CSAPP
信息的处理和表示
数字的存储
内存被划分为不同大小的字块,32位CPU->4字节,64位CPU->8字节
对字长\(w\)的机器而言,虚拟地址范围为\(0~2^w-1\),即有\(2^w\)个字节
64位架构地址空间限制为48位虚拟地址,约为\(256TB\)(\(2^{48}Bytes\)),但是仍然在64位逻辑上处理算术运算
编译器通过保持字节对齐,提高硬件效率
无论32位机器还是64位机器,\(int\_32t\)(int)和\(int\_64t\)(long long)都分别占4个和8个字节,32位机器在具体实现上,采用两个32位\(int\_32t\)模拟64位\(int\_64t\)
而浮点寄存器有自己的宽度标准,与通用寄存器宽度无关,如\(double\)始终占8个字节
小端法:最低有效位所在字节存储地址在最前面,类型转换灵活,符合数学思维
大端法:最高有效位所在字节存储地址在最前面,方便阅读识别,便于判断正负
大小端法的核心决定因素:CPU架构
x86/x86-64使用小端法
PowerPC,网络协议(TCP/IP)使用大端法
ARM, RISC-V, MIPS等同时支持两种字节序
二进制下的整数
1. 补码
对于 \(w\) 位的无符号整数\(x\):\(x = \sum\limits_{i=0}^{w-1}a_i \times2^i\)
对于\(w\)位的有符号整数\(x\) : \(x = -2^{w-1} \times a_{w - 1}+\sum\limits_{i=0}^{w-2}a_i \times2^i\)(补码表示)
在此种表示方式下有符号整数\(-x\)与无符号整数\(2^w-x\)二进制编码相同
原理:在\(mod\) \(2^w\) 意义下 \(-x\) 与 \(2^n - x\)等价, 溢出的情况下仍满足加法与乘法结合律,交换律等定律
无符号整数与有符号整数的比较:有符号整数类型转换为无符号整数再进行比较 \(eg\): \(-1\) \(>\) \(0U\)
无符号整数与符号整数的转换:
\(-t+u=2^w (t<0)\)
\(t=u(t \geq 0)\)
2.符号扩展与数字截断
符号扩展:在不改变值的情况下提升一个\(w\)位有符号整数的位数
case1:若符号位\(a_{w-1} = 0\)
直接将\(a_w\)设为\(0\),扩展到了\(w+1\)位
case2:若符号位\(a_{w-1}=1\)
将第\(a_w\)设为\(1\),第\(a_w\)和\(a_{w-1}\)的贡献从\(-2^{w-1}\)到\(-2^{w}+2^{w-1}\)不变,扩展到了\(w+1\)位
