基础算法(四)堆排序
一 堆排序
堆排序是一种非常高效且独特的排序算法,它巧妙地将数据结构中的“堆”应用于排序过程。
1.1 特性介绍
堆排序特性总结
| 特性 | 说明 |
|---|---|
| 核心思想 | 利用堆这种数据结构进行选择排序。将待排序列构造成一个大顶堆(或小顶堆),从而不断将堆顶元素(最大值或最小值)与序列末尾元素交换,并调整堆结构,最终得到有序序列 |
| 时间复杂度 | 建堆:O(n);排序过程:O(n log n)。总体时间复杂度为 O(n log n),且最好、最坏、平均情况均如此 |
| 空间复杂度 | O(1),是原地排序算法,只需要常数级别的额外空间用于元素交换 |
| 稳定性 | 不稳定。因交换堆顶和末尾元素时,可能改变相等元素的原始相对顺序 |
| 主要优势 | 时间复杂度稳定,不会出现像快速排序那样的最坏O(n²)情况;原地排序,空间效率高 |
| 主要劣势 | 常数因子较大,通常比平均情况下的快速排序慢;对小规模数据排序效率相对不高;不稳定 |
1.2 算法工作原理
堆排序的运作过程清晰地分为“建堆”和“排序”两大阶段。下图以数组 [12, 11, 13, 5, 6, 7]为例,展示了构建大顶堆以及后续排序的关键步骤:
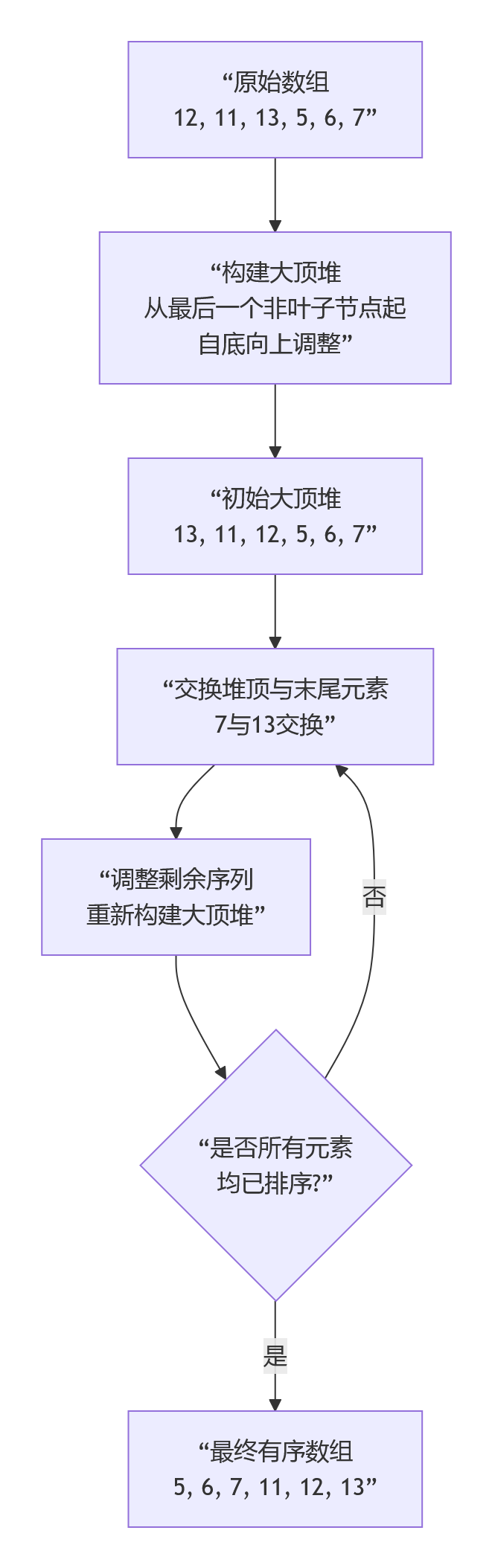
1.2.1 构建堆(Heapify)
这是堆排序的第一步,目标是將一个无序的完全二叉树调整成一个大顶堆(对于升序排序)。大顶堆的性质是:每个节点的值都大于或等于其左右子节点的值。
- 通常从最后一个非叶子节点开始(索引为 n/2 - 1,其中 n是数组长度),依次向前遍历每个非叶子节点。
- 对每个非叶子节点,执行“向下调整”操作:比较该节点与其左右子节点的值,如果子节点中有值更大的,则交换它们的位置,并递归地对被交换的子节点进行同样的调整,确保以该节点为根的子树满足堆的性质。
1.2.2 排序
一旦大顶堆构建完成,堆顶元素(根节点)就是整个序列中的最大值。
* 交换与调整:将堆顶元素与堆中最后一个元素交换。此时,最大值就位于数组的末尾,可以视为已排序部分。
* 缩小堆范围:将堆的大小减一(即忽略最后一个已排序的元素)。
- 重新调整堆:由于新的堆顶元素可能破坏堆的性质,因此需要对剩余的未排序序列(从新的根节点开始)再次进行向下调整,使其重新成为大顶堆。
- 重复上述“交换-调整-缩小”步骤,直到堆的大小变为1,此时整个数组就有序了。
1.3 复杂度分析
### 1.3.1 时间复杂度 O(n log n) 的由来:
- 建堆阶段:虽然需要调整n/2个节点,但由于二叉树的结构特性,大部分调整操作在较低的层进行。建堆操作的时间复杂度经分析为 O(n)。
- 排序阶段:需要进行n-1次交换和调整。每次调整堆(向下调整)的时间复杂度与当前堆的高度相关,即 O(log n)。因此,排序阶段的总时间复杂度为 O(n log n)。
堆排序的整体时间复杂度为 O(n log n),并且这个性能在最好、最坏和平均情况下都保持一致,非常稳定。
1.3.2 空间复杂度 O(1) 的由来:
堆排序的所有操作(交换、调整)都是在原数组上进行的,只需要固定数量的额外变量(如用于交换的临时变量 temp),因此是原地排序,空间复杂度为 O(1)。
1.4 使用场景
堆排序在以下场景中表现出色:
需要稳定的最坏情况性能:当无法承受快速排序最坏情况下O(n²)的时间复杂度时,堆排序的O(n log n)最坏情况性能是可靠的选择。
内存空间受限:由于是原地排序,空间复杂度为O(1),非常适合嵌入式系统等内存紧张的环境。
寻找Top K元素:不需要完全排序整个序列,只需找出最大或最小的K个元素。可以构建一个大小为K的小顶堆(找最大K个)或大顶堆(找最小K个),然后遍历剩余元素进行调整,效率很高。
实时数据流处理:堆结构适合处理不断产生新数据的场景,可以动态维护当前数据的极值或特定顺序。
然而,对于小规模数据,简单排序如插入排序可能因常数因子更小而实际更快。若需要稳定性(保持相等元素的原始顺序),则应选择归并排序等稳定算法。
1.5 代码实现
1.5.1 c 语言实现
以下是堆排序的一个典型C语言实现,包含了关键的堆调整(heapify)函数和排序主函数。
#include <stdio.h>// 交换数组中两个元素的值
void swap(int *a, int *b) {int temp = *a;*a = *b;*b = temp;
}// 堆调整函数(大顶堆)
// arr: 待调整的数组
// n: 当前堆的大小(即需要调整的数组长度)
// i: 待调整的根节点索引
