作业1
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
(1)代码和运行结果
点击查看代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3class WeatherDB:def openDB(self):# 连接到SQLite数据库self.con = sqlite3.connect("weathers.db")self.cursor = self.con.cursor()try:# 创建天气数据表,主键为城市+日期self.cursor.execute("""create table weathers (wCity varchar(16), wDate varchar(16), wWeather varchar(64), wTemp varchar(32), constraint pk_weather primary key (wCity, wDate))""")except:# 若表已存在则清空表数据self.cursor.execute("delete from weathers")def closeDB(self):self.con.commit() self.con.close()def insert(self, city, date, weather, temp):try:self.cursor.execute("""insert into weathers (wCity, wDate, wWeather, wTemp) values (?, ?, ?, ?) """, (city, date, weather, temp))except Exception as err:print(f"插入数据出错: {err}")def show(self):self.cursor.execute("select * from weathers")rows = self.cursor.fetchall()# 打印表头print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))# 打印每条数据for row in rows:print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))class WeatherForecast:def __init__(self):# 设置请求头,模拟浏览器访问self.headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}# 城市与对应天气网代码的映射(用于构造请求URL)self.cityCode = {"北京": "101010100","上海": "101020100","广州": "101280101","深圳": "101280601"}def forecastCity(self, city):# 检查城市是否在支持的列表中if city not in self.cityCode.keys():print(f"{city} code cannot be found")return# 构造该城市的天气查询URLurl = f"http://www.weather.com.cn/weather/{self.cityCode[city]}.shtml"try:# 发送HTTP请求req = urllib.request.Request(url, headers=self.headers)data = urllib.request.urlopen(req)data = data.read() # 读取网页原始二进制数据# 自动检测网页编码并转换为Unicodedammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(data, "lxml")# 定位包含天气数据的列表项(通过CSS选择器)lis = soup.select("ul[class='t