即扩展到第\(w+1\)位时有\(a_w=a_{w-1}\)
数字截断:舍弃数字第\(k\)位及其以前的所有位
无符号数数字截断等价于对\(2^k\)取模
从较小整数类型转换到较大整数类型时,先进行符号扩展,然后再进行有无符号的类型转换
eg. 对于short x; (unsigned)x等价于(unsigned)(int)x
3.运算
对于两个\(w\)位整数的运算,加法得到的结果最多为\(w+1\)位,截断第\(w+1\)位得到\(w\)位整数,对无符号整数来说等价于对结果\(mod\) \(2^w\)
乘法得到的结果最多为\(2w\)位,截断前\(w\)位得到\(w\)位整数
\(w\)位整数与常数相乘的时候,编译器会根据上下文进行优化,优化方式取决于架构的指令集
eg. x*14=(x<<3)+(x<<2)+(x<<1)或((x<<3)-x)<<2(乘法分解为位移和加减法)
或imul eax, edi, 14(编译器认为imul更快,直接使用乘法指令)
逻辑右移:右移一位后在最高位补0
算术右移:右移一位后,若符号位原本为1,则在最高位补1,否则补0
除以2的幂时:
无符号数采用逻辑右移,等价于向下取整
有符号数需要特殊处理:编译器会生成先加偏置再算术右移的代码,以保证向零取整的结果与C语言标准一致
二进制下的浮点数
1.浮点数的表示
标准化之前
对浮点数\(x\)有:\(x=\sum \limits_{i=-j}^{k}a_i \times2^i\)
左移,右移在算术上仍然等价于\(\times2\) 和 \(\div 2\),但是误差大,受位数有限制约
标准浮点数表示法:IEEE浮点数
IEEE浮点数
符号位(s) + 阶码位(exp) + 尾数位(frac)
单精度32位 双精度64位 (和英特尔扩展精度80位)
32 = 1 + 8 + 23
64 = 1 + 11 + 52
IEEE浮点标准用\(V=(-1)^s \times 2^E * M\)表示浮点数

设\(exp=\sum\limits_{i=0}^{k-1}2^ie_i\),\(bias=2^{k-1}-1\)(无符号整数)
\(frac = \sum\limits_{i=0}^{n-1}f_i\times2^{i-n}\)(分数)
1.规格化的情况(\(1 \leq exp \leq 2^k-2\))
\(E=exp-bias\),\(M=1.0 + frac\),那么有\(-2^{k-1} + 2 \leq E \leq 2^{k-1} -1\)
