实用指南:【论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合】
论文阅读 | PR 2024 |ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合
- 1.摘要&&引言
- 2.方法
- 2.1 架构
- 2.2 双模态特征融合(DMFF)
- 2.2.1 跨模态特征增强(CFE)
- 2.2.2 空间特征压缩(SFS)
- 2.2.3 迭代跨模态特征增强(ICFE)
- 2.2.4 检测头的融合模式
- 3.实验
- 3.1 数据集与评估指标
- 3.1.1 数据集
- 3.1.2 评估指标
- 3.2 实现细节
- 3.2.1 框架与硬件
- 3.2.2 训练配置
- 3.2.3 基线设置
- 3.3 消融实验
- 3.3.1 残差连接可学习参数
- 3.3.2 单/双模态 CFE 效果
- 3.3.3 模块堆叠数量
- 3.3.4 迭代次数影响
- 3.3.5 空间压缩方法
- 3.3.6 输入模态鲁棒性
- 3.3.7 主干网络兼容性
- 3.4 与 SOTA 技巧对比
- 3.4.1 KAIST 数据集
- 3.4.2 FLIR 数据集
- 3.4.3 VEDAI 内容集
- 3.5 定性分析
- 3.6 局限性
- 4. 结论

题目:ICAFusion: Iterative cross-attention guided featurefusionfor multispectral object detection
会议:Pattern Recognition(PR)
论文:https://doi.org/10.1016/j.patcog.2023.109913
代码:https://github.com/chanchanchan97/ICAFusion
年份:2024
1.摘要&&引言
多光谱图像的有效特征融合在多光谱目标检测中起着至关重要的作用。以往研究表明,使用卷积神经网络进行特征融合是奏效的,但由于其在局部范围特征交互方面的固有缺陷,这些途径对图像错位敏感,导致性能下降。
为克服这一疑问,本文提出了一种新型的双交叉注意力Transformer特征融合框架,用于建模全局特征交互并同时捕获跨模态的互补信息。该框架利用查询引导的交叉注意力机制增强目标特征的判别力,从而提升性能。
然而,堆叠多个 Transformer 块进行特征增强会导致大量参数和高空间复杂度。为此,受人类复习知识过程的启发,本文提出了一种迭代交互机制,在分块多模态 Transformer 之间共享参数,降低模型复杂度和计算成本。所提方法具有通用性和有效性,可集成到不同的检测框架中,并与不同的主干网络配合使用。
在 KAIST、FLIR 和 VEDAI数据集上的实验结果表明,所提方法实现了优异的性能和更快的推理速度,适用于各种实际场景。
总结起来,我们的主要贡献如下:
- 提出了一种新颖的双交叉注意力特征融合方法,用于多光谱目标检测,同时聚合来自 RGB 和热图像的互补信息。
- 设计了一种适用于高效多光谱特征融合的迭代学习策略,在不增加可学习参数的情况下进一步提升模型性能。
- 所提出的特征融合方法具有通用性和有效性,许可插入不同的主干网络并配备不同的检测框架。
- 所提出的 CFE/ICFE 模块可以与不同的输入图像模态配合使用,当其中一个模态缺失或质量较差时提供了可行的解决方案。
- 所提出的方法在 KAIST [12]、FLIR [13] 和 VEDAI [14] 数据集上实现了最先进的结果,同时获得了十分快的推理速度。