clearfix'] li")# 遍历每一天的天气数据for li in lis:try:# 提取日期(h1标签内容)date = li.select('h1')[0].text# 提取天气状况(class为wea的p标签内容)weather = li.select('p[class="wea"]')[0].text# 提取温度范围(span标签为最高温,i标签为最低温)temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text# 打印提取的数据print(city, date, weather, temp)# 调用数据库插入方法存储数据self.db.insert(city, date, weather, temp)except Exception as err:print(f"解析单条天气数据出错: {err}")except Exception as err:print(f"请求或解析页面出错: {err}")def process(self, cities):# 初始化数据库连接self.db = WeatherDB()self.db.openDB()# 遍历城市列表,逐个爬取数据for city in cities:self.forecastCity(city)# 关闭数据库连接self.db.closeDB()if __name__ == "__main__":ws = WeatherForecast()ws.process(["北京", "上海", "广州", "深圳"])print("completed")
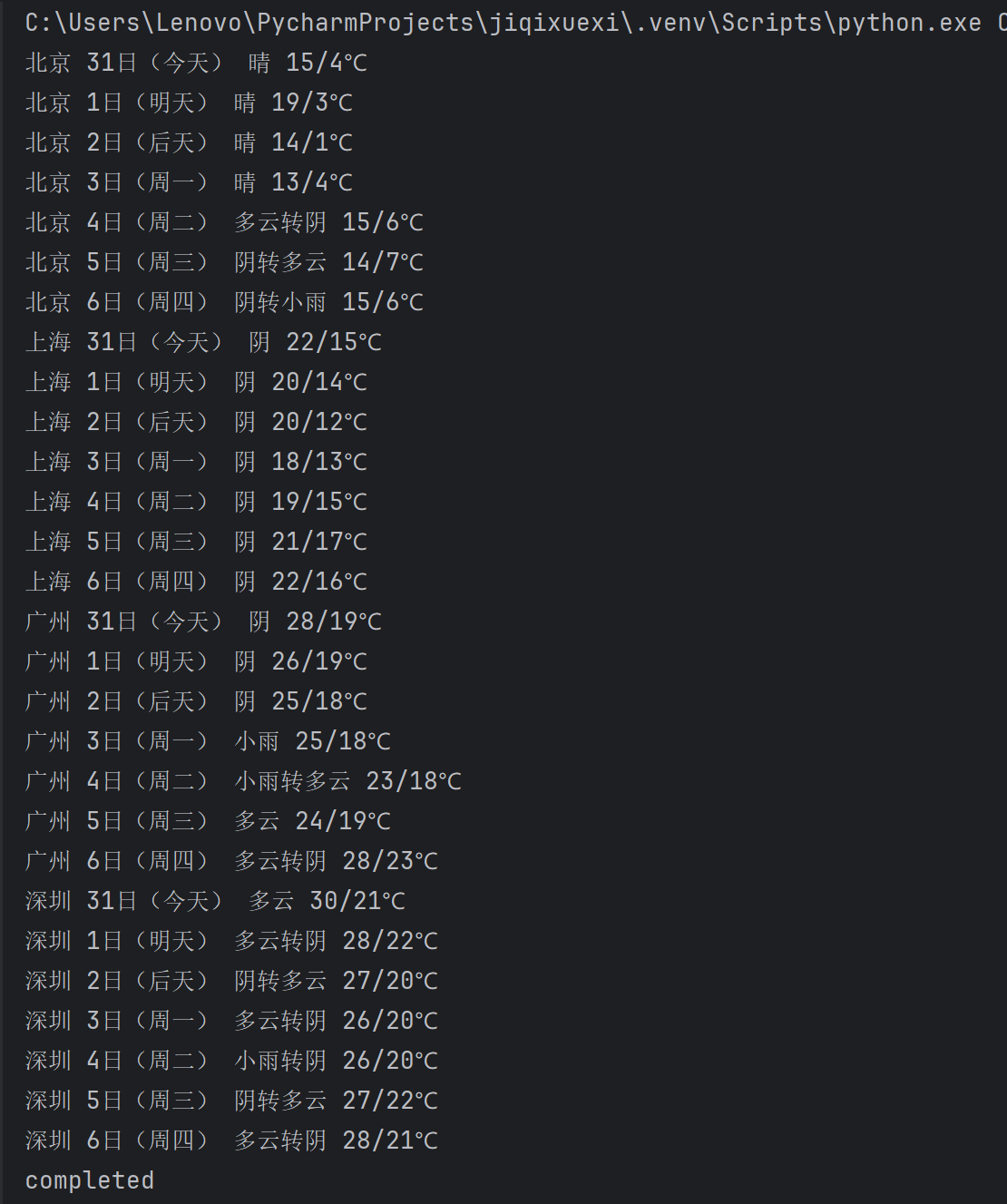
(2)心得体会
从上图的url网址中可以看出各个不同的城市之间只需要修改url城市编号即可,所以我们可以构建一个映射表,去分别访问不同城市的url。
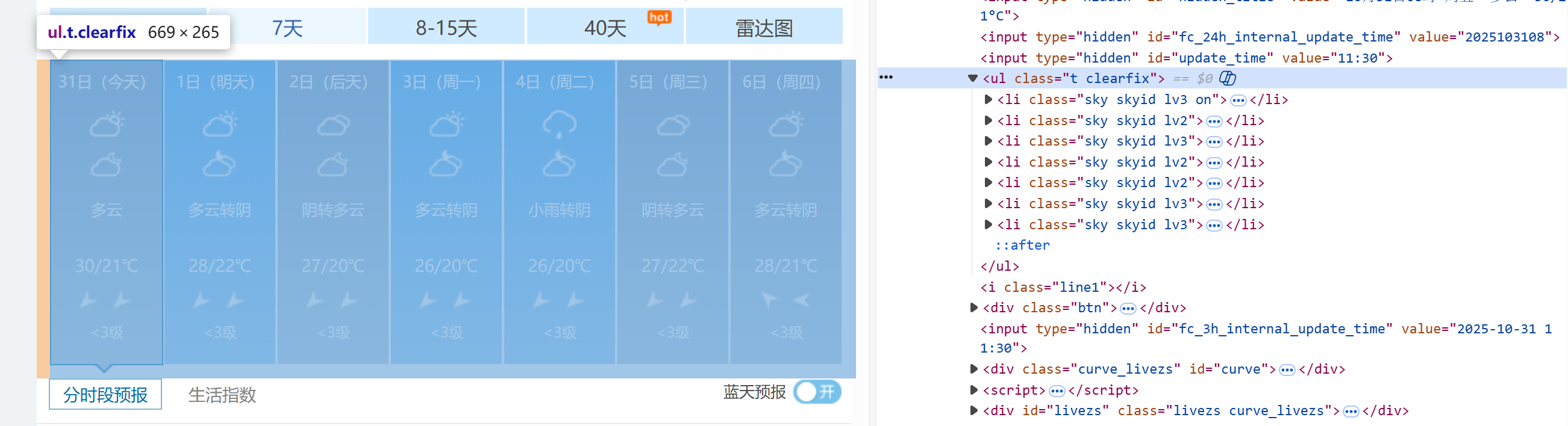
通过f12我们可以很清晰的看到我们先要的数据都被存放在一个class='t clearfix'的ul中,只要去遍历ul下面的每一个li,利用css去定位爬取,就可以得到我们想要的结果
总之,无论使用re、css,只要明确自己所要爬取的网页结构,就可以轻松爬取到
作业2
用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
(1)代码和运行结果
点击查看代码
import requests
import sqlite3
import time
import json
from datetime import datetimedef init_db():# 连接到SQLite数据库conn = sqlite3.connect('stock_data.db')cursor = conn.cursor()# 创建股票数据表,定义各字段及类型cursor.execute('''CREATE TABLE IF NOT EXISTS stocks (id INTEGER PRIMARY KEY AUTOINCREMENT, code TEXT, name TEXT, latest_price REAL, change_percent REAL, change_amount REAL, volume INTEGER, turnover REAL, increase REAL, crawl_time DATETIME )''')conn.commit() # 提交事务conn.close() # 关闭连接# 数据存储函数
