
- 显示大纲:CTRL + shift + L
环境配置及安装
1.创建新的环境
conda create -n pytorch python=3.6
其中pytorch是新环境的名字
2.激活新的环境
conda activate pytorch
3.新环境中安装pytorch
conda install pytorch torchvision torchaudio cpuonly -c pytorch4.测试是否安装成功
>>>import torch
>>>import torchvision
>>>print(torch)
<module 'torch' from 'D:\\software\\Anaconda\\anaconda\\envs\\py39\\lib\\site-packages\\torch\\__init__.py'> --- 安装成功>>>print(torch.cuda.is_available())False --- CPU版的torch显示为False为安装成功。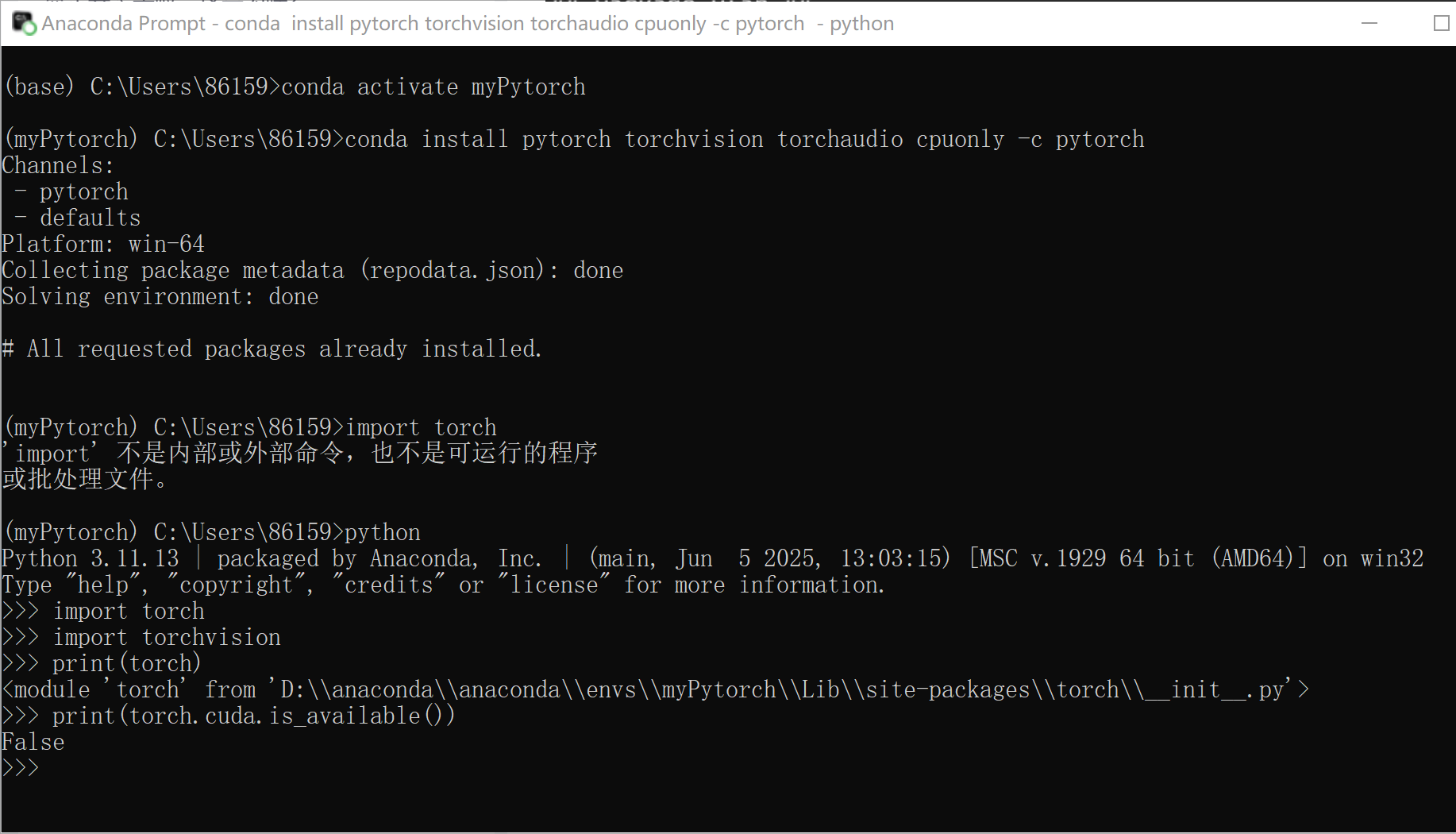
3.问题
新建项目,使用新的pytorch的环境时候,选择路径中不显示exe文件
scdn收藏夹:加载新的pytorch环境
或
在任意一个项目中:设置-项目:python-Python解释器-添加本地Conda环境-路径anacoda\Library\bin\conda.bat-使用现有的环境-选择需要的pytorch环境4.jupyter安装
交互式的模式
允许用户通过编写代码单元格(code cells)和文本单元格(markdown cells)的方式来探索数据、进行计算和可视化在anacoda中安装
安装anacoda的时候自动安装
默认安装在base环境中5.不能使用jupyter
jupyter默认安装在base环境中,而base环境中没安装pytorch,导致base环境不能使用jupyter
(1) base环境中安装一遍pytorch
(2) pytorch环境中安装jupyter
base中输入:conda list --- 主要用到的是ipykernel
进入到myPytorch环境中 --- conda activate myPytorch
安装一个包 --- conda install -c conda-forge nb_conda
启动Jupyter notebook --- jupyter notebookipykernel是Jupyter项目的核心组件,主要功能是为Jupyter Notebook和JupyterLab等交互式环境提供Python内核支持,实现代码的执行与交互通信
nb_conda包
nb_conda 是一个专为数据科学家设计的 Jupyter 笔记本扩展,它允许用户方便地管理和访问 Conda 环境以及其中的软件包,无需离开 Jupyter 界面。
环境切换:当处理不同的项目时,每个项目可能有不同的依赖,通过nb_conda,您可以直接在Jupyter内选择相应的Conda环境,避免了环境间的混淆。
包管理:可以直接在Notebook中安装或卸载包,使用 %conda install 包名 magic command,保持工作环境的纯净和针对性。
教学场景:在教学环境中,教师可以预建多个环境,每个环境对应一门课程的不同阶段或不同的编程语言要求,学生能够迅速切换到适合课堂的环境。
nb_conda是Anaconda生态系统的一部分,与其他工具如ipykernel紧密集成,后者让每个Conda环境都能作为一个独立的Jupyter内核提供服务。两大函数
可用python、pytorch
1. dir()
打开,能让我们知道工具箱,以及工具箱中的分隔区有什么东西
2. help()
能让我们知道每个工具是如何使用的,工具的使用方法
注:pycharm中ctrl+ 鼠标左键
pycharm及jupyter使用及对比
1. 运行python
编辑配置 - 添加新的配置 - 设置脚本路径
或
直接右键运行2. jupyter新建项目及使用
上述有相关说明 — 打开jupyter notebook - 新建
shift+enter 快捷键输出
3. 三种代码编辑对比
python文件
print("start")
a = "pytorch"
b = 2019
c = a + b
print(c)
# 在c = a+b时候出错,修改b = "2019",再次执行,发现代码从头开始
# 代码是以块为一个整体运行的话:python文件的块是所有行的代码python控制台
print("start")
a = "pytorch"
b = 2019
c = a + b
print(c)
# 在c = a+b时候出错,修改b = "2019",再次执行,发现代码从b = "2019"开始
# 可任意的修改每块的大小 --- shift + enter
# 阅读性不好jupyter
print("start")
a = "pytorch"
# ------------------------------
b = 2019
c = a + b
print(c)
# 可任意的修改每块的大小总结
| 优点 | 缺点 | |
|---|---|---|
| python文件 | 通用,传播方便,适用于大型项目 | 需要从头运行 |
| python控制台 | 显示每个变量属性 | 不利于代码阅读及修改 |
| jupyter | 利于代码阅读及修改 | 环境需要配置 |
pytorch加载数据
1. dataset类
提供一种方式去获取数据及其label
read_demo.py
在PyTorch中,Dataset 类是torch.utils.data模块的一部分,它是一个抽象的基类,用于定义了数据集加载和处理的标准接口。通过继承这个类并实现其方法,可以创建自定义的数据集来适应各种机器学习任务。2. dataloader类
为后面的网络提供不同的数据形式
3. 补充函数
通过os模块,我们可以执行文件和目录的创建、删除、重命名等操作
os.path.join()
Python 中 os.path 模块提供的一个函数,用于将多个路径组件智能地拼接成一个完整的路径。