2.非规格化的情况(\(exp = 0\))
\(E=1-bias\),\(M=frac\)
用来表示\(0\)和极其接近\(0\)的值
注:\(+0.0\)和\(-0.0\)是两个不同的数
3.特殊值(\(exp = 2^k-1\))
\(frac = 0\):\(V=INF\)
\(frac \neq 0\):\(V=NaN\)
注:
1.引入\(bias\)的意义:阶码无需引入符号位,使得正负相同的浮点数大小比较可以直接二进制按位比较
2.非规格化情况下\(E\)取\(1-bias\),使得非规格化最大值为\(2^{2-{2^{k-1}}} \times (1-{2^{-n}})\),而规格化最小值为\(2^{2-{2^{k-1}}}\),二者十分接近
2.整数转浮点数(以将(int)114转换为float为例)
1.转为二进制下科学计数法
\(114 = (1110010)_2 = (1.110010)_2 \times 2 ^ 6\)
2.去掉小数点前的1并在末尾添加0直到\(n\)(23)位,得到尾数部分
\(1.110010 -> 11001000000000000000000\)
3.将阶数加上偏移值\(2^{k-1}-1\)(127),转为二进制得到阶码部分
\(2^6 + 127 = 191 = (10111111)_2\)
4.加上符号位,将阶码尾数拼起来
\((01011111111001000000000000000000)_2\)
由该过程可知,整数二进制编码与其浮点数表示的尾数部分除第一个1外重合
3.思考:假设阶码足够大,有\(n\)位尾数的浮点数不能精确表示的最小正整数为\(2^{n+1}+1\)
证明:\(n\)位的\(frac\)再加上尾数隐式的\(1.0\)一共\(n+1\)位,乘\(2^E\)可以看做左移\(E\)位,在阶码可以取到无穷大的情况下,可以取遍\(1 ~ 2^{n+1}-1\),同时在\(frac\)全为\(0\)的情况下,左移\(n+1\)位得到\(2^{n+1}\),即\(1~2^{n+1}\)都可以表出,而\(2^{n+1}+1\)无法表出
推论:\(double\)在能准确表示的最大正整数为\(2^{53}=9007199254740992\)
补充:\(n\)位尾数浮点数在\(x\)处的误差(可表示数的最小间隔) \(ULP(x)=2^{\lfloor \log_2 \lvert x \rvert \rfloor - n}\)
警钟撅烂:double r = 1e18+5; \(r\)的值仍然为\(10^{18}\)
