- T = readtable(filename) 通过从文本文件、电子表格(包括 Microsoft® Excel®)文件、XML 文件、HTML 文件或 Microsoft Word 文档中读取列向数据来创建表。readtable 检测数据元素,如分隔符和数据类型,以确定如何导入数据。

ds = datastore(location) 根据 location 指定的数据集合创建一个数据存储。数据存储是一个存储库,用于收集由于体积太大而无法载入内存的数据。创建 ds 后,您可以读取并处理数据。
data = read(letterds):重复运行read会依次读取下一个文件
data = readall(letterds):读取所有文件

上图为EEG信号的特征
range(X):等效于max-min
ismissing函数
- 手写字母特征提取
点击查看代码
letter = readtable("w.txt");
plot(letter.X,letter.Y)
axis([-1 1 -1 1])function features = extractLetterFeatures(letter) % Extract features
timeToWrite = letter.Time(end);
letterHeight = range(letter.Y);
letterWidth = range(letter.X);
firstXpos = letter.X(1);
lastXpos = letter.X(end-1);
firstYpos = letter.Y(1);
lastYpos = letter.Y(end-1);
numStrokes = sum(ismissing(letter.P));% Combine features into a table
features = table(timeToWrite,letterHeight,letterWidth, ...firstXpos,lastXpos,firstYpos,lastYpos,numStrokes);endfeatures = extractLetterFeatures(letter) 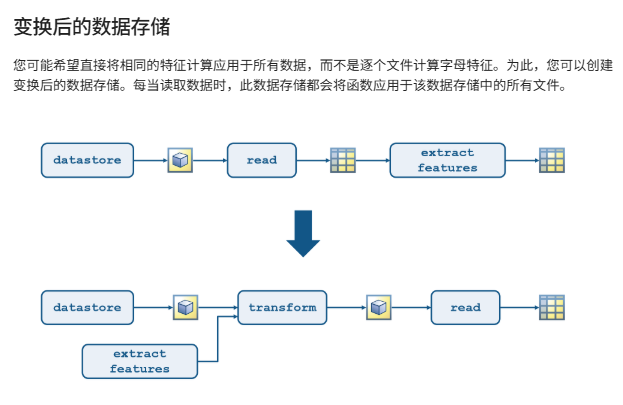
点击查看代码
`ls("*.txt")`
letterds = datastore("*.txt");
featds = transform(letterds,@extractLetterFeatures);
data = readall(featds)
c = extractBetween(letterds.Files,"_","_")
data.character = categorical(c)
4.在分类学习器中设置训练数据和测试数据
您可以在分类学习器中指定如何将数据拆分为训练数据和测试数据。
5.分类方法的工作原理
分类模型将特征空间划分为若干用输出类别标注的区域。
- 分类模型使用训练数据来确定特征空间划分。
- k 最近邻方法根据最近训练点的多数类标注各个点。
- 存在多种机器学习方法,通常最佳方式是用不同方法进行试验。
![image]()

6.什么是分类模型?
分类模型指将预测变量空间划分为若干区域。每个区域被分配一个输出类。平面的划分并没有绝对“正确”的方式。不同分类算法会导致不同划分方式。快速训练
7.更改模型超参数
每个机器学习算法都有自己的选项集,称为超参数,您可以更改超参数以调节模型的性能。例如,对于 KNN,您可以修改超参数,例如邻点数量 k 或用于计算相邻观测值之间距离的距离度量。
分类学习器应用中的超参数优化
https://ww2.mathworks.cn/help/stats/hyperparameter-optimization-in-classification-learner-app.html
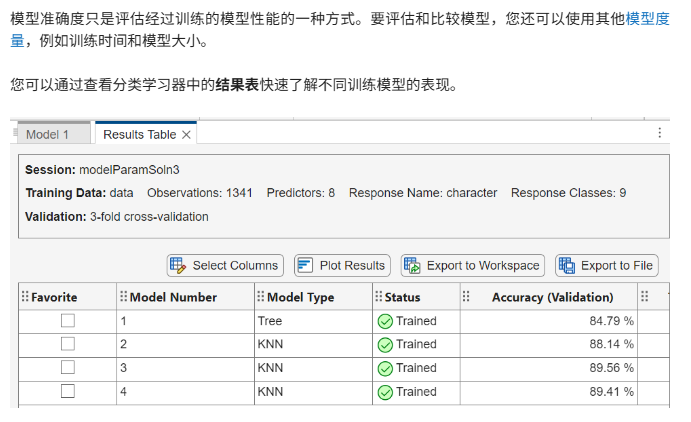
8.比较模型
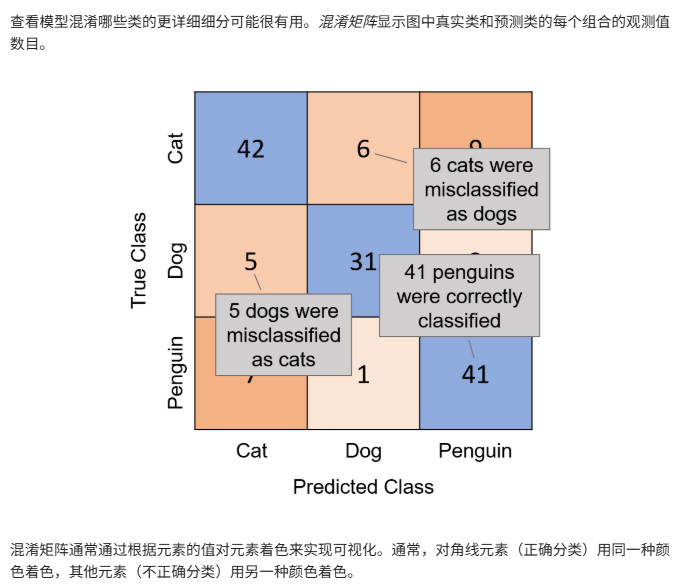
9.混淆矩阵

10
“有监督”指基于已知正确输出的示例训练模型。深度学习是一种特定的机器学习方法,它使用神经网络来提取特征并进行预测。如果您希望模型作出决策,例如玩游戏或控制机器人,该怎么办?这不属于无监督学习,因为这种情况下有明确的目标,也不属于有监督学习,因为通常无法将单个操作标注为正确还是错误。此时您需要强化学习,即定义奖励并让机器尝试不同策略,探索如何获得最多奖励。


![P4555 [国家集训队] 最长双回文串 踢姐](http://pic.xiahunao.cn/P4555 [国家集训队] 最长双回文串 踢姐)















技巧)