它会根据当前操作系统的路径分隔符(如 Windows 的 \ 或 Unix 的 /)自动处理路径拼接,避免手动拼接时可能出现的错误。 os.listdir()
Python中用于获取指定目录下所有文件和子目录的函数。 Image.open(path)
得到的img数据类型是Image对象,不是普通的数组Tensorboard使用
test.tb.py文件
Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可视化使得tensorflow程序的理解、调试和优化更加简单高效。
Tensorboard的可视化依赖于tensorflow程序运行输出的日志文件,因而tensorboard和tensorflow程序在不同的进程中运行。1.安装Tensorboard
终端中CTRL+C 结束
Anaconda Prompt中进入Mypytorch环境 --- pip install tensorboard
Pycharm终端 --- pip install tensorboard2. SummaryWriter类
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("log_dir")
SummaryWriter 创建一个tensorboard文件, 文件保存在log_dir 目录(自己指定的目录)写文件,该文件可以被tensorboard解析3. 如何打开事件文件
Anaconda Prompt中进入Mypytorch环境
或
Pycharm终端 --- tensorboard --logdir=时间文件所在文件夹名默认打开6006端口,为了与别人冲突,可指定端口
tensorboard --logdir=log_dir --port=6007
4. add_scalar()函数
这个函数用于在tensorboard中加入loss,其中常用参数有:
tag:标签
scalar_value:标签的值 - y轴的坐标
global_step:标签的x轴坐标5. add_image()函数
tag: 就是保存图的名称
img_tensor:图片的类型要是torch.Tensor, numpy.array, or string这三种
golbal_step:第几张图片6. image中图片类型转换
torch.Tensor
transforms.ToTensor方法numpy.array
opencv中cv2.imread()函数参数是jpg等类型
numpy.array()函数参数是PIL数据类型利用Opencv读取图片,获取numpy型图片数据
安装Opencv:终端 --- pip install opencv-python
import cv2
cv_img = cv2.imread(img_path)
利用numpy.array(),对PIL图片进行转换
import numpy as np
img_numpy = np.array(img) # 转换成numpy类型
注意图片的形状:print(img_array.shape),可通过查看add_image()函数定义进行修改string
transforms的使用
torchvision中的transforms
from torchvision import transforms
指的是transforms.py工具箱
transform是torchvision下的一个.py文件,这个python文件中定义了很多的类和方法,
主要实现对图片进行一些变换操作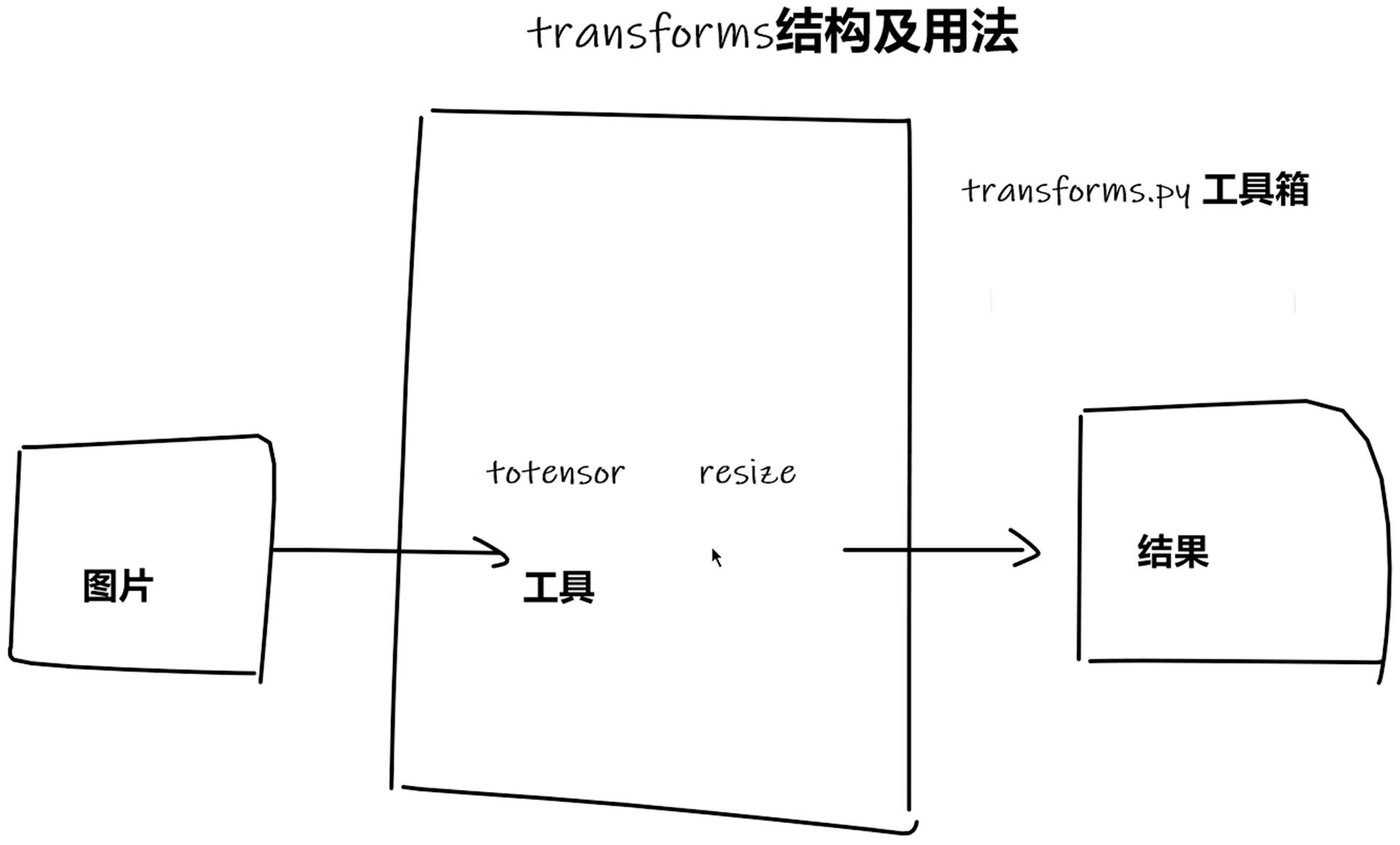
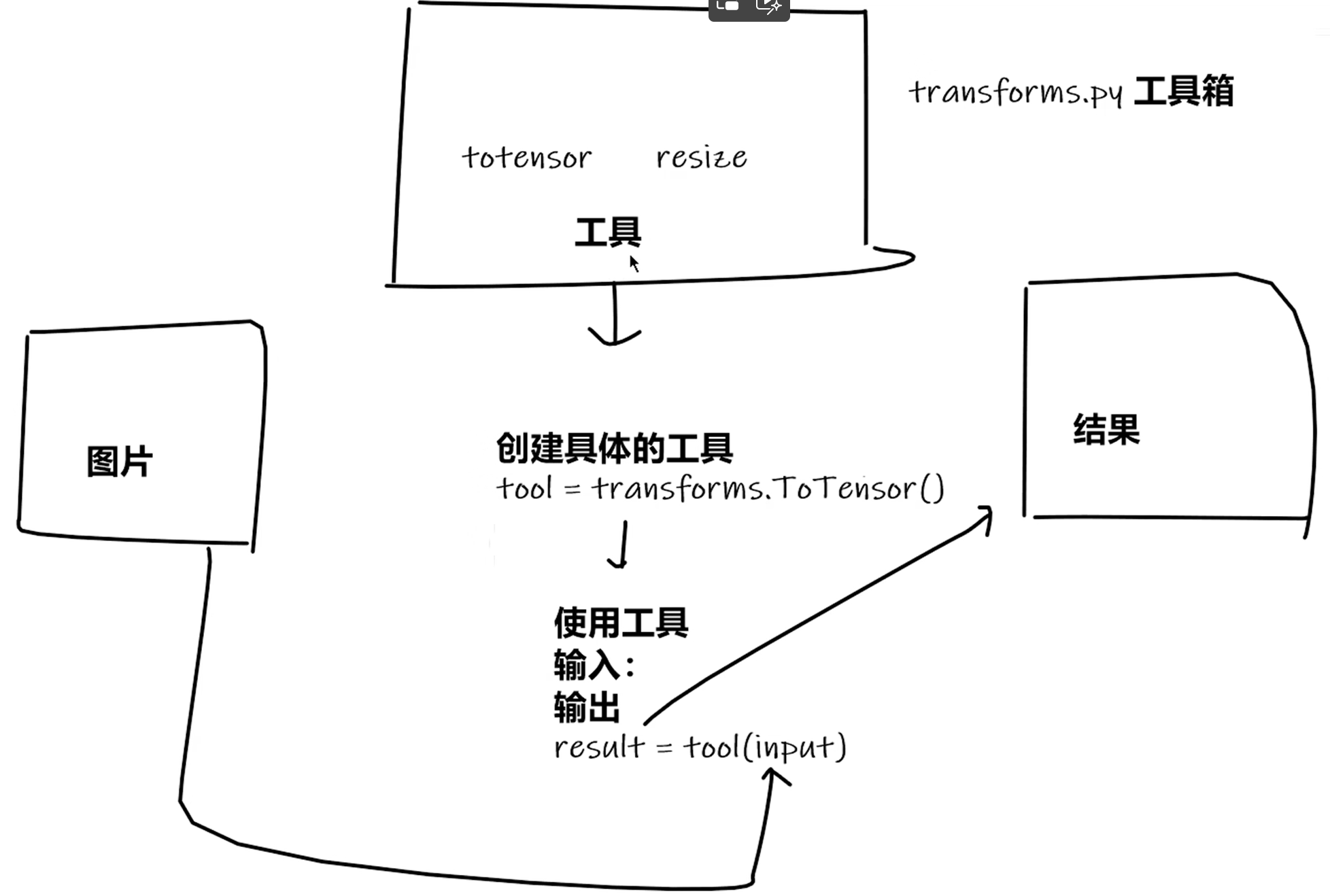
1. transforms.ToTensor - 类
Convert a PIL Image or ndarray to tensor and scale the values accordingly
transforms该如何使用
transforms.py
from torchvision import transforms from PIL import Image img_path = "dataset/train/ants_image/5650366_e22b7e1065.jpg" img = Image.open(img_path) # ToTensor类实例化 transforms = transforms.ToTensor() print(transforms) # ToTensor() # 转换成tensor数据类型 tensor_img = transforms(img) # =tensor_img = transforms.__call__(img) print(type(tensor_img))为什么需要Tensor数据类型
2. transform中的__call__()
TestCall.py
3. transform.Normalize 类
transforms.Normalize(mean, std)是torchvision.transforms模块提供的一个图像预处理方法,用于对图像的每个通道(例如 RGB)进行标准化处理。
output[channel] = (input[channel] - mean[channel]) / std[channel]
input:原始图像张量(已经通过ToTensor()转换为 [C, H, W] 格式,值域在 [0, 1])mean:每个通道的均值std:每个通道的标准差
4. transform.Resize 类
transforms.Resize(size)
是 PyTorch 中的图像处理函数之一,用于调整图像的大小。
该函数可以用于将输入图像调整为指定的大小或按照指定的缩放因子进行调整。
5. transforms.Compose 类
| 输入 | PIL | Image.open() |
|---|---|---|
| 输出 | tensor | ToTensor() |
| 作用 | narrays | cv.imread() |
是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起
Compose()中的参数需要是一个列表
Python中,列表的表示形式为[数据1, 数据2, ...]
