作者:娜米
资源的刚性交付,不是云上天生就具备的能力。当选择自建或自管理一个 Kubernetes/ECS 资源池时,就必须直面一个残酷的现实:所依赖的底层 IaaS 资源本身就是非刚性的。
阿里云上 ECS 有多代实例规格(如 g6、c7i、r8y 等),基于 Intel、AMD 及自研倚天 ARM 芯片,但这并不保证在任何时刻、任何地域、任何可用区,所需要的那款机型就一定有库存。这种底层资源的“不确定性”,会像幽灵一样渗透到自建的上层系统中。
刚性交付的本质,是将“不确定性”从系统中排除的关键机制。它通过可控的资源成本,换取了业务的稳定性、高性能和可预测性。 对于任何严肃的线上业务而言,这种确定性并非锦上添花,而是维系其商业信誉和核心价值的生命线。
以下几个案例,阐述非刚性交付”带来的典型困境。
案例一:游戏行业 —— 新品发布日的“容量灾难”
- 行业:在线游戏、元宇宙
- 故障:
- 场景:一家游戏公司万众期待的新游戏正式公测。运营团队基于压测,制定了雄心勃勃的扩容计划,需要在开服瞬间将游戏服务器(通常需要高性能计算或 GPU 优化的特定 ECS 机型)的规模扩大 10 倍。他们管理着一个基于 K8s 的自建集群。
- 触发:开服铃声敲响,CI/CD 流水线触发了大规模的横向扩容。然而,K8s 的节点自动伸缩器 Cluster Autoscaler 在向阿里云申请创建新的 ECS 节点时,API 返回了“Insufficient stock”库存不足的错误。他们所依赖的特定高性能机型,在该可用区已无库存。
- 现象:应用的 Pod 因为没有足够的节点资源而大量处于
Pending状态,无法被调度。新玩家的登录请求雪片般涌入,但服务器容量远未达到预期。
- 业务影响:
- 上线即失败:大量玩家无法登录,游戏入口处大排长龙,社交媒体和游戏社区瞬间被负面评价淹没,精心策划的发布会变成了公关灾难。
- 真金白银的损失:高额的市场推广费用付诸东流,首日充值流水远低于预期。
- 玩家永久流失:糟糕的首日体验会导致大量核心玩家永久流失至竞品。
案例二:电商行业 —— 大促活动中的“性能悬崖”
- 行业:电商与在线零售
- 故障:
- 场景:一家电商平台为了应对大促,提前“预留”了大量 ECS 节点。为了“提高资源利用率”,他们在核心的交易应用 Pod 所在的节点上,混部了一些非核心的数据分析和日志处理 Pod,并配置了非刚性的 CPU 交付。
- 触发:大促零点开启,交易量飙升,交易应用需要全部申请的 CPU。同时,数据分析任务也开始高强度运行,抢占 CPU 资源。
