一、流式输出大模型调用结果
之前提到 Graph 的流式输出有几种不同的模式,这里展示 messages 模式,是用来监控大语言模型的 Token 记录的。
代码在 stream_mode_messages.py 文件中,内容如下:
# -*- coding: utf-8 -*-
import osfrom dotenv import load_dotenvfrom langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import InMemorySaver
from langchain_deepseek import ChatDeepSeekload_dotenv()
os.environ["DEEPSEEK_API_KEY"] = os.getenv("API_KEY", "")
llm = ChatDeepSeek(model="deepseek-chat")def call_model(state: MessagesState):response = llm.invoke(state["messages"])return {"messages": response}builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")graph = builder.compile()for chunk in graph.stream({"messages": [{"role": "user", "content": "湖南省会是哪里?"}]},stream_mode="messages"
):print(chunk)
运行后,如下图:

可以看到流式输出,但却不是严格按照一个个 token 输出。所以如果想做成本统计时,就不会很准,可以结合 LangSmith 完成成本统计,这也是体系化的好处。
二、大模型消息持久化
跟之前介绍 LangGraph 的 Agent 相似,Graph(图)也支持构建消息的持久化功能。并且也支持 checkpointer 构建短期记忆,以 store 构建长期记录。
无论短期记忆或是长期记忆,都可以临时保存到内存中或持久化到数据库中。不过短期记忆更倾向于通过对消息的短期存储,实现多轮对话的效果。而长期记忆则倾向于对消息长期存储后支持语义检索。
代码在 graph_checkpointer.py 文件中,内容如下:
# -*- coding: utf-8 -*-
import osfrom dotenv import load_dotenvfrom langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import InMemorySaver
from langchain_deepseek import ChatDeepSeekload_dotenv()
os.environ["DEEPSEEK_API_KEY"] = os.getenv("API_KEY", "")
llm = ChatDeepSeek(model="deepseek-chat")def call_model(state: MessagesState):response = llm.invoke(state["messages"])return {"messages": response}builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)config = {"configurable": {"thread_id": "1"}
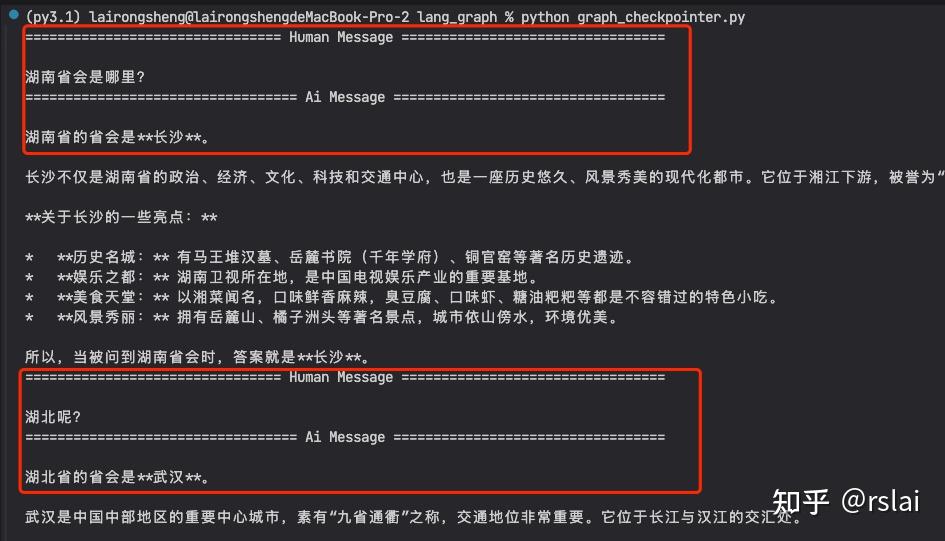
}for chunk in graph.stream({"messages": [{"role": "user", "content": "湖南省会是哪里?"}]},config,stream_mode="values"