2.方法
2.1 架构
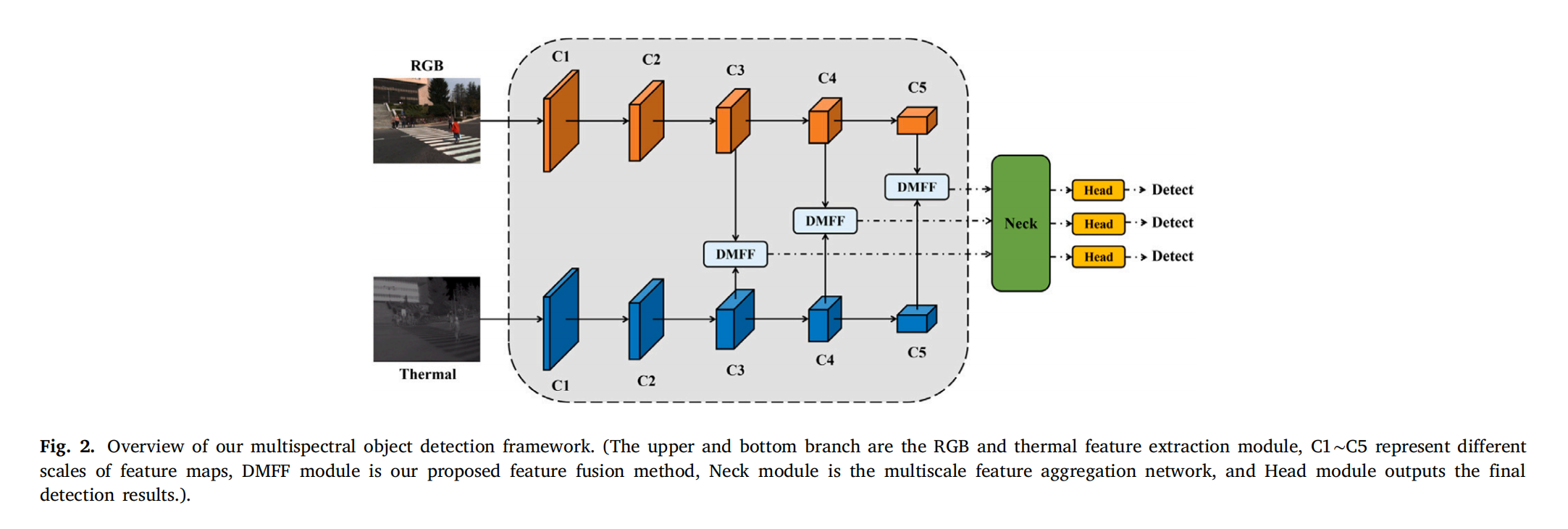
图2. 大家的多光谱目标检测框架概述。(上分支和下分支分别为RGB和热特征提取模块,C1∼C5代表不同尺度的特征图,DMFF模块是我们提出的特征融合方法,Neck模块是多尺度特征聚合网络,Head模块输出最终的检测结果。)
如图 2 所示,所提方法是一种双分支主干网络,专为从 RGB-热图像对中提取特征而设计。我们的方法主要包括三个阶段:单模态特征提取、双模态特征融合以及检测颈部和头部。
单模态特征提取
起初分别用于 RGB 和热图像(如公式(1)所示):
F R i = Ψ backbone ( I R ; θ R ) , F T i = Ψ backbone ( I T ; θ T ) F_{R}^{i} = \Psi_{\text{backbone}}(I_{R}; \theta_{R}), \quad F_{T}^{i} = \Psi_{\text{backbone}}(I_{T}; \theta_{T})FRi=Ψbackbone(IR;θR),FTi=Ψbackbone(IT;θT)
其中,
- F R i F_{R}^{i}FRi、F T i ∈ R W × H × C F_{T}^{i} \in \mathbb{R}^{W \times H \times C}FTi∈RW×H×C分别表示 RGB 和热分支第i ii 层(i = 3 , 4 , 5 i=3,4,5i=3,4,5)的特征图
- H HH、W WW 和 C CC分别表示特征图的高度、宽度和通道数
- I R I_{R}IR、I T ∈ R W × H × C I_{T} \in \mathbb{R}^{W \times H \times C}IT∈RW×H×C表示输入的 RGB 和热图像
- Ψ backbone \Psi_{\text{backbone}}Ψbackbone表示具有参数θ R \theta_{R}θR 和 θ T \theta_{T}θT的特征提取函数,分别用于 RGB 和热分支
在通用目标检测中,VGG16 [34]、ResNet [35] 和 CSPDarkNet [36] 通常用作函数Ψ backbone \Psi_{\text{backbone}}Ψbackbone。在特征提取阶段,多尺度特征通常用于捕获不同大小的目标。
双模态特征融合
给定 F R i F_{R}^{i}FRi 和 F T i F_{T}^{i}FTi的特征图,在多光谱目标检测中需要跨模态特征融合来聚合不同分支的特征(如公式(2)所示):
F R + T i = Φ fusion ( F R i ; F T i ; θ f ) F_{R+T}^{i} = \Phi_{\text{fusion}}(F_{R}^{i}; F_{T}^{i}; \theta_{f})FR+Ti=Φfusion(FRi;FTi;θf)
其中,
- F R + T i ∈ R W × H × C F_{R+T}^{i} \in \mathbb{R}^{W \times H \times C}FR+Ti∈RW×H×C 表示第 i ii层的融合特征
- Φ fusion ( ⋅ ) \Phi_{\text{fusion}}(\cdot)Φfusion(⋅)表示具有参数θ f \theta_{f}θf的特征融合函数