def save_to_db(data_list):conn = sqlite3.connect('stock_data.db')cursor = conn.cursor()crawl_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')# 遍历股票数据列表,逐条插入数据库for data in data_list:cursor.execute('''INSERT INTO stocks (code, name, latest_price, change_percent, change_amount, volume, turnover, increase, crawl_time)VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?) ''', (data['code'],data['name'],data['latest_price'],data['change_percent'],data['change_amount'],data['volume'],data['turnover'],data['increase'],crawl_time))conn.commit()conn.close()# 爬取股票数据并处理格式转换
def crawl_stock_data(page=1, pagesize=20):# 抓包的东方财富网股票数据接口url = f"https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery37107275901173684839_1761722704966&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn={page}&pz={pagesize}&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb&_=1761722704968"try:# 设置请求头,模拟浏览器访问headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Referer": "https://www.eastmoney.com/","Accept": "text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01","X-Requested-With": "XMLHttpRequest"}# 发送GET请求response = requests.get(url, headers=headers, timeout=10)response.encoding = 'utf-8' # 手动指定编码为utf-8,避免中文乱码# 处理JSONP格式数据if '(' in response.text and ')' in response.text:json_str = response.text[response.text.find('(') + 1: response.text.rfind(')')]else:print("返回数据非JSONP格式,无法解析")return []# 解析JSON字符串为字典data = json.loads(json_str)# 提取核心数据(接口返回的股票列表在data.diff中)if data.get('data') and 'diff' in data['data']:stock_list = []for item in data['data']['diff']:# 位转换(API返回原始数据为最小单位,需转换为常规显示单位)stock_info = {'code': item.get('f12', ''),'name': item.get('f14', ''),'latest_price': item.get('f2', 0) / 100,'change_percent': item.get('f3', 0) / 100,'change_amount': item.get('f4', 0) / 100,'volume': item.get('f5', 0),'turnover': item.get('f6', 0) / 10000,'increase': item.get('f3', 0) / 100}if stock_info['code'] and