4.浮点数的运算
舍入:找到最接近的值\(x\),使其可以按期望的浮点形式表示出来
向零舍入,向上舍入,向下舍入
向偶数舍入:优先向满足条件的最接近的数舍入,若存在两个这样的数,则向最低有效位为偶数的那个数舍入(避免了统计误差)
浮点加法,乘法运算不满足结合律,浮点乘法在加法上不存在分配律
eg.对于\(float\)有\(1.14+1e18-1e18=0\)(舍入导致1.14丢失),\(1.14+(1e18-1e18)=1.14\)
无穷运算规则:+∞ + (+∞) = +∞,+∞ + (-∞) = NaN,+∞ × 0 = NaN
NaN的传播特性:任何包含NaN的运算结果都是NaN
5.C中浮点数与有符号数的转换
\(int\)转\(float\)可能被舍入
\(double\)转\(int,float\)可能会溢出或者被舍入
\(float,double\)转\(int\)值会向零舍入,若溢出则产生整数不确定值\((100..00)_2\) 即\(-2^{w-1}\)
Datalab
Github
上古版本的c语法标准,需要变量声明在函数代码的顶部(
以及不能使用实现过的函数,导致每次用的时候需要手动展开((
Machine Language
程序的机器级表示
编译过程
以GCC编译C语言为例
linux> gcc -Og -o hello hello.c
(-Og 优化等级低,避免机器代码严重变形,便于进行调试)
- 预处理:将预处理指令进行替换 (头文件包含,宏展开,条件编译
#if #ifdef #endif...),删除注释,得到处理后的.iC代码 - 编译:将
.i文件进行编译得到.s汇编语言文件 - 汇编:将
.s翻译成机器指令,得到二进制文件 (windows下.objlinux下.o) - 链接:将
.o文件和所需要的库文件组合在一起(头文件的函数在预处理中只声明,链接定位函数的具体实现),生成可执行文件
linux> gcc -Og -S hello.c 产生一个汇编文件 hello.s
linux> gcc -Og -c hello.c 产生二进制文件hello.o
linux> objdump -d hello.o 实现反汇编
机器级代码概述
指令集架构(ISA Instruction Set Architecture) 定义机器级代码的格式和行为,虽然指令在ISA层面被描述为顺序执行,但现代处理器采用流水线、乱序执行等技术实现并发执行,最终结果与顺序执行一致