鉴于以往研究 [5,19] 探索了不同的融合架构,并验证了中途融合优于其他融合方法,我们将中途融合作为默认设置,并融合来自卷积层 C3∼C5 的多模态特征(如图 2 所示)。通常,加法操作或 NIN 融合 [17] 常用作特征融合函数Φ fusion ( ⋅ ) \Phi_{\text{fusion}}(\cdot)Φfusion(⋅)。在本文中,提出了一种双交叉注意力特征融合 Transformer 来建模Φ fusion ( ⋅ ) \Phi_{\text{fusion}}(\cdot)Φfusion(⋅),这将在 3.2 节中描述。
检测颈部和头部
最后,来自 { F R + T i } i = 1 L \{F_{R+T}^{i}\}_{i=1}^{L}{FR+Ti}i=1L的特征图被馈送到检测颈部进行多尺度特征融合,之后传递到检测头部进行后续的分类和回归(如公式(3)所示):
[ D cls , D bbox ] = ϕ head ( ϕ neck ( { F R + T i } i = 1 L ) ; θ h ) \left[D_{\text{cls}}, D_{\text{bbox}}\right] = \phi_{\text{head}}\left(\phi_{\text{neck}}\left(\{F_{R+T}^{i}\}_{i=1}^{L}\right); \theta_{h}\right)[Dcls,Dbbox]=ϕhead(ϕneck({FR+Ti}i=1L);θh)
其中,
- ϕ neck \phi_{\text{neck}}ϕneck 和 ϕ head \phi_{\text{head}}ϕhead分别表示多尺度特征聚合和检测头部函数
- FPN [37] 和 PANet [38] 通常用作函数ϕ neck \phi_{\text{neck}}ϕneck来增强特征的语义表达和定位能力
- ϕ head \phi_{\text{head}}ϕhead则充当具有参数θ h \theta_{h}θh的分类和边界框回归角色,如 YOLO [36] 和 FCOS [39] 的检测头部
为了公平比较,我们采用原始论文中的检测颈部和头部的默认设置。
2.2 双模态特征融合(DMFF)
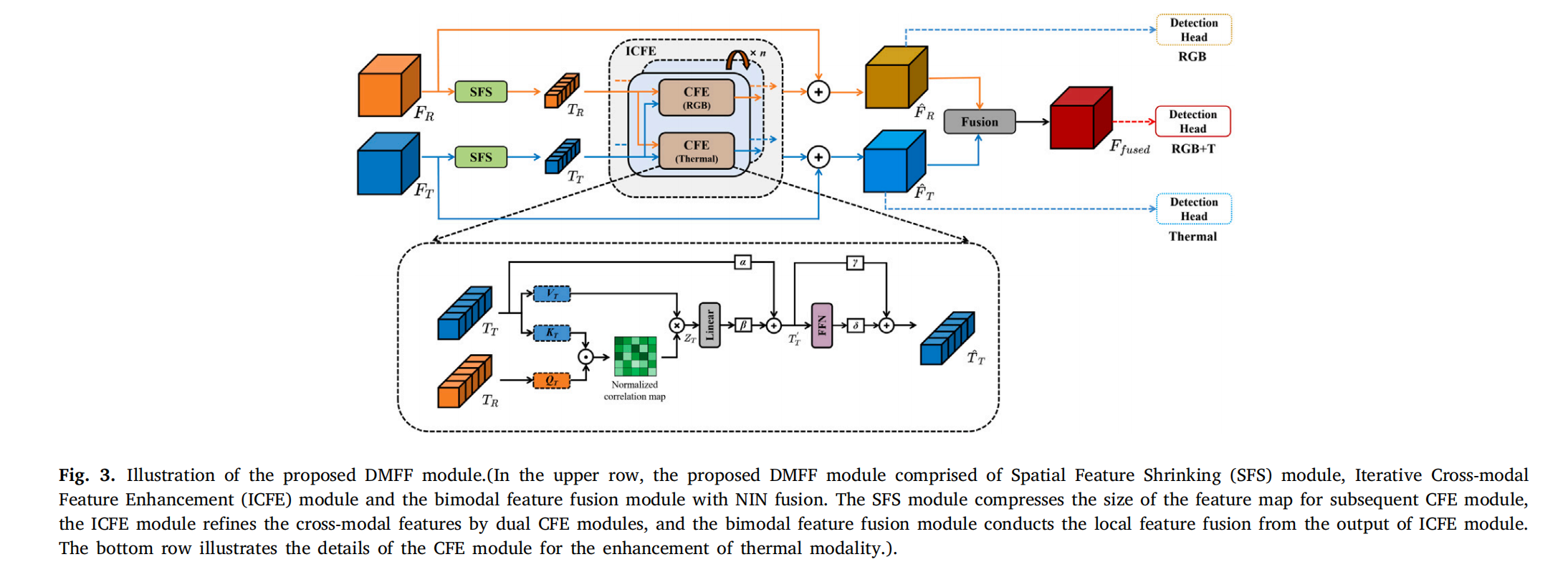
图3. 所提出的DMFF模块示意图。(在上排中,所提出的DMFF模块由空间特征压缩(SFS)模块、迭代跨模态特征增强(ICFE)模块和带有NIN融合的双峰特征融合模块组成。SFS模块为后续的CFE模块压缩特征图的尺寸,ICFE模块通过双CFE模块细化跨模态特征,双峰特征融合模块对ICFE模块的输出进行局部特征融合。下排展示了用于热模态增强的CFE模块的细节。)
图 3 展示了我们的双模态特征融合(DMFF)模块的结构,主要包含三个组件:空间特征压缩(SFS)模块、迭代跨模态特征增强(ICFE)模块和带有 NIN 融合的双峰特征融合模块。这些模块将在以下部分详细介绍。
2.2.1 跨模态特征增强(CFE)
与以往捕获不同模态局部特征的研究不同,所提出的 CFE 模块使单模态能够从全局视角学习来自辅助模态的更多互补信息。该模块不仅检索 RGB 和热模态之间的互补关系,还克服了跨模态特征长程依赖建模的不足。给定输入特征图F R F_{R}FR 和 F T ∈ R H × W × C F_{T} \in \mathbb{R}^{H \times W \times C}FT∈RH×W×C,首先将每个特征图展平为标记集,并添加可学习的位置嵌入(维度为H × W × C H \times W \times CH×W×C的可训练参数)以编码空间信息。