在Compose中,数据需要时transforms类型
所以得到,Compose([transforms参数1, transforms参数2, ...])6. transforms.RandomCrop 类、
transforms.RandomCrop是一个数据转换操作,用于从图片中随机裁剪出指定尺寸的图片。
参数:
transforms.RandomCrop是一个数据转换操作,用于从图片中随机裁剪出指定尺寸的图片。
参数:
size:所需裁剪图片的尺寸,可以是一个整数或一个元组(width, height)。如果是一个整数,则表示裁剪出的图片将具有相等的宽度和高度。
padding:填充大小,可以是一个整数、一个元组或一个列表。当为整数时,表示上下左右均填充相同数量的像素;当为元组或列表时,分别表示左、上、右、下的填充数量。
pad_if_needed:若图像小于设定的尺寸,则是否进行填充,默认为False。
fill:填充的像素值,默认为0。
padding_mode:填充模式,有4种模式
1、constant:像素值由 fill 设定
2、edge:像素值由图像边缘像素决定
3、reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4] → [3,2,1,2,3,4,3,2]
4、symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] → [2,1,1,2,3,4,4,3]
使用transforms.RandomCrop可以在保持图像比例的情况下,随机裁剪出指定尺寸的图片。裁剪时会随机选择裁剪的起始位置,并保证裁剪后的图片尺寸与指定的尺寸相匹配。如果需要进行填充,则会根据填充大小和填充模式进行填充操作。
7. 总结
torchvision中的数据集使用
P10_dataset_transform.py
torchvision中的dataset的使用
DataLoader的使用
DataLoader是PyTorch基础概念
DataLoader是PyTorch中用于加载数据的工具,它可以:批量加载数据(batch loading)打乱数据(shuffling)并行加载数据(多线程)
自定义数据加载方式Dataloader的基本使用from torch.utils.data import Dataset, DataLoader
DataLoader是什么?
我们可以这样理解:如果Dataset数据集是一个存储所有数据(图像、音频)的容器,那么DataLoader就是另一个具有更好收纳功能的容器,其中分隔开来很多小隔间,可以自己设定一个小隔间有多少个数据集的数据来组成,每次将数据放进收纳小隔间的时候要不要把源数据集打乱再进行收纳等等
也就是说,给定了一个数据集,我们可以决定如何从数据集里面拿取数据来进行训练,比如一次拿取多少数据作为一个对象来对数据集进行分割,对数据集进行分割之前要不要打乱数据集等等。DataLoader的结果就是一个对数据集进行分割的大字典列表,列表中的每个对象都是由设置的多少个数据集的对象组合而成的.
默认情况下遍历dataloader其实就是输出一个batch内的图像和对应的label
DataLoader重要参数详解
- dataset: 要加载的数据集,必须是Dataset类的实例
- batch_size: 每个批次的样本数
- shuffle:是否在每个epoch重新打乱数据,True:重置
- sampler:自定义从数据集中抽取样本的策略,如果指定了sampler,则shuffle必须为False
- num_workers:使用多少个子进程加载数据,0表示在主进程中加载。
- collate_fn:将一批数据整合成一个批次的函数,特别使用于处理不同长度的序列数据
- Pin_memory:如果为True,数据加载器会将张量复制到CUDA固定内存中,加速CPU到GPU的数据传输
- drop_last: 如果数据集大小不能被batch_size整除,是否丢弃最后一个不完整的批次。True:丢弃,False:保留
- timeout:收集一个批次的超时值
- worker_init_fn:每个worker初始化时被调用的函数
- weight_sampler:参数决定是都使用加权采样器来平衡类别分布
神经网络nn
torch.nn
- Containers
- Convolution Layers
- Pooling layers
- Padding Layers
- Non-linear Activations (weighted sum, nonlinearity)
- Non-linear Activations (other)
- Normalization Layers
- Recurrent Layers
- Transformer Layers
- Linear Layers
- Dropout Layers
- Sparse Layers
- Distance Functions
- Loss Functions
- Vision Layers
- Shuffle Layers
- DataParallel Layers (multi-GPU, distributed)
- Utilities
- Quantized Functions
- Lazy Modules Initialization
神经网络的骨架Containers
1. nn.Module的使用
神经网络的基本骨架 — Neural network
Neural network文本
输入 —> forward()函数 —> 输出
重写方法快捷键:代码 - 生成 — Alt+insert
2. nn.Sequential
类似与transforms.Compose
卷积层Convolution Layers
1. 卷积操作nn.functional.Conv2d
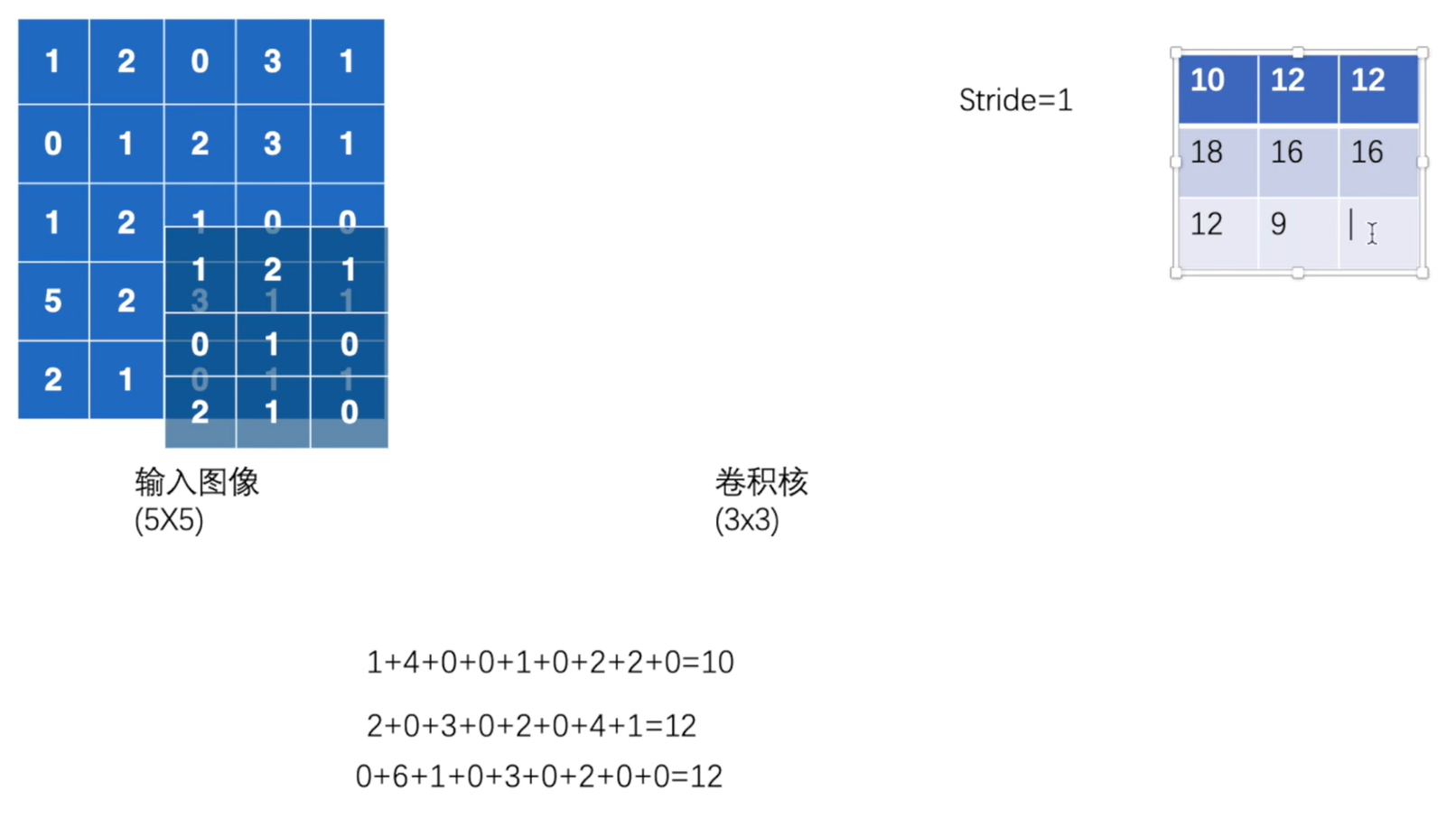
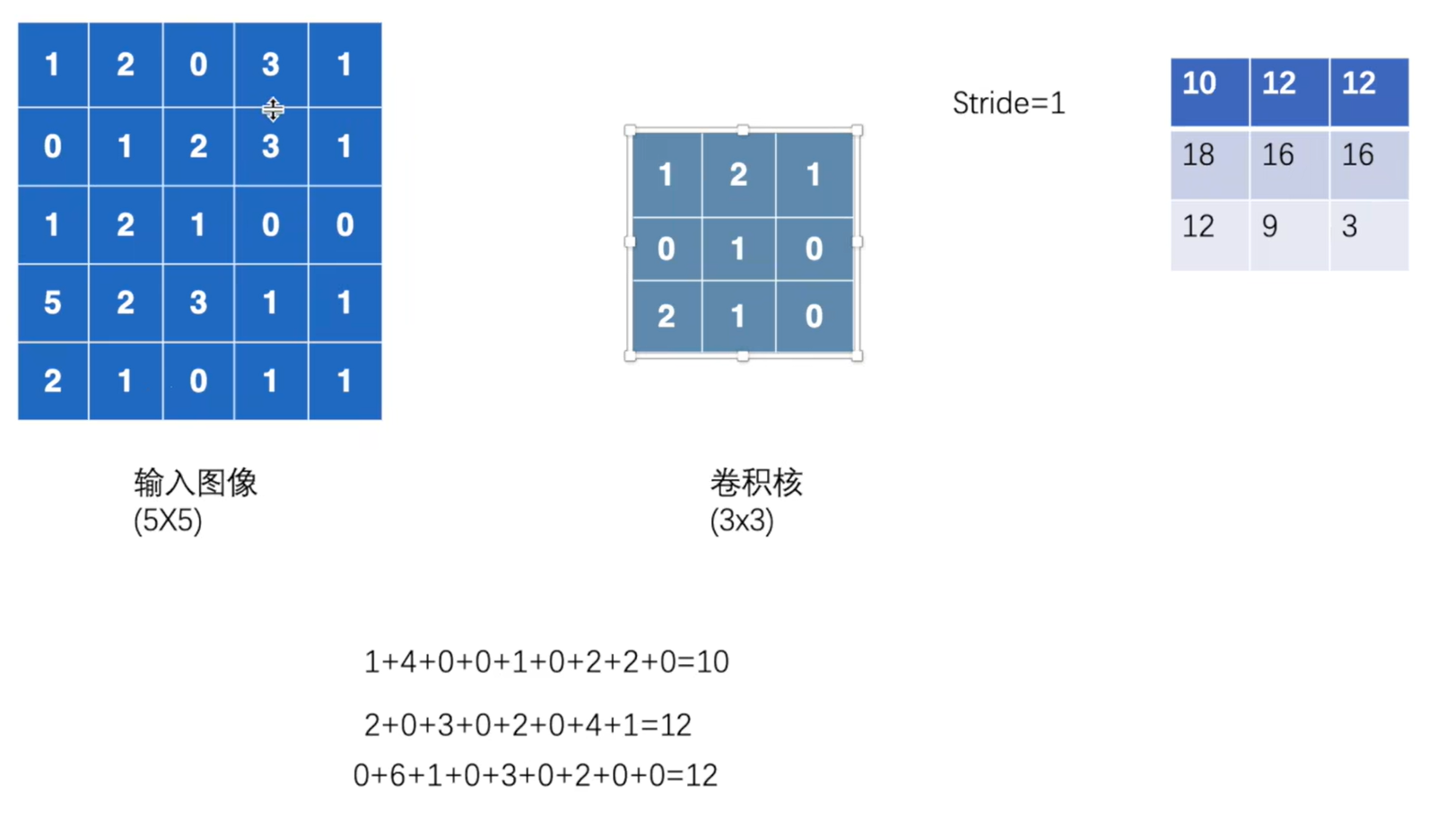
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)input:input – input tensor of shape (minibatch,in_channels,iH,iW)
minibatch:batch中的样例个数
in_channels:每个样例数据的通道数
iH:每个样例的高(行数)
iW:每个样例的宽(列数)weight(就是filter 卷积核\textcolor{red}{卷积核}卷积核 )weight – filters of shape (out_channels, groupsin_channels ,kH,kW)
out_channels:卷积核的个数
in_channels/groups:每个卷积核的通道数
kH:每个卷积核的高(行数)
kW:每个卷积核的宽(列数)bias:即是否要添加偏置参数作为可学习参数的一个,默认为True。
stride = 1:卷积核在图像窗口上每次平移的间隔,即所谓的步长。
padding:指图像填充,后面的int型常数代表填充的多少(行数、列数),默认为0。需要注意的是这里的填充包括图像的上下左右,以padding=1为例,若原始图像大小为[32, 32],那么padding后的图像大小就变成了[34, 34]
dilation:是否采用空洞卷积,默认为1(不采用)。从中文上来讲,这个参数的意义从卷积核上的一个参数到另一个参数需要走过的距离,那当然默认是1了,毕竟不可能两个不同的参数占同一个地方吧(为0)。更形象和直观的图示可以观察Github上的Dilated convolution animations,展示了dilation=2的情况。
groups:决定了是否采用分组卷积,groups参数可以参考groups参数详解
调节尺寸:
img = touch.reshape(图像名称, (minibatch, in_channels, iH, kW))
output = torch.reshape(output, (-1, 3, 30, 30))
