作业1
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
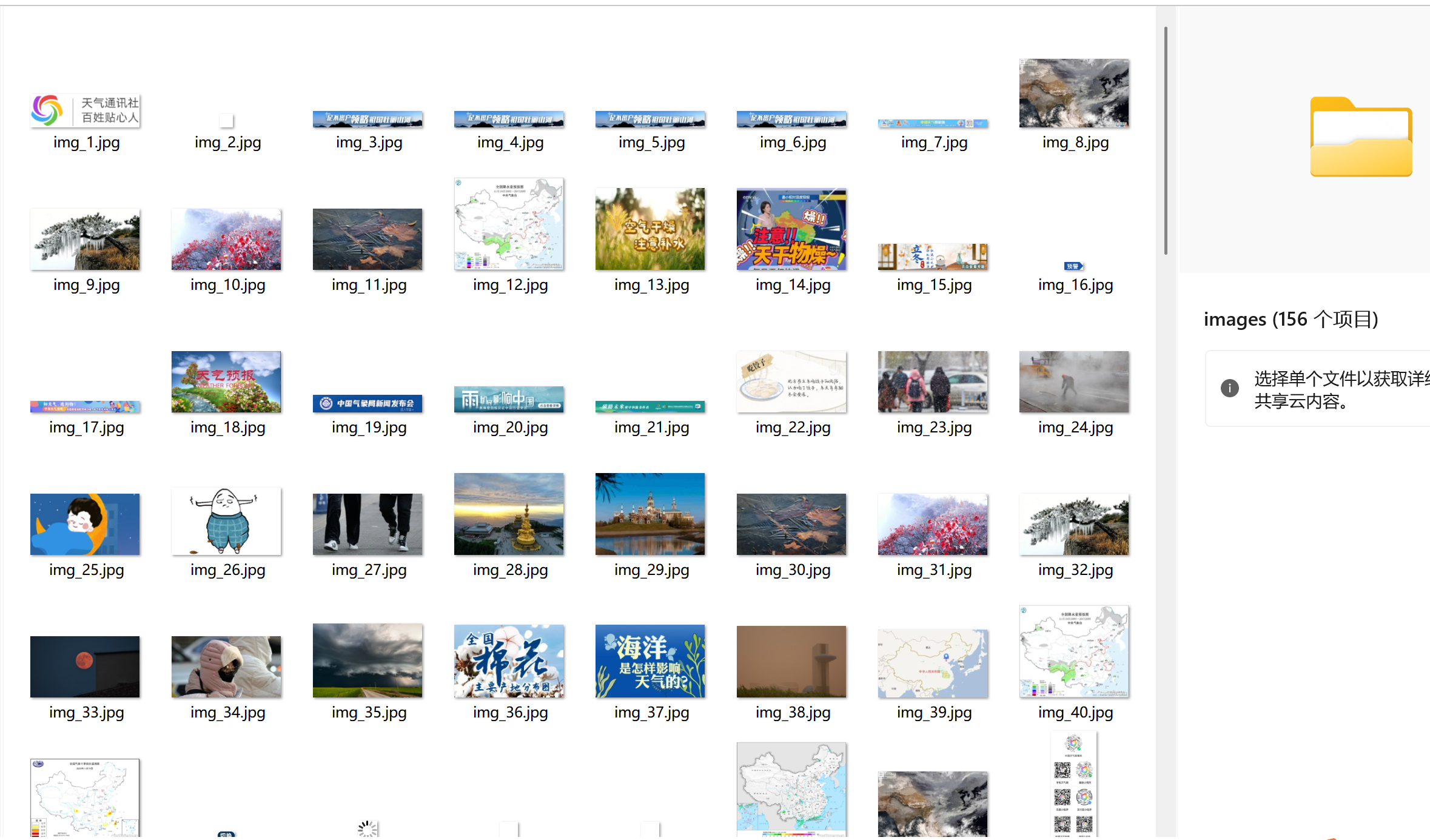
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
(1)代码和运行结果
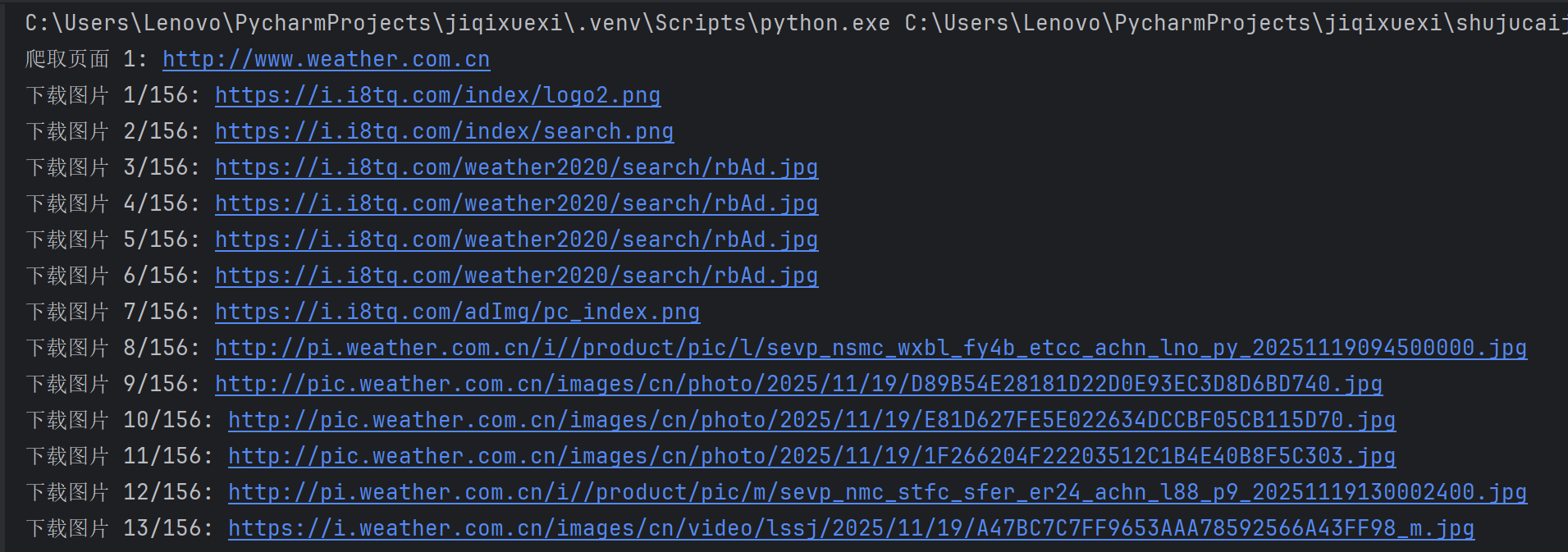
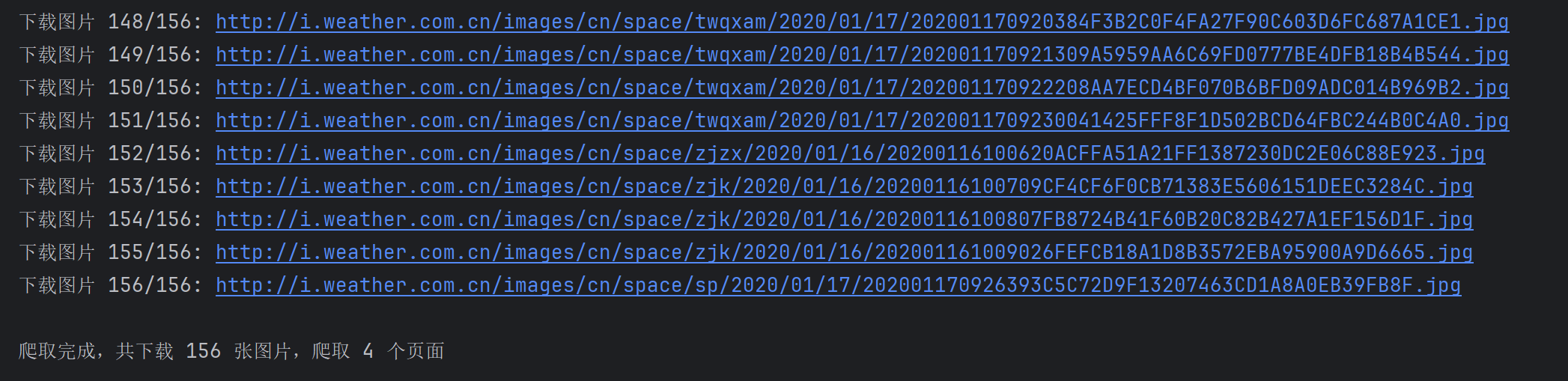
单线程爬取
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin# 配置参数
BASE_URL = "http://www.weather.com.cn"
MAX_PAGES = 56 # 最大爬取页数
MAX_IMAGES = 156 # 最大下载图片数
SAVE_DIR = "images"# 创建保存目录
os.makedirs(SAVE_DIR, exist_ok=True)def download_image(img_url, count):"""下载单张图片并保存"""try:# 处理相对路径if not img_url.startswith('http'):img_url = urljoin(BASE_URL, img_url)# 输出图片URLprint(f"下载图片 {count}/{MAX_IMAGES}: {img_url}")# 发送请求response = requests.get(img_url, timeout=10)response.raise_for_status()# 提取文件名filename = os.path.join(SAVE_DIR, f"img_{count}.jpg")# 保存图片with open(filename, 'wb') as f:f.write(response.content)return Trueexcept Exception as e:print(f"下载失败 {img_url}: {str(e)}")return Falsedef crawl_page(url, img_count):"""爬取单个页面的图片"""try:response = requests.get(url, timeout=10)response.encoding = 'utf-8'soup = BeautifulSoup(response.text, 'html.parser')# 查找所有图片标签img_tags = soup.find_all('img')for img_tag in img_tags:if img_count >= MAX_IMAGES:return img_countimg_url = img_tag.get('src')if img_url and (img_url.endswith(('.jpg', '.jpeg', '.png', '.gif'))):if download_image(img_url, img_count + 1):img_count += 1return img_countexcept Exception as e:print(f"爬取页面失败 {url}: {str(e)}")return img_countdef main():img_count = 0page_count = 0# 爬取首页print(f"爬取页面 1: {BASE_URL}")img_count = crawl_page(BASE_URL, img_count)page_count += 1# 爬取其他页面(从站内链接获取)try:response = requests.get(BASE_URL, timeout=10)soup = BeautifulSoup(response.text, 