随后,得到带有位置嵌入的标记集T R , T T ∈ R H × W × C T_{R}, T_{T} \in \mathbb{R}^{H \times W \times C}TR,TT∈RH×W×C作为 CFE 模块的输入。由于 RGB-热图像对通常不完全对齐,大家采用双 CFE 模块分别获取 RGB 和热特征的互补信息(两个模块不共享参数)。如图 3(底部)所示的热分支 CFE 模块流程如下(公式 4):
T ^ T = F C F E − T ( { T R , T T } ) \hat{T}_{T} = F_{CFE-T}\left( \{T_{R}, T_{T}\} \right)T^T=FCFE−T({TR,TT})
其中,T R T_{R}TR 和 T T T_{T}TT表示输入热模块的 RGB 和热特征标记,T ^ T \hat{T}_{T}T^T为增强后的热特征,F C F E − T ( ⋅ ) F_{CFE-T}(\cdot)FCFE−T(⋅)为热分支的 CFE 模块。
CFE 模块细节
标记投影:热模态标记T T T_{T}TT被投影为查询矩阵V T V_{T}VT 和键矩阵 K T ∈ R H × W × C K_{T} \in \mathbb{R}^{H \times W \times C}KT∈RH×W×C(公式 5),RGB 模态标记T R T_{R}TR被投影为查询矩阵Q R ∈ R H × W × C Q_{R} \in \mathbb{R}^{H \times W \times C}QR∈RH×W×C:
V T = T T W V , K T = T T W K , Q R = T R W Q ,VTKTQR=TTWV,=TTWK,=TRWQ,
其中 W V , W K , W Q ∈ R C × C W^{V}, W^{K}, W^{Q} \in \mathbb{R}^{C \times C}WV,WK,WQ∈RC×C为权重矩阵。跨模态相关性计算:通过点积构建相关矩阵,并应用 softmax 归一化相似度分数(公式 6):
Z T = softmax ( Q R K T ⊤ D K ) ⋅ V T Z_{T} = \text{softmax}\left( \frac{Q_{R} K_{T}^{\top}}{\sqrt{D_{K}}} \right) \cdot V_{T}ZT=softmax(DKQRKT⊤)⋅VT
其中 D K D_{K}DK为维度缩放因子。随后,通过线性变换生成增强特征T T ′ T_{T}'TT′(公式 7):
T T ′ = α ⋅ Z T W O + β ⋅ T T T_{T}' = \alpha \cdot Z_{T} W^{O} + \beta \cdot T_{T}TT′=α⋅ZTWO+β⋅TT
其中 W O ∈ R C × C W^{O} \in \mathbb{R}^{C \times C}WO∈RC×C为 FFN 层前的输出权重矩阵,α , β \alpha, \betaα,β为可学习参数。残差连接与多头机制:增强特征通过残差连接(公式 8)和 FFN 进一步细化(受 [40] 启发):
T ^ T = γ ⋅ T T ′ + δ ⋅ FFN ( T T ′ ) \hat{T}_{T} = \gamma \cdot T_{T}' + \delta \cdot \text{FFN}(T_{T}')T^T=γ⋅TT′+δ⋅FFN(TT′)
