近期花了点时间,通过编译解决了原来停留ollama0.12.3版本不支持qwen3vl模型的问题。解决思路提供个大家参考,部分细节需要根据思路去做源码修改。
下载解压 ollama-0.13.0源码
github中下载
进入解压目录
使用VSCode打开代码目录,方便编辑
将ROCm 6 替换成ROCm 7(会有很多处,全局检索并修改)
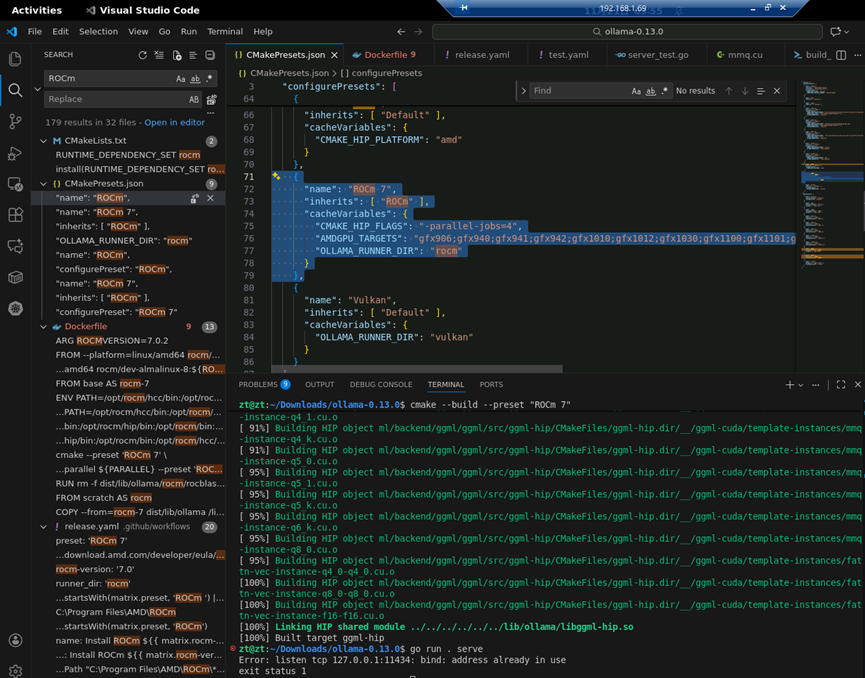
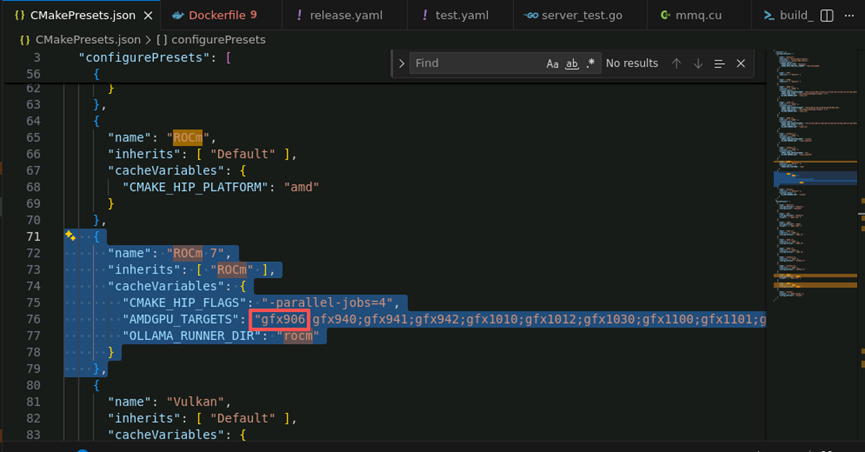
增加gfx906配置,用来支持MI50(代号gfx906)
找到删除gfx906的库支持的代码,进行屏蔽(有多处,查找下)
RUN rm -f dist/lib/ollama/rocm/rocblas/library/*gfx90[06]*
参考
{
"name": "ROCm 7",
"inherits": [ "ROCm" ],
"cacheVariables": {
"CMAKE_HIP_FLAGS": "-parallel-jobs=4",
"AMDGPU_TARGETS": "gfx906;gfx940;gfx941;gfx942;gfx1010;gfx1012;gfx1030;gfx1100;gfx1101;gfx1102;gfx1151;gfx1200;gfx1201;gfx908:xnack-;gfx90a:xnack+;gfx90a:xnack-",
"OLLAMA_RUNNER_DIR": "rocm"
}
},
进行环境变量设定
export PATH=$PATH:/opt/rocm/bin
export CGO_CFLAGS="-I/opt/rocm/include"
export CGO_LDFLAGS="-L/opt/rocm/lib -Wl,-rpath,/opt/rocm/lib"
export OLLAMA_LLAMA_CPP_FLAGS="-DBUILD_SHARED_LIBS=OFF -DLLAMA_HIPBLAS=ON"
安装Vulkan SDK
wget -qO- https://packages.lunarg.com/lunarg-signing-key-pub.asc | sudo tee /etc/apt/trusted.gpg.d/lunarg.asc
sudo wget -qO /etc/apt/sources.list.d/lunarg-vulkan-1.4.313-jammy.list https://packages.lunarg.com/vulkan/1.4.313/lunarg-vulkan-1.4.313-jammy.list
sudo apt update
sudo apt install vulkan-sdk
(不安装也行,最早这边是按Vulkan编译的,但是很不稳定,桌面经常异常卡死,可能是我这边使用了最新的Vulkan版本导致的不兼容,后放弃)
ROCm也要提前安装(之前有介绍过升级7.0.2的处理,可参考之前的说明)
编译参考:
ollama/docs/development.md at main · ollama/ollama
进行编译
启用ROCm 7
cmake --preset "ROCm 7"
cmake –build –preset “ROCm 7”
(这里vscode中使用AI提示获得的编译命令,官方教程命令只能编译cpu部分)
启动 Ollama:
go run . serve
另外开一个终端,运行模型进行测试
go run . run qwen3-vl:2b
为了方便使用,可以编译成主程序使用。
编译成最终主程序
go build -tags=nolegacy -ldflags="-s -w -X main.Version=0.13.0"
:~/Downloads/ollama-0.13.0$ ./ollama serve
time=2025-11-21T10:27:13.878+08:00 level=INFO source=routes.go:1544 msg="server config" env="map[CUDA_VISIBLE_DEVICES: GGML_VK_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:4096 OLLAMA_DEBUG:INFO OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/home/zt/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_REMOTES:[ollama.com] OLLAMA_SCHED_SPREAD:false OLLAMA_VULKAN:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-11-21T10:27:13.879+08:00 level=INFO source=images.go:522 msg="total blobs: 4"
time=2025-11-21T10:27:13.879+08:00 level=INFO source=images.go:529 msg="total unused blobs removed: 0"
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] HEAD / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
[GIN-debug] GET / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
[GIN-debug] HEAD /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func3 (5 handlers)
[GIN-debug] GET /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func4 (5 handlers)
[GIN-debug] POST /api/pull --> github.com/ollama/ollama/server.(*Server).PullHandler-fm (5 handlers)
[GIN-debug] POST /api/push --> github.com/ollama/ollama/server.(*Server).PushHandler-fm (5 handlers)
[GIN-debug] HEAD /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] GET /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] POST /api/show --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (5 handlers)
[GIN-debug] DELETE /api/delete --> github.com/ollama/ollama/server.(*Server).DeleteHandler-fm (5 handlers)