第一个参数不知道是什么数字时候,填写-1,系统自动计算出minibatch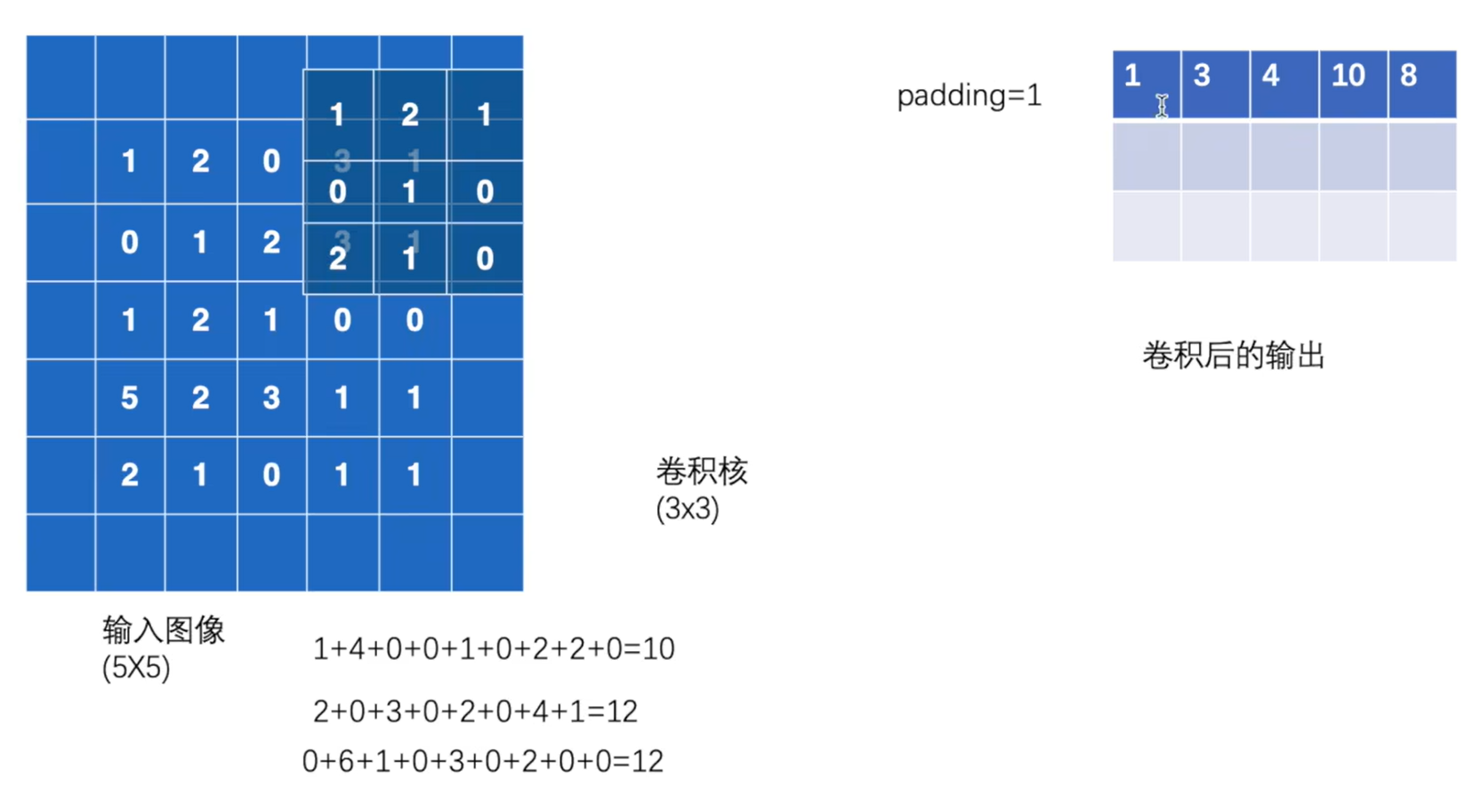
2. Conv2d卷积函数
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)- in_channels (int) – 输入图像的通道数,RGB图像的输入通道数为3\textcolor{red}{RGB 图像的输入通道数为3}RGB图像的输入通道数为3 可通过torch.reshape()函数修改
- out_channels (int) – 卷积生成的输出通道数
- kernel_size (int 或 tuple) – 卷积核的大小
- stride (int 或 tuple, 可选) – 卷积的步幅。默认值:1
- padding (int, tuple 或 str, 可选) – 在输入的四周添加的填充。默认值:0。padding=0表示在输入的周围不添加填充;padding=1表示在输入的四周添加0填充。
- padding_mode (str, 可选) – 填充模式,可以为 ‘zeros’(零填充)、‘reflect’(用输入的反射值填充)、‘replicate’(复制输入边缘的值填充)或 ‘circular’(循环填充)。默认值:‘zeros’
- dilation (int 或 tuple, 可选) – 卷积核元素之间的间隔。默认值:1
- groups (int, 可选) – 从输入通道到输出通道的分组连接数。默认值:1
- bias (bool, 可选) – 如果为 True,则为输出添加可学习的偏差项。默认值:True
kernel_size:卷积核的大小,一般我们会使用 5x5、3x3 这种左右两个数相同的卷积核,因此这种情况只需要写 kernel_size = 5这样的就行了。如果左右两个数不同,比如3x5的卷积核,那么写作kernel_size = (3, 5),注意需要写一个 tuple,而不能写一个 list。所有参数动态展示
dilation效果展示
[卷积层图片网站vgg6 model](vgg6 model)
论文重要使用公式:
Input:( N , Cin , Hin , Win ) or ( Cin , Hin , Win )
Output:(N , Cout , Hout , Wout) or ( Cout , Hout , Wout) , where
Hout = ⌊ H in +2×padding[0]−dilation[0]×(kernel_size[0]−1)−1stride[0]\frac{H~in~+2×padding[0]−dilation[0]×(kernel\_size[0]−1)-1}{stride[0]}stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1⌋
Wout = ⌊ W in +2×padding[1]−dilation[1]×(kernel_size[1]−1)−1stride[1]\frac{W~in~+2×padding[1]−dilation[1]×(kernel\_size[1]−1)−1}{stride[1]}stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1⌋
池化层Pooling Layers
1.最大池化MaxPool2d
最大池化是一种空间降维操作,它通过在局部区域取最大值来缩减特征图的尺寸,同时保留最重要的特征信息。
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)- kernel_size (Union[int,tuple[int,int]]) – the size of the window to take a max over
- stride (Union[int,tuple[int,int]]) – the stride of the window. Default value is kernel_size\textcolor{red}{Default\ value\ is\ kernel\_size}Defaultvalueiskernel_size
- padding (Union[int,tuple[int,int]]) – Implicit negative infinity padding to be added on both sides
- dilation (Union[int,tuple[int,int]]) – a parameter that controls the stride of elements in the window
- return_indices (bool) – if
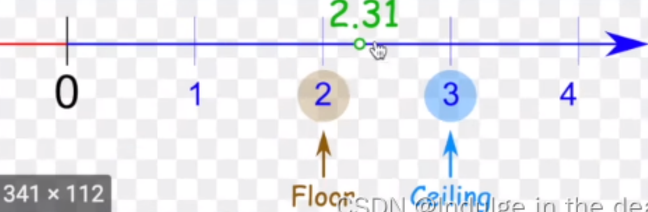
True, will return the max indices along with the outputs. Useful fortorch.nn.MaxUnpool2dlater - ceil_mode (bool) – when True, will use ceil\textcolor{red}{ceil}ceil instead of floor\textcolor{red}{floor}floor to compute the output shape
ceil 和 floor 区别
[图片搜索ceil floor mode](ceil floor mode)
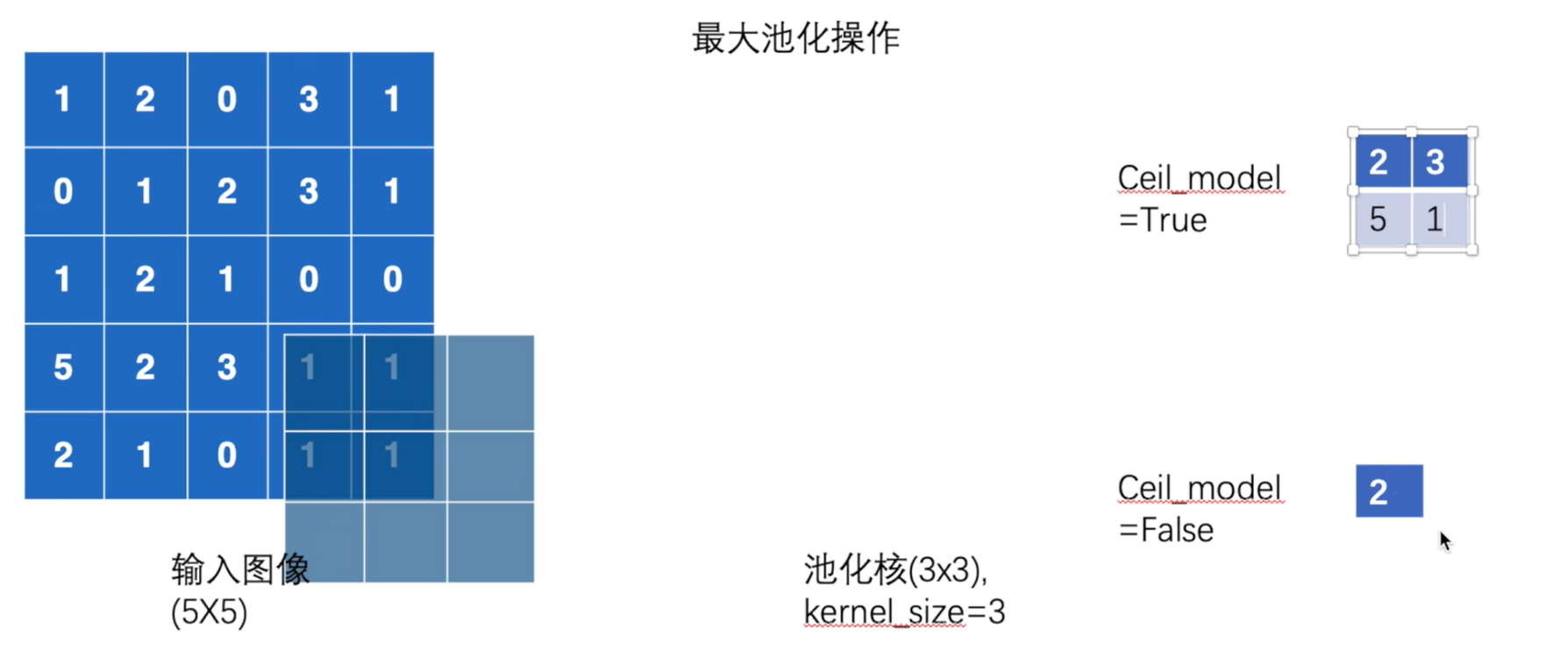
1. 池化前后不改变通道数
2. 图片池类似于马赛克情况非线性激活Non-linear Activations(other)
1.nn.ReIU
class torch.nn.ReLU(inplace=False)
Parameters
- inplace (bool) – can optionally do the operation in-place. Default:
False
input = -1
nn.ReLu(input, inplace = True)
input = 0
---------------------------------
input = -1
output = nn.ReLU(input, inplace = False)
input = -1
output = 0Shape:
- Input: (∗), where ∗ means any number of dimensions. — 必须有batch_size — 可通过torch.reshape()更改
- Output: (∗), same shape as the input.
2.Sigmoid
class torch.nn.Sigmoid(***args, **kwargs)
1. 阴影效果线性层Linear Layers
1. nn.linear
class torch.nn.Linear\textcolor{purple}{Linear}Linear(in_features , out_features , bias=True, device=None, dtype=None)
Applies an affine linear transformation to the incoming data: y=xAT+by=xAT+b.
Parameters
- in_features (int) – size of each input sample
- out_features (int) – size of each output sample
- bias (bool) – If set to
False, the layer will not learn an additive bias. Default:True,则公式中+b
输入
- Linear 层需要的输入是一维的特征向量
输入维度和输出维度