其中 γ , δ \gamma, \deltaγ,δ为初始化为 1 的可学习参数。多头交叉注意力机制(8 个并行头)使模型从多视角理解跨模态相关性。
RGB 分支增强
类似地,另一个 CFE 模块用于增强 RGB 分支特征(公式 9):
T ^ R = F C F E − R ( { T R , T T } ) \hat{T}_{R} = \mathcal{F}_{CFE-R}\left( \{T_{R}, T_{T}\} \right)T^R=FCFE−R({TR,TT})
与 CFT [10] 不同,本文采用双独立交叉注意力 Transformer,仅通过辅助模态查询计算相关性,降低了计算复杂度(见表 1)。
2.2.2 空间特征压缩(SFS)
尽管用于融合的初始特征图借助主干网络进行了下采样,但模型的参数和内存成本仍可能远超标准处理器的运行要求。为了在特征图中减少信息损失的同时降低后续模块的计算成本,我们在 CFE 模块前应用了 SFS 模块来压缩特征图。在该模块中,我们尝试了两种不同的卷积和池化操作方法,细节如下:
卷积操作:大家首先设计了一种基于卷积处理的降维方法(如公式(10)所示)。具体来说,依据重塑特征图的维度将空间信息转换到通道维度,再通过1 × 1 1 \times 11×1卷积压缩通道维度:
F conv = conv 1 × 1 ( Reshape ( F ) ) F_{\text{conv}} = \text{conv}_{1 \times 1}(\text{Reshape}(F))Fconv=conv1×1(Reshape(F))
其中,F FF表示输入特征图,F conv F_{\text{conv}}Fconv表示压缩后的特征图。
池化操作:平均池化和最大池化通过不同策略保留背景或纹理信息(如公式(12)所示)。受混合池化 [41] 启发,我们采用自适应加权聚合方法:
F a = AvgPooling ( F , S ) , F m = MaxPooling ( F , S ) , F o = λ ⋅ F a + ( 1 − λ ) ⋅ F m ,
其中,λ ∈ [ 0 , 1 ] \lambda \in [0, 1]λ∈[0,1]是可学习参数。
2.2.3 迭代跨模态特征增强(ICFE)
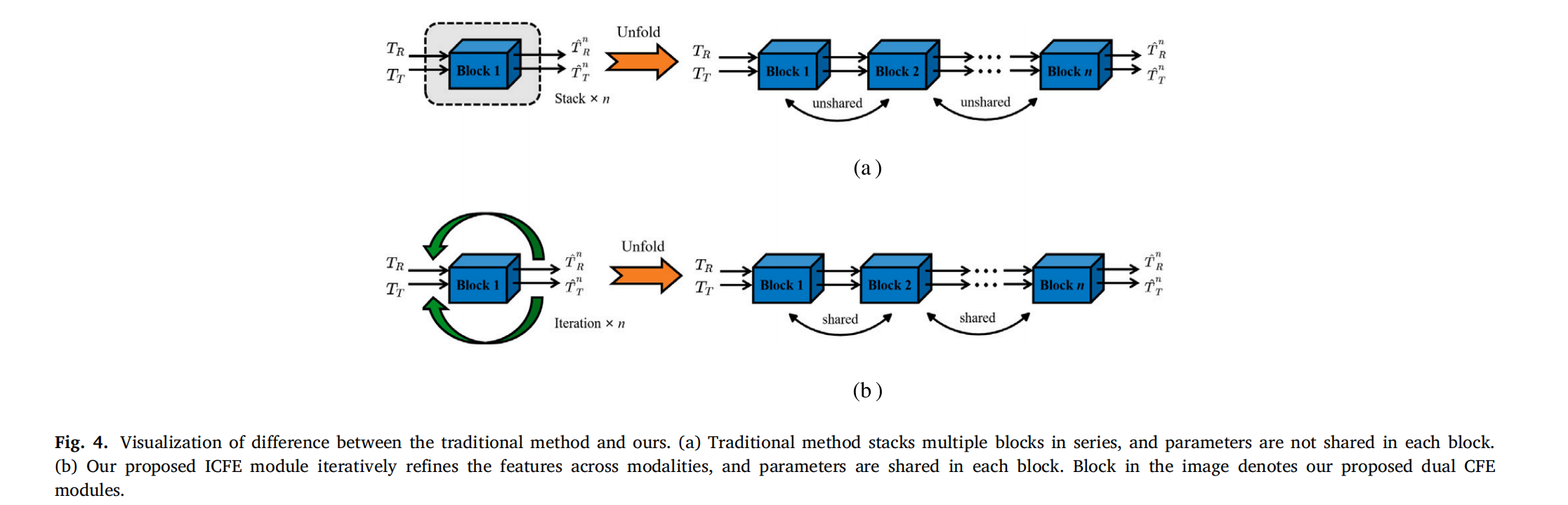
图4. 传统方式与我们技巧的差异可视化。(a) 传统技巧串联堆叠多个模块,且每个模块的参数不共享。(b) 我们提出的ICFE模块利用迭代方式跨模态细化特征,且每个模块共享参数。图中的“Block”表示我们提出的双CFE模块。
为增强对跨模态和模态内互补信息的记忆,我们提出 ICFE 模块(如图 4(b))。与传统堆叠模块(图 4(a))不同,ICFE 通过参数共享的迭代学习逐步细化特征:
{ T ^ R n , T ^ T n } = F ICFE ( { T R , T T } , n ) = F CFE ( ⋯ F CFE ( { T R , T T } ) ) ⏟ n 次迭代 ,
其中 F ICFE ( ⋅ ) \mathcal{F}_{\text{ICFE}}(\cdot)FICFE(⋅)集成两个 CFE 模块(分别用于 RGB 和热分支),每次迭代输出作为下一轮输入。最终特征图通过双线性插值恢复至原始尺寸。
2.2.4 检测头的融合模式
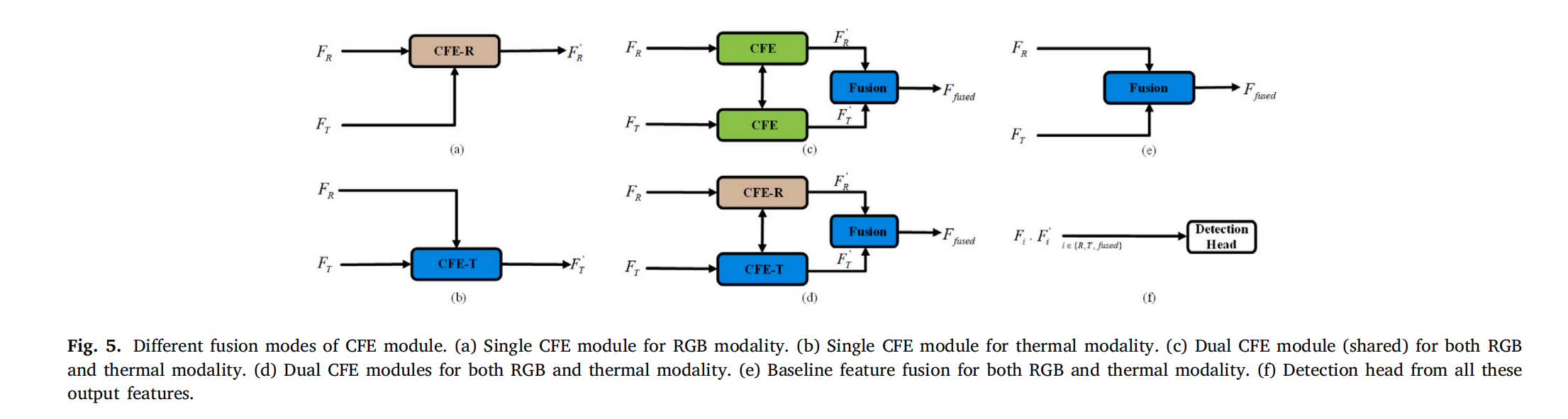