- 现象:交易应用的实际可用 CPU 被严重挤压,响应时间急剧恶化,大量请求超时。
- 业务影响:
- 订单大量流失:支付和下单环节的堵塞,直接导致 GMV 损失。
- 品牌信誉受损:用户在关键时刻掉链子,严重损害品牌可靠性。
案例三:金融科技行业 —— 交易时段的“随机掉线”
- 行业:金融科技 (FinTech),尤其是证券交易
- 故障:
- 场景:一个核心的行情推送 Java 服务,以内存非刚性交付的方式运行在一个自管理的 K8s 集群上。
- 触发:交易时段,订阅量激增,服务实际内存使用远超其申请值。此时节点内存压力增大,触发 OOM Killer。
- 现象:行情服务 Pod 被系统判定为“劣质进程”而随机杀死,导致客户端行情刷新中断。
- 业务影响:
- 交易决策失误:用户因行情中断而做出错误决策或错失交易时机,造成直接经济损失。
- 合规与监管风险:核心系统频繁中断,可能触犯金融行业的高可用性监管要求。
案例四:企业软件行业 —— 核心 ERP 系统的“性能抽奖”
- 行业:企业软件 (ERP, CRM),尤其是大型单体应用
- 故障:
- 场景:一家企业将其庞大的、无法轻易水平扩展的单体 ERP 系统容器化后,部署在一个资源非刚性交付的自建集群上,以期“节约成本”。
- 触发:在月末财务结算等高峰期,ERP 系统需要大量 CPU 和内存。但它必须和节点上其他应用“共享”资源。
- 现象:ERP 系统的性能变得极不稳定,时快时慢,如同“抽奖”。有时一个报表生成需要 2 分钟,有时需要 20 分钟。
- 业务影响:
- 工作效率低下:员工的核心工作流程被频繁打断,财务、供应链等部门的月末结算工作无法按时完成。
- 决策延迟:管理者无法及时获取准确的业务报表,影响了商业决策的时效性。
资源刚性交付困境
资源供给的不确定性
困境本质:“承诺的资源” ≠ “可即时获取的资源”。
- 库存波动:热门规格 ECS,在大促或行业高峰期容易出现“秒光”,导致扩容失败。
- 区域/可用区差异:某些 AZ 因物理机房容量限制,无法提供特定资源类型,跨 AZ 调度又需额外网络与配置成本。
- 代际断层:旧代实例停售或库存枯竭,但应用尚未适配新架构,造成刚性承诺无法兑现。
性能隔离难以真正实现
困境本质:“逻辑隔离”不等于“物理隔离”,刚性性能难以 100% 保障。
- 虚拟化开销与干扰:即使使用 Cgroups、CPU 绑核等技术,共享 NUMA 节点、内存带宽、磁盘 I/O 队列仍可能被“嘈杂邻居”抢占。