stock_info['name']:stock_list.append(stock_info)return stock_listelse:print(f"API返回数据结构异常:{data.get('rc', '未知错误码')},{data.get('rt', '无返回信息')}")return []except requests.exceptions.RequestException as e:print(f"网络请求错误: {e}") # 捕获请求超时、连接失败等网络错误return []except json.JSONDecodeError as e:print(f"JSON解析错误(返回内容:{response.text[:100]}...): {e}") # 捕获JSON格式错误return []except Exception as e:print(f"其他爬取错误: {e}") # 捕获其他未预料的错误return []# 打印股票数据:格式化输出
def print_stock_data(stock_list):# 打印表头,使用制表符和对齐符保证格式整齐print(f"\n{'序号':<4}\t{'代码':<8}\t{'名称':<8}\t{'最新价':<8}\t{'涨跌幅(%)':<10}\t{'涨跌额':<8}\t{'成交量':<10}\t{'成交额(万)':<10}\t{'涨幅(%)':<8}")print("-" * 120) # 分隔线# 遍历股票列表,按格式打印每条数据for i, stock in enumerate(stock_list, 1):print(f"{i:<4}\t{stock['code']:<8}\t{stock['name']:<8}\t{stock['latest_price']:<8.2f}\t"f"{stock['change_percent']:<10.2f}\t{stock['change_amount']:<8.2f}\t{stock['volume']:<10}\t"f"{stock['turnover']:<10.1f}\t{stock['increase']:<8.2f}")def main():init_db()print("数据库初始化完成,开始爬取股票数据...")total_pages = 3 # 爬取的总页数pagesize = 20 # 每页数据量# 循环爬取多页数据for page in range(1, total_pages + 1):print(f"\n=== 正在爬取第{page}/{total_pages}页数据 ===")# 调用爬取函数获取当前页数据stock_list = crawl_stock_data(page=page, pagesize=pagesize)# 若获取到有效数据,则打印并存储if stock_list:print_stock_data(stock_list) # 打印数据save_to_db(stock_list) # 存储数据print(f"第{page}页数据已保存至stock_data.db(共{len(stock_list)}条记录)")else:print(f"第{page}页未获取到有效股票数据")time.sleep(3)print(f"\n爬取完成!数据已存储至stock_data.db")if __name__ == "__main__":main()
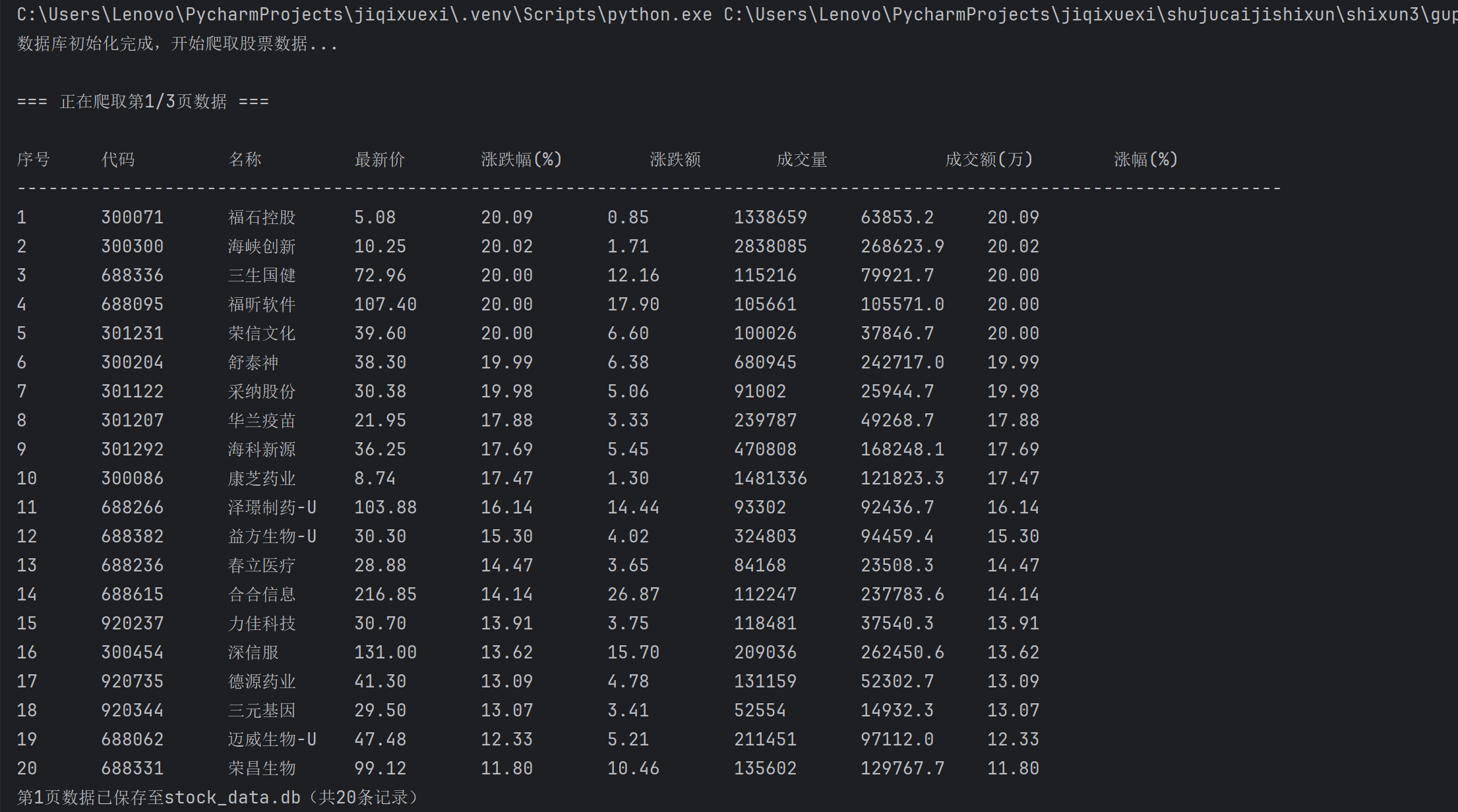
(2)心得体会

通过f12去抓包到相应的信息包,可以从预览中查看到存储的数据,将这个我们所需要的包的标头复制下来,通过浏览器可以查看到我们所需要的信息存储在data下的diff
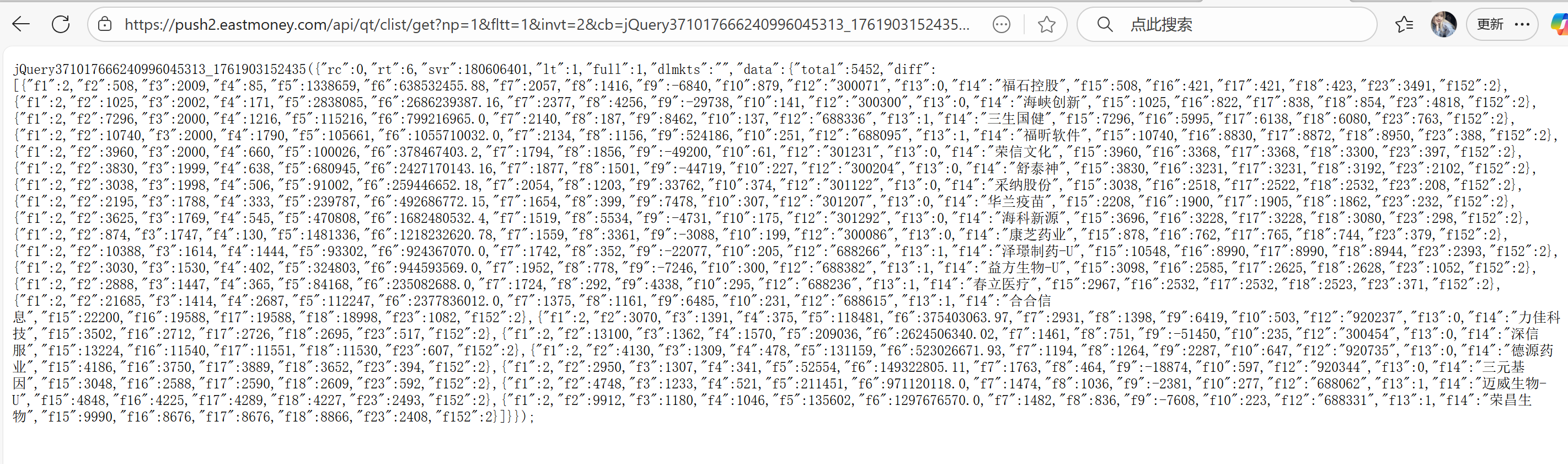
这个网页结构很整洁也很清晰,所以只需要找到我们所需对应的数据,用get方法获取请求的参数f数据即可得到
这道题是用了一种新方法,刚开始还不能够很熟练的掌握,抓包的时候也需要一个一个去点击查看是不是自己想要的包,第一次代码运行出来的时候,我发现API返回原始数据为最小单位,需要我们对数据进行处理,转换为常规显示单位