图 5. CFE 模块的不同融合模式。(a) 用于 RGB 模态的单个 CFE 模块。(b) 用于热模态的单个 CFE 模块。© 用于 RGB 和热模态的双 CFE 模块(参数共享)。(d) 用于 RGB 和热模态的双 CFE 模块(参数不共享)。(e) RGB 和热模态的基线特征融合模式。(f) 基于所有这些输出特征的检测头。
图 5 展示了四种融合模式的对比实验:
- 单模态输出(图 5(a)(b)):强制 CFE-R/CFE-T 分别从热/RGB 特征中提取互补信息。
- 双 CFE 共享参数(图 5©):共享 CFE 参数处理双模态输入。
- 双 CFE 独立参数(图 5(d)):为 RGB 和热分支分配独立 CFE 参数。
- 基线 NIN 融合(图 5(e)):采用 NIN [17] 的传统融合方法。
所有融合后的特征图(F i , F i ′ , i ∈ { R , T , fused } F_i, F_i', i \in \{R, T, \text{fused}\}Fi,Fi′,i∈{R,T,fused})均输入检测头(如图 5(f))。实验表明,即使单模态输入质量较差(如图 5©),交叉注意力机制仍能保证鲁棒性。
3.实验
3.1 内容集与评估指标
3.1.1 资料集
KAIST 数据集 [12]
多光谱行人检测基准资料集,囊括 8,963 对训练图像和 2,252 对测试图像(分辨率 640×512)。评估采用对数平均漏检率(M R − 2 MR^{-2}MR−2),使用清洗后的标注数据 [20,5]。FLIR 素材集 [13]
包含 5,142 对多光谱图像(4,129 训练/1,013 测试),目标类别为“行人”“汽车”“自行车”。采用对齐版本 [16],标注 3 类目标。VEDAI 内容集 [14]
航空图像信息集,含 1,268 对 RGB-红外图像(1024×1024 分辨率),标注 3,700+ 个车辆目标。采用水平框格式标注 [43]。
3.1.2 评估指标
- M R − 2 MR^{-2}MR−2:用于 KAIST,计算 9 个对数均匀采样 FPPI 值的平均漏检率(值越低越好)。
- AP/m A P mAPmAP:目标检测指标,IoU=0.5 阈值下计算平均精度,m A P mAPmAP为多类平均。
3.2 实现细节
3.2.1 框架与硬件
- 框架:PyTorch 1.7.1
- 硬件:Ubuntu 18.04,CPU i7-9700,64G RAM,Nvidia RTX 3090 24G GPU。
3.2.2 训练配置
- 优化器:SGD(初始学习率1.0 × 10 − 2 1.0 \times 10^{-2}1.0×10−2,动量 0.937,权重衰减 0.0005)。
- 数据增强:马赛克增强 + 随机翻转。
- 学习率策略:余弦退火,60 个 epoch。
3.2.3 基线设置
- 消融基线:YOLOv5 + NIN 融合 [17](检测头/颈部沿用原始设计)。
3.3 消融实验
3.3.1 残差连接可学习参数
表 2 显示双分支可学习参数使 KAIST 的M R MRMR从 7.86% 降至 7.63%,FLIR 的m A P 50 mAP_{50}mAP50从 77.1% 提升至 77.5%。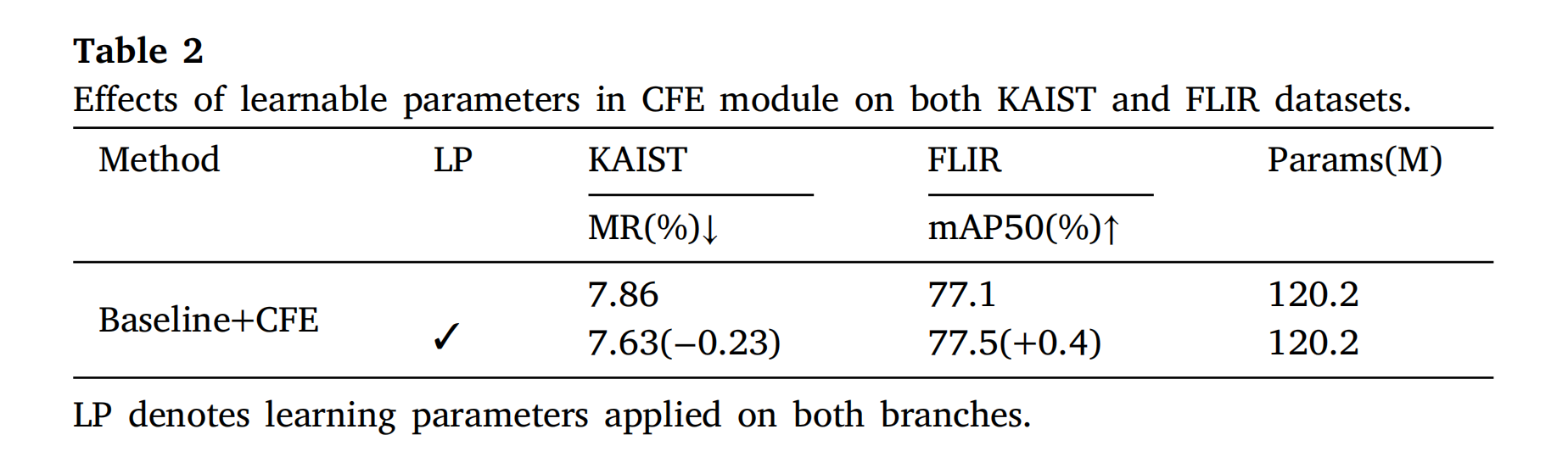
3.3.2 单/双模态 CFE 效果
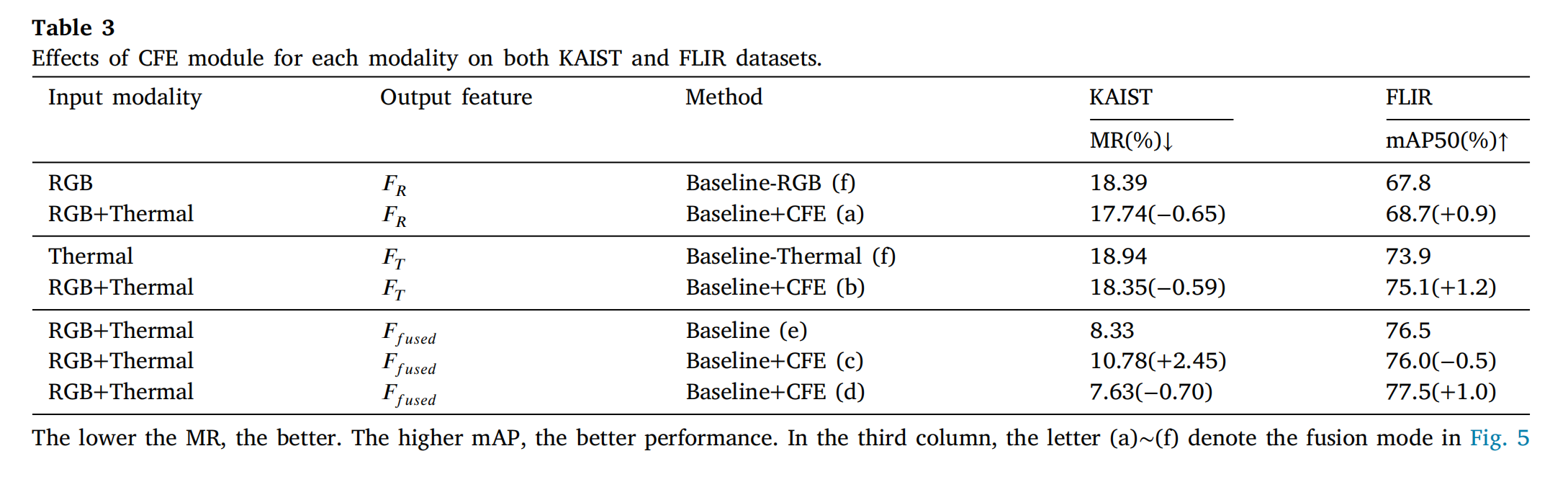
MR值越低越好。mAP值越高,性能越好。在第三列中,字母(a)~(f)表示图5中的融合模式。
表 3 对比不同模式:
- 单模态增强(图 5(a)(b)):KAISTM R MRMR降 0.59%~0.65%,FLIRm A P 50 mAP_{50}mAP50提 0.9%~1.2%。
- 双模态融合(图 5(d)):综合性能最优,KAISTM R MRMR降 0.70%,FLIRm A P 50 mAP_{50}mAP50提 1.00%。
3.3.3 模块堆叠数量
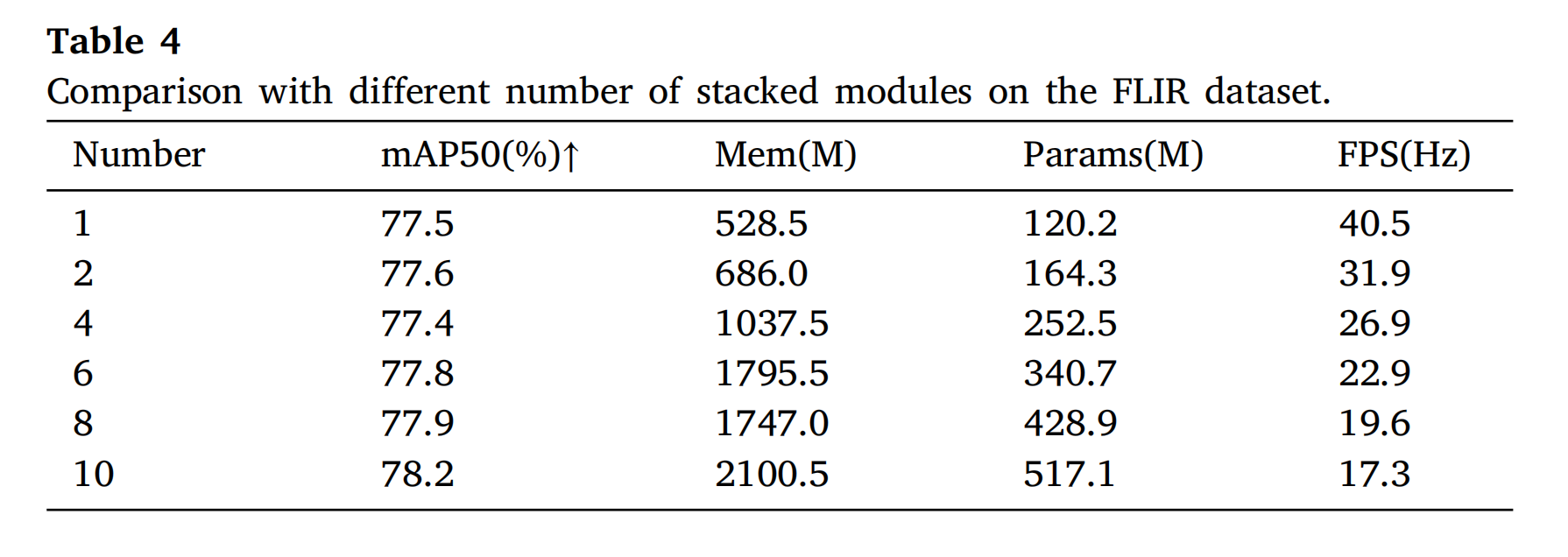
表 4 显示堆叠 10 个 CFE 模块时,参数/CPU 内存增 4 倍,推理速度从 40.5 Hz 降至 17.3 Hz,m A P mAPmAP仅增 0.70%(图 6右)。
3.3.4 迭代次数影响
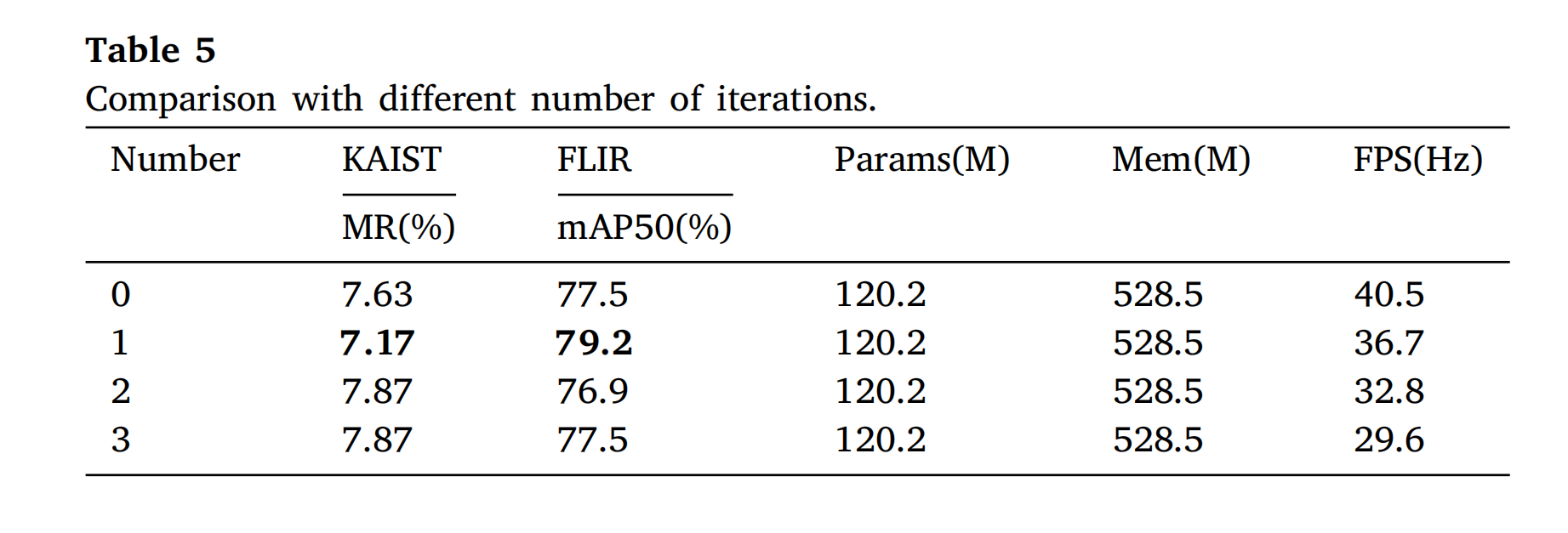
表 5 表明:1 次迭代即可使 KAISTM R MRMR从 7.63% 降至 7.17%,FLIRm A P 50 mAP_{50}mAP50从 77.5% 提至 79.2%(图 6左)。
3.3.5 空间压缩方法
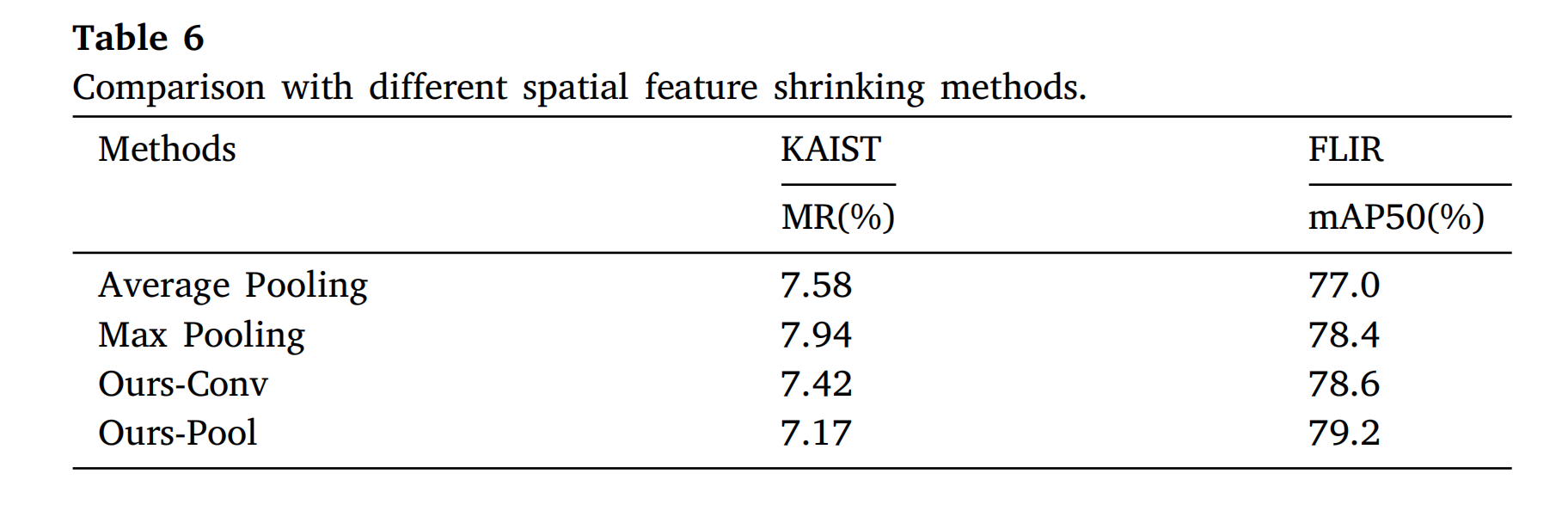
表 6 对比下采样方法:混合池化(Ours-Pool)在 KAIST/FLIR 上分别达到M R = 7.17 % MR=7.17\%MR=7.17% 和 m A P 50 = 79.20 % mAP_{50}=79.20\%mAP50=79.20%。
3.3.6 输入模态鲁棒性
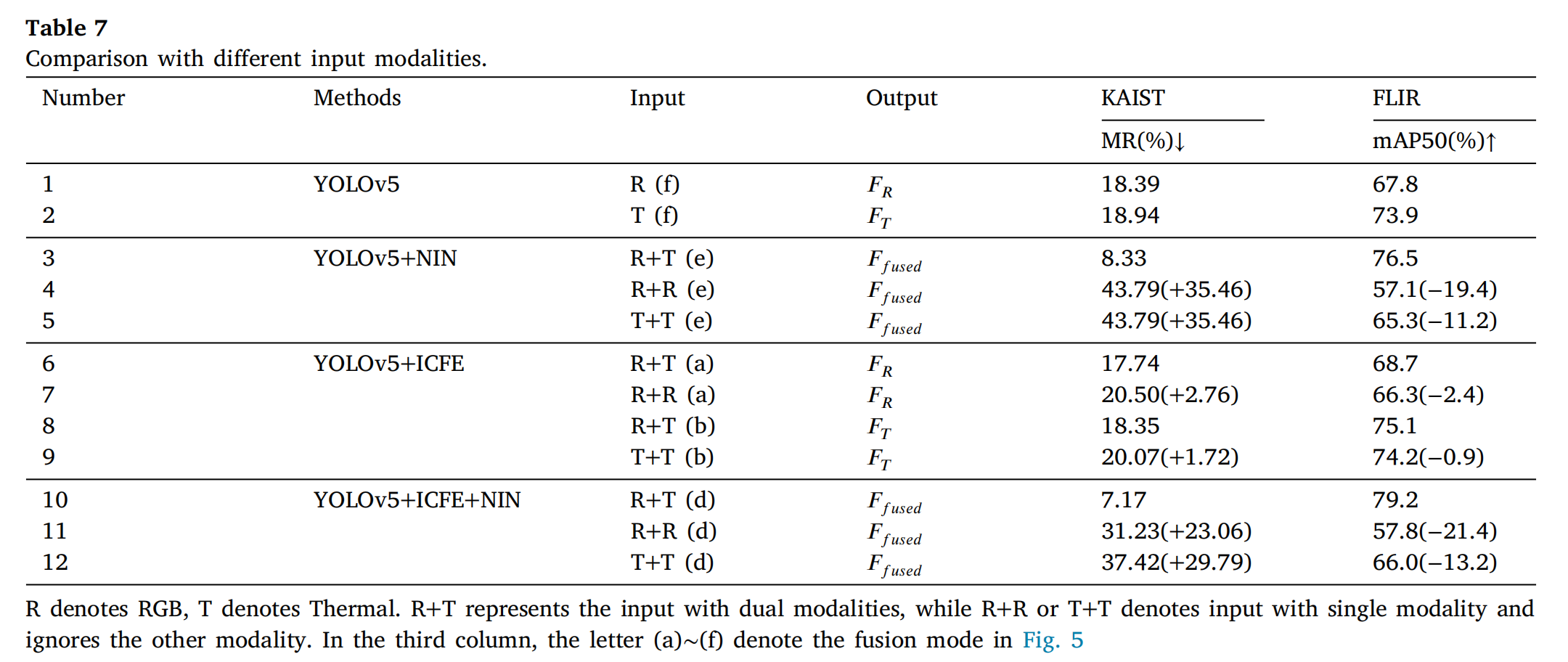
R表示RGB,T表示热成像。R+T代表双模态输入,而R+R或T+T表示单模态输入(忽略另一模态)。在第三列中,字母(a)~(f)对应图5中的融合模式。
表 7 验证:
- 单模态输入:YOLOv5+ICFE 性能接近双模态基线。
- 同模态输入:ICFE 在 R+R/T+T 场景下仍保持鲁棒性,NIN 融合性能骤降。
3.3.7 主干网络兼容性
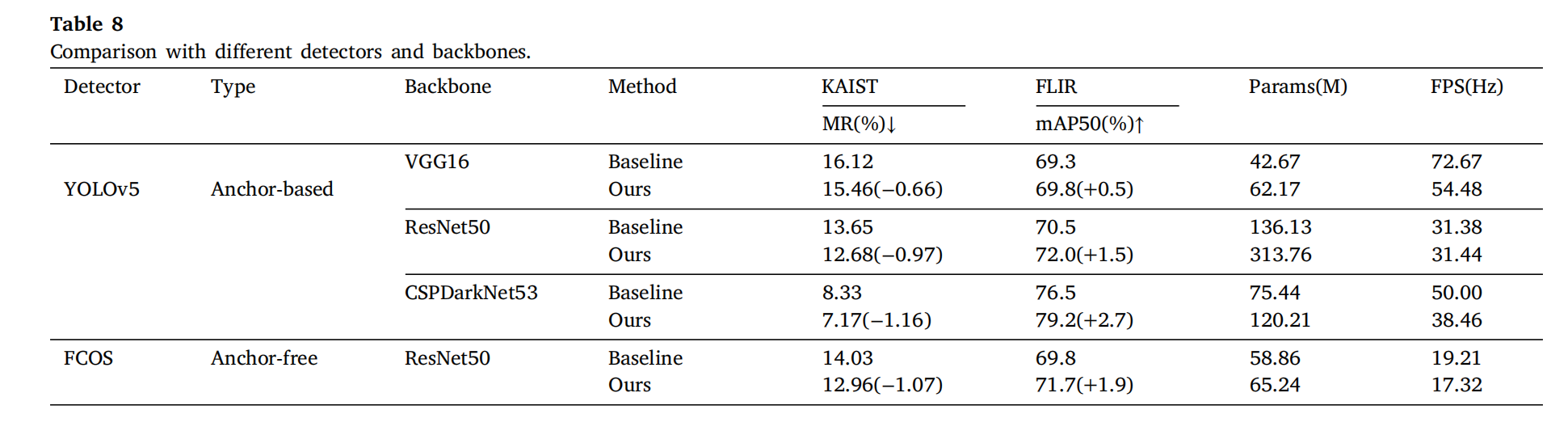
表 8 表现 DMFF 在 YOLOv5(VGG16/ResNet50/CSPDarkNet53)和 FCOS 上均提升性能(KAISTM R MRMR降 0.66%~1.16%)。
3.4 与 SOTA 方法对比
3.4.1 KAIST 数据集
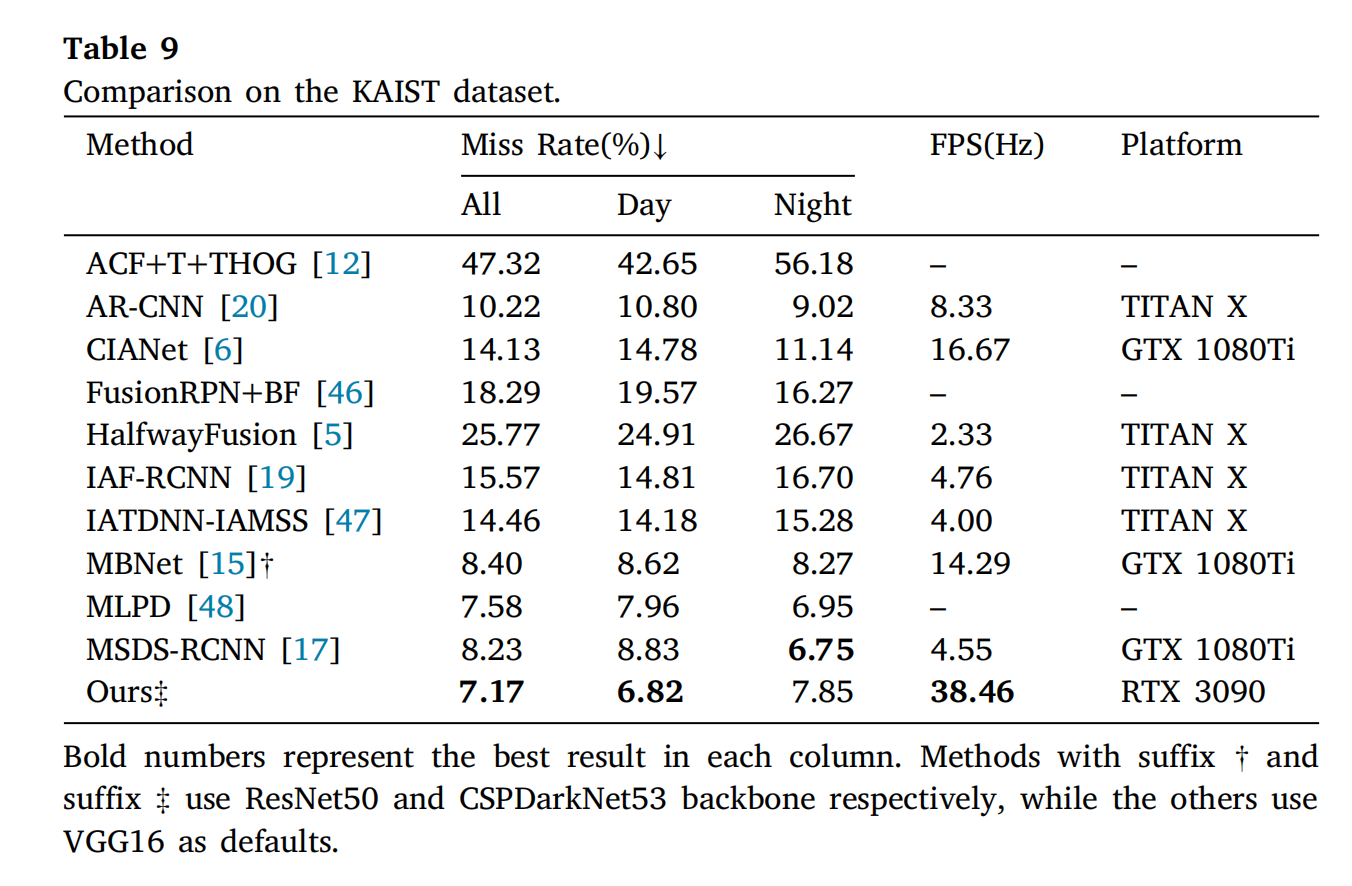
粗体数字表示每列中的最佳结果。带有后缀†和后缀‡的办法分别利用ResNet50和CSPDarkNet53主干网络,而其他方法默认启用VGG16。
表 9 显示:
- 白天子集 M R = 6.82 % MR=6.82\%MR=6.82%(最低漏检率)。
- 实时推理速度 38.46 Hz。
3.4.2 FLIR 数据集
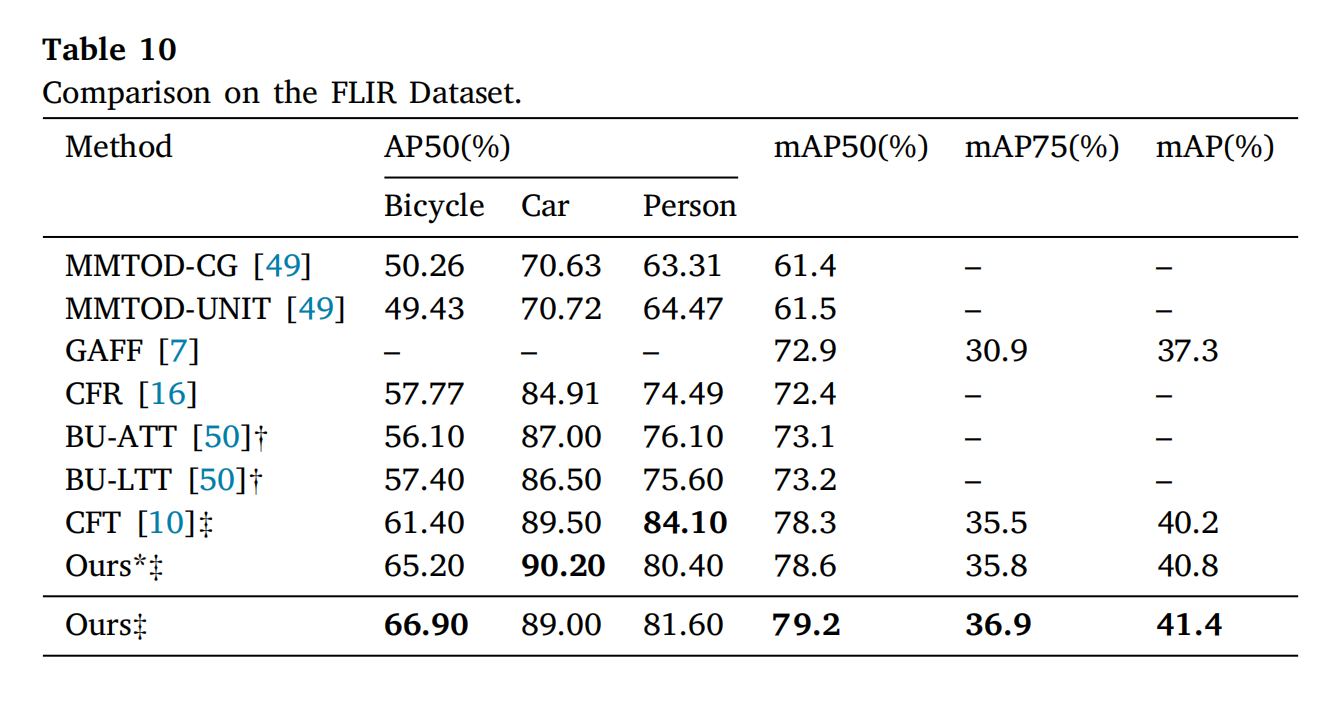
表 10 刷新记录:m A P 50 = 79.20 % mAP_{50}=79.20\%mAP50=79.20%,m A P = 41.4 % mAP=41.4\%mAP=41.4%(各类别 AP 领先)。
3.4.3 VEDAI 内容集
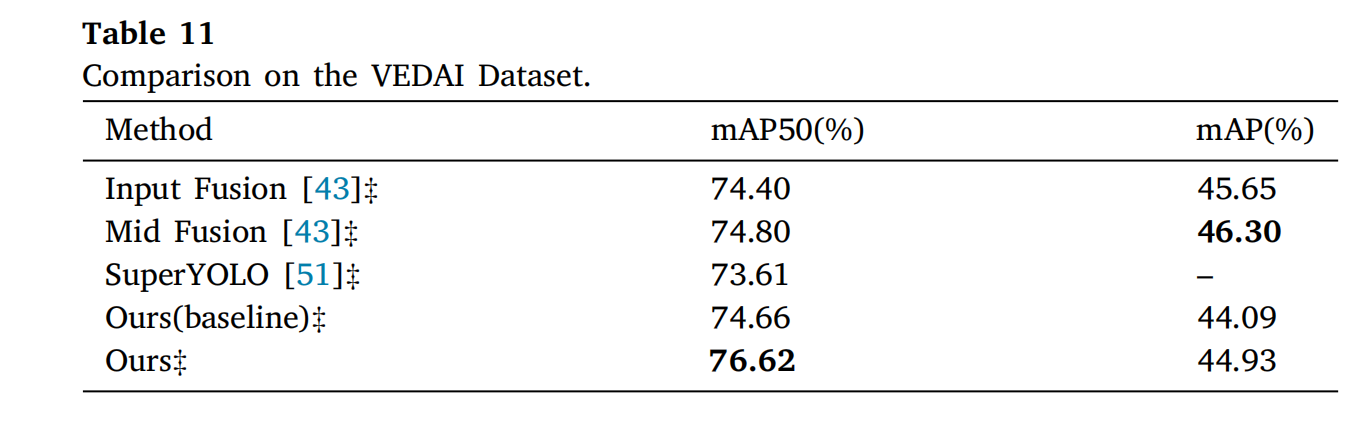
表 11 中m A P 50 = 76.62 % mAP_{50}=76.62\%mAP50=76.62%,小目标检测竞争力显著。
3.5 定性分析