):chunk["messages"][-1].pretty_print()for chunk in graph.stream({"messages": [{"role": "user", "content": "湖北呢?"}]},config,stream_mode="values"
):chunk["messages"][-1].pretty_print()
运行后,如下图:
三、Human-In-Loop 人类干预
在 LangGraph 中也可以通过中断任务,等待确认的方式,来实现干预,这样能减少由于大语言模型的不稳定给任务带来的影响。
具体实现人类干预时,需要注意以下几点:
- 必须指定一个 checkpointer 短期记忆,否则无法保存任务状态。
- 在执行 Graph 任务时,必须指定一个带有 thread_id 的配置项,指定线程ID。之后才能通过线程ID,指定恢复线程;
- 在执行任务过程中,通过 interrupt() 方法,中断任务,等待确认;
- 在人类确认之后,使用 Graph 提交一个 resume=True 的 Command 指令,恢复任务,并继续进行。
这种实现方式,在之前介绍 LangGraph 构建单 Agent 时已经介绍过,不过,结合 Graph 的 State,在多个 Node 之前进行复杂控制,这样更能体现出人类监督的价值。
例如,下面的案例可以实现这样一种典型的人类确认:
代码在 human_in_loop.py 文件中,内容如下:
# -*- coding: utf-8 -*-
# 构建一个带有 Human_In_Loop 的图
import osfrom dotenv import load_dotenv
from operator import addfrom langchain_core.messages import AnyMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langchain_deepseek import ChatDeepSeekload_dotenv()
os.environ["DEEPSEEK_API_KEY"] = os.getenv("API_KEY", "")
llm = ChatDeepSeek(model="deepseek-chat")from typing import Literal, TypedDict, Annotated, final
from langgraph.types import interrupt, Commandclass State(TypedDict):messages: Annotated[list[AnyMessage], add]def human_approval(state: State) -> Command[Literal["call_llm", END]]:is_approved = interrupt({"question": "是否同意调用大语言模型?"})if is_approved:return Command(goto="call_llm")else:return Command(goto=END)def call_llm(state: State) -> State:response = llm.invoke(state["messages"])return {"messages": [response]}builder = StateGraph(State)# Add the node to the graph in an appropriate location
# and connect it to the relevant nodes.
builder.add_node("human_approval", human_approval)