'html.parser')links = soup.find_all('a', href=True)page_urls = [urljoin(BASE_URL, link['href']) for link in links]# 去重并过滤有效链接page_urls = list(set(page_urls))valid_urls = [url for url in page_urls if url.startswith(BASE_URL) and url != BASE_URL]# 继续爬取直到达到页数或图片数量限制for url in valid_urls:if page_count >= MAX_PAGES or img_count >= MAX_IMAGES:breakpage_count += 1print(f"爬取页面 {page_count}: {url}")img_count = crawl_page(url, img_count)except Exception as e:print(f"获取链接失败: {str(e)}")print(f"\n爬取完成,共下载 {img_count} 张图片,爬取 {page_count} 个页面")if __name__ == "__main__":main()
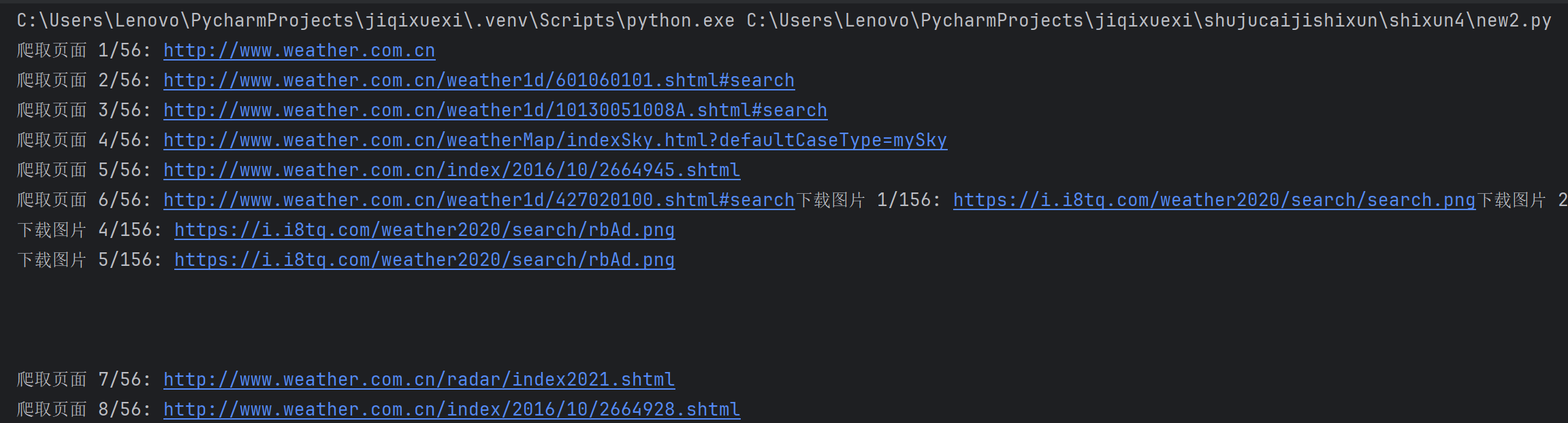
多线程爬取
点击查看代码
import os
import requests
import threading
from queue import Queue
from bs4 import BeautifulSoup
from urllib.parse import urljoin# 配置参数
BASE_URL = "http://www.weather.com.cn"
MAX_PAGES = 56
MAX_IMAGES = 156
SAVE_DIR = "images"
THREAD_NUM = 5 # 线程数量(可调整)# 创建保存目录
os.makedirs(SAVE_DIR, exist_ok=True)# 全局计数器与锁(避免多线程竞争)
img_count = 0
page_count = 0
count_lock = threading.Lock() # 用于保护计数器的锁# 队列(用于线程间通信)
page_queue = Queue() # 存储待爬取的页面URL
img_queue = Queue() # 存储待下载的图片URLdef is_valid_image(url):"""检查是否为有效图片URL"""return url and url.endswith(('.jpg', '.jpeg', '.png', '.gif', '.bmp'))def download_worker():"""图片下载线程的工作函数(每个线程循环从队列取任务)"""global img_countwhile True:img_url = img_queue.get() # 从队列获取图片URL,若队列为空则阻塞# 退出信号:如果获取到None,则终止线程if img_url is None:img_queue.task_done()break# 加锁判断是否超过最大图片数(避免多线程同时修改计数器导致错误)with count_lock:current_count = img_count + 1if current_count > MAX_IMAGES:img_queue.task_done()continueimg_count = current_count # 更新计数器try:# 处理相对路径(补全为完整URL)if not img_url.startswith(('http:', 'https:')):img_url = urljoin(BASE_URL, img_url)# 输出下载信息print(f"下载图片 {current_count}/{MAX_IMAGES}: {img_url}")# 下载图片response = requests.get(img_url, timeout=10)response.raise_for_status() # 若请求失败(如404),抛出异常# 保存图片到本地filename = os.path.join(SAVE_DIR, f"img_{current_count}.jpg")with open(filename, 'wb') as f:f.write(response.content)except Exception as e:print(f"下载失败 {img_url}: {str(e)}")img_queue.task_done() # 标记当前任务完成def crawl_worker():"""页面爬取线程的工作函数(从队列取页面URL,提取图片链接)"""global page_countwhile True:page_url = page_queue.get() # 从队列获取页面URL,若队列为空则阻塞# 退出信号:如果获取到None,则终止线程if page_url is None:page_queue.task_done()break# 加锁判断是否超过最大页数with count_lock:current_page = page_count + 1if current_page > MAX_PAGES:page_queue.task_done()continuepage_count = current_page # 更新页数计数器try:# 爬取页面内容print(f"爬取页面 {current_page}/{MAX_PAGES}: {page_url}")response = requests.get(page_url, timeout=10)response.encoding = 'utf-8' # 确保中文正常解析soup = BeautifulSoup(response.text, 'html.parser')# 提取页面中的所有图片链接img_tags = soup.find_all('img')for img_tag in img_tags:img_url = img_tag.get('src') # 获取图片URLif is_valid_image(img_url):img_queue.put(img_url) # 将图片URL放入下载队列except Exception as e:print(f"爬取页面失败 {page_url}: {str(e)}")page_queue.task_done() # 标记当前任务完成def main():# 1. 初始化页面队列(先加入首页,再从首页提取其他链接)page_queue.put(BASE_URL) # 首页URL入队# 从首页提取其他站内链接,补充到页面队列try:response = requests.get(BASE_URL, timeout=10)soup = BeautifulSoup(response.text, 'html.parser')links = soup.find_all('a', href=True) # 提取所有<a>标签的链接# 过滤有效链接(仅保留本站链接,去重)valid_links = set()for link in links:href = urljoin(BASE_URL, link['href']) # 补全相对路径if href.startswith(BASE_URL) and href not in valid_links:valid_links.add(href)# 将有效链接加入页面队列for link in valid_links:page_queue.put(link)except Exception as e:print(f"提取首页链接失败: {str(e)}")# 2. 