- Linear 层有明确的输入维度和输出维度,输入维度对应上一层输出特征的数量,输出维度则根据具体任务需求来设定

2. Flatten
Flatten概念
- 在深度学习中,很多层的输出往往是多维的张量,例如卷积层输出的特征图通常是(batch_size, channels, height, width)的四维张量。而 Linear 层需要的输入是一维的特征向量,此时 Flatten 层就发挥了关键作用,它能够将多维张量展平为一维向量,为后续的 Linear 层处理做好准备
Flatten层的作用
- Flatten 层的核心作用就是数据格式转换。它将多维的输入张量按照一定的顺序(通常是从后往前依次拼接)展平成一个一维的向量。这种转换不会改变数据的本质信息,只是改变了数据的组织形式,使得多维特征能够被 Linear 层等需要一维输入的层所处理
Flatten层的核心要素
torch.flatten(input, start_dim=0, end_dim=1) -> Tensor
Parameters
- input (Tensor) – the input tensor.
- start_dim (int) – the first dim to flatten
- end_dim (int) – the last dim to flatten*
正则化层Normalization Layers
Recurrent Layers
Recurrent Layers、Transformer Layers、Sparse Layers三者在特定网络中用到
Transformer Layers
Sparse Layers
Dropout Layers
搭建小实战
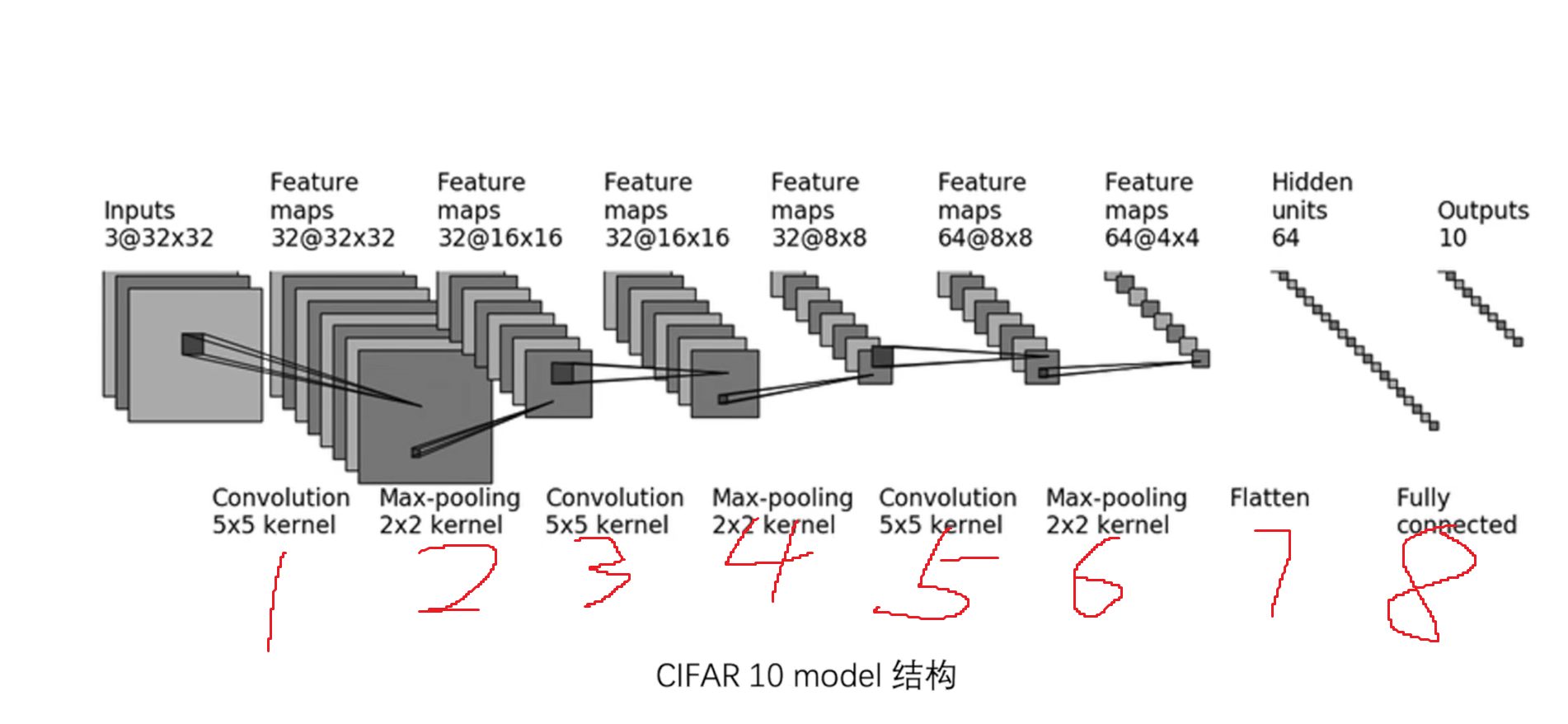
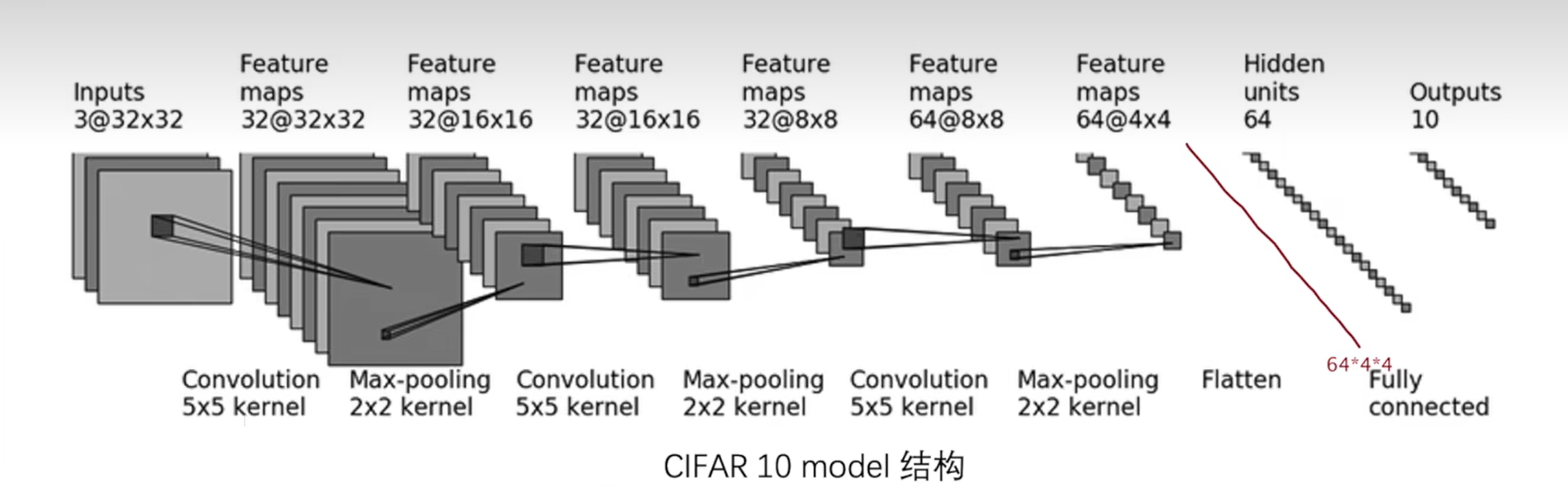
Convolution 5×5 kernel
宽度和高度未变,通过公式可以求出来padding [32+2*padding-1*(5-1)-1]/stride +1 = 32 ->padding=2; stride=1[跳转到函数位置](#2. Conv2d卷积函数)
Max-pooling 2×2 kernel
Convolution 5×5 kernel
[16+2*padding-1*(5-1)-1]/stride +1 = 16 ->padding=2; stride=1Max-pooling 2×2 kernel
Convolution 5×5 kernel
[8+2*padding-1*(5-1)-1]/stride +1 = 8 ->padding=2; stride=1前后尺寸不变则padding=2,stride=1
Max-pooling 2×2 kernel
Flatten
Full connected
衡量误差,损失函数Loss Function

1. nn.L1Loss
L1Loss 计算方法很简单,取预测值和真实值的绝对误差的平均数即可。

class torch.nn.L1Loss\textcolor{purple}{L1Loss}L1Loss (size_average=None, reduce=None, reduction=‘mean’)
- reduction = “mean” 是求误差的平均值
- reduction = “sum” 是求误差的和
input = torch.tensor([1, 2, 3], dtype=torch.float32)
target = torch.tensor([1, 2, 5], dtype=torch.float32)
# print(input.shape) #torch.Size([3])
loss = torch.nn.L1Loss(reduction="sum")
output = loss(input, target)
print(output) # tensor(2.)2.nn.MSELoss
平方损失函数。其计算公式是预测值和真实值之间的平方和的平均数。

class torch.nn.MSELoss\textcolor{purple}{MSELoss}MSELoss (size_average=None, reduce=None, reduction=‘mean’)
# 接上部分
# mse
loss_mse = torch.nn.MSELoss()
output_mse = loss_mse(input, target)
print(output_mse) # tensor(1.3333)3. nn.CrossEntropyLoss
交叉熵损失函数
该公式用的也较多,比如在图像分类神经网络模型中就常常用到该公式。

class torch.nn. CrossEntropyLoss\textcolor{purple}{CrossEntropyLoss}CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=‘mean’, label_smoothing=0.0)

函数是用于图像识别验证的,对输入参数有格式要求
Shape:\textcolor{red}{Shape:}Shape:
- Input: Shape ©, (N,C) or (N,C,d1,d2,…,dK) with K≥1 in the case of K-dimensional loss.
4. 反向传播
backward()函数
5. 损失函数
如何在之前写的神经网络(搭建小实战)中用到Loss Function(损失函数)
P21_nn_network.py
优化器
作为系列的第一篇文章,本文介绍Pytorch中的SGD、ASGD、Rprop、Adagrad,其中主要介绍SGD和Adagrad。因为这四个优化器出现的比较早,都存在一些硬伤,而作为现在主流优化器的基础又跳不过,所以作为开端吧。
我们定义一个通用的思路框架,方便在后面理解各算法之间的关系和改进。首先定义待优化参数 ,目标函数,学习率为 ,然后我们进行迭代优化,假设当前的epoch为,参数更新步骤如下:
计算目标函数关于当前参数的梯度:
gt=▽J(θt−1) (1)
根据历史梯度计算一阶动量和二阶动量:
mt=ϕ(g1,g2…,gt) (2)
vt=φ(g1,g2…,gt) (3)
计算当前时刻的下降梯度:
△θ=η∗m t v t \frac{m~t~}{\sqrt{v~t~}}vtmt (4)
根据下降梯度进行更新:
θt=θt−1−△θ (5)
下面介绍的所有优化算法基本都能套用这个流程,只是式子(4)的形式会有变化。优化器使用时必须构造一个优化器对象,它将保存当前状态,并将根据计算的梯度(grad)更新参数。
调用优化器的step方法。
CLASS torch.optim.Optimizer(params, defaults)
- Optimizer - 优化器的优化算法。
- params (iterable) – torch的迭代器。张量s或dict s,指定应该优化什么张量。
- defaults – (dict): 包含优化选项默认值的字典(在参数组没有指定优化选项时使用)。每个Optimizer算法都有其独特的设置字典。
| 算法(Optimizer | 说明 |
|---|---|
| Adadelta | 采用Adadelta算法 |
| Adagrad | 采用Adagrad算法 |
| Adam | 采用Adam算法 |
| AdamW | 采用AdamW算法 |
| SparseAdam | 采用适合稀疏张量的Adam算法的惰性版本 |
| Adamax | 采用Adamax算法(Adam基于无穷范数的变种) |
| ASGD | 采用平均随机梯度下降 |
| LBFGS | 采用L-BFGS算法,深受minFunc的启发 |
| NAdam | 采用NAdam 算法 |
| RAdam | 采用RAdam 算法 |
| RMSprop | 采用RMSprop 算法 |
| Rprop | 采用有弹性的反向传播算法 |
| SGD | 采用随机梯度下降算法 |