- 突发流量冲击:同节点上其他租户突发高负载(如备份、扫描),导致本应“独占”的实例出现延迟毛刺。
- 存储性能抖动:存储在多租户争抢下 IOPS 和吞吐不稳定,影响核心业务等关键应用。
弹性与刚性的内在矛盾
困境本质:刚性要求确定性,弹性依赖不确定性,二者天然张力。
- 预占 vs 按需:为保障刚性需提前预留资源,但业务负载波动大时造成浪费;若完全按需,则无法应对突发高峰。
- 冷启动延迟:首次启动需拉镜像、初始化,往往无法满足业务的刚性响应要求。
异构资源管理复杂度高
困境本质:“资源刚性”需端到端栈协同,任一环节短板即导致整体失效。
- 专用硬件:驱动版本、CUDA 兼容性、拓扑感知调度、故障恢复机制各异,难以标准化交付。
- 混合架构支持难:x86 与 ARM(如倚天710)指令集不同,应用需重新编译测试,刚性交付需维护多套镜像与部署流程。
- 网络与存储耦合:高性能计算需 RDMA、NVMe over Fabric 等底层能力,但这些能力在虚拟化层常被削弱或不可用。
传统架构与云原生理念割裂
困境本质:刚性交付不仅是技术问题,更是组织与认知转型问题。
- 缺乏弹性设计:应用未做无状态改造,无法横向扩展,只能纵向升级(Scale-Up),而大规格实例更稀缺、更昂贵。
- 运维惯性阻力:企业习惯“买服务器、装系统、长期运行”,对“按需申请、用完即弃”的刚性交付模式接受度低。
成本模型与刚性目标冲突
困境本质:财务约束常迫使技术理想向现实低头。
- 刚性 = 高成本:独占物理机、专用集群、多AZ冗余等方案显著推高 TCO。
- 企业被迫妥协:为控制预算,用户常选择共享资源池+监控告警“事后补救”,而非事前刚性保障。
- 计费模式滞后:传统按小时计费无法匹配秒级弹性需求,导致“为不用的资源付费”或“关键时刻无资源可用”。
SAE 在刚性交付上做的工作
作为阿里云面向应用层的全托管 Serverless PaaS 平台,针对资源刚性交付的系统性困境,从资源供给、性能隔离、弹性模型、异构调度、成本结构、容灾能力、可观测性与架构演进等多个维度进行了设计。
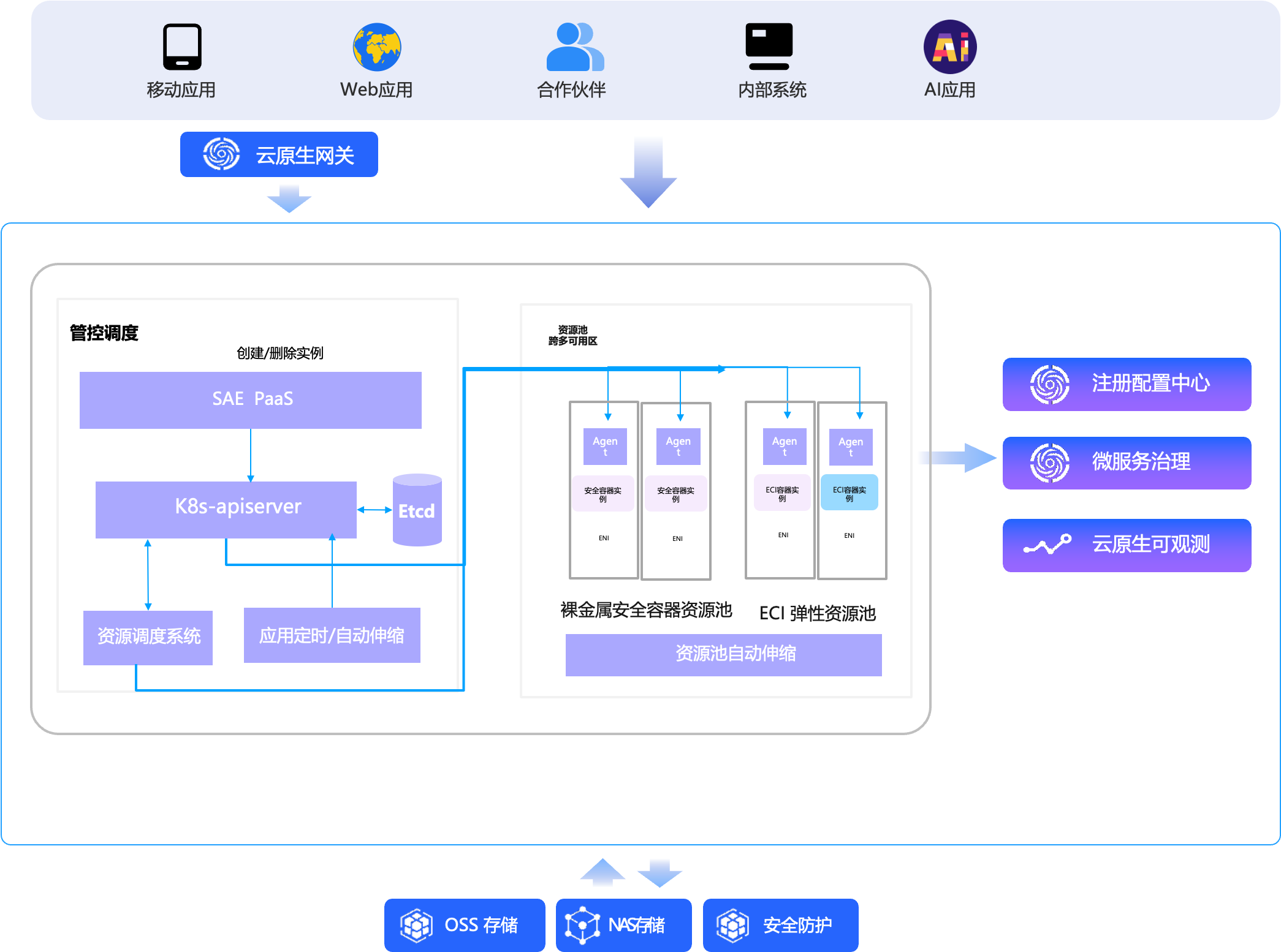
1. 破解“资源供给不确定性” → 构建无限弹性资源池
- 多源异构资源整合:
SAE 背后打通神龙裸金属服务器、弹性容器实例(ECI)支持各代 x86/ARM等海量资源,形成统一调度池。 - 智能跨机型调度:
当用户指定规格库存不足时,调度器自动选择性能相当、兼容性一致的替代资源(如 g7 缺货 → 自动调度 g8i),全程对用户透明。 - 结果:
交付的是“计算能力”,而非“特定机型”,彻底规避因库存波动导致的扩容失败。
2. 解决“性能隔离难” → 天然沙箱化 + 独占资源
- 默认运行在 ECI 沙箱中:
每个应用实例运行在轻量级安全容器,实现内核级隔离,杜绝“嘈杂邻居”干扰。 - 资源 100% 独占:
用户申请的 CPU、内存、网络带宽均由 runD 底层安全沙箱保障,无超分、无争抢,性能稳定可预期。 - 结果:
刚性性能不再是“尽力而为”,而是确定性交付,尤其适合金融交易、实时推荐等敏感场景。
3. 调和“弹性与刚性矛盾” → 按实际用量计费 + 缩容至零
- 闲置不计费:
应用缩容到 0 实例时,CPU/内存资源完全释放,不产生费用(仅保留配置元数据)。 - 秒级冷启动优化:
结合镜像预热、快照加速、本地缓存等技术,大幅缩短首次启动延迟,逼近“即时刚性响应”。 - 结果:
用户无需为“以防万一”长期预留资源,刚性保障与极致成本兼得,替代高风险混部策略。
4. 简化“异构资源管理” → 屏蔽底层复杂性
- ARM/x86 无缝兼容:
如支持海光国产芯片,用户只需提供兼容镜像,SAE 自动完成调度与运行时适配。 - 结果:
开发者只需关注“我要多少算力”,无需关心“卡在哪台机器上、驱动是否匹配”。
5. 重构“成本模型” → 从“买资源”到“买能力”
- 按实际 CPU/内存使用量秒级计费:
不再按整机小时付费,避免资源闲置浪费。 - 免运维成本:
无需管理节点、打补丁、编写扩缩容脚本,人力成本大幅降低。 - 结果:
刚性交付不再昂贵,中小企业也能享受企业级可靠性。
6. 强化“容灾与高可用” → 多可用区刚性容灾
- 一键开启多 AZ 部署:
SAE 自动将应用实例分散到多个可用区,跨机房冗余。 - AZ 故障自动恢复:
若某 AZ 整体不可用,SAE 在其他 AZ 刚性拉起新实例,RTO控制在分钟级。 - 结果:
刚性交付从“单点稳定”升级为“应用级连续性保障”。
7. 提升“可观测性与可信度” → 内置全链路监控
- 集成 ARMS + SLS + Prometheus:
提供应用性能监控(APM)、日志、指标、链路追踪一体化视图。 - 资源使用透明化:
用户可清晰看到 CPU 使用率、内存水位、网络吞吐是否达到承诺值。 - 结果:
刚性 SLA 可验证、可审计,告别“黑盒交付”。
8. 支持“传统应用平滑演进” → 兼顾稳定与未来