作业3
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
(1)代码和运行结果
点击查看代码
import os
import re
import datetime
import requests
import sqlite3
from sqlite3 import Errordef download_payload_js(url, save_path="payload.js"):"""下载payload.js文件到本地"""try:headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"}print(f"开始下载: {url}")response = requests.get(url, headers=headers, timeout=15)response.raise_for_status()with open(save_path, "w", encoding="utf-8") as f:f.write(response.text)print(f"下载成功,保存至: {os.path.abspath(save_path)}")return Trueexcept requests.exceptions.RequestException as e:print(f"下载失败: {str(e)}")return Falsedef parse_all_rankings(file_path="payload.js"):"""解析本地文件,提取所有排名数据"""if not os.path.exists(file_path):print(f"{file_path}不存在,无法解析")return []# 编码映射表province_map = {"q": "北京", "D": "上海", "x": "浙江", "k": "江苏", "v": "湖北","y": "安徽", "u": "广东", "B": "黑龙江", "C": "吉林", "n": "山东","o": "河南", "p": "河北", "N": "天津", "G": "山西", "F": "福建","t": "四川", "s": "陕西", "w": "湖南", "M": "重庆", "K": "甘肃","L": "内蒙古", "H": "云南", "I": "广西", "J": "贵州", "az": "宁夏","aA": "青海", "aB": "西藏", "O": "新疆", "Y": "海南", "r": "辽宁"}category_map = {"f": "综合类", "e": "理工类", "h": "师范类", "m": "农业类","S": "林业类", "dS": "政法类", "21": "医药类", "22": "财经类","19": "语言类", "23": "艺术类", "24": "体育类", "25": "民族类"}tag_map = {"i": "双一流", "l": "985", "j": "211"}try:with open(file_path, "r", encoding="utf-8") as f:content = f.read()# 提取univData核心区域univ_data_match = re.search(r'univData:\s*\[(.*?)\],\s*indList:', content, re.S)if not univ_data_match:print("未找到核心数据区域")return []# 提取所有大学对象univ_items = re.findall(r'\{[^}]*univNameCn:"[^"]+"[^}]*\}', univ_data_match.group(1), re.S)all_rankings = []for idx, item in enumerate(univ_items, 1):# 基础信息提取name_cn = re.search(r'univNameCn:"(.