创建并启动爬取线程(负责从页面提取图片链接)crawl_threads = []for _ in range(THREAD_NUM):t = threading.Thread(target=crawl_worker) # 绑定爬取工作函数t.daemon = True # 守护线程:主程序退出时自动结束t.start()crawl_threads.append(t)# 3. 创建并启动下载线程(负责下载图片)download_threads = []for _ in range(THREAD_NUM):t = threading.Thread(target=download_worker) # 绑定下载工作函数t.daemon = Truet.start()download_threads.append(t)# 4. 等待页面队列处理完成(所有页面爬取完毕)page_queue.join()# 等待图片队列处理完成(所有图片下载完毕)img_queue.join()# 5. 发送退出信号给所有线程(避免线程无限阻塞)for _ in range(THREAD_NUM):page_queue.put(None) # 给爬取线程发退出信号img_queue.put(None) # 给下载线程发退出信号# 6. 等待所有线程结束for t in crawl_threads:t.join()for t in download_threads:t.join()print(f"\n爬取完成:共爬取 {page_count} 页,下载 {img_count} 张图片")if __name__ == "__main__":main()

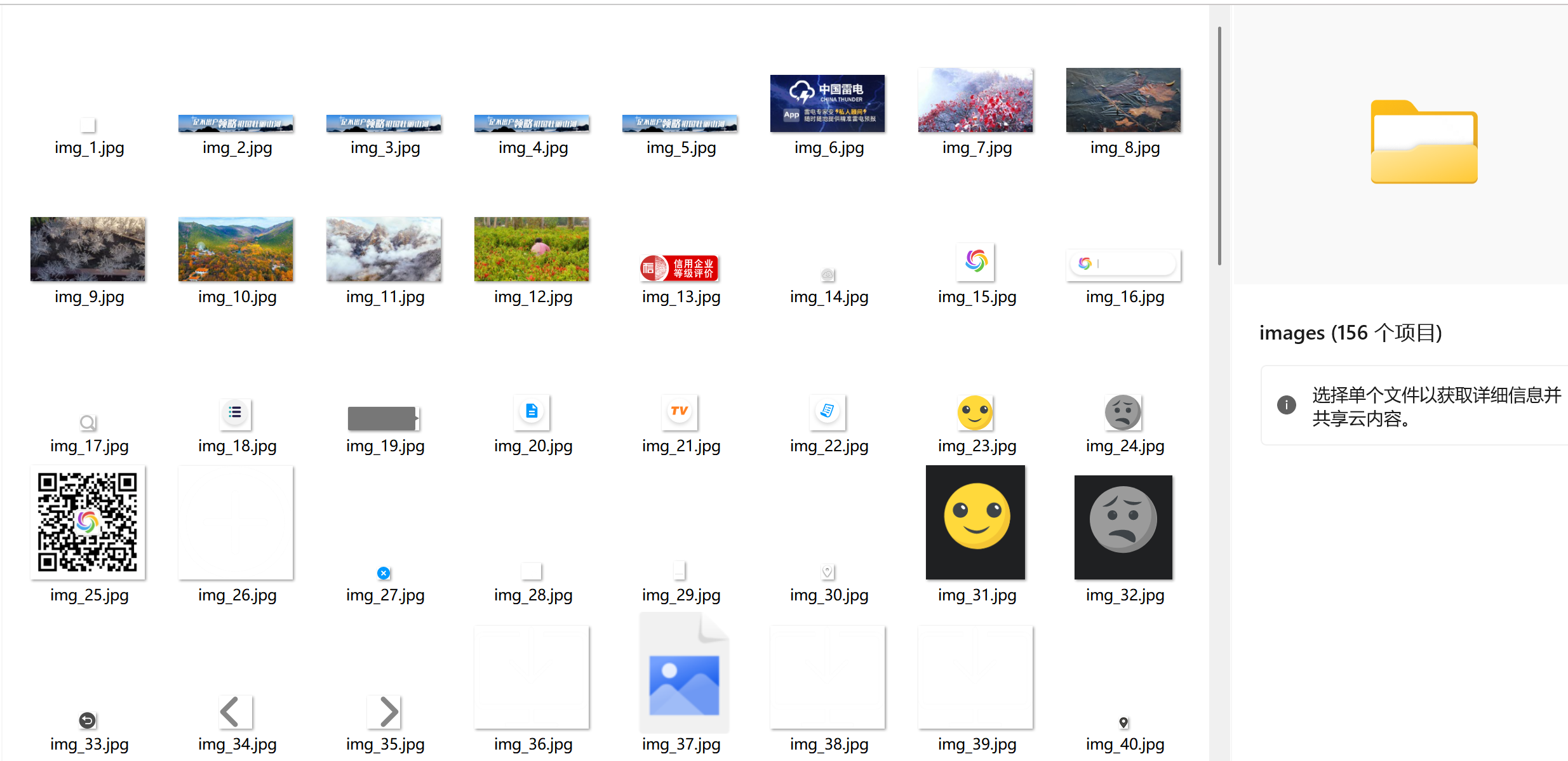
(2)心得体会
本次爬取中国气象网图片的实践,让我对单线程与多线程的差异有了直观认知。单线程实现简单,无需处理并发冲突,请求频率稳定不易触发反爬,但效率低下,图片下载需逐个等待响应,总耗时较长。多线程通过线程池并发请求,大幅缩短了爬取时间,资源利用率更高,但需解决线程安全问题,需用锁保护共享计数器和已爬取URL集合,同时要控制并发数避免触发网站反爬机制。
Gitee文件夹链接:https://gitee.com/lizixian66/shujucaiji/tree/homework3/shixun4
作业2
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
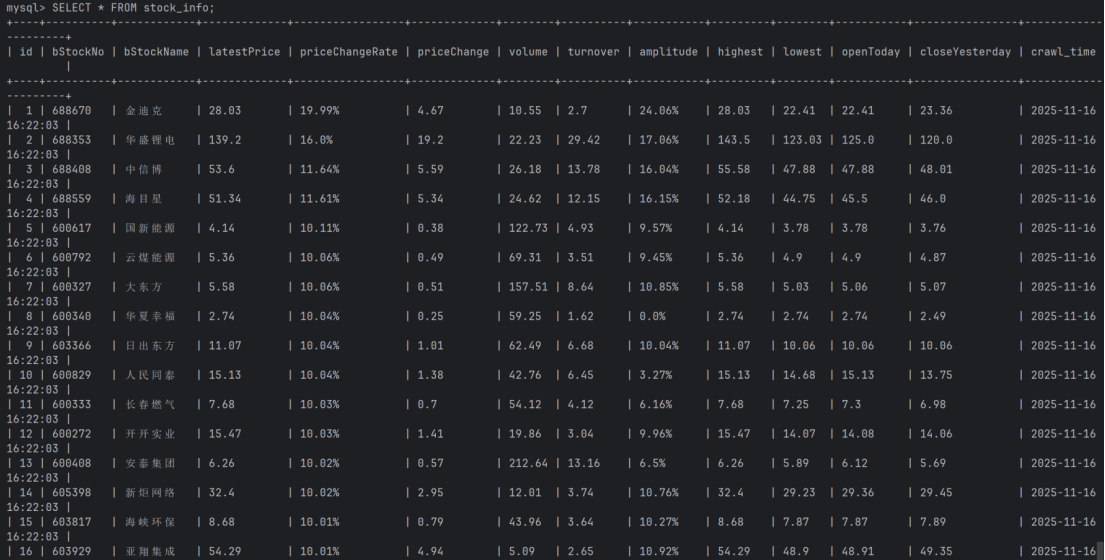
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
(1)代码和运行结果
1.新建Scrapy项目
2.定义数据结构(items.py)
点击查看代码
import scrapyclass StockspiderItem(scrapy.Item):bStockNo = scrapy.Field() # 股票代码bStockName = scrapy.Field() # 股票名称latestPrice = scrapy.Field() # 最新价priceChangeRate = scrapy.Field() # 涨跌幅priceChange = scrapy.Field() # 涨跌额volume = scrapy.Field() # 成交量turnover = scrapy.Field() # 成交额amplitude = scrapy.Field() # 振幅highest = scrapy.Field() # 最高lowest = scrapy.Field() # 最低openToday = scrapy.Field() # 今开closeYesterday = scrapy.Field() # 昨收crawl_time = scrapy.Field() # 爬取时间