x86系列:8086(16位架构) \(\rightarrow\) IA-32 (32位架构) \(\rightarrow\) x86-64(64位架构)
机器级程序使用多个硬件存储器组成的虚拟地址,操作系统负责将虚拟地址翻译成对应的物理地址
一条机器代码一般只执行非常基本的操作,如寄存器中两个数相加,存储器与寄存器之间传送数据,条件分支转移到新的指令地址等
汇编代码格式:AT&T与Intel
- Intel 代码省略了指示大小的后缀:
movq\(\rightarrow\)mov - Intel 代码省略寄存器前面的"%":
%rax\(\rightarrow\)rax - Intel 代码描述内存的方式不同:
(%rax)\(\rightarrow\)QWORD PTR [rax] - Intel 与 AT&T列出操作数的顺序相反:
movq %rax, %rbx\(\rightarrow\)mov rbx, rax
本文采用x86-64 AT&T格式
机器代码的优势:性能优化,访问硬件特性(PC,寄存器),更难逆向分析
数据的传输
数据格式
最初的架构为16位,所以Intel用 字(word) 表示16位,32位为双字(double words/long word),64位为四字(quad words)
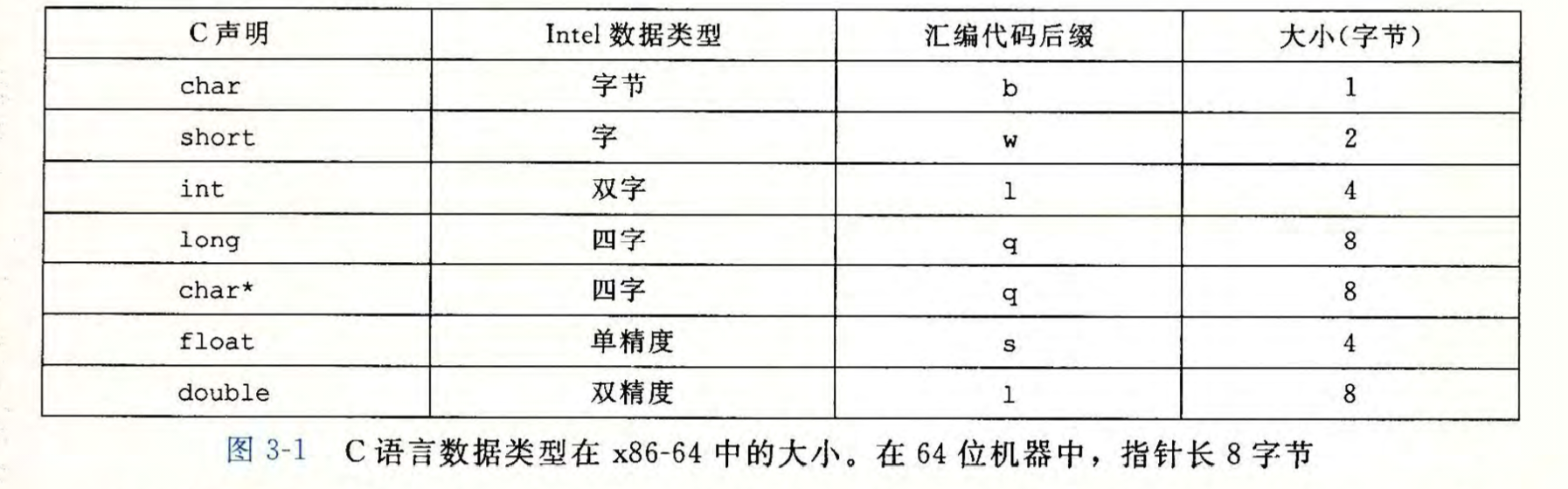
GCC生成的部分汇编代码指令都带有一个字符后缀表示操作的大小,如movl表示传送双字
信息访问
x86-64 CPU 中含有16个通用寄存器

8086中含有%ax到%sp8个通用寄存器
IA32将这8个寄存器扩展为32位 (%eax中的"e":extended)
x86-64将寄存器扩展到64位(%rax中的"r":register整个寄存器),并采用新的命名方式增加8个寄存器(%r8~%r15,%r8d中的"d":double words,%r8w中的"w":word)
指令通过不同的后缀大小(b,w,l,q),得以访问寄存器的不同最低字节(1,2,4,8)
小于8字节的数据传送到寄存器中时,若传送字节为1或2,则更高的字节不变;若传送字节为4,则更高的4个字节全置为0(IA32到x86-64扩展导致的)
操作数指示符
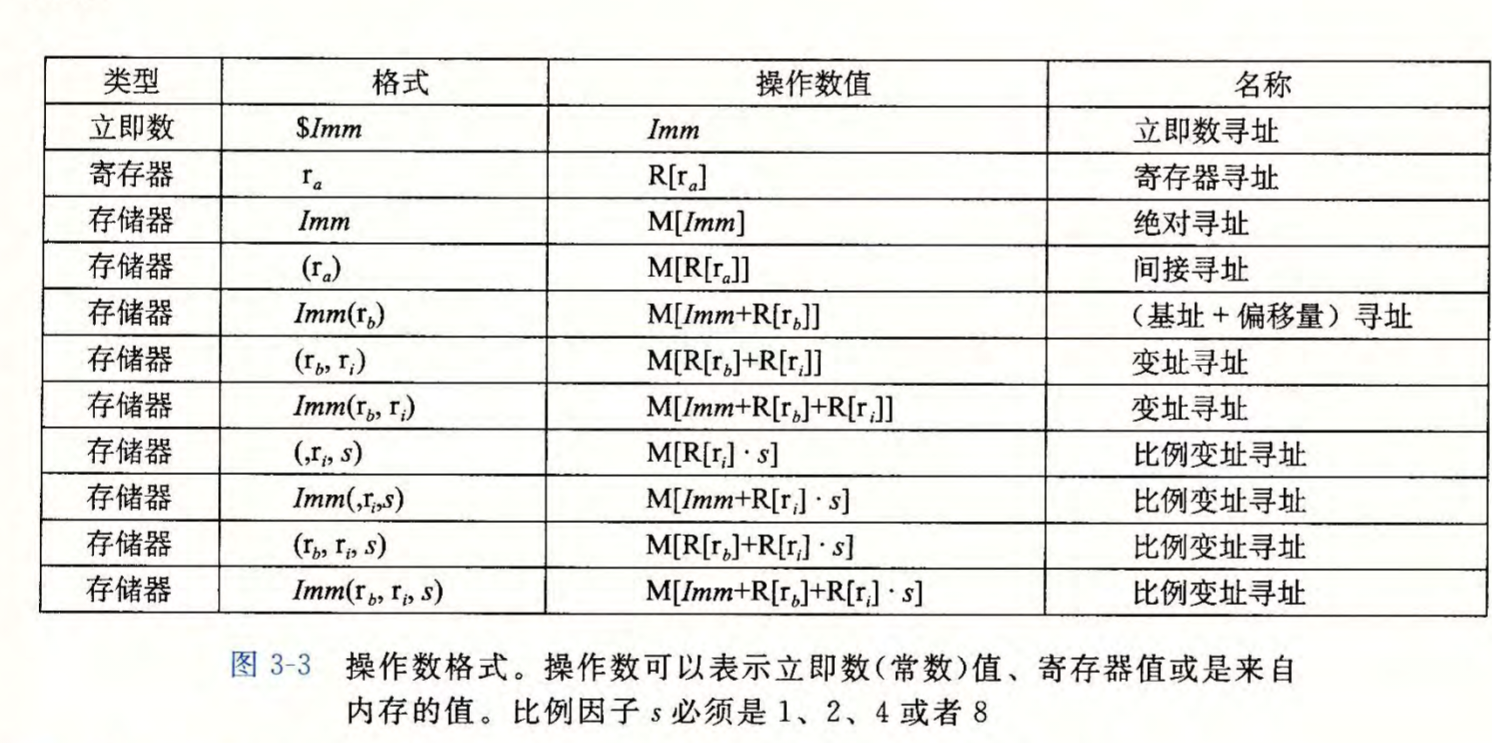
将寄存器看做数组\(R[]\),内存看做数组\(M[]\)
- 立即数(immediate):
$后面接常数 eg.$114514 - 寄存器(register):以指定寄存器的低位1,2,4,8字节为操作数,返回寄存器中的值即\(R[r_a]\) eg.