*?)"', item).group(1) if re.search(r'univNameCn:"(.*?)"',item) else f"未知大学_{idx}"name_en = re.search(r'univNameEn:"(.*?)"', item).group(1) if re.search(r'univNameEn:"(.*?)"',item) else "Unknown University"# 排名处理rank_match = re.search(r'ranking:([^,]+)', item)if rank_match and rank_match.group(1).strip('"').isdigit():rank = int(rank_match.group(1).strip('"'))else:rank = idx # 若无法提取排名,使用索引# 省份处理province_match = re.search(r'province:([^,]+)', item)province_code = province_match.group(1).strip('"') if province_match else ""province = province_map.get(province_code, "未知省份")# 学校类型处理category_match = re.search(r'univCategory:([^,]+)', item)category_code = category_match.group(1) if category_match else ""category = category_map.get(category_code, "未知类型")# 总分处理score_match = re.search(r'score:([^,]+)', item)if score_match:score_str = score_match.group(1).strip('"')score = float(score_str) if score_str.replace('.', '').isdigit() else Noneelse:score = None# 标签处理tags = "无"tags_match = re.search(r'univTags:\[([^\]]*)\]', item)if tags_match:tag_codes = [t.strip() for t in tags_match.group(1).split(',') if t.strip()]tags = ",".join([tag_map.get(t, t) for t in tag_codes])# 指标得分提取ind_data = {}ind_match = re.search(r'indData:(\{[^}]+\})', item)if ind_match:ind_str = ind_match.group(1)ind_name_map = {"159": "办学层次", "160": "学科水平", "163": "人才培养"}for code, name in ind_name_map.items():val_match = re.search(f'"{code}":"?([^,"]+)"?', ind_str)if val_match:val = val_match.group(1).strip()ind_data[name] = float(val) if val.replace('.', '').isdigit() else valelse:ind_data[name] = None# 