3.配置项目设置(settings.py)
点击查看代码
# 启用管道(指定Pipeline类的路径)
ITEM_PIPELINES = {'StockSpider.pipelines.StockspiderPipeline': 300,
}# 设置请求头(模拟浏览器)
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'# 关闭ROBOTSTXT_OBEY
ROBOTSTXT_OBEY = False
4.编写爬虫脚本(stock_spider.py)
点击查看代码
import scrapy
import json
from datetime import datetime
from ..items import StockspiderItemclass StockApiSpider(scrapy.Spider):name = 'stock_api'api_url = "https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37102428814534866044_1763278238593&fs=m%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn=1&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb&_=1763278238597"def start_requests(self):yield scrapy.Request(url=self.api_url,callback=self.parse_api,headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36","X-Requested-With": "XMLHttpRequest"})def parse_api(self, response):raw_data = response.textjson_str = raw_data.split('(')[1].rsplit(')', 1)[0]data = json.loads(json_str)stock_list = data.get('data', {}).get('diff', [])crawl_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')for item in stock_list:stock_item = StockspiderItem()stock_item['bStockNo'] = item.get('f12') # 股票代码stock_item['bStockName'] = item.get('f14') # 股票名称# 单位转换:除以100,保留两位小数后转字符串stock_item['latestPrice'] = str(round(item.get('f2', 0) / 100, 2))stock_item['priceChangeRate'] = str(round(item.get('f3', 0) / 100, 2)) + '%'stock_item['priceChange'] = str(round(item.get('f4', 0) / 100, 2))stock_item['volume'] = str(round(item.get('f5', 0) / 10000, 2)) # 成交量(万手)stock_item['turnover'] = str(round(item.get('f6', 