%eax返回第一个寄存器的低32位 - 内存引用:将内存看做很大的字节数组,根据计算的有效地址访问内存位置
内存引用的寻址模式:\(Imm(r_b,r_i,s)\),其中\(Imm\)为立即数偏移,\(r_b\)和\(r_i\)为64位寄存器,\(s\)取1,2,4,8(默认为1)
有效地址被计算为\(addr=Imm+R[r_b]+R[r_i]*s\),返回\(M[addr]\)
数据传送指令
将数据从一个位置传送到另一个位置的指令
MOV
MOV S, D指将数据从\(S\)复制到\(D\),其中\(S\)称为源操作数,\(D\)称为目的操作数
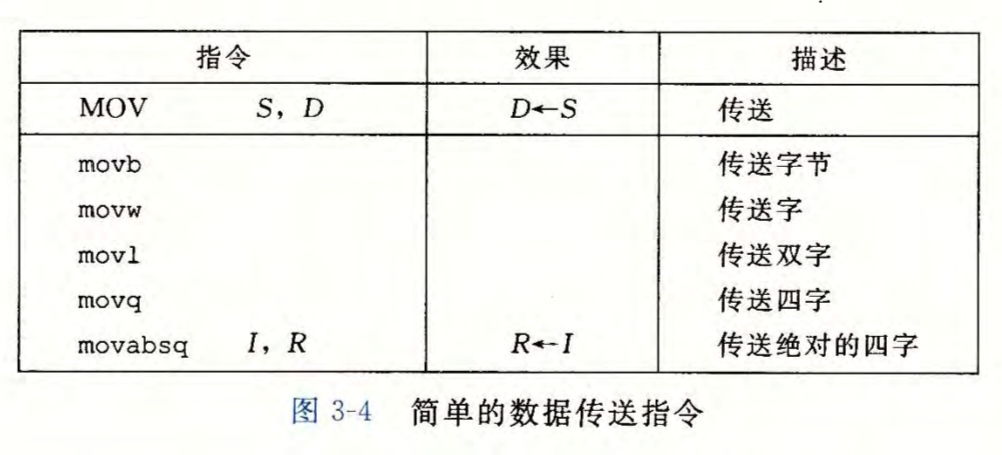
其中源操作数可以取立即数,寄存器,内存;目的操作数可以取寄存器和内存
注意:x86架构中大部分操作(包括MOV)源操作数和目的操作数不能同时为内存,必须通过寄存器进行中转
\(movabsq\)作用:处理立即数时,\(movq\)只能传送32位立即数然后在符号扩展到64位,而\(movabsq\)能将64位立即数直接传送到寄存器,但只能移动立即数

MOVZ与MOVS
两者都是将较小源值复制到较大的目的值,后缀都有两个大小指示符,分别是源的大小和目的的大小
MOVZ 采用零扩展进行复制,无符号数扩展
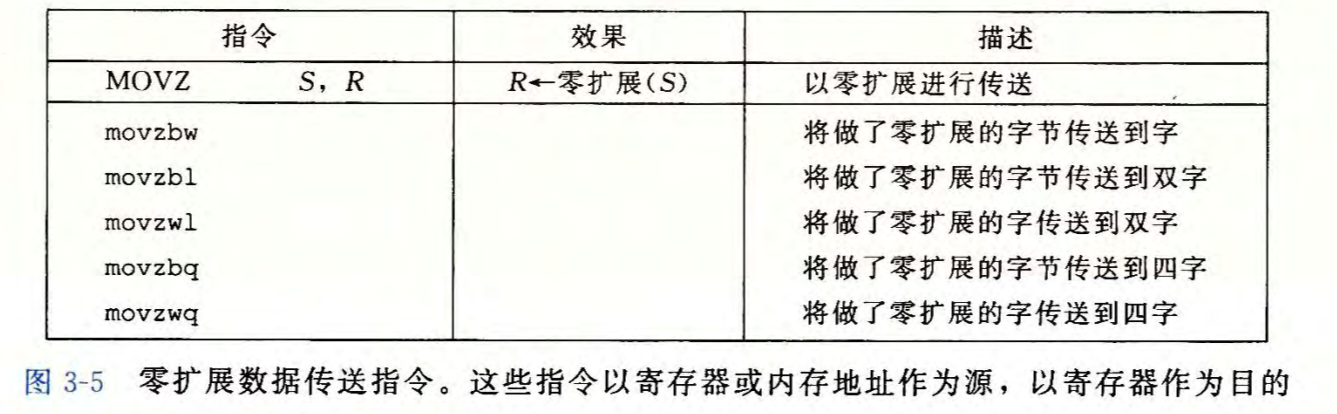
注:没有movzlq的原因是使用movl传送4个字节会把前面更高的4个字节全赋为0,两者等价
MOVS采用符号扩展进行复制,有符号数扩展