图7. KAIST和FLIR数据集上注意力图的可视化结果。从左到右列:RGB和热图像中的真实标注(ground truth)、NIN融合[17]方法(基线)的热力图、以及我们提出的方法。
图 7 可视化注意力图:
- 光照不足场景:热模态特征实用辅助行人检测。
- 困难城市场景:跨模态全局信息减少误检(基线 NIN 注意力分散)。
3.6 局限性

图8. KAIST、FLIR和VEDAI数据集上的失败案例。从左到右列分别为KAIST数据集(a)、FLIR数据集(b)和VEDAI数据集(c)上的失败案例。红色三角形表示图像中的假阳性或假阴性。请放大查看更多细节。
图 8 展示失败案例:
- KAIST:低质量图像导致交通标志/树木误检为行人。
- FLIR:遮挡行人漏检。
- VEDAI:航拍视角下车辆与屋顶设备形状相似导致误判。
4. 结论
本文提出了一种适用于多光谱目标检测的新型跨模态特征融合框架 ——ICAFusion,该框架借助双交叉注意力 Transformer和迭代学习策略解决了传统方法在局部特征交互和计算复杂度上的局限性。具体贡献如下:
- 双交叉注意力特征增强(CFE)模块:通过跨模态的全局特征交互,捕获 RGB 与热图像的互补信息,显著提升特征判别力。与传统 Transformer 方法相比,本文设计的双分支结构仅通过辅助模态生成查询,计算复杂度降低 50%(见表 1)。
- 迭代跨模态特征增强(ICFE)模块:受人类知识复习机制启发,通过参数共享的迭代机制替代传统堆叠模块,在不增加可学习参数的前提下,实现特征的逐层细化。实验表明,仅需 1 次迭代即可使 FLIR 数据集的 mAP50 提升 1.7%,且推理速度达 36.7 FPS,优于堆叠 10 个模块的基线方法(见表 5、表 4)。
- 通用融合架构:所提途径可无缝集成到 YOLOv5、FCOS 等主流检测框架,并兼容 VGG16、ResNet50 等多种主干网络。在 KAIST、FLIR、VEDAI 资料集上的实验表明,ICAFusion 在检测精度(如 KAIST 数据集 MR 低至 7.17%)和推理速度(如 FLIR 数据集 38.46 FPS)上均优于现有方法。
局限性与未来工作:
尽管 ICAFusion 在多光谱融合中表现优异,但在极端遮挡(如 FLIR 材料集中重叠行人)、小目标(如 VEDAI 数据集)和模态严重失配场景下仍存在误检风险。未来计划通过以下方向优化:
- 引入层次化特征对齐机制,缓解图像错位对跨模态交互的影响;
- 设计轻量化注意力模块,进一步降低计算成本以适配边缘设备;
- 拓展至视频多模态任务,探索时空特征联合建模的可行性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/928068.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

软件设计师难考吗网站seo规划

做网站一般要了解哪些重庆妇科医院排名最好的医院
)

生成式AI改进极端多标签分类技术


NIO----JAVA - 教程

【清晰教程】利用Git工具将本地项目push上传至GitHub仓库中 - 指南

建设工程敎育那个网站青岛网站建设官网

建设银行的网站用户名服务器的作用

题解:2025.10.信友队.智灵班选拔面试题目

做义工旅行有哪些网站上海财务外包公司

电影网站网页设计手机微网站

如何用模板建站wordpress删除登录

南昌网站建设资讯公司官网制作教程

三合一网站怎么建立东莞做网站微信巴巴


实用指南:蓝桥杯_DS18B20温度传感器---新手入门级别超级详细解析
综合布线)
实用指南:【25软考网工】第十章 网络规划与设计(1)综合布线

2025.10.4 刷题
 - 指南)