0) / 100000000, 2)) # 成交额(亿)stock_item['amplitude'] = str(round(item.get('f7', 0) / 100, 2)) + '%'stock_item['highest'] = str(round(item.get('f15', 0) / 100, 2))stock_item['lowest'] = str(round(item.get('f16', 0) / 100, 2))stock_item['openToday'] = str(round(item.get('f17', 0) / 100, 2))stock_item['closeYesterday'] = str(round(item.get('f18', 0) / 100, 2))stock_item['crawl_time'] = crawl_timeyield stock_item
5.编写数据处理与存储(pipelines.py)
点击查看代码
import mysql.connector
from datetime import datetimeclass StockspiderPipeline:def open_spider(self, spider):self.db = mysql.connector.connect(host='localhost',user='root',password='lzx2022666',database='stock_db')self.cursor = self.db.cursor()def process_item(self, item, spider):insert_sql = """INSERT INTO stock_info (bStockNo, bStockName, latestPrice, priceChangeRate, priceChange, volume, turnover, amplitude, highest, lowest, openToday, closeYesterday, crawl_time)VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""values = (item['bStockNo'],item['bStockName'],item['latestPrice'], # 移除float(),直接存字符串item['priceChangeRate'],item['priceChange'],item['volume'],item['turnover'],item['amplitude'],item['highest'],item['lowest'],item['openToday'],item['closeYesterday'],item['crawl_time'])self.cursor.execute(insert_sql, values)self.db.commit()return itemdef close_spider(self, spider):self.cursor.close()self.db.close()
运行结果:

(2)心得体会
刚开始做这道题的时候,我根据页面的Xpath对我想要的数据进行处理,但是我发现一直爬取不出来,我就去问了大模型,发现因为我们爬取的页面是动态加载的,Scrapy默认的请求方式无法获取动态加载内容。于是我就改用之前学过的捕获js接口,去爬取就爬取出来了。
Gitee文件夹链接:https://gitee.com/lizixian66/shujucaiji/tree/homework3/StockSpider
作业3
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