组装数据all_rankings.append({"rank": rank,"name_cn": name_cn,"name_en": name_en,"province": province,"category": category,"score": score,"tags": tags,"school_level": ind_data.get("办学层次"),"discipline_level": ind_data.get("学科水平"),"talent_train": ind_data.get("人才培养"),"crawl_time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")})print(f"成功解析所有 {len(all_rankings)} 条排名数据")return all_rankingsexcept Exception as e:print(f"解析失败: {str(e)}")return []def create_db_connection(db_file):"""创建与SQLite数据库的连接"""conn = Nonetry:conn = sqlite3.connect(db_file)print(f"数据库连接成功 (SQLite版本: {sqlite3.version})")return connexcept Error as e:print(f"数据库连接失败: {e}")return conndef create_ranking_table(conn):"""创建大学排名表"""try:sql_create_rankings_table = """CREATE TABLE IF NOT EXISTS university_rankings (id INTEGER PRIMARY KEY AUTOINCREMENT,rank INTEGER NOT NULL,name_cn TEXT NOT NULL,name_en TEXT,province TEXT,category TEXT,score REAL,tags TEXT,school_level REAL,discipline_level REAL,talent_train REAL,crawl_time TEXT);"""cursor = conn.cursor()cursor.execute(sql_create_rankings_table)print("大学排名表创建成功")except Error as e:print(f"创建表失败: {e}")def insert_rankings(conn, rankings):"""将排名数据插入数据库"""if not rankings:print("没有数据可插入")return Falsetry:# 先清空表中现有数据cursor = conn.cursor()cursor.execute("DELETE FROM university_rankings")# 插入新数据sql = """INSERT INTO university_rankings (rank, name_cn, name_en, province, category, score, tags, school_level, discipline_level, talent_train, crawl_time) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)"""# 准备数据data_to_insert = []for item in rankings:data_to_insert.append((item['rank'],item['name_cn'],item['name_en'],item['province'],item['category'],item['score'],item['tags'],item['school_level'],item['discipline_level'],item['talent_train'],item['crawl_time']))# 批量插入cursor.executemany(sql, data_to_insert)conn.commit()print(f"成功插入 {cursor.rowcount} 条数据")return