[GIN-debug] POST /api/me --> github.com/ollama/ollama/server.(*Server).WhoamiHandler-fm (5 handlers)
[GIN-debug] POST /api/signout --> github.com/ollama/ollama/server.(*Server).SignoutHandler-fm (5 handlers)
[GIN-debug] DELETE /api/user/keys/:encodedKey --> github.com/ollama/ollama/server.(*Server).SignoutHandler-fm (5 handlers)
[GIN-debug] POST /api/create --> github.com/ollama/ollama/server.(*Server).CreateHandler-fm (5 handlers)
[GIN-debug] POST /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).CreateBlobHandler-fm (5 handlers)
[GIN-debug] HEAD /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).HeadBlobHandler-fm (5 handlers)
[GIN-debug] POST /api/copy --> github.com/ollama/ollama/server.(*Server).CopyHandler-fm (5 handlers)
[GIN-debug] GET /api/ps --> github.com/ollama/ollama/server.(*Server).PsHandler-fm (5 handlers)
[GIN-debug] POST /api/generate --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (5 handlers)
[GIN-debug] POST /api/chat --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (5 handlers)
[GIN-debug] POST /api/embed --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (5 handlers)
[GIN-debug] POST /api/embeddings --> github.com/ollama/ollama/server.(*Server).EmbeddingsHandler-fm (5 handlers)
[GIN-debug] POST /v1/chat/completions --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (6 handlers)
[GIN-debug] POST /v1/completions --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (6 handlers)
[GIN-debug] POST /v1/embeddings --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (6 handlers)
[GIN-debug] GET /v1/models --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (6 handlers)
[GIN-debug] GET /v1/models/:model --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (6 handlers)
time=2025-11-21T10:27:13.879+08:00 level=INFO source=routes.go:1597 msg="Listening on 127.0.0.1:11434 (version 0.13.0)"
time=2025-11-21T10:27:13.880+08:00 level=INFO source=runner.go:67 msg="discovering available GPUs..."
time=2025-11-21T10:27:13.880+08:00 level=INFO source=server.go:392 msg="starting runner" cmd="/home/zt/Downloads/ollama-0.13.0/ollama runner --ollama-engine --port 37621"
time=2025-11-21T10:27:13.983+08:00 level=INFO source=server.go:392 msg="starting runner" cmd="/home/zt/Downloads/ollama-0.13.0/ollama runner --ollama-engine --port 44047"
time=2025-11-21T10:27:13.983+08:00 level=INFO source=server.go:392 msg="starting runner" cmd="/home/zt/Downloads/ollama-0.13.0/ollama runner --ollama-engine --port 34325"
time=2025-11-21T10:27:14.135+08:00 level=INFO source=runner.go:449 msg="failure during GPU discovery" OLLAMA_LIBRARY_PATH=[/home/zt/Downloads/ollama-0.13.0/build/lib/ollama] extra_envs="map[GGML_CUDA_INIT:1 ROCR_VISIBLE_DEVICES:1]" error="runner crashed"
time=2025-11-21T10:27:14.879+08:00 level=INFO source=types.go:42 msg="inference compute" id=GPU-778640c173497dd4 filter_id="" library=ROCm compute=gfx906 name=ROCm0 description="AMD Instinct MI50/MI60" libdirs=ollama driver=70051.83 pci_id=0000:03:00.0 type=discrete total="32.0 GiB" available="31.5 GiB"
MI50显卡ROCm成功识别,显存也正常。运行模型调用显卡也正常。
实测运行qwen3vl:32b模型大概有19tocken/s,比之前的qwen3是要快的,最最重要的是解决了原来停留ollama0.12.3版本不支持qwen3vl模型的问题。



















