基于模型的强化学习(Model-based RL)
无模型与有模型方法的比较
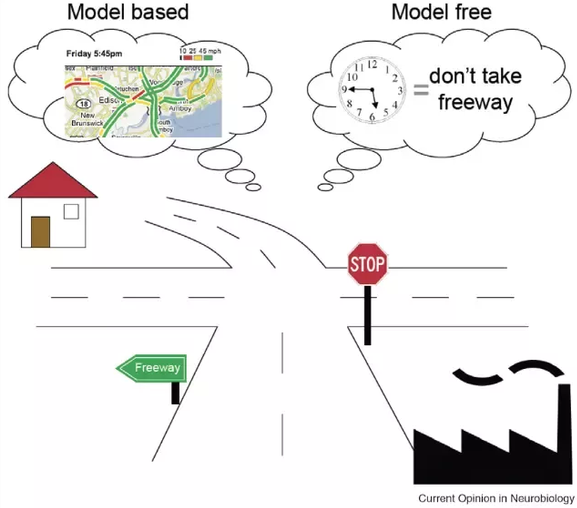
在此前介绍的无模型(Model-free, MF)强化学习中,我们无需了解环境的动态规律即可开始训练策略:
我们仅需采样状态转移 \((s, a, r, s')\) 来更新价值或策略网络。
这种方法的主要优点是:
- 智能体在执行时无需“思考”:只需选择具有最高 Q 值或策略网络输出概率最高的动作(反射式行为);
- 可以直接用于任意 MDP,无需事先知道环境的结构,可视为黑箱优化器。
然而,无模型方法的缺点是学习极其缓慢(样本复杂度高):由于没有任何先验假设,智能体必须完全依赖试错学习。
如果我们拥有一个环境模型(model),则可以提前规划(planning):
“如果我执行这个动作,会发生什么?”
通过这种方式,智能体能更高效地探索并避免显然错误的尝试。
这种利用环境模型进行决策的强化学习方法被称为 基于模型的强化学习(Model-based RL, MB)。
例如:
- 在国际象棋中,棋手会预先推演数步;
- 在即时战略游戏中,学习世界模型是战略的一部分;
- 动态规划(参见第 @sec-dp 节)就是典型的基于模型方法,因为它要求已知 \(p(s'|s,a)\) 与 \(r(s,a,s')\) 来求解贝尔曼方程。
本章将介绍几种常见的 Model-based RL 算法,包括:
- 模型预测控制(MPC);
- 世界模型(World Models);
- AlphaGo 系列方法。
我们首先区分两类模型强化学习:
- 规划算法(MPC);
- 基于模型增强的无模型方法(Dyna)。
在 AlphaGo 部分,我们还将讨论“已知模型 vs. 学习模型”的区别。
动态模型的学习(Learning a Dynamics Model)
在理论上,学习环境模型并不复杂。
我们只需通过随机策略或专家策略收集足够多的转移样本 \((s, a, r, s')\),并用监督学习的方式训练一个预测下一个状态和奖励的模型:

该模型被称为:
- 动态模型(dynamics model);
- 转移模型(transition model);
- 或 前向模型(forward model)。
它回答的问题是:
“如果我执行这个动作,会发生什么?”
模型可以是:
- 确定性(通常用神经网络建模);
- 随机性(使用高斯过程、混合密度网络或递归状态空间模型)。
任何类型的监督学习方法都可用于此任务。
一旦训练出足够精确的动态模型,就可以使用该模型生成虚拟轨迹(rollouts),即想象中的状态序列。
假设初始状态为 \(s_0\) 且策略为 \(\pi\),则可以通过模型不断推演:
在获得完整轨迹 \(\tau\) 后,可以计算回报 \(R(\tau)\),仿佛真实地与环境交互。
此时,模型本身就相当于环境,可以在该模型上优化策略。
在“想象”中训练(Training in Imagination)
- 使用随机或专家策略 \(b\) 收集转移样本 \((s, a, r, s')\);
- 构建数据集 \(\mathcal{D} = \{(s_k, a_k, r_k, s'_k)\}_k\);
- 使用监督学习训练动态模型 \(M(s, a) = (s', r)\);
- 使用训练好的模型生成虚拟轨迹 \(\tau\);
- 在这些轨迹上优化策略 \(\pi\)。
任何强化学习算法(包括 model-free 方法)都可以在模型上进行策略优化:
模型训练阶段的采样复杂度是主要瓶颈。
一旦模型收敛,策略优化阶段几乎不需要额外的环境交互。
对于那些物理仿真昂贵而模型预测极快的任务(如机器人控制),
该方法可显著降低实验成本。
局限性
基于模型的强化学习虽然高效,但存在两大挑战:
-
模型误差积累
模型预测误差会在长时间推演中不断放大,尤其在随机环境中;
对于长轨迹任务,误差可能导致策略训练方向完全错误。 -
数据覆盖不足
若收集的数据集未包含关键转移(例如稀疏奖励区域),
模型将无法准确预测这些关键状态,导致策略次优。
在极端情况下,为训练出高精度模型所需的数据量甚至超过直接训练一个无模型智能体。
因此,Model-based RL 通常结合 Model-free 元素,形成 混合型架构(如 Dyna、MBPO、Dreamer 等),
以平衡样本效率与稳定性。
)

)
)
)
)
)



![【光照】UnityURP[天空盒]原理与[动态天空盒]实现](http://pic.xiahunao.cn/【光照】UnityURP[天空盒]原理与[动态天空盒]实现)






![[DAX/数据分析表达式/Power BI] DAX 查询视图语言 = `Data Analysis eXpressions`(数据分析表达式) = 编程式数据分析语言](http://pic.xiahunao.cn/[DAX/数据分析表达式/Power BI] DAX 查询视图语言 = `Data Analysis eXpressions`(数据分析表达式) = 编程式数据分析语言)

