策略优化(TRPO 与 PPO)
信赖域策略优化(Trust Region Policy Optimization, TRPO)
基本原理
@Schulman2015 将自然梯度的思想推广到非线性函数逼近(如深度网络),提出了 TRPO。
该方法已在实践中被 PPO(Proximal Policy Optimization) 所取代,但其核心思想对理解现代策略优化方法极为重要。
设策略 \(\pi\) 的期望回报为:
其中 \(\rho_\pi(s)\) 为折扣访问频率:
@Kakade2002 证明:两个策略 \(\pi_\theta\) 与 \(\pi_{\theta_\text{old}}\) 的期望回报满足:
其中 \(A_{\pi_{\theta_\text{old}}}\) 为旧策略下的优势函数。
由于该期望依赖于新策略的状态分布,计算困难。
若假设新旧策略相差不大,可近似为:
这体现了自然梯度的思想:
希望找到既能提升回报、又能保持策略分布变化较小的更新方向。
定义代理目标函数(surrogate objective):
若 \(\pi_\theta\) 与 \(\pi_{\theta_\text{old}}\) 过于不同,则上述近似不再成立。
因此,需约束两者的差异,常用方法是限制它们的 KL 散度。
KL 散度约束形式
- 硬约束(constrained form):
- 软约束(regularized form):
两种形式皆旨在平衡性能提升与策略平稳性。
信赖域的概念

“信赖域(Trust Region)”指在参数空间中能进行较大步长更新、但在策略空间中保持变化较小的区域。
在该区域内,TRPO 可在单次更新中大幅提升策略性能而不致发散。
基于采样的表达式
为避免从未知策略采样,采用重要性采样(importance sampling)修正:
这便是 TRPO 的核心优化形式。
其理论保证:每次更新均单调提高策略性能(monotonic improvement)。
实际实现
利用拉格朗日乘子法:
展开后可得:
即自然梯度方向。
其中 \(F(\theta_\text{old})\) 为 Fisher 信息矩阵。
为避免显式求逆,@Schulman2015 采用共轭梯度法(Conjugate Gradient)近似求解。
小结
TRPO 的关键特性:
- 使用自然梯度更新;
- 每步保证单调性能改进;
- 对学习率不敏感。
缺点:
- 难以扩展至复杂网络(如 CNN、RNN);
- 实现复杂,依赖二阶优化;
- 无法轻松共享参数(例如在 Actor–Critic 框架中)。
近端策略优化(Proximal Policy Optimization, PPO)
@Schulman2017 提出 PPO,以解决 TRPO 的复杂性与适用性问题。
PPO 保留了 TRPO 的核心思想(限制策略变化),但采用一阶优化(如 Adam),实现简洁且性能更优。
剪切代理目标(Clipped Surrogate Objective)
TRPO 的代理目标为:
若不加约束,\(\rho_t(\theta)\) 可能剧烈变化。
PPO 引入剪切项(clip)抑制策略剧烈更新:
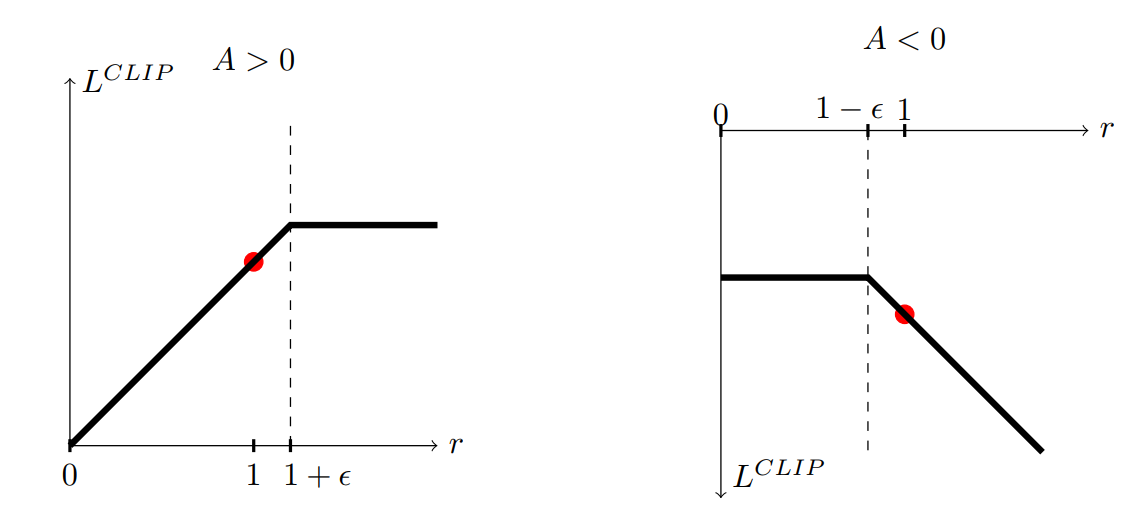
- 当 \(A_t>0\)(动作优于期望)时,增大其概率,但限制 \(\rho_t(\theta)\le1+\epsilon\);
- 当 \(A_t<0\)(动作劣于期望)时,减小其概率,但不低于 \(1-\epsilon\)。
最终目标取剪切前后较小值,确保优化过程保守稳定。
算法步骤
PPO 算法:
- 初始化策略网络 \(\pi_\theta\) 与价值网络 \(V_\varphi\)。
- 重复以下步骤直到收敛:
- 多个 actor 并行采样 \(T\) 步轨迹;
- 使用评论者计算每步的广义优势估计(GAE);
- 重复 \(K\) 个 epoch:
- 随机采样批量;
- 最大化剪切代理目标:\[L^{CLIP}(\theta) = \mathbb{E}[\min(\rho_t A_t, \text{clip}(\rho_t,1-\epsilon,1+\epsilon)A_t)] \]
- 更新评论者以最小化 TD 误差。
特点与优势
- 简单稳定:仅使用一阶优化(Adam);
- 高效:每批样本可多次复用;
- 通用性强:适用于 CNN、RNN 等复杂结构;
- 表现优异:在 Atari、MuJoCo 等任务上达 SOTA。
缺点:
- 无理论收敛保证;
- 需调节超参数 \(\epsilon\)。
PPO 已成为连续控制与通用强化学习任务的默认选择。
推荐阅读
- OpenAI 官方解读:https://blog.openai.com/openai-baselines-ppo
- TRPO 解析:https://www.depthfirstlearning.com/2018/TRPO
- PPO 理论与可视化讲解视频:https://www.youtube.com/watch?v=jwSbzNHGflM
)
)
)



![【光照】UnityURP[天空盒]原理与[动态天空盒]实现](http://pic.xiahunao.cn/【光照】UnityURP[天空盒]原理与[动态天空盒]实现)






![[DAX/数据分析表达式/Power BI] DAX 查询视图语言 = `Data Analysis eXpressions`(数据分析表达式) = 编程式数据分析语言](http://pic.xiahunao.cn/[DAX/数据分析表达式/Power BI] DAX 查询视图语言 = `Data Analysis eXpressions`(数据分析表达式) = 编程式数据分析语言)