builder.add_node("call_llm", call_llm)builder.add_edge(START, "human_approval")checkpointer = InMemorySaver()graph = builder.compile(checkpointer=checkpointer)from langchain_core.messages import HumanMessage# 提交任务,等待确认
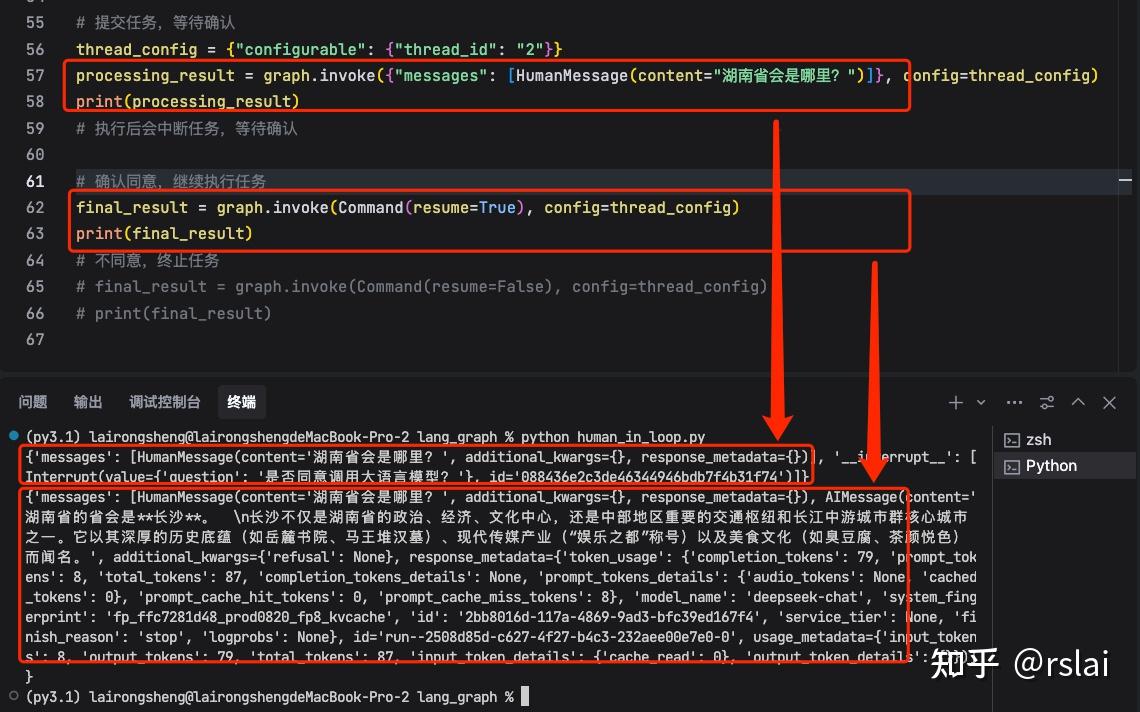
thread_config = {"configurable": {"thread_id": "2"}}
processing_result = graph.invoke({"messages": [HumanMessage(content="湖南省会是哪里?")]}, config=thread_config)
print(processing_result)
# 执行后会中断任务,等待确认# 确认同意,继续执行任务
final_result = graph.invoke(Command(resume=True), config=thread_config)
print(final_result)
# 不同意,终止任务
# final_result = graph.invoke(Command(resume=False), config=thread_config)
# print(final_result)
运行后,如下图:
注意:
- 任务中断和恢复,需要保持相同的 thread_id。通常应用当中都会单独生成一个随机的 thread_id,保证唯一的同时,防止其他任务干扰;
- interrupt() 方法中断任务的时间不能过长,过长了之后就无法恢复任务了;
- 任务确认时,Command 中传递的 resume 可以是简单的 True 或 False,也可以是一个字典。通过字典可以进行更多的判读。
四、Time Travel 时间回溯
由于大语言模型回答的不确定性,基于大语言模型构建的应用,也是充满不确定性的。而对于这种不确定性的系统,就有必要进行更精确的检查。当某一个步骤出现问题时,才能及时发现问题,并从发现问题的那个步骤进行重演。为此,LangGraph 提供了 Time Travel (时间回溯)功能,可以保存 Graph 的运行过程,并可以手动指定从 Graph 的某一个 Node 开始进行重演。
具体实现时,需要注意以下几点:
- 在运行 Graph 时,需要提供初始的输入消息;
- 运行时,指定 thread_id(线程ID)。并且要基于这个线程ID,再指定一个 checkpoint(检查点)。执行后将在每一个 Node 执行后,生成一个 check_point_id;
- 指定 thread_id 和 check_point_id,进行任务重演。重演前,可以选择更新 state,当然如果没问题,也可以不指定。
代码在 time_travel.py 文件中,内容如下:
# -*- coding: utf-8 -*-
# 构建一个图。图中两个步骤:1、让大模型推荐一个有名的作家。2、让大模型用推荐作家的风格写一个100字的文章
import osfrom dotenv import load_dotenvfrom typing import TypedDict
from typing_extensions import NotRequired
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langchain_deepseek import ChatDeepSeekload_dotenv()
os.environ["DEEPSEEK_API_KEY"] = os.getenv("API_KEY", "")