(1)代码和运行结果
1.新建Scrapy项目

2.定义数据结构(items.py)
点击查看代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass BocExchangeItem(scrapy.Item):currency = scrapy.Field()tbp = scrapy.Field()cbp = scrapy.Field()tsp = scrapy.Field()csp = scrapy.Field()mid_rate = scrapy.Field() # 新增中行折算价字段time = scrapy.Field()点击查看代码
ROBOTSTXT_OBEY = True
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'点击查看代码
import scrapy
from ..items import BocExchangeItemclass BocSpider(scrapy.Spider):name = 'boc'allowed_domains = ['boc.cn']start_urls = ['https://www.boc.cn/sourcedb/whpj/']def parse(self, response):# 精准定位表格行rows = response.xpath('//div[@class="BOC_main"]//table[@cellpadding="0"]//tr[position() > 1]')print(f"匹配到{len(rows)}条数据行")for row in rows:item = BocExchangeItem()# 提取货币名称(注意去除多余空格)item['currency'] = row.xpath('td[1]/text()').get().strip()# 现汇买入价item['tbp'] = row.xpath('td[2]/text()').get(default='').strip()# 现钞买入价item['cbp'] = row.xpath('td[3]/text()').get(default='').strip()# 现汇卖出价item['tsp'] = row.xpath('td[4]/text()').get(default='').strip()# 现钞卖出价item['csp'] = row.xpath('td[5]/text()').get(default='').strip()# 中行折算价item['mid_rate'] = row.xpath('td[6]/text()').get(default='').strip()# 发布日期item['time'] = row.xpath('td[7]/text()').get().strip()yield item
点击查看代码
import mysql.connector
from mysql.connector import errorcodeclass BocExchangePipeline:def open_spider(self, spider):# 连接 MySQL 数据库try:self.conn = mysql.connector.connect(host='localhost',user='root', # 你的 MySQL 用户名password='lzx2022666', # 你的 MySQL 密码database='boc_exchange', # 数据库名(需提前创建)charset='utf8mb4',use_unicode=True)self.cursor = self.conn.cursor()# 创建表(若不存在)create_table_sql = '''CREATE