1. SGD
CLASS torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False, *, maximize=False, foreach=None, differentiable=False)
params (iterable) – iterable参数优化或字典定义参数组。
lr (float) – 学习率,需要用户输入。
momentum (float, optional) – 动量系数(默认值为0)。
weight_decay (float, optional) – 权重衰减(L2惩罚) (默认值为0)。
dampening (float, optional) – 动量阻尼(默认值为0)。
nesterov (bool, optional) – 使能Nesterov动量(默认值为False)。
【Nesterov动量(Nesterov Momentum)是一种基于动量法的优化算法,用于加速神经网络的训练过程。它在随机梯度下降(SGD)的基础上进行改进,通过考虑参数更新前的动量信息来调整参数更新的方向。】
maximize (bool, optional) – 根据目标最大化参数,而不是最小化参数(默认值为False)。
foreach (bool, optional) – 是否使用foreach优化器的实现。如果用户未指定(foreach为None),我们将尝试在CUDA上的for循环实现上使用foreach,因为CUDA通常性能更高(默认值:None)。
differentiable (bool, optional) – 是否在训练中的优化器步骤中发生autograd。否则,step()函数在torch.no_grad()上下文中运行。设置为True会影响性能,所以如果你不打算通过这个实例运行autograd,请保留False(默认值为False)。
学习速率(lr)的取值,如果太大,则模型很不稳定;如果太小,学习速度非常缓慢。因此一般先设置较大的学习速率,然后降低学习速率。
loss = torch.nn.CrossEntropyLoss()
tudui = TuDui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for data in data_loader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
# print(result_loss)
optim.zero_grad() # grad清零
result_loss.backward()
optim.step() # 优化结论:运行opitm.zero_grad()后,清空weight和bias的梯度grad;运行result_loss.backward()后,计算得到新的weight和bias的梯度grad;运行opitm.step()后,调整weight和bias的值。现有网络的使用和修改
Downloading: “https://download.pytorch.org/models/vgg16-397923af.pth” to C:\Users\86159/.cache\torch\hub\checkpoints\vgg16-397923af.pth
VGG6模型
VGG16是一种深度卷积神经网络模型,用于图像分类和识别任务。它是由牛津大学的研究团队开发的,命名为Visual Geometry Group(VGG),并在2014年的ImageNet图像识别挑战中取得了很好的成绩。
VGG16模型具有13个卷积层和3个全连接层,总共有约138百万个可训练参数。该模型的核心思想是通过堆叠多个小尺寸的卷积核和池化层来增加网络的深度,从而提高图像特征的表示能力。它采用了相对较小的3x3卷积核和2x2最大池化核,每个卷积层后都使用了ReLU激活函数。
VGG16的结构相对简单而经典,是深度学习中常用的基准模型之一。它在图像分类任务中表现出色,能够有效地识别和区分不同的物体类别。由于其简单的结构和可扩展性,VGG16也常被用作迁移学习的基础模型,在各种计算机视觉任务中发挥重要作用,如目标检测、图像分割等。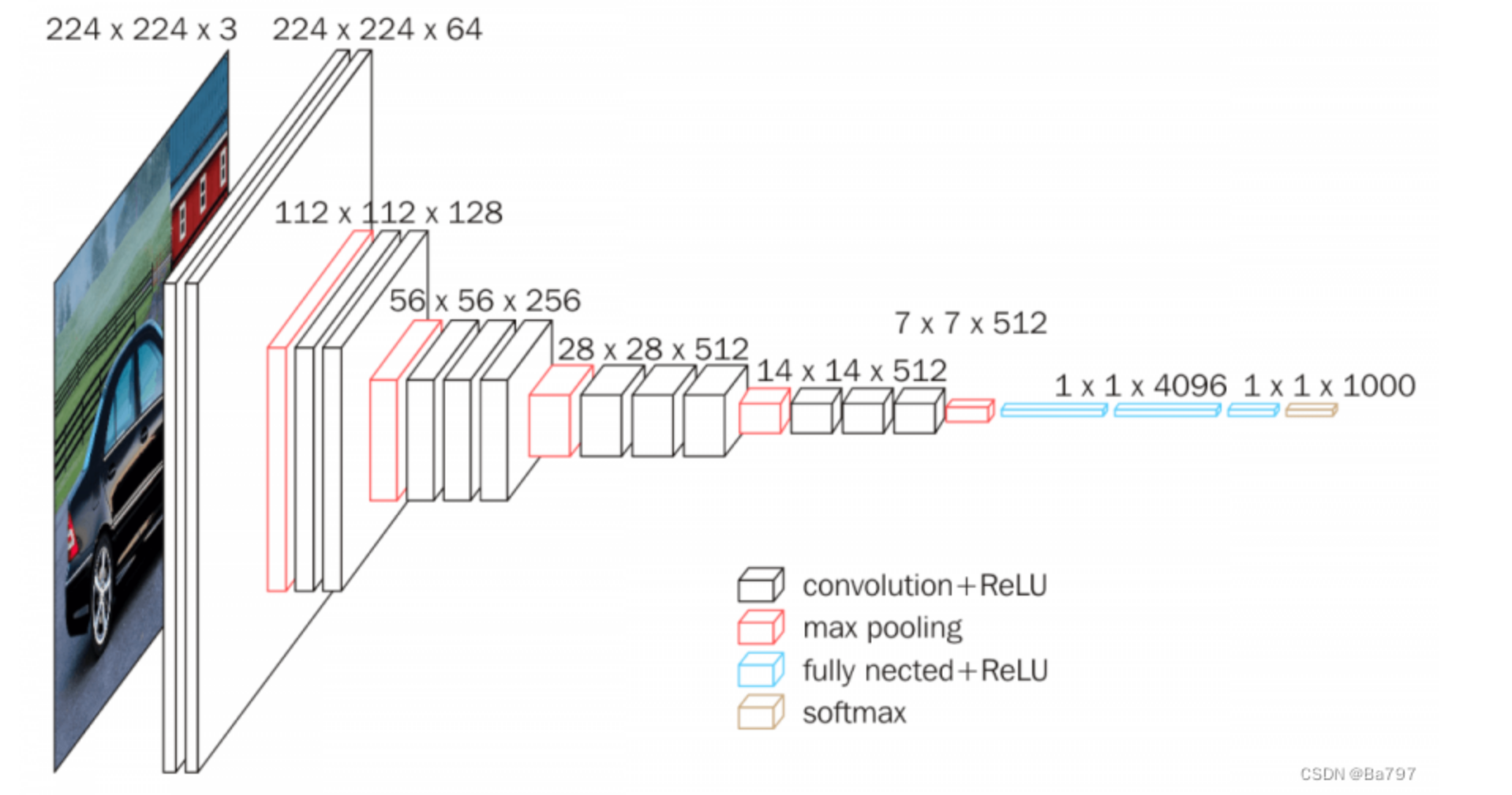
import torch
import torchvision
# # 生成image net数据集
# train_data = torchvision.datasets.ImageNet(root="../data_image_net", split="train",
# transform=torchvision.transforms.ToTensor(),
# downloard=True)
# 网络模型
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print("vgg16_false:{}".format(vgg16_false))
# 对vgg16_false进行增加linear
vgg16_false.add_module("add_linear_out", torch.nn.Linear(1000, 10)) # 在外部增加
vgg16_false.classifier.add_module("add_linear_in", torch.nn.Linear(1000, 10))
print("vgg16_false:{}".format(vgg16_false))
print("vgg16_true:{}".format(vgg16_true))
# 对vgg16_true进行修改
vgg16_true.classifier[6] = torch.nn.Linear(1000, 10)
print("vgg16_true:{}".format(vgg16_true))模型的保存和加载
1. 模型的保存
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2,模型参数(官方推荐)--- 对于大型模型,该方法保存书数据所占空间少
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 保存方式1的陷阱1
class TuDui(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(64, 32, kernel_size=5)
def forward(self, x):
y = self.conv1(x)
return y
tudui = TuDui()
torch.save(tudui, "tudui_method1.pth")2. 模型的加载
import torch
import torchvision
from P24_model_save import *
# 方式1的加载
model1 = torch.load("vgg16_method1.pth")
print(model1)
# 方式2的加载
vgg16 = torchvision.models.vgg16(pretrained=False)
model2 = vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# print(model2) # <All keys matched successfully>print(vgg16)# 方式1的陷阱1的加载 --- 会报错# 需要在model_load.py文件在写一遍class TuDui()类(不用实例化tudui),或from P24_model_save import *# 解决方法1# class TuDui(torch.nn.Module):# def __init__(self):# super().__init__()# self.conv1 = torch.nn.Conv2d(64, 32, kernel_size=5)## def forward(self, x):# y = self.conv1(x)# return ymodel3 = torch.load("tudui_method1.pth")print(model3)加载方式2直接用加载方式1的方法,输出结果是字典形式完整的模型训练套路