void heapify(int arr[], int n, int i) {int largest = i; // 初始化最大元素为根节点int left = 2 * i + 1; // 左子节点索引int right = 2 * i + 2; // 右子节点索引// 如果左子节点存在且大于根节点if (left < n && arr[left] > arr[largest])largest = left;// 如果右子节点存在且大于当前最大节点if (right < n && arr[right] > arr[largest])largest = right;// 如果最大元素不是根节点,则需要交换并递归调整被破坏的子堆if (largest != i) {swap(&arr[i], &arr[largest]);heapify(arr, n, largest); // 递归调整受影响的子树}
}// 堆排序主函数
void heapSort(int arr[], int n) {// 1. 构建初始大顶堆// 从最后一个非叶子节点开始向上调整for (int i = n / 2 - 1; i >= 0; i--)heapify(arr, n, i);// 2. 逐个从堆顶提取元素for (int i = n - 1; i > 0; i--) {// 将当前堆顶元素(最大值)与末尾元素交换swap(&arr[0], &arr[i]);// 交换后,调整剩余的元素(从0到i-1),使其重新成为大顶堆heapify(arr, i, 0);}
}// 打印数组函数
void printArray(int arr[], int n) {for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");
}// 主函数测试
int main() {int arr[] = {12, 11, 13, 5, 6, 7};int n = sizeof(arr) / sizeof(arr[0]);printf("排序前的数组: \n");printArray(arr, n);heapSort(arr, n);printf("排序后的数组: \n");printArray(arr, n);return 0;
}
1.5.2 关键点解释
- heapify函数:这是堆排序的核心。它确保以节点 i为根的子树满足大顶堆的性质。通过比较根节点与其左右子节点,找到最大值,并在需要时进行交换和递归调整。
- heapSort函数:
* 建堆循环:for (int i = n / 2 - 1; i >= 0; i--)从最后一个非叶子节点开始,自底向上地调用 heapify,最终构建出整个大顶堆。
* 排序循环:for (int i = n - 1; i > 0; i--)每次循环将堆顶(最大值)与当前未排序序列的最后一个元素交换,然后对新的堆顶调用 heapify来调整剩余元素,使其恢复成大顶堆。
1.6 与常见排序算法比较
排序算法比较
| 算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 主要特点与适用场景 |
|---|---|---|---|---|---|
| 堆排序 | O(n log n) | O(n log n) | O(1) | 不稳定 | 最坏性能稳定,原地排序,适合内存受限和需要稳定最坏情况性能的场景 |
| 快速排序 | O(n log n) | O(n²) | O(log n) | 不稳定 | 平均性能极佳,是许多标准库的实现选择,但对初始数据敏感,最坏情况性能差 |
| 归并排序 | O(n log n) | O(n log n) | O(n) | 稳定 | 性能稳定,是稳定的O(n log n)排序,但需要O(n)额外空间,适合外部排序和对稳定性有要求的场景 |
| 插入排序 | O(n²) | O(n²) | O(1) | 稳定 | 对小规模或基本有序数据效率很高,常作为快速排序或归并排序的辅助排序 |
1.7 总结
总的来说,堆排序是一种基于堆数据结构的高效排序算法,其时间复杂度稳定在O(n log n),并且是原地排序,空间复杂度为O(1)。虽然在实际应用中可能不如快速排序快速,且是不稳定排序,但在需要保证最坏情况性能、内存空间有限或需要解决Top K问题等特定场景下,它依然是一个非常有价值的选择。理解堆排序对于深入掌握数据结构和算法设计思想具有重要意义。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/951608.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
:编排复杂的业务逻辑 - 教程)
第6章:工作流 (Workflow):编排复杂的业务逻辑 - 教程