- 支持 WAR/JAR/镜像直接部署:
ERP、OA 等单体应用无需改造即可运行在 SAE 上,享受刚性资源保障。 - 内置诊断能力:
通过性能剖析定位瓶颈(如数据库慢查询、线程阻塞),为后续微服务拆分提供数据依据。 - 结果:
SAE 不仅是“运行平台”,更是企业云原生转型的跳板。
了解 Serverless 应用引擎 SAE
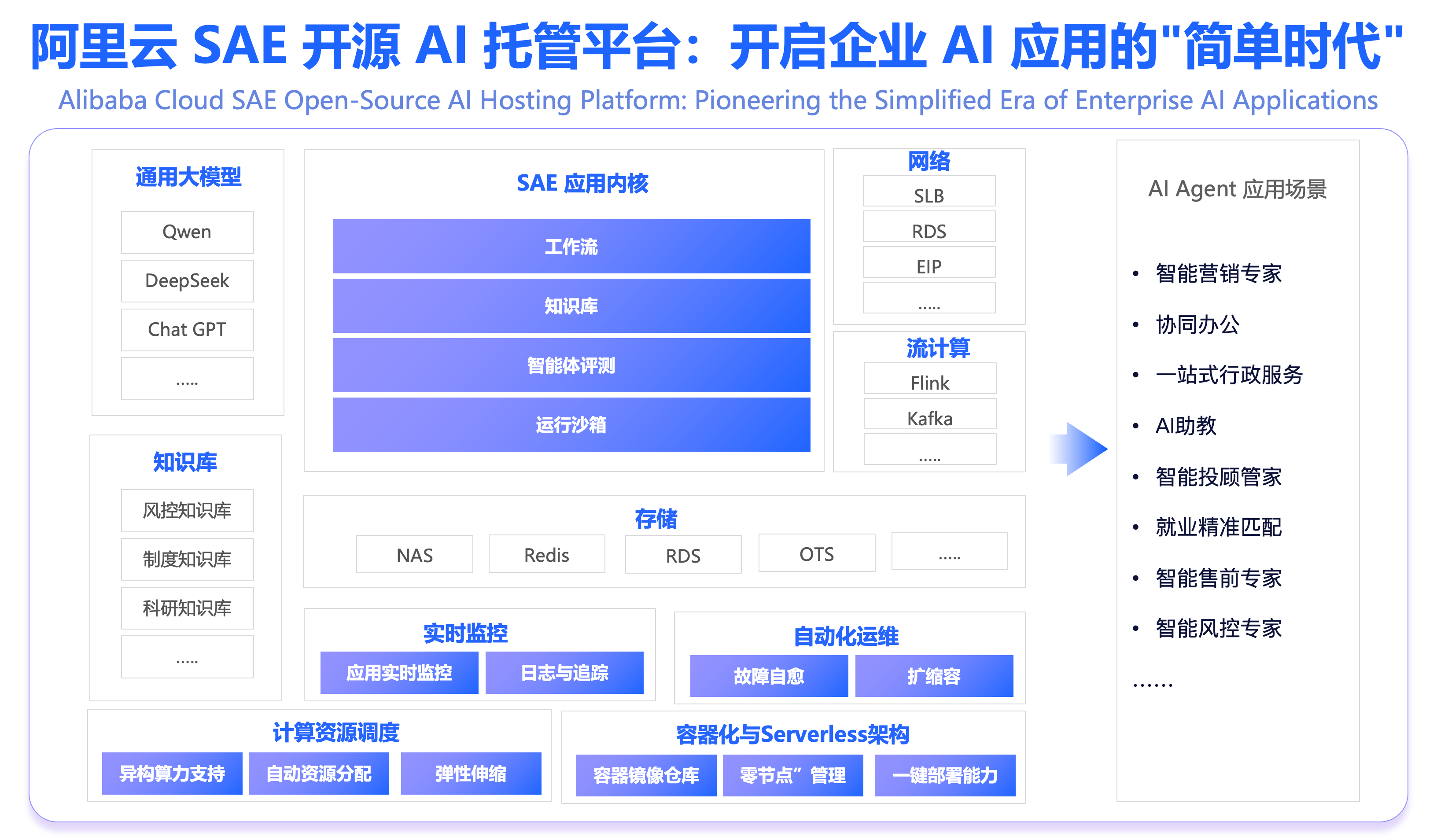
阿里云 Serverless 应用引擎 SAE 是面向 AI 时代的一站式容器化应用托管平台,以“托底传统应用、加速 AI 创新”为核心理念。它简化运维、保障稳定、闲置特性降低 75% 成本,并通过 AI 智能助手提升运维效率。
 面向 AI,SAE 集成 Dify 等主流框架,支持一键部署与弹性伸缩,在 Dify 场景中实现性能提升 50 倍、成本优化 30% 以上。
面向 AI,SAE 集成 Dify 等主流框架,支持一键部署与弹性伸缩,在 Dify 场景中实现性能提升 50 倍、成本优化 30% 以上。
产品优势
凭借八年技术沉淀,SAE 入选 2025 年 Gartner 云原生魔力象限全球领导者,亚洲第一,助力企业零节点管理、专注业务创新。SAE 既是传统应用现代化的“托举平台”,也是 AI 应用规模化落地的“加速引擎”。
- 传统应用运维的“简、稳、省”优化之道
- 简:零运维心智,专注业务创新
- 稳:企业级高可用,内置全方位保障
- 省:极致弹性,将成本降至可度量
2.加速 AI 创新:从快速探索到高效落地
- 快探索:内置 Dify、RAGFlow、OpenManus 等 热门 AI 应用模板,开箱即用,分钟级启动 POC;
- 稳落地:提供生产级 AI 运行时,性能优化(如 Dify 性能提升 50 倍)、无感升级、多版本管理,确保企业级可靠交付;
- 易集成:深度打通网关、ARMS、计量、审计等能力,助力传统应用智能化升级。
适合谁?
✅ 创业团队:没有专职运维,需要快速上线
✅ 中小企业:想降本增效,拥抱云原生
✅ 大型企业:需要企业级稳定性和合规性
✅ 出海企业:需要中国区 + 全球部署
✅ AI 创新团队:想快速落地AI应用
了解更多
产品详情页地址:https://www.aliyun.com/product/sae
SAE 客户服务群









 - 实践)
利用经过时间证明(PoET)共识算法,降低物联网区块链能耗)