Trueexcept Error as e:print(f"插入数据失败: {e}")conn.rollback()return Falsedef main():"""主函数:下载-解析-存储到数据库全流程"""# 配置参数js_url = "https://www.shanghairanking.cn/_nuxt/static/1761118404/rankings/bcur/2021/payload.js"local_file = "payload.js"db_file = "university_rankings.db" # SQLite数据库文件# 步骤1:下载文件(如果不存在)if not os.path.exists(local_file):if not download_payload_js(js_url, local_file):print("无法继续,缺少必要的数据源文件")return# 步骤2:解析所有排名数据all_rankings = parse_all_rankings(local_file)if not all_rankings:print("解析过程出现问题,无法获取数据")return# 步骤3:数据库操作conn = create_db_connection(db_file)if conn is not None:# 创建表create_ranking_table(conn)# 插入数据insert_rankings(conn, all_rankings)# 关闭连接conn.close()print("数据库连接已关闭")else:print("无法建立数据库连接,数据未保存")# 步骤4:打印部分结果预览print("\n数据预览:")print(f"{'排名':<6}{'学校':<18}{'省市':<6}{'类型':<8}{'总分':<6}")print("-" * 45)for item in all_rankings[::]: print(f"{item['rank']:<6}{item['name_cn']:<18}{item['province']:<6}{item['category']:<8}{str(item['score']):<6}")print(f"\n共解析 {len(all_rankings)} 所大学的排名数据并存储到数据库")if __name__ == "__main__":main()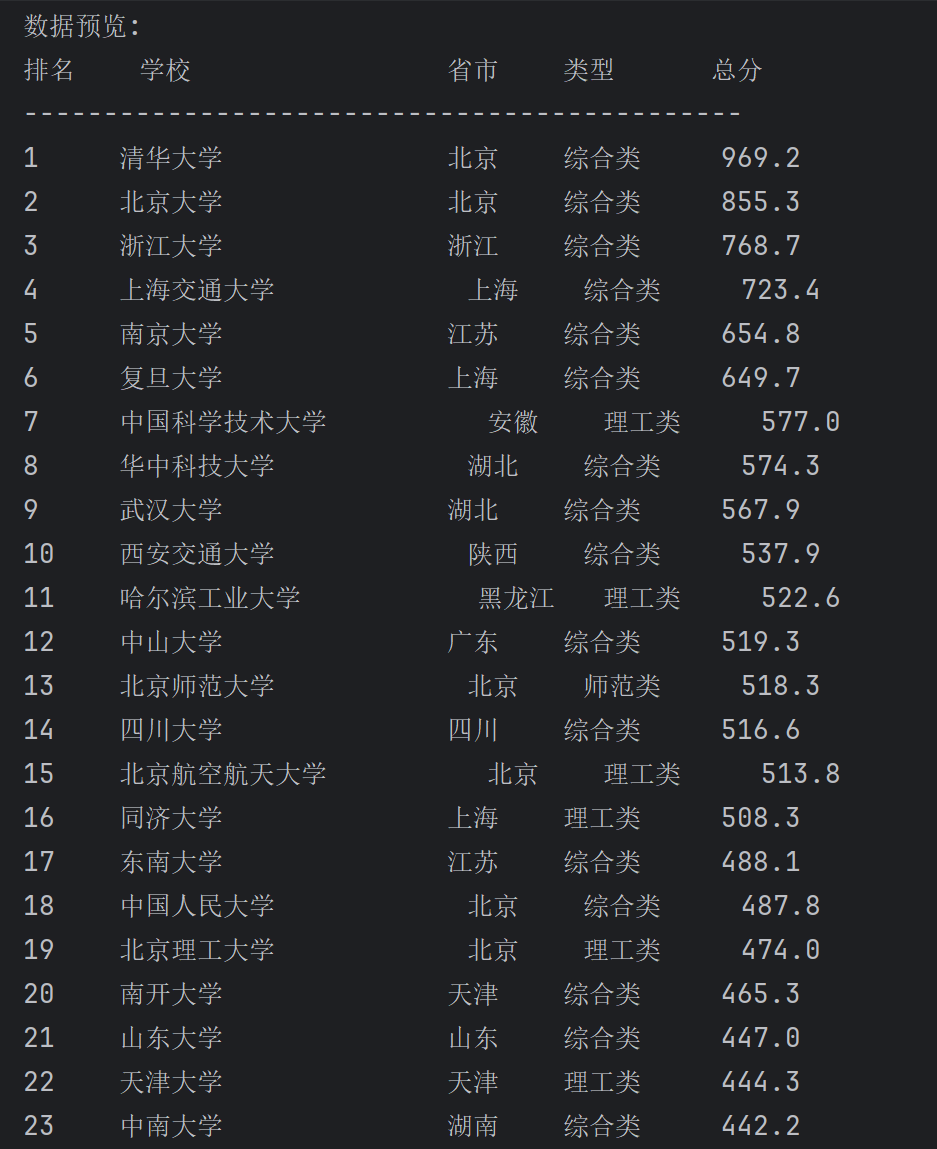
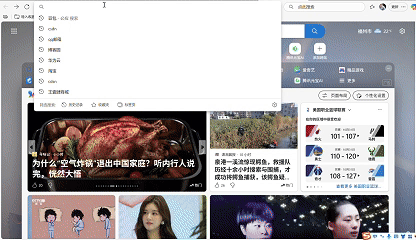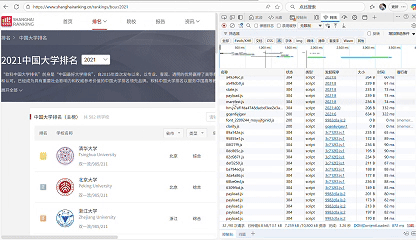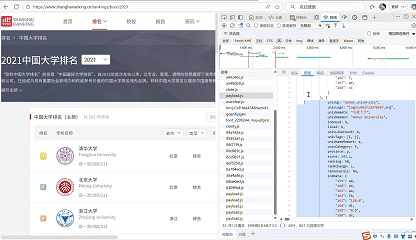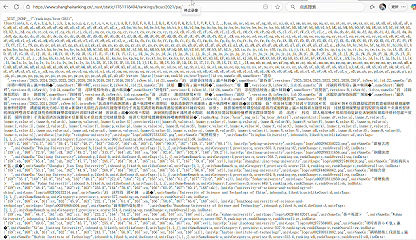
(2)心得体会
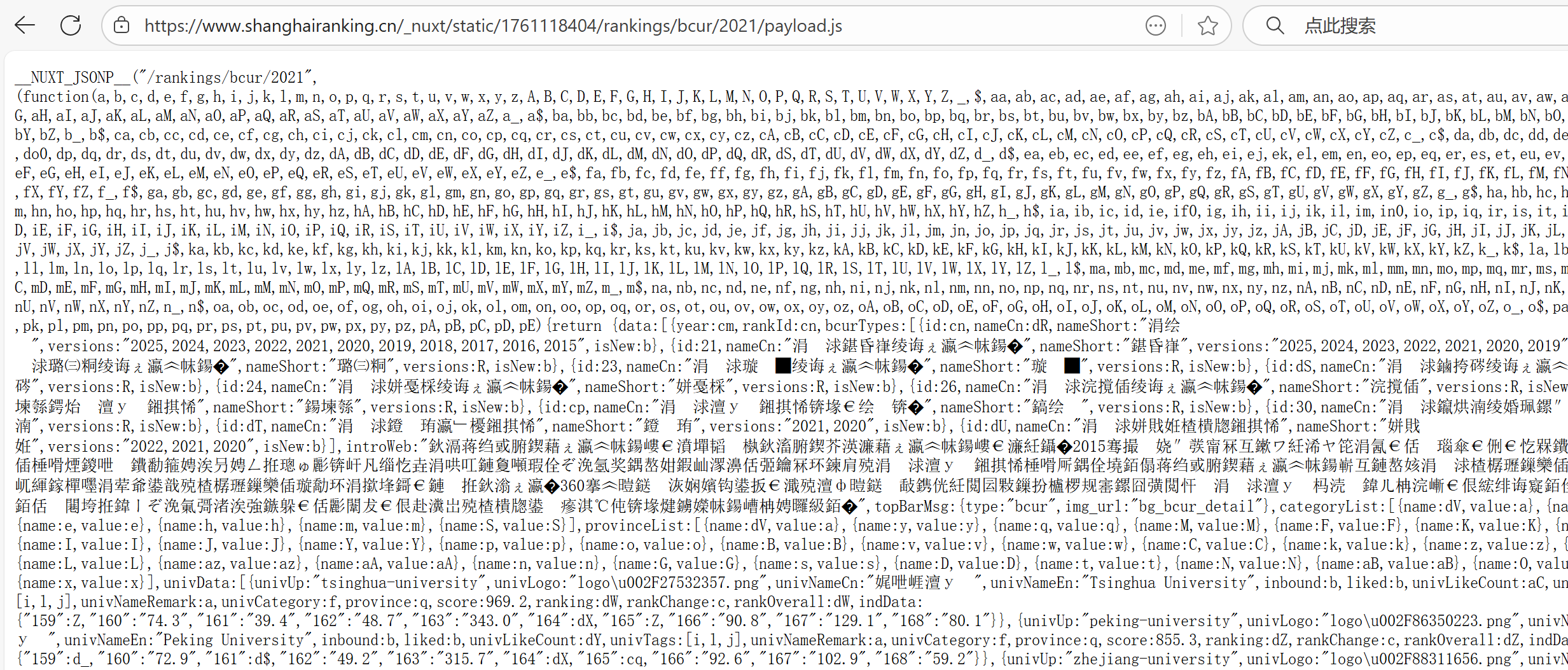
依旧是打开网址后进行抓包,找到存储数据的包,但是当我们用浏览器去预览这个包的标头时,我发现它的信息是乱码的
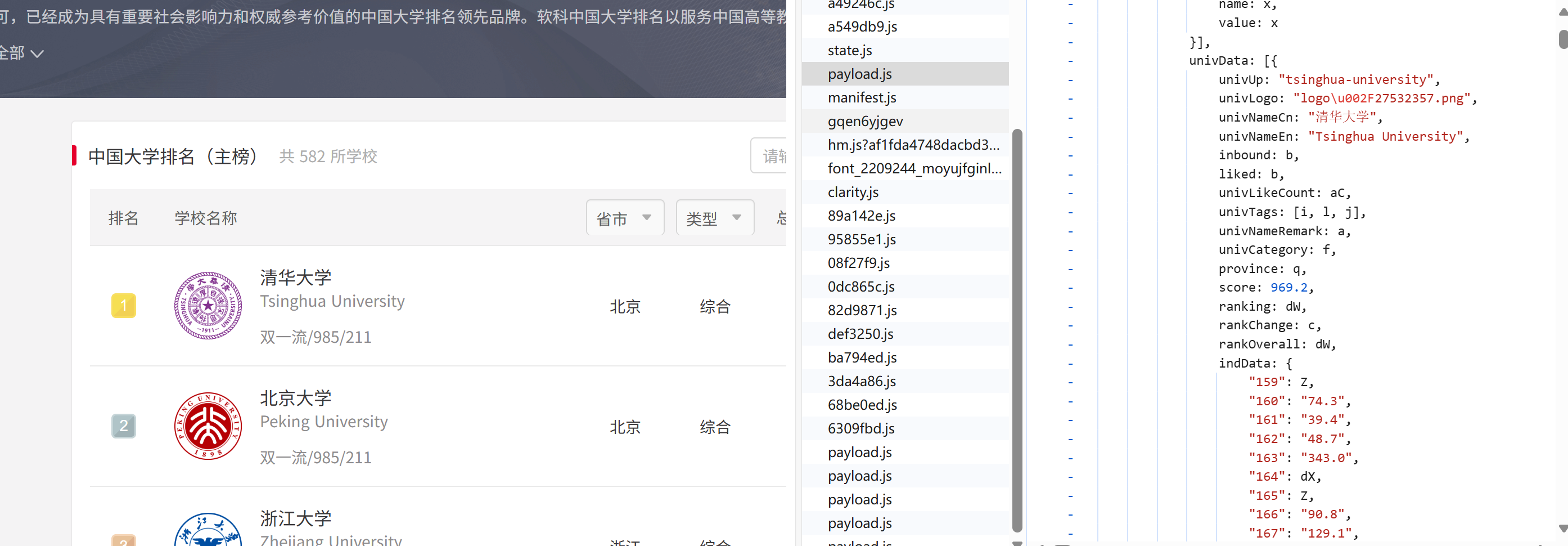
这就造成我们没有办法很清晰的去查看数据的结构,同学给我提供了一个思路,他让我将这个js文件下载并解析下来
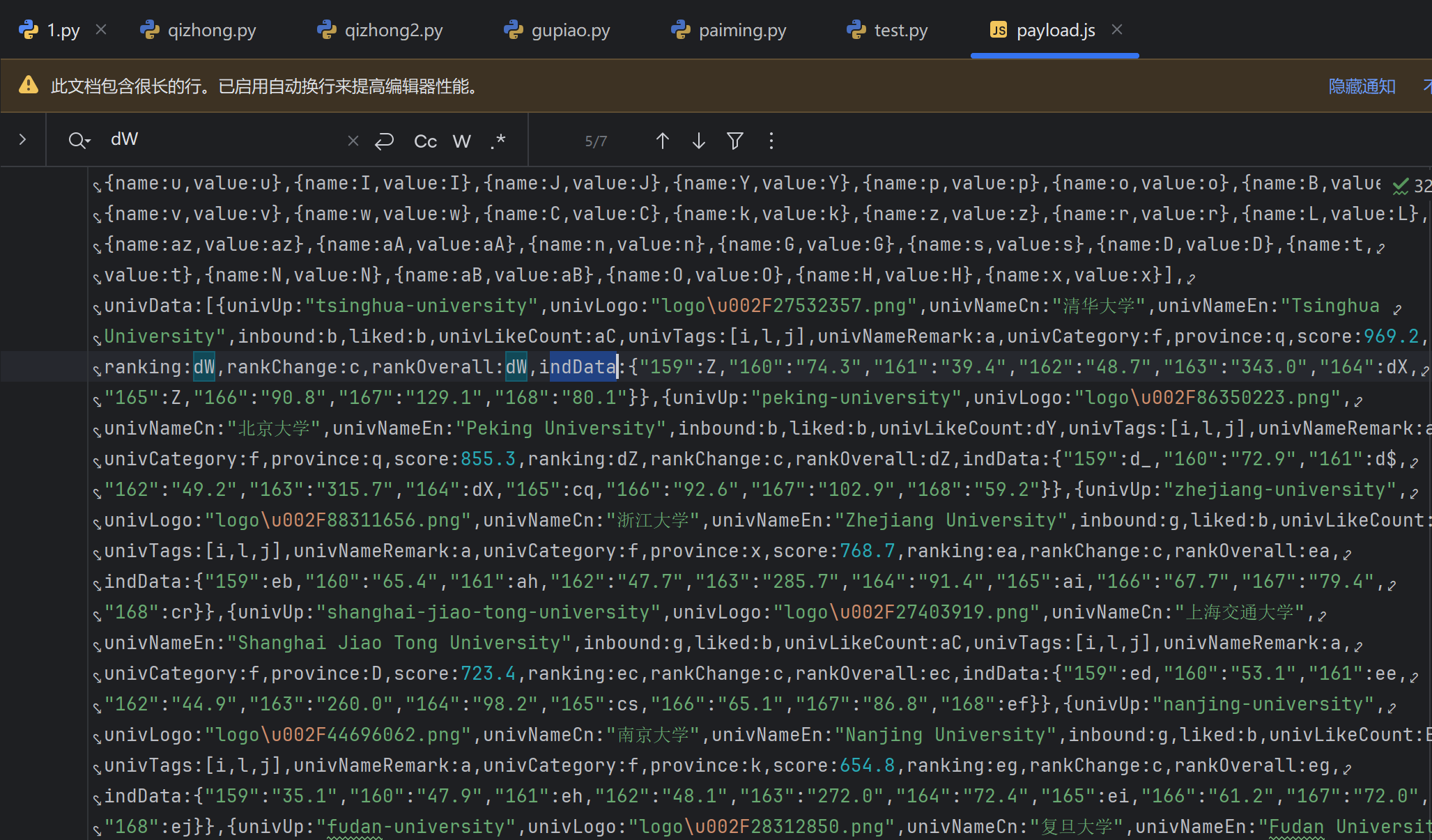
通过下载解析后,我们可以清楚的看到存储数据的结构,通过re正则表达式去匹配univNameCn(学校)、ranking(排名)、province(省份)等等。

但是在查看结构的时候,我们发现这个网址为了不想让我们能够很轻易的爬取到数据,它应用了一些密钥来转换,所以我们只能去添加一下映射表,先爬取它的代号,再将其通过密钥转换过来。
代码地址:https://gitee.com/lizixian66/shujucaiji/tree/homework2/





--定义ADT)









2023icpc济南)