TABLE IF NOT EXISTS exchange_data (id INT AUTO_INCREMENT PRIMARY KEY,currency VARCHAR(50),tbp DECIMAL(10,2),cbp DECIMAL(10,2),tsp DECIMAL(10,2),csp DECIMAL(10,2),time VARCHAR(20))'''self.cursor.execute(create_table_sql)self.conn.commit()spider.logger.info("数据库连接成功并创建表")except mysql.connector.Error as err:if err.errno == errorcode.ER_ACCESS_DENIED_ERROR:spider.logger.error("用户名或密码错误")elif err.errno == errorcode.ER_BAD_DB_ERROR:spider.logger.error("数据库不存在,请先创建数据库")else:spider.logger.error(f"数据库连接错误: {err}")raise # 抛出异常终止爬虫def process_item(self, item, spider):# 插入数据try:insert_sql = '''INSERT INTO exchange_data (currency, tbp, cbp, tsp, csp, time)VALUES (%s, %s, %s, %s, %s, %s)'''# 执行插入语句,参数与 pymysql 兼容self.cursor.execute(insert_sql, (item['currency'],item['tbp'],item['cbp'],item['tsp'],item['csp'],item['time']))self.conn.commit()spider.logger.debug(f"插入数据成功: {item['currency']}")except mysql.connector.Error as err:self.conn.rollback() # 出错时回滚spider.logger.error(f"插入数据失败: {err},数据: {item}")return itemdef close_spider(self, spider):# 关闭数据库连接if hasattr(self, 'cursor'):self.cursor.close()if hasattr(self, 'conn') and self.conn.is_connected():self.conn.close()spider.logger.info("数据库连接已关闭")

(2)心得体会
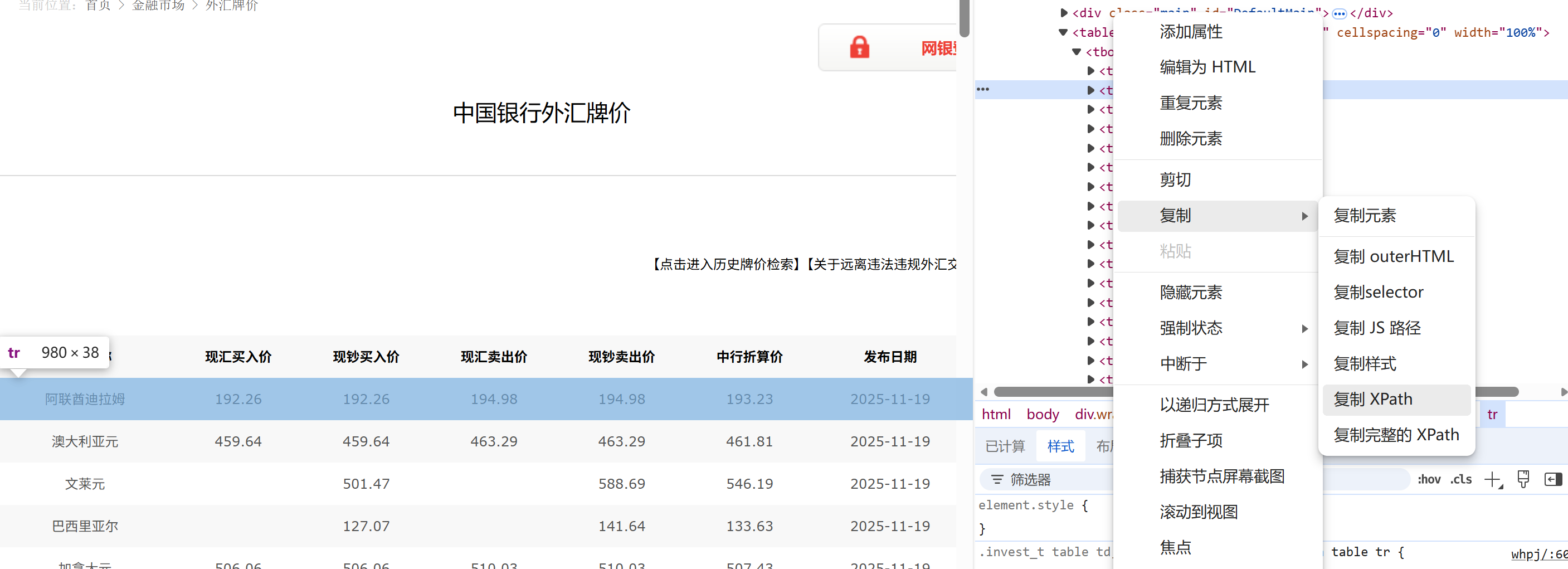
通过复制想要爬取的XPath,就可以直接得到我们想要的规则“//div[@class="BOC_main"]//table[@cellpadding="0"]//tr[position() > 1]”非常方便,然后了解scrapyge框架的用处,配置各前置条件,就完成了爬取。
Gitee文件夹链接:https://gitee.com/lizixian66/shujucaiji/tree/homework3/boc_exchange





--工程结构)




--Model 领域)
)


)


![Luogu P6234 [eJOI 2019] T 形覆盖 题解 [ 紫 ] [ 图论建模 ] [ 分类讨论 ] [ 基环树 ]](http://pic.xiahunao.cn/Luogu P6234 [eJOI 2019] T 形覆盖 题解 [ 紫 ] [ 图论建模 ] [ 分类讨论 ] [ 基环树 ])