主要框架
# 获取数据集
# 批量获取数据集
# 数据集的长度
# 创建网络模型
# 损失函数
# 优化器
# 训练时的一些参数
# 记录训练次数
# 记录测试次数
# 记录循环次数
# 训练步骤开始
# 优化器模型
# 测试步骤开始model1.py文件
import torch
from torch import nn
class TuDui(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
tudui = TuDui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)train.py文件
import torchvision
import torch
from torch import nn
from model1 import *
# 获取数据集
train_data = torchvision.datasets.CIFAR10(root="dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset2", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
# 批量获取数据集
loader_train = torch.utils.data.DataLoader(dataset=train_data, batch_size=64)
loader_test = torch.utils.data.DataLoader(dataset=test_data, batch_size=64)
# 数据集的长度
len_train = len(train_data)
print("训练集的长度:{}".format(len_train))
len_test = len(test_data)
print("测试集的长度:{}".format(len(test_data)))
# 创建网络模型
tudui = TuDui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
# 训练时的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 记录循环次数
epoch = 10
for i in range(epoch):
print("--------第 {} 轮循环--------".format(i))
for data in loader_train:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器模型
optim.zero_grad()
loss.backward()
optim.step()
total_train_step += 1
print("训练次数:{},Loss:{}".format(total_test_step, loss))第一次:优化train.py文件
1. 训练次数输出太频繁,改成每100次训练输出一次
2. 增加测试步骤
3. 通过tensorboard中的SummaryWriter进行图像显示:每100次训练loss和每一轮测试的loss总和import torchvision
import torch
from torch import nn
from model1 import *
from torch.utils.tensorboard import SummaryWriter
# 获取数据集
train_data = torchvision.datasets.CIFAR10(root="dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset2", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
writer = SummaryWriter("P26")
# 批量获取数据集
loader_train = torch.utils.data.DataLoader(dataset=train_data, batch_size=64)
loader_test = torch.utils.data.DataLoader(dataset=test_data, batch_size=64)
# 数据集的长度
len_train = len(train_data)
print("训练集的长度:{}".format(len_train))
len_test = len(test_data)
print("测试集的长度:{}".format(len(test_data)))
# 创建网络模型
tudui = TuDui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
# 训练时的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 记录循环次数
epoch = 10
for i in range(epoch):
print("--------第 {} 轮循环--------".format(i))
for data in loader_train:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器模型
optim.zero_grad()
loss.backward()
optim.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss))
writer.add_scalar("train_loss", loss, total_train_step)
# 测试步骤开始
total_test_loss = 0
with torch.no_grad():
for data in loader_test:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_step += 1
total_test_loss += loss
print("整体测试集上的Loss:{}".format(total_test_loss))
total_test_step += 1
writer.add_scalar("test_loss", total_test_loss, total_test_step)第二次:优化train.py文件
1.测试集的正确率计算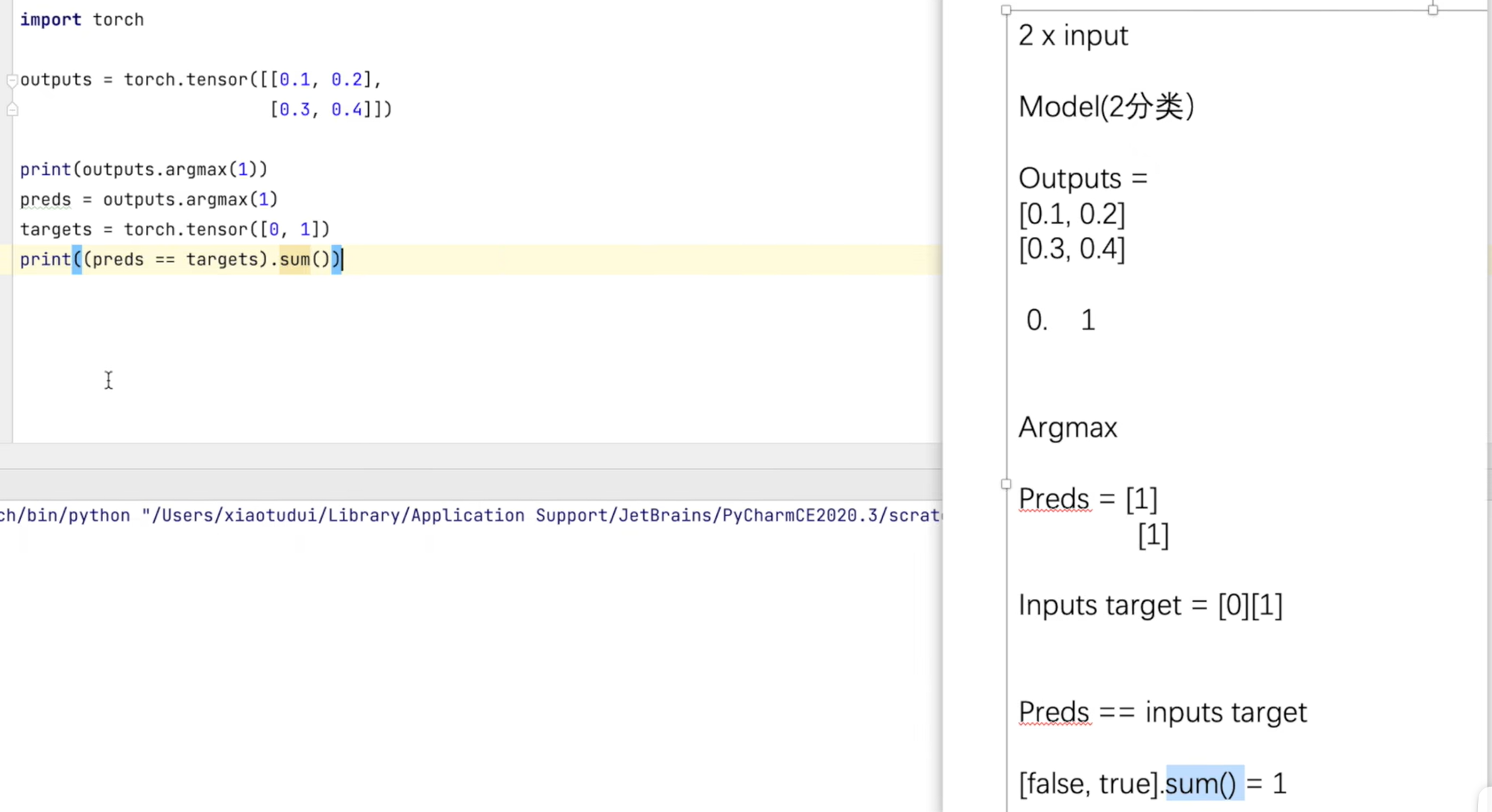
# 测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in loader_test:
imgs, targets = data
outputs = tudui(imgs)
# print(outputs)
# print(targets)
loss = loss_fn(outputs, targets)
total_test_step += 1
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
a = accuracy/len_test
print("整体测试的Loss:{}".format(total_test_loss))
print("整体测试的正确率:{}".format(total_accuracy/len_test))
total_test_step += 1
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("accuracy", total_accuracy, total_test_step)
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()什么是train()函数?