2025年皮带称厂家权威推荐榜单:装载机秤/螺旋秤/定量给料机源头厂家精选

2025年led全彩显示屏制造商权威推荐榜单:led数字显示屏/工业显示屏/led异形显示屏源头厂家精选

全新升级!山海鲸4.6.3版本正式亮相

2025年中国玻璃钢管道厂家排名:高性价比玻璃钢管道厂家深度测评

刚刚 Cursor2.0炸裂发布!这3大亮点必学

2025年10月中型挖掘机品牌推荐:五强综合榜对比排行
![AT_arc195_d [ARC195D] Swap and Erase](http://pic.xiahunao.cn/AT_arc195_d [ARC195D] Swap and Erase)
AT_arc195_d [ARC195D] Swap and Erase

ubuntu24.04本地部署stable-diffusion-v1.5


单目相机Matlab参数标定

2025年10月大型挖掘机品牌实力榜:外资在华累计销量与口碑数据公开

2025年10月挖掘机厂家评测榜:五强国四排放对比排行

2025年10月小型挖掘机品牌推荐榜:五强评测对比解析

2025年10月挖掘机品牌推荐榜:迪万伦领衔全品类对比评测

Nginx作用以及应用场景

2025年10月中型挖掘机租赁品牌对比榜:性能与服务综合排名

2025年10月挖掘机厂家对比榜:迪万伦高寒施工机型与主流厂家排行

2025年10月中型挖掘机租赁品牌榜:高原施工场景下的五强对比与选择