llm = ChatDeepSeek(model="deepseek-chat")class State(TypedDict):author: NotRequired[str]joke: NotRequired[str]def author_node(state: State) -> State:print(">>> author_node")prompt = "帮我推荐一位受人们欢迎的作家。只需要给出作家的名字即可。"author = llm.invoke(prompt)return {"author": author}def joke_node(state: State) -> State:print(">>> joke_node")prompt = f"请用作家:{state.get('author', '佚名')} 的风格,写一个100字以内的笑话。"joke = llm.invoke(prompt)return {"joke": joke}builder = StateGraph(State)
builder.add_node("author_node", author_node)
builder.add_node("joke_node", joke_node)builder.add_edge(START, "author_node")
builder.add_edge("author_node", "joke_node")
builder.add_edge("joke_node", END)checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
# graph# 正常执行一个图
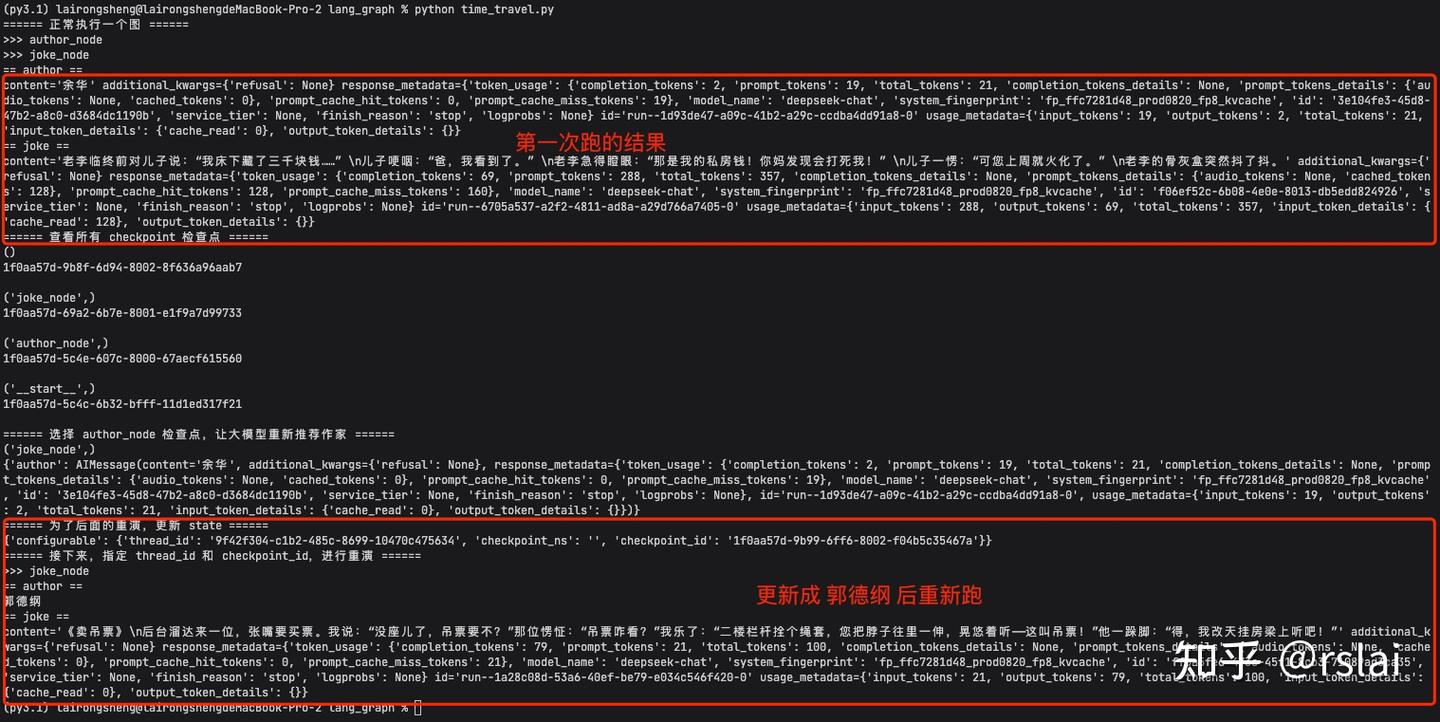
print("====== 正常执行一个图 ======")
import uuidconfig = {"configurable": {"thread_id": uuid.uuid4()}
}
state = graph.invoke({}, config=config)
print("== author ==")
print(state["author"])
print("== joke ==")
print(state["joke"])# 查看所有 checkpoint 检查点
print("====== 查看所有 checkpoint 检查点 ======")
states = list(graph.get_state_history(config))
for state in states:print(state.next)print(state.config["configurable"]["checkpoint_id"])print()# 选定一个检查点。这里选择 author_node 检查点,让大模型重新推荐作家
print("====== 选择 author_node 检查点,让大模型重新推荐作家 ======")
selected_state = states[1]
print(selected_state.next)
print(selected_state.values)# 为了后面的重演,更新 state。可选步骤:
print("====== 为了后面的重演,更新 state ======")
new_config = graph.update_state(selected_state.config, values={"author": "郭德纲"})
print(new_config)# 接下来,指定 thread_id 和 checkpoint_id,进行重演
print("====== 接下来,指定 thread_id 和 checkpoint_id,进行重演 ======")
new_state = graph.invoke(None, config=new_config)
print("== author ==")
print(new_state["author"])
print("== joke ==")
print(new_state["joke"])
运行完后,如下图:



)






)
金字塔))