在PyTorch中,train()方法是用于在训练神经网络时启用dropout、batch normalization和其他特定于训练的操作的函数。这个方法会通知模型进行反向传播,并更新模型的权重和偏差。
在训练期间,我们通常会对模型的参数进行调整,以使其更好地拟合训练数据。而dropout和batch normalization层的行为可能会有所不同,因此在训练期间需要启用它们。
什么是eval()函数?
eval()方法是用于在评估模型性能时禁用dropout和batch normalization的函数。它还可以用于在测试数据上进行推理。这个方法不会更新模型的权重和偏差。
在评估期间,我们通常只需要使用模型来生成预测结果,而不需要进行参数调整。因此,在评估期间应该禁用dropout和batch normalization,以确保模型的行为是一致的。
什么是no_grad()函数?
no_grad()方法是用于在评估模型性能时禁用autograd引擎的梯度计算的函数。这是因为在评估过程中,我们通常不需要计算梯度。因此,使用no_grad()方法可以提高代码的运行效率。
在PyTorch中,所有的张量都可以被视为计算图中的节点,每个节点都有一个梯度,用于计算反向传播。no_grad()方法可以用于禁止梯度计算,从而节省内存和计算资源。
最终版本train.py文件
import torchvision
import torch
from torch import nn
from model1 import *
from torch.utils.tensorboard import SummaryWriter
# 获取数据集
train_data = torchvision.datasets.CIFAR10(root="dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset2", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
writer = SummaryWriter("P26")
# 批量获取数据集
loader_train = torch.utils.data.DataLoader(dataset=train_data, batch_size=64)
loader_test = torch.utils.data.DataLoader(dataset=test_data, batch_size=64)
# 数据集的长度
len_train = len(train_data)
print("训练集的长度:{}".format(len_train))
len_test = len(test_data)
print("测试集的长度:{}".format(len(test_data)))
# 创建网络模型
tudui = TuDui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
# 训练时的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 记录循环次数
epoch = 10
for i in range(epoch):
print("--------第 {} 轮循环--------".format(i))
# 训练步骤开始
tudui.train()
for data in loader_train:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器模型
optim.zero_grad()
loss.backward()
optim.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss))
writer.add_scalar("train_loss", loss, total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in loader_test:
imgs, targets = data
outputs = tudui(imgs)
# print(outputs)
# print(targets)
loss = loss_fn(outputs, targets)
total_test_step += 1
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
a = accuracy/len_test
print("整体测试的Loss:{}".format(total_test_loss))
print("整体测试的正确率:{}".format(total_accuracy/len_test))
total_test_step += 1
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("accuracy", total_accuracy, total_test_step)
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()利用GPU训练
模型、数据(输入和标注)、损失函数可以调用.cuda
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
# 获取数据集
train_data = torchvision.datasets.CIFAR10(root="dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset2", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
writer = SummaryWriter("P26")
# 批量获取数据集
loader_train = torch.utils.data.DataLoader(dataset=train_data, batch_size=64)
loader_test = torch.utils.data.DataLoader(dataset=test_data, batch_size=64)
# 数据集的长度
len_train = len(train_data)
print("训练集的长度:{}".format(len_train))
len_test = len(test_data)
print("测试集的长度:{}".format(len(test_data)))
# 创建网络模型
class TuDui(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
tudui = TuDui()
if torch.cuda.is_available():
tudui = tudui.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
# 训练时的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 记录循环次数
epoch = 10
for i in range(epoch):
print("--------第 {} 轮循环--------".format(i))
# 训练步骤开始
tudui.train()
start_time = time.time()
for data in loader_train:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器模型
optim.zero_grad()
loss.backward()
optim.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss))
writer.add_scalar("train_loss", loss, total_train_step)
end_time = time.time()
print(end_time - start_time)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in loader_test:
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
imgs, targets = data
outputs = tudui(imgs)
# print(outputs)
# print(targets)
loss = loss_fn(outputs, targets)
total_test_step += 1
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
a = accuracy / len_test
print("整体测试的Loss:{}".format(total_test_loss))
print("整体测试的正确率:{}".format(total_accuracy / len_test))
total_test_step += 1
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("accuracy", total_accuracy, total_test_step)
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()方法二

# 1. 网络模型和损失函数不需要再重新赋值,二数据必须要重新赋值
# 2. 定义训练的设备 --- 有的写代码块
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
# 定义训练的设备
device = torch.device("cpu")
# 获取数据集
train_data = torchvision.datasets.CIFAR10(root="dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset2", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
writer = SummaryWriter("P26")
# 批量获取数据集
loader_train = torch.utils.data.DataLoader(dataset=train_data, batch_size=64)
loader_test = torch.utils.data.DataLoader(dataset=test_data, batch_size=64)
# 数据集的长度
len_train = len(train_data)
print("训练集的长度:{}".format(len_train))
len_test = len(test_data)
print("测试集的长度:{}".format(len(test_data)))
# 创建网络模型
class TuDui(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
tudui = TuDui()
tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
# 训练时的一些参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 记录循环次数
epoch = 10
for i in range(epoch):
print("--------第 {} 轮循环--------".format(i))
# 训练步骤开始
tudui.train()
start_time = time.time()
for data in loader_train:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器模型
optim.zero_grad()
loss.backward()
optim.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss))
writer.add_scalar("train_loss", loss, total_train_step)
end_time = time.time()
print(end_time - start_time)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in loader_test:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
# print(outputs)
# print(targets)
loss = loss_fn(outputs, targets)
total_test_step += 1
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
a = accuracy / len_test
print("整体测试的Loss:{}".format(total_test_loss))
print("整体测试的正确率:{}".format(total_accuracy / len_test))
total_test_step += 1
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("accuracy", total_accuracy, total_test_step)
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()完整的模型验证(测试,demo)套路
利用已经训练好的模型,然后给他提供输入
在第9行要加image=image.convert('RGB')。
因为png格式是四个通道,除了RGB三通道外,还有一个透明度通道。
所以,我们调用image=image.convert('RGB),保留其颜色通道。
当然,如果图片本来就是三个颜色通道,经过此操作,不变。
加上这一步后,可以适应png jpg各种格式的图片。
(我这里可以运行,是因为不同截图软件截图保留的通道数是不一样的。import torch
from PIL import Image
import torchvision
from torch import nn
img_path = "images/deer.png"
img_PIL = Image.open(img_path)
# 改变通道数为3
img_PIL = img_PIL.convert("RGB")
img_transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
img = img_transform(img_PIL)
# print(img.shape) # torch.Size([3, 32, 32])
# 创建网络模型
class TuDui(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
# 加载模型
model = torch.load("tudui_14.pth")
# print(model)
img = torch.reshape(img, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(img)
# print(output)
num = output.argmax(1)
if num == 0:
print("飞机")
elif num == 1:
print("汽车")
elif num == 2:
print("鸟")
elif num == 4:
print("鹿")
elif num == 5:
print("狗")
elif num == 6:
print("青蛙")
elif num == 7:
print("马")
elif num == 8:
print("船")
elif num == 9:
print("卡车")
else:
print("数据库里面没有此类")
print(num)se()
# 完整的模型验证(测试,demo)套路
> 利用已经训练好的模型,然后给他提供输入在第9行要加image=image.convert(‘RGB’)。
因为png格式是四个通道,除了RGB三通道外,还有一个透明度通道。
所以,我们调用image=image.convert('RGB),保留其颜色通道。
当然,如果图片本来就是三个颜色通道,经过此操作,不变。
加上这一步后,可以适应png jpg各种格式的图片。
(我这里可以运行,是因为不同截图软件截图保留的通道数是不一样的。
```python
import torch
from PIL import Image
import torchvision
from torch import nn
img_path = "images/deer.png"
img_PIL = Image.open(img_path)
# 改变通道数为3
img_PIL = img_PIL.convert("RGB")
img_transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),torchvision.transforms.ToTensor()])
img = img_transform(img_PIL)
# print(img.shape) # torch.Size([3, 32, 32])
# 创建网络模型
class TuDui(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024, 64),nn.Linear(64, 10),)def forward(self, x):x = self.model(x)return x
# 加载模型
model = torch.load("tudui_14.pth")
# print(model)
img = torch.reshape(img, (1, 3, 32, 32))
model.eval()
with torch.no_grad():output = model(img)
# print(output)
num = output.argmax(1)
if num == 0:print("飞机")
elif num == 1:print("汽车")
elif num == 2:print("鸟")
elif num == 4:print("鹿")
elif num == 5:print("狗")
elif num == 6:print("青蛙")
elif num == 7:print("马")
elif num == 8:print("船")
elif num == 9:print("卡车")
else:print("数据库里面没有此类")
print(num)









:实战进阶与生态拓展)








